Desain arsitektur database
Artikel ini memberikan gambaran umum tentang solusi database Azure yang dijelaskan di Azure Architecture Center.
Apache®, Apache Cassandra®, dan logo Hadoop adalah merek dagang terdaftar atau merek dagang dari Apache Software Foundation di Amerika Serikat dan/atau negara lain. Tidak ada dukungan oleh The Apache Software Foundation yang tersirat oleh penggunaan tanda ini.
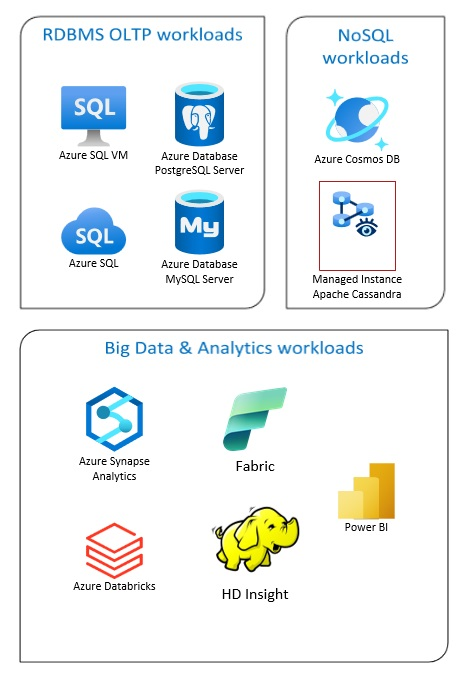
Solusi Azure Database mencakup sistem manajemen database relasional tradisional (RDBMS dan OLTP), beban kerja big data dan analitik (termasuk OLAP), dan beban kerja NoSQL.
Beban kerja RDBMS termasuk pemrosesan transaksi online (OLTP) dan pemrosesan analitik online (OLAP). Data dari beberapa sumber dalam organisasi dapat dikonsolidasikan ke dalam gudang data. Anda dapat menggunakan proses ekstrak, transformasi, pemuatan (ETL) atau ekstrak, muat, transformasi (ELT) untuk memindahkan dan mengubah data sumber. Untuk informasi selengkapnya tentang Database RDBMS, lihat Menjelajahi Database Relasional di Azure.
Arsitektur big data dirancang untuk menangani penyerapan, pemrosesan, dan analisis data besar atau kompleks. Solusi big data biasanya melibatkan sejumlah besar data relasional dan nonrelasional, yang sistem RDBMS tradisional tidak cocok untuk disimpan. Ini biasanya melibatkan solusi seperti Data Lakes, Delta Lakes, dan lakehouse. Lihat informasi selengkapnya dalam Desain Arsitektur Analitik.
Database NoSQL secara bergantian disebut sebagai nonrelasional, NoSQL DB, atau non-SQL untuk menyoroti fakta bahwa mereka dapat menangani volume besar data yang berubah dan tidak terstruktur dengan cepat. Mereka tidak menyimpan data dalam tabel, baris, dan kolom, seperti database (SQL). Untuk informasi selengkapnya tentang Tidak Ada Database DB SQL, lihat Data NoSQL dan Apa itu Database NoSQL?.
Artikel ini menyediakan sumber daya untuk mempelajari tentang database Azure. Ini menguraikan jalur untuk mengimplementasikan arsitektur yang memenuhi kebutuhan Anda dan praktik terbaik untuk diingat saat Anda merancang solusi Anda.
Ada banyak arsitektur untuk Anda gambar dari untuk memenuhi kebutuhan database Anda. Kami juga menyediakan ide solusi untuk Anda bangun, yang mencakup tautan ke semua komponen yang Anda butuhkan.
Pelajari tentang database di Azure
Saat Anda mulai memikirkan kemungkinan arsitektur untuk solusi Anda, sangat penting bagi Anda untuk memilih penyimpanan data yang benar. Jika Anda baru menggunakan database di Azure, tempat terbaik untuk memulai adalah Microsoft Learn. Platform online gratis ini menyediakan video dan tutorial untuk pembelajaran langsung. Microsoft Learn menawarkan jalur pembelajaran yang didasarkan pada peran pekerjaan Anda, seperti pengembang atau analis data.
Anda dapat memulai dengan deskripsi umum tentang berbagai database di Azure dan penggunaannya. Anda juga dapat menelusuri modul data Azure dan Memilih pendekatan penyimpanan data di Azure. Artikel ini membantu Anda memahami pilihan Anda dalam solusi data Azure dan mempelajari mengapa beberapa solusi direkomendasikan dalam skenario tertentu.
Berikut adalah beberapa modul Learn yang mungkin berguna bagi Anda:
- Merancang migrasi Anda ke Azure
- Menyebarkan Azure SQL Database
- Menjelajahi database Azure dan layanan analitik
- Mengamankan Azure SQL Database Anda
- Azure Cosmos DB
- Azure Database untuk PostgreSQL
- Azure Database untuk MySQL
- SQL Server di Mesin Virtual Azure
Jalur menuju produksi
Untuk menemukan opsi yang berguna untuk menangani data relasional, pertimbangkan sumber daya ini:
- Untuk mempelajari tentang sumber daya untuk mengumpulkan data dari beberapa sumber dan cara dan menerapkan transformasi data dalam alur data, lihat Analitik di Azure.
- Untuk mempelajari tentang OLAP, yang mengatur database bisnis besar dan mendukung analisis kompleks, lihat Pemrosesan analitik online.
- Untuk mempelajari tentang sistem OLTP yang merekam interaksi bisnis saat terjadi, lihat Pemrosesan transaksi online.
Database nonrelasional tidak menggunakan skema tabular baris dan kolom. Untuk informasi selengkapnya, lihat Data nonrelasi dan NoSQL.
Untuk mempelajari tentang data lake, yang menyimpan sejumlah besar data dalam format aslinya yang mentah, lihat Data lake.
Arsitektur big data dapat menangani penyerapan, pemrosesan, dan analisis data yang terlalu besar atau terlalu kompleks untuk sistem database tradisional. Untuk informasi selengkapnya, lihat Arsitektur big data dan Analitik.
Cloud hibrid adalah lingkungan TI yang menggabungkan cloud publik dan pusat data lokal. Untuk informasi selengkapnya, pertimbangkan Azure Arc dikombinasikan dengan database Azure.
Azure Cosmos DB adalah layanan database NoSQL yang terkelola sepenuhnya untuk pengembangan aplikasi modern. Untuk informasi selengkapnya, lihat Model sumber daya Azure Cosmos DB.
Untuk mempelajari tentang opsi untuk mentransfer data ke dan dari Azure, lihat Mentransfer data ke dan dari Azure.
Praktik terbaik
Tinjau praktik terbaik ini saat merancang solusi Anda.
| Praktik terbaik | Deskripsi |
|---|---|
| Pola Outbox Transaksional dengan Azure Cosmos DB | Pelajari cara menggunakan pola Transactional Outbox untuk pesan yang andal dan pengiriman peristiwa yang terjamin. |
| Distribusikan data Anda secara global dengan Azure Cosmos DB | Untuk mencapai latensi rendah dan ketersediaan tinggi, beberapa aplikasi perlu disebarkan di pusat data yang dekat dengan pengguna mereka. |
| Keamanan di Azure Cosmos DB | Praktik terbaik keamanan membantu mencegah, mendeteksi, dan merespons pelanggaran database. |
| Pencadangan berkelanjutan dengan pemulihan point-in-time di Azure Cosmos DB | Pelajari tentang fitur pemulihan titik waktu Azure Cosmos DB. |
| Mencapai ketersediaan tinggi dengan Azure Cosmos DB | Azure Cosmos DB menyediakan beberapa fitur dan opsi konfigurasi untuk mencapai ketersediaan tinggi. |
| Ketersediaan tinggi untuk Azure SQL Database dan SQL Managed Instance | Database seharusnya tidak menjadi satu titik kegagalan dalam arsitektur Anda. |
Pilihan teknologi
Ada banyak opsi untuk teknologi yang digunakan dengan Azure Databases. Artikel ini membantu Anda memilih teknologi terbaik untuk kebutuhan Anda.
- Pilih Penyimpanan Data
- Memilih penyimpanan data analitis di Azure
- Memilih teknologi analitik data di Azure
- Memilih teknologi pemrosesan batch di Azure
- Memilih teknologi penyimpanan big data di Azure
- Memilih teknologi orkestrasi alur data di Azure
- Memilih penyimpanan data pencarian di Azure
- Memilih teknologi pemrosesan aliran di Azure
Tetap terkini dengan database
Lihat Pembaruan Azure untuk tetap terkini dengan teknologi Azure Databases.
Sumber daya terkait
- Skenario Adatum Corporation untuk manajemen data dan analitik di Azure
- Skenario Lamna Healthcare untuk manajemen data dan analitik di Azure
- Mengoptimalkan administrasi instans SQL Server
- Skenario relecloud untuk manajemen data dan analitik di Azure
Produk database serupa
Jika Anda terbiasa dengan Amazon Web Services (AWS) atau Google Cloud, lihat perbandingan berikut: