Masalah umum yang dihadapi organisasi adalah bagaimana mengumpulkan data dari berbagai sumber, dalam berbagai format. Maka Anda harus memindahkannya ke satu atau lebih penyimpanan data. Tujuan mungkin bukan jenis penyimpanan data yang sama dengan sumbernya. Seringkali formatnya berbeda, atau data perlu dibentuk atau dibersihkan sebelum memuatnya ke tujuan akhir.
Berbagai alat, layanan, dan proses telah dikembangkan selama bertahun-tahun untuk membantu mengatasi tantangan ini. Tidak peduli proses yang digunakan, ada kebutuhan umum untuk mengkoordinasikan pekerjaan dan menerapkan beberapa tingkat transformasi data dalam pipa data. Bagian berikut menyoroti metode umum yang digunakan untuk melakukan tugas-tugas ini.
Proses ekstrak, transformasi, muat (ETL)
extract, transform, load (ETL) adalah alur data yang digunakan untuk mengumpulkan data dari berbagai sumber. Kemudian mengubah data sesuai dengan aturan bisnis, dan memuat data ke penyimpanan data tujuan. Pekerjaan transformasi di ETL berlangsung di mesin khusus, dan sering melibatkan penggunaan tabel pementasan untuk sementara menyimpan data saat sedang diubah dan akhirnya dimuat ke tujuannya.
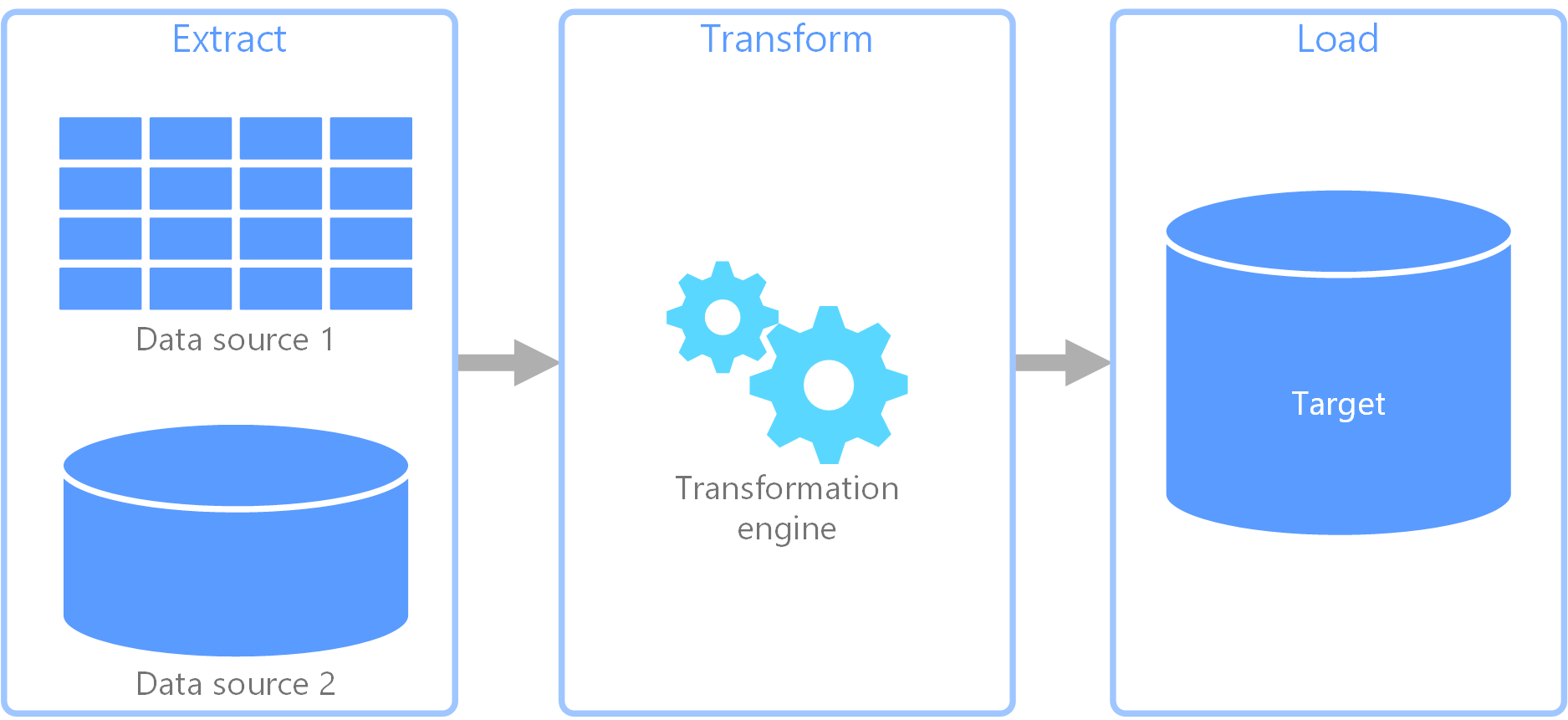
Transformasi data yang terjadi biasanya melibatkan berbagai operasi, seperti penyaringan, penyortiran, penggabungan, penggabungan data, membersihkan data, menghilangkan duplikasi, dan validasi data.
