Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Lakebase Autoscaling adalah versi terbaru Lakebase, dengan komputasi penskalaan otomatis, skala-ke-nol, percabangan, dan pemulihan instan. Untuk wilayah yang didukung, lihat Ketersediaan wilayah. Jika Anda adalah pengguna Lakebase Provisioned, lihat Lakebase Provisioned.
Panduan ini mencakup mengaktifkan dan mengelola ketersediaan tinggi untuk titik akhir Lakebase Anda. Untuk latar belakang tentang cara kerja ketersediaan tinggi dan bagaimana instans komputasi sekunder berbeda dari replika baca mandiri, lihat Ketersediaan tinggi.
Aktifkan ketersediaan tinggi
Untuk mengaktifkan ketersediaan tinggi, atur jenis komputasi dan konfigurasi HA di UI atau konfigurasikan titik EndpointGroupSpec akhir melalui API.
Prasyarat
- Fitur skala ke nol harus dinonaktifkan. Di UI, atur Skala ke nol menjadi Nonaktif di laci pengaturan komputasi. Melalui API, atur
no_suspension: truedalam spesifikasi titik akhir (gunakanspec.suspensionsebagai masker pembaruan).
Antarmuka Pengguna
Setelah membuat proyek, klik tautan komputasi utama di dasbor proyek untuk membuka laci mengedit komputasi.
dasbor proyek memperlihatkan cabang produksi dengan tautan komputasi utamanya
Atur Jenis komputasi ke Ketersediaan tinggi, lalu pilih Konfigurasi di bawah Ketersediaan tinggi:
- 2 (1 primer, 1 sekunder),
- 3 (1 primer, 2 sekunder),
- atau 4 (1 primer, 3 sekunder) total instansi komputasi.
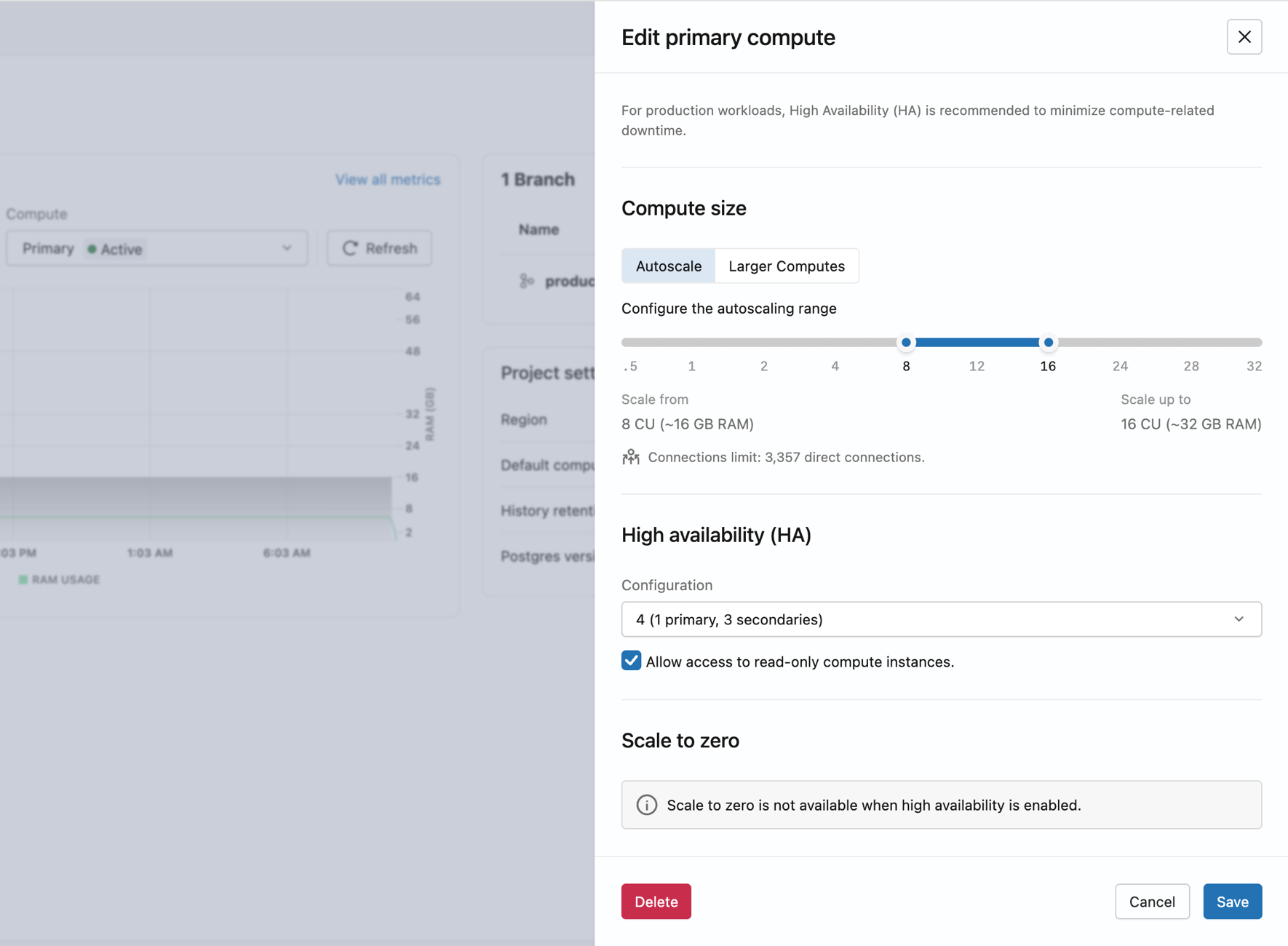
Lakebase menyediakan instans komputasi sekunder di zona ketersediaan yang berbeda. Setelah semua instans komputasi aktif, titik akhir memiliki failover otomatis.
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
Endpoint, EndpointSpec, EndpointType, EndpointGroupSpec, FieldMask
)
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-endpoint"
result = w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(
name=endpoint_name,
spec=EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
group=EndpointGroupSpec(
min=2,
max=2,
enable_readable_secondaries=True
)
)
),
update_mask=FieldMask(field_mask=["spec.group"])
).wait()
print(f"Group size: {result.status.group.max}")
print(f"Host: {result.status.hosts.host}")
print(f"Read-only host: {result.status.hosts.read_only_host}")
CLI
