Hadoop Distributed File System (HDFS) adalah sistem file terdistribusi berbasis Java yang menyediakan penyimpanan data yang andal dan dapat diskalakan yang dapat menjangkau kluster besar server komoditas. Artikel ini menyediakan gambaran umum HDFS dan panduan untuk memigrasikannya ke Azure.
Apache®, Apache Spark®, Apache Hadoop®, Apache Hive, dan logo api adalah merek dagang terdaftar atau merek dagang dari Apache Software Foundation di Amerika Serikat dan/atau negara lain. Tidak ada dukungan oleh The Apache Software Foundation yang tersirat oleh penggunaan tanda ini.
Arsitektur dan Komponen HDFS
HDFS memiliki desain primer/sekunder. Dalam diagram berikut, NameNode adalah yang utama dan DataNodes adalah sekunder.
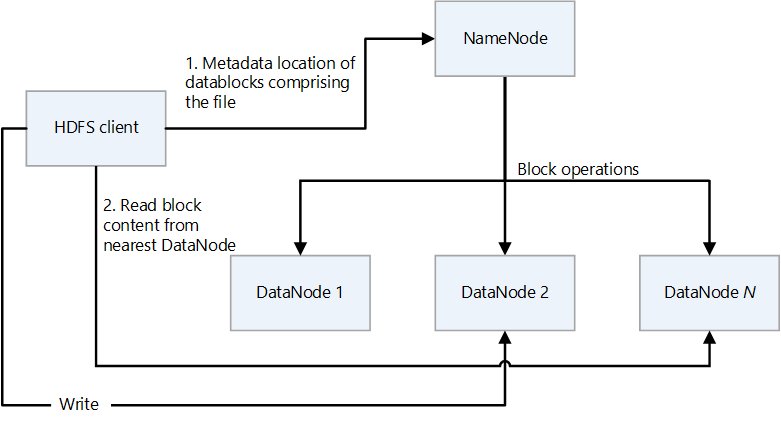
- NameNode mengelola akses ke file dan ke namespace sistem file, yang merupakan hierarki direktori.
- File dan direktori adalah simpul di NameNode. Mereka memiliki atribut seperti izin, waktu modifikasi dan akses, dan kuota ukuran untuk namespace layanan dan ruang disk.
- File terdiri dari beberapa blok. Ukuran blok default adalah 128 megabyte. Ukuran blok non-default dapat diatur untuk kluster dengan memodifikasi file hdfs-site.xml.
- Setiap blok file direplikasi secara independen di beberapa DataNodes. Nilai default untuk faktor replikasi adalah tiga, tetapi setiap kluster dapat memiliki nilai non-default sendiri. Faktor replikasi dapat diubah kapan saja. Perubahan menyebabkan penyeimbangan ulang kluster.
- NameNode mempertahankan pohon namespace dan pemetaan blok file ke DataNodes (lokasi fisik data file).
- Saat klien HDFS membaca file:
- Ini menghubungi NameNode untuk lokasi blok data file.
- Ini membaca memblokir konten dari DataNode terdekat.
- HDFS menyimpan seluruh namespace dalam RAM.
- DataNodes adalah simpul sekunder yang melakukan operasi baca dan tulis pada sistem file, dan melakukan operasi blok seperti pembuatan, replikasi, dan penghapusan.
- DataNode berisi file metadata yang menyimpan checksum file yang disimpan. Untuk setiap replika blok yang dihosting oleh DataNode, ada file metadata terkait yang berisi metadata tentang replika, termasuk informasi checksum-nya. File metadata memiliki nama dasar yang sama dengan file blok, dan ekstensi .meta.
- DataNode berisi file data yang menyimpan data blok.
- Saat DataNode membaca file, DataNode mengambil lokasi blok dan lokasi replika dari NameNode dan mencoba membaca dari lokasi terdekat.
- Kluster HDFS dapat memiliki ribuan DataNodes dan puluhan ribu klien HDFS per kluster. Setiap DataNode dapat menjalankan beberapa tugas aplikasi secara bersamaan.
- Perhitungan checksum end-to-end dilakukan sebagai bagian dari alur tulis HDFS saat blok ditulis ke DataNodes.
