Membangun dan melatih model klasifikasi kustom
Konten ini berlaku untuk:![]() v4.0 (pratinjau) | Versi sebelumnya:
v4.0 (pratinjau) | Versi sebelumnya:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Penting
Model klasifikasi kustom saat ini dalam pratinjau publik. Fitur, pendekatan, dan proses dapat berubah, sebelum Ketersediaan Umum (GA), berdasarkan umpan balik pengguna.
Model klasifikasi kustom dapat mengklasifikasikan setiap halaman dalam file input untuk mengidentifikasi dokumen di dalamnya. Model pengklasifikasi juga dapat mengidentifikasi beberapa dokumen atau beberapa instans dari satu dokumen dalam file input. Model kustom Kecerdasan Dokumen memerlukan sekitar lima dokumen pelatihan per kelas dokumen untuk memulai. Untuk mulai melatih model klasifikasi kustom, Anda memerlukan setidaknya lima dokumen untuk setiap kelas dan dua kelas dokumen.
Persyaratan input model klasifikasi kustom
Pastikan himpunan data pelatihan Anda mengikuti persyaratan input untuk Kecerdasan Dokumen.
Untuk hasil terbaik, berikan satu foto yang jelas atau pemindaian berkualitas tinggi per dokumen.
Format file yang didukung:
Model PDF Gambar:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), dan HTMLRead ✔ ✔ ✔ Tata letak ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Dokumen Umum ✔ ✔ Bawaan ✔ ✔ Ekstraksi kustom ✔ ✔ Klasifikasi kustom ✔ ✔ ✔ (Pratinjau 2024-02-29) Untuk PDF dan TIFF, hingga 2000 halaman yang dapat diproses (dengan langganan tingkat gratis, hanya dua halaman pertama yang diproses).
Ukuran file untuk menganalisis dokumen adalah 500 MB untuk tingkat berbayar (S0) dan 4 MB secara gratis (F0).
Dimensi gambar harus antara 50 x 50 piksel dan 10.000 piksel x 10.000 piksel.
Jika PDF Anda dikunci dengan kata sandi, Anda harus menghapus kunci sebelum pengiriman.
Tinggi minimum teks yang akan diekstrak adalah 12 piksel untuk gambar piksel 1024 x 768. Dimensi ini sesuai dengan teks sekitar
8-point pada 150 titik per inci (DPI).Untuk pelatihan model kustom, jumlah maksimum halaman untuk data pelatihan adalah 500 untuk model template kustom dan 50.000 untuk model neural kustom.
Untuk pelatihan model ekstraksi kustom, ukuran total data pelatihan adalah 50 MB untuk model templat dan 1G-MB untuk model neural.
Untuk pelatihan model klasifikasi kustom, ukuran total data pelatihan adalah
1GBdengan maksimum 10.000 halaman.
Tips data pelatihan
Ikuti tips berikut ini untuk lebih mengoptimalkan himpunan data Anda untuk pelatihan:
Jika memungkinkan, gunakan dokumen PDF berbasis teks daripada dokumen berbasis gambar. PDF yang dipindai ditangani sebagai gambar.
Jika gambar formulir Anda memiliki kualitas yang lebih rendah, gunakan kumpulan data yang lebih besar (10-15 gambar, misalnya).
Mengunggah data pelatihan Anda
Setelah Anda mengumpulkan sekumpulan formulir atau dokumen untuk pelatihan, Anda perlu mengunggahnya ke kontainer penyimpanan blob Azure. Jika Anda tidak tahu cara membuat akun penyimpanan Azure dengan kontainer, ikuti panduan mulai cepat Azure Storage untuk portal Azure. Untuk mencoba layanan, Anda dapat menggunakan tingkat harga gratis (F0), lalu meningkatkannya ke tingkat berbayar untuk produksi. Jika himpunan data Anda diatur sebagai folder, pertahankan struktur tersebut karena Studio dapat menggunakan nama folder Anda untuk label guna menyederhanakan proses pelabelan.
Membuat proyek klasifikasi di Studio Kecerdasan Dokumen
Studio Kecerdasan Dokumen menyediakan dan mengatur semua panggilan API yang diperlukan untuk menyelesaikan himpunan data Anda dan melatih model Anda.
Mulailah dengan menavigasi ke Studio Kecerdasan Dokumen. Saat pertama kali menggunakan Studio, Anda perlu menginisialisasi langganan, grup sumber daya, dan sumber daya Anda. Kemudian, ikuti prasyarat untuk proyek kustom untuk mengonfigurasi Studio untuk mengakses himpunan data pelatihan Anda.
