Membangun dan melatih model ekstraksi kustom
Konten ini berlaku untuk:![]() v4.0 (pratinjau) | Versi sebelumnya:
v4.0 (pratinjau) | Versi sebelumnya:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1
v2.1
Model Kecerdasan Dokumen memerlukan sekitar lima dokumen pelatihan untuk memulai. Jika Anda memiliki setidaknya lima dokumen, Anda dapat mulai melatih model khusus. Anda dapat melatih model templat kustom (formulir kustom) atau model neural kustom (dokumen kustom). Proses pelatihan identik untuk kedua model dan dokumen ini memandu Anda melalui proses pelatihan salah satu model.
Persyaratan masukan model kustom
Pertama, pastikan himpunan data pelatihan Anda mengikuti persyaratan input untuk Kecerdasan Dokumen.
Untuk hasil terbaik, berikan satu foto yang jelas atau pemindaian berkualitas tinggi per dokumen.
Format file yang didukung:
Model PDF Gambar:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), dan HTMLRead ✔ ✔ ✔ Tata letak ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Dokumen Umum ✔ ✔ Bawaan ✔ ✔ Ekstraksi kustom ✔ ✔ Klasifikasi kustom ✔ ✔ ✔ (Pratinjau 2024-02-29) Untuk PDF dan TIFF, hingga 2000 halaman yang dapat diproses (dengan langganan tingkat gratis, hanya dua halaman pertama yang diproses).
Ukuran file untuk menganalisis dokumen adalah 500 MB untuk tingkat berbayar (S0) dan 4 MB secara gratis (F0).
Dimensi gambar harus antara 50 x 50 piksel dan 10.000 piksel x 10.000 piksel.
Jika PDF Anda dikunci dengan kata sandi, Anda harus menghapus kunci sebelum pengiriman.
Tinggi minimum teks yang akan diekstrak adalah 12 piksel untuk gambar piksel 1024 x 768. Dimensi ini sesuai dengan teks sekitar
8-point pada 150 titik per inci (DPI).Untuk pelatihan model kustom, jumlah maksimum halaman untuk data pelatihan adalah 500 untuk model template kustom dan 50.000 untuk model neural kustom.
Untuk pelatihan model ekstraksi kustom, ukuran total data pelatihan adalah 50 MB untuk model templat dan 1G-MB untuk model neural.
Untuk pelatihan model klasifikasi kustom, ukuran total data pelatihan adalah
1GBdengan maksimum 10.000 halaman.
Tips data pelatihan
Ikuti tips berikut ini untuk lebih mengoptimalkan himpunan data Anda untuk pelatihan:
- Gunakan dokumen PDF berbasis teks alih-alih dokumen berbasis gambar. PDF yang dipindai ditangani sebagai gambar.
- Gunakan contoh yang memiliki semua bidang yang diselesaikan untuk formulir dengan bidang input.
- Gunakan formulir dengan nilai berbeda di setiap bidang.
- Gunakan himpunan data yang lebih besar (10-15 gambar) jika gambar formulir Anda berkualitas lebih rendah.
Mengunggah data pelatihan Anda
Setelah mengumpulkan sekumpulan formulir atau dokumen untuk pelatihan, Anda perlu mengunggahnya ke kontainer penyimpanan blob Azure. Jika Anda tidak tahu cara membuat akun penyimpanan Azure dengan kontainer, ikuti panduan mulai cepat Azure Storage untuk portal Azure. Untuk mencoba layanan, Anda dapat menggunakan tingkat harga gratis (F0), lalu meningkatkannya ke tingkat berbayar untuk produksi.
Video: Melatih model kustom Anda
- Setelah mengumpulkan dan mengunggah himpunan data pelatihan, Anda siap untuk melatih model kustom Anda. Dalam video berikut, kami membuat proyek dan menjelajahi beberapa dasar untuk berhasil memberi label dan melatih model.
