Cara mengevaluasi aplikasi AI generatif dengan Azure AI Studio
Penting
Item yang ditandai (pratinjau) dalam artikel ini sedang dalam pratinjau publik. Pratinjau ini disediakan tanpa perjanjian tingkat layanan, dan kami tidak merekomendasikannya untuk beban kerja produksi. Fitur tertentu mungkin tidak didukung atau mungkin memiliki kemampuan terbatas. Untuk mengetahui informasi selengkapnya, lihat Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure.
Untuk menilai performa aplikasi AI generatif Anda secara menyeluruh saat diterapkan ke himpunan data yang substansial, Anda dapat memulai proses evaluasi. Selama evaluasi ini, aplikasi Anda diuji dengan himpunan data yang diberikan, dan performanya akan diukur secara kuantitatif dengan metrik berbasis matematika dan metrik yang dibantu AI. Eksekusi evaluasi ini memberi Anda wawasan komprehensif tentang kemampuan dan batasan aplikasi.
Untuk melakukan evaluasi ini, Anda dapat menggunakan fungsionalitas evaluasi di Azure AI Studio, platform komprehensif yang menawarkan alat dan fitur untuk menilai performa dan keamanan model AI generatif Anda. Di AI Studio, Anda dapat mencatat, melihat, dan menganalisis metrik evaluasi terperinci.
Dalam artikel ini, Anda belajar membuat evaluasi yang dijalankan dari himpunan data pengujian atau alur dengan metrik evaluasi bawaan dari Antarmuka Pengguna Azure AI Studio. Untuk fleksibilitas yang lebih besar, Anda dapat membuat alur evaluasi kustom dan menggunakan fitur evaluasi kustom. Atau, jika tujuan Anda semata-mata untuk melakukan eksekusi batch tanpa evaluasi apa pun, Anda juga dapat menggunakan fitur evaluasi kustom.
Prasyarat
Untuk menjalankan evaluasi dengan metrik yang dibantu AI, Anda harus menyiapkan hal berikut:
- Himpunan data pengujian dalam salah satu format ini:
csvataujsonl. - Koneksi Azure OpenAI.
- Penyebaran salah satu model ini: model GPT 3.5, model GPT 4, atau model Davinci.
Membuat evaluasi dengan metrik evaluasi bawaan
Eksekusi evaluasi memungkinkan Anda menghasilkan output metrik untuk setiap baris data dalam himpunan data pengujian Anda. Anda dapat memilih satu atau beberapa metrik evaluasi untuk menilai output dari berbagai aspek. Anda dapat membuat evaluasi yang dijalankan dari halaman alur evaluasi dan prompt di AI Studio. Kemudian wizard pembuatan evaluasi muncul untuk memandu Anda melalui proses menyiapkan eksekusi evaluasi.
Dari halaman evaluasi
Dari menu kiri yang dapat diciutkan, pilih Evaluasi>+ Evaluasi baru.

Dari halaman alur
Dari menu kiri yang dapat diciutkan, pilih Alur>perintah Evaluasi>Evaluasi Bawaan.

Informasi dasar
Saat Anda memulai evaluasi dari halaman evaluasi, Anda perlu memutuskan apa target evaluasi terlebih dahulu. Dengan menentukan target evaluasi yang sesuai, kami dapat menyesuaikan evaluasi dengan sifat spesifik aplikasi Anda, memastikan metrik yang akurat dan relevan. Saat ini kami mendukung dua jenis target evaluasi:
Himpunan data: Anda sudah memiliki output yang dihasilkan model dalam himpunan data pengujian. Alur perintah: Anda telah membuat alur, dan Anda ingin mengevaluasi output dari alur.

Saat Anda memasukkan wizard pembuatan evaluasi, Anda dapat memberikan nama opsional untuk eksekusi evaluasi Anda dan memilih skenario yang paling sesuai dengan tujuan aplikasi Anda. Saat ini kami menawarkan dukungan untuk skenario berikut:
- Pertanyaan dan jawaban dengan konteks: Skenario ini dirancang untuk aplikasi yang melibatkan jawaban kueri pengguna dan memberikan respons dengan informasi konteks.
- Pertanyaan dan jawaban tanpa konteks: Skenario ini dirancang untuk aplikasi yang melibatkan jawaban atas kueri pengguna dan memberikan respons tanpa konteks.
Anda dapat menggunakan panel bantuan untuk memeriksa FAQ dan memandu diri Anda melalui wizard.

