Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Jumlah solusi multipenyewa yang terus meningkat dibangun di sekitar kecerdasan buatan (AI) dan pembelajaran mesin (ML). Solusi AI/ML multipenyewa adalah solusi yang menyediakan kemampuan berbasis ML serupa dengan sejumlah penyewa. Penyewa umumnya tidak dapat melihat atau berbagi data penyewa lain, tetapi dalam beberapa situasi, penyewa mungkin menggunakan model yang sama dengan penyewa lain.
Arsitektur AI/ML multipenyewa perlu mempertimbangkan persyaratan untuk data dan model, serta sumber daya komputasi yang diperlukan untuk melatih model dan melakukan inferensi dari model. Penting untuk mempertimbangkan bagaimana model AI/ML multipenyewa disebarkan, didistribusikan, dan diorkestrasi, dan untuk memastikan bahwa solusi Anda akurat, andal, dan dapat diskalakan.
Sebagai teknologi AI generatif, didukung oleh model bahasa besar dan kecil, mendapatkan popularitas, sangat penting untuk menetapkan praktik dan strategi operasional yang efektif untuk mengelola model ini di lingkungan produksi melalui adopsi operasi Pembelajaran Mesin (MLOps) dan GenAIOps (kadang-kadang dikenal sebagai LLMOps).
Pertimbangan dan persyaratan utama
Ketika Anda bekerja dengan AI dan ML, penting untuk secara terpisah mempertimbangkan persyaratan Anda untuk pelatihan dan untuk inferensi. Tujuan pelatihan adalah untuk membangun model prediktif yang didasarkan pada sekumpulan data. Anda melakukan inferensi saat menggunakan model untuk memprediksi sesuatu di aplikasi Anda. Masing-masing proses ini memiliki persyaratan yang berbeda. Dalam solusi multipenyewa, Anda harus mempertimbangkan bagaimana model penyewaan Anda memengaruhi setiap proses. Dengan mempertimbangkan masing-masing persyaratan ini, Anda dapat memastikan bahwa solusi Anda memberikan hasil yang akurat, berkinerja baik di bawah beban, hemat biaya, dan dapat menskalakan untuk pertumbuhan Anda di masa depan.
Isolasi penyewa
Pastikan bahwa penyewa tidak mendapatkan akses yang tidak sah atau tidak diinginkan ke data atau model penyewa lain. Perlakukan model dengan sensitivitas yang sama dengan data mentah yang melatihnya. Pastikan penyewa Anda memahami bagaimana data mereka digunakan untuk melatih model, dan bagaimana model yang dilatih pada data penyewa lain mungkin digunakan untuk tujuan inferensi pada beban kerja mereka.
Ada tiga pendekatan umum untuk bekerja dengan model ML dalam solusi multipenyewa: model khusus penyewa, model bersama, dan model bersama yang disetel.
Model khusus penyewa
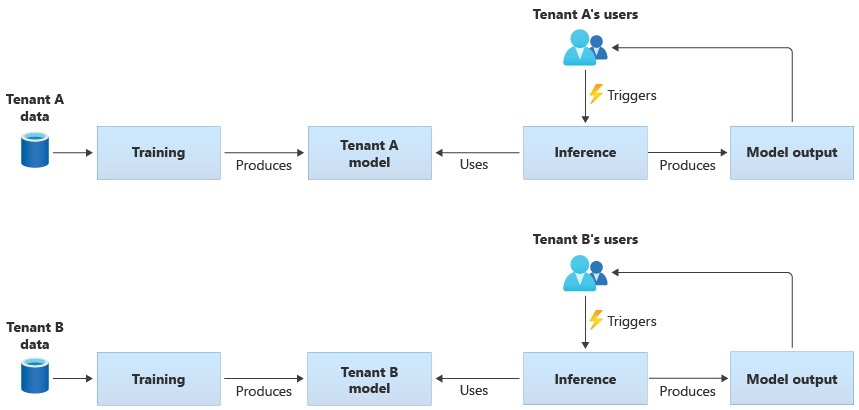
Model khusus penyewa hanya dilatih pada data untuk satu penyewa, lalu diterapkan ke penyewa tunggal tersebut. Model khusus penyewa sesuai ketika data penyewa Anda sensitif, atau ketika ada sedikit cakupan untuk belajar dari data yang disediakan oleh satu penyewa, dan Anda menerapkan model ke penyewa lain. Diagram berikut mengilustrasikan bagaimana Anda dapat membangun solusi dengan model khusus penyewa untuk dua penyewa:
Model bersama
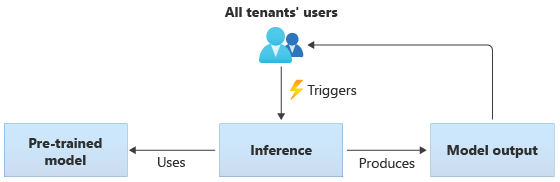
Dalam solusi yang menggunakan model bersama, semua penyewa melakukan inferensi berdasarkan model bersama yang sama. Model bersama mungkin merupakan model yang telah dilatih sebelumnya yang Anda peroleh atau peroleh dari sumber komunitas. Diagram berikut menggambarkan bagaimana satu model yang telah dilatih dapat digunakan untuk inferensi oleh semua penyewa:
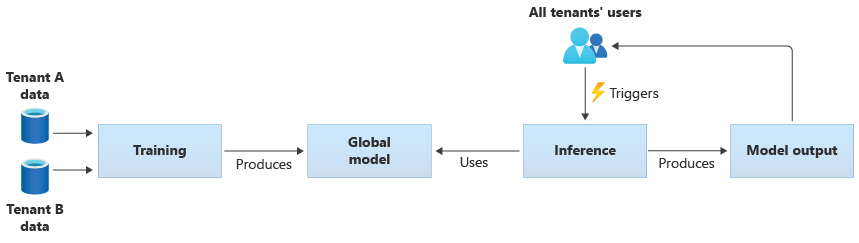
Anda juga dapat membangun model bersama Anda sendiri dengan melatihnya dari data yang disediakan oleh semua penyewa Anda. Diagram berikut mengilustrasikan satu model bersama, yang dilatih pada data dari semua penyewa:
Penting
Jika Anda melatih model bersama dari data penyewa, pastikan penyewa Anda memahami dan menyetujui penggunaan data mereka. Pastikan informasi identifikasi dihapus dari data penyewa Anda.
Pertimbangkan apa yang harus dilakukan, jika penyewa objek ke data mereka digunakan untuk melatih model yang akan diterapkan ke penyewa lain. Misalnya, apakah Anda dapat mengecualikan data penyewa tertentu dari himpunan data pelatihan?
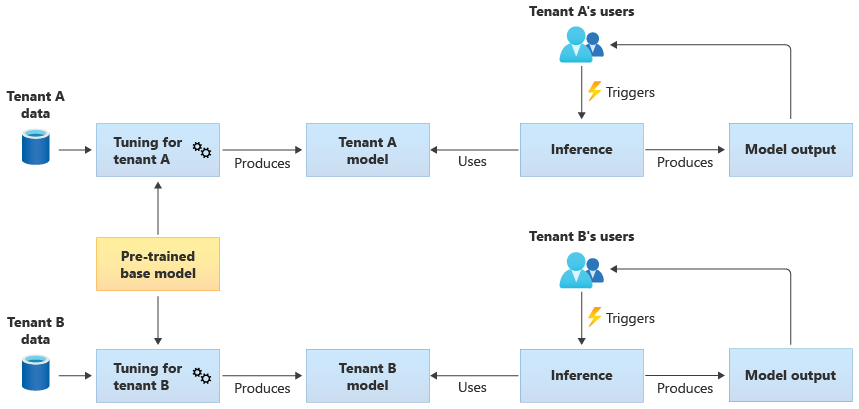
Menyetel model bersama
Anda juga dapat memilih untuk memperoleh model dasar yang telah dilatih sebelumnya, lalu melakukan penyetelan model lebih lanjut untuk membuatnya berlaku untuk setiap penyewa Anda, berdasarkan data mereka sendiri. Diagram berikut mengilustrasikan pendekatan ini:
Skalabilitas
Pertimbangkan bagaimana pertumbuhan solusi Anda memengaruhi penggunaan komponen AI dan ML Anda. Pertumbuhan dapat mengacu pada peningkatan jumlah penyewa, jumlah data yang disimpan untuk setiap penyewa, jumlah pengguna, dan volume permintaan ke solusi Anda.
Pelatihan: Ada beberapa faktor yang memengaruhi sumber daya yang diperlukan untuk melatih model Anda. Faktor-faktor ini termasuk jumlah model yang perlu Anda latih, jumlah data yang Anda latih modelnya, dan frekuensi Anda melatih atau melatih kembali model. Jika Anda membuat model khusus penyewa, maka seiring bertambahnya jumlah penyewa Anda, jumlah sumber daya komputasi dan penyimpanan yang Anda butuhkan juga akan cenderung bertambah. Jika Anda membuat model bersama dan melatihnya berdasarkan data dari semua penyewa Anda, kemungkinan kecil sumber daya untuk pelatihan akan diskalakan pada tingkat yang sama dengan pertumbuhan jumlah penyewa Anda. Namun, peningkatan jumlah keseluruhan data pelatihan akan memengaruhi sumber daya yang digunakan, untuk melatih model bersama dan khusus penyewa.
Kesimpulan: Sumber daya yang diperlukan untuk inferensi biasanya sebanding dengan jumlah permintaan yang mengakses model untuk inferensi. Ketika jumlah penyewa meningkat, jumlah permintaan juga cenderung meningkat.
Ini adalah praktik umum yang baik untuk menggunakan layanan Azure yang menskalakan dengan baik. Karena beban kerja AI/ML cenderung menggunakan kontainer, Azure Kubernetes Service (AKS) dan Azure Container Instances (ACI) cenderung menjadi pilihan umum untuk beban kerja AI/ML. AKS biasanya merupakan pilihan yang baik untuk mengaktifkan skala tinggi, dan untuk menskalakan sumber daya komputasi Anda secara dinamis berdasarkan permintaan. Untuk beban kerja kecil, ACI dapat menjadi platform komputasi sederhana untuk dikonfigurasi, meskipun tidak menskalakan semampu AKS.
Performa
Pertimbangkan persyaratan performa untuk komponen AI/ML solusi Anda, untuk pelatihan dan inferensi. Penting untuk mengklarifikasi latensi dan persyaratan performa Anda untuk setiap proses, sehingga Anda dapat mengukur dan meningkatkan sesuai kebutuhan.
Pelatihan: Pelatihan sering dilakukan sebagai proses batch, yang berarti bahwa itu mungkin tidak sensitif terhadap performa seperti bagian lain dari beban kerja Anda. Namun, Anda perlu memastikan bahwa Anda menyediakan sumber daya yang memadai untuk melakukan pelatihan model Anda secara efisien, termasuk saat Anda menskalakan.
Kesimpulan: Inferensi adalah proses yang sensitif terhadap latensi, sering membutuhkan respons yang cepat atau bahkan real-time. Bahkan jika Anda tidak perlu melakukan inferensi secara real time, pastikan Anda memantau performa solusi Anda dan menggunakan layanan yang sesuai untuk mengoptimalkan beban kerja Anda.
Pertimbangkan untuk menggunakan kemampuan komputasi performa tinggi Azure untuk beban kerja AI dan ML Anda. Azure menyediakan berbagai jenis komputer virtual dan instans perangkat keras lainnya. Pertimbangkan apakah solusi Anda akan mendapat manfaat dari menggunakan CPU, GPU, FPGA, atau lingkungan yang dipercepat perangkat keras lainnya. Azure juga menyediakan inferensi real time dengan GPU NVIDIA, termasuk Server Inferensi NVIDIA Triton. Untuk persyaratan komputasi berprioritas rendah, pertimbangkan untuk menggunakan kumpulan simpul spot AKS. Untuk mempelajari selengkapnya tentang mengoptimalkan layanan komputasi dalam solusi multipenyewa, lihat Pendekatan arsitektur untuk komputasi dalam solusi multipenyewa.
Pelatihan model biasanya memerlukan banyak interaksi dengan penyimpanan data Anda, jadi penting juga untuk mempertimbangkan strategi data Anda dan performa yang disediakan tingkat data Anda. Untuk informasi selengkapnya tentang multipenyewa dan layanan data, lihat Pendekatan arsitektur untuk penyimpanan dan data dalam solusi multipenyewa.
Pertimbangkan untuk membuat profil performa solusi Anda. Misalnya, Azure Machine Learning menyediakan kemampuan pembuatan profil yang dapat Anda gunakan saat mengembangkan dan melengkapi solusi Anda.
Kompleksitas implementasi
Saat Anda membangun solusi untuk menggunakan AI dan ML, Anda dapat memilih untuk menggunakan komponen bawaan, atau untuk membangun komponen kustom. Ada dua keputusan utama yang perlu Anda buat. Yang pertama adalah platform atau layanan yang Anda gunakan untuk AI dan ML. Yang kedua adalah apakah Anda menggunakan model yang telah dilatih sebelumnya atau membangun model kustom Anda sendiri.
Platform: Ada banyak layanan Azure yang dapat Anda gunakan untuk beban kerja AI dan ML Anda. Misalnya, Azure AI Services dan Azure OpenAI di Foundry Model menyediakan API untuk melakukan inferensi terhadap model bawaan, dan Microsoft mengelola sumber daya yang mendasarinya. Azure AI Services memungkinkan Anda menyebarkan solusi baru dengan cepat, tetapi memberi Anda lebih sedikit kontrol atas bagaimana pelatihan dan inferensi dilakukan, dan mungkin tidak sesuai dengan setiap jenis beban kerja. Sebaliknya, Azure Pembelajaran Mesin adalah platform yang memungkinkan Anda membangun, melatih, dan menggunakan model ML Anda sendiri. Azure Pembelajaran Mesin memberikan kontrol dan fleksibilitas, tetapi meningkatkan kompleksitas desain dan implementasi Anda. Tinjau produk dan teknologi pembelajaran mesin dari Microsoft untuk membuat keputusan berdasarkan informasi saat memilih pendekatan.
Model: Bahkan ketika Anda tidak menggunakan model lengkap yang disediakan oleh layanan seperti Azure AI Services, Anda masih dapat mempercepat pengembangan Anda dengan menggunakan model yang telah dilatih sebelumnya. Jika model yang telah dilatih sebelumnya tidak sesuai dengan kebutuhan Anda, pertimbangkan untuk memperluas model yang telah dilatih sebelumnya dengan menerapkan teknik yang disebut pembelajaran transfer atau penyempurnaan. Pembelajaran transfer memungkinkan Anda memperluas model yang ada dan menerapkannya ke domain yang berbeda. Misalnya, jika Anda membangun layanan rekomendasi musik multipenyewa, Anda mungkin mempertimbangkan untuk membangun model rekomendasi musik yang telah dilatih sebelumnya, dan menggunakan pembelajaran transfer untuk melatih model untuk preferensi musik pengguna tertentu.
Dengan menggunakan platform ML bawaan seperti Azure AI Services atau Azure OpenAI, atau model yang telah dilatih sebelumnya, Anda dapat secara signifikan mengurangi biaya penelitian dan pengembangan awal Anda. Penggunaan platform bawaan mungkin menghemat banyak bulan penelitian Anda, dan menghindari kebutuhan untuk merekrut ilmuwan data yang sangat memenuhi syarat untuk melatih, merancang, dan mengoptimalkan model.
Pengoptimalan biaya
Umumnya, beban kerja AI dan ML menimbulkan proporsi terbesar biayanya dari sumber daya komputasi yang diperlukan untuk pelatihan dan inferensi model. Tinjau Pendekatan arsitektur untuk komputasi dalam solusi multipenyewa untuk memahami cara mengoptimalkan biaya beban kerja komputasi Anda untuk kebutuhan Anda.
Pertimbangkan persyaratan berikut saat merencanakan biaya AI dan ML Anda:
- Tentukan SKU komputasi untuk pelatihan. Misalnya, lihat panduan tentang cara melakukan ini dengan Azure Machine Learning.
- Tentukan SKU komputasi untuk inferensi. Sebagai contoh perkiraan biaya untuk inferensi, lihat panduan untuk Azure Machine Learning.
- Pantau pemanfaatan Anda. Dengan mengamati pemanfaatan sumber daya komputasi, Anda dapat menentukan apakah Anda harus mengurangi atau meningkatkan kapasitasnya dengan menyebarkan SKU yang berbeda, atau menskalakan sumber daya komputasi saat kebutuhan Anda berubah. Lihat Azure Machine Learning Monitor.
- Optimalkan lingkungan pengklusteran komputasi Anda. Saat Anda menggunakan kluster komputasi, pantau pemanfaatan kluster atau konfigurasikan penskalaan otomatis untuk menurunkan skala simpul komputasi.
- Bagikan sumber daya komputasi Anda. Pertimbangkan apakah Anda dapat mengoptimalkan biaya sumber daya komputasi Anda dengan membagikannya di beberapa penyewa.
- Pertimbangkan anggaran Anda. Pahami apakah Anda memiliki anggaran tetap, dan pantau konsumsi Anda dengan sesuai. Anda dapat menyiapkan anggaran untuk mencegah pengeluaran berlebih dan mengalokasikan kuota berdasarkan prioritas penyewa.
Pendekatan dan pola yang perlu dipertimbangkan
Azure menyediakan serangkaian layanan untuk mengaktifkan beban kerja AI dan ML. Ada beberapa pendekatan arsitektur umum yang digunakan dalam solusi multipenyewa: untuk menggunakan solusi AI/ML bawaan, untuk membangun arsitektur AI/ML kustom dengan menggunakan Azure Pembelajaran Mesin, dan menggunakan salah satu platform analitik Azure.
Menggunakan layanan AI/ML bawaan
Ini adalah praktik yang baik untuk mencoba menggunakan layanan AI/ML bawaan, di mana Anda bisa. Misalnya, organisasi Anda mungkin mulai melihat AI/ML dan ingin dengan cepat berintegrasi dengan layanan yang berguna. Atau, Anda mungkin memiliki persyaratan dasar yang tidak memerlukan pelatihan dan pengembangan model ML kustom. Layanan ML bawaan memungkinkan Anda menggunakan inferensi tanpa membangun dan melatih model Anda sendiri.
Azure menyediakan beberapa layanan yang menyediakan teknologi AI dan ML di berbagai domain, termasuk pemahaman bahasa, pengenalan ucapan, pengetahuan, pengenalan dokumen dan formulir, dan visi komputer. Layanan AI/ML bawaan Azure mencakup Azure AI Services, Azure OpenAI di Foundry Models, Azure AI Search, dan Azure AI Document Intelligence. Setiap layanan menyediakan antarmuka sederhana untuk integrasi, dan kumpulan model yang telah dilatih dan diuji sebelumnya. Sebagai layanan terkelola, mereka menyediakan perjanjian tingkat layanan dan memerlukan sedikit konfigurasi atau manajemen yang sedang berlangsung. Anda tidak perlu mengembangkan atau menguji model Anda sendiri untuk menggunakan layanan ini.
Banyak layanan ML terkelola tidak memerlukan pelatihan atau data model, jadi biasanya tidak ada masalah isolasi data penyewa. Namun, saat Anda bekerja dengan Pencarian AI dalam solusi multipenyewa, tinjau Pola desain untuk aplikasi SaaS multipenyewa dan Azure AI Search.
Pertimbangkan persyaratan skala untuk komponen dalam solusi Anda. Misalnya, banyak API dalam Azure AI Services mendukung jumlah maksimum permintaan per detik. Jika Anda menyebarkan satu sumber daya Layanan AI untuk dibagikan di seluruh penyewa Anda, maka saat jumlah penyewa meningkat, Anda mungkin perlu menskalakan ke beberapa sumber daya.
Catatan
Beberapa layanan terkelola memungkinkan Anda berlatih dengan data Anda sendiri, termasuk layanan Custom Vision, Face API, model kustom Kecerdasan Dokumen, dan beberapa model OpenAI yang mendukung penyesuaian dan penyempurnaan. Saat Anda bekerja dengan layanan ini, penting untuk mempertimbangkan persyaratan isolasi untuk data penyewa Anda.
Arsitektur AI/ML kustom
Jika solusi Anda memerlukan model kustom, atau Anda bekerja di domain yang tidak tercakup oleh layanan ML terkelola, maka pertimbangkan untuk membangun arsitektur AI/ML Anda sendiri. Azure Machine Learning menyediakan serangkaian kemampuan untuk mengatur pelatihan dan penyebaran model ML. Azure Machine Learning mendukung banyak pustaka pembelajaran mesin sumber terbuka, termasuk PyTorch, TensorFlow, Scikit, dan Keras. Anda dapat terus memantau metrik performa model, mendeteksi penyimpangan data, dan memicu pelatihan ulang untuk meningkatkan performa model. Sepanjang siklus hidup model ML Anda, Azure Pembelajaran Mesin memungkinkan auditabilitas dan tata kelola dengan pelacakan dan silsilah data bawaan untuk semua artefak ML Anda.
Saat bekerja dalam solusi multipenyewa, penting untuk mempertimbangkan persyaratan isolasi penyewa Anda selama tahap pelatihan dan inferensi. Anda juga perlu menentukan proses pelatihan dan penyebaran model Anda. Azure Pembelajaran Mesin menyediakan alur untuk melatih model, dan untuk menyebarkannya ke lingkungan yang akan digunakan untuk inferensi. Dalam konteks multipenyewa, pertimbangkan apakah model harus disebarkan ke sumber daya komputasi bersama, atau jika setiap penyewa memiliki sumber daya khusus. Desain alur penyebaran model Anda, berdasarkan model isolasi dan proses penyebaran penyewa Anda.
Saat Anda menggunakan model sumber terbuka, Anda mungkin perlu melatih kembali model ini dengan menggunakan pembelajaran transfer atau penyetelan. Pertimbangkan bagaimana Anda akan mengelola berbagai model dan data pelatihan untuk setiap penyewa, serta versi model.
Diagram berikut mengilustrasikan contoh arsitektur yang menggunakan Azure Pembelajaran Mesin. Contohnya menggunakan pendekatan isolasi model khusus penyewa .
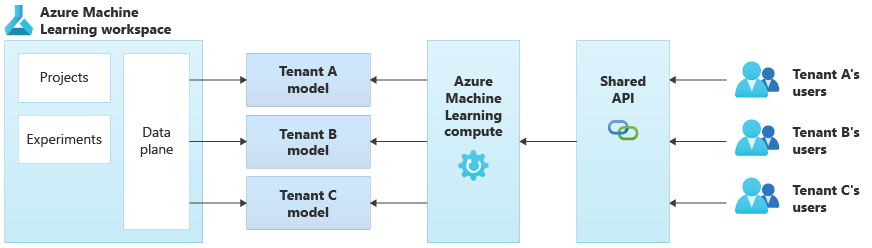
Solusi AI/ML terintegrasi
Azure menyediakan beberapa platform analitik canggih yang dapat digunakan untuk berbagai tujuan. Platform ini termasuk Azure Synapse Analytics, Databricks, dan Apache Spark.
Anda dapat mempertimbangkan untuk menggunakan platform ini untuk AI/ML, ketika Anda perlu menskalakan kemampuan ML Anda ke sejumlah besar penyewa, dan ketika Anda membutuhkan komputasi dan orkestrasi skala besar. Anda juga dapat mempertimbangkan untuk menggunakan platform ini untuk AI/ML, saat Anda memerlukan platform analitik yang luas untuk bagian lain dari solusi Anda, seperti untuk analitik data dan integrasi dengan pelaporan melalui Microsoft Power BI. Anda dapat menyebarkan satu platform yang mencakup semua kebutuhan analitik dan AI/ML Anda. Saat Anda menerapkan platform data dalam solusi multipenyewa, tinjau Pendekatan arsitektur untuk penyimpanan dan data dalam solusi multipenyewa.
Model operasional ML
Saat mengadopsi AI dan pembelajaran mesin, termasuk praktik AI generatif, ini adalah praktik yang baik untuk terus meningkatkan dan menilai kemampuan organisasi Anda dalam mengelolanya. Pengenalan MLOps dan GenAIOps secara objektif menyediakan kerangka kerja untuk terus memperluas kemampuan praktik AI dan ML Anda di organisasi Anda. Tinjau dokumen MLOps Maturity Model dan LLMOps Maturity Model untuk panduan lebih lanjut.
Antipattern yang perlu dihindari
- Kegagalan untuk mempertimbangkan persyaratan isolasi. Penting untuk mempertimbangkan dengan cermat bagaimana Anda mengisolasi data dan model penyewa, baik untuk pelatihan maupun inferensi. Gagal melakukannya mungkin melanggar persyaratan hukum atau kontraktual. Ini juga dapat mengurangi akurasi model Anda untuk dilatih di beberapa data penyewa, jika datanya sangat berbeda.
- Tetangga berisik. Pertimbangkan apakah proses pelatihan atau inferensi Anda dapat tunduk pada masalah Noisy Neighbor. Misalnya, jika Anda memiliki beberapa penyewa besar dan satu penyewa kecil, pastikan bahwa pelatihan model untuk penyewa besar tidak secara tidak sengaja menggunakan semua sumber daya komputasi dan kelaparan penyewa yang lebih kecil. Gunakan tata kelola dan pemantauan sumber daya untuk mengurangi risiko beban kerja komputasi penyewa yang terpengaruh oleh aktivitas penyewa lain.
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Kevin Ashley | Insinyur Pelanggan Senior, FastTrack untuk Azure
Kontributor lain:
- Paul Burpo | Teknisi Pelanggan Utama, FastTrack untuk Azure
- John Downs | Insinyur Perangkat Lunak Utama
- Daniel Scott-Raynsford | Ahli Strategi Teknologi untuk Mitra
- Arsen Vladimirskiy | Teknisi Pelanggan Utama, FastTrack untuk Azure
- Vic Perdana | Arsitek Solusi Mitra ISV
Langkah berikutnya
- Tinjau Pendekatan arsitektur untuk komputasi dalam pendekatan solusi multipenyewa .
- Untuk mempelajari selengkapnya tentang merancang pipeline Azure Machine Learning untuk mendukung multi-penyewa, lihat Solusi untuk Alur ML dalam Mode Multi-penyewa.