Ide solusi
Artikel ini menjelaskan ide solusi. Arsitek cloud Anda dapat menggunakan panduan ini untuk membantu memvisualisasikan komponen utama untuk implementasi umum arsitektur ini. Gunakan artikel ini sebagai titik awal untuk merancang solusi yang dirancang dengan baik yang selaras dengan persyaratan spesifik beban kerja Anda.
Menerapkan solusi pemrosesan bahasa alami kustom (NLP) di Azure. Gunakan Spark NLP untuk tugas seperti topik dan deteksi dan analisis sentimen.
Apache®, Apache Spark, dan logo api adalah merek dagang terdaftar atau merek dagang Dari Apache Software Foundation di Amerika Serikat dan/atau negara lain. Tidak ada dukungan oleh The Apache Software Foundation yang tersirat oleh penggunaan tanda ini.
Sistem

Unduh file Visio arsitektur ini.
Alur kerja
- Azure Event Hubs, Azure Data Factory, atau kedua layanan menerima dokumen atau data teks yang tidak terstruktur.
- Azure Event Hubs dan Data Factory menyimpan data dalam format file di Azure Data Lake Storage. Kami menyarankan agar Anda menyiapkan struktur direktori yang mematuhi persyaratan bisnis.
- Azure Computer Vision API menggunakan kemampuan pengenalan karakter optik (OCR) untuk mengonsumsi data. API kemudian menulis data ke lapisan perunggu. Platform konsumsi ini menggunakan arsitektur lakehouse.
- Di lapisan perunggu, berbagai fitur Spark NLP telah memproses teks. Contohnya termasuk memisahkan, mengoreksi ejaan, membersihkan, dan memahami tata bahasa. Sebaiknya jalankan klasifikasi dokumen di lapisan perunggu lalu tulis hasilnya ke lapisan perak.
- Di lapisan perak, fitur NLP Spark tingkat lanjut melakukan tugas analisis dokumen seperti pengenalan entitas bernama, ringkasan, dan pengambilan informasi. Dalam beberapa arsitektur, hasilnya ditulis ke lapisan emas.
- Di lapisan emas, Spark NLP menjalankan berbagai analisis visual linguistik pada data teks. Analisis ini memberikan wawasan tentang dependensi bahasa dan membantu visualisasi label NER.
- Pengguna mengkueri data teks lapisan emas sebagai bingkai data dan menampilkan hasilnya di Power BI atau aplikasi web.
Selama langkah-langkah pemrosesan, Azure Databricks, Azure Synapse Analytics, dan Azure HDInsight digunakan dengan Spark NLP untuk menyediakan fungsionalitas NLP.
Komponen
- Data Lake Storage adalah sistem file yang kompatibel dengan Hadoop yang memiliki namespace hierarkis terintegrasi dan skala besar dan ekonomi Azure Blob Storage.
- Azure Synapse Analytics adalah layanan analitik untuk gudang data dan sistem big data.
- Azure Databricks adalah layanan analitik untuk big data yang mudah digunakan, memfasilitasi kolaborasi, dan didasarkan pada Apache Spark. Azure Databricks dirancang untuk ilmu data dan rekayasa data.
- Azure Event Hubs menyerap aliran data yang dihasilkan aplikasi klien. Azure Event Hubs menyimpan data streaming dan mempertahankan urutan peristiwa yang diterima. Konsumen dapat terhubung ke titik akhir hub untuk mengambil pesan untuk diproses. Azure Event Hubs terintegrasi dengan Data Lake Storage, seperti yang ditunjukkan solusi ini.
- Azure HDInsight adalah layanan analitik sumber terbuka dengan spektrum penuh yang terkelola di cloud untuk perusahaan. Anda dapat menggunakan kerangka kerja sumber terbuka dengan Azure HDInsight, seperti Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Storm, dan R.
- Data Factory secara otomatis memindahkan data antara akun penyimpanan dengan tingkat keamanan yang berbeda untuk memastikan pemisahan tugas.
- Computer Vision menggunakan API pengenalan teks untuk mengenali teks dalam gambar dan mengekstrak informasi tersebut. API Baca menggunakan model pengenalan terbaru, dan dioptimalkan untuk dokumen besar dan teks-berat dan gambar berisik. API OCR tidak dioptimalkan untuk dokumen besar tetapi mendukung lebih banyak bahasa daripada API Baca. Solusi ini menggunakan OCR untuk menghasilkan data dalam format hOCR .
Detail skenario
Pemrosesan bahasa alami (NLP) memiliki banyak kegunaan: analisis sentimen, deteksi topik, deteksi bahasa, ekstraksi frasa kunci, dan kategorisasi dokumen.
Apache Spark adalah kerangka kerja pemrosesan paralel yang mendukung pemrosesan dalam memori untuk meningkatkan performa aplikasi analitik big data seperti NLP. Azure Synapse Analytics, Azure HDInsight, dan Azure Databricks menawarkan akses ke Spark dan memanfaatkan daya pemrosesannya.
Untuk beban kerja NLP yang disesuaikan, pustaka sumber terbuka Spark NLP berfungsi sebagai kerangka kerja yang efisien untuk memproses sejumlah besar teks. Artikel ini menyajikan solusi untuk NLP kustom skala besar di Azure. Solusi ini menggunakan fitur NLP Spark untuk memproses dan menganalisis teks. Untuk informasi selengkapnya tentang Spark NLP, lihat Fungsionalitas dan alur NLP Spark, nanti di artikel ini.
Kemungkinan kasus penggunaan
Klasifikasi dokumen: Spark NLP menawarkan beberapa opsi untuk klasifikasi teks:
- Pra-pemrosesan teks dalam NLP Spark dan algoritma pembelajaran mesin yang didasarkan pada Spark ML
- Pra-pemrosesan teks dan penyematan kata dalam NLP Spark dan algoritma pembelajaran mesin seperti GloVe, BERT, dan ELMo
- Pra-pemrosesan teks dan penyematan kalimat di Spark NLP dan algoritma dan model pembelajaran mesin seperti Universal Sentence Encoder
- Pra-pemrosesan dan klasifikasi teks di Spark NLP yang menggunakan anotator ClassifierDL dan didasarkan pada TensorFlow
Ekstraksi entitas nama (NER): Di Spark NLP, dengan beberapa baris kode, Anda dapat melatih model NER yang menggunakan BERT, dan Anda dapat mencapai akurasi canggih. NER adalah subtugas ekstraksi informasi. NER menemukan entitas bernama dalam teks yang tidak terstruktur dan mengklasifikasikannya ke dalam kategori yang telah ditentukan sebelumnya seperti nama orang, organisasi, lokasi, kode medis, ekspresi waktu, jumlah, nilai moneter, dan persentase. Spark NLP menggunakan model NER canggih dengan BERT. Model ini terinspirasi oleh model NER sebelumnya, LSTM-CNN dua arah. Model sebelumnya menggunakan arsitektur jaringan neural baru yang secara otomatis mendeteksi fitur tingkat kata dan tingkat karakter. Untuk tujuan ini, model menggunakan arsitektur LSTM dan CNN dua arah hibrid, sehingga menghilangkan kebutuhan akan sebagian besar rekayasa fitur.
Deteksi sentimen dan emosi: Spark NLP dapat secara otomatis mendeteksi aspek positif, negatif, dan netral bahasa.
Bagian dari ucapan (POS): Fungsionalitas ini menetapkan label tata bahasa ke setiap token dalam teks input.
Deteksi kalimat (SD): SD didasarkan pada model jaringan neural tujuan umum untuk deteksi batas kalimat yang mengidentifikasi kalimat dalam teks. Banyak tugas NLP mengambil kalimat sebagai unit input. Contoh tugas-tugas ini termasuk pemberian tag POS, penguraian dependensi, pengenalan entitas bernama, dan terjemahan mesin.
Fungsionalitas dan alur Spark NLP
Spark NLP menyediakan pustaka Python, Java, dan Scala yang menawarkan fungsionalitas penuh pustaka NLP tradisional seperti spaSi, NLTK, Stanford CoreNLP, dan Open NLP. Spark NLP juga menawarkan fungsionalitas seperti pemeriksaan ejaan, analisis sentimen, dan klasifikasi dokumen. Spark NLP meningkatkan upaya sebelumnya dengan memberikan akurasi, kecepatan, dan skalabilitas yang canggih.
Spark NLP sejauh ini adalah pustaka NLP sumber terbuka tercepat. Tolok ukur publik terbaru menunjukkan Spark NLP sebagai 38 dan 80 kali lebih cepat daripada spaSi, dengan akurasi yang sebanding untuk melatih model kustom. Spark NLP adalah satu-satunya pustaka sumber terbuka yang dapat menggunakan kluster Spark terdistribusi. Spark NLP adalah ekstensi asli dari Spark ML yang beroperasi langsung pada bingkai data. Akibatnya, speedup pada kluster menghasilkan urutan lain dari besarnya perolehan performa. Karena setiap alur Spark NLP adalah alur Spark ML, Spark NLP sangat cocok untuk membangun NLP terpadu dan alur pembelajaran mesin seperti klasifikasi dokumen, prediksi risiko, dan alur pemberi rekomendasi.
Selain performa yang sangat baik, Spark NLP juga memberikan akurasi state-of-the-art untuk semakin banyak tugas NLP. Tim Spark NLP secara teratur membaca makalah akademik terbaru yang relevan dan menghasilkan model yang paling akurat.
Untuk urutan eksekusi alur NLP, Spark NLP mengikuti konsep pengembangan yang sama dengan model pembelajaran mesin Spark tradisional. Tetapi Spark NLP menerapkan teknik NLP. Diagram berikut menunjukkan komponen inti dari alur NLP Spark.
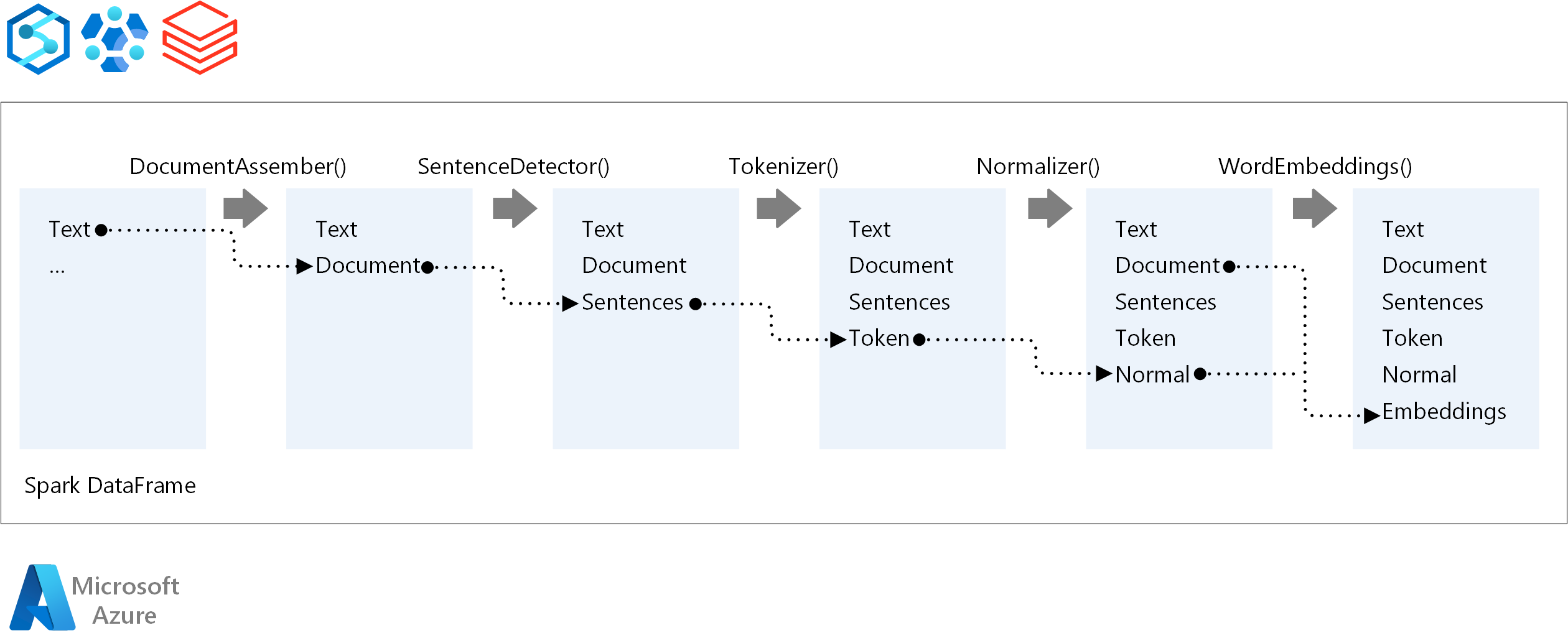
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Moritz Steller | Arsitek Solusi Cloud Senior
Langkah berikutnya
Dokumentasi Spark NLP:
Komponen Azure: