Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Saat Anda siap untuk membuat teks kustom ke suara ucapan untuk aplikasi Anda, langkah pertama adalah mengumpulkan rekaman audio dan skrip terkait untuk mulai melatih model suara. Untuk detail tentang cara merekam sampel suara, lihat tutorial. Layanan Ucapan menggunakan data ini untuk membuat suara unik yang disetel agar sesuai dengan suara dalam rekaman. Setelah melatih suara, Anda dapat mulai mensintesis ucapan dalam aplikasi Anda.
Setiap data yang Anda unggah harus memenuhi persyaratan untuk jenis data yang dipilih. Data harus diformat dengan benar sebelum diunggah untuk memastikan bahwa data itu akan diproses secara akurat oleh layanan Azure Cognitive Service untuk Ucapan. Untuk mengonfirmasi bahwa data Anda diformat dengan benar, lihat Jenis data pelatihan.
Catatan
- Pengguna langganan standar (S0) dapat mengunggah lima himpunan data sekaligus. Jika batas tercapai, tunggu hingga setidaknya salah satu himpunan data Anda selesai diimpor. Kemudian coba lagi.
- Jumlah maksimum file data yang diizinkan untuk diimpor per langganan adalah 500 file .zip untuk pengguna langganan standar (S0). Harap lihat Kuota dan batas layanan ucapan untuk detail selengkapnya.
Unggah data Anda
Petunjuk / Saran
Untuk contoh pernyataan persetujuan dan data pelatihan, lihat repositori GitHub.
Jika sudah siap mengunggah data, buka tab Siapkan data pelatihan untuk menambahkan set pelatihan pertama Anda dan mengunggah data. Set pelatihan adalah sekumpulan ungkapan audio dan skrip pemetaannya yang digunakan untuk melatih model suara. Anda dapat menggunakan set pelatihan untuk mengatur data pelatihan Anda. Layanan ini memeriksa kesiapan data per setiap set pelatihan. Anda dapat mengimpor beberapa data ke set pelatihan.
Untuk mengunggah data pelatihan, ikuti langkah-langkah berikut:
Masuk ke portal Azure AI Foundry.
Pilih Penyempurnaan dari panel kiri lalu pilih Penyempurnaan Layanan AI.
Pilih tugas penyesuaian suara profesional (berdasarkan nama model) yang Anda mulai sebagaimana dijelaskan dalam artikel membuat suara profesional.
Pilih Siapkan data> pelatihanUnggah data.
Di wizard Unggah data , pilih jenis data. Jika Anda menggunakan data sampel, pilih Ucapan individual + transkrip yang cocok.
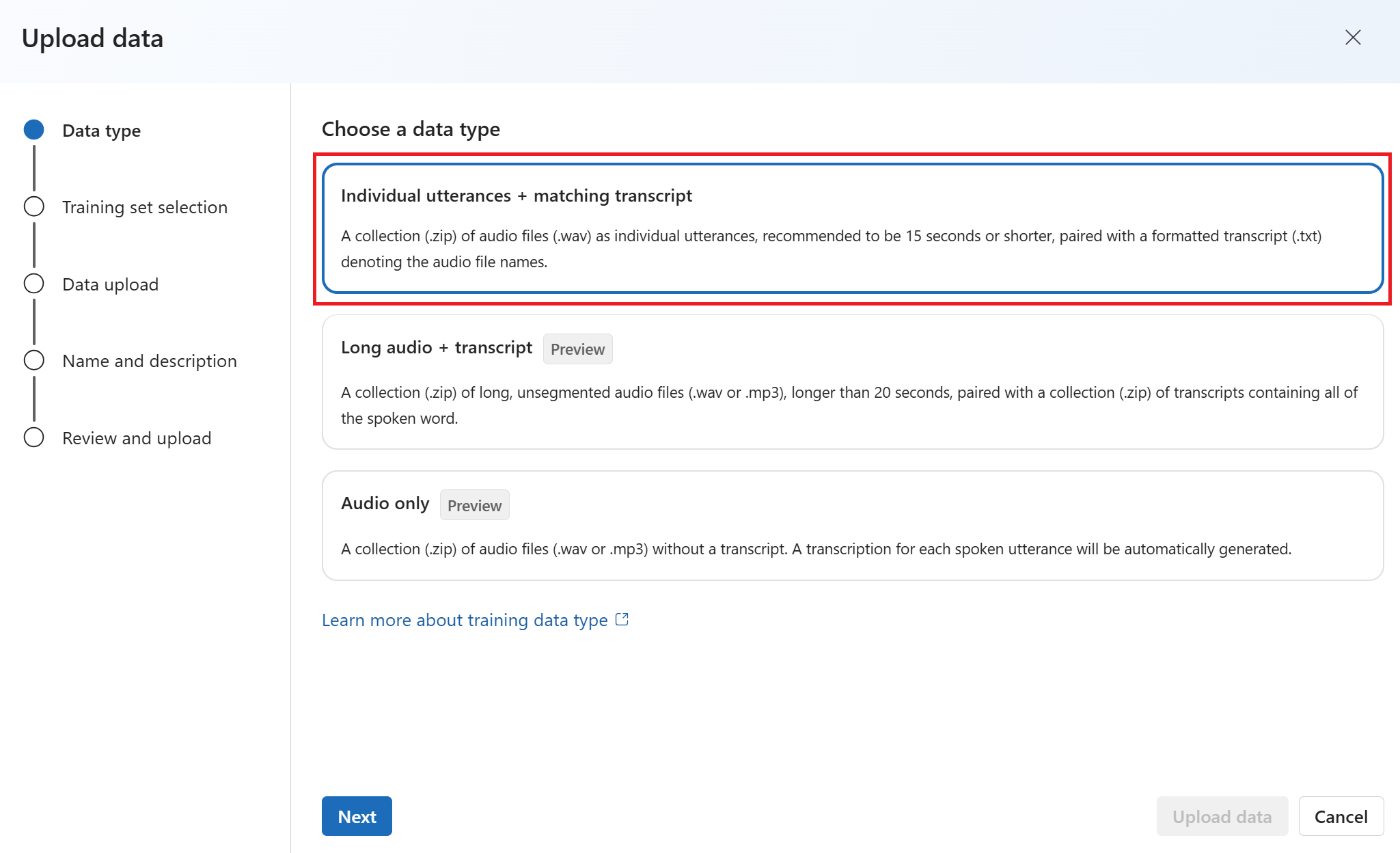
Pilih Selanjutnya.
Pada halaman Tentukan set pelatihan target , pilih Buat baru.
Masukkan nama set pelatihan lalu pilih Buat.
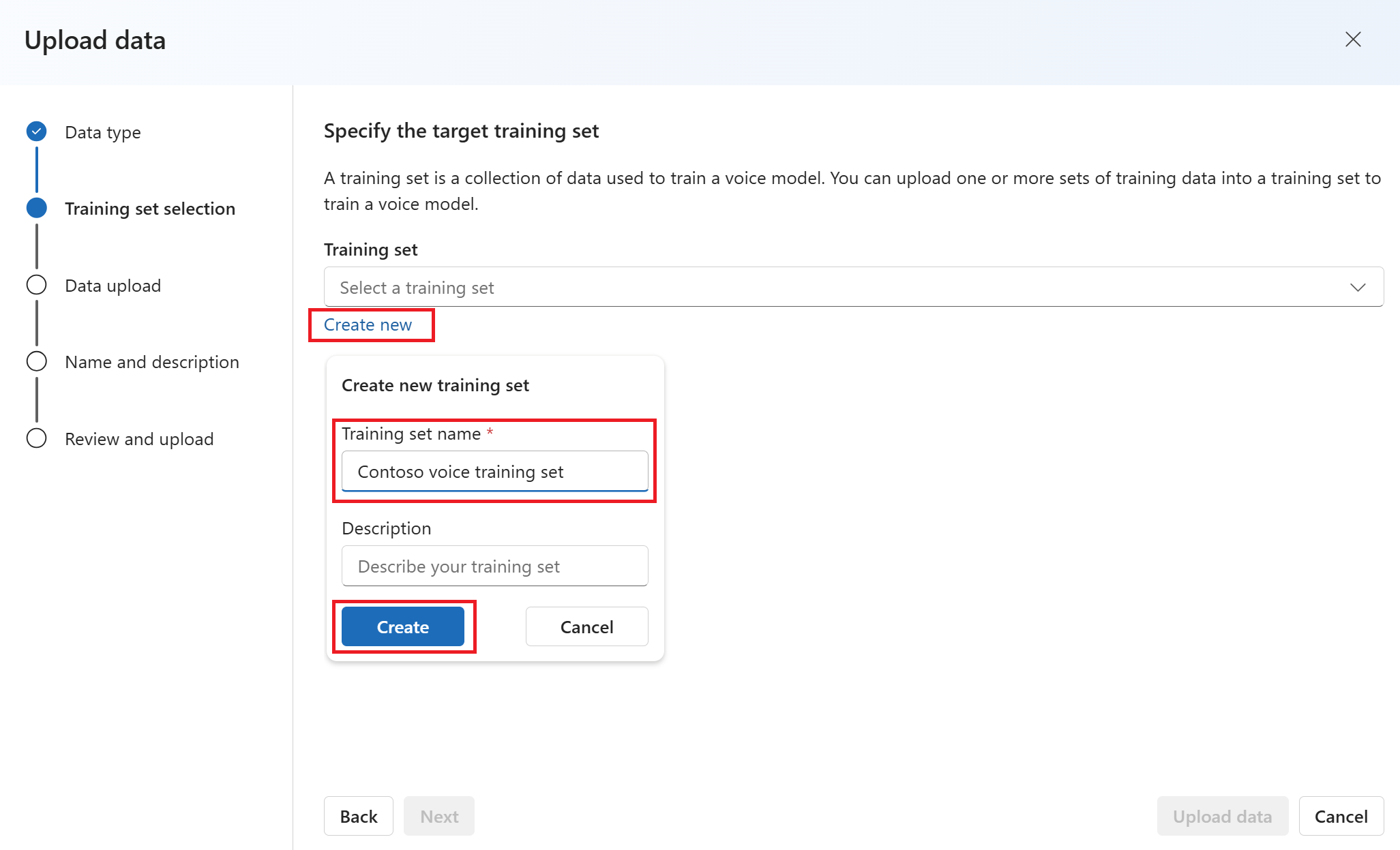
Pilih Selanjutnya.
Pada halaman Pengunggahan data , pilih File rekaman dan file Skrip di petak peta masing-masing. Anda dapat memilih file lokal dari komputer Anda atau memasukkan URL penyimpanan Azure Blob untuk mengunggah data.
Pilih Selanjutnya.
Masukkan nama dan deskripsi untuk data Anda lalu pilih Berikutnya.
Tinjau detail unggahan, dan pilih Unggah data.


Catatan
ID duplikat tidak diterima. Ucapan dengan ID yang sama akan dihapus.
Nama audio duplikat akan dihapus dari pelatihan. Pastikan data yang Anda pilih tidak berisi nama audio yang sama dalam file .zip atau di beberapa file .zip. Jika ID ungkapan (baik dalam file audio maupun skrip) berupa duplikat, ID ini akan ditolak.
File data secara otomatis divalidasi saat Anda memilih Unggah data. Validasi data meliputi serangkaian pemeriksaan pada file audio untuk memverifikasi format file, ukuran, dan laju pengambilan sampelnya. Jika ada kesalahan, perbaiki dan kirimkan lagi.