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
"spec.group" \
--json '{
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}'
melengkung
curl -X PATCH "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint?update_mask=spec.group" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-endpoint",
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}' | jq
Mengonfigurasi akses baca-saja ke instans komputasi sekunder
Mengizinkan akses ke instans komputasi baca-saja mengontrol apakah instans komputasi sekunder melayani lalu lintas baca melalui -ro string koneksi.
Antarmuka Pengguna
- Pada tab Komputasi , klik Edit pada komputasi utama.
- Di bawah Ketersediaan tinggi, centang atau hapus centang Izinkan akses ke instans komputasi baca-saja.
- Kliklah Simpan.
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
Endpoint, EndpointSpec, EndpointType, EndpointGroupSpec, FieldMask
)
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-endpoint"
# Get current group size first
current = w.postgres.get_endpoint(name=endpoint_name)
current_size = current.status.group.max
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(
name=endpoint_name,
spec=EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
group=EndpointGroupSpec(
min=current_size,
max=current_size,
enable_readable_secondaries=True # set False to disable
)
)
),
update_mask=FieldMask(field_mask=["spec.group.enable_readable_secondaries"])
).wait()
CLI
# Replace 2 with your current group size
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
"spec.group.enable_readable_secondaries" \
--json '{
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}'
melengkung
# Replace 2 with your current group size
curl -X PATCH "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint?update_mask=spec.group.enable_readable_secondaries" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-endpoint",
"spec": {
"group": {
"min": 2,
"max": 2,
"enable_readable_secondaries": true
}
}
}' | jq
Peringatan
Dengan hanya satu instans komputasi sekunder dan akses baca diaktifkan, semua lalu lintas baca pada string koneksi -ro terganggu selama failover hingga penggantian ditambahkan. Untuk akses baca yang tangguh, konfigurasikan dua atau beberapa instans komputasi sekunder dengan akses baca diaktifkan.
Mengubah jumlah instans komputasi sekunder
Antarmuka Pengguna
- Pada tab Komputasi , klik Edit pada komputasi utama.
- Pada Ketersediaan Tinggi, pilih konfigurasi komputasi baru dari dropdown (2, 3, atau 4 total instans komputasi).
- Kliklah Simpan.
Nota
Untuk menonaktifkan ketersediaan tinggi, atur jenis Komputasi kembali ke Komputasi tunggal. Ini menghapus semua instans komputasi sekunder dan titik akhir Anda kembali ke konfigurasi komputasi tunggal.
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import (
Endpoint, EndpointSpec, EndpointType, EndpointGroupSpec, FieldMask
)
w = WorkspaceClient()
endpoint_name = "projects/my-project/branches/production/endpoints/my-endpoint"
# Scale to 3 compute instances (1 primary + 2 secondaries)
w.postgres.update_endpoint(
name=endpoint_name,
endpoint=Endpoint(
name=endpoint_name,
spec=EndpointSpec(
endpoint_type=EndpointType.ENDPOINT_TYPE_READ_WRITE,
group=EndpointGroupSpec(min=3, max=3)
)
),
update_mask=FieldMask(field_mask=["spec.group.min", "spec.group.max"])
).wait()
CLI
# Scale to 3 compute instances (1 primary + 2 secondaries)
databricks postgres update-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
"spec.group.min,spec.group.max" \
--json '{
"spec": {
"group": { "min": 3, "max": 3 }
}
}'
melengkung
curl -X PATCH "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint?update_mask=spec.group.min,spec.group.max" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "projects/my-project/branches/production/endpoints/my-endpoint",
"spec": {
"group": { "min": 3, "max": 3 }
}
}' | jq
Melihat status dan peran ketersediaan tinggi
Tab Komputasi menunjukkan setiap instans komputasi dalam konfigurasi ketersediaan tinggi Anda dengan peran, status, dan tingkat aksesnya saat ini.
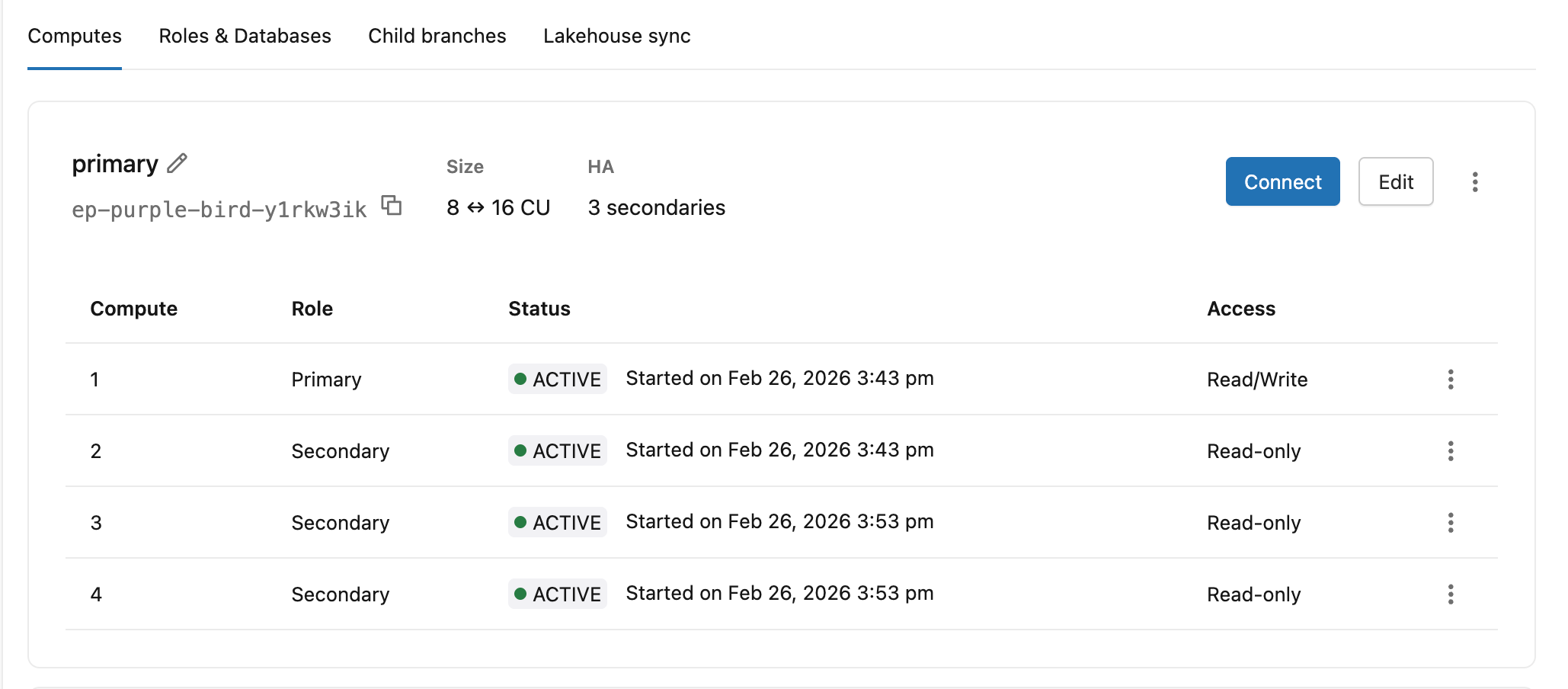
| kolom | Nilai |
|---|---|
| Peranan | Primer, Sekunder |
| Keadaan | Mulai, Aktif |
| Access | Baca/Tulis (utama), Baca-saja (instans komputasi sekunder dengan akses diaktifkan), Dinonaktifkan (instans komputasi sekunder tanpa akses baca) |
Header komputasi utama juga menunjukkan ID titik akhir, rentang penskalaan otomatis, dan jumlah sekunder (misalnya 8 ↔ 16 CU · 3 secondaries).
Dapatkan string koneksi
Antarmuka Pengguna
Klik Sambungkan pada komputasi utama untuk membuka dialog detail koneksi. Dropdown Komputasi mencantumkan kedua opsi koneksi untuk titik akhir ketersediaan tinggi Anda.
Dialog detail koneksi 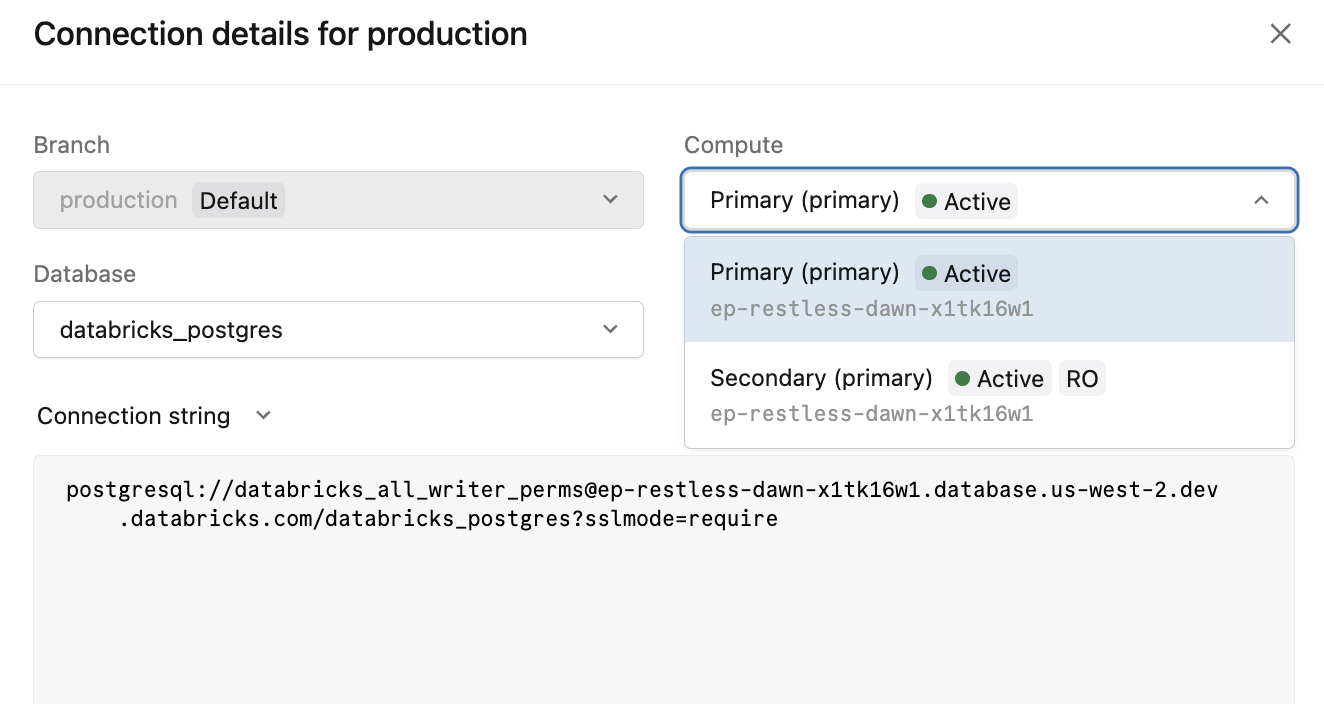
| Opsi komputasi | Rangkaian koneksi | Gunakan untuk |
|---|---|---|
Primary (name) ● Active |
{endpoint-id}.database.{region}.databricks.com |
Semua penulisan dan koneksi baca/tulis |
Secondary (name) ● Active RO |
{endpoint-id}-ro.database.{region}.databricks.com |
Pemindahan beban ke instans komputasi sekunder |
String koneksi -ro hanya tersedia jika mengizinkan akses ke instans komputasi read-only diaktifkan.
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
endpoint = w.postgres.get_endpoint(
name="projects/my-project/branches/production/endpoints/my-endpoint"
)
print(f"Read/write host: {endpoint.status.hosts.host}")
print(f"Read-only host: {endpoint.status.hosts.read_only_host}")
CLI
databricks postgres get-endpoint \
projects/my-project/branches/production/endpoints/my-endpoint \
-o json | jq '{rw_host: .status.hosts.host, ro_host: .status.hosts.read_only_host}'
melengkung
curl -X GET "$DATABRICKS_HOST/api/2.0/postgres/projects/my-project/branches/production/endpoints/my-endpoint" \
-H "Authorization: Bearer $DATABRICKS_TOKEN" \
| jq '{rw_host: .status.hosts.host, ro_host: .status.hosts.read_only_host}'
Untuk referensi lengkap connection string, lihat Connection strings.
Langkah berikutnya
- Ketersediaan tinggi — konsep, perilaku failover, dan praktik terbaik
- Replika baca — replika baca mandiri untuk kapasitas baca tambahan tanpa dukungan ketersediaan tinggi
- String koneksi