Jika Anda mengevaluasi alur perintah, Anda dapat memilih alur untuk dievaluasi. Jika Anda memulai evaluasi dari halaman Alur, kami akan secara otomatis memilih alur Anda untuk dievaluasi. Jika Anda ingin mengevaluasi alur lain, Anda dapat memilih alur lain. Penting untuk dicatat bahwa dalam alur, Anda mungkin memiliki beberapa simpul, yang masing-masing dapat memiliki serangkaian variannya sendiri. Dalam kasus seperti itu, Anda harus menentukan simpul dan varian yang ingin Anda nilai selama proses evaluasi.

Mengonfigurasi data pengujian
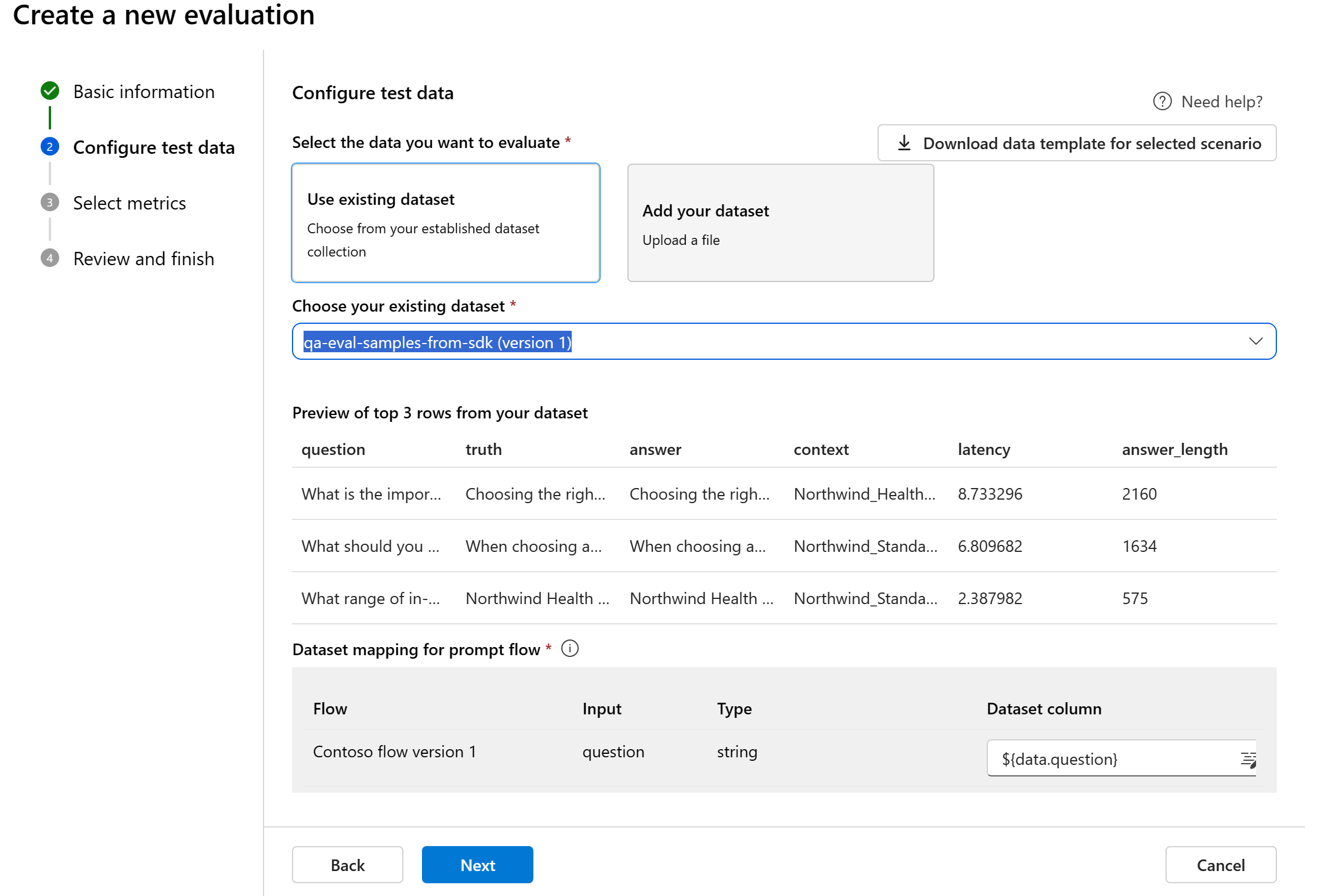
Anda dapat memilih dari himpunan data yang sudah ada sebelumnya atau mengunggah himpunan data baru khusus untuk dievaluasi. Himpunan data pengujian harus memiliki output yang dihasilkan model untuk digunakan untuk evaluasi jika tidak ada alur yang dipilih pada langkah sebelumnya.
Pilih himpunan data yang ada: Anda dapat memilih himpunan data pengujian dari kumpulan data yang anda buat.
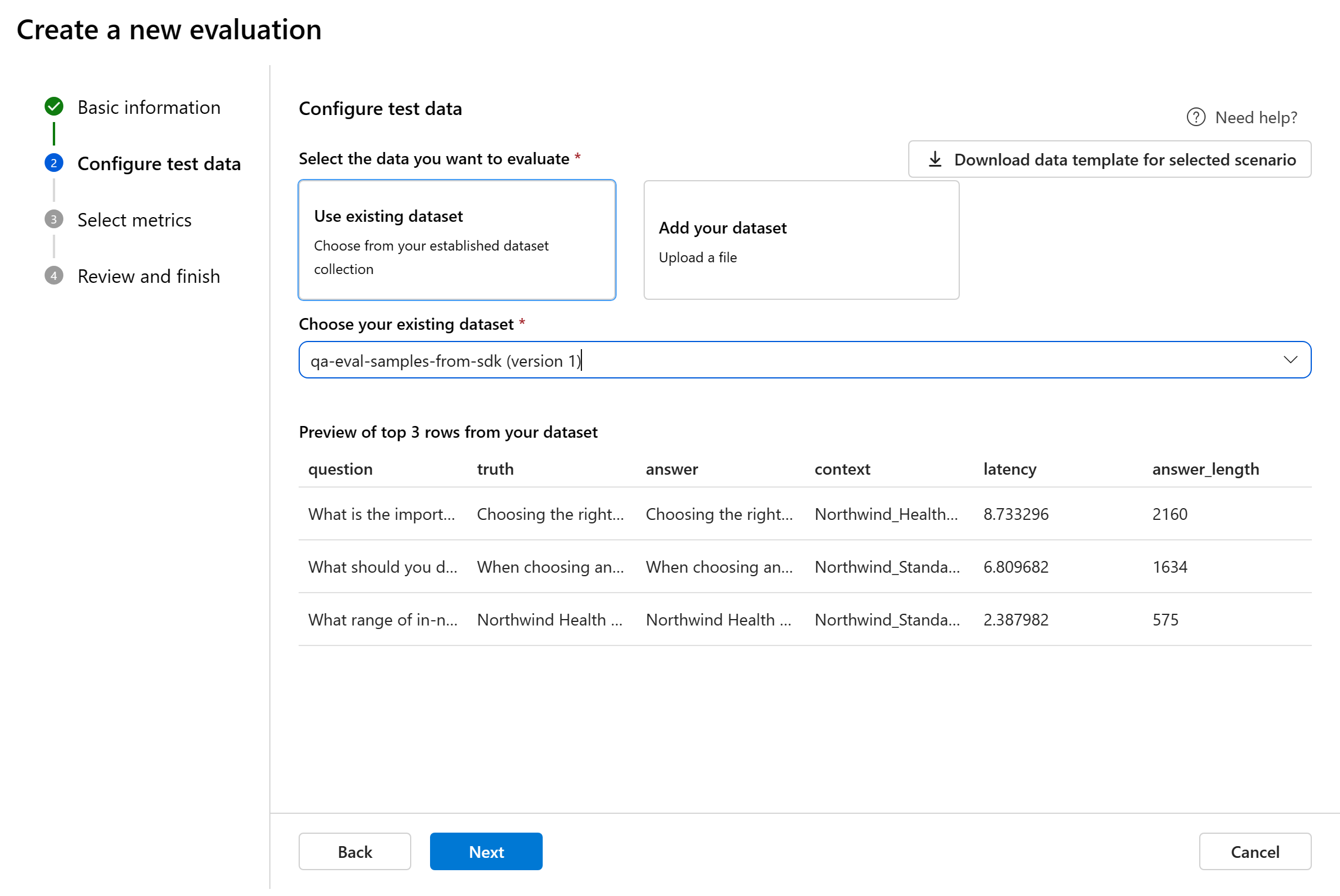
Menambahkan himpunan data baru: Anda dapat mengunggah file dari penyimpanan lokal Anda. Kami hanya mendukung
.csvdan.jsonlformat file.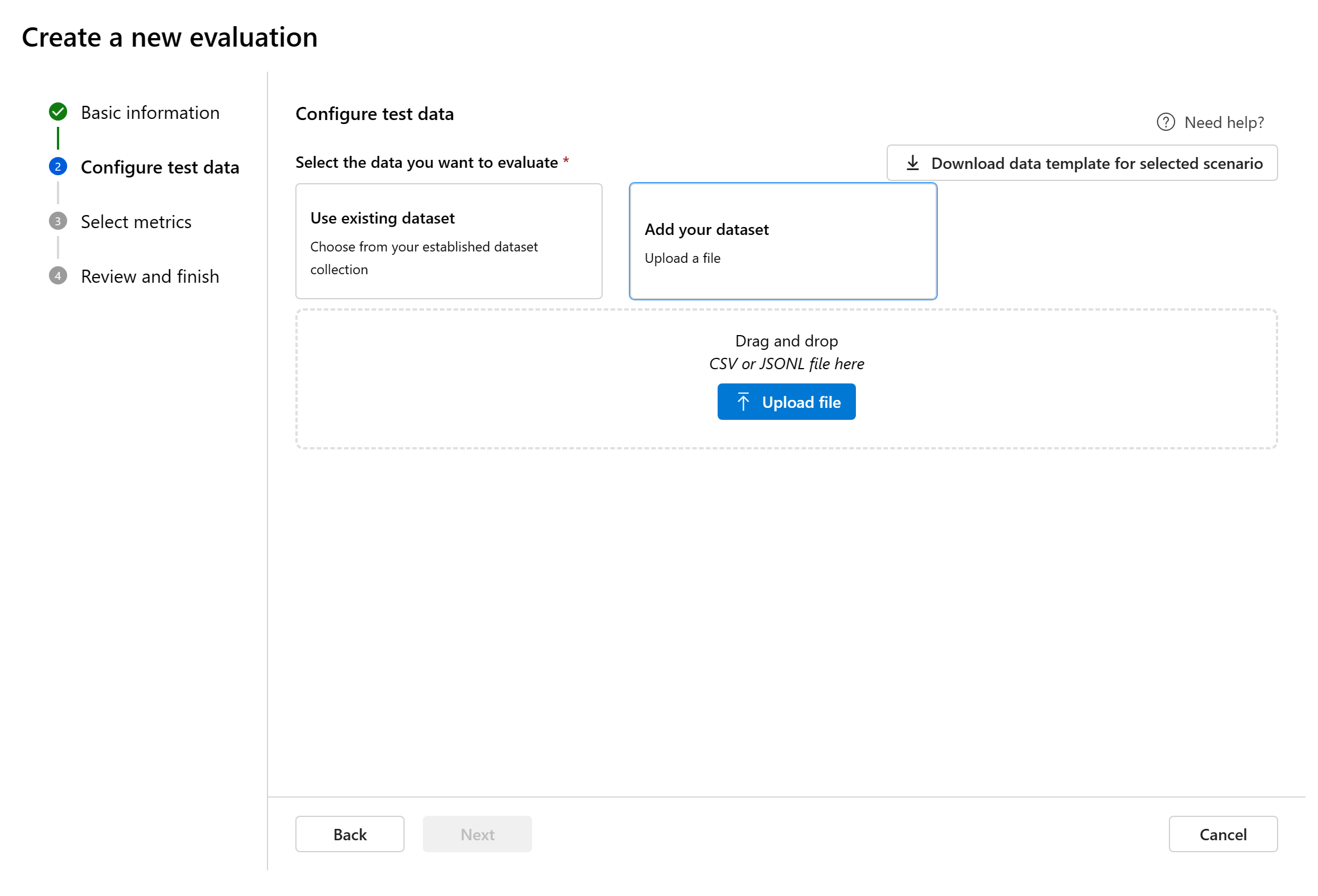
Pemetaan data untuk alur: Jika Anda memilih alur untuk dievaluasi, pastikan bahwa kolom data Anda dikonfigurasi agar selaras dengan input yang diperlukan agar alur dapat menjalankan eksekusi batch, menghasilkan output untuk penilaian. Evaluasi kemudian akan dilakukan menggunakan output dari alur. Kemudian, konfigurasikan pemetaan data untuk input evaluasi di langkah berikutnya.



