Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Azure AI Foundry menyertakan sistem pemfilteran konten yang berfungsi bersama model inti dan model pembuatan gambar.
Penting
Sistem pemfilteran konten tidak diterapkan ke perintah dan penyelesaian yang diproses oleh model Whisper di Azure OpenAI di Model Azure AI Foundry. Pelajari selengkapnya tentang model Whisper di Azure OpenAI.
Cara kerjanya
Sistem pemfilteran konten didukung oleh Azure AI Content Safety, dan berfungsi dengan menjalankan input permintaan model dan output penyelesaian melalui serangkaian model klasifikasi yang dirancang untuk mendeteksi dan mencegah output konten berbahaya. Variasi dalam konfigurasi API dan desain aplikasi dapat memengaruhi penyelesaian dan dengan demikian memfilter perilaku.
Dengan penyebaran model Azure OpenAI, Anda dapat menggunakan filter konten default atau membuat filter konten Anda sendiri (dijelaskan nanti). Model yang tersedia melalui penyebaran API tanpa server memiliki pemfilteran konten yang diaktifkan secara default. Untuk mempelajari selengkapnya tentang filter konten default yang diaktifkan untuk penyebaran API tanpa server, lihat Keamanan konten untuk Model yang Dijual Langsung oleh Azure .
Dukungan bahasa
Model pemfilteran konten telah dilatih dan diuji pada bahasa berikut: bahasa Inggris, bahasa Jerman, bahasa Jepang, bahasa Spanyol, bahasa Prancis, bahasa Italia, bahasa Portugis, dan bahasa Mandarin. Namun, layanan ini dapat bekerja dalam banyak bahasa lain, tetapi kualitasnya dapat bervariasi. Dalam semua kasus, Anda harus melakukan pengujian Anda sendiri untuk memastikan bahwa itu berfungsi untuk aplikasi Anda.
Filter risiko konten (filter input dan output)
Filter khusus berikut berfungsi untuk input dan output model AI generatif:
Kategori
| Kategori | Deskripsi |
|---|---|
| Benci | Kategori kebencian menjelaskan serangan bahasa atau penggunaan yang mencakup bahasa pejoratif atau diskriminatif dengan merujuk ke seseorang atau kelompok identitas berdasarkan atribut pembeda tertentu dari kelompok-kelompok ini termasuk tetapi tidak terbatas pada ras, etnis, kebangsaan, identitas dan ekspresi gender, orientasi seksual, agama, status imigrasi, status kemampuan, penampilan pribadi, dan ukuran tubuh. |
| Seksual | Kategori seksual menggambarkan bahasa yang terkait dengan organ anatomi dan alat kelamin, hubungan romantis, tindakan yang digambarkan dalam istilah erotis atau kasih sayang, tindakan seksual fisik, termasuk yang digambarkan sebagai penyerangan atau tindakan kekerasan seksual paksa terhadap kehendak, prostitusi, pornografi, dan penyalahgunaan seseorang. |
| Kekerasan | Kategori kekerasan menjelaskan bahasa yang terkait dengan tindakan fisik yang dimaksudkan untuk menyakiti, melukai, merusak, atau membunuh seseorang atau sesuatu; menjelaskan senjata, dll. |
| Melukai Diri Sendiri | Kategori self-harm menggambarkan bahasa yang terkait dengan tindakan fisik yang dimaksudkan untuk secara sengaja melukai, melukai, atau merusak tubuh seseorang, atau membunuh diri sendiri. |
Tingkat keparahan
| Kategori | Deskripsi |
|---|---|
| Aman | Konten mungkin terkait dengan kekerasan, menyakiti diri sendiri, seksual, atau kategori kebencian tetapi istilah-istilah tersebut digunakan secara umum, jurnalistik, ilmiah, medis, dan konteks profesional serupa, yang sesuai untuk sebagian besar audiens. |
| Kurang Penting | Konten yang mengekspresikan pandangan berprasangka, menghakimen, atau berpendapat, termasuk penggunaan bahasa yang menyinggung, stereotip, kasus penggunaan yang menjelajahi dunia fiksi (misalnya, permainan, sastra) dan penggambaran dengan intensitas rendah. |
| Menengah | Konten yang menggunakan bahasa yang menyinggung, menghina, meniru, mengintimidasi, atau meremehkan terhadap grup identitas tertentu, termasuk penggambaran tentang mencari dan menjalankan instruksi berbahaya, fantasi, kemuliaan, promosi bahaya pada intensitas sedang. |
| Tinggi | Konten yang menampilkan instruksi, tindakan, kerusakan, atau penyalahgunaan berbahaya yang eksplisit dan parah; termasuk dukungan, kemuliaan, atau promosi tindakan berbahaya yang parah, bentuk bahaya ekstrem atau ilegal, radikalisasi, atau pertukaran kekuasaan nonkonsensual atau penyalahgunaan. |
Filter input lainnya
Anda juga dapat mengaktifkan filter khusus untuk skenario AI generatif:
- Serangan Jailbreak: Serangan Jailbreak adalah Permintaan Pengguna yang dirancang untuk memprovokasi model AI Generatif agar menunjukkan perilaku yang dilatih untuk menghindari atau melanggar aturan yang ditetapkan dalam Pesan Sistem.
- Serangan tidak langsung: Serangan Tidak Langsung, juga disebut sebagai Serangan Prompt Tidak Langsung atau Serangan Injeksi Prompt Lintas Domain, adalah potensi kerentanan di mana pihak ketiga menempatkan instruksi berbahaya di dalam dokumen yang dapat diakses dan diproses oleh sistem AI Generatif.
Filter output lainnya
Anda juga dapat mengaktifkan filter output khusus berikut:
- Materi yang dilindungi untuk teks: Teks materi yang dilindungi menjelaskan konten teks yang diketahui (misalnya, lirik lagu, artikel, resep, dan konten web yang dipilih) yang dapat dihasilkan oleh model bahasa besar.
- Bahan yang dilindungi untuk kode: Kode bahan yang dilindungi menjelaskan kode sumber yang cocok dengan sekumpulan kode sumber dari repositori publik, yang dapat dihasilkan oleh model bahasa besar tanpa kutipan repositori sumber yang tepat.
- Groundedness: Filter deteksi groundedness mendeteksi apakah respons teks model bahasa besar (LLM) di-grounded dalam materi sumber yang disediakan oleh pengguna.
Membuat filter konten di Azure AI Foundry
Untuk penyebaran model apa pun di Azure AI Foundry, Anda dapat langsung menggunakan filter konten default, tetapi Anda mungkin ingin memiliki lebih banyak kontrol. Misalnya, Anda dapat membuat filter lebih ketat atau lebih longgar, atau mengaktifkan kemampuan yang lebih canggih seperti perlindungan prompt dan deteksi bahan yang dilindungi.
Penting
Model GPT-image-1 tidak mendukung konfigurasi pemfilteran konten: hanya filter konten default yang digunakan.
Petunjuk / Saran
Untuk panduan tentang filter konten di proyek Azure AI Foundry, Anda dapat membaca selengkapnya di pemfilteran konten Azure AI Foundry.
Ikuti langkah-langkah berikut untuk membuat filter konten:
Petunjuk / Saran
Karena Anda bisa mengkustomisasi panel kiri di portal Azure AI Foundry, Anda mungkin melihat item yang berbeda dari yang diperlihatkan dalam langkah-langkah ini. Jika Anda tidak melihat apa yang Anda cari, pilih ... Lainnya di bagian bawah panel kiri.
Buka Azure AI Foundry dan navigasikan ke proyek Anda. Lalu pilih halaman Pagar Pembatas + kontrol dari menu sebelah kiri dan pilih tab Filter konten .

Pilih + Buat filter konten.
Pada halaman Informasi dasar , masukkan nama untuk konfigurasi pemfilteran konten Anda. Pilih koneksi untuk dikaitkan dengan filter konten. Kemudian pilih Berikutnya.
Sekarang Anda dapat mengonfigurasi filter input (untuk permintaan pengguna) dan filter output (untuk penyelesaian model).
Pada halaman Filter input , Anda dapat mengatur filter untuk perintah input. Untuk empat kategori konten pertama ada tiga tingkat keparahan yang dapat dikonfigurasi: Rendah, sedang, dan tinggi. Anda dapat menggunakan penggeser untuk mengatur ambang keparahan jika Anda menentukan bahwa aplikasi atau skenario penggunaan Anda memerlukan pemfilteran yang berbeda dari nilai default. Beberapa filter, seperti Prompt Shields dan Deteksi material yang dilindungi, memungkinkan Anda menentukan apakah model harus membuat anotasi dan/atau memblokir konten. Memilih Anotasi hanya menjalankan model masing-masing dan mengembalikan anotasi melalui respons API, tetapi tidak akan memfilter konten. Selain membuat anotasi, Anda juga dapat memilih untuk memblokir konten.
Jika kasus penggunaan Anda disetujui untuk filter konten yang dimodifikasi, Anda menerima kontrol penuh atas konfigurasi pemfilteran konten dan dapat memilih untuk mengaktifkan pemfilteran sebagian atau sepenuhnya, atau mengaktifkan anotasi hanya untuk kategori bahaya konten (kekerasan, kebencian, seksual, dan bahaya diri).
Konten akan dianotasikan menurut kategori dan diblokir sesuai dengan ambang yang Anda tetapkan. Untuk kategori kekerasan, kebencian, seksual, dan melukai diri sendiri, sesuaikan slider untuk memblokir konten dengan tingkat keparahan tinggi, sedang, atau rendah.

Pada halaman Filter output , Anda dapat mengonfigurasi filter output, yang akan diterapkan ke semua konten output yang dihasilkan oleh model Anda. Konfigurasikan filter individual seperti sebelumnya. Halaman ini juga menyediakan opsi Mode Streaming, yang memungkinkan Anda untuk memfilter konten dalam hampir waktu nyata saat dihasilkan oleh model, sehingga mengurangi latensi. Setelah selesai, pilih Berikutnya.
Konten akan dianotasikan oleh setiap kategori dan diblokir sesuai dengan ambang batas. Untuk konten kekerasan, konten kebencian, konten seksual, dan kategori konten yang merugikan diri sendiri, sesuaikan ambang batas untuk memblokir konten berbahaya dengan tingkat keparahan yang sama atau lebih tinggi.

Secara opsional, pada halaman Penyebaran , Anda dapat mengaitkan filter konten dengan penyebaran. Jika penyebaran yang dipilih sudah melampirkan filter, Anda harus mengonfirmasi bahwa Anda ingin menggantinya. Anda juga dapat mengaitkan filter konten dengan penyebaran nanti. Pilih Buat.
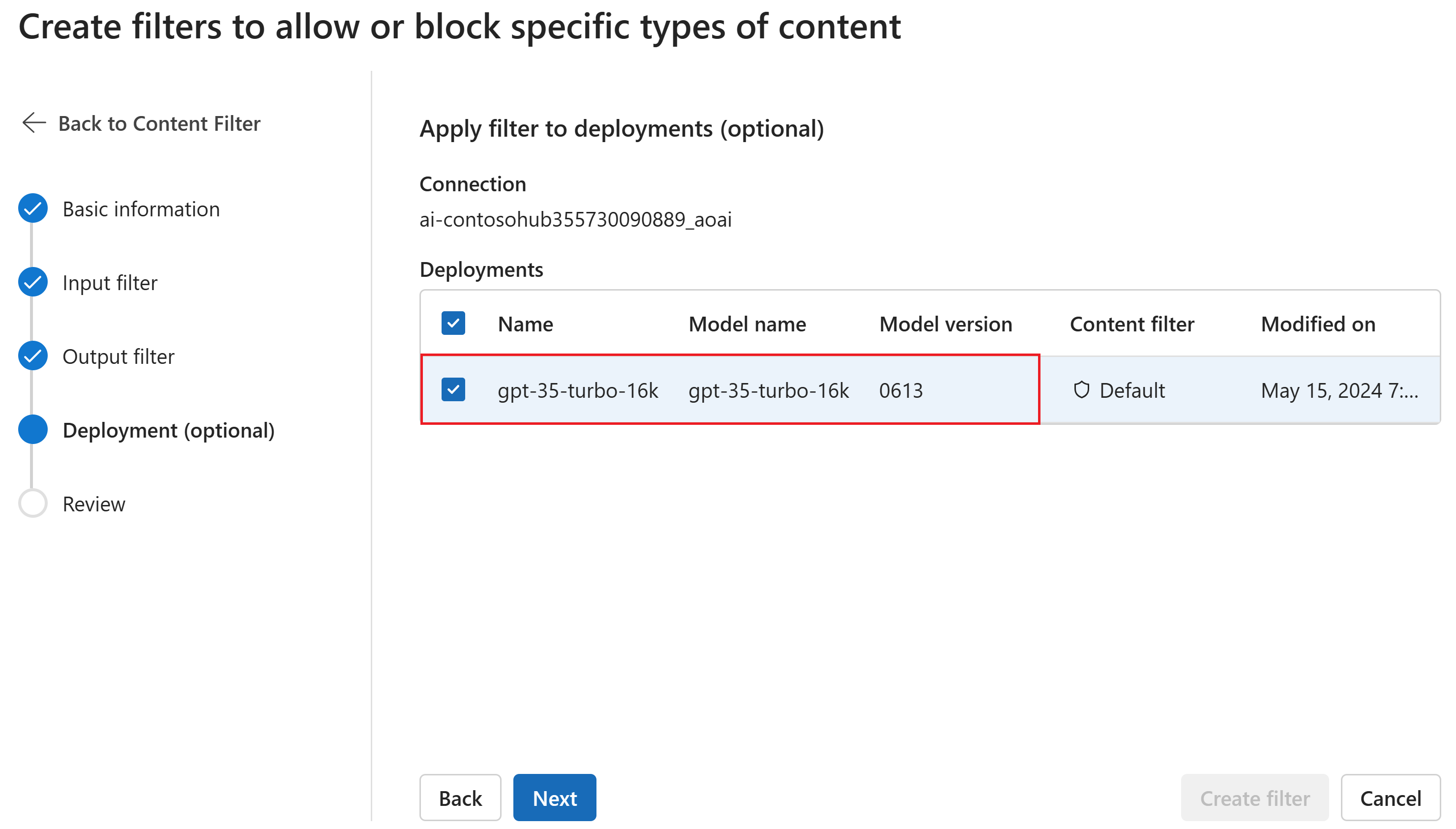
Konfigurasi pemfilteran konten dibuat di tingkat hub di portal Azure AI Foundry. Pelajari selengkapnya tentang konfigurasi di Azure OpenAI dalam dokumentasi Model Azure AI Foundry.
Pada halaman Tinjau , tinjau pengaturan lalu pilih Buat filter.



Menggunakan daftar blokir sebagai filter
Anda dapat menerapkan daftar blokir sebagai filter input atau output, atau keduanya. Aktifkan opsi Daftar blokir pada halaman Filter input dan/atau Filter output . Pilih satu atau beberapa daftar blokir dari menu dropdown, atau gunakan daftar blokir kata-kata kotor bawaan. Anda dapat menggabungkan beberapa daftar blok ke dalam filter yang sama.
Menerapkan filter konten
Proses pembuatan filter memberi Anda opsi untuk menerapkan filter ke penyebaran yang Anda inginkan. Kapan saja, Anda juga dapat mengubah atau menghapus filter konten dari penerapan Anda.
Ikuti langkah-langkah berikut untuk menerapkan filter konten ke penyebaran:
Buka Azure AI Foundry dan pilih proyek.
Pilih Model + endpoint di panel kiri dan pilih salah satu deployment Anda, lalu pilih Edit.

Di jendela Perbarui penyebaran , pilih filter konten yang ingin Anda terapkan ke penyebaran. Lalu pilih Simpan dan tutup.

Anda juga dapat mengedit dan menghapus konfigurasi filter konten jika diperlukan. Sebelum menghapus konfigurasi pemfilteran konten, Anda harus melepas penugasan dan menggantinya pada penyebaran apa pun di tab Penyebaran.


Sekarang, Anda dapat pergi ke taman bermain untuk menguji apakah filter konten berfungsi seperti yang diharapkan.
Petunjuk / Saran
Anda juga dapat membuat dan memperbarui filter konten menggunakan REST API. Untuk mengetahui informasi selengkapnya, lihat referensi API. Filter konten dapat dikonfigurasi di tingkat sumber daya. Setelah konfigurasi baru dibuat, ini dapat dihubungkan dengan satu atau lebih penyebaran. Untuk informasi selengkapnya tentang penyebaran model, lihat panduan penyebaran sumber daya.
Konfigurasi (pratinjau)
Azure OpenAI di Model Azure AI Foundry menyertakan pengaturan keamanan default yang diterapkan ke semua model (tidak termasuk model API audio seperti Whisper). Konfigurasi ini memberi Anda pengalaman yang bertanggung jawab secara default, termasuk model pemfilteran konten, daftar blokir, transformasi permintaan, kredensial konten, dan lainnya. Baca selengkapnya tentang hal itu di sini.
Semua pelanggan juga dapat mengonfigurasi filter konten dan membuat kebijakan konten kustom yang disesuaikan dengan persyaratan kasus penggunaan mereka. Fitur konfigurasi memungkinkan pelanggan untuk menyesuaikan pengaturan, secara terpisah untuk permintaan dan penyelesaian, untuk memfilter konten untuk setiap kategori konten pada tingkat keparahan yang berbeda seperti yang dijelaskan dalam tabel di bawah ini. Konten yang terdeteksi pada tingkat keparahan 'aman' diberi label dalam output anotasi tetapi tidak tunduk pada pemfilteran dan tidak dapat dikonfigurasi.
| Tingkat keparahan difilter | Dapat dikonfigurasi untuk petunjuk | Dapat dikonfigurasi untuk penyelesaian tugas | Deskripsi |
|---|---|---|---|
| Rendah, sedang, tinggi | Ya | Ya | Konfigurasi pemfilteran paling ketat. Konten yang terdeteksi pada tingkat keparahan rendah, sedang, dan tinggi difilter. |
| Sedang, tinggi | Ya | Ya | Konten yang terdeteksi pada tingkat keparahan rendah tidak difilter, konten pada sedang dan tinggi difilter. |
| Tinggi | Ya | Ya | Konten yang terdeteksi pada tingkat keparahan rendah dan sedang tidak difilter. Hanya konten pada tingkat keparahan tinggi yang difilter. |
| Tidak ada filter | Jika disetujui1 | Jika disetujui1 | Tidak ada konten yang difilter terlepas dari tingkat keparahan yang terdeteksi. Memerlukan persetujuan1. |
| Anotasi saja | Jika disetujui1 | Jika disetujui1 | Menonaktifkan fungsionalitas filter, sehingga konten tidak akan diblokir, tetapi anotasi dikembalikan melalui respons API. Memerlukan persetujuan1. |
1 Untuk model Azure OpenAI, hanya pelanggan yang telah disetujui untuk pemfilteran konten yang dimodifikasi yang memiliki kontrol pemfilteran konten penuh dan dapat menonaktifkan filter konten. Ajukan permohonan untuk filter konten yang dimodifikasi melalui formulir ini: Tinjauan Akses Terbatas Azure OpenAI: Filter Konten yang Dimodifikasi. Untuk pelanggan Azure Government, ajukan filter konten yang dimodifikasi melalui formulir ini: Azure Government - Minta Pemfilteran Konten yang Dimodifikasi untuk Azure OpenAI.
Filter konten yang dapat dikonfigurasi untuk input (perintah) dan output (penyelesaian) tersedia untuk semua model Azure OpenAI.
Konfigurasi pemfilteran konten dibuat dalam Resource di portal Azure AI Foundry, dan dapat dikaitkan dengan Penerapan. Pelajari selengkapnya tentang mengonfigurasi filter konten di sini.
Pelanggan bertanggung jawab untuk memastikan bahwa aplikasi yang mengintegrasikan Azure OpenAI mematuhi Kode Etik.
Konten terkait
- Pelajari selengkapnya tentang model yang mendasari yang mendukung Azure OpenAI.
- Pemfilteran konten Azure AI Foundry didukung oleh Azure AI Content Safety.
- Pelajari selengkapnya tentang memahami dan mengurangi risiko yang terkait dengan aplikasi Anda: Gambaran umum praktik AI yang Bertanggung Jawab untuk model Azure OpenAI.
- Pelajari selengkapnya tentang mengevaluasi model AI dan sistem AI generatif Anda melalui Evaluasi Azure AI.