Di Studio, pilih petak peta Model klasifikasi kustom, pada bagian model kustom halaman dan pilih tombol Buat proyek .

Pada dialog buat proyek, berikan nama untuk proyek Anda, secara opsional sebuah deskripsi, dan pilih lanjutkan.
Selanjutnya, pilih atau buat sumber daya Kecerdasan Dokumen sebelum Anda memilih lanjutkan.
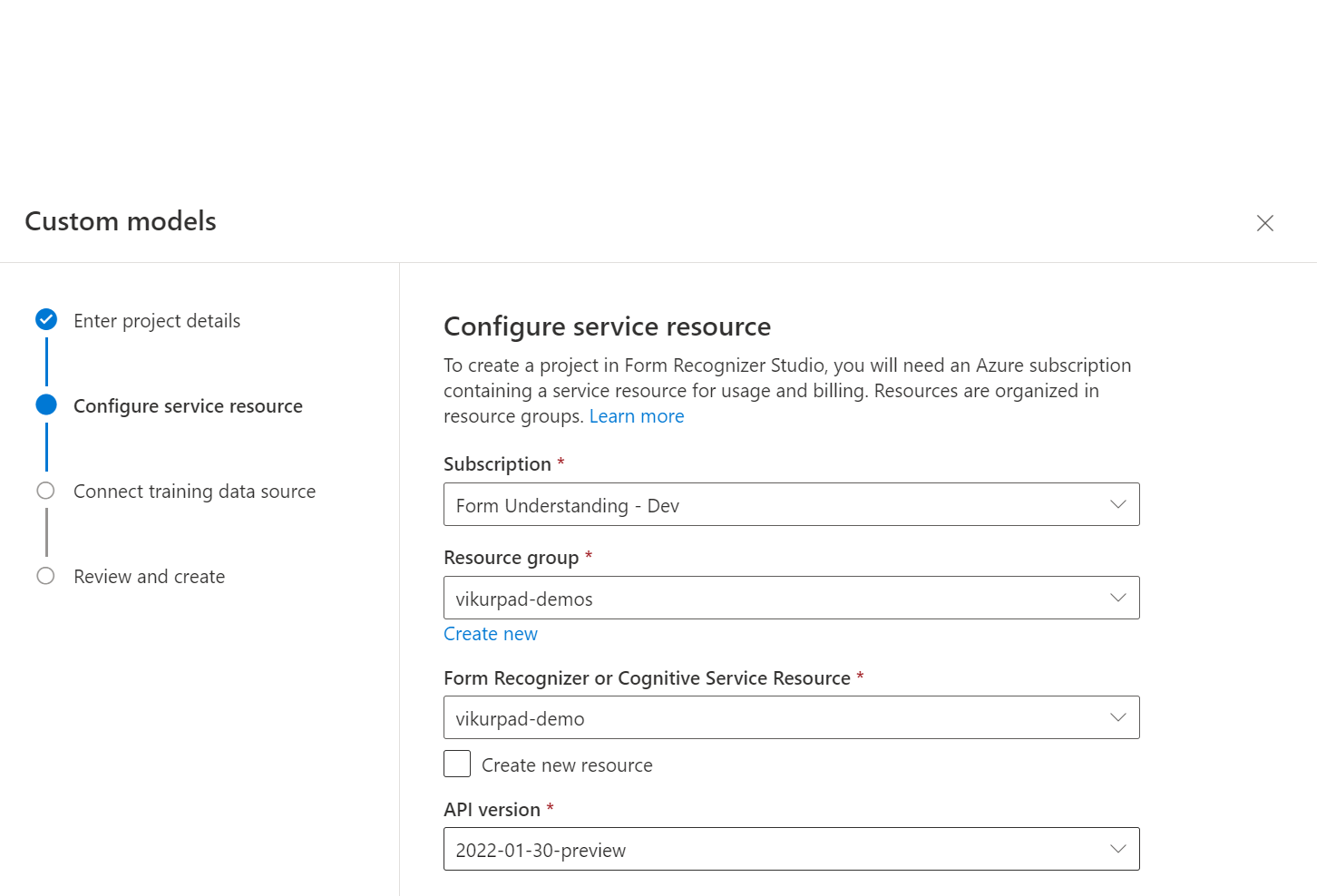
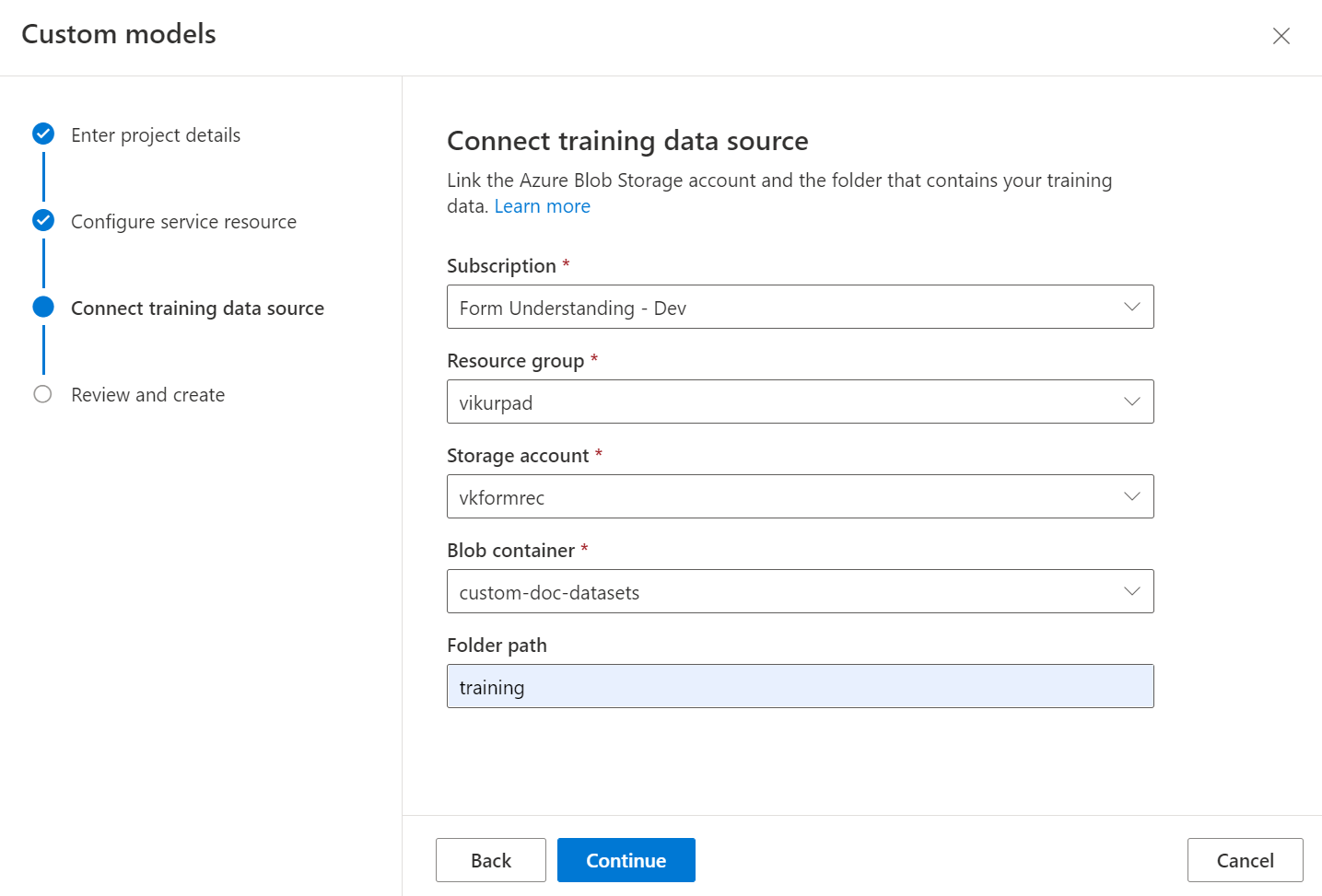
Selanjutnya pilih akun penyimpanan yang Anda gunakan untuk mengunggah himpunan data pelatihan model kustom Anda. Jalur Folder harus kosong jika dokumen pelatihan Anda berada di akar kontainer. Jika dokumen Anda berada di subfolder, masukkan jalur relatif dari akar kontainer di bidang Jalur folder. Setelah akun penyimpanan Anda dikonfigurasi, pilih lanjutkan.
Penting
Anda dapat mengatur himpunan data pelatihan menurut folder tempat nama folder adalah label atau kelas untuk dokumen atau membuat daftar datar dokumen yang dapat Anda tetapkan labelnya di Studio.
Melatih pengklasifikasi kustom memerlukan output dari model Tata Letak untuk setiap dokumen dalam himpunan data Anda. Jalankan tata letak pada semua dokumen sebelum proses pelatihan model.
Terakhir, tinjau pengaturan proyek Anda dan pilih Create Project untuk membuat proyek baru. Anda saat ini seharusnya berada di jendela pelabelan dan melihat file dalam himpunan data Anda telah tercantum.
Memberi label pada data Anda
Dalam proyek, Anda hanya perlu memberi label setiap dokumen dengan label kelas yang sesuai.

Anda melihat file yang Anda unggah ke penyimpanan dalam daftar file, siap untuk diberi label. Anda memiliki beberapa opsi untuk memberi label himpunan data Anda.
Jika dokumen diatur dalam folder, Studio akan meminta Anda untuk menggunakan nama folder sebagai label. Langkah ini menyederhanakan pelabelan Anda ke satu pilihan.
Untuk menetapkan label ke dokumen, pilih pada tanda tambahkan pilihan label untuk menetapkan label.
Kontrol pilih untuk memilih beberapa dokumen untuk menetapkan label
Anda sekarang harus memiliki semua dokumen dalam himpunan data Anda berlabel. Jika Anda melihat akun penyimpanan, Anda menemukan file .ocr.json yang sesuai dengan setiap dokumen dalam himpunan data pelatihan Anda dan file class-name.jsonl baru untuk setiap kelas berlabel. Himpunan data pelatihan ini dikirimkan untuk melatih model.
Melatih model
Dengan label himpunan data Anda, Anda sekarang siap untuk melatih model Anda. Pilih tombol Train di sudut kanan atas.
Pada dialog model pelatihan, berikan ID pengklasifikasi unik dan, secara opsional, deskripsi. ID pengklasifikasi menerima jenis data string.
Pilih Train untuk memulai proses pelatihan.
Model pengklasifikasi dilatih dalam beberapa menit.
Navigasikan ke menu Model untuk melihat status pengoperasian pelatihan.
Menguji model
Setelah pelatihan model selesai, Anda dapat menguji model Anda dengan memilih model pada halaman daftar model.
Pilih model dan pilih pada tombol Test.
Tambahkan file baru dengan menelusuri file atau menjatuhkan file ke pemilih dokumen.
Dengan file yang telah terpilih, pilih tombol Analyze untuk menguji model.
Hasil model ditampilkan dengan daftar dokumen yang diidentifikasi, skor keyakinan untuk setiap dokumen yang diidentifikasi dan rentang halaman untuk setiap dokumen yang diidentifikasi.
Validasi model Anda dengan mengevaluasi hasil untuk setiap dokumen yang diidentifikasi.
Melatih pengklasifikasi kustom menggunakan SDK atau API
Studio mengatur panggilan API bagi Anda untuk melatih pengklasifikasi kustom. Himpunan data pelatihan pengklasifikasi memerlukan output dari API tata letak yang cocok dengan versi API untuk model pelatihan Anda. Menggunakan hasil tata letak dari versi API yang lebih lama dapat menghasilkan model dengan akurasi yang lebih rendah.
Studio menghasilkan hasil tata letak untuk himpunan data pelatihan Anda jika himpunan data tidak berisi hasil tata letak. Saat menggunakan API atau SDK untuk melatih pengklasifikasi, Anda perlu menambahkan hasil tata letak ke folder yang berisi dokumen individual. Hasil tata letak harus dalam format respons API saat memanggil tata letak secara langsung. Model objek SDK berbeda, pastikan bahwa layout results adalah hasil API dan bukan SDK response.
Pecahkan masalah
Model klasifikasi memerlukan hasil dari model tata letak untuk setiap dokumen pelatihan. Jika Anda tidak memberikan hasil tata letak, Studio mencoba menjalankan model tata letak untuk setiap dokumen sebelum melatih pengklasifikasi. Proses ini dibatasi dan dapat menghasilkan respons 429.
Di Studio, sebelum pelatihan dengan model klasifikasi, jalankan model tata letak pada setiap dokumen dan unggah ke lokasi yang sama dengan dokumen asli. Setelah hasil tata letak ditambahkan, Anda dapat melatih model pengklasifikasi dengan dokumen Anda.