Aplikasi dan layanan terdistribusi yang berjalan di cloud, pada dasarnya, merupakan bagian dari perangkat lunak yang kompleks yang terdiri dari banyak bagian yang bergerak. Dalam lingkungan produksi, penting untuk dapat melacak cara pengguna menggunakan sistem Anda, melacak pemanfaatan sumber daya, dan secara umum memantau kesehatan dan performa sistem Anda. Anda dapat menggunakan informasi ini sebagai bantuan diagnostik untuk mendeteksi dan memperbaiki masalah, serta untuk membantu menemukan kemungkinan masalah dan mencegahnya terjadi.
Skenario pemantauan dan diagnostik
Anda dapat menggunakan pemantauan untuk mendapatkan wawasan tentang seberapa baik sistem berfungsi. Pemantauan adalah bagian penting dalam mempertahankan target kualitas layanan. Skenario umum untuk mengumpulkan data pemantauan meliputi:
- Memastikan bahwa sistem tetap sehat.
- Melacak ketersediaan sistem dan elemen komponennya.
- Mempertahankan performa untuk memastikan bahwa throughput sistem tidak menurun secara tiba-tiba seiring dengan meningkatnya volume pekerjaan.
- Menjamin bahwa sistem memenuhi perjanjian tingkat layanan (SLA) yang dibuat dengan pelanggan.
- Melindungi privasi dan keamanan sistem, pengguna, dan datanya.
- Melacak operasi yang dilakukan untuk tujuan audit atau peraturan.
- Memantau penggunaan sistem sehari-hari dan menemukan tren yang mungkin menyebabkan masalah jika tidak ditangani.
- Melacak masalah yang terjadi, dari laporan awal hingga analisis kemungkinan penyebab, perbaikan, pembaruan perangkat lunak, dan penyebaran.
- Menelusuri operasi dan penelusuran kesalahan rilis perangkat lunak.
Catatan
Daftar ini tidak dirancang untuk menjadi komprehensif. Dokumen ini berfokus pada skenario ini sebagai situasi paling umum untuk melakukan pemantauan. Mungkin ada orang lain yang kurang umum atau khusus untuk lingkungan Anda.
Bagian berikut menjelaskan skenario ini secara lebih rinci. Informasi untuk setiap skenario dibahas dalam format berikut:
- Gambaran singkat dari skenario.
- Persyaratan umum skenario ini.
- Data instrumentasi mentah yang diperlukan untuk mendukung skenario, dan kemungkinan sumber informasi ini.
- Bagaimana data mentah ini dapat dianalisis dan digabungkan untuk menghasilkan informasi diagnostik yang berarti.
Pemantauan kesehatan
Suatu sistem sehat jika berjalan dan mampu memproses permintaan. Tujuan pemantauan kesehatan adalah untuk menghasilkan snapshot tentang kesehatan sistem saat ini sehingga Anda dapat memastikan bahwa semua komponen sistem berfungsi seperti yang diharapkan.
Persyaratan untuk pemantauan kesehatan
Operator harus diperingatkan dengan cepat (dalam hitungan detik) jika ada bagian dari sistem yang dianggap tidak sehat. Operator harus dapat memastikan bagian mana dari sistem yang berfungsi normal, dan bagian mana yang mengalami masalah. Kesehatan sistem dapat disorot melalui sistem lampu lalu lintas:
- Merah untuk tidak sehat (sistem telah berhenti)
- Kuning untuk sebagian sehat (sistem berjalan dengan fungsionalitas yang berkurang)
- Hijau untuk benar-benar sehat
Sistem pemantauan kesehatan yang komprehensif memungkinkan operator menelusuri sistem untuk melihat status kesehatan subsistem dan komponen. Misalnya, jika keseluruhan sistem digambarkan sebagai sebagian sehat, operator harus dapat memperbesar dan menentukan fungsionalitas mana yang saat ini tidak tersedia.
Persyaratan sumber data, instrumentasi, dan pengumpulan data
Data mentah yang diperlukan untuk mendukung pemantauan kesehatan dapat dihasilkan sebagai hasil dari:
- Menelusuri eksekusi permintaan pengguna. Informasi ini dapat digunakan untuk menentukan permintaan mana yang berhasil, mana yang gagal, dan berapa lama waktu yang dibutuhkan setiap permintaan.
- Pemantauan pengguna sintetis. Proses ini mensimulasikan langkah-langkah yang dilakukan oleh pengguna dan mengikuti serangkaian langkah yang telah ditentukan sebelumnya. Hasil dari setiap langkah harus ditangkap.
- Melakukan log pengecualian, kesalahan, dan peringatan. Informasi ini dapat ditangkap sebagai hasil dari pernyataan jejak yang disematkan ke dalam kode aplikasi, serta mengambil informasi dari log peristiwa layanan apa pun yang dirujuk oleh sistem.
- Memantau kesehatan layanan pihak ketiga yang digunakan sistem. Pemantauan ini mungkin memerlukan pengambilan dan penguraian data kesehatan yang disediakan oleh layanan ini. Informasi ini mungkin mengambil berbagai format.
- Pemantauan titik akhir. Mekanisme ini dijelaskan secara lebih rinci di bagian "Pemantauan ketersediaan".
- Mengumpulkan informasi performa sekitar, seperti penggunaan CPU latar belakang atau aktivitas I/O (termasuk jaringan).
Menganalisis data kesehatan
Fokus utama pemantauan kesehatan adalah dengan cepat menunjukkan apakah sistem sedang berjalan. Analisis hot dari data langsung dapat memicu peringatan jika komponen penting terdeteksi tidak sehat. (Ini gagal merespons serangkaian ping berturut-turut, misalnya.) Operator kemudian dapat mengambil tindakan korektif yang sesuai.
Sistem tingkat lanjut mungkin menyertakan elemen prediktif yang melakukan analisis cold atas beban kerja terbaru dan terkini. Analisis cold dapat melihat tren dan menentukan apakah sistem kemungkinan akan tetap sehat atau apakah sistem akan membutuhkan sumber daya tambahan. Elemen prediktif ini harus didasarkan pada metrik performa penting, seperti:
- Tingkat permintaan diarahkan pada setiap layanan atau subsistem.
- Waktu respons dari permintaan ini.
- Volume aliran data masuk dan keluar dari setiap layanan.
Jika nilai metrik apa pun melebihi ambang batas yang ditentukan, sistem dapat meningkatkan peringatan untuk mengaktifkan operator atau penskalaan otomatis (jika tersedia) untuk mengambil tindakan pencegahan yang diperlukan untuk menjaga kesehatan sistem. Tindakan ini mungkin melibatkan penambahan sumber daya, memulai ulang satu atau beberapa layanan yang gagal, atau menerapkan pembatasan ke permintaan dengan prioritas lebih rendah.
Pemantauan ketersediaan
Sistem yang benar-benar sehat mensyaratkan tersedianya komponen dan subsistem yang menyusun sistem tersebut. Pemantauan ketersediaan erat kaitannya dengan pemantauan kesehatan. Tetapi sementara pemantauan kesehatan memberikan pandangan langsung tentang kesehatan sistem saat ini, pemantauan ketersediaan berkaitan dengan penelusuran ketersediaan sistem dan komponennya untuk menghasilkan statistik tentang waktu aktif sistem.
Dalam banyak sistem, beberapa komponen (seperti database) dikonfigurasi dengan redundansi bawaan untuk memungkinkan failover cepat jika terjadi kesalahan serius atau kehilangan konektivitas. Idealnya, pengguna tidak boleh menyadari bahwa kegagalan seperti itu telah terjadi. Namun dari perspektif pemantauan ketersediaan, penting untuk mengumpulkan informasi sebanyak mungkin tentang kegagalan tersebut untuk menentukan penyebabnya dan mengambil tindakan korektif untuk mencegahnya berulang.
Data yang diperlukan untuk melacak ketersediaan mungkin bergantung pada sejumlah faktor tingkat yang lebih rendah. Banyak dari faktor ini mungkin spesifik untuk aplikasi, sistem, dan lingkungan. Sistem pemantauan yang efektif menangkap data ketersediaan yang sesuai dengan faktor tingkat rendah ini lalu mengagregasi untuk memberikan gambaran keseluruhan sistem. Misalnya, dalam sistem e-niaga, fungsi bisnis yang memungkinkan pelanggan untuk memesan mungkin bergantung pada repositori tempat detail pesanan disimpan dan sistem pembayaran yang menangani transaksi moneter untuk membayar pesanan ini. Oleh karena itu, ketersediaan bagian penempatan pesanan dari sistem merupakan fungsi dari ketersediaan repositori dan subsistem pembayaran.
Persyaratan untuk pemantauan ketersediaan
Operator juga harus dapat melihat ketersediaan historis dari setiap sistem dan subsistem, dan menggunakan informasi ini untuk menemukan tren yang mungkin menyebabkan satu atau lebih subsistem gagal secara berkala. (Apakah layanan mulai gagal pada waktu tertentu dalam sehari yang sesuai dengan jam pemrosesan puncak?)
Solusi pemantauan harus memberikan pandangan langsung dan historis tentang ketersediaan atau ketidaktersediaan setiap subsistem. Itu juga harus mampu dengan cepat memperingatkan operator ketika satu atau lebih layanan gagal atau ketika pengguna tidak dapat terhubung ke layanan. Ini bukan hanya masalah memantau setiap layanan, tetapi juga memeriksa tindakan yang dilakukan setiap pengguna jika tindakan ini gagal saat mereka mencoba berkomunikasi dengan layanan. Sampai batas tertentu, tingkat kegagalan konektivitas adalah normal dan mungkin karena kesalahan sementara. Tetapi mungkin berguna untuk mengizinkan sistem meningkatkan peringatan untuk jumlah kegagalan konektivitas ke subsistem tertentu yang terjadi selama periode tertentu.
Persyaratan sumber data, instrumentasi, dan pengumpulan data
Seperti halnya pemantauan kesehatan, data mentah yang diperlukan untuk mendukung pemantauan ketersediaan dapat dihasilkan sebagai hasil dari pemantauan pengguna sintetis dan mencatat pengecualian, kesalahan, dan peringatan apa pun yang mungkin terjadi. Selain itu, data ketersediaan dapat diperoleh dari melakukan pemantauan titik akhir. Aplikasi dapat mengekspos satu atau lebih titik akhir kesehatan, masing-masing menguji akses ke area fungsional dalam sistem. Sistem pemantauan dapat melakukan ping ke setiap titik akhir dengan mengikuti jadwal yang ditentukan dan mengumpulkan hasilnya (berhasil atau gagal).
Semua batas waktu, kegagalan konektivitas jaringan, dan upaya percobaan ulang koneksi harus dicatat. Semua data harus diberi stempel waktu.
Menganalisis data ketersediaan
Data instrumentasi harus digabungkan dan dikorelasikan untuk mendukung jenis analisis berikut:
- Ketersediaan langsung dari sistem dan subsistem.
- Tingkat kegagalan ketersediaan sistem dan subsistem. Idealnya, seorang operator harus dapat menghubungkan kegagalan dengan aktivitas tertentu: apa yang terjadi ketika sistem gagal?
- Pandangan historis tingkat kegagalan sistem atau subsistem apa pun selama periode tertentu, dan beban pada sistem (jumlah permintaan pengguna, misalnya) ketika terjadi kegagalan.
- Alasan tidak tersedianya sistem atau subsistem apa pun. Misalnya, alasannya mungkin karena layanan tidak berjalan, konektivitas terputus, terhubung tetapi waktu habis, dan terhubung tetapi mengembalikan kesalahan.
Anda dapat menghitung persentase ketersediaan layanan selama periode waktu tertentu dengan menggunakan rumus berikut:
%Availability = ((Total Time – Total Downtime) / Total Time ) * 100
Hal ini berguna untuk tujuan SLA. (Pemantauan SLA dijelaskan secara lebih rinci nanti dalam panduan ini.) Definisi waktu henti tergantung pada layanan. Misalnya, Layanan Build Visual Studio Team Services mendefinisikan waktu henti sebagai periode (total akumulasi menit) selama Layanan Build tidak tersedia. Satu menit dianggap tidak tersedia jika semua permintaan HTTP berkelanjutan ke Layanan Build untuk melakukan operasi yang dimulai pelanggan sepanjang menit menghasilkan kode kesalahan atau tidak mengembalikan respons.
Pemantauan kinerja
Ketika sistem ditempatkan di bawah tekanan yang semakin besar (dengan meningkatkan volume pengguna), ukuran set data yang diakses pengguna ini akan meningkat dan kemungkinan kegagalan satu atau lebih komponen menjadi lebih mungkin. Seringkali, kegagalan komponen didahului oleh penurunan performa. Jika Anda dapat mendeteksi penurunan seperti itu, Anda dapat mengambil langkah proaktif untuk memperbaiki situasi.
Performa sistem tergantung pada sejumlah faktor. Setiap faktor biasanya diukur melalui indikator performa utama (KPI), seperti jumlah transaksi database per detik atau volume permintaan jaringan yang berhasil dilayani dalam jangka waktu tertentu. Beberapa dari KPI ini mungkin tersedia sebagai ukuran performa tertentu, sedangkan yang lain mungkin berasal dari kombinasi metrik.
