Artikel ini menyajikan pohon keputusan dan contoh opsi ketersediaan tinggi (HA) dan pemulihan bencana (DR) saat menerapkan aplikasi infrastruktur-sebagai-layanan bertingkat (IaaS) ke Azure.
Sistem
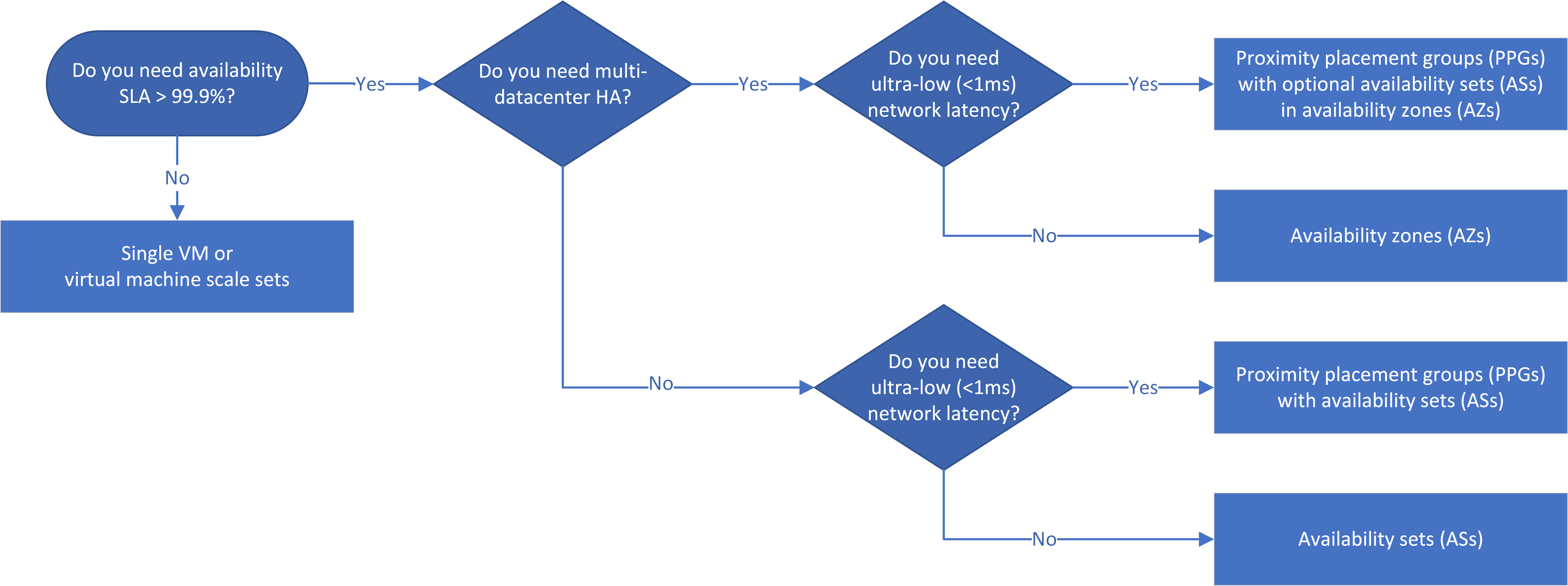
Alur kerja
Set ketersediaan (ASs) atau set ketersediaan menyediakan redudansi dan ketersediaan VM pada pusat data dengan mendistribusikan VM di beberapa simpul perangkat keras yang terisolasi. Subset VM terus berjalan selama terhentinya waktu baik yang direncanakan atau tidak direncanakan, sehingga seluruh aplikasi tetap tersedia dan beroperasi.
Zona ketersediaan (AZs) atau Zona ketersediaan adalah lokasi fisik unik yang mencakup pusat data dalam Azure. Setiap AZ mengakses satu atau lebih pusat data yang memiliki kekuatan independen, pendinginan, dan jaringan, dan setiap penerapan Azure memiliki minimal tiga AZ yang terpisah. Pemisahan fisik AZ di beberapa wilayah melindungi VM yang digunakan dari kegagalan pusat data.
Diagram alur keputusan mencerminkan prinsip bahwa aplikasi HA jika memungkinkan harus menggunakan AZS. Zona-lintas, dan karena itu pusat data-lintas, menyediakan HA > 99,99% SLA karena daya tahannya terhadap kegagalan pusat data.
AZs dan ASs untuk tingkatan aplikasi yang berbeda tidak menjamin berada pada pusat data yang sama. Jika latensi aplikasi yang menjadi perhatian utama, Anda mencarikan layanan dalam satu pusat data dengan menggunakan penempatan grup yang berdekatan (PPG) dengan AZs dan ASs.
Komponen
Alternatif
Alternatif DR regional untuk menggunakan Azure Site Recovery, jika aplikasi dapat mereplikasi data asli, Anda dapat menerapkan DR multi-wilayah penggunaan server siaga panas / dingin, seperti klaster bentangan hanya untuk DR. Alternatif ini tidak secara khusus dirinci pada contoh, tetapi dapat ditambahkan sebagai salah satu solusi. Perhatikan bahwa replikasi antar bagian bersifat tidak serempak, dan bisa saja kehilangan sebagian data yang diperlukan.
Alternatif lain, jika Anda memiliki teknologi replikasi data sendiri, Anda dapat menggunakannya sebagai cadangan sekunder di wilayah zona DR. Bergantung pada wilayah beban kerja Anda, mungkin juga menggunakan Azure Site Recovery untuk mereplikasi item ke zona alternatif, Anda dapat memeriksa ketersediaan regional dan membaca selengkapnya tentang fitur ini di Mengaktifkan Pemulihan Bencana Zona ke Zona untuk komputer virtual Azure.
HA multi-bagian juga memungkinkan, tetapi membutuhkan penyeimbang beban global seperti Pintu Depan atau Traffic Manager. Untuk informasi selengkapnya, lihat Menjalankan aplikasi tingkat-N di beberapa wilayah Azure untuk ketersediaan tinggi.
Detail skenario
Arsitektur bertingkat atau n-tier umum di aplikasikaan secara lokal tradisional, ini merupakan pilihan alami untuk memigrasikan aplikasi lokal ke cloud, atau saat mengembangkan aplikasi untuk lokal dan cloud. Arsitektur N-tingkat biasanya diimplementasikan sebagai aplikasi IaaS yang dibagi menjadi lapisan logis dan tingkatan fisik, dengan web teratas atau tingkat presentasi, tingkat bisnis menengah, dan tingkat data.
Dalam aplikasi n-tier IaaS, setiap tingkat berjalan pada satu set VM yang terpisah. Tingkat web dan bisnis tidak ada batas wilayah, yang berarti setiap VM di tingkatan dapat menangani permintaan apa pun untuk tingkat tersebut. Tingkat data merupakan replikasi database, penyimpanan objek, atau penyimpanan file. Beberapa VM di setiap tingkat memiliki pertahanan jika satu VM gagal, dan penyeimbang beban untuk mendistribusikan permintaan di seluruh VM.
Anda dapat menskalakan tingkatan dengan menambahkan lebih banyak VM ke kelompok, dan menggunakan set skala mesin virtual untuk menskalakan VM identik secara otomatis . Karena Anda menggunakan penyeimbang beban, Anda dapat menskalakan tingkatan tanpa memengaruhi aplikasi pada saat aktif.
Jika perjanjian tingkat layanan (SLA) untuk aplikasi IaaS memerlukan ketersediaan >99%, Anda dapat menempatkan VM di kumpulan ketersediaan, zona ketersediaan, dan grup penempatan kedekatan untuk mengonfigurasi ketersediaan tinggi untuk aplikasi. Solusi HA dan DR yang dipilih tergantung pada SLA yang diperlukan, pertimbangan latensi, dan persyaratan DR regional.
Kemungkinan kasus penggunaan
- Migrasikan aplikasi n-tier dari lokal ke cloud.
- Sebarkan aplikasi n-tier baik lokal maupun ke cloud.
- Konfigutasi ketersediaan tinggi dan skenario pemulihan bencana untuk aplikasi IaaS.
Solusi ini dapat digunakan untuk industri apa pun, termasuk skenario berikut:
- Aplikasi sektor publik
- Perbankan (industri keuangan)
- Layanan Kesehatan
Pertimbangan
AZs tidak tersedia di semua bagian Azure.
Tentukan opsi penerapan apa yang akan digunakan sebelum membuat solusi. Meskipun mungkin, tidak mudah untuk berpindah dari opsi satu ke opsi lainnya setelah proses penyebaran. Anda harus menghapus VM dan membuatnya kembali dari disk yang dikelola, dimana data tersebut diproses.
Pastikan Anda dapat memetakan aplikasi Anda dengan solusi yang dipilih. Banyak aplikasi pola dan desain ketahanan lapisan diluar lingkup pohon keputusan yang dibuat.