Pilih metrik
Kami mendukung dua jenis metrik yang dikumpulkan oleh Microsoft untuk memfasilitasi evaluasi komprehensif aplikasi Anda:
- Metrik performa dan kualitas: Metrik ini mengevaluasi kualitas dan koherensi keseluruhan konten yang dihasilkan.
- Metrik risiko dan keamanan: Metrik ini berfokus pada mengidentifikasi potensi risiko konten dan memastikan keamanan konten yang dihasilkan.
Anda dapat merujuk ke tabel untuk daftar lengkap metrik yang kami tawarkan dukungan untuk dalam setiap skenario. Untuk informasi lebih mendalam tentang setiap definisi metrik dan cara menghitungnya, lihat Metrik evaluasi dan pemantauan.
| Skenario | Metrik performa dan kualitas | Metrik risiko dan keamanan |
|---|---|---|
| Pertanyaan dan jawaban dengan konteks | Groundedness, Relevansi, Koherensi, Kefasihan, kesamaan GPT, skor F1 | Konten terkait bahaya diri sendiri, Konten benci dan tidak adal, Konten kekerasan, Konten seksual, Materi yang dilindungi, Serangan tidak langsung |
| Pertanyaan dan jawaban tanpa konteks | Koherensi, Kefasihan, kesamaan GPT, skor F1 | Konten terkait bahaya diri sendiri, Konten benci dan tidak adal, Konten kekerasan, Konten seksual, Materi yang dilindungi, Serangan tidak langsung |
Saat menggunakan metrik yang dibantu AI untuk evaluasi performa dan kualitas, Anda harus menentukan model GPT untuk proses penghitungan. Pilih koneksi Azure OpenAI dan penyebaran dengan GPT-3.5, GPT-4, atau model Davinci untuk perhitungan kami.

Untuk metrik risiko dan keamanan, Anda tidak perlu menyediakan koneksi dan penyebaran. Layanan back-end evaluasi keamanan Azure AI Studio menyediakan model GPT-4 yang dapat menghasilkan skor tingkat keparahan risiko konten dan penalaran untuk memungkinkan Anda mengevaluasi aplikasi Anda atas bahaya konten.
Anda dapat mengatur ambang batas untuk menghitung tingkat cacat untuk metrik bahaya konten (konten terkait bahaya diri sendiri, konten yang penuh kebencian dan tidak adulir, konten kekerasan, konten seksual). Tingkat cacat dihitung dengan mengambil persentase instans dengan tingkat keparahan (Sangat rendah, Rendah, Sedang, Tinggi) di atas ambang batas. Secara default, kami menetapkan ambang batas sebagai "Sedang".
Untuk material yang dilindungi dan serangan tidak langsung, tingkat cacat dihitung dengan mengambil persentase instans di mana outputnya adalah 'true' (Tingkat Cacat = (#trues / #instances) × 100).

Catatan
Metrik risiko dan keselamatan yang dibantu AI dihosting oleh layanan back-end evaluasi keamanan Azure AI Studio dan hanya tersedia di wilayah berikut: US Timur 2, Prancis Tengah, Inggris Selatan, Swedia Tengah
Pemetaan data untuk evaluasi: Anda harus menentukan kolom data mana dalam himpunan data Anda yang sesuai dengan input yang diperlukan dalam evaluasi. Metrik evaluasi yang berbeda menuntut jenis input data yang berbeda untuk perhitungan yang akurat.