Setelah mengunggah data itu, Anda dapat memeriksa detail dalam tampilan detail set pelatihan. Pada halaman detail, Anda dapat memeriksa lebih lanjut masalah pengucapan dan tingkat kebisingan untuk setiap data Anda. Skor pengucapan pada tingkat kalimat berkisar antara 0-100. Skor di bawah 70 biasanya menunjukkan kesalahan ucapan atau ketidakcocokan skrip. Ucapan dengan skor keseluruhan yang lebih rendah dari 70 akan ditolak. Aksen berat dapat mengurangi skor pengucapan dan berdampak pada suara digital yang dihasilkan.
Mengatasi masalah data secara online
Setelah mengunggah, Anda dapat memeriksa detail data kumpulan pelatihan. Sebelum terus melatih model suara, Anda harus mencoba menyelesaikan masalah data apa pun.
Masalah data yang umum
Masalah ini dibagi menjadi tiga jenis. Lihat tabel berikut untuk memeriksa jenis kesalahan masing-masing.
Ditolak otomatis
Data dengan kesalahan ini tidak akan digunakan untuk pelatihan. Data yang diimpor dengan kesalahan akan diabaikan, sehingga Anda tidak perlu menghapusnya. Anda dapat memperbaiki kesalahan data ini secara online atau mengunggah data yang dikoreksi lagi untuk pelatihan.
| Kategori | Nama | Deskripsi |
|---|---|---|
| Skrip | Pemisah tidak valid | Anda harus memisahkan ID ungkapan dan konten skrip dengan karakter Tab. |
| Skrip | ID skrip tidak valid | ID baris skrip harus berupa angka. |
| Skrip | Skrip duplikat | Setiap baris konten skrip harus unik. Garis ini diduplikasi dengan {}. |
| Skrip | Skrip terlalu panjang | Skrip harus kurang dari 1.000 karakter. |
| Skrip | Tidak ada audio yang cocok | ID dari setiap ucapan (setiap baris file skrip) harus sesuai dengan ID audio. |
| Skrip | Tidak ada skrip yang valid | Tak ada skrip valid yang ditemukan dalam himpunan data ini. Perbaiki baris skrip yang muncul dalam daftar masalah terperinci. |
| Suara | Tidak ada skrip yang cocok | Tidak ada file audio yang cocok dengan ID skrip. Nama file .wav harus cocok dengan ID dalam file skrip. |
| Suara | Format audio tidak valid | Format audio dari file .wav tidak valid. Periksa format file .wav menggunakan alat audio seperti SoX. |
| Suara | Laju pengambilan sampel rendah | Tingkat pengambilan sampel file .wav tidak boleh lebih rendah dari 16 KHz. |
| Suara | Audio terlalu panjang | Durasi audio lebih dari 30 detik. Pisahkan audio panjang menjadi beberapa file. Sebaiknya buat ungkapan lebih singkat dari 15 detik. |
| Suara | Tidak ada audio yang valid | Tidak ada audio sahih dalam himpunan data ini. Periksa data audio Anda dan unggah lagi. |
| Tidak cocok | Ucapan dengan skor rendah | Skor pengucapan tingkat kalimat lebih rendah dari 70. Baca skrip dan konten audio untuk memastikan keduanya cocok. |
Diperbaiki otomatis
Kesalahan berikut diperbaiki secara otomatis, tetapi sebaiknya tinjau dan konfirmasi bahwa perbaikan dilakukan dengan benar.
| Kategori | Nama | Deskripsi |
|---|---|---|
| Tidak cocok | Keheningan diperbaiki otomatis | Keheningan awal terdeteksi lebih dari 100 ms, dan telah dipangkas menjadi 100 ms secara otomatis. Unduh himpunan data yang dinormalkan dan tinjau. |
| Tidak cocok | Keheningan diperbaiki otomatis | Keheningan akhir terdeteksi lebih pendek dari 100 ms, dan telah diperpanjang menjadi 100 ms secara otomatis. Unduh himpunan data yang dinormalkan dan tinjau. |
| Skrip | Teks dinormalisasi secara otomatis | Teks secara otomatis dinormalisasi untuk digit, simbol, dan singkatan. Tinjau skrip dan audio untuk memastikan skrip dan audio cocok. |
Pemeriksaan manual diperlukan
Kesalahan yang belum terselesaikan yang tercantum dalam tabel berikutnya memengaruhi kualitas pelatihan, tetapi data dengan kesalahan ini tidak akan dikecualikan selama pelatihan. Untuk pelatihan berkualitas tinggi, sebaiknya perbaiki kesalahan ini secara manual.