- Klien HDFS adalah klien yang digunakan aplikasi untuk mengakses file.
- Ini adalah pustaka kode yang mengekspor antarmuka sistem file HDFS.
- Ini mendukung operasi untuk membaca, menulis, dan menghapus file, dan operasi untuk membuat dan menghapus direktori.
- Ini melakukan langkah-langkah berikut saat aplikasi membaca file:
- Ini mendapatkan dari NameNode daftar DataNodes dan lokasi yang menyimpan blok file. Daftar ini mencakup replika.
- Ini menggunakan daftar untuk mendapatkan blok yang diminta dari DataNodes.
- HDFS menyediakan API yang mengekspos lokasi blok file. Ini memungkinkan aplikasi seperti kerangka kerja MapReduce untuk menjadwalkan tugas untuk menjalankan tempat data berada, untuk mengoptimalkan performa baca.
Peta fitur
Driver Azure Blob Filesystem (ABFS) menyediakan antarmuka yang memungkinkan Azure Data Lake Storage bertindak sebagai sistem file HDFS. Tabel berikut membandingkan fungsionalitas inti driver ABFS dan Data Lake Storage dengan HDFS.
| Fitur | Driver ABFS dan Data Lake Storage | HDFS |
|---|---|---|
| Akses yang kompatibel dengan Hadoop | Anda dapat mengelola dan mengakses data seperti yang Anda lakukan dengan HDFS. Driver ABFS tersedia di semua lingkungan Apache Hadoop, termasuk Azure HDInsight dan Azure Databricks. | Kluster MapR dapat mengakses kluster HDFS eksternal dengan protokol hdfs:// atau webhdfs:// |
| Izin POSIX | Model keamanan untuk Data Lake Gen2 mendukung izin daftar kontrol akses (ACL) dan POSIX bersama dengan beberapa granularitas tambahan yang khusus untuk Data Lake Storage Gen2. Pengaturan dapat dikonfigurasi dengan menggunakan alat admin atau kerangka kerja seperti Apache Hive dan Apache Spark. | Pekerjaan yang memerlukan fitur sistem file seperti penggantian nama direktori atom yang ketat, izin HDFS yang mendetail, atau symlink HDFS hanya dapat berfungsi pada HDFS. |
| Efektivitas biaya | Data Lake Storage menawarkan kapasitas dan transaksi penyimpanan berkursi rendah. Siklus hidup Azure Blob Storage membantu menurunkan biaya dengan menyesuaikan tarif penagihan saat data bergerak melalui siklus hidupnya. | |
| Driver yang dioptimalkan | Driver ABFS dioptimalkan untuk analitik big data. REST API yang sesuai disediakan melalui titik akhir sistem file terdistribusi (DFS), dfs.core.windows.net. |
|
| Ukuran Blok | Blok setara dengan satu pemanggilan APPEND API (APPEND API membuat blok baru) dan dibatasi hingga 100 MB per pemanggilan. Namun, pola tulis mendukung panggilan Tambahkan berkali-kali per file (bahkan secara paralel) hingga maksimum 50.000 dan kemudian memanggil Flush (setara dengan PutBlockList). Ini adalah cara ukuran file maksimum 4,75 TB tercapai. | HDFS menyimpan data dalam blok data. Anda mengatur ukuran blok dengan mengatur nilai dalam file hdfs-site.xml di direktori Hadoop. Ukuran defaultnya adalah 128 MB. |
| ACL default | File tidak memiliki ACL default dan tidak diaktifkan secara default. | File tidak memiliki ACL default. |
| File Biner | File biner dapat dipindahkan ke Azure Blob Storage di namespace layanan non-hierarkis. Objek di Blob Storage dapat diakses melalui Azure Storage REST API, Azure PowerShell, Azure CLI, atau pustaka klien Azure Storage. Pustaka klien tersedia untuk berbagai bahasa, termasuk .NET, Java, Node.js, Python, Go, PHP, dan Ruby | Hadoop menyediakan kemampuan untuk membaca dan menulis file biner. SequenceFile adalah file datar yang terdiri dari pasangan kunci biner dan nilai. SequenceFile menyediakan kelas Penulis, Pembaca, dan Pengurut untuk menulis, membaca, dan mengurutkan. Konversikan file gambar atau video menjadi SequenceFile dan simpan di HDFS. Kemudian gunakan metode HDFS SequenceFileReader/Writer atau perintah put: bin/hadoop fs -put /src_image_file /dst_image_file |