Seringkali, tiga fase ETL dijalankan secara paralel untuk menghemat waktu. Misalnya, sementara data sedang diekstraksi, proses transformasi dapat bekerja pada data yang sudah diterima dan mempersiapkannya untuk memuat, dan proses pemuatan dapat mulai mengerjakan data yang disiapkan, daripada menunggu seluruh proses ekstraksi selesai.
Layanan Azure yang relevan:
Alat lain:
Ekstrak, muat, transformasi (ELT)
Ekstrak, muat, transformasi (ELT) berbeda dari ETL semata-mata di mana transformasi terjadi. Dalam alur ELT, transformasi terjadi di penyimpanan data target. Alih-alih menggunakan mesin transformasi terpisah, kemampuan pemrosesan penyimpanan data target digunakan untuk mengubah data. Ini menyederhanakan arsitektur dengan menghapus mesin transformasi dari alur. Manfaat lain untuk pendekatan ini adalah bahwa penskalaan penyimpanan data target juga menskalakan performa alur ELT. Namun, ELT hanya bekerja dengan baik ketika sistem target cukup kuat untuk mengubah data secara efisien.
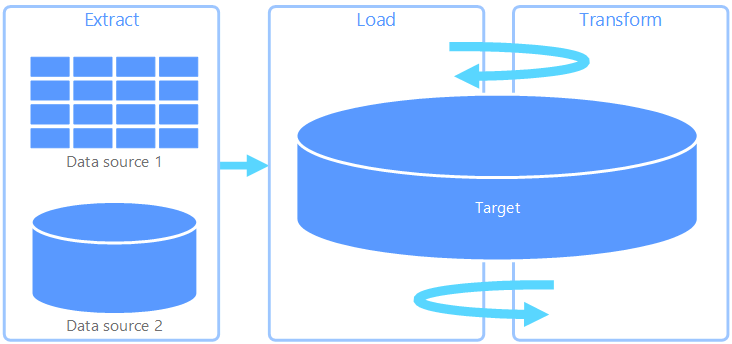
Kasus penggunaan khas untuk ELT termasuk dalam ranah data besar. Misalnya, Anda mungkin mulai dengan mengekstrak semua data sumber ke file datar dalam penyimpanan yang dapat diskalakan, seperti Sistem File Terdistribusi Hadoop, penyimpanan blob Azure, atau Azure Data Lake gen 2 (atau kombinasi). Teknologi, seperti Spark, Apache Hive, atau PolyBase, kemudian dapat digunakan untuk mengkueri data sumber. Poin utama dengan ELT adalah bahwa penyimpanan data yang digunakan untuk melakukan transformasi adalah penyimpanan data yang sama di mana data akhirnya dikonsumsi. Penyimpanan data ini berbunyi langsung dari penyimpanan yang dapat diskalakan, alih-alih memuat data ke penyimpanan miliknya sendiri. Pendekatan ini melewatkan langkah salinan data yang ada di ETL, yang seringkali dapat menjadi operasi yang memakan waktu untuk himpunan data besar.
Dalam praktiknya, penyimpanan data target adalah gudang data menggunakan kluster Hadoop (menggunakan Apache Hive atau Spark) atau kumpulan khusus SQL di Azure Synapse Analytics. Secara umum, skema dilapisi pada data file datar pada waktu kueri dan disimpan sebagai tabel, memungkinkan data untuk ditanyakan seperti tabel lain di penyimpanan data. Ini disebut sebagai tabel eksternal karena data tidak berada di penyimpanan yang dikelola oleh penyimpanan data itu sendiri, tetapi pada beberapa penyimpanan eksternal yang dapat diskalakan seperti penyimpanan Azure Data Lake atau penyimpanan blob Azure.
Penyimpanan data hanya mengelola skema data dan menerapkan skema saat dibaca. Misalnya, kluster Hadoop menggunakan Apache Hive akan menggambarkan tabel Apache Hive di mana sumber data secara efektif merupakan jalur ke satu set file dalam HDFS. Di Azure Synapse, PolyBase dapat mencapai hasil yang sama — membuat tabel terhadap data yang disimpan secara eksternal ke database itu sendiri. Setelah data sumber dimuat, data yang ada dalam tabel eksternal dapat diproses menggunakan kemampuan penyimpanan data. Dalam skenario big data, ini berarti penyimpanan data harus mampu diproses secara paralel secara besar-besaran (MPP), yang memecah data menjadi potongan yang lebih kecil dan mendistribusikan pemrosesan potongan di beberapa node secara paralel.
Fase akhir dari alur ELT biasanya untuk mengubah data sumber menjadi format akhir yang lebih efisien untuk jenis kueri yang perlu didukung. Misalnya, data dapat dipartisi. Selain itu, ELT mungkin menggunakan format penyimpanan yang dioptimalkan seperti Parquet, yang menyimpan data berorientasi baris secara kolumnis dan menyediakan pengindeksan yang dioptimalkan.
Layanan Azure yang relevan:
- SQL kumpulan khusus di Azure Synapse Analytics
- SQL kumpulan tanpa server di Azure Synapse Analytics
- HDInsight dengan Apache Hive
- Azure Data Factory
- Datamarts di Power BI
Alat lain:
Aliran data dan aliran kontrol
Dalam konteks alur data, alur kontrol memastikan pemrosesan tugas yang teratur. Untuk menegakkan urutan pemrosesan yang benar dari tugas-tugas ini, batasan prioritas digunakan. Anda dapat menganggap batasan ini sebagai konektor dalam diagram alur kerja, seperti yang ditunjukkan pada gambar di bawah ini. Setiap tugas memiliki hasil, seperti keberhasilan, kegagalan, atau penyelesaian. Setiap tugas berikutnya tidak memulai pemrosesan sampai pendahulunya selesai dengan salah satu hasil ini.
Aliran kontrol mengeksekusi aliran data sebagai tugas. Dalam tugas aliran data, data diekstraksi dari sumber, diubah, atau dimuat ke dalam penyimpanan data. Output dari satu tugas aliran data dapat menjadi input ke tugas aliran data berikutnya, dan aliran data dapat berjalan secara paralel. Tidak seperti alur kontrol, Anda tidak dapat menambahkan batasan antar tugas dalam aliran data. Namun, Anda dapat menambahkan penampil data untuk mengamati data saat diproses oleh setiap tugas.
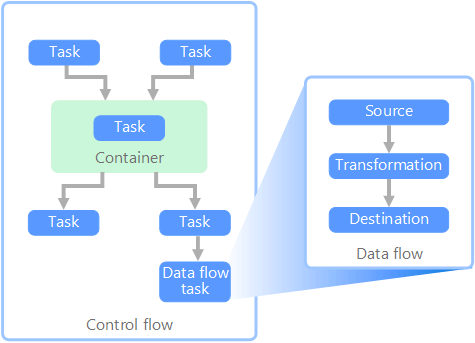
Pada diagram di atas, ada beberapa tugas dalam alur kontrol, salah satunya adalah tugas aliran data. Salah satu tugas bersarang di dalam kontainer. Kontainer dapat digunakan untuk menyediakan struktur untuk tugas-tugas, menyediakan unit kerja. Salah satu contohnya adalah mengulangi elemen dalam koleksi, seperti file dalam folder atau pernyataan database.
Layanan Azure yang relevan:
Alat lain:
Pilihan teknologi
- Penyimpanan data Pemrosesan Transaksi Online (OLTP)
- Penyimpanan data Pemrosesan Analitik Online (OLAP)
- Gudang data
- Orkestrasi alur
Langkah berikutnya
- Mengintegrasikan data dengan Azure Data Factory atau Azure Synapse Pipeline
- Pengantar Azure Synapse Analytics
- Mengatur pergerakan dan transformasi data di Azure Data Factory atau Alur Azure Synapse
Sumber daya terkait
Arsitektur referensi berikut menampilkan alur ELT end-to-end di Azure: