Pelatihan adalah proses di mana model belajar dari data berlabel Anda. Setelah pelatihan selesai, Anda akan dapat melihat performa model untuk menentukan apakah Anda perlu meningkatkan model Anda.
Untuk melatih model, mulai pekerjaan pelatihan. Hanya pekerjaan yang berhasil diselesaikan yang membuat model yang dapat digunakan. Pekerjaan pelatihan kedaluwarsa setelah tujuh hari. Setelah periode ini, Anda tidak akan dapat mengambil detail pekerjaan. Jika pekerjaan pelatihan Anda berhasil diselesaikan dan model dibuat, maka tidak akan terpengaruh oleh kedaluwarsa pekerjaan. Anda hanya dapat memiliki satu pekerjaan pelatihan yang berjalan pada satu waktu, dan Anda tidak dapat memulai pekerjaan lain dalam proyek yang sama.
Waktu pelatihan dapat dilakukan dari beberapa menit saat berhadapan dengan beberapa dokumen, hingga beberapa jam tergantung pada ukuran himpunan data dan kompleksitas skema Anda.
Sebelum Anda memulai proses pelatihan, dokumen berlabel dalam proyek Anda dibagi menjadi set pelatihan dan set pengujian. Masing-masing dari mereka melayani fungsi yang berbeda.
Set pelatihan digunakan dalam melatih model, ini adalah set tempat model mempelajari kelas/kelas yang ditetapkan ke setiap dokumen.
Set pengujian adalah perangkat buta yang tidak diperkenalkan ke model selama pelatihan tetapi hanya selama evaluasi.
Setelah model berhasil dilatih, model digunakan untuk membuat prediksi dari dokumen dalam set pengujian. Berdasarkan prediksi ini, metrik evaluasi model akan dihitung.
Disarankan untuk memastikan bahwa semua kelas Anda diwakili secara memadai dalam set pelatihan dan pengujian.
Klasifikasi teks kustom mendukung dua metode untuk pemisahan data:
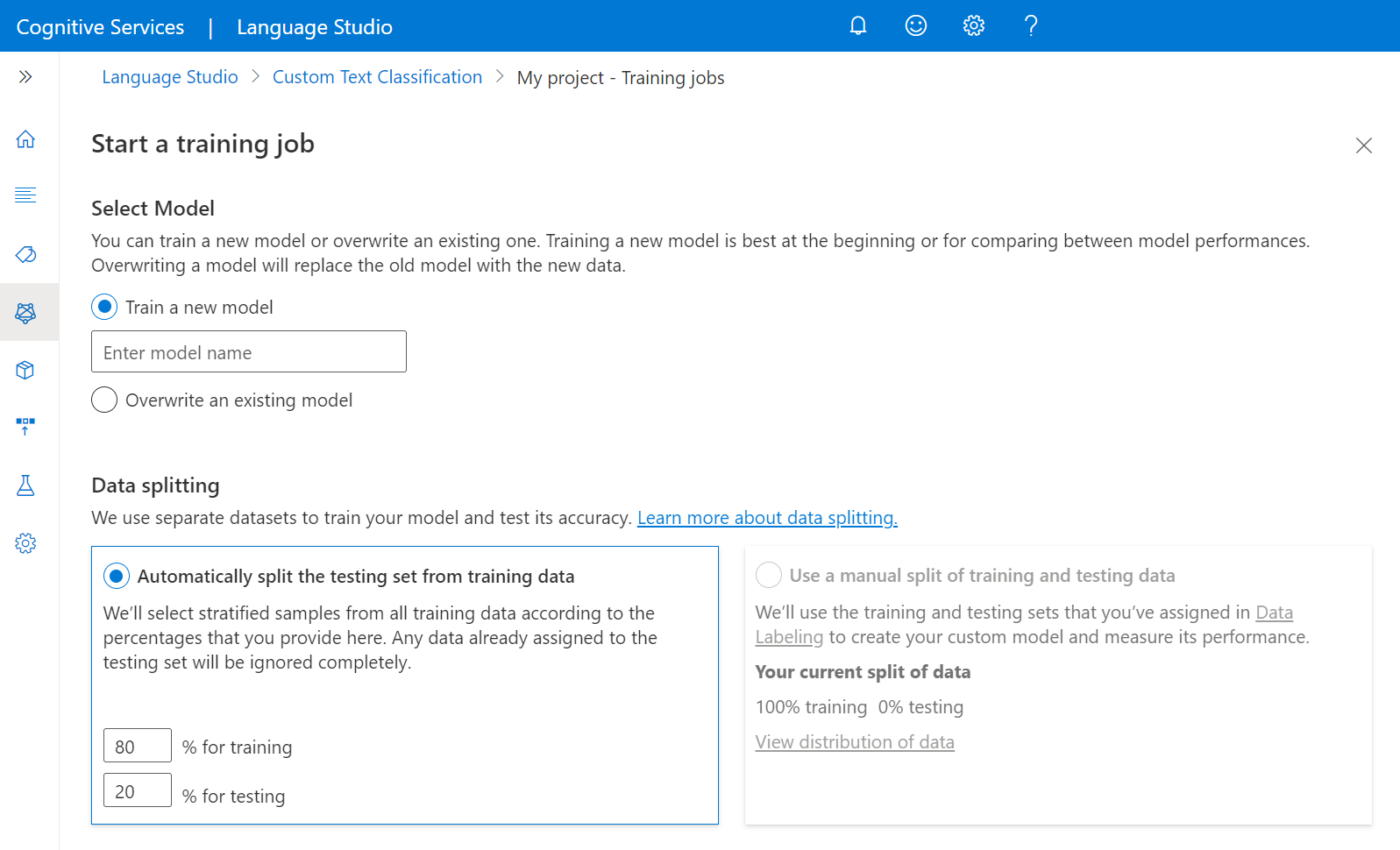
Secara otomatis memisahkan set pengujian dari data pelatihan: Sistem akan memisahkan data berlabel Anda antara set pengujian dan pelatihan, sesuai dengan persentase yang Anda pilih. Sistem akan mencoba untuk memiliki representasi semua kelas dalam set pelatihan Anda. Pembagian persentase yang disarankan adalah 80% untuk pelatihan dan 20% untuk pengujian.
Catatan
Jika Anda memilih opsi Memisahkan set pengujian dari data pelatihan secara otomatis, hanya data yang ditetapkan ke set pelatihan yang akan dibagi menurut persentase yang diberikan.
Gunakan pemisahan manual data pelatihan dan pengujian: Metode ini memungkinkan pengguna untuk menentukan dokumen berlabel mana yang harus termasuk dalam set mana. Langkah ini hanya diaktifkan jika Anda telah menambahkan dokumen ke set pengujian Selama pelabelan data.
Pilih Latih model baru dan ketik nama model di kotak teks. Anda juga dapat menimpa model yang ada dengan memilih opsi ini dan memilih model yang ingin Anda timpa dari menu drop-down. Menimpa model terlatih tidak dapat diubah, tetapi tidak akan memengaruhi model yang Anda sebarkan hingga Anda menyebarkan model baru.
Pilih metode pemisahan data. Anda dapat memilih Memisahkan set pengujian secara otomatis dari data pelatihan di mana sistem akan membagi data berlabel Anda antara set pelatihan dan pengujian, sesuai dengan persentase yang ditentukan. Atau Anda dapat Menggunakan pemisahan manual data pelatihan dan pengujian, opsi ini hanya diaktifkan jika Anda telah menambahkan dokumen ke set pengujian Anda selama pelabelan data. Lihat Cara melatih model untuk informasi selengkapnya tentang pemisahan data.
Pilih tombol Latih.
Jika Anda memilih ID pekerjaan pelatihan dari daftar, panel samping akan muncul di mana Anda dapat memeriksa kemajuan Pelatihan, Status pekerjaan, dan detail lainnya untuk pekerjaan ini.
Catatan
Hanya pekerjaan pelatihan yang berhasil diselesaikan yang akan menghasilkan model.
Waktu untuk melatih model dapat memakan waktu antara beberapa menit hingga beberapa jam berdasarkan ukuran data berlabel Anda.
Anda hanya dapat memiliki satu pekerjaan pelatihan yang berjalan pada satu waktu. Anda tidak dapat memulai pekerjaan pelatihan lain dalam proyek yang sama sampai pekerjaan yang sedang berjalan selesai.
Mulai pekerjaan pelatihan
Kirim permintaan POST menggunakan URL, header, dan isi JSON berikut untuk mengirimkan pekerjaan pelatihan. Ganti nilai tempat penampung di bawah ini dengan nilai Anda sendiri.
Nama proyek Anda. Nilai ini peka huruf besar/kecil.
myProject
{API-VERSION}
Versi API yang Anda panggil. Nilai yang dirujuk di sini adalah untuk versi terbaru yang dirilis. Pelajari selengkapnya tentang versi API lain yang tersedia
2022-05-01
Header
Gunakan header berikut untuk mengautentikasi permintaan Anda.
Tombol
Nilai
Ocp-Apim-Subscription-Key
Kunci sumber daya Anda. Digunakan untuk mengautentikasi permintaan API Anda.
Isi permintaan
Gunakan JSON berikut di isi permintaan Anda. Model akan diberi {MODEL-NAME} setelah pelatihan selesai. Hanya pekerjaan pelatihan yang berhasil yang akan menghasilkan model.
Nama model yang akan ditetapkan ke model Anda setelah berhasil dilatih.
myModel
trainingConfigVersion
{CONFIG-VERSION}
Ini adalah versi model yang akan digunakan untuk melatih model.
2022-05-01
evaluationOptions
Opsi untuk membagi data Anda di seluruh set pelatihan dan pengujian.
{}
jenis
percentage
Memisahkan metode. Nilai yang mungkin adalah percentage atau manual. Lihat Cara melatih model untuk informasi selengkapnya.
percentage
trainingSplitPercentage
80
Persentase data Anda yang diberi tag untuk disertakan dalam set pelatihan. Nilai yang disarankan adalah 80.
80
testingSplitPercentage
20
Persentase data Anda yang diberi tag untuk disertakan dalam set pengujian. Nilai yang disarankan adalah 20.
20
Catatan
trainingSplitPercentage dan testingSplitPercentage hanya diperlukan jika Kind diatur ke percentage dan jumlah kedua persentase harus sama dengan 100.
Setelah mengirim permintaan API, Anda akan menerima respons 202 yang menunjukkan bahwa pekerjaan telah dikirimkan dengan benar. Di header respons, ekstrak nilai location. Nilai ini akan diformat seperti ini:
{JOB-ID} digunakan untuk mengidentifikasi permintaan Anda, karena operasi ini tidak asinkron. Anda dapat menggunakan URL ini untuk mendapatkan status pelatihan.
Dapatkan status pekerjaan pelatihan
Pelatihan dapat memakan waktu tergantung pada ukuran data pelatihan dan kompleksitas skema Anda. Anda dapat menggunakan permintaan berikut untuk terus melakukan polling status pekerjaan pelatihan hingga berhasil diselesaikan.
Gunakan permintaan GET berikut untuk mendapatkan status kemajuan pelatihan model Anda. Ganti nilai tempat penampung di bawah ini dengan nilai Anda sendiri.
Nama proyek Anda. Nilai ini peka huruf besar/kecil.
myProject
{JOB-ID}
ID untuk menemukan status pelatihan model Anda. Nilai ini ada di nilai header location yang Anda terima pada langkah sebelumnya.
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx
{API-VERSION}
Versi API yang Anda panggil. Nilai yang dirujuk di sini adalah untuk versi terbaru yang dirilis. Lihat Siklus hidup model untuk mempelajari selengkapnya mengenai versi API lain yang tersedia.
2022-05-01
Header
Gunakan header berikut untuk mengautentikasi permintaan Anda.
Tombol
Nilai
Ocp-Apim-Subscription-Key
Kunci sumber daya Anda. Digunakan untuk mengautentikasi permintaan API Anda.
Isi Respons
Setelah mengirim permintaan, Anda akan mendapatkan respons berikut.
Untuk membatalkan pekerjaan pelatihan dalam Language Studio, buka halaman Pekerjaan pelatihan. Pilih pekerjaan pelatihan yang ingin Anda batalkan, dan pilih Batalkan dari menu atas.
Buat permintaan POST menggunakan URL, header, dan isi JSON berikut untuk membatalkan pekerjaan pelatihan.
URL Permintaan
Gunakan URL berikut saat membuat permintaan API Anda. Ganti nilai tempat penampung di bawah ini dengan nilai Anda sendiri.
Nama untuk proyek Anda. Nilai ini peka huruf besar/kecil.
EmailApp
{JOB-ID}
Nilai ini adalah ID pekerjaan pelatihan.
XXXXX-XXXXX-XXXX-XX
{API-VERSION}
Versi API yang Anda panggil. Nilai yang dirujuk adalah untuk versi model terbaru yang dirilis.
2022-05-01
Header
Gunakan header berikut untuk mengautentikasi permintaan Anda.
Tombol
Nilai
Ocp-Apim-Subscription-Key
Kunci sumber daya Anda. Digunakan untuk mengautentikasi permintaan API Anda.
Setelah mengirim permintaan API, Anda akan menerima respons 202 dengan Operation-Location header yang digunakan untuk memeriksa status pekerjaan.
Langkah berikutnya
Setelah pelatihan selesai, Anda akan dapat melihat performa model untuk secara opsional meningkatkan model Anda jika diperlukan. Setelah Anda puas dengan model Anda, Anda dapat menerapkannya, membuatnya tersedia untuk digunakan untuk mengklasifikasikan teks.