| Kategori | Nama | Deskripsi |
|---|---|---|
| Skrip | Teks yang tidak dinormalisasi | Skrip ini berisi simbol. Normalisasi simbol agar sesuai dengan audio. Misalnya, normalisasi / ke garis miring. |
| Skrip | Tidak cukup ucapan pertanyaan | Setidaknya 10% dari total ungkapan harus berupa kalimat pertanyaan. Ini membantu model suara mengekspresikan nada pertanyaan dengan benar. |
| Skrip | Tidak cukup ucapan seruan | Setidaknya 10% dari total ungkapan harus berupa kalimat perintah. Ini membantu model suara mengekspresikan nada bersemangat dengan benar. |
| Skrip | Tidak ada tanda baca akhir yang valid | Tambahkan salah satu berikut di akhir baris: titik (setengah lebar '.' atau lebar penuh '。'), tanda seru (setengah lebar '!' atau lebar penuh '!'), atau tanda tanya (setengah lebar '?' atau lebar penuh '?'). |
| Suara | Laju pengambilan sampel rendah untuk suara neural | Disarankan agar tingkat pengambilan sampel file .wav Anda harus 24 KHz atau lebih tinggi untuk membuat suara saraf. Jika lebih rendah, tingkat pengambilan otomatis akan dinaikkan menjadi 24 KHz. |
| Kapasitas | Volume keseluruhan terlalu rendah | Volume tidak boleh lebih rendah dari -18 dB (10% dari volume maksimum). Kontrol ketinggian rata-rata volume ke rentang yang tepat selama perekaman atau penyiapan data. |
| Kapasitas | Volume meluap | Volume yang meluap terdeteksi pada {}s. Sesuaikan alat rekam untuk menghindari volume yang meluap pada nilai puncaknya. |
| Kapasitas | Mulai masalah keheningan | Keheningan 100 ms pertama tidak bersih. Kurangi tingkat kebisingan rekaman dan biarkan 100 ms pertama di awal hening. |
| Kapasitas | Akhiri masalah keheningan | Keheningan 100 ms pertama tidak bersih. Kurangi tingkat kebisingan rekaman dan biarkan 100 md terakhir di akhir hening. |
| Tidak cocok | Kata-kata dengan skor rendah | Tinjau skrip dan konten audio untuk memastikan keduanya cocok dan kontrol tingkat bawah kebisingan. Kurangi durasi keheningan yang panjang atau bagi audio menjadi beberapa ungkapan jika terlalu panjang. |
| Tidak cocok | Mulai masalah keheningan | Audio tambahan terdengar sebelum kata pertama. Tinjau skrip dan konten audio untuk memastikannya cocok, kontrol tingkat lantai kebisingan, dan buat 100 ms pertama diam. |
| Tidak cocok | Akhiri masalah keheningan | Audio tambahan terdengar setelah kata terakhir. Tinjau skrip dan konten audio untuk memastikannya cocok, kontrol tingkat lantai kebisingan, dan buat 100 ms terakhir diam. |
| Tidak cocok | Rasio sinyal-kebisingan rendah | Tingkat SNR audio lebih rendah dari 20 dB. Setidaknya 35 dB direkomendasikan. |
| Tidak cocok | Tidak ada skor yang tersedia | Gagal mengenali konten ucapan dalam audio ini. Periksa konten skrip dan audio untuk memastikan audionya valid, dan cocokkan dengan skrip. |
Langkah berikutnya
Saat Anda siap untuk membuat teks kustom ke suara ucapan untuk aplikasi Anda, langkah pertama adalah mengumpulkan rekaman audio dan skrip terkait untuk mulai melatih model suara. Untuk detail tentang cara merekam sampel suara, lihat tutorial. Layanan Ucapan menggunakan data ini untuk membuat suara unik yang disetel agar sesuai dengan suara dalam rekaman. Setelah melatih suara, Anda dapat mulai mensintesis ucapan dalam aplikasi Anda.
Setiap data yang Anda unggah harus memenuhi persyaratan untuk jenis data yang dipilih. Data harus diformat dengan benar sebelum diunggah untuk memastikan bahwa data itu akan diproses secara akurat oleh layanan Azure Cognitive Service untuk Ucapan. Untuk mengonfirmasi bahwa data Anda diformat dengan benar, lihat Jenis data pelatihan.
Catatan
- Pengguna langganan standar (S0) dapat mengunggah lima himpunan data sekaligus. Jika batas tercapai, tunggu hingga setidaknya salah satu himpunan data Anda selesai diimpor. Kemudian coba lagi.
- Jumlah maksimum file data yang diizinkan untuk diimpor per langganan adalah 500 file .zip untuk pengguna langganan standar (S0). Harap lihat Kuota dan batas layanan ucapan untuk detail selengkapnya.
Unggah data Anda
Jika sudah siap mengunggah data, buka tab Siapkan data pelatihan untuk menambahkan set pelatihan pertama Anda dan mengunggah data. Set pelatihan adalah sekumpulan ungkapan audio dan skrip pemetaannya yang digunakan untuk melatih model suara. Anda dapat menggunakan set pelatihan untuk mengatur data pelatihan Anda. Layanan ini memeriksa kesiapan data per setiap set pelatihan. Anda dapat mengimpor beberapa data ke set pelatihan.
Untuk mengunggah data pelatihan, ikuti langkah-langkah berikut:
- Masuk ke Speech Studio.
- Pilih Suara
- Di wizard Unggah data, pilih jenis data lalu pilih Berikutnya.
- Pilih file lokal dari komputer Anda atau masukkan URL penyimpanan Azure Blob untuk mengunggah data.
- Jika Anda memilih Audio panjang + transkrip atau Jenis data audio saja dalam proyek dukungan kontekstual, Anda akan melihat opsi untuk memilih mode pemrosesan:
- Diproses sebagai Kontekstual: Memproses audio sambil mempertahankan informasi kontekstual untuk kemampuan percakapan yang ditingkatkan dan pola ucapan yang lebih alami.
- Tersegmentasi: Memproses audio dan mengubah transkrip menjadi bentuk ucapan individual dengan menggunakan segmentasi standar.
- Di bawah Tentukan set pelatihan target, pilih set pelatihan yang sudah ada atau buat yang baru. Jika Anda membuat set pelatihan baru, pastikan set pelatihan dipilih di daftar drop-down sebelum Anda melanjutkan.
- Pilih Selanjutnya.
- Masukkan nama dan deskripsi untuk data Anda lalu pilih Berikutnya.
- Tinjau detail unggahan, dan pilih Kirim.
Catatan
ID duplikat tidak diterima. Ucapan dengan ID yang sama akan dihapus.
Nama audio duplikat akan dihapus dari pelatihan. Pastikan data yang Anda pilih tidak berisi nama audio yang sama dalam file .zip atau di beberapa file .zip. Jika ID ungkapan (baik dalam file audio maupun skrip) berupa duplikat, ID ini akan ditolak.
Set pelatihan hanya dapat berisi data yang diproses dalam mode yang sama. Misalnya, jika Anda mengunggah data dengan mode Diproses sebagai Kontekstual ke set pelatihan, semua unggahan berikutnya ke set pelatihan yang sama juga harus menggunakan mode Diproses sebagai Kontekstual .
File data otomatis divalidasi saat Anda memilih Kirim. Validasi data meliputi serangkaian pemeriksaan pada file audio untuk memverifikasi format file, ukuran, dan laju pengambilan sampelnya. Jika ada kesalahan, perbaiki dan kirimkan lagi.
Setelah mengunggah data itu, Anda dapat memeriksa detail dalam tampilan detail set pelatihan. Pada halaman detail, Anda dapat memeriksa lebih lanjut masalah pengucapan dan tingkat kebisingan untuk setiap data Anda. Skor pengucapan pada tingkat kalimat berkisar antara 0-100. Skor di bawah 70 biasanya menunjukkan kesalahan ucapan atau ketidakcocokan skrip. Ucapan dengan skor keseluruhan yang lebih rendah dari 70 akan ditolak. Aksen berat dapat mengurangi skor pengucapan dan berdampak pada suara digital yang dihasilkan.
Mengatasi masalah data secara online
Setelah mengunggah, Anda dapat memeriksa detail data kumpulan pelatihan. Sebelum terus melatih model suara, Anda harus mencoba menyelesaikan masalah data apa pun.
Anda dapat mengidentifikasi dan mengatasi masalah data per ucapan di Speech Studio.
Diproses sebagai Tersegmentasi
Pada halaman detail, buka halaman Data yang Diterima atau Data yang Ditolak. Pilih ucapan individual yang ingin Anda ubah, lalu pilih Edit.
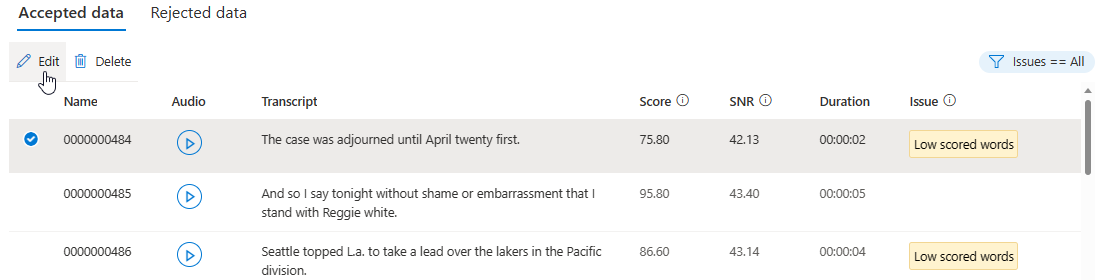
Anda dapat memilih masalah data mana yang akan ditampilkan berdasarkan kriteria Anda.
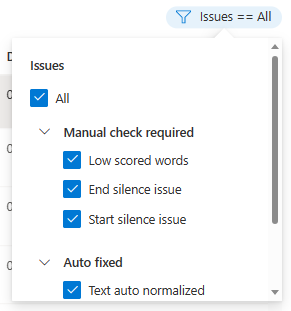
Jendela edit ditampilkan.
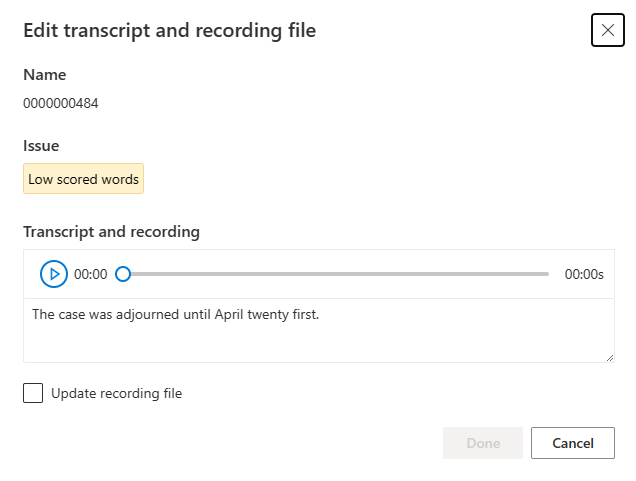
Perbarui transkrip atau file rekaman sesuai deskripsi masalah pada jendela edit.
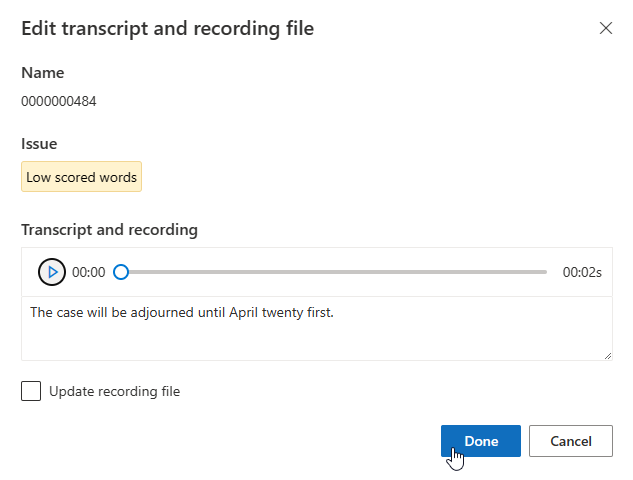
Anda dapat mengedit transkrip dalam kotak teks, lalu pilih Selesai
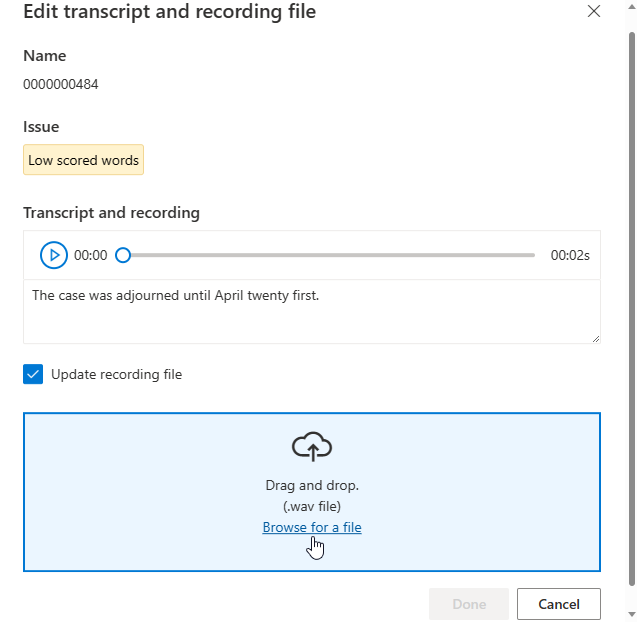
Jika Anda harus memperbarui file rekaman, pilih Perbarui file rekaman, lalu unggah file rekaman tetap (.wav).
