Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Azure Databricks adalah platform analitik terbuka terpadu untuk membangun, menyebarkan, berbagi, dan memelihara data, analitik, dan solusi AI tingkat perusahaan dalam skala besar. Platform Data Intelligence Databricks terintegrasi dengan penyimpanan dan keamanan cloud di akun cloud Anda, serta mengelola dan menyebarkan infrastruktur cloud untuk Anda.
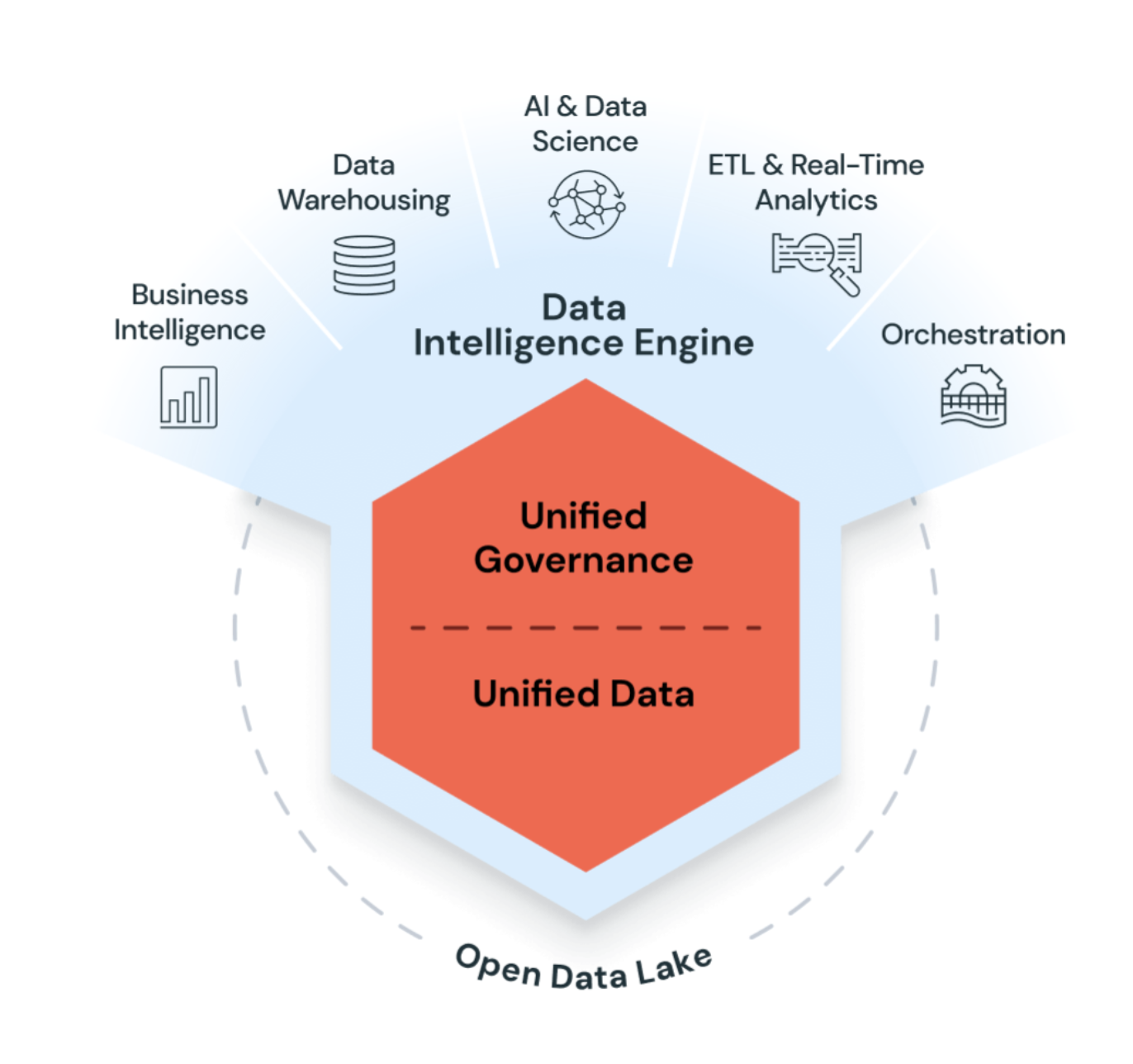
Azure Databricks menggunakan AI generatif dengan data lakehouse untuk memahami semantik unik data Anda. Kemudian, secara otomatis mengoptimalkan performa dan mengelola infrastruktur agar sesuai dengan kebutuhan bisnis Anda.
Pemrosesan bahasa alami mempelajari bahasa bisnis Anda, sehingga Anda dapat mencari dan menemukan data dengan mengajukan pertanyaan dengan kata-kata Anda sendiri. Bantuan bahasa alami membantu Anda menulis kode, memecahkan masalah kesalahan, dan menemukan jawaban dalam dokumentasi.
Integrasi sumber terbuka terkelola
Databricks berkomitmen untuk komunitas sumber terbuka dan mengelola pembaruan integrasi sumber terbuka dengan rilis Databricks Runtime. Teknologi berikut adalah sumber terbuka proyek yang awalnya dibuat oleh karyawan Databricks:
Kasus penggunaan umum
Kasus penggunaan berikut menyoroti beberapa cara pelanggan menggunakan Azure Databricks untuk menyelesaikan tugas yang penting untuk memproses, menyimpan, dan menganalisis data yang mendorong fungsi dan keputusan bisnis penting.
Membangun lakehouse untuk data perusahaan
Data lakehouse menggabungkan gudang data perusahaan dan data lake untuk mempercepat, menyederhanakan, dan menyatukan solusi data perusahaan. Teknisi data, ilmuwan data, analis, dan sistem produksi semuanya dapat menggunakan data lakehouse sebagai sumber kebenaran tunggal mereka, memberikan akses ke data yang konsisten dan mengurangi kompleksitas membangun, memelihara, dan menyinkronkan banyak sistem data terdistribusi. Lihat Apa itu data lakehouse?.
ETL dan rekayasa data
Baik Anda membuat dasbor atau mendukung aplikasi kecerdasan buatan, rekayasa data menyediakan tulang punggung untuk perusahaan yang ber sentris data dengan memastikan data tersedia, bersih, dan disimpan dalam model data untuk penemuan dan penggunaan yang efisien. Azure Databricks menggabungkan kekuatan Apache Spark dengan Delta dan alat kustom untuk memberikan pengalaman ETL yang tidak tertandingi. Gunakan SQL, Python, dan Scala untuk menyusun logika ETL dan mengatur penyebaran pekerjaan terjadwal dengan beberapa klik.
Lakeflow Declarative Pipelines lebih menyederhanakan ETL dengan secara cerdas mengelola dependensi antara himpunan data dan secara otomatis menyebarkan dan menskalakan infrastruktur produksi untuk memastikan pengiriman data yang tepat waktu dan akurat sesuai spesifikasi Anda.
Azure Databricks menyediakan alat untuk penyerapan data, termasuk Auto Loader, alat yang efisien dan dapat diskalakan untuk memuat data secara bertingkat dan idempoten dari penyimpanan objek di cloud dan data lake ke dalam data lakehouse.
Pembelajaran mesin, AI, dan ilmu data
Pembelajaran mesin Azure Databricks memperluas fungsionalitas inti platform dengan serangkaian alat yang disesuaikan dengan kebutuhan ilmuwan data dan insinyur ML, termasuk MLflow dan Databricks Runtime untuk Pembelajaran Mesin.
Model bahasa besar dan AI generatif
Databricks Runtime for Machine Learning mencakup pustaka seperti Hugging Face Transformers yang memungkinkan Anda mengintegrasikan model yang sudah dilatih sebelumnya atau pustaka sumber terbuka lainnya ke dalam alur kerja Anda. Integrasi Databricks MLflow memudahkan penggunaan layanan pelacakan MLflow dengan alur transformator, model, dan komponen pemrosesan. Integrasikan model atau solusi OpenAI dari mitra seperti John Snow Labs dalam alur kerja Databricks Anda.
Dengan Azure Databricks, sesuaikan LLM berdasarkan data Anda untuk tugas yang spesifik. Dengan dukungan alat sumber terbuka, seperti Hugging Face dan DeepSpeed, Anda dapat secara efisien mengambil LLM fondasi dan memulai pelatihan dengan data Anda sendiri untuk lebih akurasi untuk domain dan beban kerja Anda.
Selain itu, Azure Databricks menyediakan fungsi AI yang dapat digunakan analis data SQL untuk mengakses model LLM, termasuk dari OpenAI, langsung dalam alur data dan alur kerja mereka. Lihat Menerapkan AI pada data menggunakan Azure Databricks AI Functions.
Pergudangan data, analitik, dan BI
Azure Databricks menggabungkan UI yang mudah digunakan dengan sumber daya komputasi hemat biaya dan penyimpanan yang terjangkau dan dapat diskalakan tanpa batas untuk menyediakan platform yang kuat untuk menjalankan kueri analitik. Administrator mengonfigurasi kluster komputasi yang dapat diskalakan sebagai gudang SQL, memungkinkan pengguna akhir untuk menjalankan kueri tanpa khawatir tentang salah satu kompleksitas bekerja di cloud. Pengguna SQL dapat menjalankan kueri terhadap data di lakehouse menggunakan editor kueri SQL atau di buku catatan. Notebooks mendukung Python, R, dan Scala selain SQL, dan memungkinkan pengguna untuk menyematkan visualisasi yang tersedia di dasbor lama bersama tautan, gambar, dan komentar yang ditulis dalam markdown.
Tata kelola data dan berbagi data yang aman
Unity Catalog menyediakan model tata kelola data terpadu untuk data lakehouse. Administrator cloud mengonfigurasi dan mengintegrasikan izin kontrol akses kasar untuk Unity Catalog, lalu administrator Azure Databricks dapat mengelola izin untuk tim dan individu. Hak istimewa dikelola dengan daftar kontrol akses (ACL) melalui UI yang mudah digunakan atau sintaks SQL, sehingga memudahkan administrator database untuk mengamankan akses ke data tanpa perlu menskalakan manajemen akses identitas cloud-native (IAM) dan jaringan.
Unity Catalog mempermudah menjalankan analitik aman di cloud dengan cara yang sederhana, dan menyediakan pembagian tanggung jawab yang membantu mengurangi kebutuhan akan reskilling atau upskilling untuk administrator dan pengguna akhir platform. Lihat Apa itu Katalog Unity?.
Lakehouse mempermudah berbagi data dalam organisasi Anda seperti memberikan akses kueri ke tabel atau tampilan. Untuk berbagi di luar lingkungan aman Anda, Unity Catalog menampilkan versi yang dikelola dari Berbagi Delta.
DevOps, CI/CD, dan orkestrasi tugas
Siklus hidup pengembangan untuk alur ETL, model ML, dan dasbor analitik masing-masing menyajikan tantangan unik mereka sendiri. Azure Databricks memungkinkan semua pengguna Anda memanfaatkan satu sumber data, yang mengurangi upaya duplikat dan pelaporan yang tidak sinkron. Dengan menyediakan serangkaian alat umum untuk versi, otomatisasi, penjadwalan, penyebaran sumber daya produksi dan kode, Anda dapat menyederhanakan beban kerja untuk pemantauan, orkestrasi, dan operasi.
Jadwal pekerjaan notebook Azure Databricks, kueri SQL, dan kode arbitrer lainnya. Bundel Aset Databricks memungkinkan Anda menentukan, menyebarkan, dan menjalankan sumber daya Databricks seperti pekerjaan dan alur secara terprogram. folder Git memungkinkan Anda menyinkronkan proyek Azure Databricks dengan sejumlah penyedia git populer.
Untuk praktik dan rekomendasi terbaik CI/CD, lihat Praktik terbaik dan alur kerja CI/CD yang direkomendasikan di Databricks. Untuk gambaran umum lengkap alat untuk pengembang, lihat Mengembangkan di Databricks.
Analitik waktu nyata dan streaming
Azure Databricks memanfaatkan Apache Spark Structured Streaming untuk bekerja dengan data streaming dan perubahan data bertahap. Streaming Terstruktur terintegrasi erat dengan Delta Lake, dan teknologi ini menyediakan fondasi untuk Alur Deklaratif Lakeflow dan Auto Loader. Lihat Konsep Streaming Terstruktur.