Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam artikel ini, Anda mempelajari cara mengukur dan meningkatkan akurasi ucapan dasar ke model teks atau model kustom Anda sendiri secara kuantitatif. Data transkrip berlabel audio + manusia diperlukan untuk menguji akurasi. Anda harus menyediakan audio perwakilan dari 30 menit hingga 5 jam.
Penting
Saat pengujian, sistem akan melakukan transkripsi. Hal ini penting untuk diingat, karena harga bervariasi per penawaran layanan dan tingkat langganan. Selalu lihat harga layanan Azure AI resmi untuk detail terbaru.
Membuat pengujian
Anda dapat menguji keakuratan model kustom Anda dengan membuat pengujian. Pengujian memerlukan kumpulan file audio dan transkripsi yang sesuai. Anda dapat membandingkan akurasi model kustom dengan model dasar ucapan ke teks atau model kustom lainnya. Setelah Anda mendapatkan hasil pengujian, lakukan evaluasi tingkat kesalahan kata (WER) dibandingkan dengan hasil pengenalan ucapan.
Setelah mengunggah himpunan data pelatihan dan pengujian, Anda dapat membuat pengujian.
Untuk menguji model ucapan kustom yang disempurnakan, ikuti langkah-langkah berikut:
Masuk ke portal Azure AI Foundry.
Pilih Penyempurnaan dari panel kiri lalu pilih Penyempurnaan Layanan AI.
Pilih tugas penyempurnaan ucapan kustom (berdasarkan nama model) yang Anda mulai seperti yang dijelaskan dalam artikel cara memulai penyempurnaan ucapan kustom.
Pilih Uji model>+ Buat pengujian.
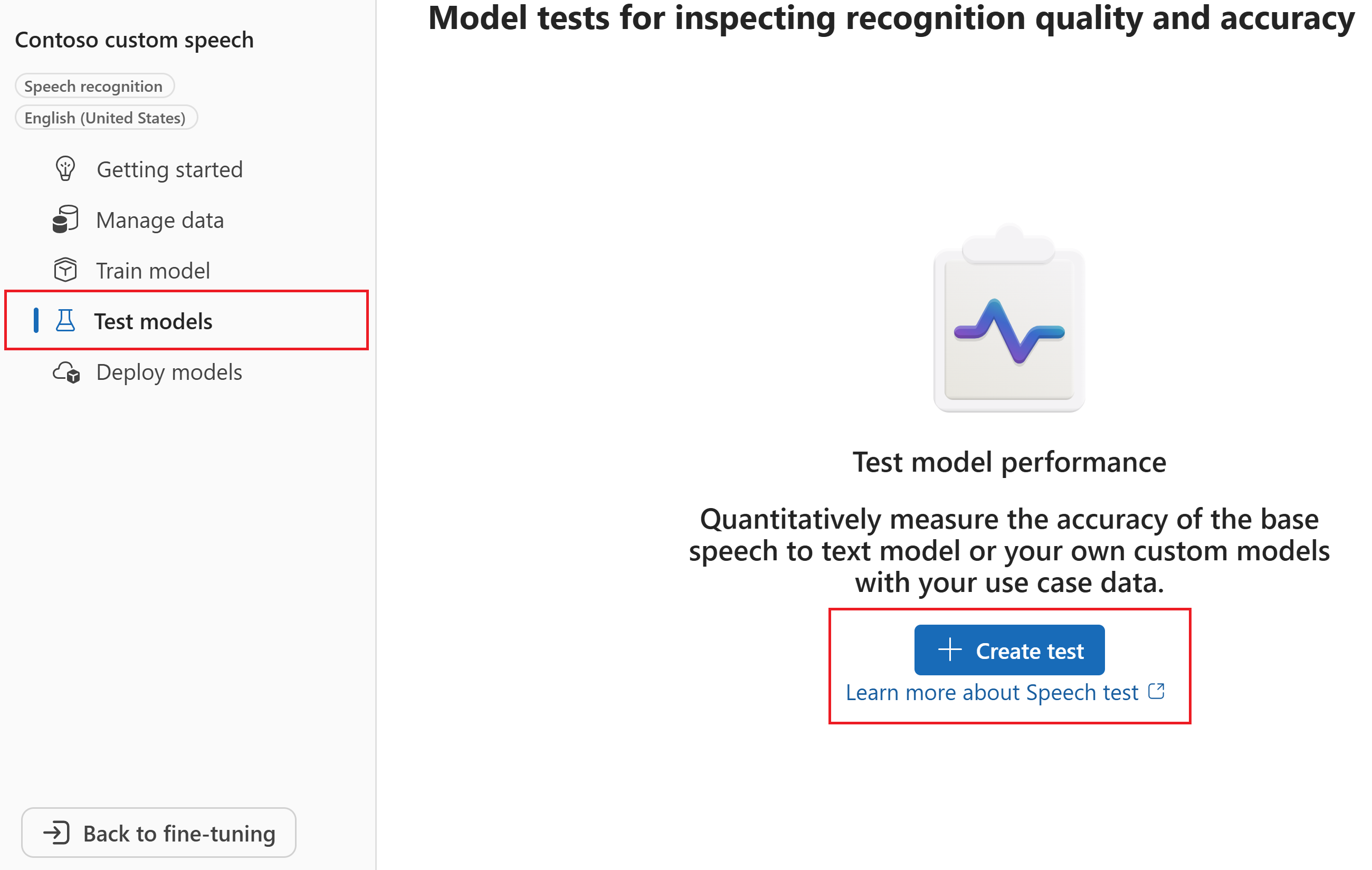
Di wizard Buat pengujian baru, pilih jenis pengujian. Untuk pengujian akurasi (kuantitatif), pilih Evaluasi akurasi (Audio + data transkrip). Kemudian pilih Berikutnya.
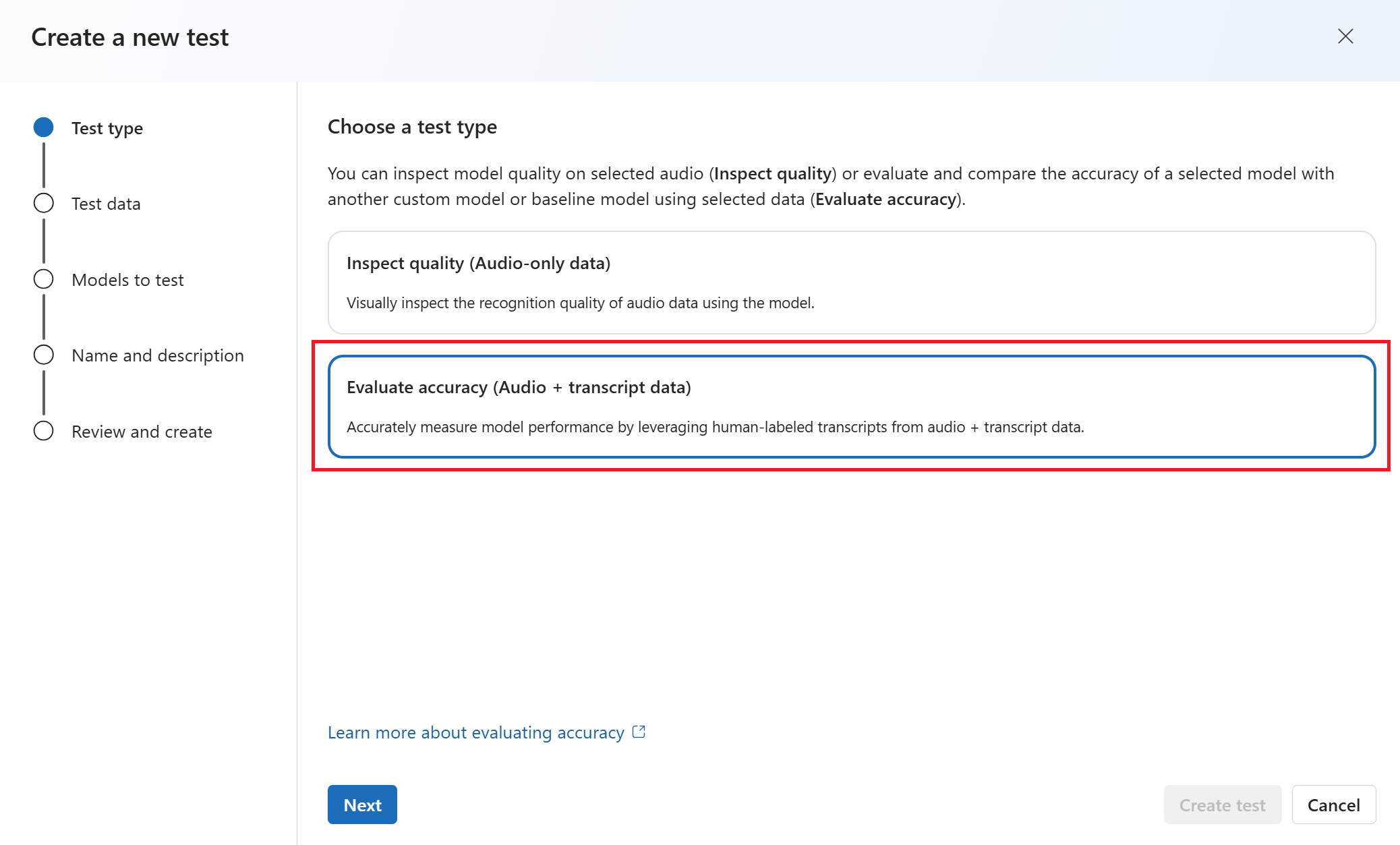
Pilih data yang ingin Anda gunakan untuk pengujian. Kemudian pilih Berikutnya.
Pilih hingga dua model untuk mengevaluasi dan membandingkan akurasi. Dalam contoh ini, kami memilih model yang kami latih dan model dasar. Kemudian pilih Berikutnya.
Masukkan nama dan deskripsi untuk pengujian. Kemudian pilih Berikutnya.
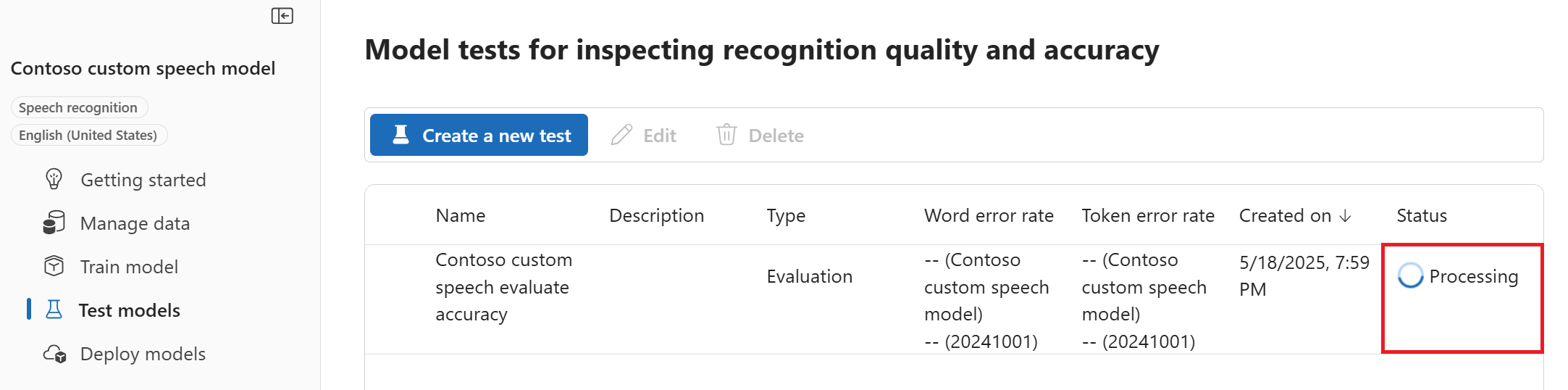
Tinjau pengaturan dan pilih Buat pengujian. Anda dibawa kembali ke halaman Uji model . Status data adalah Pemrosesan.




Ikuti langkah-langkah ini untuk membuat pengujian akurasi:
Masuk ke Speech Studio.
Pilih Ucapan> kustom Model pengujian nama >proyek Anda.
Pilih Buat pengujian baru.
Pilih Evaluasi akurasi>Berikutnya.
Pilih satu himpunan data transkripsi berlabel audio + manusia, lalu pilih Berikutnya. Jika tidak ada himpunan data yang tersedia, batalkan penyiapan, lalu buka menu Himpunan data ucapan untuk mengunggah himpunan data.
Catatan
Penting untuk memilih himpunan data akustik yang berbeda dari yang Anda gunakan dengan model Anda. Pendekatan ini dapat memberikan performa model yang lebih realistis.
Pilih hingga dua model untuk dievaluasi, lalu pilih Berikutnya.
Masukkan nama dan deskripsi pengujian, lalu pilih Berikutnya.
Tinjau detail pengujian, lalu pilih Simpan dan tutup.
Untuk membuat pengujian, gunakan perintah spx csr evaluation create. Buat parameter permintaan sesuai dengan instruksi berikut:
- Atur
projectproperti ke ID proyek yang sudah ada. Properti ini direkomendasikan sehingga Anda juga dapat melihat pengujian di portal Azure AI Foundry. Anda dapat menjalankan perintahspx csr project listuntuk mendapatkan proyek yang tersedia. - Atur properti yang diperlukan
model1ke ID model yang ingin Anda uji. - Atur properti yang diperlukan
model2ke ID model lain yang ingin Anda uji. Jika Anda tidak ingin membandingkan dua model, gunakan model yang sama untukmodel1danmodel2. - Atur properti yang diperlukan
datasetke ID himpunan data yang ingin Anda gunakan untuk pengujian. - Atur
languageproperti , jika tidak, Speech CLI mengatur "en-US" secara default. Parameter ini harus menjadi lokal konten himpunan data. Lokal tidak dapat diubah nanti. Propertilanguagepada Speech CLI sesuai dengan propertilocaledalam permintaan dan respons JSON. - Atur properti
nameyang diperlukan. Parameter ini adalah nama yang ditampilkan di portal Azure AI Foundry. Propertinamepada Speech CLI sesuai dengan propertidisplayNamedalam permintaan dan respons JSON.
Berikut adalah contoh perintah Speech CLI yang membuat pengujian:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 ff43e922-e3e6-4bf0-8473-55c08fd68048 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Evaluation" --description "My Evaluation Description"
Anda akan menerima isi respons dalam format berikut:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Properti self tingkat atas dalam isi respons adalah URI evaluasi. Gunakan URI ini untuk mendapatkan detail tentang proyek dan hasil pengujian. Anda juga menggunakan URI ini untuk memperbarui atau menghapus evaluasi.
Untuk bantuan Speech CLI dengan evaluasi, jalankan perintah berikut:
spx help csr evaluation
Untuk membuat pengujian, gunakan operasi Evaluations_Create REST API Ucapan ke teks. Buat isi permintaan sesuai dengan instruksi berikut:
- Atur properti
projectke URI proyek yang ada. Properti ini direkomendasikan sehingga Anda juga dapat melihat pengujian di portal Azure AI Foundry. Anda dapat membuat permintaan Projects_List untuk mendapatkan proyek yang tersedia. - Atur properti
testingKindkeEvaluationdalamcustomProperties. Jika Anda tidak menentukanEvaluation, pengujian diperlakukan sebagai uji pemeriksaan kualitas. ApakahtestingKindproperti diatur keEvaluationatauInspection, atau tidak, Anda dapat mengakses skor akurasi melalui API, tetapi tidak di portal Azure AI Foundry. - Atur properti
model1yang diperlukan ke URI model yang ingin Anda uji. - Atur properti
model2yang diperlukan ke URI model lain yang ingin Anda uji. Jika Anda tidak ingin membandingkan dua model, gunakan model yang sama untukmodel1danmodel2. - Atur properti
datasetyang diperlukan ke URI himpunan data yang ingin Anda gunakan untuk pengujian. - Atur properti
localeyang diperlukan. Properti ini harus menjadi lokal konten himpunan data. Lokal tidak dapat diubah nanti. - Atur properti
displayNameyang diperlukan. Properti ini adalah nama yang ditampilkan di portal Azure AI Foundry.
Buat permintaan HTTP POST menggunakan URI seperti yang ditunjukkan dalam contoh berikut. Ganti YourSpeechResoureKey dengan kunci sumber daya Ucapan Anda, ganti YourServiceRegion dengan wilayah sumber daya Ucapan Anda, dan atur properti isi permintaan seperti yang dijelaskan sebelumnya.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
},
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
Anda akan menerima isi respons dalam format berikut:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Properti self tingkat atas dalam isi respons adalah URI evaluasi. Gunakan URI ini untuk mendapatkan detail tentang proyek evaluasi dan hasil pengujian. Anda juga menggunakan URI ini untuk memperbarui atau menghapus evaluasi.
Mendapatkan hasil pengujian
Anda akan mendapatkan hasil pengujian dan mengevaluasi tingkat kesalahan kata (WER) yang dibandingkan dengan hasil pengenalan ucapan.
Saat status pengujian Berhasil, Anda dapat melihat hasilnya. Pilih pengujian untuk melihat hasilnya.
Ikuti langkah-langkah berikut untuk mendapatkan hasil pengujian:
- Masuk ke Speech Studio.
- Pilih Ucapan> kustom Model pengujian nama >proyek Anda.
- Pilih link berdasarkan nama pengujian.
- Setelah pengujian selesai, seperti yang ditunjukkan oleh status yang diatur ke Berhasil, Anda akan melihat hasil yang menyertakan nomor WER untuk setiap model yang diuji.
Halaman ini mencantumkan semua ungkapan dalam himpunan data Anda dan hasil pengenalan, serta transkripsi dari himpunan data yang dikirim. Anda dapat beralih ke berbagai jenis kesalahan, termasuk penyisipan, penghapusan, dan penggantian. Dengan mendengarkan audio dan membandingkan hasil pengenalan di setiap kolom, Anda dapat memutuskan model mana yang memenuhi kebutuhan Anda dan menentukan di mana lebih banyak pelatihan dan peningkatan diperlukan.
Untuk mendapatkan hasil pengujian, gunakan perintah spx csr evaluation status. Buat parameter permintaan sesuai dengan instruksi berikut:
- Atur properti yang diperlukan
evaluationke ID evaluasi yang ingin Anda dapatkan hasil pengujiannya.
Berikut adalah contoh perintah Speech CLI yang mendapatkan hasil pengujian:
spx csr evaluation status --api-version v3.2 --evaluation 8bfe6b05-f093-4ab4-be7d-180374b751ca
Tingkat kesalahan kata dan detail selengkapnya ditampilkan dalam isi respons.
Anda akan menerima isi respons dalam format berikut:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Untuk bantuan Speech CLI dengan evaluasi, jalankan perintah berikut:
spx help csr evaluation
Untuk mendapatkan hasil pengujian, mulailah dengan menggunakan operasi Evaluations_Get REST API Ucapan ke teks.
Buat permintaan HTTP GET menggunakan URI seperti yang ditunjukkan dalam contoh berikut. Ganti YourEvaluationId dengan ID evaluasi Anda, ganti YourSpeechResoureKey dengan kunci sumber Ucapan Anda, dan ganti YourServiceRegion dengan wilayah sumber Ucapan Anda.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey"
Tingkat kesalahan kata dan detail selengkapnya ditampilkan dalam isi respons.
Anda akan menerima isi respons dalam format berikut:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Mengevaluasi tingkat kesalahan kata (WER)
Standar industri untuk mengukur akurasi model adalah word error rate (WER). WER menghitung jumlah kata yang salah yang diidentifikasi selama pengenalan, lalu dibagi dengan jumlah total kata yang disediakan dalam transkrip berlabel manusia (N).
Kata-kata yang salah diidentifikasi termasuk dalam tiga kategori:
- Penyisipan (I): Kata-kata yang salah ditambahkan dalam transkrip hipotesis
- Penghapusan (D): Kata-kata yang tidak terdeteksi dalam transkrip hipotesis
- Substitusi (S): Kata-kata yang digantikan antara referensi dan hipotesis
Di portal Azure AI Foundry dan Speech Studio, kuota dikalikan dengan 100 dan ditampilkan sebagai persentase. Hasil Speech CLI dan REST API tidak dikalikan dengan 100.
$$ WER = {{I+D+S}\over N} \times 100 $$
Berikut adalah contoh yang menunjukkan kata-kata yang salah diidentifikasi, saat dibandingkan dengan transkrip berlabel manusia:

Hasil pengenalan ucapan yang salah adalah sebagai berikut:
- Penyisipan (I): Menambahkan kata "a"
- Penghapusan (D): Menghapus kata "are"
- Penggantian (S): Mengganti kata "Jones" untuk "John"
Tingkat kesalahan kata dari contoh sebelumnya adalah 60%.
Jika ingin mereplikasi pengukuran WER secara lokal, Anda dapat menggunakan alat sclite dari NIST Scoring Toolkit (SCTK).
Mengatasi kesalahan dan meningkatkan WER
Anda dapat menggunakan perhitungan WER dari hasil pengenalan komputer untuk mengevaluasi kualitas model yang digunakan dengan aplikasi, alat, atau produk. WER dengan persentase 5-10% dianggap memiliki kualitas yang baik dan siap digunakan. WER sebesar 20% dapat diterima, tetapi Anda mungkin ingin mempertimbangkan lebih banyak pelatihan. WER sebesar 30% atau lebih menandakan kualitas buruk dan memerlukan penyesuaian dan pelatihan.
Cara kesalahan didistribusikan itu penting. Saat banyak kesalahan penghapusan dialami, biasanya karena kekuatan sinyal audio yang lemah. Untuk mengatasi masalah ini, Anda harus mengumpulkan data audio yang lebih mendekati sumbernya. Kesalahan penyisipan berarti bahwa audio direkam di lingkungan yang bising dan crosstalk mungkin ada, yang menyebabkan masalah pengenalan. Kesalahan substitusi sering ditemui ketika sampel istilah khusus domain yang tidak memadai disediakan sebagai transkripsi berlabel manusia atau teks terkait.
Dengan menganalisis file individual, Anda dapat menentukan jenis kesalahan apa yang ada, dan kesalahan mana yang unik untuk file tertentu. Memahami masalah di tingkat file membantu Anda menargetkan peningkatan.
Mengevaluasi tingkat kesalahan token (TER)
Selain tingkat kesalahan kata, Anda juga dapat menggunakan pengukuran laju Kesalahan Token (TER) yang diperluas untuk mengevaluasi kualitas pada format tampilan end-to-end akhir. Selain format leksikal (That will cost $900. alih-alih that will cost nine hundred dollars), TER memperhitungkan aspek format tampilan seperti tanda baca, kapitalisasi, dan ITN. Pelajari selengkapnya tentang Menampilkan pemformatan output dengan ucapan ke teks.
TER menghitung jumlah token yang salah yang diidentifikasi selama pengenalan, dan membagi jumlah dengan jumlah total token yang disediakan dalam transkrip berlabel manusia (N).
$$ TER = {{I+D+S}\over N} \times 100 $$
Rumus perhitungan TER juga mirip dengan WER. Satu-satunya perbedaan adalah BAHWA TER dihitung berdasarkan tingkat token alih-alih tingkat kata.
- Penyisipan (I): Token yang salah ditambahkan dalam transkrip hipotesis
- Penghapusan (D): Token yang tidak terdeteksi dalam transkrip hipotesis
- Substitusi (S): Token yang diganti antara referensi dan hipotesis
Dalam kasus dunia nyata, Anda dapat menganalisis hasil WER dan TER untuk mendapatkan peningkatan yang diinginkan.
Catatan
Untuk mengukur TER, Anda perlu memastikan data pengujian audio + transkrip menyertakan transkrip dengan pemformatan tampilan seperti tanda baca, kapitalisasi, dan ITN.
Contoh hasil skenario
Skenario pengenalan ucapan bervariasi menurut kualitas audio dan bahasa (kosakata dan gaya berbicara). Tabel berikut memeriksa empat skenario umum:
| Skenario | Kualitas audio | Kosakata | Gaya berbicara |
|---|---|---|---|
| Pusat panggilan | Rendah, 8 kHz, bisa dua manusia di satu saluran audio, dapat dikompresi | Sempit, unik untuk domain dan produk | Percakapan, terstruktur secara longgar |
| Asisten suara seperti Cortana, atau jendela drive-through | Tinggi, 16 kHz | Entitas berat (judul lagu, produk, lokasi) | Kata dan frasa yang dinyatakan dengan jelas |
| Dikte (pesan instan, catatan, pencarian) | Tinggi, 16 kHz | Bervariasi | Pencatatan |
| Teks tertutup video | Bervariasi, termasuk penggunaan mikrofon yang bervariasi, musik yang ditambahkan | Bervariasi, dari rapat, ucapan yang dibacakan, lirik musik | Dibaca, disiapkan, atau terstruktur secara longgar |
Skenario yang berbeda menghasilkan hasil kualitas yang berbeda. Tabel berikut memeriksa cara konten dari keempat skenario ini menilai dalam (WER). Tabel menunjukkan jenis kesalahan mana yang paling umum dalam setiap skenario. Tingkat kesalahan penyisipan, penggantian, dan penghapusan membantu Anda menentukan jenis data yang akan ditambahkan untuk meningkatkan model.
| Skenario | Kualitas pengenalan ucapan | Kesalahan penyisipan | Kesalahan penghapusan | Kesalahan penggantian |
|---|---|---|---|---|
| Pusat panggilan | Menengah (< 30% WER) |
Rendah, kecuali saat orang lain berbicara di latar belakang | Bisa tinggi. Pusat panggilan bisa berisik, dan pembicara yang tumpang tindih dapat membingungkan model | Sedang. Produk dan nama orang dapat menyebabkan kesalahan ini |
| Asisten suara | Sangat Penting (bisa < 10% WER) |
Kurang Penting | Kurang Penting | Sedang, karena judul lagu, nama produk, atau lokasi |
| Pendiktean | Sangat Penting (bisa < 10% WER) |
Kurang Penting | Kurang Penting | Sangat Penting |
| Teks tertutup video | Bergantung pada jenis video (bisa < 50% WER) | Kurang Penting | Bisa tinggi karena musik, kebisingan, kualitas mikrofon | Jargon mungkin menyebabkan kesalahan ini |