Catatan
Menentukan performa yang buruk atau baik mengharuskan Anda memahami tingkat performa di mana sistem harus mampu berjalan. Hal ini memerlukan pengamatan sistem saat berfungsi di bawah beban umum dan menangkap data untuk setiap KPI selama periode waktu tertentu. Hal ini mungkin melibatkan dengan menjalankan sistem di bawah beban simulasi di lingkungan pengujian dan mengumpulkan data yang sesuai sebelum menyebarkan sistem ke lingkungan produksi.
Anda juga harus memastikan bahwa pemantauan untuk tujuan performa tidak menjadi beban pada sistem. Anda mungkin dapat menyesuaikan tingkat detail secara dinamis untuk data yang dikumpulkan oleh proses pemantauan performa.
Persyaratan untuk pemantauan performa
Untuk memeriksa performa sistem, operator biasanya perlu melihat informasi yang mencakup:
- Tingkat respons untuk permintaan pengguna.
- Jumlah permintaan pengguna bersamaan.
- Volume lalu lintas jaringan.
- Tingkat di mana transaksi bisnis sedang diselesaikan.
- Waktu pemrosesan rata-rata untuk permintaan.
Juga dapat membantu untuk menyediakan alat yang memungkinkan operator membantu menemukan korelasi, seperti:
- Jumlah pengguna bersamaan versus waktu latensi permintaan (berapa lama waktu yang dibutuhkan untuk mulai memproses permintaan setelah pengguna mengirimnya).
- Jumlah pengguna bersamaan versus waktu respons rata-rata (berapa lama waktu yang dibutuhkan untuk menyelesaikan permintaan setelah mulai diproses).
- Volume permintaan versus jumlah kesalahan pemrosesan.
Seiring dengan informasi fungsional tingkat tinggi ini, seorang operator harus dapat memperoleh gambaran rinci tentang performa setiap komponen dalam sistem. Data ini biasanya diberikan melalui penghitung performa tingkat rendah yang melacak informasi seperti:
- Pemanfaatan memori.
- Jumlah alur.
- Waktu pemrosesan CPU.
- Panjang antrean permintaan
- Disk atau rasio dan kesalahan jaringan I/O.
- Jumlah byte yang ditulis atau dibaca.
- Indikator middleware, seperti panjang antrean.
Semua visualisasi harus memungkinkan operator untuk menentukan jangka waktu. Data yang ditampilkan mungkin merupakan rekam jepret dari situasi saat ini atau tampilan historis performa.
Operator harus dapat meningkatkan peringatan berdasarkan ukuran performa apa pun untuk nilai tertentu selama interval waktu tertentu.
Persyaratan sumber data, instrumentasi, dan pengumpulan data
Anda dapat mengumpulkan data performa tingkat tinggi (throughput, jumlah pengguna secara bersamaan, jumlah transaksi bisnis, tingkat kesalahan, dan sebagainya) dengan memantau kemajuan permintaan pengguna saat data tersebut tiba dan melewati sistem. Hal ini melibatkan penggabungan pernyataan penelusuran pada poin-poin penting dalam kode aplikasi, bersama dengan informasi waktu. Semua kesalahan, pengecualian, dan peringatan harus ditangkap dengan data yang cukup untuk menghubungkannya dengan permintaan yang menyebabkannya. Internet Information Services (IIS) adalah sumber lain yang berguna.
Jika memungkinkan, Anda juga harus merekam data performa untuk sistem eksternal apa pun yang digunakan aplikasi. Sistem eksternal ini mungkin menyediakan penghitung performanya sendiri atau fitur lain untuk meminta data performa. Jika ini tidak memungkinkan, catat informasi seperti waktu mulai dan waktu berakhir dari setiap permintaan yang dibuat ke sistem eksternal, bersama dengan status (berhasil, gagal, atau peringatan) operasi. Misalnya, Anda dapat menggunakan pendekatan stopwatch untuk permintaan waktu: mulai timer saat permintaan dimulai dan kemudian hentikan timer saat permintaan selesai.
Data performa tingkat rendah untuk masing-masing komponen dalam sistem mungkin tersedia melalui fitur dan layanan seperti penghitung performa Windows dan Azure Diagnostics.
Menganalisis data performa
Sebagian besar pekerjaan analisis terdiri dari menggabungkan data performa berdasarkan jenis permintaan pengguna atau subsistem atau layanan tempat setiap permintaan dikirim. Contoh permintaan pengguna adalah menambahkan item ke keranjang belanja atau melakukan proses checkout dalam sistem e-commerce.
Persyaratan umum lainnya adalah meringkas data performa dalam persentil yang dipilih. Misalnya, operator mungkin menentukan waktu respons untuk 99 persen permintaan, 95 persen permintaan, dan 70 persen permintaan. Mungkin ada target SLA atau sasaran lain yang ditetapkan untuk setiap persentil. Hasil yang sedang berlangsung harus dilaporkan dalam waktu dekat untuk membantu mendeteksi masalah langsung. Hasilnya juga harus diagregasi dalam waktu yang lebih lama untuk tujuan statistik.
Dalam kasus masalah latensi yang memengaruhi performa, operator harus dapat dengan cepat mengidentifikasi penyebab penyempitan dengan memeriksa latensi dari setiap langkah yang dilakukan setiap permintaan. Oleh karena itu, data performa harus menyediakan sarana untuk menghubungkan ukuran performa untuk setiap langkah untuk mengikatnya ke permintaan tertentu.
Bergantung pada persyaratan visualisasi, mungkin berguna untuk membuat dan menyimpan kubus data yang berisi tampilan data mentah. Kubus data ini dapat memungkinkan kueri ad hoc yang kompleks dan analisis informasi performa.
Pemantauan keamanan
Semua sistem komersial yang menyertakan data sensitif harus menerapkan struktur keamanan. Kompleksitas mekanisme keamanan biasanya merupakan fungsi dari sensitivitas data. Dalam sistem yang mengharuskan pengguna untuk diautentikasi, Anda harus mencatat:
- Semua upaya kredensial masuk, baik gagal atau berhasil.
- Semua operasi yang dilakukan oleh—dan detail semua sumber daya yang diakses oleh—pengguna yang diautentikasi.
- Saat pengguna mengakhiri sesi dan keluar.
Pemantauan mungkin dapat membantu mendeteksi serangan pada sistem. Misalnya, sejumlah besar upaya kredensial masuk yang gagal mungkin mengindikasikan serangan brute force. Lonjakan permintaan yang tidak terduga mungkin merupakan hasil dari penolakan serangan layanan (DDoS) terdistribusi. Anda harus siap untuk memantau semua permintaan ke semua sumber daya terlepas dari sumber permintaan tersebut. Sistem yang memiliki kerentanan kredensial masuk mungkin secara tidak sengaja mengekspos sumber daya ke dunia luar tanpa mengharuskan pengguna untuk benar-benar masuk.
Persyaratan untuk pemantauan keamanan
Aspek paling kritis dari pemantauan keamanan harus memungkinkan operator untuk dengan cepat:
- Mendeteksi upaya penyusupan oleh entitas yang tidak diautentikasi.
- Identifikasi upaya entitas untuk melakukan operasi pada data yang aksesnya belum diberikan kepada mereka.
- Tentukan apakah sistem, atau bagian dari sistem, sedang diserang dari luar atau dari dalam. (Misalnya, pengguna terautentikasi yang berbahaya mungkin mencoba menjatuhkan sistem.)
Untuk mendukung persyaratan ini, operator harus diberitahu jika:
- Satu akun melakukan upaya kredensial masuk yang gagal berulang kali dalam jangka waktu tertentu.
- Satu akun yang diautentikasi berulang kali mencoba mengakses sumber daya yang dilarang selama periode tertentu.
- Sejumlah besar permintaan yang tidak diautentikasi atau tidak sah terjadi selama periode tertentu.
Informasi yang diberikan kepada operator harus menyertakan alamat host sumber untuk setiap permintaan. Jika pelanggaran keamanan sering muncul dari rentang alamat tertentu, host ini mungkin akan diblokir.
Bagian penting dalam menjaga keamanan suatu sistem adalah dapat dengan cepat mendeteksi tindakan yang menyimpang dari pola biasanya. Informasi seperti jumlah permintaan masuk yang gagal atau berhasil dapat ditampilkan secara visual untuk membantu mendeteksi apakah ada lonjakan aktivitas pada waktu yang tidak biasa. (Contoh aktivitas ini adalah pengguna masuk pada pukul 3:00 pagi dan melakukan sejumlah besar operasi saat hari kerja mereka dimulai pada pukul 9:00). Informasi ini juga dapat digunakan untuk membantu mengonfigurasi penskalaan otomatis berbasis waktu. Misalnya, jika operator mengamati bahwa sejumlah besar pengguna secara teratur masuk pada waktu tertentu dalam sehari, operator dapat mengatur untuk memulai layanan autentikasi tambahan untuk menangani volume pekerjaan, dan kemudian mematikan layanan tambahan ini ketika puncak telah lulus.
Persyaratan sumber data, instrumentasi, dan pengumpulan data
Keamanan adalah aspek menyeluruh dari sebagian besar sistem terdistribusi. Data terkait kemungkinan akan dihasilkan di beberapa titik di seluruh sistem. Anda harus mempertimbangkan untuk mengadopsi pendekatan Security Information and Event Management (SIEM) untuk mengumpulkan informasi terkait keamanan yang dihasilkan dari peristiwa yang ditimbulkan oleh aplikasi, peralatan jaringan, server, firewall, perangkat lunak antivirus, dan elemen pencegahan intrusi lainnya.
Pemantauan keamanan dapat menggabungkan data dari alat yang bukan bagian dari aplikasi Anda. Alat-alat ini dapat mencakup utilitas yang mengidentifikasi aktivitas pemindaian port oleh agen eksternal, atau filter jaringan yang mendeteksi upaya untuk mendapatkan akses yang tidak diautentikasi ke aplikasi dan data Anda.
Dalam semua kasus, data yang dikumpulkan harus memungkinkan administrator untuk menentukan sifat serangan apa pun dan mengambil tindakan pencegahan yang sesuai.
Menganalisis data keamanan
Fitur pemantauan keamanan adalah berbagai sumber dari mana data muncul. Format dan tingkat detail yang berbeda sering kali memerlukan analisis kompleks dari data yang diambil untuk mengikatnya menjadi satu alur informasi yang koheren. Terlepas dari kasus yang paling sederhana (seperti mendeteksi sejumlah besar upaya masuk yang gagal, atau upaya berulang kali untuk mendapatkan akses tidak sah ke sumber daya penting), mungkin tidak mungkin untuk melakukan pemrosesan otomatis yang rumit atas data keamanan. Sebagai gantinya, mungkin lebih baik untuk menulis data ini, dengan stempel waktu tetapi sebaliknya dalam bentuk aslinya, ke repositori yang aman untuk memungkinkan analisis manual ahli.
Pemantauan SLA
Banyak sistem komersial yang mendukung pelanggan yang membayar membuat jaminan tentang performa sistem dalam bentuk SLA. Pada dasarnya, SLA menyatakan bahwa sistem dapat menangani volume pekerjaan yang ditentukan dalam jangka waktu yang disepakati dan tanpa kehilangan informasi penting. Pemantauan SLA berkaitan dengan memastikan bahwa sistem dapat memenuhi SLA yang terukur.
Catatan
Pemantauan SLA berkaitan erat dengan pemantauan performa. Namun sementara pemantauan performa berkaitan dengan memastikan bahwa sistem berfungsi secara optimal, pemantauan SLA diatur oleh kewajiban kontraktual yang mendefinisikan apa arti sebenarnya optimal.
SLA sering didefinisikan dalam hal:
- Ketersediaan sistem secara keseluruhan. Misalnya, sebuah organisasi mungkin menjamin bahwa sistem akan tersedia untuk 99,9 persen dari waktu. Ini sama dengan tidak lebih dari 9 jam waktu henti per tahun, atau sekitar 10 menit seminggu.
- Throughput operasional. Aspek ini sering dinyatakan sebagai satu atau lebih tanda air yang tinggi, seperti menjamin bahwa sistem dapat mendukung hingga 100.000 permintaan pengguna secara bersamaan atau menangani 10.000 transaksi bisnis bersamaan.
- Waktu respons operasional. Sistem mungkin juga membuat jaminan untuk tingkat di mana permintaan diproses. Contohnya adalah 99 persen dari semua transaksi bisnis akan selesai dalam waktu 2 detik, dan tidak ada satu pun transaksi yang membutuhkan waktu lebih dari 10 detik.
Catatan
Beberapa kontrak untuk sistem komersial mungkin juga menyertakan SLA untuk dukungan pelanggan. Contohnya adalah bahwa semua permintaan meja bantuan akan mendapat respons dalam waktu lima menit, dan bahwa 99 persen dari semua masalah akan diselesaikan sepenuhnya dalam 1 hari kerja. Pelacakan masalah yang efektif (dijelaskan nanti di bagian ini) adalah kunci untuk memenuhi SLA seperti ini.
Persyaratan untuk pemantauan SLA
Pada level tertinggi, seorang operator harus dapat menentukan secara sekilas apakah sistem memenuhi SLA yang telah disepakati atau tidak. Dan jika tidak, operator harus dapat menelusuri dan memeriksa paling detail faktor-faktor yang mendasari untuk menentukan alasan performa di bawah standar.
Indikator tingkat tinggi tipikal yang dapat digambarkan secara visual meliputi:
- Persentase waktu aktif layanan.
- Throughput aplikasi (diukur dalam hal transaksi atau operasi yang berhasil per detik).
- Jumlah permintaan aplikasi yang berhasil/gagal.
- Jumlah kesalahan aplikasi dan sistem, pengecualian, dan peringatan.
Semua indikator ini harus mampu disaring dengan jangka waktu tertentu.
Aplikasi cloud kemungkinan akan terdiri dari sejumlah subsistem dan komponen. Operator harus dapat memilih indikator tingkat tinggi dan melihat bagaimana indikator tersebut disusun dari kesehatan elemen yang mendasarinya. Misalnya, jika waktu kerja sistem secara keseluruhan turun di bawah nilai yang dapat diterima, operator harus dapat memperbesar dan menentukan elemen mana yang berkontribusi terhadap kegagalan ini.
Catatan
Waktu aktif sistem perlu didefinisikan dengan hati-hati. Dalam sistem yang menggunakan redundansi untuk memastikan ketersediaan maksimum, instans elemen individual mungkin gagal, tetapi sistem dapat tetap berfungsi. Waktu aktif sistem seperti yang disajikan oleh pemantauan kesehatan harus menunjukkan waktu aktif agregat dari setiap elemen dan tidak harus apakah sistem benar-benar berhenti. Selain itu, kegagalan mungkin terisolasi. Jadi, bahkan jika sistem tertentu tidak tersedia, sisa sistem mungkin tetap tersedia, meskipun dengan fungsionalitas yang menurun. (Dalam sistem e-niaga, kegagalan dalam sistem mungkin mencegah pelanggan melakukan pemesanan, tetapi pelanggan mungkin masih dapat menelusuri katalog produk.)
Untuk tujuan peringatan, sistem harus dapat meningkatkan suatu peristiwa jika salah satu indikator tingkat tinggi melebihi ambang batas yang ditentukan. Detail tingkat yang lebih rendah dari berbagai faktor yang menyusun indikator tingkat tinggi harus tersedia sebagai data kontekstual ke sistem peringatan.
Persyaratan sumber data, instrumentasi, dan pengumpulan data
Data mentah yang diperlukan untuk mendukung pemantauan SLA serupa dengan data mentah yang diperlukan untuk pemantauan performa, bersama dengan beberapa aspek pemantauan kesehatan dan ketersediaan. (Lihat bagian tersebut untuk detail selengkapnya.) Anda dapat mengambil data ini dengan:
- Melakukan pemantauan titik akhir.
- Melakukan log pengecualian, kesalahan, dan peringatan.
- Menelusuri eksekusi permintaan pengguna.
- Memantau ketersediaan layanan pihak ketiga yang digunakan sistem.
- Menggunakan metrik dan penghitung performa.
Semua data harus diberi waktu dan stempel waktu.
Menganalisis data SLA
Data instrumentasi harus diagregasi untuk menghasilkan gambaran performa sistem secara keseluruhan. Data agregat juga harus mendukung penelusuran untuk memungkinkan pemeriksaan performa subsistem yang mendasarinya. Misalnya, Anda harus dapat:
- Menghitung jumlah total permintaan pengguna selama periode tertentu dan menentukan tingkat keberhasilan dan kegagalan permintaan ini.
- Menggabungkan waktu respons permintaan pengguna untuk menghasilkan tampilan keseluruhan waktu respons sistem.
- Menganalisis kemajuan permintaan pengguna untuk membagi waktu respons keseluruhan permintaan menjadi waktu respons masing-masing item pekerjaan dalam permintaan itu.
- Menentukan ketersediaan keseluruhan sistem sebagai persentase waktu aktif untuk periode tertentu.
- Menganalisis persentase ketersediaan waktu dari masing-masing komponen dan layanan dalam sistem. Ini mungkin melibatkan penguraian log yang dihasilkan oleh layanan pihak ketiga.
Banyak sistem komersial diminta untuk melaporkan angka performa nyata terhadap SLA yang disepakati untuk jangka waktu tertentu, biasanya satu bulan. Informasi ini dapat digunakan untuk menghitung kredit atau bentuk pembayaran lainnya untuk pelanggan jika SLA tidak terpenuhi selama periode tersebut. Anda dapat menghitung ketersediaan layanan dengan menggunakan teknik yang dijelaskan di bagian Menganalisis data ketersediaan.
Untuk tujuan internal, organisasi mungkin juga melacak jumlah dan sifat insiden yang menyebabkan layanan gagal. Mempelajari cara menyelesaikan masalah ini dengan cepat, atau menghilangkannya sepenuhnya, akan membantu mengurangi waktu henti dan memenuhi SLA.
Audit
Bergantung pada sifat aplikasi, mungkin ada undang-undang atau peraturan hukum lainnya yang menetapkan persyaratan untuk mengaudit operasi pengguna dan merekam semua akses data. Audit dapat memberikan bukti yang menghubungkan pelanggan dengan permintaan tertentu. Nonrepudiasi merupakan faktor penting dalam banyak sistem e-business untuk membantu menjaga kepercayaan antara pelanggan dan organisasi yang bertanggung jawab atas aplikasi atau layanan.
Persyaratan untuk audit
Seorang analis harus dapat melacak urutan operasi bisnis yang dilakukan pengguna sehingga Anda dapat merekonstruksi tindakan pengguna. Ini mungkin diperlukan hanya sebagai catatan, atau sebagai bagian dari penyelidikan forensik.
Informasi audit sangat sensitif. Ini kemungkinan akan mencakup data yang mengidentifikasi pengguna sistem, bersama dengan tugas yang mereka lakukan. Untuk alasan ini, informasi audit kemungkinan besar akan berbentuk laporan yang hanya tersedia untuk analis tepercaya daripada sebagai sistem interaktif yang mendukung penelusuran operasi grafis paling detail. Seorang analis harus mampu menghasilkan berbagai laporan. Misalnya, laporan mungkin mencantumkan semua aktivitas pengguna yang terjadi selama jangka waktu tertentu, merinci kronologi aktivitas untuk satu pengguna, atau membuat daftar urutan operasi yang dilakukan terhadap satu atau lebih sumber daya.
Persyaratan sumber data, instrumentasi, dan pengumpulan data
Sumber informasi utama untuk audit dapat mencakup:
- Sistem keamanan yang mengelola autentikasi pengguna.
- Lacak log yang merekam aktivitas pengguna.
- Log keamanan yang melacak semua permintaan jaringan yang dapat diidentifikasi dan tidak dapat diidentifikasi.
Format data audit dan cara penyimpanannya mungkin didorong oleh persyaratan peraturan. Misalnya, mungkin tidak mungkin untuk membersihkan data dengan cara apa pun. (Ini harus direkam dalam format aslinya.) Akses ke repositori tempat penyimpanannya harus dilindungi untuk mencegah perubahan.
Menganalisis data audit
Seorang analis harus dapat mengakses data mentah secara keseluruhan, dalam bentuk aslinya. Selain persyaratan untuk menghasilkan laporan audit umum, alat untuk menganalisis data ini cenderung dikhususkan dan disimpan di luar sistem.
Pemantauan penggunaan
Pemantauan penggunaan melacak bagaimana fitur dan komponen aplikasi digunakan. Operator dapat menggunakan data yang dikumpulkan untuk:
Tentukan fitur mana yang banyak digunakan dan tentukan hotspot potensial di sistem. Elemen lalu lintas tinggi mungkin mendapat manfaat dari partisi fungsional atau bahkan replikasi untuk menyebarkan beban lebih merata. Operator juga dapat menggunakan informasi ini untuk memastikan fitur mana yang jarang digunakan dan kemungkinan kandidat untuk penghentian atau penggantian di versi sistem yang akan datang.
Dapatkan informasi tentang peristiwa operasional sistem dalam penggunaan normal. Misalnya, di situs e-niaga, Anda dapat merekam informasi statistik tentang jumlah transaksi dan volume pelanggan yang bertanggung jawab atasnya. Informasi ini dapat digunakan untuk perencanaan kapasitas seiring dengan bertambahnya jumlah pelanggan.
Mendeteksi (mungkin secara tidak langsung) kepuasan pengguna dengan performa atau fungsionalitas sistem. Misalnya, jika sejumlah besar pelanggan dalam sistem e-niaga secara teratur meninggalkan keranjang belanja mereka, perilaku ini mungkin karena masalah dengan fungsi pembayaran.
Menghasilkan informasi penagihan. Aplikasi komersial atau layanan multitenant mungkin membebankan biaya kepada pelanggan untuk sumber daya yang mereka gunakan.
Terapkan kuota. Jika pengguna dalam sistem multitenant melebihi kuota waktu pemrosesan atau penggunaan sumber daya yang dibayar selama periode tertentu, akses mereka dapat dibatasi atau pemrosesan dapat dibatasi.
Persyaratan untuk pemantauan penggunaan
Untuk memeriksa penggunaan sistem, operator biasanya perlu melihat informasi yang mencakup:
- Jumlah permintaan yang diproses oleh setiap subsistem dan diarahkan ke masing-masing sumber daya.
- Pekerjaan yang dilakukan setiap pengguna.
- Volume penyimpanan data yang ditempati setiap pengguna.
- Sumber daya yang diakses setiap pengguna.
Operator juga harus dapat menghasilkan grafik. Misalnya, grafik mungkin menampilkan pengguna yang paling haus sumber daya, atau sumber daya atau fitur sistem yang paling sering diakses.
Persyaratan sumber data, instrumentasi, dan pengumpulan data
Penelusuran penggunaan dapat dilakukan pada tingkat yang relatif tinggi. Penelusuran penggunaan dapat mencatat waktu mulai dan berakhir setiap permintaan dan sifat permintaan (membaca, menulis, dan sebagainya, tergantung pada sumber daya yang bersangkutan). Anda dapat memperoleh informasi ini dengan:
- Melacak aktivitas pengguna.
- Menangkap penghitung performa yang mengukur pemanfaatan untuk setiap sumber daya.
- Memantau konsumsi sumber daya oleh setiap pengguna.
Untuk tujuan pengukuran, Anda juga harus dapat mengidentifikasi pengguna mana yang bertanggung jawab untuk melakukan operasi mana, dan sumber daya yang digunakan operasi ini. Informasi yang dikumpulkan harus cukup rinci untuk memungkinkan penagihan yang akurat.
Pelacakan masalah
Pelanggan dan pengguna lain mungkin melaporkan masalah jika peristiwa atau perilaku tak terduga terjadi di sistem. Pelacakan masalah berkaitan dengan pengelolaan masalah ini, mengaitkannya dengan upaya untuk menyelesaikan masalah mendasar apa pun dalam sistem, dan memberi tahu pelanggan tentang kemungkinan penyelesaian.
Persyaratan untuk pelacakan masalah
Operator sering melakukan pelacakan masalah dengan menggunakan sistem terpisah yang memungkinkan mereka untuk merekam dan melaporkan detail masalah yang dilaporkan pengguna. Detail ini dapat mencakup tugas yang coba dilakukan pengguna, gejala masalah, urutan kejadian, dan pesan kesalahan atau peringatan apa pun yang dikeluarkan.
Persyaratan sumber data, instrumentasi, dan pengumpulan data
Sumber data awal untuk data pelacakan masalah adalah pengguna yang melaporkan masalah tersebut di tempat pertama. Pengguna mungkin dapat memberikan data tambahan seperti:
- Crash dump (jika aplikasi menyertakan komponen yang berjalan di desktop pengguna).
- Snapshot layar
- Tanggal dan waktu saat kesalahan terjadi, bersama dengan informasi lingkungan lainnya seperti lokasi pengguna.
Informasi ini dapat digunakan untuk membantu upaya penelusuran kesalahan dan membantu membangun backlog untuk rilis perangkat lunak di masa mendatang.
Menganalisis data pelacakan masalah
Pengguna yang berbeda mungkin melaporkan masalah yang sama. Sistem pelacakan masalah harus mengaitkan laporan umum.
Kemajuan upaya penelusuran kesalahan harus dicatat terhadap setiap laporan masalah. Ketika masalah teratasi, pelanggan dapat diberitahu tentang solusinya.
Jika pengguna melaporkan masalah yang memiliki solusi yang diketahui dalam sistem pelacakan masalah, operator harus dapat segera memberi tahu pengguna tentang solusi tersebut.
Menelusuri operasi dan penelusuran kesalahan rilis perangkat lunak
Saat pengguna melaporkan masalah, pengguna sering kali hanya menyadari efek langsungnya pada operasi mereka. Pengguna hanya dapat melaporkan hasil pengalaman mereka sendiri kembali ke operator yang bertanggung jawab untuk memelihara sistem. Pengalaman-pengalaman ini biasanya hanya merupakan gejala yang terlihat dari satu atau lebih masalah mendasar. Dalam banyak kasus, seorang analis perlu menggali kronologi operasi yang mendasarinya untuk menetapkan akar penyebab masalah. Proses ini disebut analisis akar penyebab.