| Pewarisan izin | Data Lake Storage menggunakan model bergaya POSIX dan berulah sama seperti Hadoop jika ACL mengontrol akses ke objek. Untuk informasi selengkapnya, lihat Daftar kontrol akses (ACL) di Data Lake Storage Gen2. | Izin untuk item disimpan pada item itu sendiri, tidak diwariskan setelah item ada. Izin hanya diwariskan jika izin default diatur pada item induk sebelum item anak dibuat. |
| Replikasi data | Data di akun Azure Storage direplikasi tiga kali di wilayah utama. Penyimpanan redundansi zona adalah opsi replikasi yang direkomendasikan. Ini secara sinkron mereplikasi di tiga zona ketersediaan Azure di wilayah utama. | Secara default, faktor replikasi file adalah tiga. Untuk file atau file penting yang sering diakses, faktor replikasi yang lebih tinggi meningkatkan toleransi kesalahan dan meningkatkan bandwidth baca. |
| Bit lengket | Dalam konteks Data Lake Storage, tidak mungkin bit lengket diperlukan. Secara singkat, jika bit lengket diaktifkan pada direktori, item anak hanya dapat dihapus atau diganti namanya oleh pengguna yang memiliki item anak. Bit lekat tidak ditampilkan di portal Microsoft Azure. | Bit lengket dapat diatur pada direktori untuk mencegah siapa pun kecuali superuser, pemilik direktori, atau pemilik file menghapus atau memindahkan file dalam direktori. Mengatur bit lengket untuk file tidak berpengaruh. |
Tantangan umum HDFS lokal

Banyaknya tantangan yang disajikan oleh implementasi HDFS lokal dapat menjadi alasan untuk mempertimbangkan keuntungan bermigrasi ke cloud:
- Peningkatan versi HDFS yang sering
- Meningkatkan jumlah data
- Memiliki banyak file kecil yang meningkatkan tekanan pada NameNode, yang mengontrol metadata semua file dalam kluster. Lebih banyak file sering berarti lebih banyak lalu lintas baca di NameNode ketika klien membaca file, dan lebih banyak panggilan saat klien menulis.
- Jika beberapa tim dalam organisasi memerlukan himpunan data yang berbeda, pemisahan kluster HDFS berdasarkan kasus penggunaan atau organisasi tidak dimungkinkan. Hasilnya adalah duplikasi data meningkat, yang meningkatkan biaya dan mengurangi efisiensi.
- NameNode dapat menjadi hambatan performa saat kluster HDFS ditingkatkan atau ditingkatkan.
- Sebelum Hadoop 2.0, semua permintaan klien ke kluster HDFS terlebih dahulu melewati NameNode, karena semua metadata disimpan dalam satu NameNode. Desain ini menjadikan NameNode kemungkinan hambatan dan satu titik kegagalan. Jika NameNode gagal, kluster tidak tersedia.
Pertimbangan migrasi
Berikut adalah beberapa hal yang penting untuk dipertimbangkan saat Anda merencanakan migrasi HDFS ke Data Lake Storage:
- Pertimbangkan untuk menggabungkan data yang ada dalam file kecil ke dalam satu file di Data Lake Storage.
- Cantumkan semua struktur direktori dalam HDFS dan replikasi zonasi serupa di Data Lake Storage. Anda dapat memperoleh struktur direktori HDFS dengan menggunakan
hdfs -lsperintah . - Cantumkan semua peran yang ditentukan dalam kluster HDFS sehingga Anda dapat mereplikasinya di lingkungan target.
- Perhatikan kebijakan siklus hidup data file yang disimpan dalam HDFS.
- Perlu diingat bahwa beberapa fitur sistem HDFS tidak tersedia di Data Lake Storage, termasuk:
- Penggantian nama direktori atom secara ketat
- Izin HDFS halus
- Symlink HDFS
- Azure Storage memiliki replikasi geo-redundan, tetapi tidak selalu bijaksana untuk menggunakannya. Ini memberikan redundansi data dan pemulihan geografis, tetapi failover ke lokasi yang lebih jauh dapat sangat menurunkan performa dan dikenakan biaya tambahan. Pertimbangkan apakah ketersediaan data yang lebih tinggi sepadan.
- Jika file memiliki nama dengan awalan yang sama, HDFS memperlakukannya sebagai partisi tunggal. Oleh karena itu, jika Anda menggunakan Azure Data Factory, semua unit pergerakan data (DMU) menulis ke satu partisi.

- Jika Anda menggunakan Pabrik data untuk transfer data, pindai melalui setiap direktori, tidak termasuk rekam jepret, dan periksa ukuran direktori dengan menggunakan
hdfs duperintah . Jika ada beberapa subdirektori dan data dalam jumlah besar, mulai beberapa aktivitas salin di Data Factory. Misalnya, gunakan satu salinan per subdirektori daripada mentransfer seluruh direktori dengan menggunakan satu aktivitas salin.

- Platform data sering digunakan untuk retensi informasi jangka panjang yang mungkin telah dihapus dari sistem rekaman. Anda harus berencana untuk membuat cadangan pita atau rekam jepret data yang diarsipkan. Pertimbangkan untuk mereplikasi informasi ke situs pemulihan. Biasanya data diarsipkan baik untuk kepatuhan atau untuk tujuan data historis. Sebelum mengarsipkan data, Anda harus memiliki alasan yang jelas untuk menyimpannya. Selain itu, putuskan kapan data yang diarsipkan akan dihapus dan buat proses untuk menghapusnya pada saat itu.
- Biaya rendah tingkat akses Arsip Data Lake Storage menjadikannya opsi yang menarik untuk mengarsipkan data. Untuk informasi selengkapnya, buka Tingkat akses arsip.
- Ketika klien HDFS menggunakan driver ABFS untuk mengakses Blob Storage, mungkin ada instans di mana metode yang digunakan oleh klien tidak didukung dan AzureNativeFileSystem melempar UnsupportedOperationException. Misalnya,
append(Path f, int bufferSize, Progressable progress)saat ini tidak didukung. Untuk memeriksa masalah yang terkait dengan driver ABFS, lihat Fitur dan perbaikan Hadoop. - Ada versi driver ABFS yang didukung untuk digunakan pada kluster Hadoop yang lebih lama. Untuk informasi selengkapnya, lihat Backport untuk Driver ABFS.
- Di lingkungan jaringan virtual Azure, alat DistCp tidak mendukung peering privat Azure ExpressRoute dengan titik akhir jaringan virtual Azure Storage. Untuk informasi selengkapnya, lihat Menggunakan Azure Data Factory untuk memigrasikan data dari kluster Hadoop lokal ke Azure Storage.
Pendekatan migrasi
Pendekatan umum untuk memigrasikan HDFS ke Data Lake Storage menggunakan langkah-langkah berikut:

Penilaian HDFS
Skrip penilaian lokal menyediakan informasi yang membantu Anda menentukan beban kerja mana yang dapat dimigrasikan ke Azure dan apakah data harus dimigrasikan sekaligus atau satu per satu. Alat pihak ketiga seperti Unravel dapat menyediakan metrik dan mendukung penilaian otomatis HDFS lokal. Beberapa faktor penting yang perlu dipertimbangkan saat merencanakan meliputi:
- Volume data
- Dampak bisnis
- Kepemilikan data
- Kompleksitas pemrosesan
- Kompleksitas ekstrak, transfer, dan muat (ETL)
- Informasi pengidentifikasi pribadi (PII) dan data sensitif lainnya
Berdasarkan faktor tersebut, Anda dapat merumuskan rencana untuk memindahkan data ke Azure yang meminimalkan gangguan waktu henti dan bisnis. Mungkin data sensitif dapat tetap lokal. Data historis dapat dipindahkan dan diuji sebelum memindahkan beban inkremental.
Alur keputusan berikut membantu memutuskan kriteria dan perintah yang akan dijalankan untuk mendapatkan informasi yang tepat.

Perintah HDFS untuk mendapatkan metrik penilaian dari HDFS meliputi:
Cantumkan semua direktori di lokasi:
hdfs dfs -ls booksMencantumkan semua file secara rekursif di lokasi:
hdfs dfs -ls -R booksDapatkan ukuran direktori dan file HDFS:
hadoop fs -du -s -h commandPerintah
hadoop fs -du -s -hmenampilkan ukuran file dan direktori HDFS. Karena sistem file Hadoop mereplikasi setiap file, ukuran fisik file yang sebenarnya adalah jumlah replika file yang dikalikan dengan ukuran satu replika.Tentukan apakah ACL diaktifkan. Untuk melakukan ini, dapatkan nilai
dfs.namenode.acls.enableddalam Hdfs-site.xml. Mengetahui nilai membantu dalam merencanakan kontrol akses pada akun Azure Storage. Untuk informasi tentang isi file ini, lihat Pengaturan file default.
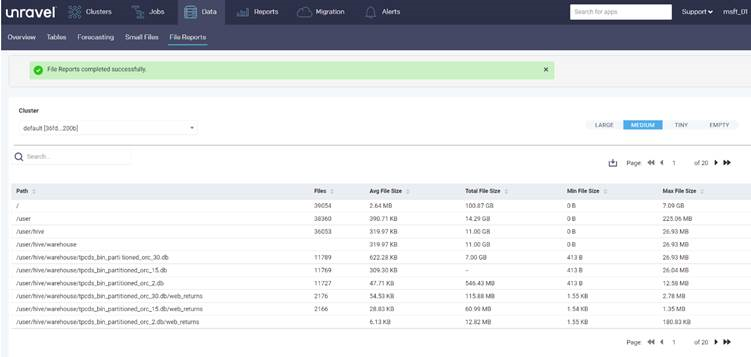
Alat mitra seperti Unravel menyediakan laporan penilaian untuk merencanakan migrasi data. Alat harus berjalan di lingkungan lokal atau terhubung ke kluster Hadoop untuk menghasilkan laporan.
Laporan Unravel berikut ini menyediakan statistik, per direktori, tentang file kecil di direktori:

Laporan berikut ini menyediakan statistik, per direktori, tentang file di direktori:
Transfer data
Data harus ditransfer ke Azure seperti yang diuraikan dalam rencana migrasi Anda. Mentransfer memerlukan aktivitas berikut:
Identifikasi semua titik penyerapan.
Jika, karena persyaratan keamanan, data tidak dapat didaratkan ke cloud secara langsung, maka lokal dapat berfungsi sebagai zona pendaratan menengah. Anda dapat membangun alur di Data Factory untuk menarik data dari sistem lokal, atau menggunakan skrip AZCopy untuk mendorong data ke akun Azure Storage.
Sumber penyerapan umum meliputi:
- Server SFTP
- Penyerapan file
- Penyerapan database
- Pencadangan database
- Mengubah pengambilan data
- Penyerapan streaming
Rencanakan jumlah akun penyimpanan yang diperlukan.
Untuk merencanakan jumlah akun penyimpanan yang diperlukan, pahami total beban pada HDFS saat ini. Anda dapat menggunakan metrik TotalLoad, yang merupakan jumlah akses file bersamaan saat ini di semua DataNodes. Tetapkan batas pada akun penyimpanan di wilayah sesuai dengan nilai TotalLoad lokal dan pertumbuhan yang diharapkan di Azure. Jika memungkinkan untuk meningkatkan batas, satu akun penyimpanan mungkin sudah cukup. Namun untuk data lake, yang terbaik adalah menyimpan akun penyimpanan terpisah untuk setiap zona, untuk mempersiapkan pertumbuhan volume data di masa mendatang. Alasan lain untuk menyimpan akun penyimpanan terpisah meliputi:
- Kontrol akses
- Persyaratan ketahanan
- Persyaratan replikasi data
- Mengekspos data untuk penggunaan publik
Saat mengaktifkan namespace hierarkis di akun penyimpanan, Anda tidak dapat mengubahnya kembali ke namespace datar. Beban kerja seperti cadangan dan file gambar VM tidak mendapatkan manfaat apa pun dari namespace hierarkis.

Untuk informasi tentang mengamankan lalu lintas antara jaringan virtual Anda dan akun penyimpanan melalui tautan privat, lihat Mengamankan Akun Penyimpanan.
Untuk informasi tentang batas default untuk akun Azure Storage, lihat Skalabilitas dan target performa untuk akun penyimpanan standar. Batas ingress berlaku untuk data yang dikirim ke akun penyimpanan. Batas keluar berlaku untuk data yang diterima dari akun penyimpanan
Tentukan persyaratan ketersediaan.
Anda dapat menentukan faktor replikasi untuk platform Hadoop di hdfs-site.xml atau menentukannya per file. Anda dapat mengonfigurasi replikasi pada Data Lake Storage sesuai dengan sifat data. Jika aplikasi mengharuskan data direkonstruksi jika terjadi kehilangan, maka penyimpanan zona redundan (ZRS) adalah opsi. Di Data Lake Storage ZRS, data disalin secara sinkron di tiga zona ketersediaan di wilayah utama. Untuk aplikasi yang memerlukan ketersediaan tinggi dan yang dapat berjalan di lebih dari satu wilayah, salin data ke wilayah sekunder. Ini adalah replikasi geo-redundan.

Periksa blok yang rusak atau hilang.
Periksa laporan pemindai blok untuk blok yang rusak atau hilang. Jika ada, tunggu hingga file dipulihkan sebelum mentransfernya.

Periksa apakah NFS diaktifkan.
Periksa apakah NFS diaktifkan di platform Hadoop lokal dengan memeriksa file core-site.xml. Ini memiliki properti nfsserver.groups dan nfsserver.hosts.
Fitur NFS 3.0 dalam pratinjau di Data Lake Storage. Beberapa fitur mungkin belum didukung. Untuk informasi selengkapnya, lihat Dukungan protokol Network File System (NFS) 3.0 untuk Azure Blob Storage.

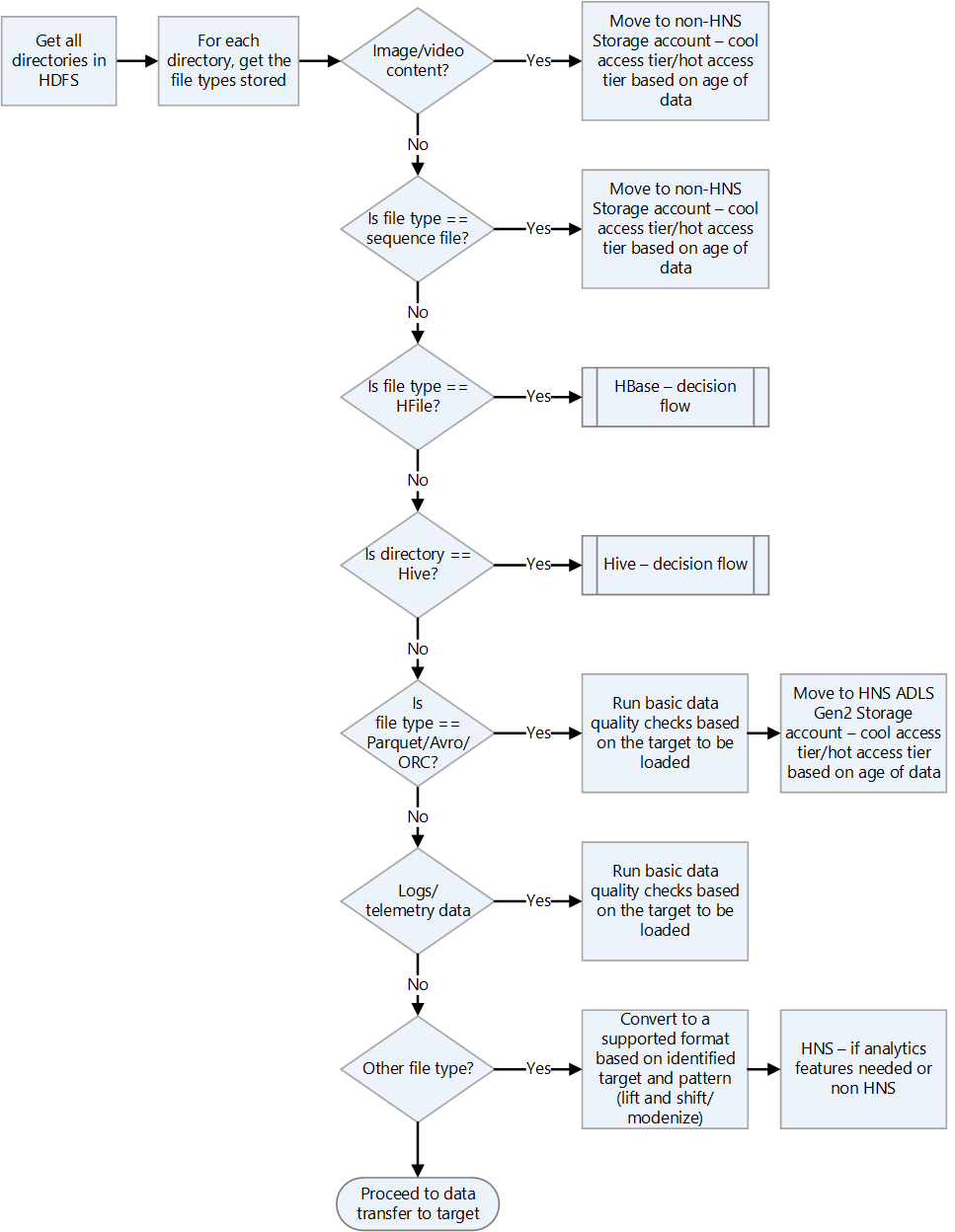
Periksa format file Hadoop.
Gunakan bagan alur keputusan berikut untuk panduan tentang cara menangani format file.
Pilih solusi Azure untuk transfer data.
Transfer data dapat online melalui jaringan atau offline dengan menggunakan perangkat fisik. Metode mana yang akan digunakan tergantung pada volume data, bandwidth jaringan, dan frekuensi transfer data. Data historis harus ditransfer hanya sekali. Beban inkremental memerlukan transfer berkelanjutan berulang.
Metode transfer data dibahas dalam daftar berikut. Untuk informasi selengkapnya tentang memilih jenis transfer data, lihat Memilih solusi Azure untuk transfer data.
Azcopy
Azcopy adalah utilitas baris perintah yang dapat menyalin file dari HDFS ke akun penyimpanan. Ini adalah opsi untuk transfer bandwidth tinggi (lebih dari 1 GBPS).
Berikut adalah contoh perintah untuk memindahkan direktori HDFS:
*azcopy copy "C:\local\path" "https://account.blob.core.windows.net/mycontainer1/?sv=2018-03-28&ss=bjqt&srt=sco&sp=rwddgcup&se=2019-05-01T05:01:17Z&st=2019-04-30T21:01:17Z&spr=https&sig=MGCXiyEzbtttkr3ewJIh2AR8KrghSy1DGM9ovN734bQF4%3D" --recursive=true*DistCp
DistCp adalah utilitas baris perintah di Hadoop yang dapat melakukan operasi salin terdistribusi dalam kluster Hadoop. DistCp membuat beberapa tugas peta di kluster Hadoop untuk menyalin data dari sumber ke sink. Pendekatan pendorongan ini baik ketika ada bandwidth jaringan yang memadai, dan tidak memerlukan sumber daya komputasi tambahan untuk disediakan untuk migrasi data. Namun, jika kluster HDFS sumber sudah kehabisan kapasitas dan komputasi tambahan tidak dapat ditambahkan, maka pertimbangkan untuk menggunakan Data Factory dengan aktivitas salin DistCp untuk menarik daripada mendorong file.
*hadoop distcp -D fs.azure.account.key.<account name>.blob.core.windows.net=<Key> wasb://<container>@<account>.blob.core.windows.net<path to wasb file> hdfs://<hdfs path>*Azure Data Box untuk transfer data besar
Azure Data Box adalah perangkat fisik yang dipesan dari Microsoft. Ini menyediakan transfer data skala besar, dan ini adalah opsi transfer data offline ketika bandwidth jaringan terbatas dan volume data tinggi (misalnya, ketika volume antara beberapa terabyte dan petabyte).
Anda menyambungkan Data Box ke LAN untuk mentransfer data ke dalamnya. Anda kemudian mengirimkannya kembali ke pusat data Microsoft, tempat data ditransfer oleh teknisi Microsoft ke akun penyimpanan yang dikonfigurasi.
Ada beberapa opsi Data Box yang berbeda dengan volume data yang dapat mereka tangani. Untuk informasi selengkapnya tentang pendekatan Data Box, lihat dokumentasi Azure Data Box - Transfer offline.
Data Factory
Data Factory adalah layanan integrasi data yang membantu membuat alur kerja berbasis data yang mengatur dan mengotomatiskan pergerakan data dan transformasi data. Anda dapat menggunakannya ketika ada bandwidth jaringan yang memadai yang tersedia dan ada persyaratan untuk mengatur dan memantau migrasi data. Anda dapat menggunakan Data Factory untuk pemuatan data inkremental reguler saat data inkremental tiba di sistem lokal sebagai hop pertama dan tidak dapat langsung ditransfer ke akun penyimpanan Azure karena pembatasan keamanan.
Untuk informasi selengkapnya tentang berbagai pendekatan transfer, lihat Transfer data untuk himpunan data besar dengan bandwidth jaringan sedang hingga tinggi.
Untuk informasi tentang menggunakan Data Factory untuk menyalin data dari HDFS, lihat Menyalin data dari server HDFS menggunakan Azure Data Factory atau Synapse Analytics
Solusi mitra seperti migrasi WANdisco LiveData
WANdisco LiveData Platform for Azure adalah salah satu solusi pilihan Microsoft untuk migrasi dari Hadoop ke Azure. Anda mengakses kemampuannya dengan menggunakan portal Azure dan Azure CLI. Untuk informasi selengkapnya, lihat Memigrasikan data lake Hadoop Anda dengan WANdisco LiveData Platform for Azure.
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Namrata Maheshwary | Arsitek Solusi Cloud Senior
- Raja N | Direktur, Keberhasilan Pelanggan
- Hideo Takagi | Arsitek Solusi Cloud
- Ram Yerrabotu | Arsitek Solusi Cloud Senior
Kontributor lain:
- Ram Baskaran | Arsitek Solusi Cloud Senior
- Jason Bouska | Insinyur Perangkat Lunak Senior
- Eugene Chung | Arsitek Solusi Cloud Senior
- Pawan Hosatti | Arsitek Solusi Cloud Senior - Teknik
- Daman Kaur | Arsitek Solusi Cloud
- Danny Liu | Arsitek Solusi Cloud Senior - Teknik
- Arsitek Solusi Cloud Senior Jose Mendez
- Ben Sadeghi | Spesialis Senior
- Sunil Sattiraju | Arsitek Solusi Cloud Senior
- Amanjeet Singh | Manajer Program Utama
- Nagaraj Seeplapudur Venkatesan | Arsitek Solusi Cloud Senior - Teknik
Untuk melihat profil LinkedIn non-publik, masuk ke LinkedIn.
Langkah berikutnya
Pengenalan produk Azure
- Pengantar Azure Data Lake Storage Gen2
- Apa itu Apache Spark di Azure HDInsight
- Apa itu Apache Hadoop di Azure HDInsight?
- Apa itu Apache HBase di Azure HDInsight
- Apa itu Apache Kafka di Azure HDInsight
Referensi produk Azure
- Dokumentasi Microsoft Entra
- Dokumentasi Azure Cosmos DB
- Dokumentasi Azure Data Factory
- Dokumentasi Azure Databricks
- Dokumentasi Azure Event Hubs
- Dokumentasi Azure Functions
- Dokumentasi Azure HDInsight
- Dokumentasi tata kelola data Microsoft Purview
- Dokumentasi Azure Stream Analytics
- Azure Synapse Analytics
Lainnya
- Paket Keamanan Perusahaan untuk Azure HDInsight
- Kembangkan program Java MapReduce untuk Apache Hadoop di HDInsight
- Menggunakan Apache Sqoop dengan Hadoop di HDInsight
- Gambaran Umum Apache Spark Streaming
- Tutorial Streaming Terstruktur
- Menggunakan Azure Event Hubs dari aplikasi Apache Kafka