Melatih model suara profesional Anda
Dalam artikel ini, Anda akan mempelajari cara melatih suara neural kustom melalui portal Speech Studio.
Penting
Pelatihan suara neural kustom saat ini hanya tersedia di beberapa wilayah. Setelah model suara Anda dilatih di wilayah yang didukung, Anda dapat menyalinnya ke sumber daya Ucapan di wilayah lain sesuai kebutuhan. Untuk informasi selengkapnya, lihat catatan kaki dalam tabel layanan Ucapan.
Durasi pelatihan bervariasi tergantung pada berapa banyak data yang Anda gunakan. Dibutuhkan waktu rata-rata sekitar 40 jam komputasi untuk melatih suara neural kustom. Pengguna langganan standar (S0) dapat melatih empat suara secara bersamaan. Jika Anda mencapai batas, tunggu hingga setidaknya salah satu model suara Anda menyelesaikan pelatihan, lalu coba lagi.
Catatan
Meskipun jumlah total jam yang diperlukan per metode pelatihan bervariasi, harga satuan yang sama berlaku untuk masing-masing. Untuk informasi selengkapnya, lihat detail harga pelatihan neural kustom.
Pilih metode pelatihan
Setelah Memvalidasi file data, gunakan file tersebut untuk membangun model suara neural kustom Anda. Saat membuat suara saraf kustom, Anda dapat memilih untuk melatihnya dengan salah satu metode berikut:
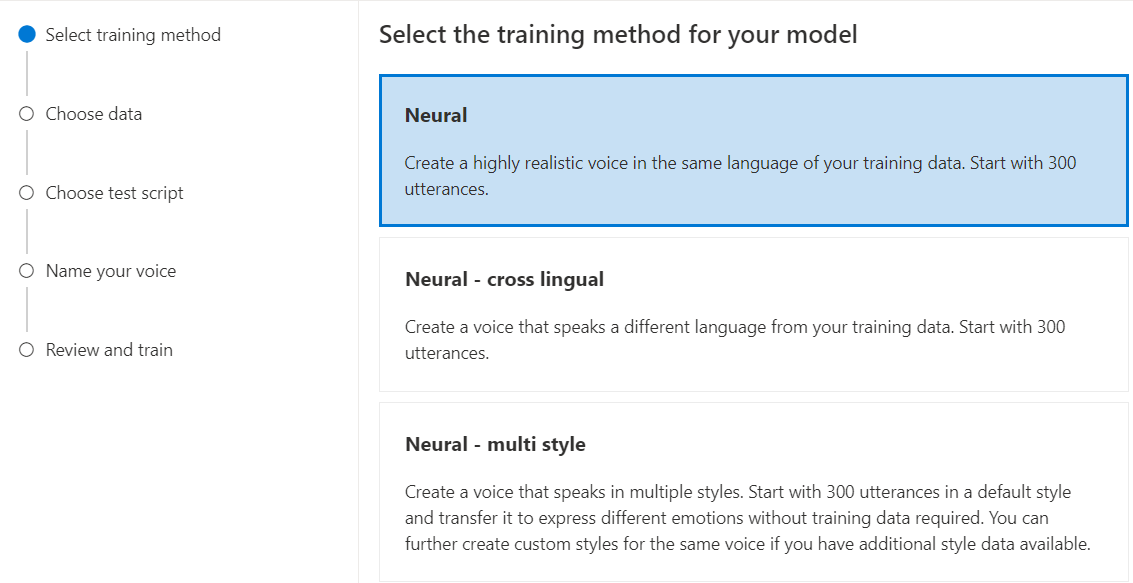
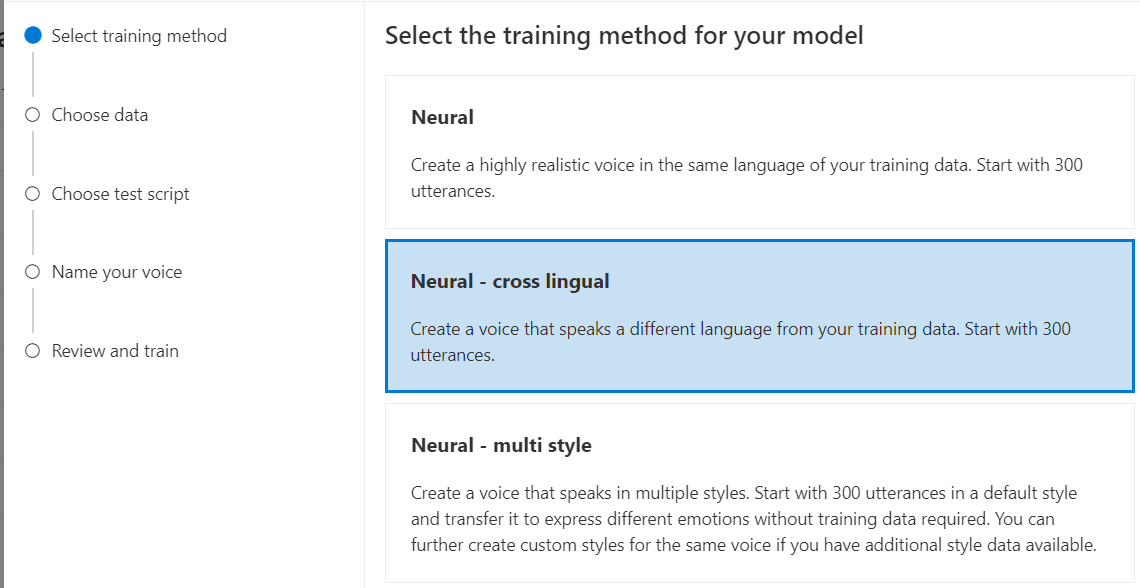
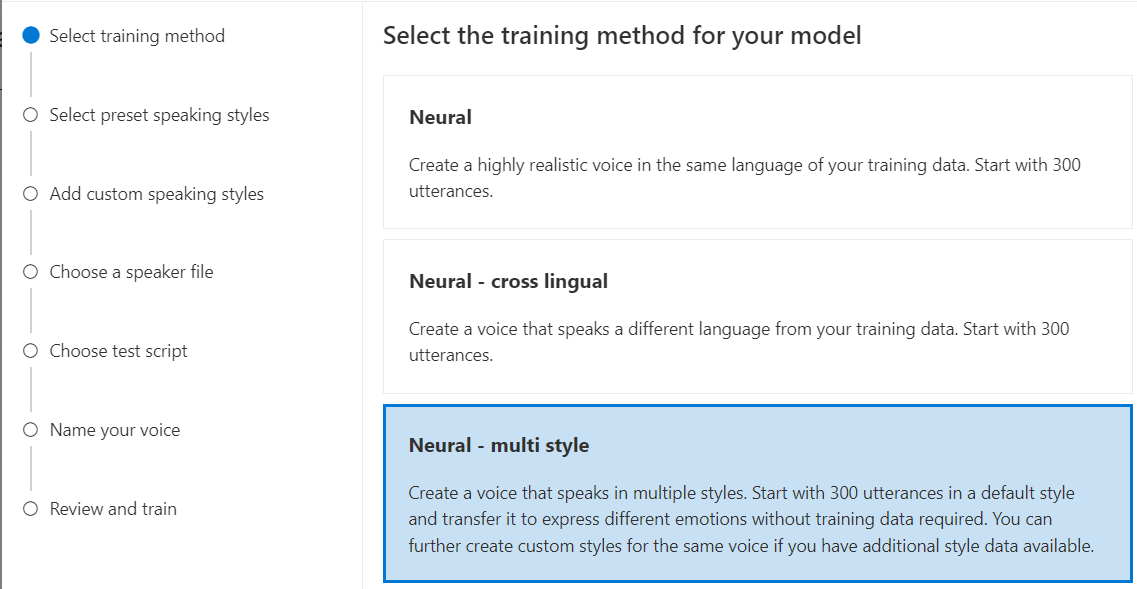
Neural: Buat suara dalam bahasa yang sama dengan data pelatihan Anda.
Neural - bahasa silang: Buat suara yang berbicara bahasa yang berbeda dari data pelatihan Anda. Misalnya, dengan
zh-CNdata pelatihan, Anda dapat membuat suara yang berbicaraen-US.Bahasa data pelatihan dan bahasa target keduanya harus menjadi salah satu bahasa yang didukung untuk pelatihan suara lintas bahasa. Anda tidak perlu menyiapkan data pelatihan dalam bahasa target, tetapi skrip pengujian Anda harus dalam bahasa target.
Neural - multi gaya: Buat suara saraf kustom yang berbicara dalam beberapa gaya dan emosi, tanpa menambahkan data pelatihan baru. Beberapa suara gaya berguna untuk karakter video game, chatbot percakapan, buku audio, pembaca konten, dan banyak lagi.
Untuk membuat suara beberapa gaya, Anda perlu menyiapkan sekumpulan data pelatihan umum, setidaknya 300 ucapan. Pilih satu atau beberapa gaya berbicara target prasetel. Anda juga dapat membuat beberapa gaya kustom dengan menyediakan sampel gaya, setidaknya 100 ucapan per gaya, sebagai data pelatihan tambahan untuk suara yang sama. Gaya prasetel yang didukung bervariasi sesuai dengan bahasa yang berbeda. Lihat gaya prasetel yang tersedia di berbagai bahasa.
Bahasa data pelatihan harus menjadi salah satu bahasa yang didukung untuk suara saraf kustom, lintas bahasa, atau pelatihan gaya ganda.
Melatih model suara neural kustom Anda
Untuk membuat suara neural kustom di Speech Studio, ikuti langkah-langkah berikut untuk salah satu metode berikut:
Masuk ke Speech Studio.
Pilih Suara<>kustom Nama>>proyek Anda Melatih model>Melatih model baru.
Pilih Neural sebagai metode pelatihan untuk model Anda lalu pilih Berikutnya. Untuk menggunakan metode pelatihan yang berbeda, lihat Neural - bahasa silang atau Neural - multi gaya.
Pilih versi resep pelatihan untuk model Anda. Versi terbaru akan dipilih secara default. Fitur dan waktu pelatihan yang didukung dapat bervariasi menurut versi. Biasanya, kami merekomendasikan versi terbaru. Dalam beberapa kasus, Anda dapat memilih versi yang lebih lama untuk mengurangi waktu pelatihan. Lihat Pelatihan dua bahasa untuk informasi selengkapnya tentang pelatihan dua bahasa dan perbedaan antara lokal.
Catatan
Versi model
V2.2021.07, ,V4.2021.10V5.2022.05,V6.2022.11, danV9.2023.10akan dihentikan pada 1 Oktober 2024. Model suara yang sudah dibuat pada versi yang dihentikan ini tidak akan terpengaruh.Pilih data yang ingin Anda gunakan untuk pelatihan. Nama audio duplikat akan dihapus dari pelatihan. Pastikan bahwa data yang Anda pilih tidak berisi nama audio yang sama di beberapa file .zip .
Anda hanya dapat memilih himpunan data yang berhasil diproses untuk pelatihan. Jika Anda tidak melihat set pelatihan Anda dalam daftar, periksa status pemrosesan data Anda.
Pilih file pembicara dengan pernyataan bakat suara yang sesuai dengan pembicara dalam data pelatihan Anda.
Pilih Selanjutnya.
Setiap pelatihan menghasilkan 100 file audio sampel secara otomatis untuk membantu Anda menguji model dengan skrip default.
Secara opsional, Anda juga dapat memilih Tambahkan skrip pengujian saya sendiri dan berikan skrip pengujian Anda sendiri hingga 100 ucapan untuk menguji model tanpa biaya tambahan. File audio yang dihasilkan adalah kombinasi dari skrip pengujian otomatis dan skrip pengujian kustom. Untuk informasi selengkapnya, lihat persyaratan skrip pengujian.
Masukkan Nama untuk membantu Anda mengidentifikasi model. Pilih nama dengan hati-hati. Nama model digunakan sebagai nama suara dalam permintaan sintesis ucapan Anda oleh input SDK dan SSML. Hanya huruf, angka, dan beberapa karakter tanda baca yang diizinkan. Gunakan nama yang berbeda untuk model suara neural yang berbeda.
Secara opsional, masukkan Deskripsi untuk membantu Anda mengidentifikasi model. Penggunaan umum deskripsi adalah merekam nama data yang Anda gunakan untuk membuat model.
Pilih Selanjutnya.
Tinjau pengaturan dan pilih kotak untuk menerima ketentuan penggunaan.
Pilih Kirim untuk mulai melatih model.
Pelatihan dua bahasa
Jika Anda memilih jenis pelatihan Neural , Anda dapat melatih suara untuk berbicara dalam beberapa bahasa. Lokal zh-CN, , zh-HKdan zh-TW mendukung pelatihan dua bahasa agar suara dapat berbicara bahasa Tionghoa dan Inggris. Bergantung sebagian pada data pelatihan Anda, suara yang disintesis dapat berbicara bahasa Inggris dengan aksen asli bahasa Inggris atau bahasa Inggris dengan aksen yang sama dengan data pelatihan.
Catatan
Untuk mengaktifkan suara di zh-CN lokal untuk berbicara bahasa Inggris dengan aksen yang sama dengan data sampel, Anda harus memilih Chinese (Mandarin, Simplified), English bilingual saat membuat proyek atau menentukan zh-CN (English bilingual) lokal untuk data set pelatihan melalui REST API.
Tabel berikut ini memperlihatkan perbedaan di antara lokal:
| Lokal Speech Studio | Lokal REST API | Dukungan dua bahasa |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Jika data sampel Anda menyertakan bahasa Inggris, suara yang disintesis berbicara bahasa Inggris dengan aksen asli bahasa Inggris, alih-alih aksen yang sama dengan data sampel, terlepas dari jumlah data bahasa Inggris. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Jika Anda ingin suara yang disintesis berbicara bahasa Inggris dengan aksen yang sama dengan data sampel, sebaiknya sertakan lebih dari 10% data bahasa Inggris dalam set pelatihan Anda. Jika tidak, aksen berbahasa Inggris mungkin tidak ideal. |
Chinese (Cantonese, Simplified) |
zh-HK |
Jika Anda ingin melatih suara yang disintesis yang mampu berbicara bahasa Inggris dengan aksen yang sama dengan data sampel Anda, pastikan untuk memberikan lebih dari 10% data bahasa Inggris dalam set pelatihan Anda. Jika tidak, defaultnya adalah aksen asli bahasa Inggris. Ambang batas 10% dihitung berdasarkan data yang diterima setelah berhasil diunggah, bukan data sebelum diunggah. Jika beberapa data bahasa Inggris yang diunggah ditolak karena cacat dan tidak memenuhi ambang 10%, suara yang disintesis default ke aksen asli bahasa Inggris. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Jika Anda ingin melatih suara yang disintesis yang mampu berbicara bahasa Inggris dengan aksen yang sama dengan data sampel Anda, pastikan untuk memberikan lebih dari 10% data bahasa Inggris dalam set pelatihan Anda. Jika tidak, defaultnya adalah aksen asli bahasa Inggris. Ambang batas 10% dihitung berdasarkan data yang diterima setelah berhasil diunggah, bukan data sebelum diunggah. Jika beberapa data bahasa Inggris yang diunggah ditolak karena cacat dan tidak memenuhi ambang 10%, suara yang disintesis default ke aksen asli bahasa Inggris. |
Gaya prasetel yang tersedia di berbagai bahasa
Tabel berikut ini meringkas gaya prasetel yang berbeda sesuai dengan bahasa yang berbeda.
| Gaya berbicara | Bahasa (lokal) |
|---|---|
| marah | Inggris (Amerika Serikat) (en-US)Jepang (Jepang) ( ja-JP) 1Mandarin (Mandarin, Sederhana) ( zh-CN) 1 |
| tenang | Mandarin (Mandarin, Sederhana) (zh-CN) 1 |
| mengobrol | Mandarin (Mandarin, Sederhana) (zh-CN) 1 |
| gembira | Inggris (Amerika Serikat) (en-US)Jepang (Jepang) ( ja-JP) 1Mandarin (Mandarin, Sederhana) ( zh-CN) 1 |
| tidak puas | Mandarin (Mandarin, Sederhana) (zh-CN) 1 |
| gembira | Inggris (Amerika Serikat) (en-US) |
| takut | Mandarin (Mandarin, Sederhana) (zh-CN) 1 |
| ramah | Inggris (Amerika Serikat) (en-US) |
| Berharap | Inggris (Amerika Serikat) (en-US) |
| Sedih | Inggris (Amerika Serikat) (en-US)Jepang (Jepang) ( ja-JP) 1Mandarin (Mandarin, Sederhana) ( zh-CN) 1 |
| Berteriak | Inggris (Amerika Serikat) (en-US) |
| serius | Mandarin (Mandarin, Sederhana) (zh-CN) 1 |
| takut | Inggris (Amerika Serikat) (en-US) |
| Ramah | Inggris (Amerika Serikat) (en-US) |
| Berbisik | Inggris (Amerika Serikat) (en-US) |
1 Gaya suara neural tersedia dalam pratinjau publik. Gaya dalam pratinjau publik hanya tersedia di wilayah layanan ini: US Timur, Eropa Barat, dan Asia Tenggara.
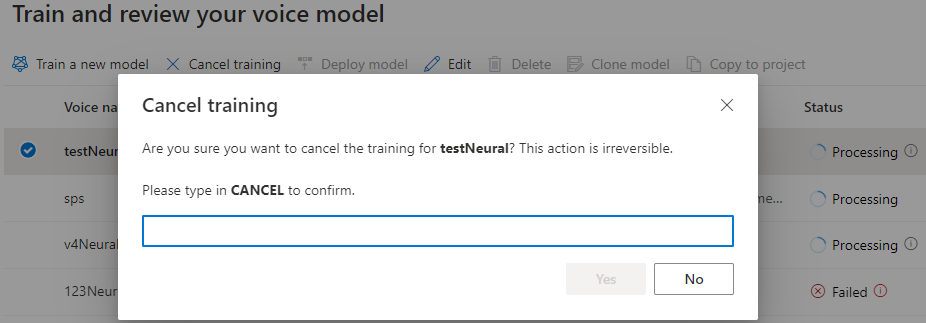
Tabel Latih model menampilkan entri baru yang sesuai dengan model yang baru dibuat ini. Status mencerminkan proses konversi data Anda ke model suara, seperti yang dijelaskan dalam tabel ini:
| Provinsi | Makna |
|---|---|
| Sedang diproses | Model suara Anda sedang dibuat. |
| Berhasil | Model suara Anda telah dibuat dan dapat disebarkan. |
| Gagal | Model suara Anda telah gagal dalam pelatihan. Penyebab kegagalan mungkin, misalnya, masalah data yang tidak terlihat atau masalah jaringan. |
| Canceled | Pelatihan untuk model suara Anda dibatalkan. |
Saat status model sedang Diproses, Anda dapat memilih Batalkan pelatihan untuk membatalkan model suara Anda. Anda tidak dikenakan biaya untuk pelatihan yang dibatalkan ini.
Setelah berhasil melatih model, Anda dapat meninjau detail model dan Menguji model suara Anda.
Anda dapat menggunakan alat Pembuatan Konten Audio di Speech Studio untuk membuat audio dan menyempurnakan suara yang Anda sebarkan. Jika berlaku untuk suara, Anda dapat memilih salah satu dari beberapa gaya.
Mengganti nama model Anda
Jika Anda ingin mengganti nama model yang Anda buat, pilih Kloning model untuk membuat klon model dengan nama baru dalam proyek saat ini.
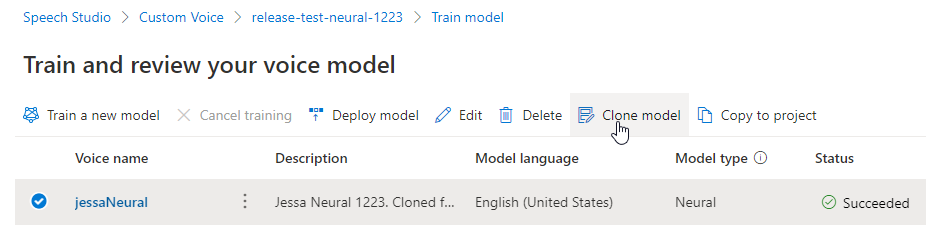
Masukkan nama baru di jendela Kloning model suara, lalu pilih Kirim. Teks Neural secara otomatis ditambahkan sebagai akhiran ke nama model baru Anda.
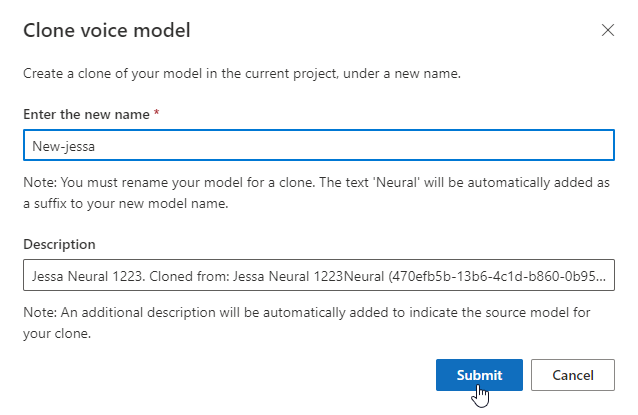
Menguji model suara Anda
Setelah model suara berhasil dibuat, Anda dapat menggunakan file audio sampel yang dihasilkan untuk mengujinya sebelum menyebarkannya.
Kualitas suara bergantung pada banyak faktor, seperti:
- Ukuran pelatihan data.
- Kualitas rekaman.
- Keakuratan file transkrip.
- Seberapa baik suara yang direkam dalam data pelatihan cocok dengan kepribadian suara yang dirancang untuk kasus penggunaan yang Anda maksudkan.
Pilih DefaultTests di bawah Pengujian untuk mendengarkan file audio sampel. Sampel pengujian default mencakup 100 sampel file audio yang dihasilkan secara otomatis selama pelatihan untuk membantu Anda menguji model. Selain 100 file audio yang disediakan secara default, ucapan skrip pengujian Anda sendiri juga ditambahkan ke set DefaultTests . Penambahan ini paling banyak 100 ucapan. Anda tidak dikenakan biaya untuk pengujian dengan DefaultTests.
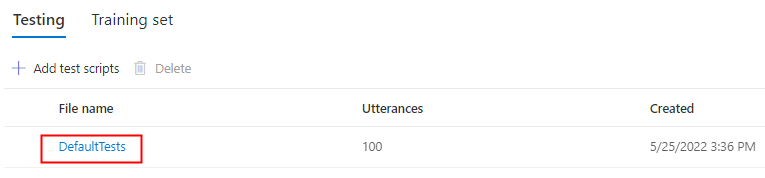
Jika Anda ingin mengunggah skrip pengujian Anda sendiri untuk menguji model Anda lebih lanjut, pilih Tambahkan skrip pengujian untuk mengunggah skrip pengujian Anda sendiri.
Sebelum Anda mengunggah skrip pengujian, periksa persyaratan Uji skrip. Anda dikenakan biaya untuk pengujian tambahan dengan sintesis batch berdasarkan jumlah karakter yang dapat ditagih. Lihat Harga Azure AI Speech.
Di bawah Tambahkan skrip pengujian, pilih Telusuri file untuk memilih skrip Anda sendiri, lalu pilih Tambahkan untuk mengunggahnya.
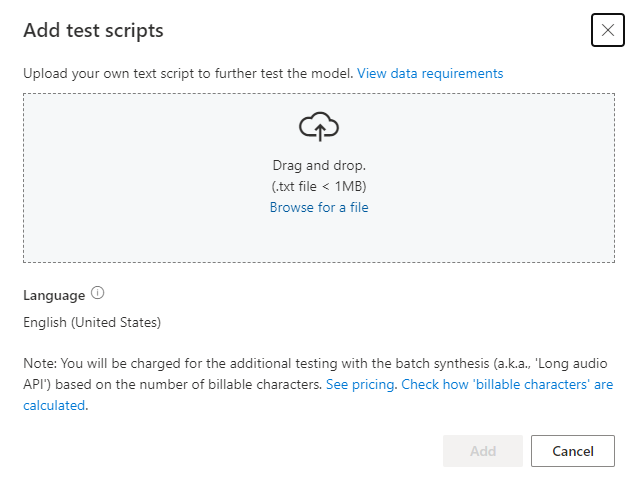
Persyaratan skrip pengujian
Skrip pengujian harus berupa file .txt yang kurang dari 1 MB. Format pengodean yang didukung mencakup ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE, atau UTF-16-BE.
Tidak seperti file transkripsi pelatihan, skrip pengujian harus mengecualikan ID ucapan, yang merupakan nama file dari setiap ucapan. Jika tidak, ID ini diucapkan.
Berikut adalah contoh sekumpulan ucapan dalam satu file .txt :
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Setiap paragraf hasil ungkapan akan menghasilkan audio terpisah. Jika Anda ingin menggabungkan semua kalimat dalam satu audio, buat dalam satu paragraf.
Catatan
File audio yang dihasilkan adalah kombinasi dari skrip pengujian otomatis dan skrip pengujian kustom.
Memperbarui versi mesin bagi model suara Anda
Mesin teks ke ucapan Azure diperbarui dari waktu ke waktu untuk mengambil model bahasa terbaru yang menentukan pengucapan bahasa. Setelah melatih suara, Anda dapat menerapkan suara ke model bahasa baru dengan memperbarui ke versi mesin terbaru.
Saat mesin baru tersedia, Anda akan segera diminta untuk memperbarui model suara neural Anda.

Buka halaman detail model dan ikuti petunjuk di layar untuk menginstal mesin terbaru.
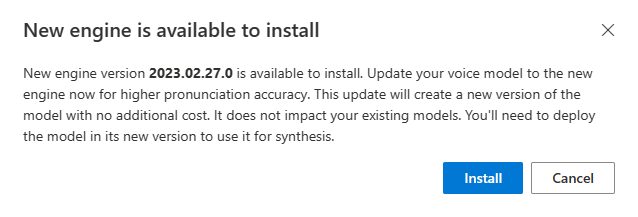
Atau, pilih Instal mesin terbaru nanti untuk memperbarui model Anda ke versi mesin terbaru.
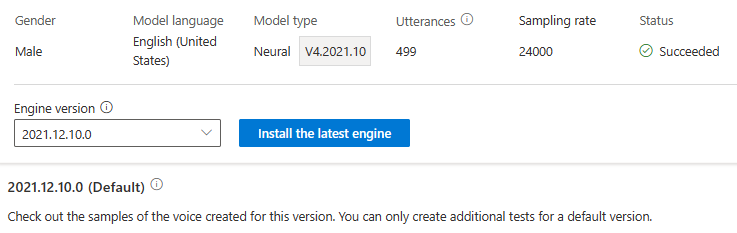
Anda tidak akan dikenakan biaya untuk pembaruan mesin. Versi sebelumnya masih akan disimpan.
Anda dapat memeriksa semua versi mesin untuk model dari daftar Versi mesin, atau menghapusnya jika Anda tidak membutuhkannya lagi.
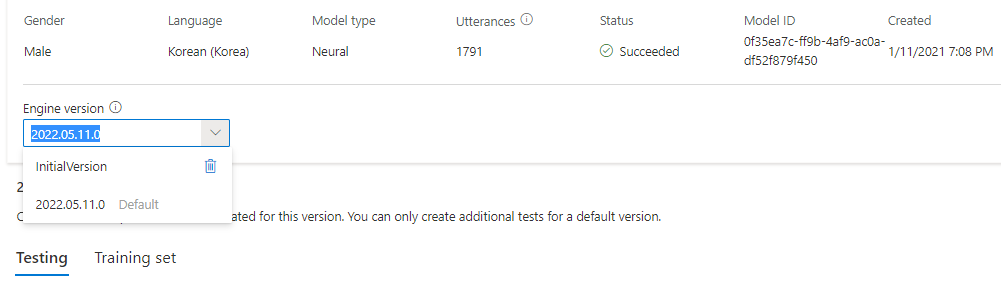
Versi yang diperbarui secara otomatis akan diatur sebagai default. Tetapi Anda dapat mengubah versi default dengan memilih versi dari daftar drop-down dan memilih Atur sebagai default.
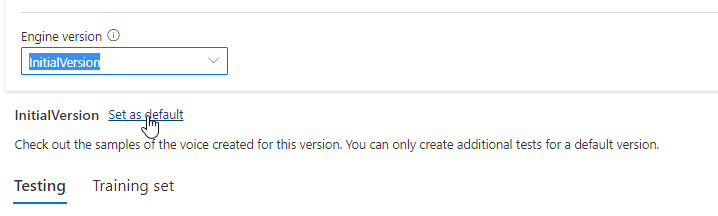

Jika Anda ingin menguji setiap versi mesin model suara, Anda dapat memilih versi dari daftar, lalu pilih DefaultTests di bawah Pengujian untuk mendengarkan file audio sampel. Jika Anda ingin mengunggah skrip pengujian Anda sendiri untuk menguji lebih lanjut versi mesin Anda saat ini, pertama-tama pastikan versi diatur sebagai default, lalu ikuti langkah-langkah dalam Menguji model suara Anda.
Memperbarui mesin membuat versi baru model tanpa biaya tambahan. Setelah memperbarui versi mesin untuk model suara, Anda perlu menyebarkan versi baru untuk membuat titik akhir baru. Anda hanya bisa menyebarkan versi default.
Setelah membuat titik akhir baru, Anda perlu mentransfer lalu lintas ke titik akhir baru di produk Anda.
Untuk mempelajari selengkapnya tentang kemampuan dan batas fitur ini, dan praktik terbaik untuk meningkatkan kualitas model Anda, lihat Karakteristik dan batasan untuk menggunakan suara saraf kustom.
Menyalin model suara Anda ke proyek lain
Anda dapat menyalin model suara ke proyek lain untuk wilayah yang sama atau wilayah lain. Misalnya, Anda dapat menyalin model suara neural yang dilatih di satu wilayah, ke suatu proyek untuk wilayah lain.
Catatan
Pelatihan suara neural kustom saat ini hanya tersedia di beberapa wilayah. Anda dapat menyalin model suara neural dari wilayah tersebut ke wilayah lain. Untuk informasi selengkapnya, lihat wilayah untuk suara neural kustom.
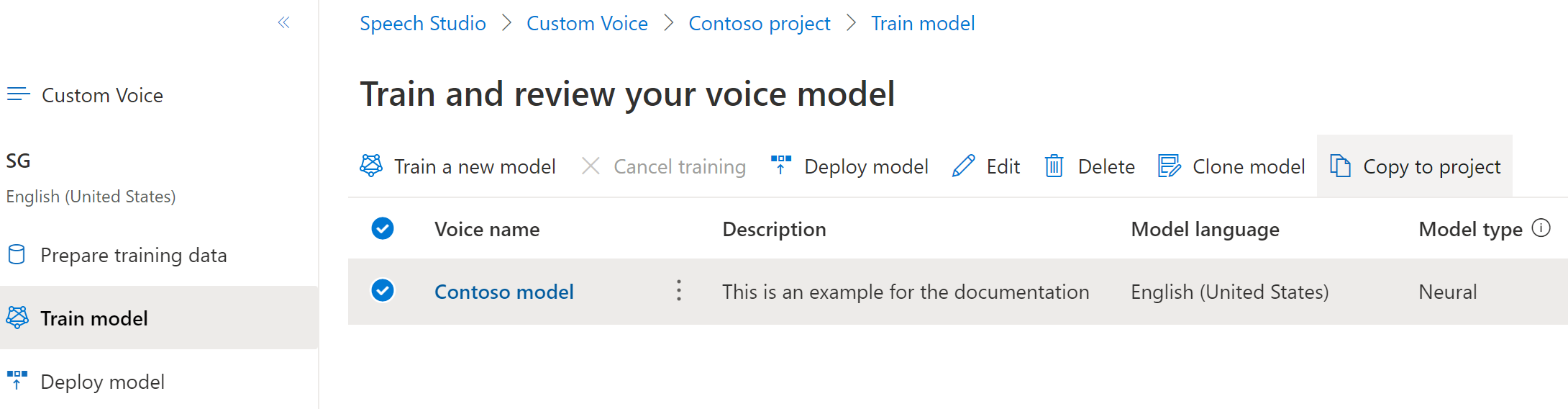
Untuk menyalin model suara neural kustom Anda ke proyek lain:
Di tab Latih model, pilih model suara yang ingin disalin, lalu pilih Salin ke proyek.
Pilih Langganan, Wilayah, Sumber daya Ucapan, dan Proyek tempat Anda ingin menyalin model. Anda harus memiliki sumber daya ucapan dan proyek di wilayah target, jika tidak, Anda perlu membuatnya terlebih dahulu.
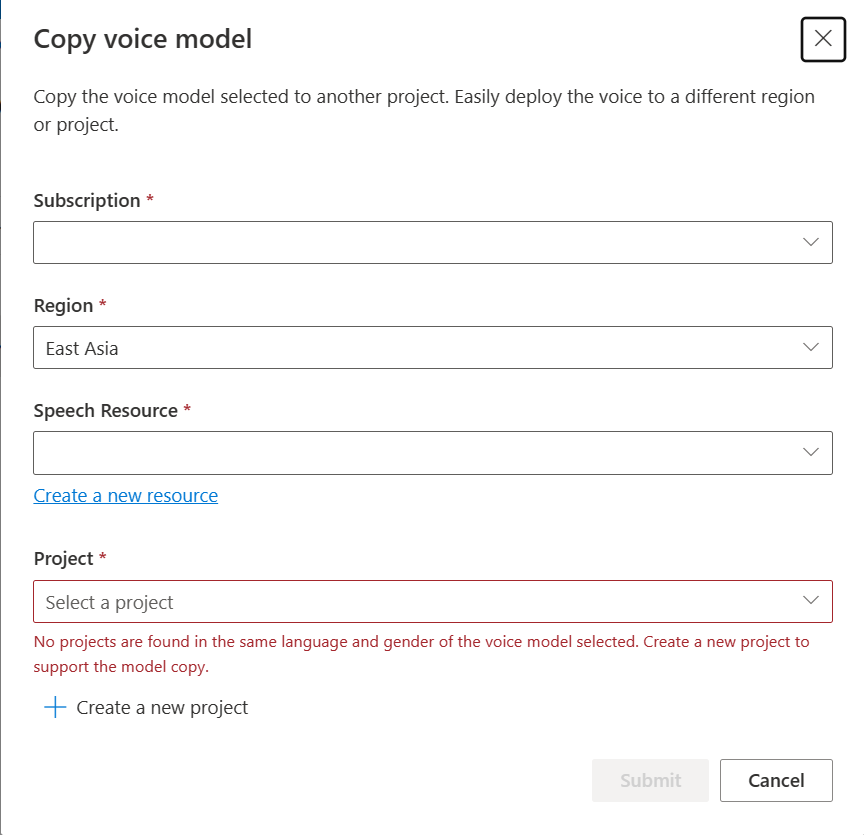
Pilih Kirim untuk menyalin model tersebut.
Pilih Tampilkan model di bawah pesan pemberitahuan untuk penyalinan yang berhasil.
Navigasikan ke proyek tempat Anda menyalin model untuk menyebarkan salinan model.
Langkah berikutnya
Dalam artikel ini, Anda mempelajari cara melatih suara neural kustom melalui API suara kustom.
Penting
Pelatihan suara neural kustom saat ini hanya tersedia di beberapa wilayah. Setelah model suara Anda dilatih di wilayah yang didukung, Anda dapat menyalinnya ke sumber daya Ucapan di wilayah lain sesuai kebutuhan. Untuk informasi selengkapnya, lihat catatan kaki dalam tabel layanan Ucapan.
Durasi pelatihan bervariasi tergantung pada berapa banyak data yang Anda gunakan. Dibutuhkan waktu rata-rata sekitar 40 jam komputasi untuk melatih suara neural kustom. Pengguna langganan standar (S0) dapat melatih empat suara secara bersamaan. Jika Anda mencapai batas, tunggu hingga setidaknya salah satu model suara Anda menyelesaikan pelatihan, lalu coba lagi.
Catatan
Meskipun jumlah total jam yang diperlukan per metode pelatihan bervariasi, harga satuan yang sama berlaku untuk masing-masing. Untuk informasi selengkapnya, lihat detail harga pelatihan neural kustom.
Pilih metode pelatihan
Setelah Memvalidasi file data, gunakan file tersebut untuk membangun model suara neural kustom Anda. Saat membuat suara saraf kustom, Anda dapat memilih untuk melatihnya dengan salah satu metode berikut:
Neural: Buat suara dalam bahasa yang sama dengan data pelatihan Anda.
Neural - bahasa silang: Buat suara yang berbicara bahasa yang berbeda dari data pelatihan Anda. Misalnya, dengan
fr-FRdata pelatihan, Anda dapat membuat suara yang berbicaraen-US.Bahasa data pelatihan dan bahasa target keduanya harus menjadi salah satu bahasa yang didukung untuk pelatihan suara lintas bahasa. Anda tidak perlu menyiapkan data pelatihan dalam bahasa target, tetapi skrip pengujian Anda harus dalam bahasa target.
Neural - multi gaya: Buat suara saraf kustom yang berbicara dalam beberapa gaya dan emosi, tanpa menambahkan data pelatihan baru. Beberapa suara gaya berguna untuk karakter video game, chatbot percakapan, buku audio, pembaca konten, dan banyak lagi.
Untuk membuat suara beberapa gaya, Anda perlu menyiapkan sekumpulan data pelatihan umum, setidaknya 300 ucapan. Pilih satu atau beberapa gaya berbicara target prasetel. Anda juga dapat membuat beberapa gaya kustom dengan menyediakan sampel gaya, setidaknya 100 ucapan per gaya, sebagai data pelatihan tambahan untuk suara yang sama. Gaya prasetel yang didukung bervariasi sesuai dengan bahasa yang berbeda. Lihat gaya prasetel yang tersedia di berbagai bahasa.
Bahasa data pelatihan harus menjadi salah satu bahasa yang didukung untuk suara saraf kustom, lintas bahasa, atau pelatihan gaya ganda.
Membuat model suara
Untuk membuat suara saraf, gunakan operasi Models_Create API suara kustom. Buat isi permintaan sesuai dengan instruksi berikut:
- Atur properti
projectIdyang diperlukan. Lihat membuat proyek. - Atur properti
consentIdyang diperlukan. Lihat menambahkan persetujuan bakat suara. - Atur properti
trainingSetIdyang diperlukan. Lihat membuat set pelatihan. - Atur properti resep
kindyang diperlukan keDefaultuntuk pelatihan suara saraf. Jenis resep menunjukkan metode pelatihan dan tidak dapat diubah nanti. Untuk menggunakan metode pelatihan yang berbeda, lihat Neural - bahasa silang atau Neural - multi gaya. Lihat Pelatihan dua bahasa untuk informasi selengkapnya tentang pelatihan dua bahasa dan perbedaan antara lokal. - Atur properti
voiceNameyang diperlukan. Nama suara harus diakhir dengan "Neural" dan tidak dapat diubah nanti. Pilih nama dengan hati-hati. Nama suara digunakan dalam permintaan sintesis ucapan Anda oleh input SDK dan SSML. Hanya huruf, angka, dan beberapa karakter tanda baca yang diizinkan. Gunakan nama yang berbeda untuk model suara neural yang berbeda. - Secara opsional, atur
descriptionproperti untuk deskripsi suara. Deskripsi suara dapat diubah nanti.
Buat permintaan HTTP PUT menggunakan URI seperti yang ditunjukkan dalam contoh Models_Create berikut.
- Ganti
YourResourceKeydengan kunci sumber daya Ucapan Anda. - Ganti
YourResourceRegiondengan wilayah sumber daya Ucapan Anda. - Ganti
JessicaModelIddengan ID model pilihan Anda. ID peka huruf besar/kecil akan digunakan dalam URI model dan tidak dapat diubah nanti.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview"
Anda akan menerima isi respons dalam format berikut:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Pelatihan dua bahasa
Jika Anda memilih jenis pelatihan Neural , Anda dapat melatih suara untuk berbicara dalam beberapa bahasa. Lokal zh-CN, , zh-HKdan zh-TW mendukung pelatihan dua bahasa agar suara dapat berbicara bahasa Tionghoa dan Inggris. Bergantung sebagian pada data pelatihan Anda, suara yang disintesis dapat berbicara bahasa Inggris dengan aksen asli bahasa Inggris atau bahasa Inggris dengan aksen yang sama dengan data pelatihan.
Catatan
Untuk mengaktifkan suara di zh-CN lokal untuk berbicara bahasa Inggris dengan aksen yang sama dengan data sampel, Anda harus memilih Chinese (Mandarin, Simplified), English bilingual saat membuat proyek atau menentukan zh-CN (English bilingual) lokal untuk data set pelatihan melalui REST API.
Tabel berikut ini memperlihatkan perbedaan di antara lokal:
| Lokal Speech Studio | Lokal REST API | Dukungan dua bahasa |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Jika data sampel Anda menyertakan bahasa Inggris, suara yang disintesis berbicara bahasa Inggris dengan aksen asli bahasa Inggris, alih-alih aksen yang sama dengan data sampel, terlepas dari jumlah data bahasa Inggris. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Jika Anda ingin suara yang disintesis berbicara bahasa Inggris dengan aksen yang sama dengan data sampel, sebaiknya sertakan lebih dari 10% data bahasa Inggris dalam set pelatihan Anda. Jika tidak, aksen berbahasa Inggris mungkin tidak ideal. |
Chinese (Cantonese, Simplified) |
zh-HK |
Jika Anda ingin melatih suara yang disintesis yang mampu berbicara bahasa Inggris dengan aksen yang sama dengan data sampel Anda, pastikan untuk memberikan lebih dari 10% data bahasa Inggris dalam set pelatihan Anda. Jika tidak, defaultnya adalah aksen asli bahasa Inggris. Ambang batas 10% dihitung berdasarkan data yang diterima setelah berhasil diunggah, bukan data sebelum diunggah. Jika beberapa data bahasa Inggris yang diunggah ditolak karena cacat dan tidak memenuhi ambang 10%, suara yang disintesis default ke aksen asli bahasa Inggris. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Jika Anda ingin melatih suara yang disintesis yang mampu berbicara bahasa Inggris dengan aksen yang sama dengan data sampel Anda, pastikan untuk memberikan lebih dari 10% data bahasa Inggris dalam set pelatihan Anda. Jika tidak, defaultnya adalah aksen asli bahasa Inggris. Ambang batas 10% dihitung berdasarkan data yang diterima setelah berhasil diunggah, bukan data sebelum diunggah. Jika beberapa data bahasa Inggris yang diunggah ditolak karena cacat dan tidak memenuhi ambang 10%, suara yang disintesis default ke aksen asli bahasa Inggris. |
Gaya prasetel yang tersedia di berbagai bahasa
Tabel berikut ini meringkas gaya prasetel yang berbeda sesuai dengan bahasa yang berbeda.
| Gaya berbicara | Bahasa (lokal) |
|---|---|
| marah | Inggris (Amerika Serikat) (en-US)Jepang (Jepang) ( ja-JP) 1Mandarin (Mandarin, Sederhana) ( zh-CN) 1 |
| tenang | Mandarin (Mandarin, Sederhana) (zh-CN) 1 |
| mengobrol | Mandarin (Mandarin, Sederhana) (zh-CN) 1 |
| gembira | Inggris (Amerika Serikat) (en-US)Jepang (Jepang) ( ja-JP) 1Mandarin (Mandarin, Sederhana) ( zh-CN) 1 |
| tidak puas | Mandarin (Mandarin, Sederhana) (zh-CN) 1 |
| gembira | Inggris (Amerika Serikat) (en-US) |
| takut | Mandarin (Mandarin, Sederhana) (zh-CN) 1 |
| ramah | Inggris (Amerika Serikat) (en-US) |
| Berharap | Inggris (Amerika Serikat) (en-US) |
| Sedih | Inggris (Amerika Serikat) (en-US)Jepang (Jepang) ( ja-JP) 1Mandarin (Mandarin, Sederhana) ( zh-CN) 1 |
| Berteriak | Inggris (Amerika Serikat) (en-US) |
| serius | Mandarin (Mandarin, Sederhana) (zh-CN) 1 |
| takut | Inggris (Amerika Serikat) (en-US) |
| Ramah | Inggris (Amerika Serikat) (en-US) |
| Berbisik | Inggris (Amerika Serikat) (en-US) |
1 Gaya suara neural tersedia dalam pratinjau publik. Gaya dalam pratinjau publik hanya tersedia di wilayah layanan ini: US Timur, Eropa Barat, dan Asia Tenggara.
Dapatkan status pelatihan
Untuk mendapatkan status pelatihan model suara, gunakan operasi Models_Get API suara kustom. Buat URI permintaan sesuai dengan instruksi berikut:
Buat permintaan HTTP GET menggunakan URI seperti yang ditunjukkan dalam contoh Models_Get berikut.
- Ganti
YourResourceKeydengan kunci sumber daya Ucapan Anda. - Ganti
YourResourceRegiondengan wilayah sumber daya Ucapan Anda. - Ganti
JessicaModelIdjika Anda menentukan ID model yang berbeda di langkah sebelumnya.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
Anda harus menerima isi respons dalam format berikut.
Catatan
Resep kind dan properti lainnya tergantung pada cara Anda melatih suara. Dalam contoh ini, jenis resep adalah Default untuk pelatihan suara saraf.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Anda mungkin perlu menunggu beberapa menit sebelum pelatihan selesai. Akhirnya status akan berubah menjadi atau Succeeded Failed.