Catatan
Analisis akar penyebab mungkin mengungkap inefisiensi dalam desain aplikasi. Dalam situasi ini, dimungkinkan untuk mengerjakan ulang elemen yang terpengaruh dan menyebarkannya sebagai bagian dari rilis berikutnya. Proses ini memerlukan kontrol yang cermat, dan komponen yang diperbarui harus dipantau secara ketat.
Persyaratan untuk pelacakan dan penelusuran kesalahan
Untuk menelusuri peristiwa tak terduga dan masalah lainnya, sangat penting bahwa data pemantauan menyediakan informasi yang cukup untuk memungkinkan seorang analis menelusuri kembali ke asal-usul masalah ini dan merekonstruksi urutan peristiwa yang terjadi. Informasi ini harus cukup untuk memungkinkan seorang analis mendiagnosis akar penyebab masalah. Pengembang kemudian dapat membuat modifikasi yang diperlukan untuk mencegahnya berulang.
Persyaratan sumber data, instrumentasi, dan pengumpulan data
Pemecahan masalah dapat melibatkan penelusuran semua metode (dan parameternya) yang dipanggil sebagai bagian dari operasi untuk membangun pohon yang menggambarkan alur logis melalui sistem saat pelanggan membuat permintaan khusus. Pengecualian dan peringatan yang dihasilkan sistem sebagai hasil dari alur ini perlu ditangkap dan dicatat.
Untuk mendukung penelusuran kesalahan, sistem dapat menyediakan hook yang memungkinkan operator untuk menangkap informasi status pada titik-titik penting dalam sistem. Atau, sistem dapat memberikan informasi langkah demi langkah yang mendetail seiring kemajuan operasi yang dipilih. Menangkap data pada tingkat detail ini dapat membebani sistem dan seharusnya merupakan proses sementara. Operator menggunakan proses ini terutama ketika serangkaian peristiwa yang sangat tidak biasa terjadi dan sulit untuk ditiru, atau ketika rilis baru dari satu atau lebih elemen ke dalam sistem memerlukan pemantauan yang cermat untuk memastikan bahwa elemen berfungsi seperti yang diharapkan.
Alur pemantauan dan diagnostik
Pemantauan sistem terdistribusi skala besar menimbulkan tantangan yang signifikan. Setiap skenario yang dijelaskan di bagian sebelumnya tidak harus dipertimbangkan secara terpisah. Kemungkinan ada tumpang tindih yang signifikan dalam pemantauan dan data diagnostik yang diperlukan untuk setiap situasi, meskipun data ini mungkin perlu diproses dan disajikan dengan cara yang berbeda. Untuk alasan ini, Anda harus mengambil pandangan holistik dari pemantauan dan diagnostik.
Anda dapat membayangkan seluruh proses pemantauan dan diagnostik sebagai alur yang terdiri dari tahapan yang ditunjukkan pada Gambar 1.

Gambar 1 - Tahapan dalam alur pemantauan dan diagnostik.
Gambar 1 menyoroti bagaimana data untuk pemantauan dan diagnostik dapat berasal dari berbagai sumber data. Tahap instrumentasi dan pengumpulan berkaitan dengan mengidentifikasi sumber dari mana data perlu diambil, menentukan data mana yang akan diambil, bagaimana menangkapnya, dan bagaimana memformat data ini sehingga dapat dengan mudah diperiksa. Tahap analisis/diagnosis mengambil data mentah dan menggunakannya untuk menghasilkan informasi yang berarti yang dapat digunakan operator untuk menentukan status sistem. Operator dapat menggunakan informasi ini untuk membuat keputusan tentang tindakan yang mungkin diambil, dan kemudian memasukkan hasilnya kembali ke tahap instrumentasi dan pengumpulan. Fase tahap visualisasi/pemberitahuan menyajikan tampilan status sistem yang dapat dikonsumsi. Ini dapat menampilkan informasi hampir secara real time dengan menggunakan serangkaian dasbor. Dan ini dapat menghasilkan laporan, grafik, dan bagan untuk memberikan tampilan historis dari data yang dapat membantu mengidentifikasi tren jangka panjang. Jika informasi menunjukkan bahwa KPI cenderung melebihi batas yang dapat diterima, tahap ini juga dapat memicu peringatan ke operator. Dalam beberapa kasus, peringatan juga dapat digunakan untuk memicu proses otomatis yang mencoba mengambil tindakan korektif, seperti penskalaan otomatis.
Perhatikan bahwa langkah-langkah ini merupakan proses alur berkelanjutan di mana tahapan terjadi secara paralel. Idealnya, semua fase harus dapat dikonfigurasi secara dinamis. Di beberapa titik, terutama ketika sistem baru digunakan atau mengalami masalah, mungkin perlu untuk mengumpulkan data yang diperluas secara lebih sering. Di lain waktu, dimungkinkan untuk kembali menangkap tingkat dasar informasi penting untuk memverifikasi bahwa sistem berfungsi dengan baik.
Selain itu, seluruh proses pemantauan harus dianggap sebagai solusi langsung dan berkelanjutan yang tunduk pada penyempurnaan dan peningkatan sebagai hasil dari umpan balik. Misalnya, Anda mungkin mulai dengan mengukur banyak faktor untuk menentukan kesehatan sistem. Analisis dari waktu ke waktu dapat mengarah pada penyempurnaan saat Anda membuang langkah-langkah yang tidak relevan, memungkinkan Anda untuk lebih fokus secara tepat pada data yang Anda butuhkan sambil meminimalkan kebisingan latar belakang.
Sumber data pemantauan dan diagnostik
Informasi yang digunakan dalam proses monitoring dapat berasal dari beberapa sumber, seperti digambarkan pada Gambar 1. Pada tingkat aplikasi, informasi berasal dari log penelusuran yang dimasukkan ke dalam kode sistem. Pengembang harus mengikuti pendekatan standar untuk menelusuri alur kontrol melalui kode mereka. Misalnya, entri ke metode dapat memancarkan pesan penelusuran yang menentukan nama metode, waktu saat ini, nilai setiap parameter, dan informasi terkait lainnya. Merekam waktu masuk dan keluar juga terbukti bermanfaat.
Anda harus mencatat semua pengecualian dan peringatan, dan memastikan bahwa Anda menyimpan penelusuran lengkap dari setiap pengecualian dan peringatan bersarang. Idealnya, Anda juga dapat menangkap informasi yang mengidentifikasi pengguna yang menjalankan kode, bersama dengan informasi korelasi aktivitas (untuk melacak permintaan saat mereka melewati sistem). Dan Anda harus mencatat upaya untuk mengakses semua sumber daya seperti antrean pesan, database, file, dan layanan dependen lainnya. Informasi ini dapat digunakan untuk tujuan pengukuran dan audit.
Banyak aplikasi menggunakan pustaka dan kerangka kerja untuk melakukan tugas-tugas umum seperti mengakses penyimpanan data atau berkomunikasi melalui jaringan. Kerangka kerja ini dapat dikonfigurasi untuk memberikan pesan jejak mereka sendiri dan informasi diagnostik mentah, seperti tingkat transaksi dan keberhasilan serta kegagalan transmisi data.
Catatan
Banyak kerangka kerja modern yang secara otomatis menerbitkan performa dan melacak peristiwa. Menangkap informasi ini hanyalah masalah menyediakan sarana untuk mengambil dan menyimpannya di tempat yang dapat diproses dan dianalisis.
Sistem operasi tempat aplikasi berjalan dapat menjadi sumber informasi tingkat rendah di seluruh sistem, seperti penghitung performa yang menunjukkan kecepatan I/O, penggunaan memori, dan penggunaan CPU. Kesalahan sistem operasi (seperti kegagalan untuk membuka file dengan benar) juga dapat dilaporkan.
Anda juga harus mempertimbangkan infrastruktur dan komponen yang mendasari di mana sistem Anda berjalan. Mesin virtual, jaringan virtual, dan layanan penyimpanan semuanya dapat menjadi sumber penghitung performa tingkat infrastruktur yang penting dan data diagnostik lainnya.
Jika aplikasi Anda menggunakan layanan eksternal lainnya, seperti server web atau sistem manajemen database, layanan ini mungkin menerbitkan informasi penelusuran, log, dan penghitung performanya sendiri. Contohnya termasuk Tampilan Manajemen Dinamis SQL Server untuk operasi pelacakan yang dilakukan terhadap database SQL Server, dan log pelacakan IIS untuk permintaan perekaman yang dibuat ke server web.
Karena komponen sistem dimodifikasi dan versi baru disebarkan, penting untuk dapat mengaitkan masalah, peristiwa, dan metrik ke setiap versi. Informasi ini harus dihubungkan kembali ke alur rilis sehingga masalah dengan versi tertentu dari komponen dapat ditelusuri dengan cepat dan diperbaiki.
Masalah keamanan dapat terjadi kapan saja dalam sistem. Misalnya, pengguna mungkin mencoba masuk dengan ID pengguna atau kata sandi yang tidak valid. Pengguna yang diautentikasi mungkin mencoba mendapatkan akses tidak sah ke sumber daya. Atau pengguna mungkin memberikan kunci yang tidak valid atau tidak berlaku lagi untuk mengakses informasi terenkripsi. Informasi terkait keamanan untuk permintaan yang berhasil dan yang gagal harus selalu dicatat.
Bagian Melengkapi aplikasi berisi panduan selengkapnya tentang informasi yang harus Anda tangkap. Namun, Anda dapat menggunakan berbagai strategi untuk mengumpulkan informasi ini:
Pemantauan aplikasi/sistem. Strategi ini menggunakan sumber internal dalam aplikasi, kerangka kerja aplikasi, sistem operasi, dan infrastruktur. Kode aplikasi dapat membuat data pemantauannya sendiri pada titik-titik penting selama siklus hidup permintaan klien. Aplikasi dapat menyertakan pernyataan pelacakan yang mungkin diaktifkan atau dinonaktifkan secara selektif sesuai dengan keadaan. Aplikasi juga dapat memasukkan diagnostik secara dinamis dengan menggunakan kerangka kerja diagnostik. Kerangka kerja ini biasanya menyediakan plug-in yang dapat dilampirkan ke berbagai titik instrumentasi dalam kode Anda dan menangkap data jejak pada titik-titik ini.
Selain itu, kode Anda atau infrastruktur yang mendasar dapat memunculkan peristiwa di titik kritis. Agen pemantauan yang dikonfigurasi untuk mendengarkan peristiwa ini dapat merekam informasi peristiwa.
Pemantauan pengguna nyata. Pendekatan ini mencatat interaksi antara pengguna dan aplikasi serta mengamati alur setiap permintaan dan respons. Informasi ini dapat memiliki dua tujuan: dapat digunakan untuk pengukuran penggunaan oleh setiap pengguna, dan dapat digunakan untuk menentukan apakah pengguna menerima kualitas layanan yang sesuai (misalnya, waktu respons yang cepat, latensi rendah, dan kesalahan). Anda dapat menggunakan data yang diambil untuk mengidentifikasi area yang menjadi perhatian tempat kegagalan paling sering terjadi. Anda juga dapat menggunakan data untuk mengidentifikasi elemen tempat sistem melambat, mungkin karena hotspot dalam aplikasi atau beberapa bentuk penyempitan lainnya. Jika Anda menerapkan pendekatan ini dengan hati-hati, Anda dapat merekonstruksi alur pengguna melalui aplikasi untuk tujuan pencarian kesalahan dan pengujian.
Penting
Anda harus mempertimbangkan bahwa data yang diambil dengan memantau pengguna nyata sangat sensitif karena mungkin berisi materi rahasia. Jika Anda menyimpan data yang diambil, simpan dengan aman. Jika Anda ingin menggunakan data untuk tujuan pemantauan performa atau penelusuran kesalahan, hapus semua data pribadi terlebih dahulu.
Pemantauan pengguna sintetis. Dalam pendekatan ini, Anda menulis klien pengujian Anda sendiri yang mensimulasikan pengguna dan melakukan serangkaian operasi yang dapat dikonfigurasi tetapi tipikal. Anda dapat melacak performa klien pengujian untuk membantu menentukan status sistem. Anda juga dapat menggunakan beberapa instans klien uji sebagai bagian dari operasi pengujian beban untuk menentukan cara sistem merespons stres, dan jenis output pemantauan apa yang dihasilkan dalam kondisi ini.
Catatan
Anda dapat menerapkan pemantauan pengguna nyata dan buatan dengan memasukkan kode yang melacak dan menghitung waktu eksekusi pemanggilan metode dan bagian penting lainnya dari suatu aplikasi.