Tiga skenario dapat membuat Azure VM melakukan menyalakan ulang aplikasi: pemeliharaan perangkat keras yang tidak terencana, pemadaman yang tidak terduga, dan pemeliharaan yang terencana. Untuk informasi selengkapnya tentang hal ini dan praktik terbaik HA untuk mengurangi dampak, lihat Memahami reboot VM, pemeliharaan, dan pemadaman.
VM tunggal
Jika aplikasi tidak memerlukan > ketersediaan 99,9%, Anda tidak perlu mengkonfigurasikannya untuk HA, dan dapat menerapkan VM tunggal. Anda dapat menggunakan set timbangan mesin virtual yang secara otomatis akan menskalakan VMs identik. Sebarkan VM tunggal tanpa menentukan zona secara spesifik, sehingga dapat didistribusikan ke seluruh bagian. Aplikasi ini memiliki SLA sebesar 99,9% jika Anda menggunakan disk SSD Azure Premium.
VM tunggal menggunakan fungsi penyembuhan layanan bawaan yang dibangun pada semua pusat data Azure. Untuk kegagalan yang dapat diprediksi, fungsionalitas ini biasanya menggunakan migrasi langsung, tetapi selama peristiwa yang tidak dapat diprediksi, VM mungkin di-boot ulang atau dibuat tidak tersedia.
Ketersediaan tinggi
Jika aplikasi memerlukan SLA sebesar > 99,9%, rancanglah aplikasi untuk HA. Gunakan AZ jika memungkinkan, karena AZ memberikan toleransi kesalahan pada pusat data. Anda dapat menggunakan AS alih-alih AZ, tetapi menggunakan AS mengurangi ketersediaan dari 99,99% menjadi 99,95%, karena AS tidak mentolerir kegagalan pada pusat data.
AZ cocok untuk skenario aplikasi yang banyak berkerumun, termasuk klaster Alwayson SQL, menggunakan aktif-aktif, aktif-pasif, atau kombinasi dari kedua level HA di setiap tingkatan dengan kegagalan yang cepat. Replikasi secara bersamaan dimungkinkan antar simpul Database Management System (DBMS), karena rendahnya latensi jaringan lintas zona. Anda juga dapat menjalankan konfigurasi klaster terbentang di seluruh zona, yang memiliki latensi lebih tinggi dan mendukung replikasi tidak bersamaan.
Jika Anda ingin menggunakan arbiter klasteryang berbasis VM, misalnya berbagi file saksi, letakkan di AZ ketiga, untuk memastikan jumlah anggota minimum tidak hilang jika ada satu zona yang gagal. Atau, Anda dapat menggunakan saksi berbasis cloud di wilayah lain.
Semua VM dalam AZ merupakan data tunggal domain yang salah (FD) dan domain terbaru (UD), yang berarti semuanya berbagi sumber daya dan jaringan, dan dapat dinyalakan ulang pada saat yang sama. Jika Anda membuat VM yang berbeda AZ, VM Anda akan terdistribusikan secara efektif di berbagai FD dan UD, sehingga semuanya tidak akan gagal atau dinyalakan ulang pada saat yang bersamaan. Jika Anda memiliki VM didalam zona yang berulang begitu juga di lintas zona, Anda harus menempatkan VM di zona dalam ASs dalam PPG untuk memastikan semuanya tidak akan dinyalakan ulang sekaligus. Bahkan untuk beban VM tunggal yang tidak berlebihan, Anda masih dapat secara opsional menggunakan AS di PPG untuk pertumbuhan dan fleksibilitas berbagai kemungkinan di masa mendatang.
Untuk menerapkan mesin virtual di seluruh AZ, pertimbangkan untuk menggunakan mode Orkestra, saat ini masih dalam pratinjau publik, yang memungkinkan menggabungkan FD dan AZ.
AZ yang ada dalam zona PPG memungkinkan salah satu latensi jaringan terendah di Azure, dan SLA setidaknya 99,99% karena ketahanan di banyak pusat data. Jika memungkinkan gunakan jaringan percepatan pada VM.
Solusi ini mungkin menyajikan skenario di mana layanan yang berjalan pada VM dalam satu zona perlu berinteraksi dengan layanan di zona lain. Misalnya, mungkin ada tingkat web aktif-aktif dan tingkat database pasif aktif di seluruh zona. Beberapa permintaan akan melintasi zona, yang memperkenalkan latensi. Meskipun latensi lintas zona masih sangat rendah, jika Anda perlu memastikan berapa rendah latensi, simpan semua jaringan komunikasi antar tingkat aplikasi dalam satu zona.
Pertimbangan latensi
Latensi jaringan tergantung, antara lain, pada jarak fisik antara VM yang digunakan. Jika aplikasi memerlukan latensi yang sangat rendah antar tiap tingkat, Anda dapat menerapkannya dalam satu pusat data, dengan menggunakan PPG dengan AS untuk setiap tingkatnya. Jika memungkinkan gunakan jaringan percepatan pada VM. Skenario ini memungkinkan adanya satu latensi jaringan terendah di Azure, dan dengan SLA 99,95%.
Anda dapat menggunakan alat berikut untuk mendapatkan wawasan lebih baik tentang kondisi latensi dalam berbagai skenario:
- Untuk menguji latensi antara VM, lihat Pengujian latensi jaringan VM.
- Untuk menguji latensi antar zona, gunakan Pengujian Latensi AvZone. Tes ini dapat membantu Anda menentukan zona logis mana yang memiliki latensi terendah untuk kebutuhan berlangganan.
- Untuk menguji latensi antar bagian pada Azure, gunakan http://www.azurespeed.com/. Alat yang secara teratur diperbarui ini dapat berguna ketika akan mempertimbangkan replikasi tidak serempak antar wilayah.
Pemulihan dari bencana
Pertimbangan DR meliputi ketersediaan, kemampuan aplikasi untuk tetap berjalan dalam kondisi baik, dan daya tahan data, pelestarian data jika terjadi bencana.
Kegagalan HA biasanya berlangsung cepat, tanpa kehilangan data, dan dengan efek yang sangat minim pada layanan. Sebaliknya, failover DR tradisional mungkin memiliki Tujuan Waktu Pemulihan (RTO) dan Tujuan Titik Pemulihan (RPO) yang lebih lama, dan asinkron, dengan potensi kehilangan data.
Anda dapat memanfaatkan zona ketersediaan untuk ketersediaan tinggi dan pemulihan bencana dengan menggunakan zona ketersediaan yang berbeda untuk solusi pemulihan bencana Anda. Zona ketersediaan cukup dekat untuk memiliki koneksi latensi rendah ke zona ketersediaan lain (latensi pulang pergi kurang dari 2m). Namun, mereka cukup jauh untuk mengurangi kemungkinan bahwa pemadaman lokal atau cuaca dapat memengaruhi lebih dari satu zona ketersediaan. Untuk beban kerja misi penting, Anda harus mempertimbangkan solusi yang menggunakan beberapa wilayah selain beberapa zona ketersediaan.
Azure Site Recovery memungkinkan untuk mereplikasi VM ke bagian Azure lain untuk pemulihan bencana regional dan kelangsungan bisnis. Anda dapat menggunakan Azure Site Recovery untuk memulihkan aplikasi jika terjadi pemadaman wilayah sumber atau melakukan latihan pemulihan bencana berkala untuk memastikan Anda memenuhi persyaratan kepatuhan.
Jika aplikasi mendukung Azure Site Recovery, Anda dapat memberikan solusi DR regional untuk meningkatkan perlindungan, jika aplikasi menuntut adanya sikap yang kritis. Namun, ketersediaan tinggi lintas zona, pusat data silang saja mungkin cukup perlindungan, karena jika aplikasi sepenuhnya tahan terhadap kegagalan pusat data, seharusnya tidak ada waktu henti atau kehilangan data.
Pengoptimalan biaya
Tidak ada biaya tambahan untuk penggunaan VM di AZ. Mungkin ada biaya transfer data antar-AZ VM-ke-VM tambahan. Untuk informasi selengkapnya, lihat Harga Bandwidth pada halaman.
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Shaun Croucher | Konsultan Senior
Langkah berikutnya
- Set ketersediaan
- Zona ketersediaan
- Set skala komputer virtual
- Mengaktifkan Pemulihan Bencana Zona ke Zona untuk komputer virtual Azure
Sumber daya terkait
- Gaya arsitektur N-tingkat
- Aplikasi web multi-tingkat dibangun untuk ketersediaan yang tinggi dan pemulihan bencana pada Azure
- Menjalankan aplikasi web zona-redundan untuk ketersediaan tinggi
- Menjalankan aplikasi web di beberapa wilayah Azure untuk ketersediaan tinggi
- Menjalankan aplikasi N-tier di beberapa wilayah Azure untuk ketersediaan tinggi