Membuat proyek di Studio Kecerdasan Dokumen
Studio Kecerdasan Dokumen menyediakan dan mengatur semua panggilan API yang diperlukan untuk menyelesaikan himpunan data Anda dan melatih model Anda.
Mulailah dengan menavigasi ke Studio Kecerdasan Dokumen. Saat pertama kali menggunakan Studio, Anda perlu menginisialisasi langganan, grup sumber daya, dan sumber daya Anda. Kemudian, ikuti prasyarat untuk proyek kustom untuk mengonfigurasi Studio untuk mengakses himpunan data pelatihan Anda.
Di Studio, pilih petak Model kustom, di halaman model kustom dan pilih tombol Buat proyek.

Pada dialog buat proyek, berikan nama untuk proyek Anda, secara opsional sebuah deskripsi, dan pilih lanjutkan.
Pada langkah berikutnya dalam alur kerja, pilih atau buat sumber daya Kecerdasan Dokumen sebelum Anda memilih lanjutkan.
Penting
Model neural kustom hanya tersedia di beberapa wilayah. Jika Anda berencana untuk melatih model neural, silakan pilih atau buat sumber daya di salah satu wilayah yang didukung ini.
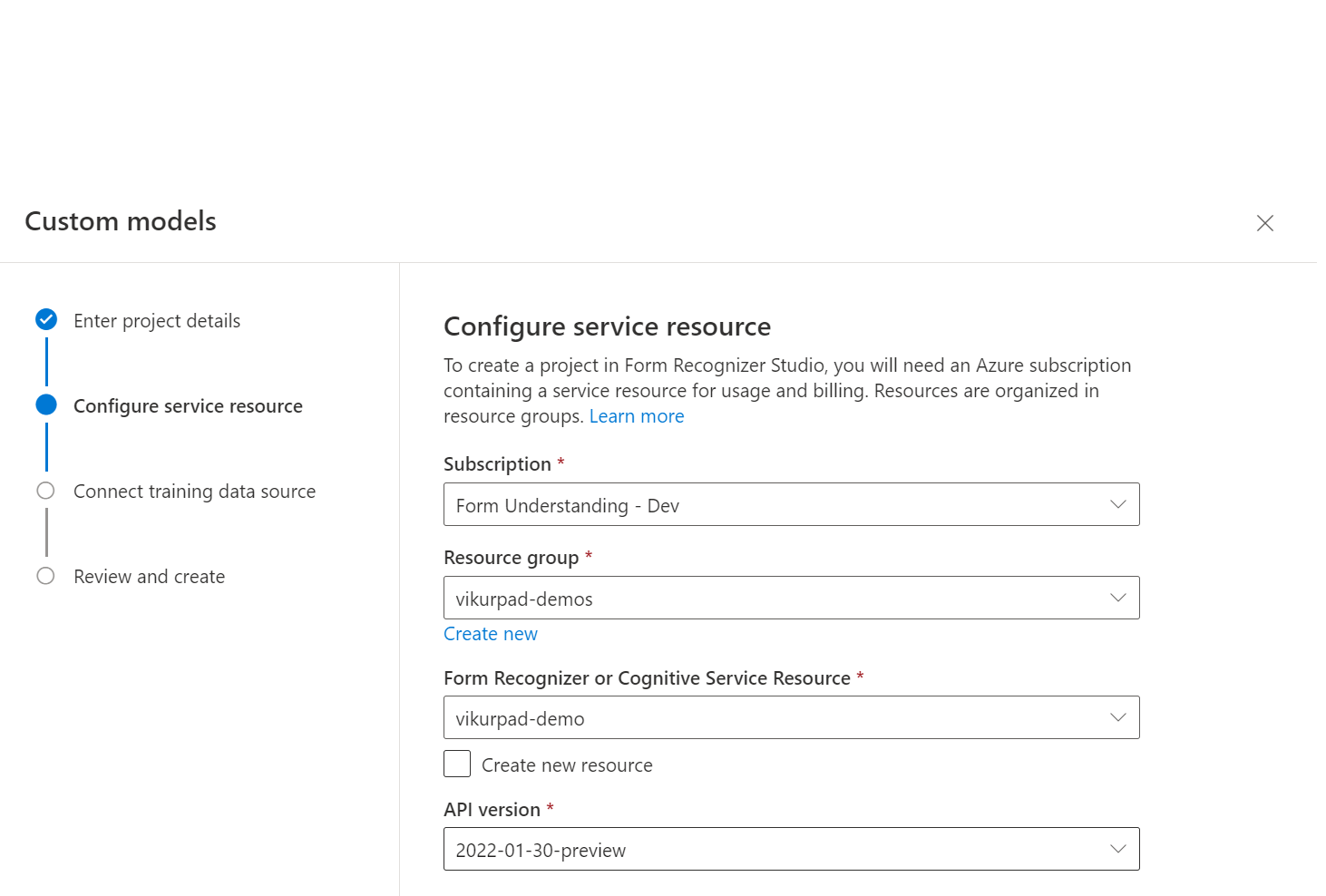
Selanjutnya pilih akun penyimpanan yang Anda gunakan untuk mengunggah himpunan data pelatihan model kustom Anda. Jalur Folder harus kosong jika dokumen pelatihan Anda berada di akar kontainer. Jika dokumen Anda berada di subfolder, masukkan jalur relatif dari akar kontainer di bidang Jalur folder. Setelah akun penyimpanan Anda dikonfigurasi, pilih lanjutkan.
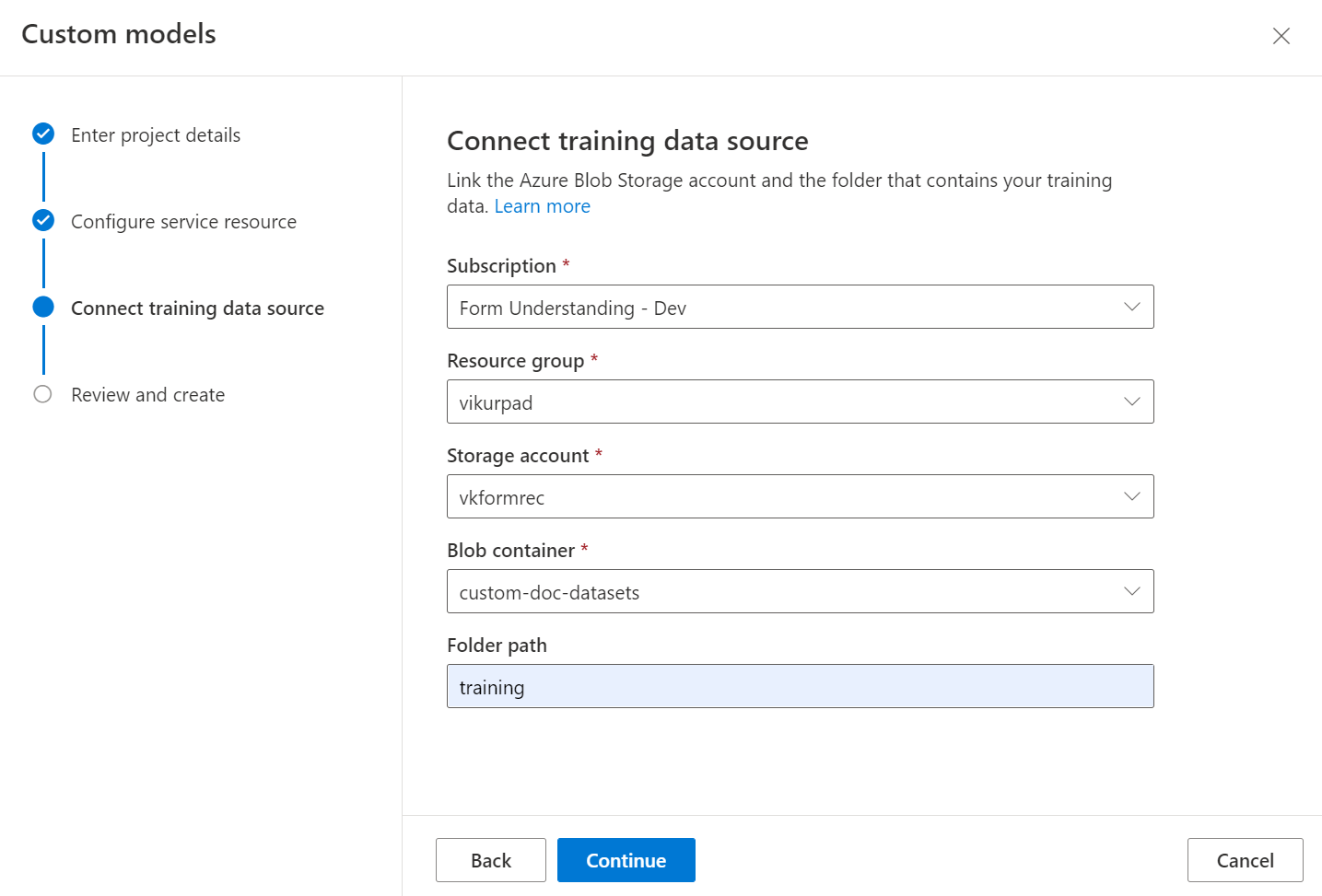
Terakhir, tinjau pengaturan proyek Anda dan pilih Create Project untuk membuat proyek baru. Anda saat ini seharusnya berada di jendela pelabelan dan melihat file dalam himpunan data Anda telah tercantum.
Memberi label pada data Anda
Dalam proyek Anda, tugas pertama Anda adalah memberi label himpunan data Anda dengan bidang yang ingin Anda ekstrak.
File yang Anda unggah ke penyimpanan tercantum di sebelah kiri layar Anda, dengan file pertama siap untuk diberi label.
Mulai pelabelan himpunan data Anda dan buat bidang pertama Anda dengan memilih tombol plus (➕) di kanan atas layar.
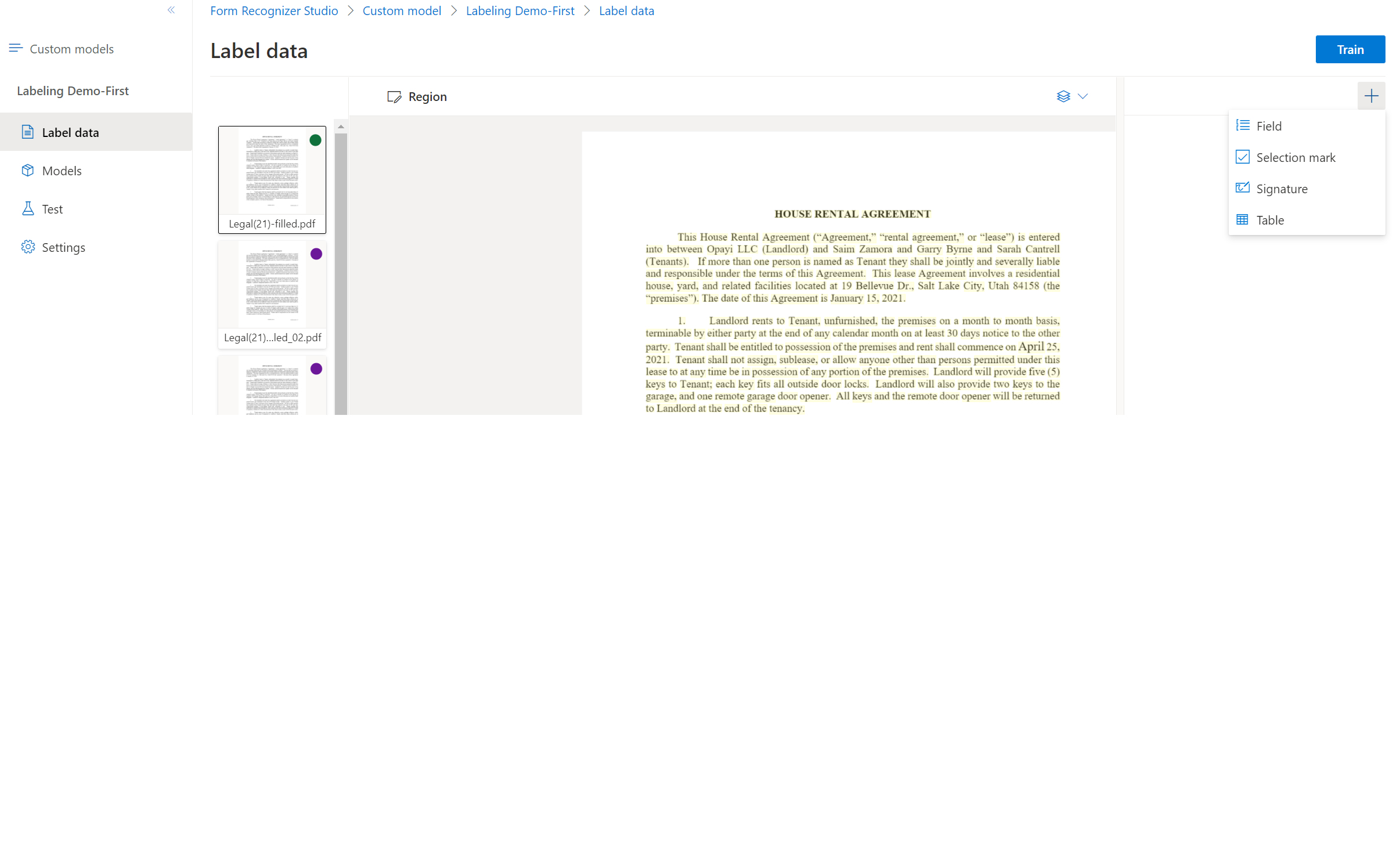
Masukkan nama untuk bidang.
Tetapkan nilai ke bidang dengan memilih kata atau kata dalam dokumen. Pilih bidang di menu dropdown atau daftar bidang di bilah navigasi kanan. Nilai berlabel berada di bawah nama bidang dalam daftar bidang.
Ulangi proses untuk semua bidang yang ingin Anda beri label untuk himpunan data Anda.
Beri label dokumen yang tersisa dalam himpunan data Anda dengan memilih setiap dokumen dan memilih teks yang akan diberi label.
Anda sekarang memiliki semua dokumen yang ada di himpunan data Anda telah berlabel. File .labels.json dan .ocr.json sesuai dengan setiap dokumen dalam himpunan data pelatihan Anda dan file fields.json baru. Himpunan data pelatihan ini dikirimkan untuk melatih model.
Melatih model
Dengan label himpunan data Anda, Anda sekarang siap untuk melatih model Anda. Pilih tombol Train di sudut kanan atas.
Pada dialog model pelatihan, berikan ID model unik dan, secara opsional, deskripsinya. ID model menerima tipe data string.
Untuk mode build, pilih jenis model yang ingin Anda latih. Pelajari lebih lanjut jenis dan kemampuan model.
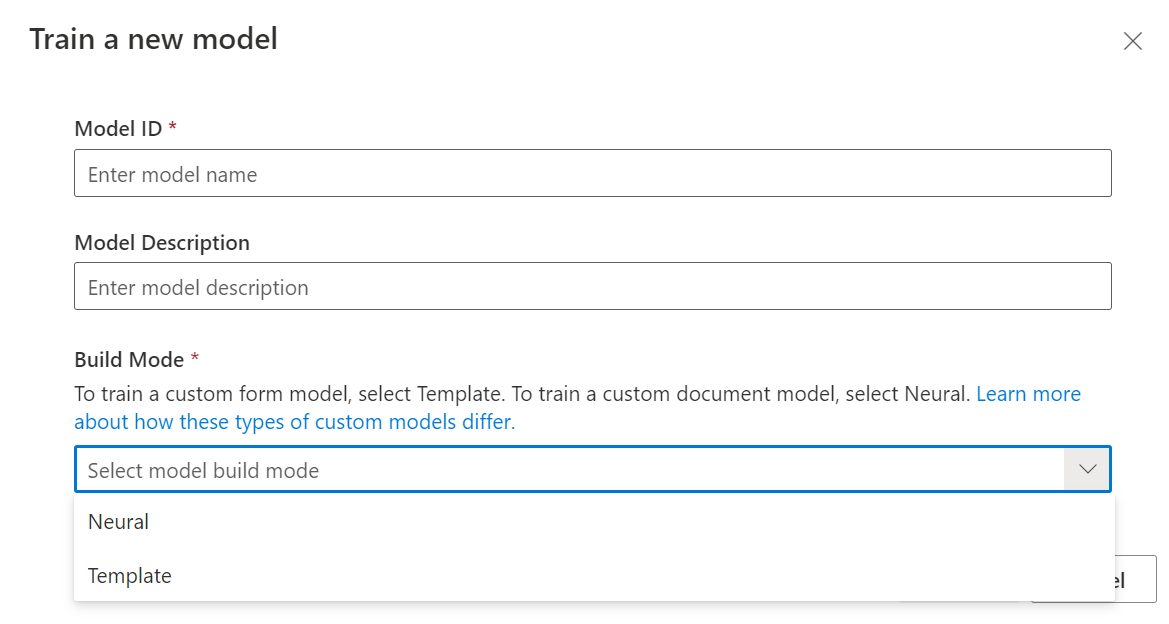
Pilih Train untuk memulai proses pelatihan.
Model templat akan dilatih dalam beberapa menit. Model neural dapat memakan waktu hingga 30 menit untuk dilatih.
Navigasikan ke menu Model untuk melihat status pengoperasian pelatihan.
Menguji model
Setelah pelatihan model selesai, Anda dapat menguji model Anda dengan memilih model pada halaman daftar model.
Pilih model dan pilih pada tombol Test.
Pilih tombol
+ Adduntuk memilih file untuk menguji model tersebut.Dengan file yang telah terpilih, pilih tombol Analyze untuk menguji model.
Hasil model akan ditampilkan di jendela utama dan bidang yang diekstraksi tercantum di bilah navigasi kanan.
Validasi model Anda dengan mengevaluasi hasil untuk setiap bidang.
Bilah kanan navigasi juga memiliki kode sampel untuk meminta model Anda dan hasil JSON dari API.
Selamat anda belajar untuk melatih model kustom di Document Intelligence Studio! Model Anda siap digunakan dengan REST API atau SDK untuk menganalisis dokumen.
Berlaku untuk:![]() v2.1. Versi lain:v3.0
v2.1. Versi lain:v3.0
Saat Anda menggunakan model kustom Kecerdasan Dokumen, Anda menyediakan data pelatihan Anda sendiri ke operasi Latih Model Kustom, sehingga model dapat melatih ke formulir khusus industri Anda. Ikuti panduan ini untuk mempelajari cara mengumpulkan dan menyiapkan data untuk melatih model secara efektif.
Anda memerlukan setidaknya lima formulir lengkap dengan jenis yang sama.
Jika Anda ingin menggunakan data pelatihan berlabel manual, Anda harus memulai dengan setidaknya lima formulir lengkap dengan jenis yang sama. Anda masih dapat menggunakan formulir yang tidak berlabel selain kumpulan data yang diperlukan.
Persyaratan masukan model kustom
Pertama, pastikan himpunan data pelatihan Anda mengikuti persyaratan input untuk Kecerdasan Dokumen.
Untuk hasil terbaik, berikan satu foto yang jelas atau pemindaian berkualitas tinggi per dokumen.
Format file yang didukung:
Model PDF Gambar:
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), dan HTMLRead ✔ ✔ ✔ Tata letak ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Dokumen Umum ✔ ✔ Bawaan ✔ ✔ Ekstraksi kustom ✔ ✔ Klasifikasi kustom ✔ ✔ ✔ (Pratinjau 2024-02-29) Untuk PDF dan TIFF, hingga 2000 halaman yang dapat diproses (dengan langganan tingkat gratis, hanya dua halaman pertama yang diproses).
Ukuran file untuk menganalisis dokumen adalah 500 MB untuk tingkat berbayar (S0) dan 4 MB secara gratis (F0).
Dimensi gambar harus antara 50 x 50 piksel dan 10.000 piksel x 10.000 piksel.
Jika PDF Anda dikunci dengan kata sandi, Anda harus menghapus kunci sebelum pengiriman.
Tinggi minimum teks yang akan diekstrak adalah 12 piksel untuk gambar piksel 1024 x 768. Dimensi ini sesuai dengan teks sekitar
8-point pada 150 titik per inci (DPI).Untuk pelatihan model kustom, jumlah maksimum halaman untuk data pelatihan adalah 500 untuk model template kustom dan 50.000 untuk model neural kustom.
Untuk pelatihan model ekstraksi kustom, ukuran total data pelatihan adalah 50 MB untuk model templat dan 1G-MB untuk model neural.
Untuk pelatihan model klasifikasi kustom, ukuran total data pelatihan adalah
1GBdengan maksimum 10.000 halaman.
Tips data pelatihan
Ikuti tips ini untuk mengoptimalkan himpunan data Anda lebih lanjut untuk pelatihan.
- Gunakan dokumen PDF berbasis teks alih-alih dokumen berbasis gambar. PDF yang dipindai ditangani sebagai gambar.
- Gunakan contoh yang memiliki semua bidang yang diisi untuk formulir yang telah selesai.
- Gunakan formulir dengan nilai berbeda di setiap bidang.
- Gunakan himpunan data yang lebih besar (10-15 gambar) untuk formulir yang sudah selesai.
Mengunggah data pelatihan Anda
Setelah mengumpulkan kumpulan dokumen untuk pelatihan, Anda perlu mengunggahnya ke kontainer penyimpanan blob Azure. Jika Anda tidak tahu cara membuat akun penyimpanan Azure dengan kontainer, ikuti panduan mulai cepat Azure Storage untuk portal Azure. Gunakan tingkat performa standar.
Jika Anda ingin menggunakan data berlabel manual, unggah file .labels.json dan .ocr.json yang sesuai dengan dokumen pelatihan Anda. Anda dapat menggunakan alat Sample Labeling (atau UI Anda sendiri) untuk menghasilkan file-file ini.
Atur data Anda dalam subfolder (opsional)
Secara default, API Latih Model Kustom hanya menggunakan dokumen yang terletak di akar kontainer penyimpanan Anda. Namun, Anda dapat berlatih dengan data dalam subfolder jika Anda menentukannya dalam panggilan API. Biasanya, isi panggilan Train Custom Model memiliki format berikut, dengan <SAS URL> adalah URL tanda tangan akses bersama dari kontainer Anda:
{
"source":"<SAS URL>"
}
Jika Anda menambahkan konten berikut ke isi permintaan, API akan melatih dengan dokumen yang terletak di subfolder. Bidang "prefix" bersifat opsional dan membatasi himpunan data pelatihan ke file yang jalurnya dimulai dengan string yang diberikan. Jadi nilai "Test", misalnya, menyebabkan API hanya melihat file atau folder yang dimulai dengan kata Uji.
{
"source": "<SAS URL>",
"sourceFilter": {
"prefix": "<prefix string>",
"includeSubFolders": true
},
"useLabelFile": false
}
Langkah berikutnya
Sekarang setelah Anda mempelajari cara membuat himpunan data pelatihan, ikuti mulai cepat untuk melatih model Kecerdasan Dokumen kustom dan mulai menggunakannya di formulir Anda.