Pembuatan Profil. Pendekatan ini terutama ditargetkan untuk memantau dan meningkatkan performa aplikasi. Daripada beroperasi pada tingkat fungsional pemantauan pengguna nyata dan sintetis, pendekatan ini menangkap informasi tingkat yang lebih rendah saat aplikasi berjalan. Anda dapat menerapkan pembuatan profil dengan menggunakan pengambilan sampel berkala dari status eksekusi aplikasi (menentukan bagian kode yang dijalankan aplikasi pada titik waktu tertentu). Anda juga dapat menggunakan instrumentasi yang menyisipkan probe ke dalam kode pada saat-saat penting (seperti awal dan akhir panggilan metode) dan mencatat metode mana yang dipanggil, kapan, dan berapa lama setiap panggilan berlangsung. Anda kemudian dapat menganalisis data ini untuk menentukan bagian dari aplikasi yang dapat menyebabkan masalah performa.
Pemantauan titik akhir. Teknik ini menggunakan satu atau beberapa titik akhir diagnostik yang diekspos aplikasi secara khusus untuk mengaktifkan pemantauan. Titik akhir menyediakan jalur ke dalam kode aplikasi dan dapat menampilkan informasi tentang kesehatan sistem. Titik akhir yang berbeda dapat berfokus pada berbagai aspek fungsionalitas. Anda dapat menulis klien diagnostik Anda sendiri yang mengirimkan permintaan berkala ke titik akhir ini dan mengasimilasi tanggapannya. Untuk informasi selengkapnya, lihat Pola Pemantauan Titik Akhir Kesehatan.
Untuk cakupan yang maksimal, sebaiknya gunakan kombinasi dari teknik-teknik tersebut.
Menginstrumentasikan aplikasi
Instrumentasi adalah bagian penting dari proses pemantauan. Anda dapat membuat keputusan yang berarti tentang performa dan kesehatan sistem hanya jika Anda terlebih dahulu mengambil data yang memungkinkan Anda membuat keputusan ini. Informasi yang Anda kumpulkan dengan menggunakan instrumentasi sudah cukup untuk memungkinkan Anda menilai performa, mendiagnosis masalah, dan membuat keputusan tanpa mengharuskan Anda masuk ke server produksi jarak jauh untuk melakukan penelusuran (dan penelusuran kesalahan) secara manual. Data instrumentasi biasanya terdiri dari metrik dan informasi yang ditulis untuk melacak log.
Konten log jejak dapat berupa data tekstual yang ditulis oleh aplikasi atau data biner yang dibuat sebagai hasil dari peristiwa jejak, jika aplikasi menggunakan Event Tracing for Windows (ETW). Konten log jejak juga dapat dihasilkan dari log sistem yang merekam peristiwa yang muncul dari bagian infrastruktur, seperti server web. Pesan log tekstual sering didesain agar dapat dibaca manusia, tetapi juga harus ditulis dalam format yang memungkinkan sistem otomatis untuk menguraikannya dengan mudah.
Anda juga harus mengategorikan log. Jangan menulis semua data penelusuran ke satu log, tetapi gunakan log terpisah untuk merekam output penelusuran dari berbagai aspek operasional sistem. Anda kemudian dapat dengan cepat memfilter pesan log dengan membaca dari log yang sesuai daripada harus memproses satu file panjang. Jangan pernah menulis informasi yang memiliki persyaratan keamanan berbeda (seperti informasi audit dan data penelusuran kesalahan) ke log yang sama.
Catatan
Log mungkin diimplementasikan sebagai file pada sistem file, atau mungkin disimpan dalam beberapa format lain, seperti blob di penyimpanan blob. Informasi log mungkin juga disimpan di penyimpanan yang lebih terstruktur, seperti baris dalam tabel.
Metrik umumnya akan menjadi ukuran atau hitungan beberapa aspek atau sumber daya dalam sistem pada waktu tertentu, dengan satu atau beberapa tag atau dimensi terkait (terkadang disebut sampel). Satu instans metrik biasanya tidak berguna secara terpisah. Sebaliknya, metrik harus diambil dari waktu ke waktu. Masalah utama yang perlu dipertimbangkan adalah metrik mana yang harus Anda rekam dan seberapa sering. Menghasilkan data untuk metrik terlalu sering dapat menimbulkan beban tambahan yang signifikan pada sistem, sedangkan, mengambil secara jarang metrik dapat menyebabkan Anda melewatkan keadaan yang mengarah ke peristiwa penting. Pertimbangannya akan bervariasi dari metrik ke metrik. Misalnya, penggunaan CPU di server mungkin berbeda secara signifikan dari detik ke detik, tetapi penggunaan yang tinggi menjadi masalah hanya jika bertahan lama selama beberapa menit.
Informasi untuk menghubungkan data
Anda dapat dengan mudah memantau penghitung performa tingkat sistem individual, mengambil metrik untuk sumber daya, dan mendapatkan informasi pelacakan aplikasi dari berbagai file log. Tetapi berapa bentuk pemantauan memerlukan tahap analisis dan diagnostik dalam alur pemantauan untuk menghubungkan data yang diambil dari beberapa sumber. Data ini mungkin mengambil beberapa bentuk dalam data mentah, dan proses analisis harus dilengkapi dengan data instrumentasi yang memadai untuk dapat memetakan bentuk-bentuk yang berbeda ini. Misalnya, pada tingkat kerangka kerja aplikasi, tugas mungkin diidentifikasi oleh ID utas. Dalam aplikasi, pekerjaan yang sama mungkin terkait dengan ID pengguna untuk pengguna yang melakukan tugas itu.
Selain itu, tidak mungkin ada pemetaan 1:1 antara utas dan permintaan pengguna, karena operasi asinkron mungkin menggunakan kembali utas yang sama untuk melakukan operasi atas nama lebih dari satu pengguna. Untuk memperumit masalah selengkapnya, satu permintaan dapat ditangani oleh lebih dari satu utas saat eksekusi mengalir melalui sistem. Jika memungkinkan, kaitkan setiap permintaan dengan ID aktivitas unik yang disebarkan melalui sistem sebagai bagian dari konteks permintaan. (Teknik untuk menghasilkan dan menyertakan ID aktivitas dalam informasi penelusuran bergantung pada teknologi yang digunakan untuk menangkap data penelusuran.)
Semua data pemantauan harus diberi stempel waktu dengan cara yang sama. Untuk konsistensi, rekam semua tanggal dan waktu dengan menggunakan Waktu Universal Terkoordinasi. Ini akan membantu Anda menelusuri urutan peristiwa dengan lebih mudah.
Catatan
Komputer yang beroperasi di zona waktu dan jaringan yang berbeda mungkin tidak disinkronkan. Jangan bergantung pada penggunaan stempel waktu saja untuk menghubungkan data instrumentasi yang mencakup beberapa komputer.
Informasi yang harus disertakan dalam data instrumentasi
Pertimbangkan poin-poin berikut saat Anda memutuskan data instrumentasi mana yang perlu Anda kumpulkan:
Pastikan bahwa informasi yang ditangkap oleh peristiwa pelacakan dapat dibaca oleh komputer dan manusia. Mengadopsi skema yang terdefinisi dengan baik untuk informasi ini guna memfasilitasi pemrosesan otomatis data log di seluruh sistem, dan untuk memberikan konsistensi bagi staf operasi dan teknik yang membaca log. Sertakan informasi lingkungan, seperti lingkungan penyebaran, komputer tempat proses berjalan, detail proses, dan tumpukan panggilan.
Aktifkan pembuatan profil hanya jika diperlukan karena dapat memaksakan overhead yang signifikan pada sistem. Pembuatan profil dengan menggunakan instrumentasi merekam suatu peristiwa (seperti pemanggilan metode) setiap kali peristiwa itu terjadi, sedangkan pengambilan sampel hanya merekam peristiwa yang dipilih. Pilihan dapat berbasis waktu (sekali setiap n detik), atau berdasarkan frekuensi (sekali setiap n permintaan). Jika peristiwa sangat sering terjadi, pembuatan profil dengan instrumentasi dapat menyebabkan terlalu banyak beban dan memengaruhi performa secara keseluruhan itu sendiri. Dalam hal ini, pendekatan sampling mungkin lebih disukai. Namun, jika frekuensi peristiwanya rendah, pengambilan sampel mungkin terlewatkan. Dalam kasus ini, instrumentasi mungkin merupakan pendekatan yang lebih baik.
Berikan konteks yang memadai untuk memungkinkan pengembang atau administrator menentukan sumber setiap permintaan. Ini mungkin termasuk beberapa bentuk ID aktivitas yang mengidentifikasi instans permintaan tertentu. Ini juga dapat mencakup informasi yang dapat digunakan untuk menghubungkan aktivitas ini dengan pekerjaan komputasi yang dilakukan dan sumber daya yang digunakan. Perhatikan bahwa pekerjaan ini mungkin melintasi batas proses dan komputer. Untuk pengukuran, konteksnya juga harus mencakup (baik secara langsung atau tidak langsung melalui informasi terkait lainnya) referensi ke pelanggan yang menyebabkan permintaan dibuat. Konteks ini memberikan informasi berharga tentang status aplikasi pada saat data pemantauan diambil.
Rekam semua permintaan, dan lokasi atau wilayah tempat permintaan ini dibuat. Informasi ini dapat membantu dalam menentukan apakah ada hotspot khusus lokasi. Informasi ini juga dapat berguna dalam menentukan apakah akan mempartisi ulang aplikasi atau data yang digunakannya.
Rekam dan ambil detail pengecualian dengan hati-hati. Seringkali, informasi debug penting hilang sebagai akibat dari penanganan pengecualian yang buruk. Ambil detail lengkap pengecualian yang ditampilkan aplikasi, termasuk pengecualian dalam dan informasi konteks lainnya. Jika memungkinkan, sertakan tumpukan panggilan.
Konsisten dalam data yang diambil oleh berbagai elemen aplikasi Anda, karena ini dapat membantu dalam menganalisis peristiwa dan menghubungkannya dengan permintaan pengguna. Pertimbangkan untuk menggunakan paket pengelogan yang komprehensif dan dapat dikonfigurasi untuk mengumpulkan informasi, daripada bergantung pada pengembang untuk mengadopsi pendekatan yang sama saat pengembang menerapkan bagian sistem yang berbeda. Kumpulkan data dari penghitung performa utama, seperti volume I/O yang dilakukan, pemanfaatan jaringan, jumlah permintaan, penggunaan memori, dan pemanfaatan CPU. Beberapa layanan infrastruktur mungkin menyediakan penghitung performa spesifiknya sendiri, seperti jumlah koneksi ke database, kecepatan transaksi yang dilakukan, dan jumlah transaksi yang berhasil atau gagal. Aplikasi mungkin juga menentukan penghitung performa spesifiknya sendiri.
Catat semua panggilan yang dilakukan ke layanan eksternal, seperti sistem basis data, layanan web, atau layanan tingkat sistem lainnya yang merupakan bagian dari infrastruktur. Catat informasi tentang waktu yang dibutuhkan untuk melakukan setiap panggilan, dan keberhasilan atau kegagalan panggilan. Jika memungkinkan, ambil informasi tentang semua upaya coba lagi dan kegagalan untuk kesalahan sementara yang terjadi.
Memastikan kompatibilitas dengan sistem telemetri
Dalam banyak kasus, informasi yang dihasilkan instrumentasi dihasilkan sebagai rangkaian peristiwa dan diteruskan ke sistem telemetri terpisah untuk diproses dan dianalisis. Sistem telemetri biasanya tidak bergantung pada aplikasi atau teknologi tertentu, tetapi mengharapkan informasi mengikuti format tertentu yang biasanya ditentukan oleh skema. Skema secara efektif menentukan kontrak yang menentukan bidang data dan jenis yang dapat diserap oleh sistem telemetri. Skema harus digeneralisasi untuk memungkinkan data datang dari berbagai platform dan perangkat.
Skema umum harus mencakup bidang yang umum untuk semua peristiwa instrumentasi, seperti nama peristiwa, waktu peristiwa, alamat IP pengirim, dan detail yang diperlukan untuk menghubungkannya dengan peristiwa lain (seperti ID pengguna, ID perangkat, dan ID aplikasi). Ingat bahwa sejumlah perangkat dapat memunculkan peristiwa, jadi skema tidak boleh bergantung pada jenis perangkat. Selain itu, berbagai perangkat mungkin memunculkan peristiwa untuk aplikasi yang sama; aplikasi mungkin mendukung roaming atau bentuk lain dari distribusi lintas perangkat.
Skema mungkin juga menyertakan bidang domain yang relevan dengan skenario tertentu yang umum di berbagai aplikasi. Ini mungkin informasi tentang pengecualian, peristiwa awal dan akhir aplikasi, dan keberhasilan atau kegagalan panggilan API layanan web. Semua aplikasi yang menggunakan kumpulan bidang domain yang sama harus memancarkan kumpulan peristiwa yang sama, memungkinkan sekumpulan laporan dan analitik umum untuk dibangun.
Terakhir, skema mungkin berisi bidang kustom untuk mengambil detail peristiwa khusus aplikasi.
Praktik terbaik untuk aplikasi instrumentasi
Daftar berikut merangkum praktik terbaik untuk instrumentasi aplikasi terdistribusi yang berjalan di cloud.
Buat log mudah dibaca dan mudah diurai. Gunakan pengelogan terstruktur jika memungkinkan. Buat pesan log ringkas dan deskriptif.
Di semua log, identifikasi sumber dan berikan konteks dan informasi waktu saat setiap rekaman log ditulis.
Gunakan zona waktu dan format yang sama untuk semua stempel waktu. Ini akan membantu menghubungkan peristiwa untuk operasi yang mencakup perangkat keras dan layanan yang berjalan di berbagai wilayah geografis.
Kategorikan log dan tulis pesan ke file log yang sesuai.
Jangan mengungkapkan informasi sensitif tentang sistem atau informasi pribadi tentang pengguna. Hilangkan informasi ini sebelum dicatat, tetapi pastikan bahwa detail yang relevan dipertahankan. Misalnya, hapus ID dan kata sandi dari string koneksi database apa pun, tetapi tulis informasi yang tersisa ke log sehingga analis dapat menentukan bahwa sistem mengakses database yang benar. Catat semua pengecualian penting, tetapi aktifkan administrator untuk mengaktifkan dan menonaktifkan pengelogan untuk tingkat pengecualian dan peringatan yang lebih rendah. Juga, ambil dan catat semua informasi logika coba lagi. Data ini dapat berguna dalam memantau kesehatan sementara sistem.
Telusuri panggilan di luar proses, seperti permintaan ke layanan web eksternal atau database.
Jangan mencampur pesan log dengan persyaratan keamanan yang berbeda dalam file log yang sama. Misalnya, jangan menulis informasi debug dan audit ke log yang sama.
Dengan pengecualian peristiwa audit, pastikan bahwa semua panggilan pengelogan adalah operasi fire-and-forget yang tidak menghalangi kemajuan operasi bisnis. Peristiwa audit luar biasa karena sangat penting bagi bisnis dan dapat diklasifikasikan sebagai bagian mendasar dari operasi bisnis.
Pastikan pengelogan dapat diperluas dan tidak memiliki dependensi langsung pada target konkret. Misalnya, daripada menulis informasi dengan menggunakan System.Diagnostics.Trace, tentukan antarmuka abstrak (seperti ILogger) yang mengekspos metode pengelogan dan yang dapat diimplementasikan melalui cara apa pun yang sesuai.
Pastikan semua pengelogan gagal-aman dan tidak pernah memicu kesalahan kaskade. Pengelogan tidak boleh membuang pengecualian apa pun.
Perlakukan instrumentasi sebagai proses berulang yang berkelanjutan dan tinjau log secara teratur, bukan hanya saat ada masalah.
Mengumpulkan dan menyimpan data
Tahap pengumpulan proses pemantauan berkaitan dengan pengambilan informasi yang dihasilkan instrumentasi, memformat data ini untuk memudahkan tahap analisis / diagnosis untuk dikonsumsi, dan menyimpan data yang diubah dalam penyimpanan yang andal. Data instrumentasi yang Anda kumpulkan dari berbagai bagian sistem terdistribusi dapat disimpan di berbagai lokasi dan dengan berbagai format. Misalnya, kode aplikasi Anda mungkin menghasilkan file log penelusuran dan menghasilkan data log peristiwa aplikasi, sedangkan penghitung performa yang memantau aspek utama infrastruktur yang digunakan aplikasi Anda dapat ditangkap melalui teknologi lain. Setiap komponen dan layanan pihak ketiga yang digunakan aplikasi Anda mungkin memberikan informasi instrumentasi dalam format yang berbeda, dengan menggunakan file penelusuran terpisah, penyimpanan blob, atau bahkan penyimpanan data kustom.
Pengumpulan data sering dilakukan melalui layanan pengumpulan yang dapat berjalan secara mandiri dari aplikasi yang menghasilkan data instrumentasi. Gambar 2 mengilustrasikan contoh arsitektur ini, menyoroti subsistem pengumpulan data instrumentasi.

Gambar 2 - Mengumpulkan data instrumentasi.
Perhatikan bahwa ini adalah tampilan yang disederhanakan. Layanan pengumpulan tidak harus merupakan proses tunggal dan mungkin terdiri dari banyak bagian konstituen yang berjalan pada komputer yang berbeda, seperti yang dijelaskan di bagian berikut. Selain itu, jika analisis beberapa data telemetri harus dilakukan dengan cepat (analisis panas, seperti yang dijelaskan di bagian Mendukung analisis hot, warm, dan cold nanti dalam dokumen ini), komponen lokal yang beroperasi di luar layanan pengumpulan mungkin melakukan tugas analisis segera. Gambar 2 menggambarkan situasi ini untuk peristiwa yang dipilih. Setelah pemrosesan analitis, hasilnya dapat dikirim langsung ke subsistem visualisasi dan peringatan. Data yang mengalami analisis warm atau cold disimpan di penyimpanan sementara menunggu pemrosesan.
Untuk aplikasi dan layanan Azure, Azure Diagnostics menyediakan satu solusi yang memungkinkan untuk menangkap data. Azure Diagnostics mengumpulkan data dari sumber berikut untuk setiap node komputasi, menggabungkannya, lalu mengunggahnya ke Azure Storage:
- Log IIS
- Log Permintaan Gagal IIS
- Log peristiwa Windows
- Penghitung kinerja
- Crash dumps
- Log infrastruktur Diagnostik Azure
- Log kesalahan kustom
- .NET EventSource
- ETW berbasis manifes
Untuk informasi selengkapnya, lihat artikel Azure: Dasar-dasar Telemetri dan Pemecahan Masalah.
Strategi untuk mengumpulkan data instrumentasi
Mempertimbangkan sifat elastis cloud, dan untuk menghindari perlunya pengambilan data telemetri secara manual dari setiap node dalam sistem, Anda harus mengatur agar data ditransfer ke lokasi pusat dan dikonsolidasikan. Dalam sistem yang mencakup beberapa pusat data, mungkin berguna untuk terlebih dahulu mengumpulkan, mengkonsolidasikan, dan menyimpan data berdasarkan wilayah per wilayah, dan kemudian mengumpulkan data regional ke dalam satu sistem pusat.
Untuk mengoptimalkan penggunaan bandwidth, Anda dapat memilih untuk mentransfer data yang kurang mendesak dalam potongan, sebagai batch. Namun, data tidak boleh ditunda tanpa batas waktu, terutama jika berisi informasi sensitif waktu.
Penarikan dan pendorongan data instrumentasi
Subsistem pengumpulan data instrumentasi dapat secara aktif mengambil data instrumentasi dari berbagai log dan sumber lain untuk setiap instans aplikasi (model penarikan). Atau, dapat bertindak sebagai penerima pasif yang menunggu data dikirim dari komponen yang membentuk setiap instanse aplikasi (model pendorongan).
Salah satu pendekatan untuk menerapkan model tarik adalah dengan menggunakan agen pemantauan yang berjalan secara lokal dengan setiap instans aplikasi. Agen pemantauan adalah proses terpisah yang secara berkala mengambil (menarik) data telemetri yang dikumpulkan di node lokal dan menulis informasi ini secara langsung ke penyimpanan terpusat yang dibagikan oleh semua instans aplikasi. Ini adalah mekanisme yang diterapkan Azure Diagnostics. Setiap instans peran web atau pekerja Azure dapat dikonfigurasi untuk menangkap diagnostik dan informasi penelusuran lainnya yang disimpan secara lokal. Agen pemantauan yang berjalan bersama setiap instans menyalin data yang ditentukan ke Azure Storage. Artikel Mengaktifkan Diagnostik di Azure Cloud Services dan Mesin Virtual memberikan detail selengkapnya tentang proses ini. Beberapa elemen, seperti log IIS, crash dump, dan log kesalahan kustom, ditulis ke penyimpanan blob. Data dari log peristiwa Windows, peristiwa ETW, dan penghitung performa dicatat dalam penyimpanan tabel. Gambar 3 mengilustrasikan mekanisme ini.
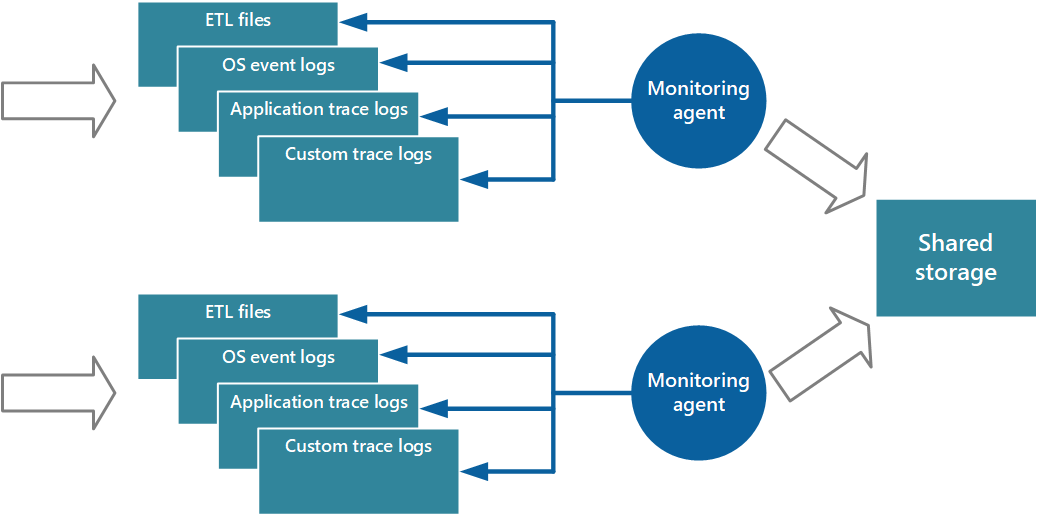
Gambar 3 - Menggunakan agen pemantauan untuk menarik informasi dan menulis ke penyimpanan bersama.
Catatan
Menggunakan agen pemantauan sangat cocok untuk menangkap data instrumentasi yang secara alami diambil dari sumber data. Contohnya adalah informasi dari SQL Server Dynamic Management Views atau panjang antrean Azure Service Bus.
Ini layak untuk menggunakan pendekatan yang baru saja dijelaskan untuk menyimpan data telemetri untuk aplikasi skala kecil yang berjalan pada sejumlah node di satu lokasi. Namun, aplikasi cloud global yang kompleks dan sangat dapat diskalakan mungkin menghasilkan volume data yang sangat besar dari ratusan peran web dan pekerja, pecahan database, dan layanan lainnya. Banjir data ini dapat dengan mudah membanjiri bandwidth I/O yang tersedia dengan satu lokasi terpusat. Oleh karena itu, solusi telemetri Anda harus dapat diskalakan untuk mencegahnya bertindak sebagai penghambat saat sistem berkembang. Idealnya, solusi Anda harus memasukkan tingkat redundansi untuk mengurangi risiko kehilangan informasi pemantauan penting (seperti audit atau data penagihan) jika bagian dari sistem gagal.
Untuk mengatasi masalah ini, Anda dapat menerapkan antrean, seperti yang ditunjukkan pada Gambar 4. Dalam arsitektur ini, agen pemantauan lokal (jika dapat dikonfigurasi dengan tepat) atau layanan pengumpulan data kustom (jika tidak) memposting data ke antrean. Proses terpisah yang berjalan secara asinkron (layanan penulisan penyimpanan pada Gambar 4) mengambil data dalam antrean ini dan menulisnya ke penyimpanan bersama. Antrean pesan cocok untuk skenario ini karena menyediakan semantik "setidaknya sekali" yang membantu memastikan bahwa data antrean tidak akan hilang setelah diposting. Anda dapat menerapkan layanan penulisan penyimpanan dengan menggunakan peran pekerja terpisah.

Gambar 4 - Menggunakan antrean untuk menyangga data instrumentasi.
Layanan pengumpulan data lokal dapat menambahkan data ke antrean segera setelah diterima. Antrean bertindak sebagai buffer, dan layanan penulisan penyimpanan dapat mengambil dan menulis data dengan kecepatannya sendiri. Secara default, antrean beroperasi berdasarkan first-in, first-out. Tetapi Anda dapat memprioritaskan pesan untuk mempercepatnya melalui antrean jika berisi data yang harus ditangani lebih cepat. Untuk informasi selengkapnya, lihat Pola Antrean Prioritas. Atau, Anda dapat menggunakan saluran yang berbeda (seperti topik Bus Layanan) untuk mengarahkan data ke tujuan yang berbeda tergantung pada bentuk pemrosesan analitik yang diperlukan.
Untuk skalabilitas, Anda dapat menjalankan beberapa instans layanan penulisan penyimpanan. Jika ada volume peristiwa yang tinggi, Anda dapat menggunakan hub peristiwa untuk mengirimkan data ke sumber daya komputasi yang berbeda untuk pemrosesan dan penyimpanan.
Mengkonsolidasikan data instrumentasi
Data instrumentasi yang diambil oleh layanan pengumpulan data dari satu instans aplikasi memberikan tampilan lokal tentang kesehatan dan performa instans tersebut. Untuk menilai kesehatan sistem secara keseluruhan, beberapa aspek data perlu dikonsolidasikan dalam tampilan lokal. Anda dapat melakukan ini setelah data disimpan, tetapi dalam beberapa kasus, Anda juga dapat mencapainya saat data dikumpulkan. Daripada ditulis langsung ke penyimpanan bersama, data instrumentasi dapat melewati layanan konsolidasi data terpisah yang menggabungkan data dan bertindak sebagai filter dan proses pembersihan. Misalnya, data instrumentasi yang menyertakan informasi korelasi yang sama seperti ID aktivitas dapat digabungkan. (Ada kemungkinan bahwa pengguna mulai melakukan operasi bisnis pada satu simpul dan kemudian ditransfer ke node lain jika terjadi kegagalan node, atau tergantung pada bagaimana penyeimbangan beban dikonfigurasi.) Proses ini juga dapat mendeteksi dan menghapus data duplikat apa pun (selalu ada kemungkinan jika layanan telemetri menggunakan antrean pesan untuk mendorong data instrumentasi ke penyimpanan). Gambar 5 menggambarkan contoh struktur ini.

Gambar 5 - Menggunakan layanan terpisah untuk menggabungkan dan membersihkan data instrumentasi.
Menyimpan data instrumentasi
Diskusi sebelumnya telah menggambarkan pandangan yang agak sederhana tentang cara penyimpanan data instrumentasi. Pada kenyataannya, masuk akal untuk menyimpan berbagai jenis informasi dengan menggunakan teknologi yang paling sesuai dengan cara di mana setiap jenis kemungkinan akan digunakan.
Misalnya, Azure blob dan penyimpanan tabel memiliki beberapa kesamaan dalam cara mengaksesnya. Tetapi mereka memiliki keterbatasan dalam operasi yang dapat Anda lakukan dengan menggunakannya, dan granularitas data yang mereka pegang sangat berbeda. Jika Anda perlu melakukan lebih banyak operasi analitik atau memerlukan kemampuan pencarian teks lengkap pada data, mungkin lebih tepat menggunakan penyimpanan data yang menyediakan kemampuan yang dioptimalkan untuk jenis kueri dan akses data tertentu. Contohnya:
- Data penghitung performa dapat disimpan dalam database SQL untuk mengaktifkan analisis ad hoc.
- Log pelacakan mungkin lebih baik disimpan di Azure Cosmos DB.
- Informasi keamanan dapat ditulis ke HDFS.
- Informasi yang memerlukan pencarian teks lengkap dapat disimpan melalui Elasticsearch (yang juga dapat mempercepat pencarian menggunakan beragam pengindeksan).
Anda dapat menerapkan layanan tambahan yang secara berkala mengambil data dari penyimpanan bersama, mempartisi dan memfilter data sesuai dengan tujuannya, dan kemudian menulisnya ke kumpulan penyimpanan data yang sesuai seperti yang ditunjukkan pada Gambar 6. Pendekatan alternatif adalah memasukkan fungsionalitas ini dalam proses konsolidasi dan pembersihan dan menulis data langsung ke penyimpanan ini saat diambil ketimbang menyimpannya di area penyimpanan bersama perantara. Setiap pendekatan memiliki kelebihan dan kekurangan. Menerapkan layanan partisi terpisah mengurangi beban pada layanan konsolidasi dan pembersihan, dan memungkinkan setidaknya beberapa data yang dipartisi dibuat ulang jika perlu (bergantung pada berapa banyak data yang disimpan dalam penyimpanan bersama). Namun, langkah ini menghabiskan sumber daya tambahan. Selain itu, mungkin ada penundaan antara penerimaan data instrumentasi dari setiap instans aplikasi dan konversi data ini menjadi informasi yang dapat ditindaklanjuti.

Gambar 6 - Membagi data sesuai dengan persyaratan analitis dan penyimpanan.
Data instrumentasi yang sama mungkin diperlukan untuk lebih dari satu tujuan. Misalnya, penghitung performa dapat digunakan untuk memberikan pandangan historis performa sistem dari waktu ke waktu. Informasi ini mungkin digabungkan dengan data penggunaan lain untuk menghasilkan informasi penagihan pelanggan. Dalam situasi ini, data yang sama mungkin dikirim ke lebih dari satu tujuan, seperti database dokumen yang dapat bertindak sebagai penyimpanan jangka panjang untuk menyimpan informasi penagihan, dan penyimpanan multidimensi untuk menangani analisis performa yang kompleks.
Anda juga harus mempertimbangkan seberapa mendesak data tersebut diperlukan. Data yang menyediakan informasi untuk peringatan harus diakses dengan cepat, sehingga harus disimpan dalam penyimpanan data yang cepat dan diindeks atau terstruktur untuk mengoptimalkan kueri yang dilakukan sistem peringatan. Dalam beberapa kasus, layanan telemetri yang mengumpulkan data pada setiap node mungkin perlu untuk memformat dan menyimpan data secara lokal sehingga instans lokal dari sistem peringatan dapat dengan cepat memberi tahu Anda tentang masalah apa pun. Data yang sama dapat dikirim ke layanan penulisan penyimpanan yang ditunjukkan pada diagram sebelumnya dan disimpan secara terpusat jika juga diperlukan untuk tujuan lain.
Informasi yang digunakan untuk analisis yang lebih dipertimbangkan, untuk pelaporan, dan untuk melihat tren historis kurang mendesak dan dapat disimpan dengan cara yang mendukung penggalian data dan kueri ad hoc. Untuk informasi selengkapnya, lihat bagian Mendukung analisis hot, warm, dan cold nanti dalam dokumen ini.
Rotasi log dan retensi data
Instrumentasi dapat menghasilkan volume data yang cukup besar. Data ini dapat disimpan di beberapa tempat, mulai dengan file log mentah, file penelusuran, dan informasi lain yang diambil di setiap node hingga tampilan data yang dikonsolidasi, dibersihkan, dan dipartisi yang disimpan di penyimpanan bersama. Dalam beberapa kasus, setelah data diproses dan ditransfer, data sumber mentah asli dapat dihapus dari setiap node. Dalam kasus lain, mungkin perlu atau berguna untuk menyimpan informasi mentah. Misalnya, data yang dihasilkan untuk tujuan penelusuran kesalahan mungkin sebaiknya dibiarkan tersedia dalam bentuk mentahnya tetapi kemudian dapat dibuang dengan cepat setelah bug diperbaiki.
Data performa sering kali memiliki masa pakai yang lebih lama sehingga dapat digunakan untuk melihat tren performa dan untuk perencanaan kapasitas. Tampilan gabungan dari data ini biasanya disimpan online untuk jangka waktu terbatas untuk memungkinkan akses cepat. Setelah itu, tampilan tersebut dapat diarsipkan atau dibuang. Data yang dikumpulkan untuk pengukuran dan penagihan pelanggan mungkin perlu disimpan tanpa batas waktu. Selain itu, persyaratan peraturan mungkin menentukan bahwa informasi yang dikumpulkan untuk tujuan audit dan keamanan juga perlu diarsipkan dan disimpan. Data ini juga sensitif dan mungkin perlu dienkripsi atau dilindungi untuk mencegah gangguan. Anda tidak boleh merekam kata sandi pengguna atau informasi lain yang mungkin digunakan untuk melakukan penipuan identitas. Detail tersebut harus dihapus dari data sebelum disimpan.
Down-sampling
Hal ini berguna untuk menyimpan data historis sehingga Anda dapat melihat tren jangka panjang. Daripada menyimpan data lama secara keseluruhan, Anda dapat menurunkan sampel data untuk mengurangi resolusi dan menghemat biaya penyimpanan. Sebagai contoh, daripada menyimpan indikator performa menit demi menit, Anda dapat menggabungkan data yang berumur lebih dari satu bulan untuk membentuk tampilan jam demi jam.
Praktik terbaik untuk mengumpulkan dan menyimpan informasi logging
Daftar berikut merangkum praktik terbaik untuk menangkap dan menyimpan informasi pengelogan:
Agen pemantauan atau layanan pengumpulan data harus dijalankan sebagai layanan di luar proses dan harus mudah diterapkan.
Semua keluaran dari agen pemantauan atau layanan pengumpulan data harus dalam format agnostik yang tidak bergantung pada mesin, sistem operasi, atau protokol jaringan. Misalnya, memancarkan informasi dalam format self-describing seperti JSON, MessagePack, atau Protobuf daripada ETL/ETW. Menggunakan format standar memungkinkan sistem untuk membangun alur pemrosesan; komponen yang membaca, mengubah, dan mengirim data dalam format yang disepakati dapat dengan mudah diintegrasikan.
Proses pemantauan dan pengumpulan data harus aman dari kegagalan dan tidak boleh memicu kondisi kesalahan berjenjang.
Jika terjadi kegagalan sementara dalam pengiriman informasi ke data sink, agen pemantau atau layanan pengumpulan data harus bersiap untuk menyusun ulang data telemetri sehingga informasi terbaru dikirim terlebih dahulu. (Agen pemantau/layanan pengumpulan data mungkin memilih untuk menghapus data lama, atau menyimpannya secara lokal dan mengirimkannya nanti untuk mengejar, atas kebijakannya sendiri.)
Menganalisis data dan mendiagnosis masalah
Bagian penting dari proses pemantauan dan diagnostik adalah menganalisis data yang dikumpulkan untuk mendapatkan gambaran tentang kesejahteraan keseluruhan sistem. Anda seharusnya mendefinisikan KPI dan metrik performa Anda sendiri, dan penting untuk memahami bagaimana Anda dapat menyusun data yang telah dikumpulkan untuk memenuhi persyaratan analisis Anda. Penting juga untuk memahami bagaimana data yang ditangkap dalam metrik dan file log yang berbeda berkorelasi, karena informasi ini dapat menjadi kunci untuk melacak urutan peristiwa dan membantu mendiagnosis masalah yang muncul.
Seperti yang dijelaskan di bagian Menggabungkan data instrumentasi, data untuk setiap bagian sistem biasanya diambil secara lokal, tetapi umumnya perlu digabungkan dengan data yang dihasilkan di situs lain yang berpartisipasi dalam sistem. Informasi ini membutuhkan korelasi yang cermat untuk memastikan bahwa data digabungkan secara akurat. Misalnya, data penggunaan untuk suatu operasi mungkin menjangkau node yang menghosting situs web yang terhubung dengan pengguna, node yang menjalankan layanan terpisah yang diakses sebagai bagian dari operasi ini, dan penyimpanan data yang disimpan di node lain. Informasi ini perlu diikat bersama untuk memberikan pandangan keseluruhan tentang penggunaan sumber daya dan pemrosesan untuk operasi. Beberapa pra-pemrosesan dan pemfilteran data mungkin terjadi pada simpul tempat data diambil, sedangkan agregasi dan pemformatan lebih mungkin terjadi pada simpul pusat.
Mendukung analisis hot, warm, dan cold
Menganalisis dan memformat ulang data untuk tujuan visualisasi, pelaporan, dan peringatan dapat menjadi proses kompleks yang mengonsumsi sumber dayanya sendiri. Beberapa bentuk pemantauan memerlukan waktu yang kritis dan memerlukan analisis data segera agar efektif. Ini dikenal sebagai analisis hot. Contohnya termasuk analisis yang diperlukan untuk peringatan dan beberapa aspek pemantauan keamanan (seperti mendeteksi serangan pada sistem). Data yang diperlukan untuk tujuan ini harus tersedia dengan cepat dan terstruktur untuk pemrosesan yang efisien. Dalam beberapa kasus, mungkin perlu untuk memindahkan pemrosesan analisis ke node individu tempat data disimpan.
Bentuk lain dari analisis kurang kritis waktu dan mungkin memerlukan beberapa komputasi dan agregasi setelah data mentah diterima. Ini disebut analisis warm. Analisis performa sering termasuk dalam kategori ini. Dalam hal ini, peristiwa performa tunggal yang terisolasi tidak mungkin signifikan secara statistik. (Ini mungkin disebabkan oleh lonjakan atau kesalahan mendadak.) Data dari serangkaian peristiwa harus memberikan gambaran performa sistem yang lebih andal.
Analisis hangat juga dapat digunakan untuk membantu mendiagnosis masalah kesehatan. Peristiwa kesehatan biasanya diproses melalui analisis hot dan dapat segera meningkatkan peringatan. Seorang operator harus dapat menelusuri alasan untuk peristiwa kesehatan dengan memeriksa data dari jalur warm. Data ini harus berisi informasi tentang peristiwa yang mengarah ke masalah yang menyebabkan peristiwa kesehatan.
Beberapa jenis pemantauan menghasilkan lebih banyak data jangka panjang. Analisis ini dapat dilakukan di kemudian hari, mungkin sesuai dengan jadwal yang telah ditentukan. Dalam beberapa kasus, analisis mungkin perlu melakukan penyaringan kompleks dari sejumlah besar data yang diambil selama periode waktu tertentu. Ini disebut analisis cold. Persyaratan utama adalah bahwa data disimpan dengan aman setelah diambil. Misalnya, pemantauan dan audit penggunaan memerlukan gambaran yang akurat tentang status sistem pada titik waktu reguler, tetapi informasi status ini tidak harus tersedia untuk diproses segera setelah dikumpulkan.
Operator juga dapat menggunakan analisis cold guna menyediakan data untuk analisis kesehatan prediktif. Operator dapat mengumpulkan informasi historis selama periode tertentu dan menggunakannya bersama dengan data kesehatan saat ini (diambil dari jalur hot) untuk melihat tren yang mungkin segera menyebabkan masalah kesehatan. Dalam kasus ini, mungkin perlu untuk meningkatkan peringatan sehingga tindakan korektif dapat diambil.
Mengkorelasikan data
Data yang ditangkap oleh instrumentasi dapat memberikan gambaran tentang status sistem, tetapi tujuan analisis adalah membuat data ini dapat ditindaklanjuti. Contohnya:
- Apa yang menyebabkan pemuatan I/O yang intens pada tingkat sistem pada waktu tertentu?
- Apakah ini adalah hasil dari operasi database dengan jumlah besar?
- Apakah ini tercermin dalam waktu respons database, jumlah transaksi per detik, dan waktu respons aplikasi pada saat yang sama?
Jika demikian, satu tindakan perbaikan yang mungkin mengurangi beban mungkin dengan membagi data ke lebih banyak server. Selain itu, pengecualian dapat muncul sebagai akibat dari kesalahan di tingkat sistem mana pun. Pengecualian dalam satu tingkat sering memicu kesalahan lain pada tingkat di atas.
Untuk alasan ini, Anda harus dapat menghubungkan berbagai jenis data pemantauan di setiap tingkat untuk menghasilkan tampilan keseluruhan dari status sistem dan aplikasi yang berjalan di dalamnya. Anda kemudian dapat menggunakan informasi ini untuk membuat keputusan tentang apakah sistem berfungsi dengan baik atau tidak, dan menentukan apa yang dapat dilakukan untuk meningkatkan kualitas sistem.
Seperti yang dijelaskan di bagian Informasi untuk data yang berkorelasi, Anda harus memastikan bahwa data instrumentasi mentah menyertakan informasi konteks dan ID aktivitas yang memadai untuk mendukung agregasi yang diperlukan untuk peristiwa yang berkorelasi. Selain itu, data ini dapat disimpan dalam format yang berbeda, dan mungkin Anda perlu mengurai informasi ini untuk mengubahnya menjadi format standar untuk analisis.
Memecahkan dan mendiagnosis masalah
Diagnosis memerlukan kemampuan untuk menentukan penyebab kesalahan atau perilaku yang tidak diharapkan, termasuk melakukan analisis akar penyebab. Informasi yang diperlukan biasanya mencakup:
- Informasi terperinci dari log peristiwa dan jejak, baik untuk seluruh sistem atau untuk subsistem tertentu selama kurun waktu tertentu.
- Jejak tumpukan lengkap yang dihasilkan dari pengecualian dan kesalahan dari setiap tingkat tertentu yang terjadi dalam sistem atau subsistem tertentu selama periode tertentu.
- Crash dump untuk setiap proses yang gagal, baik dalam sistem atau untuk subsistem tertentu selama kurun waktu tertentu.
- Log aktivitas merekam operasi yang dilakukan baik oleh semua pengguna atau untuk pengguna yang dipilih selama periode tertentu.
Menganalisis data untuk tujuan pemecahan masalah biasanya membutuhkan pemahaman teknis yang mendalam tentang arsitektur sistem dan berbagai komponen yang dapat menjadi solusi. Akibatnya, sebagian besar intervensi manual sering diperlukan untuk menafsirkan data, menetapkan penyebab masalah, dan merekomendasikan strategi yang tepat untuk memperbaikinya. Mungkin Anda hanya perlu menyimpan salinan informasi ini dalam format aslinya dan membuatnya tersedia untuk analisis dingin oleh seorang ahli.
Memvisualisasikan data dan meningkatkan peringatan
Aspek penting dari setiap sistem pemantauan adalah kemampuan untuk menyajikan data sedemikian rupa sehingga operator dapat dengan cepat melihat tren atau masalah apa pun. Yang juga penting adalah kemampuan untuk dengan cepat memberi tahu operator jika peristiwa signifikan telah terjadi yang mungkin memerlukan perhatian.
Presentasi data dapat mengambil beberapa bentuk, termasuk visualisasi dengan menggunakan dasbor, peringatan, dan pelaporan.
Visualisasi dengan menggunakan dasbor
Cara paling umum untuk memvisualisasikan data adalah dengan menggunakan dasbor yang dapat menampilkan informasi sebagai serangkaian grafik, grafik, atau ilustrasi lainnya. Item ini dapat diparameterisasi, dan seorang analis harus dapat memilih parameter penting (seperti periode waktu) untuk situasi tertentu.
Dasbor dapat diatur secara hierarkis. Dasbor tingkat atas dapat memberikan tampilan keseluruhan dari setiap aspek sistem tetapi memungkinkan operator untuk menelusuri detailnya. Misalnya, dasbor yang menunjukkan disk I/O keseluruhan untuk sistem harus memungkinkan analis untuk melihat tarif I/O untuk setiap disk individu untuk memastikan apakah satu atau lebih perangkat tertentu memperhitungkan volume lalu lintas yang tidak proporsional. Idealnya, dasbor juga harus menampilkan informasi terkait, seperti sumber setiap permintaan (pengguna atau aktivitas) yang menghasilkan I/O ini. Informasi ini kemudian dapat digunakan untuk menentukan apakah (dan bagaimana) untuk menyebarkan beban lebih merata di seluruh perangkat, dan apakah sistem akan berperforma lebih baik jika lebih banyak perangkat ditambahkan.
Dasbor juga dapat menggunakan pengkodean warna atau beberapa isyarat visual lainnya untuk menunjukkan nilai yang tampak anomali atau yang berada di luar kisaran yang diharapkan. Menggunakan contoh sebelumnya:
- Disk dengan tingkat I/O yang mendekati kapasitas maksimumnya dalam jangka waktu yang lama (disk hot) dapat disorot dengan warna merah.
- Disk dengan tingkat I/O yang secara berkala berjalan pada batas maksimumnya dalam waktu singkat (disk hot) dapat disorot dengan warna kuning.
- Disk yang menampilkan penggunaan normal dapat ditampilkan dalam warna hijau.
Perhatikan bahwa agar sistem dasbor berfungsi secara efektif, ia harus memiliki data mentah untuk digunakan. Jika Anda sedang membangun sistem dasbor Anda sendiri, atau menggunakan dasbor yang dikembangkan oleh organisasi lain, Anda harus memahami data instrumentasi mana yang perlu Anda kumpulkan, pada tingkat perincian apa, dan bagaimana formatnya harus digunakan untuk dasbor.
Dasbor yang baik tidak hanya menampilkan informasi, tetapi juga memungkinkan seorang analis untuk mengajukan pertanyaan ad hoc tentang informasi tersebut. Beberapa sistem menyediakan alat manajemen yang dapat digunakan operator untuk melakukan tugas-tugas ini dan menjelajahi data yang mendasarinya. Alternatifnya, bergantung pada repositori yang digunakan untuk menyimpan informasi ini, data ini dapat dikueri secara langsung, atau diimpor ke alat seperti Microsoft Excel untuk analisis dan pelaporan selengkapnya.
Catatan
Anda harus membatasi akses ke dasbor hanya untuk personel yang berwenang, karena informasi ini mungkin sensitif secara komersial. Anda juga harus melindungi data yang mendasari dasbor untuk mencegah pengguna mengubahnya.
Meningkatkan peringatan
Peringatan adalah proses menganalisis data pemantauan dan instrumentasi serta menghasilkan pemberitahuan jika suatu peristiwa penting terdeteksi.
Peringatan membantu memastikan bahwa sistem tetap sehat, responsif, dan aman. Ini adalah bagian penting dari sistem apa pun yang membuat jaminan performa, ketersediaan, dan privasi kepada pengguna saat data mungkin perlu segera ditindaklanjuti. Operator mungkin perlu diberi tahu tentang peristiwa yang memicu peringatan. Peringatan juga dapat digunakan untuk menjalankan fungsi sistem seperti penskalaan otomatis.
Peringatan biasanya tergantung pada data instrumentasi berikut:
- Peristiwa keamanan. Jika log peristiwa menunjukkan bahwa kegagalan autentikasi atau otorisasi berulang terjadi, sistem mungkin sedang diserang dan operator harus diberi tahu.
- Metrik performa. Sistem harus merespons dengan cepat jika metrik performa tertentu melebihi ambang batas yang ditentukan.
- Informasi ketersediaan. Jika kesalahan terdeteksi, mungkin perlu untuk menghidupkan ulang satu atau lebih subsistem dengan cepat, atau melakukan failover ke sumber daya cadangan. Kesalahan berulang dalam subsistem dapat menunjukkan masalah yang lebih serius.
Operator mungkin menerima informasi peringatan dengan menggunakan banyak saluran pengiriman seperti email, perangkat pager, atau pesan teks SMS. Peringatan mungkin juga mencakup indikasi seberapa kritis suatu situasi. Banyak sistem peringatan mendukung grup pelanggan, dan semua operator yang tergabung dalam grup yang sama dapat menerima rangkaian peringatan yang sama.
Sistem peringatan harus dapat disesuaikan, dan nilai yang sesuai dari data instrumentasi yang mendasarinya dapat diberikan sebagai parameter. Pendekatan ini memungkinkan operator untuk menyaring data dan fokus pada ambang batas atau kombinasi nilai yang menarik. Perhatikan bahwa dalam beberapa kasus, data instrumentasi mentah dapat diberikan ke sistem peringatan. Dalam situasi lain, mungkin lebih tepat untuk menyediakan data agregat. (Misalnya, peringatan dapat dipicu jika penggunaan CPU untuk sebuah node telah melebihi 90 persen selama 10 menit terakhir). Detail yang diberikan ke sistem peringatan juga harus mencakup ringkasan dan informasi konteks yang sesuai. Data ini dapat membantu mengurangi kemungkinan peristiwa positif palsu akan memicu peringatan.
Pelaporan
Pelaporan digunakan untuk menghasilkan tampilan keseluruhan sistem. Ini mungkin menggabungkan data historis di samping informasi terkini. Persyaratan pelaporan sendiri terbagi dalam dua kategori besar: pelaporan operasional dan pelaporan keamanan.
Pelaporan operasional biasanya mencakup aspek-aspek berikut:
- Menggabungkan statistik yang dapat Anda gunakan untuk memahami pemanfaatan sumber daya dari keseluruhan sistem atau subsistem tertentu selama jendela waktu tertentu.
- Mengidentifikasi tren dalam penggunaan sumber daya untuk keseluruhan sistem atau subsistem tertentu selama periode tertentu.
- Memantau pengecualian yang telah terjadi di seluruh sistem atau di subsistem tertentu selama periode tertentu.
- Menentukan efisiensi aplikasi dalam hal sumber daya yang disebarkan, dan memahami apakah volume sumber daya (dan biaya yang terkait) dapat dikurangi tanpa mempengaruhi performa yang tidak perlu.
Pelaporan keamanan berkaitan dengan penelusuran penggunaan sistem oleh pelanggan. Yang mencakup:
- Mengaudit operasi pengguna. Ini memerlukan perekaman permintaan individual yang dilakukan setiap pengguna, bersama dengan tanggal dan waktu. Data harus disusun untuk memungkinkan administrator dengan cepat merekonstruksi urutan operasi yang dilakukan pengguna selama periode tertentu.
- Melacak penggunaan sumber daya oleh pengguna. Metode ini memerlukan perekaman bagaimana setiap permintaan untuk pengguna mengakses berbagai sumber daya yang menyusun sistem, dan untuk berapa lama. Administrator harus dapat menggunakan data ini untuk menghasilkan laporan penggunaan oleh pengguna selama periode tertentu, mungkin untuk tujuan penagihan.
Dalam banyak kasus, proses batch dapat menghasilkan laporan sesuai dengan jadwal yang ditentukan. (Latensi biasanya bukan masalah.) Tetapi mereka juga harus tersedia untuk generasi berdasarkan ad hoc jika diperlukan. Sebagai contoh, jika Anda menyimpan data dalam database hubungan seperti Azure SQL Database, Anda dapat menggunakan alat seperti SQL Server Reporting Services untuk mengekstrak dan memformat data dan menyajikannya sebagai kumpulan laporan.
Langkah berikutnya
- Gambaran Umum Azure Monitor
- Memantau, mendiagnosis, dan memecahkan masalah Microsoft Azure Storage
- Sekilas tentang pemberitahuan di Microsoft Azure
- Melihat pemberitahuan kesehatan layanan dengan menggunakan portal Azure
- Apa itu Application Insights?
- Diagnostik kinerja komputer virtual Azure
- Unduh dan instal SQL Server Data Tools (SSDT) untuk Visual Studio
Sumber daya terkait
- Panduan penskalaan otomatis menjelaskan cara mengurangi overhead manajemen dengan mengurangi kebutuhan operator untuk terus memantau performa sistem dan membuat keputusan tentang menambah atau menghapus sumber daya.
- Pola Pemantauan Titik Akhir Kesehatan menjelaskan cara menerapkan pemeriksaan fungsional dalam aplikasi yang dapat diakses oleh alat eksternal melalui titik akhir yang terbuka secara berkala.
- Pola Antrean Prioritas menunjukkan cara memprioritaskan pesan dalam antrean sehingga permintaan yang mendesak diterima dan dapat diproses sebelum pesan yang kurang mendesak.