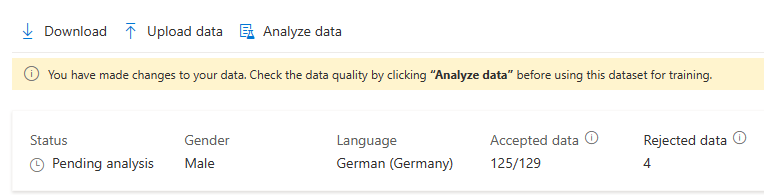
Setelah membuat perubahan pada data, Anda perlu memeriksa kualitas data dengan mengklik Analisis data sebelum menggunakan himpunan data ini untuk pelatihan.
Anda tidak dapat memilih set pelatihan ini bagi model pelatihan sebelum analisis selesai.
Anda juga dapat menghapus ucapan dengan masalah dengan cara memilihnya dan mengeklik Hapus.
Diproses secara Kontekstual
Tidak seperti yang diproses sebagai tersegmentasi, Diproses sebagai Kontekstual mempertahankan file audio asli dan menghasilkan informasi kontekstual yang sesuai.
Pada halaman detail, klik pada tuturan individu yang memiliki "Jumlah isu".

Informasi kontekstual disajikan sebagai segmen. Pilih segmen yang ingin Anda ubah, lalu klik tombol Edit .
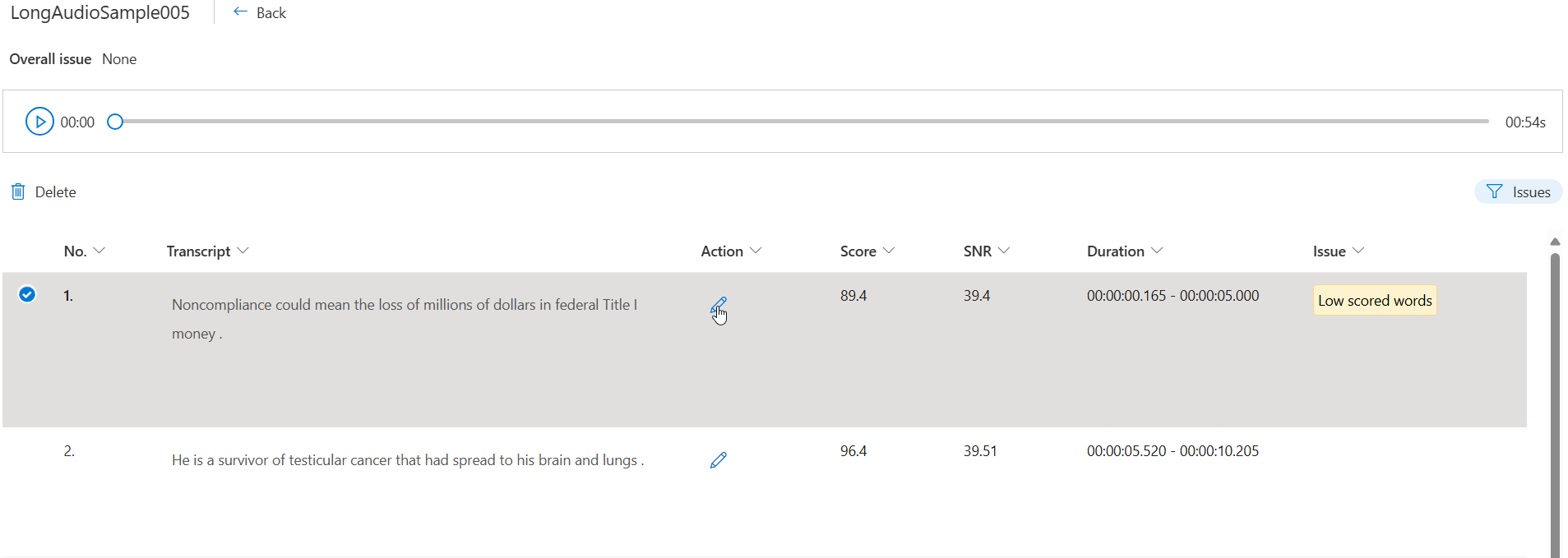
Anda dapat memilih masalah data mana yang akan ditampilkan berdasarkan kriteria Anda.
Edit transkrip dalam kotak teks sesuai dengan deskripsi masalah, lalu pilih Selesai.

Setelah membuat perubahan pada data, Anda perlu memeriksa kualitas data dengan mengklik Analisis data sebelum menggunakan himpunan data ini untuk pelatihan.
Anda tidak dapat memilih set pelatihan ini bagi model pelatihan sebelum analisis selesai.
Catatan
Menghapus segmen informasi kontekstual tidak akan mengecualikan konten tersebut dari pelatihan. Hanya hapus segmen ketika informasi mereka sudah disertakan atau akan disertakan dalam segmen yang berdekatan.
Segmen yang ditolak tidak akan digunakan untuk pelatihan.
Masalah data yang umum
Masalah ini dibagi menjadi tiga jenis. Lihat tabel berikut untuk memeriksa jenis kesalahan masing-masing.
Ditolak otomatis
Data dengan kesalahan ini tidak akan digunakan untuk pelatihan. Data yang diimpor dengan kesalahan akan diabaikan, sehingga Anda tidak perlu menghapusnya. Anda dapat memperbaiki kesalahan data ini secara online atau mengunggah data yang dikoreksi lagi untuk pelatihan.
| Kategori | Nama | Deskripsi |
|---|---|---|
| Skrip | Pemisah tidak valid | Anda harus memisahkan ID ungkapan dan konten skrip dengan karakter Tab. |
| Skrip | ID skrip tidak valid | ID baris skrip harus berupa angka. |
| Skrip | Skrip duplikat | Setiap baris konten skrip harus unik. Garis ini diduplikasi dengan {}. |
| Skrip | Skrip terlalu panjang | Skrip harus kurang dari 1.000 karakter. |
| Skrip | Tidak ada audio yang cocok | ID dari setiap ucapan (setiap baris file skrip) harus sesuai dengan ID audio. |
| Skrip | Tidak ada skrip yang valid | Tak ada skrip valid yang ditemukan dalam himpunan data ini. Perbaiki baris skrip yang muncul dalam daftar masalah terperinci. |
| Suara | Tidak ada skrip yang cocok | Tidak ada file audio yang cocok dengan ID skrip. Nama file .wav harus cocok dengan ID dalam file skrip. |
| Suara | Format audio tidak valid | Format audio dari file .wav tidak valid. Periksa format file .wav menggunakan alat audio seperti SoX. |
| Suara | Laju pengambilan sampel rendah | Tingkat pengambilan sampel file .wav tidak boleh lebih rendah dari 16 KHz. |
| Suara | Audio terlalu panjang | Durasi audio lebih dari 30 detik. Pisahkan audio panjang menjadi beberapa file. Sebaiknya buat ungkapan lebih singkat dari 15 detik. |
| Suara | Tidak ada audio yang valid | Tidak ada audio sahih dalam himpunan data ini. Periksa data audio Anda dan unggah lagi. |
| Tidak cocok | Ucapan dengan skor rendah | Skor pengucapan tingkat kalimat lebih rendah dari 70. Baca skrip dan konten audio untuk memastikan keduanya cocok. |
Diperbaiki otomatis
Kesalahan berikut diperbaiki secara otomatis, tetapi sebaiknya tinjau dan konfirmasi bahwa perbaikan dilakukan dengan benar.
| Kategori | Nama | Deskripsi |
|---|---|---|
| Tidak cocok | Keheningan diperbaiki otomatis | Keheningan awal terdeteksi lebih dari 100 ms, dan telah dipangkas menjadi 100 ms secara otomatis. Unduh himpunan data yang dinormalkan dan tinjau. |
| Tidak cocok | Keheningan diperbaiki otomatis | Keheningan akhir terdeteksi lebih pendek dari 100 ms, dan telah diperpanjang menjadi 100 ms secara otomatis. Unduh himpunan data yang dinormalkan dan tinjau. |
| Skrip | Teks dinormalisasi secara otomatis | Teks secara otomatis dinormalisasi untuk digit, simbol, dan singkatan. Tinjau skrip dan audio untuk memastikan skrip dan audio cocok. |
Pemeriksaan manual diperlukan
Kesalahan yang belum terselesaikan yang tercantum dalam tabel berikutnya memengaruhi kualitas pelatihan, tetapi data dengan kesalahan ini tidak akan dikecualikan selama pelatihan. Untuk pelatihan berkualitas tinggi, sebaiknya perbaiki kesalahan ini secara manual.
| Kategori | Nama | Deskripsi |
|---|---|---|
| Skrip | Teks yang tidak dinormalisasi | Skrip ini berisi simbol. Normalisasi simbol agar sesuai dengan audio. Misalnya, normalisasi / ke garis miring. |
| Skrip | Tidak cukup ucapan pertanyaan | Setidaknya 10% dari total ungkapan harus berupa kalimat pertanyaan. Ini membantu model suara mengekspresikan nada pertanyaan dengan benar. |
| Skrip | Tidak cukup ucapan seruan | Setidaknya 10% dari total ungkapan harus berupa kalimat perintah. Ini membantu model suara mengekspresikan nada bersemangat dengan benar. |
| Skrip | Tidak ada tanda baca akhir yang valid | Tambahkan salah satu dari berikut di akhir baris: tanda titik (lebar setengah '.' atau lebar penuh '。'), tanda seru (lebar setengah '!' atau lebar penuh '!' ), atau tanda tanya ( lebar setengah '?' atau lebar penuh '?'). |
| Suara | Laju pengambilan sampel rendah untuk suara neural | Disarankan agar tingkat pengambilan sampel file .wav Anda harus 24 KHz atau lebih tinggi untuk membuat suara saraf. Jika lebih rendah, tingkat pengambilan otomatis akan dinaikkan menjadi 24 KHz. |
| Kapasitas | Volume keseluruhan terlalu rendah | Volume tidak boleh lebih rendah dari -18 dB (10% dari volume maksimum). Kontrol ketinggian rata-rata volume ke rentang yang tepat selama perekaman atau penyiapan data. |
| Kapasitas | Volume meluap | Volume yang meluap terdeteksi pada {}s. Sesuaikan alat rekam untuk menghindari volume yang meluap pada nilai puncaknya. |
| Kapasitas | Mulai masalah keheningan | Keheningan 100 ms pertama tidak bersih. Kurangi tingkat kebisingan rekaman dan biarkan 100 ms pertama di awal hening. |
| Kapasitas | Akhiri masalah keheningan | Keheningan 100 ms pertama tidak bersih. Kurangi tingkat kebisingan rekaman dan biarkan 100 md terakhir di akhir hening. |
| Tidak cocok | Kata-kata dengan skor rendah | Tinjau skrip dan konten audio untuk memastikan keduanya cocok dan kontrol tingkat bawah kebisingan. Kurangi durasi keheningan yang panjang atau bagi audio menjadi beberapa ungkapan jika terlalu panjang. |
| Tidak cocok | Mulai masalah keheningan | Audio tambahan terdengar sebelum kata pertama. Tinjau skrip dan konten audio untuk memastikannya cocok, kontrol tingkat lantai kebisingan, dan buat 100 ms pertama diam. |
| Tidak cocok | Akhiri masalah keheningan | Audio tambahan terdengar setelah kata terakhir. Tinjau skrip dan konten audio untuk memastikannya cocok, kontrol tingkat lantai kebisingan, dan buat 100 ms terakhir diam. |
| Tidak cocok | Rasio sinyal-kebisingan rendah | Tingkat SNR audio lebih rendah dari 20 dB. Setidaknya 35 dB direkomendasikan. |
| Tidak cocok | Tidak ada skor yang tersedia | Gagal mengenali konten ucapan dalam audio ini. Periksa konten skrip dan audio untuk memastikan audionya valid, dan cocokkan dengan skrip. |
Langkah berikutnya
Anda memerlukan himpunan data pelatihan untuk membuat suara profesional. Himpunan data pelatihan mencakup file audio dan skrip. File audio adalah rekaman bakat suara yang membaca file skrip. File skrip adalah teks file audio.
Dalam artikel ini, Anda membuat set pelatihan dan mendapatkan ID sumber dayanya. Kemudian, menggunakan ID sumber daya, Anda dapat mengunggah sekumpulan file audio dan skrip.
Membuat set pelatihan
Untuk membuat set pelatihan, gunakan operasi TrainingSets_Create API suara kustom. Buat isi permintaan sesuai dengan instruksi berikut:
- Atur properti
projectIdyang diperlukan. Lihat membuat proyek. - Atur properti yang diperlukan
voiceKindkeMaleatauFemale. Jenisnya tidak dapat diubah nanti. - Atur properti
localeyang diperlukan. Ini harus menjadi lokal data set pelatihan. Lokal set pelatihan harus sama dengan lokal pernyataan persetujuan. Lokal tidak dapat diubah nanti. Anda dapat menemukan daftar lokal teks ke ucapan di sini. - Secara opsional, atur
descriptionproperti untuk deskripsi set pelatihan. Deskripsi set pelatihan dapat diubah nanti.
Buat permintaan HTTP PUT menggunakan URI seperti yang ditunjukkan dalam contoh TrainingSets_Create berikut.
- Ganti
YourResourceKeydengan kunci sumber daya Ucapan Anda. - Ganti
YourResourceRegiondengan wilayah sumber daya Ucapan Anda. - Ganti
JessicaTrainingSetIddengan ID set pelatihan pilihan Anda. ID peka huruf besar/kecil akan digunakan dalam URI set pelatihan dan tidak dapat diubah nanti.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2024-02-01-preview"
Anda akan menerima isi respons dalam format berikut:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Mengunggah data set pelatihan
Untuk mengunggah set pelatihan audio dan skrip, gunakan operasi TrainingSets_UploadData API suara kustom.
Sebelum memanggil API ini, silakan simpan file rekaman dan skrip di Azure Blob. Dalam contoh berikut, file rekaman adalah https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.wav, file skrip adalah https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt.
Buat isi permintaan sesuai dengan instruksi berikut:
- Atur properti yang diperlukan
kindkeAudioAndScript. Jenis menentukan jenis set pelatihan. - Atur properti
audiosyang diperlukan.audiosDi dalam properti , atur properti berikut:- Atur properti yang diperlukan
containerUrlke URL kontainer Azure Blob Storage yang berisi file audio. Gunakan tanda tangan akses bersama (SAS) untuk kontainer dengan izin baca dan daftar. - Atur properti yang diperlukan
extensionske ekstensi file audio. - Secara opsional, atur
prefixproperti untuk mengatur awalan untuk nama blob.
- Atur properti yang diperlukan
- Atur properti
scriptsyang diperlukan.scriptsDi dalam properti , atur properti berikut:- Atur properti yang diperlukan
containerUrlke URL kontainer Azure Blob Storage yang berisi file skrip. Gunakan tanda tangan akses bersama (SAS) untuk kontainer dengan izin baca dan daftar. - Atur properti yang diperlukan
extensionske ekstensi file skrip. - Secara opsional, atur
prefixproperti untuk mengatur awalan untuk nama blob.
- Atur properti yang diperlukan
Buat permintaan HTTP POST menggunakan URI seperti yang ditunjukkan dalam contoh TrainingSets_UploadData berikut.
- Ganti
YourResourceKeydengan kunci sumber daya Ucapan Anda. - Ganti
YourResourceRegiondengan wilayah sumber daya Ucapan Anda. - Ganti
JessicaTrainingSetIdjika Anda menentukan ID set pelatihan yang berbeda di langkah sebelumnya.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2024-02-01-preview"
Header respons berisi Operation-Location properti . Gunakan URI ini untuk mendapatkan detail tentang operasi TrainingSets_UploadData . Berikut adalah contoh header respons:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2024-02-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345