Apache Sqoop adalah alat untuk mentransfer data antara kluster Apache Hadoop dan database relasional. Ini memiliki antarmuka baris perintah.
Anda dapat menggunakan Sqoop untuk mengimpor data ke HDFS dari database relasional seperti MySQL, PostgreSQL, Oracle, dan SQL Server, dan untuk mengekspor data HDFS ke database tersebut. Sqoop dapat menggunakan MapReduce dan Apache Hive untuk mengonversi data di Hadoop. Fitur tingkat lanjut termasuk pemuatan bertambah bertahap, pemformatan dengan menggunakan SQL, dan memperbarui himpunan data. Sqoop beroperasi secara paralel untuk mencapai transfer data berkecepatan tinggi.
Catatan
Proyek Sqoop telah dihentikan. Sqoop dipindahkan ke Apache Attic pada Juni 2021. Situs web, unduhan, dan pelacak masalah semuanya tetap terbuka. Lihat Apache Sqoop di Apache Attic untuk informasi selengkapnya.
Apache, Apache Spark®, Apache Hadoop®, Apache HBase, Apache Hive, Apache Ranger®, Apache Storm®, Apache Sqoop®, Apache Kafka®, dan logo api adalah merek dagang terdaftar atau merek dagang dari Apache Software Foundation di Amerika Serikat dan/atau negara lain.® Tidak ada dukungan oleh The Apache Software Foundation yang tersirat oleh penggunaan tanda ini.
Arsitektur dan komponen Sqoop
Ada dua versi Sqoop: Sqoop1 dan Sqoop2. Sqoop1 adalah alat klien sederhana, sedangkan Sqoop2 memiliki arsitektur klien/server. Mereka tidak kompatibel satu dengan yang lain, dan berbeda dalam penggunaan. Sqoop2 tidak lengkap fiturnya, dan tidak ditujukan untuk penyebaran produksi.
Arsitektur Sqoop1
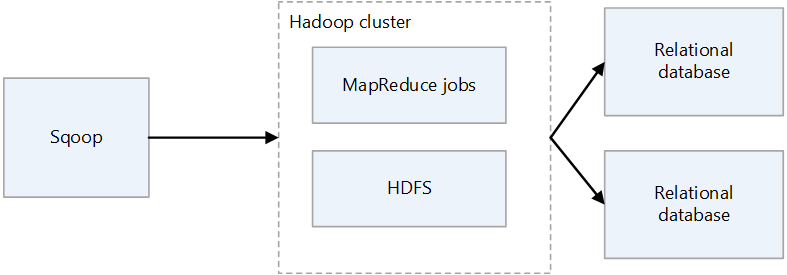
Impor dan ekspor Sqoop1
Impor
Membaca data dari database relasional dan data output ke HDFS. Setiap rekaman dalam tabel database relasional adalah output sebagai satu baris dalam HDFS. Teks, SequenceFiles, dan Avro adalah format file yang dapat ditulis ke HDFS.
Ekspor
Membaca data dari HDFS dan mentransfernya ke database relasional. Database relasional target mendukung penyisipan dan pembaruan.
Arsitektur Sqoop2
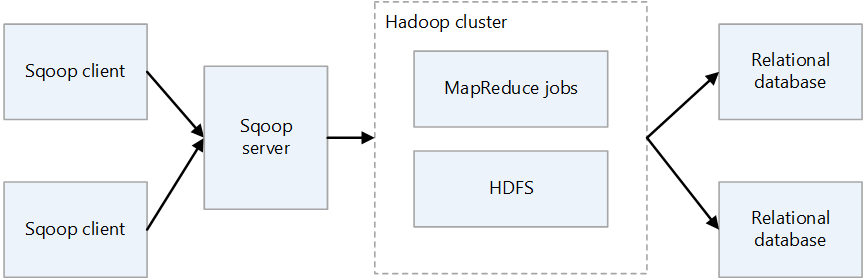
Server Sqoop
Menyediakan titik masuk untuk klien Sqoop.
Klien Sqoop
Berinteraksi dengan server Sqoop. Klien dapat berada di simpul apa pun, asalkan klien dapat berkomunikasi dengan server. Karena klien hanya perlu berkomunikasi dengan server, tidak perlu membuat pengaturan seperti yang Anda lakukan dengan MapReduce.
Tantangan Sqoop lokal
Berikut adalah beberapa tantangan umum dari penyebaran Sqoop lokal:
- Mungkin sulit untuk diskalakan, tergantung pada kapasitas perangkat keras dan pusat data.
- Ini tidak dapat dengan mudah diskalakan sesuai permintaan.
- Ketika dukungan berakhir untuk infrastruktur yang menua, Anda dapat dipaksa untuk mengganti dan meningkatkan.
- Ada kurangnya alat asli untuk menyediakan:
- Transparansi biaya
- Pemantauan
- DevOps
- Automation
Pertimbangan
- Saat Anda memigrasikan Sqoop ke Azure, jika sumber data Anda tetap lokal, Anda perlu mempertimbangkan konektivitasnya. Anda dapat membuat koneksi VPN melalui internet antara Azure dan jaringan lokal yang ada, atau Anda dapat menggunakan Azure ExpressRoute untuk membuat koneksi privat.
- Saat Anda memigrasikan Sqoop ke Azure HDInsight, pertimbangkan versi Sqoop Anda. HDInsight hanya mendukung Sqoop1, jadi jika Anda menggunakan Sqoop2 di lingkungan lokal, Anda harus menggantinya dengan Sqoop1 di HDInsight, atau menjaga Sqoop2 tetap independen.
- Saat memigrasikan Sqoop ke Azure Data Factory, Anda perlu mempertimbangkan format file data. Data Factory tidak mendukung format SequenceFile. Kurangnya dukungan dapat menjadi masalah jika implementasi Sqoop Anda mengimpor data dalam format SequenceFile. Untuk informasi selengkapnya, lihat Format file.
Pendekatan migrasi
Azure memiliki beberapa target migrasi untuk Apache Sqoop. Bergantung pada persyaratan dan fitur produk, Anda dapat memilih antara komputer virtual (VM) Azure IaaS, Azure HDInsight, dan Azure Data Factory.
Berikut adalah bagan keputusan untuk memilih target migrasi:
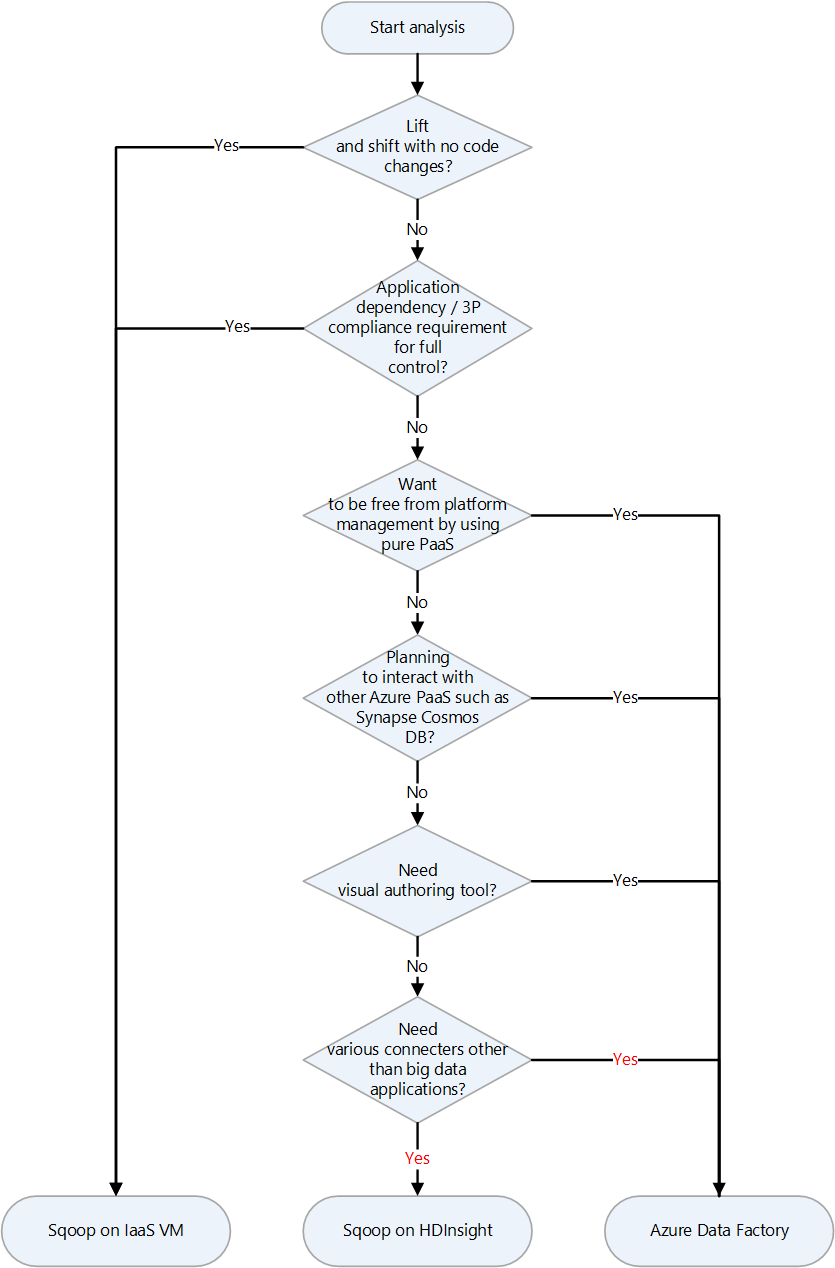
Target migrasi dibahas di bagian berikut:
Mengangkat dan mengalihkan migrasi ke Azure IaaS
Jika Anda memilih Azure IaaS VM sebagai tujuan migrasi untuk Sqoop lokal, Anda dapat melakukan migrasi lift dan shift. Anda menggunakan versi Sqoop yang sama untuk membuat lingkungan yang sepenuhnya dapat dikontrol. Oleh karena itu, Anda tidak perlu membuat perubahan apa pun pada perangkat lunak Sqoop. Sqoop bekerja dengan kluster Hadoop dan biasanya dimigrasikan bersama dengan kluster Hadoop. Artikel berikut adalah panduan untuk migrasi lift dan shift kluster Hadoop. Pilih artikel yang berlaku untuk layanan yang akan dimigrasikan.
Persiapan untuk migrasi
Untuk mempersiapkan migrasi, Anda merencanakan migrasi dan membuat koneksi jaringan.
Merencanakan migrasi
Kumpulkan informasi berikut untuk mempersiapkan migrasi Sqoop lokal Anda. Informasi ini membantu Anda menentukan ukuran komputer virtual tujuan dan merencanakan komponen perangkat lunak dan konfigurasi jaringan.
| Item | Latar belakang |
|---|---|
| Ukuran host saat ini | Dapatkan informasi tentang CPU, memori, disk, dan komponen lain dari host atau komputer virtual tempat klien atau server Sqoop berjalan. Anda menggunakan informasi ini untuk memperkirakan ukuran dasar yang diperlukan untuk komputer virtual Azure Anda. |
| Metrik host dan aplikasi | Dapatkan informasi penggunaan sumber daya (CPU, memori, disk, dan komponen lainnya) dari komputer yang menjalankan klien Sqoop dan perkirakan sumber daya yang benar-benar digunakan. Jika Anda menggunakan lebih sedikit sumber daya daripada yang dialokasikan untuk host Anda, pertimbangkan untuk mengurangi ukuran saat Anda bermigrasi ke Azure. Setelah Anda mengidentifikasi jumlah sumber daya yang diperlukan, pilih jenis komputer virtual yang akan dimigrasikan dengan merujuk ke ukuran komputer virtual Azure. |
| Versi Sqoop | Periksa versi Sqoop lokal untuk menentukan versi Sqoop mana yang akan diinstal pada komputer virtual Azure. Jika Anda menggunakan distribusi seperti Cloudera atau Hortonworks, versi komponen bergantung pada versi distribusi tersebut. |
| Menjalankan pekerjaan dan skrip | Identifikasi pekerjaan yang menjalankan Sqoop dan metode penjadwalannya. Pekerjaan dan metode adalah kandidat untuk migrasi. |
| Database yang akan disambungkan | Identifikasi database yang disambungkan Sqoop, seperti yang ditentukan oleh perintah impor dan ekspor dalam pekerjaan Sqoop. Setelah mengidentifikasinya, Anda perlu melihat apakah Anda dapat tersambung ke database tersebut setelah memigrasikan Sqoop ke komputer virtual Azure Anda. Jika beberapa database yang Anda sambungkan masih lokal, Anda memerlukan koneksi jaringan antara lokal dan Azure. Untuk informasi selengkapnya, lihat bagian Membuat koneksi jaringan. |
| Plugin | Identifikasi plugin Sqoop yang Anda gunakan dan tentukan apakah Anda dapat memigrasikannya. |
| Ketersediaan tinggi, kelangsungan bisnis, pemulihan bencana | Tentukan apakah teknik pemecahan masalah yang Anda gunakan lokal dapat digunakan di Azure. Misalnya, jika Anda memiliki konfigurasi aktif/siaga pada dua simpul, siapkan dua komputer virtual Azure untuk klien Sqoop yang memiliki konfigurasi yang sama. Hal yang sama berlaku saat mengonfigurasi pemulihan bencana. |
Membuat koneksi jaringan
Jika beberapa database yang Anda sambungkan tetap lokal, Anda memerlukan koneksi jaringan antara lokal dan Azure.
Ada dua opsi utama untuk menyambungkan lokal dan Azure di jaringan privat:
VPN Gateway
Anda dapat menggunakan Azure VPN Gateway untuk mengirim lalu lintas terenkripsi antara jaringan virtual Azure dan lokasi lokal Anda melalui internet publik. Teknik ini murah dan mudah diatur. Namun, karena koneksi terenkripsi melalui internet, bandwidth komunikasi tidak dijamin. Jika Anda perlu menjamin bandwidth, Anda harus memilih ExpressRoute, yang merupakan opsi kedua. Untuk informasi selengkapnya tentang opsi VPN, lihat Apa itu VPN Gateway? dan desain VPN Gateway.
ExpressRoute
ExpressRoute dapat menyambungkan jaringan lokal Anda ke Azure atau ke Microsoft 365 dengan menggunakan koneksi privat yang disediakan oleh penyedia konektivitas. ExpressRoute tidak melalui internet publik, sehingga lebih aman, lebih dapat diandalkan, dan memiliki latensi yang lebih konsisten daripada koneksi melalui internet. Selain itu, opsi bandwidth baris yang Anda beli dapat menjamin latensi yang stabil. Untuk informasi selengkapnya, lihat Apa itu Azure ExpressRoute?.
Jika metode koneksi privat ini tidak memenuhi kebutuhan Anda, pertimbangkan Azure Data Factory sebagai tujuan migrasi. Runtime integrasi yang dihost sendiri di Data Factory memungkinkan Anda mentransfer data dari lokal ke Azure tanpa harus mengonfigurasi jaringan privat.
Memigrasikan data dan pengaturan
Saat Anda memigrasikan Sqoop lokal ke komputer virtual Azure, sertakan data dan pengaturan berikut:
File konfigurasi Sqoop: Ini tergantung pada lingkungan Anda, tetapi file berikut sering disertakan:
sqoop-site.xmlsqoop-env.xmlpassword-fileoraoop-site.xml, jika Anda menggunakan Oraoop
Pekerjaan tersimpan: Jika Anda menyimpan pekerjaan di metastore Sqoop dengan menggunakan
sqoop job --createperintah , Anda perlu memigrasikannya. Tujuan penyimpanan metastore ditentukan dalam sqoop-site.xml. Jika metastore bersama tidak diatur, cari pekerjaan yang disimpan di subdirektori .sqoop direktori beranda pengguna yang menjalankan metastore.Anda dapat menggunakan perintah berikut untuk melihat informasi tentang pekerjaan yang disimpan.
Dapatkan daftar pekerjaan yang disimpan:
sqoop job --listMelihat parameter untuk pekerjaan yang disimpan
sqoop job --show <job-id>
Skrip: Jika Anda memiliki file skrip yang menjalankan Sqoop, Anda perlu memigrasikannya.
Penjadwal: Jika Anda menjadwalkan eksekusi Sqoop, Anda perlu mengidentifikasi penjadwalnya, seperti pekerjaan cron Linux atau alat manajemen pekerjaan. Kemudian Anda perlu mempertimbangkan apakah penjadwal dapat dimigrasikan ke Azure.
Plugin: Jika Anda menggunakan plugin kustom apa pun di Sqoop, misalnya konektor ke database eksternal, Anda perlu memigrasikannya. Jika Anda membuat file patch, terapkan patch ke Sqoop yang dimigrasikan.
Bermigrasi ke HDInsight
HDInsight menggabungkan komponen Apache Hadoop dan platform HDInsight ke dalam paket yang disebarkan pada kluster. Alih-alih memigrasikan Sqoop itu sendiri ke Azure, lebih umum untuk menjalankan Sqoop pada kluster HDInsight. Untuk informasi selengkapnya tentang menggunakan HDInsight untuk menjalankan kerangka kerja sumber terbuka seperti Hadoop dan Spark, lihat Apa itu Azure HDInsight? dan Panduan untuk Memigrasikan Beban Kerja Big Data ke Azure HDInsight.
Lihat artikel berikut untuk versi komponen di HDInsight.
Migrasi ke Data Factory
Azure Data Factory adalah layanan integrasi data yang dikelola sepenuhnya, tanpa server. Ini dapat diskalakan sesuai permintaan sesuai dengan faktor-faktor seperti volume data. Ini memiliki GUI untuk pengeditan dan pengembangan intuitif dengan menggunakan templat Python, .NET, dan Azure Resource Manager (templat ARM).
Koneksi ke sumber data
Lihat artikel yang sesuai untuk daftar konektor Sqoop standar:
Data Factory memiliki sejumlah besar konektor. Untuk informasi selengkapnya, lihat Gambaran umum konektor Azure Data Factory dan Azure Synapse Analytics.
Tabel berikut adalah contoh yang memperlihatkan konektor Data Factory yang akan digunakan untuk Sqoop1 versi 1.4.7 dan Sqoop2 versi 1.99.7. Pastikan untuk merujuk ke dokumentasi terbaru, karena daftar versi yang didukung dapat berubah.
| Sqoop1 - 1.4.7 | Sqoop2 - 1.99.7 | Data Factory | Pertimbangan |
|---|---|---|---|
| Konektor MySQL JDBC | Konektor JDBC Generik | MySQL, Azure Database for MySQL | |
| Konektor Langsung MySQL | T/A | T/A | Konektor Langsung menggunakan mysqldump untuk memasukkan dan menghasilkan data tanpa melalui JDBC. Metode ini berbeda di Data Factory, tetapi konektor MySQL dapat digunakan sebagai gantinya. |
| Konektor Microsoft SQL | Konektor JDBC Generik | SQL Server, Azure SQL Database, Azure SQL Managed Instance | |
| PostgreSQL Connector | PostgreSQL, Konektor JDBC Generik | Azure Database untuk PostgreSQL | |
| Konektor Langsung PostgreSQL | T/A | T/A | Konektor Langsung tidak melalui JDBC dan menggunakan perintah COPY untuk input dan output data. Metode ini berbeda di Data Factory, tetapi konektor PostgreSQL dapat digunakan sebagai gantinya. |
| konektor pg_bulkload | T/A | T/A | Muat ke PostgreSQL dengan menggunakan pg_bulkload. Metode ini berbeda di Data Factory, tetapi konektor PostgreSQL dapat digunakan sebagai gantinya. |
| Konektor Netezza | Konektor JDBC Generik | Netteza | |
| Konektor Data untuk Oracle dan Hadoop | Konektor JDBC Generik | Oracle | |
| T/A | Konektor FTP | FTP | |
| T/A | Konektor SFTP | SFTP | |
| T/A | Konektor Kafka | T/A | Data Factory tidak dapat terhubung langsung ke Kafka. Pertimbangkan untuk menggunakan Spark Streaming seperti Azure Databricks atau HDInsight untuk menyambungkan ke Kafka. |
| T/A | Konektor Layang-Layang | T/A | Data Factory tidak dapat terhubung langsung ke Layang-layang. |
| HDFS | HDFS | HDFS | Data Factory mendukung HDFS sebagai sumber, tetapi bukan sebagai sink. |
Menyambungkan ke database lokal
Jika, setelah memigrasikan Sqoop ke Data Factory, Anda masih perlu menyalin data antara penyimpanan data di jaringan lokal Anda dan Azure, pertimbangkan untuk menggunakan metode ini:
- Runtime integrasi yang di-host sendiri
- Jaringan virtual terkelola dengan menggunakan titik akhir privat
Runtime integrasi yang dihosting sendiri
Jika Anda mencoba mengintegrasikan data di lingkungan jaringan privat di mana tidak ada jalur komunikasi langsung dari lingkungan cloud publik, Anda dapat melakukan hal berikut untuk meningkatkan keamanan:
- Instal runtime integrasi yang dihost sendiri di lingkungan lokal, baik di firewall internal atau di jaringan privat virtual.
- Buat koneksi keluar berbasis HTTPS dari runtime integrasi yang dihost sendiri ke Azure untuk membuat koneksi untuk pergerakan data.
Runtime integrasi yang dihost sendiri hanya didukung di Windows. Anda juga dapat mencapai skalabilitas dan ketersediaan tinggi dengan menginstal dan mengaitkan runtime integrasi yang dihost sendiri pada beberapa komputer. Runtime integrasi yang dihost sendiri juga bertanggung jawab untuk mengirimkan aktivitas transformasi data ke sumber daya yang tidak lokal atau di jaringan virtual Azure.
Untuk informasi tentang cara menyiapkan runtime integrasi yang dihost sendiri, lihat Membuat dan mengonfigurasi runtime integrasi yang dihost sendiri.
Jaringan virtual terkelola dengan menggunakan titik akhir privat
Jika Anda memiliki koneksi privat antara lokal dan Azure (seperti ExpressRoute atau VPN Gateway), Anda dapat menggunakan jaringan virtual terkelola dan titik akhir privat di Data Factory untuk membuat koneksi privat ke database lokal Anda. Anda dapat menggunakan jaringan virtual untuk meneruskan lalu lintas ke sumber daya lokal Anda, seperti yang ditunjukkan dalam diagram berikut, untuk mengakses sumber daya lokal Anda tanpa melalui internet.

Unduh file Visio arsitektur ini.
Untuk informasi selengkapnya, lihat Tutorial: Cara mengakses SQL Server lokal dari Data Factory Managed VNet menggunakan Titik Akhir Privat.
Opsi jaringan
Data Factory memiliki dua opsi jaringan:
Keduanya membangun jaringan privat dan membantu mengamankan proses integrasi data. Mereka dapat digunakan pada saat yang sama.
Mengelola jaringan virtual
Anda dapat menyebarkan runtime integrasi, yang merupakan runtime Data Factory, dalam jaringan virtual terkelola. Dengan menyebarkan titik akhir privat seperti penyimpanan data yang terhubung ke jaringan virtual terkelola, Anda dapat meningkatkan keamanan integrasi data dalam jaringan privat tertutup.

Unduh file Visio arsitektur ini.
Untuk informasi selengkapnya, lihat Jaringan virtual terkelola Azure Data Factory.
Tautan privat
Anda dapat menggunakan Azure Private Link untuk Azure Data Factory untuk menyambungkan ke Data Factory.

Unduh file Visio arsitektur ini.
Untuk informasi selengkapnya, lihat Apa itu titik akhir privat? dan dokumentasi Private Link.
Performa salinan data
Sqoop meningkatkan performa transfer data dengan menggunakan MapReduce untuk pemrosesan paralel. Setelah Anda memigrasikan Sqoop, Data Factory dapat menyesuaikan performa dan skalabilitas untuk skenario yang melakukan migrasi data skala besar.
Unit integrasi data (DIU) adalah unit performa Data Factory. Ini adalah kombinasi dari CPU, memori, dan alokasi sumber daya jaringan. Data Factory dapat menyesuaikan hingga 256 DIUs untuk aktivitas salin yang menggunakan runtime integrasi Azure. Untuk informasi selengkapnya, lihat Unit Integrasi Data.
Jika Anda menggunakan runtime integrasi yang dihost sendiri, Anda dapat meningkatkan performa dengan menskalakan komputer yang menghosting runtime integrasi yang dihost sendiri. Peluasan skala maksimum adalah empat simpul.
Untuk informasi selengkapnya tentang membuat penyesuaian untuk mencapai performa yang Anda inginkan, lihat Menyalin performa aktivitas dan panduan skalabilitas.
Menerapkan SQL
Sqoop dapat mengimpor kumpulan hasil kueri SQL, seperti yang diperlihatkan dalam contoh ini:
$ sqoop import \
--query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' \
--split-by a.id --target-dir /user/foo/joinresults
Data Factory juga dapat mengkueri database dan menyalin kumpulan hasil:
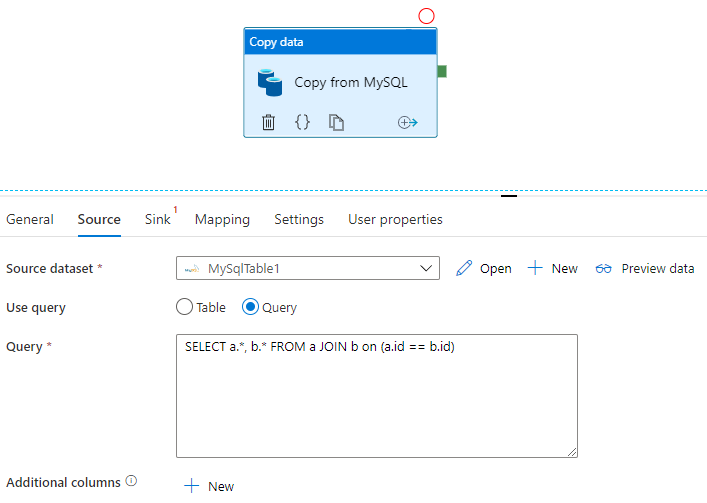
Lihat Menyalin properti aktivitas untuk contoh yang mendapatkan kumpulan hasil kueri pada database MySQL.
Transformasi data
Data Factory dan HDInsight dapat melakukan berbagai aktivitas transformasi data.
Mengubah data dengan menggunakan aktivitas Data Factory
Data Factory dapat melakukan berbagai aktivitas transformasi data, seperti aliran data dan manipulasi data. Untuk keduanya, Anda menentukan transformasi dengan menggunakan UI visual. Anda juga dapat menggunakan aktivitas berbagai komponen Hadoop hdInsight, Databricks, prosedur tersimpan, dan aktivitas kustom lainnya. Pertimbangkan untuk menggunakan aktivitas ini saat Anda memigrasikan Sqoop dan ingin menyertakan transformasi data dalam proses. Lihat Mengubah data di Azure Data Factory untuk informasi selengkapnya.
Mengubah data dengan menggunakan aktivitas HDInsight
Berbagai aktivitas HDInsight dalam alur Azure Data Factory, termasuk Apache Hive, Pig, MapReduce, Streaming, dan Spark, dapat menjalankan program dan kueri pada kluster Anda sendiri atau pada kluster HDInsight sesuai permintaan. Jika Anda memigrasikan implementasi Sqoop yang menggunakan logika transformasi data dari ekosistem Hadoop, mudah untuk memigrasikan transformasi ke aktivitas HDInsight. Untuk detailnya, lihat artikel berikut ini.
- Mengubah data menggunakan aktivitas Hadoop Hive di Azure Data Factory atau Synapse Analytics
- Mengubah data menggunakan aktivitas Hadoop MapReduce di Azure Data Factory atau Synapse Analytics
- Mengubah data menggunakan aktivitas Hadoop Pig di Azure Data Factory atau Synapse Analytics
- Mengubah data menggunakan aktivitas Spark di Azure Data Factory dan Synapse Analytics
- Mengubah data menggunakan aktivitas Streaming Hadoop di Azure Data Factory atau Synapse Analytics
Format file
Sqoop mendukung teks, SequenceFile, dan Avro sebagai format file saat mengimpor data ke HDFS. Data Factory tidak mendukung HDFS sebagai sink data, tetapi menggunakan Azure Data Lake Storage atau Azure Blob Storage sebagai penyimpanan file. Untuk informasi selengkapnya tentang migrasi HDFS, lihat migrasi Apache HDFS.
Format yang didukung untuk Data Factory untuk ditulis ke penyimpanan file adalah teks, biner, Avro, JSON, ORC, dan Parquet, tetapi bukan SequenceFile. Anda dapat menggunakan aktivitas seperti Spark untuk mengonversi file ke SequenceFile dengan menggunakan saveAsSequenceFile:
data.saveAsSequenceFile(<path>)
Menjadwalkan pekerjaan
Sqoop tidak menyediakan fungsionalitas penjadwal. Jika Anda menjalankan pekerjaan Sqoop pada penjadwal, Anda perlu memigrasikan fungsionalitas tersebut ke Data Factory. Data Factory dapat menggunakan pemicu untuk menjadwalkan eksekusi alur data. Pilih pemicu Data Factory sesuai dengan konfigurasi penjadwalan yang ada. Berikut adalah jenis pemicunya.
- Pemicu jadwal: Pemicu jadwal menjalankan alur pada jadwal jam dinding.
- Pemicu jendela tumbling: Pemicu jendela tumbling berjalan secara berkala dari waktu mulai yang ditentukan sambil mempertahankan statusnya.
- Pemicu berbasis peristiwa: Pemicu berbasis peristiwa memicu alur sebagai respons terhadap peristiwa tersebut. Ada dua jenis pemicu berbasis peristiwa:
- Pemicu peristiwa penyimpanan: Pemicu peristiwa penyimpanan memicu alur sebagai respons terhadap peristiwa penyimpanan seperti membuat, menghapus, atau menulis ke file.
- Pemicu peristiwa kustom: Pemicu peristiwa kustom memicu alur sebagai respons terhadap peristiwa yang dikirim ke topik kustom dalam kisi peristiwa. Untuk informasi tentang topik kustom, lihat Topik kustom di Azure Event Grid.
Untuk informasi selengkapnya tentang pemicu, lihat Eksekusi dan pemicu alur di Azure Data Factory atau Azure Synapse Analytics.
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Namrata Maheshwary | Arsitek Solusi Cloud Senior
- Raja N | Direktur, Keberhasilan Pelanggan
- Hideo Takagi | Arsitek Solusi Cloud
- Ram Yerrabotu | Arsitek Solusi Cloud Senior
Kontributor lain:
- Ram Baskaran | Arsitek Solusi Cloud Senior
- Jason Bouska | Insinyur Perangkat Lunak Senior
- Eugene Chung | Arsitek Solusi Cloud Senior
- Pawan Hosatti | Arsitek Solusi Cloud Senior - Teknik
- Daman Kaur | Arsitek Solusi Cloud
- Danny Liu | Arsitek Solusi Cloud Senior - Teknik
- Arsitek Solusi Cloud Senior Jose Mendez
- Ben Sadeghi | Spesialis Senior
- Sunil Sattiraju | Arsitek Solusi Cloud Senior
- Amanjeet Singh | Manajer Program Utama
- Nagaraj Seeplapudur Venkatesan | Arsitek Solusi Cloud Senior - Teknik
Untuk melihat profil LinkedIn non-publik, masuk ke LinkedIn.
Langkah berikutnya
Pengenalan produk Azure
- Pengantar Azure Data Lake Storage Gen2
- Apa itu Apache Spark di Azure HDInsight?
- Apa itu Apache Hadoop di Azure HDInsight?
- Apa itu Apache HBase di Azure HDInsight?
- Apa itu Apache Kafka di Azure HDInsight?
- Gambaran umum keamanan perusahaan di Microsoft Azure HDInsight
Referensi produk Azure
- Dokumentasi Microsoft Entra
- Dokumentasi Azure Cosmos DB
- Dokumentasi Azure Data Factory
- Dokumentasi Azure Databricks
- Dokumentasi Azure Event Hubs
- Dokumentasi Azure Functions
- Dokumentasi Azure HDInsight
- Dokumentasi tata kelola data Microsoft Purview
- Dokumentasi Azure Stream Analytics
- Azure Synapse Analytics
Lainnya
- Paket Keamanan Perusahaan untuk Azure HDInsight
- Kembangkan program Java MapReduce untuk Apache Hadoop di HDInsight
- Menggunakan Apache Sqoop dengan Hadoop di HDInsight
- Gambaran Umum Apache Spark Streaming
- Tutorial Streaming Terstruktur
- Menggunakan Azure Event Hubs dari aplikasi Apache Kafka