Catatan
Jika Anda mengevaluasi dari data, "jawaban" harus memetakan ke kolom jawaban di himpunan ${data$answer}data Anda . Jika Anda mengevaluasi dari alur, "jawaban" harus berasal dari output ${run.outputs.answer}aliran .
Untuk panduan tentang persyaratan pemetaan data tertentu untuk setiap metrik, lihat informasi yang disediakan dalam tabel:
Persyaratan metrik jawaban atas pertanyaan
| Metrik | Pertanyaan | Jawaban | Konteks | Kebenaran dasar |
|---|---|---|---|---|
| Groundedness | Diperlukan: Str | Diperlukan: Str | Diperlukan: Str | T/A |
| Koherensi | Diperlukan: Str | Diperlukan: Str | T/A | T/A |
| Kelancaran | Diperlukan: Str | Diperlukan: Str | T/A | T/A |
| Relevansi | Diperlukan: Str | Diperlukan: Str | Diperlukan: Str | T/A |
| Kesamaan GPT | Diperlukan: Str | Diperlukan: Str | T/A | Diperlukan: Str |
| Skor F1 | Diperlukan: Str | Diperlukan: Str | T/A | Diperlukan: Str |
| Konten terkait bahaya mandiri | Diperlukan: Str | Diperlukan: Str | T/A | T/A |
| Konten yang penuh kebencian dan tidak adal | Diperlukan: Str | Diperlukan: Str | T/A | T/A |
| Konten kekerasan | Diperlukan: Str | Diperlukan: Str | T/A | T/A |
| Konten seksual | Diperlukan: Str | Diperlukan: Str | T/A | T/A |
| Bahan yang dilindungi | Diperlukan: Str | Diperlukan: Str | T/A | T/A |
| Serangan tidak langsung | Diperlukan: Str | Diperlukan: Str | T/A | T/A |
- Pertanyaan: pertanyaan yang diajukan oleh pengguna di pasangan Tanya Jawab
- Jawaban: respons terhadap pertanyaan yang dihasilkan oleh model sebagai jawaban
- Konteks: sumber yang dihasilkan respons sehubungan dengan (yaitu, dokumen dasar)
- Kebenaran dasar: respons terhadap pertanyaan yang dihasilkan oleh pengguna/manusia sebagai jawaban sebenarnya
Periksa dan selesaikan
Setelah menyelesaikan semua konfigurasi yang diperlukan, Anda dapat meninjau dan melanjutkan untuk memilih 'Kirim' untuk mengirimkan eksekusi evaluasi.

Membuat evaluasi dengan alur evaluasi kustom
Anda dapat mengembangkan metode evaluasi Anda sendiri:
Dari halaman alur: Dari menu kiri yang dapat diciutkan, pilih Alur>perintah Evaluasi>Evaluasi Kustom.

Menampilkan dan mengelola evaluator di pustaka evaluator
Pustaka evaluator adalah tempat terpusat yang memungkinkan Anda melihat detail dan status evaluator Anda. Anda dapat melihat dan mengelola evaluator yang dikumpulkan Microsoft.
Tip
Anda dapat menggunakan evaluator kustom melalui SDK alur perintah. Untuk informasi selengkapnya, lihat Mengevaluasi dengan SDK alur perintah.
Pustaka evaluator juga memungkinkan manajemen versi. Anda dapat membandingkan berbagai versi pekerjaan Anda, memulihkan versi sebelumnya jika diperlukan, dan berkolaborasi dengan orang lain dengan lebih mudah.
Untuk menggunakan pustaka evaluator di AI Studio, buka halaman Evaluasi proyek Anda dan pilih tab Pustaka evaluator.

Anda dapat memilih nama evaluator untuk melihat detail selengkapnya. Anda dapat melihat nama, deskripsi, dan parameter, dan memeriksa file apa pun yang terkait dengan evaluator. Berikut adalah beberapa contoh evaluator yang dikumpulkan Microsoft:
- Untuk evaluator performa dan kualitas yang dikurasi oleh Microsoft, Anda dapat melihat perintah anotasi di halaman detail. Anda dapat menyesuaikan perintah ini ke kasus penggunaan Anda sendiri dengan mengubah parameter atau kriteria sesuai dengan data dan tujuan Anda dengan SDK alur perintah. Misalnya, Anda dapat memilih Groundedness-Evaluator dan memeriksa file Prompty yang menunjukkan cara kami menghitung metrik.
- Untuk evaluator risiko dan keselamatan yang dikumpulkan oleh Microsoft, Anda dapat melihat definisi metrik. Misalnya, Anda dapat memilih Self-Harm-Related-Content-Content-Evaluator dan mempelajari apa artinya dan bagaimana Microsoft menentukan berbagai tingkat keparahan untuk metrik keamanan ini
Langkah berikutnya
Pelajari selengkapnya tentang cara mengevaluasi aplikasi AI generatif Anda:
- Mengevaluasi aplikasi AI generatif Anda melalui taman bermain
- Menampilkan hasil evaluasi
- Pelajari selengkapnya tentang teknik mitigasi bahaya.
- Catatan Transparansi untuk evaluasi keamanan Azure AI Studio.