Komunikasi antara layanan mikro harus efisien dan kuat. Dengan banyak layanan kecil yang berinteraksi untuk menyelesaikan satu aktivitas bisnis, ini bisa menjadi tantangan. Pada artikel ini, kita melihat tradeoff antara pesan asinkron versus API sinkron. Kemudian kita melihat beberapa tantangan dalam merancang komunikasi antar layanan yang tangguh.
Tantangan
Berikut adalah beberapa tantangan utama yang timbul dari komunikasi layanan-ke-layanan. Layanan jala, dijelaskan kemudian dalam artikel ini, dirancang untuk menangani banyak tantangan ini.
Ketahanan. Mungkin ada puluhan atau bahkan ratusan instans dari setiap layanan mikro tertentu. Sebuah instans dapat gagal karena sejumlah alasan. Mungkin ada kegagalan tingkat node, seperti kegagalan perangkat keras atau reboot VM. Instans mungkin crash, atau kewalahan dengan permintaan dan tidak dapat memproses permintaan baru apa pun. Salah satu peristiwa ini dapat menyebabkan panggilan jaringan gagal. Ada dua pola desain yang dapat membantu membuat panggilan jaringan layanan-ke-layanan lebih tangguh:
Coba lagi. Panggilan jaringan mungkin gagal karena kesalahan sementara yang hilang dengan sendirinya. Daripada gagal langsung, penelepon biasanya harus mencoba kembali operasi beberapa kali, atau sampai periode time-out yang dikonfigurasi berlalu. Namun, jika operasi tidak idempotent, percobaan kembali dapat menyebabkan efek samping yang tidak diinginkan. Panggilan asli mungkin berhasil, tetapi pemanggil tidak pernah mendapat tanggapan. Jika pemanggil mencoba ulang, operasi dapat dipanggil dua kali. Umumnya, tidak aman untuk mencoba kembali metode POST atau PATCH, karena ini tidak dijamin idempotent.
Pemutus Sirkuit. Terlalu banyak permintaan yang gagal dapat menyebabkan penyempitan, karena permintaan sedang diproses menumpuk di antrean. Permintaan yang diblokir ini mungkin menyimpan sumber daya sistem penting seperti memori, utas, koneksi database, dan sebagainya, yang dapat menyebabkan kegagalan cascading. Pola Circuit Breaker dapat mencegah layanan berulang kali mencoba operasi yang kemungkinan akan gagal.
Penyeimbangan beban. Saat layanan "A" memanggil layanan "B", permintaan harus menjangkau instans layanan "B" yang berjalan. Di Kubernetes, Service jenis sumber daya menyediakan alamat IP yang stabil untuk grup pod. Lalu lintas jaringan ke layanan alamat IP diteruskan ke pod melalui aturan iptable. Secara default, pod acak dipilih. Layanan jala (lihat di bawah) dapat memberikan algoritma penyeimbangan beban yang lebih cerdas berdasarkan latensi yang diamati atau metrik lainnya.
Pelacakan terdistribusi. Transaksi tunggal dapat mencakup beberapa layanan. Itu bisa membuat sulit untuk memantau performa dan kesehatan keseluruhan sistem. Bahkan jika setiap layanan menghasilkan log dan metrik, tanpa beberapa cara untuk mengikatnya bersama-sama, mereka dapat digunakan secara terbatas. Artikel Pembuatan log dan pemantauan berbicara lebih banyak tentang pelacakan terdistribusi, tetapi kami menyebutkannya di sini sebagai tantangan.
Penerapan versi layanan. Ketika tim menyebarkan versi baru layanan, mereka harus menghindari memutus layanan lain atau klien eksternal yang bergantung padanya. Selain itu, Anda mungkin ingin menjalankan beberapa versi layanan berdampingan, dan merutekan permintaan ke versi tertentu. Lihat Penerapan versi API untuk diskusi lebih lanjut tentang masalah ini.
Enkripsi TLS dan autentikasi TLS bersama. Untuk alasan keamanan, Anda mungkin ingin mengenkripsi lalu lintas antara layanan dengan TLS, dan menggunakan autentikasi TLS bersama untuk mengautentikasi penelepon.
Olahpesan sinkron versus asinkron
Ada dua pola Olahpesan dasar yang dapat digunakan oleh layanan mikro untuk berkomunikasi dengan layanan mikro lainnya.
Komunikasi sinkron. Dalam pola ini, layanan memanggil API yang diekspos oleh layanan lain, menggunakan protokol seperti HTTP atau gRPC. Opsi ini adalah pola Olahpesan sinkron karena penelepon menunggu respons dari penerima.
Pesan asinkron lewat. Dalam pola ini, layanan mengirim pesan tanpa menunggu respons, dan satu atau lebih layanan memproses pesan secara asinkron.
Sangat penting untuk membedakan antara I/O asinkron dan protokol asinkron. I/O Asinkron berarti rangkaian panggilan tidak diblokir saat I/O selesai. Itu penting untuk performa, tetapi merupakan detail penerapan dalam hal arsitektur. Protokol asinkron berarti pengirim tidak menunggu respons. HTTP adalah protokol sinkron, meskipun klien HTTP dapat menggunakan I/O asinkron ketika mengirimkan permintaan.
Ada tradeoffs untuk setiap pola. Permintaan / respons adalah paradigma yang dipahami dengan baik, sehingga merancang API mungkin terasa lebih alami daripada merancang sistem Olahpesan. Namun, Olahpesan asinkron memiliki beberapa keunggulan yang dapat berguna dalam arsitektur layanan mikro:
Kopling yang dikurangi. Pengirim pesan tidak perlu tahu tentang konsumen.
Beberapa database pelanggan. Dengan menggunakan pub / sub model, beberapa konsumen dapat berlangganan untuk menerima peristiwa. Lihat Gaya arsitektur yang digerakkan oleh peristiwa.
Kegagalan isolasi. Jika konsumen gagal, pengirim masih dapat mengirim pesan. Pesan akan diambil ketika konsumen dipulihkan. Kemampuan ini sangat berguna dalam arsitektur layanan mikro, karena setiap layanan memiliki siklus hidupnya sendiri. Layanan dapat menjadi tidak tersedia atau diganti dengan versi yang lebih baru pada waktu tertentu. Pesan asinkron dapat menghandel downtime terputus-putus. API sinkron, di sisi lain, memerlukan layanan hilir tersedia atau operasi gagal.
Daya tanggap. Layanan upstram dapat membalas lebih cepat jika tidak menunggu layanan hilir. Hal ini sangat berguna dalam arsitektur layanan mikro. Jika ada rantai dependensi layanan (layanan A memanggil B, yang memanggil C, dan seterusnya), yang menunggu panggilan sinkron dapat menambahkan jumlah latensi yang tidak dapat diterima.
Tingkatan beban. Antrean dapat bertindak sebagai buffer untuk meratakan beban kerja, sehingga penerima dapat memproses pesan dengan kecepatan mereka sendiri.
Alur kerja. Antrean dapat digunakan untuk mengelola alur kerja, dengan memeriksa titik pesan setelah setiap langkah dalam alur kerja.
Namun, ada juga beberapa tantangan untuk menggunakan Olahpesan asinkron secara efektif.
Kopling dengan infrastruktur Olahpesan. Menggunakan infrastruktur Olahpesan tertentu dapat menyebabkan kopling yang ketat dengan infrastruktur itu. Akan sulit untuk beralih ke infrastruktur Olahpesan lain nanti.
Latensi. Latensi end-to-end untuk operasi mungkin menjadi tinggi jika antrean pesan terisi.
Biaya. Pada throughput tinggi, biaya moneter dari infrastruktur Olahpesan bisa menjadi signifikan.
Kompleksitas. Menghandel Olahpesan asinkron bukanlah tugas yang sepele. Misalnya, Anda harus menghandel pesan duplikat, baik dengan de-duplikasi atau dengan membuat idempotent operasi. Juga sulit untuk menerapkan semantik permintaan-respons menggunakan pesan asinkron. Untuk mengirim respons, Anda memerlukan antrean lain, ditambah cara untuk menghubungkan pesan permintaan dan respons.
Throughput. Jika pesan memerlukan semantik antrean, antrean bisa menjadi hambatan dalam sistem. Setiap pesan membutuhkan setidaknya satu operasi antrean dan satu operasi dequeue. Selain itu, semantik antrean umumnya memerlukan semacam penguncian di dalam infrastruktur Olahpesan. Jika antrean adalah layanan terkelola, mungkin ada latensi tambahan, karena antrean berada di luar jaringan virtual kluster. Anda dapat mengurangi masalah ini dengan batching pesan, tetapi itu mempersulit kode. Jika pesan tidak memerlukan semantik antrean, Anda mungkin dapat menggunakan aliran peristiwa, bukan antrean. Untuk informasi selengkapnya, lihat Gaya arsitektur berbasis peristiwa.
Pengiriman Drone: Memilih pola Olahpesan
Solusi ini menggunakan contoh Pengiriman Drone. Ini ideal untuk industri dirgantara dan pesawat terbang.
Dengan mempertimbangkan pertimbangan ini, tim pengembangan membuat pilihan desain berikut untuk aplikasi Pengiriman Drone:
Layanan Ingestion mengekspos REST API publik yang digunakan aplikasi klien untuk menjadwalkan, memperbarui, atau membatalkan pengiriman.
Layanan Ingestion menggunakan Azure Event Hubs untuk mengirim pesan asinkron ke layanan Microsoft Azure Scheduler. Pesan asinkron diperlukan untuk menerapkan peningkatan beban yang diperlukan untuk konsumsi.
Layanan Akun, Pengiriman, Paket, Drone, dan Transportasi Pihak Ketiga semuanya mengekspos REST API internal. Layanan Microsoft Azure Scheduler memanggil API ini untuk melaksanakan permintaan pengguna. Salah satu alasan untuk menggunakan API sinkron adalah bahwa Microsoft Azure Scheduler perlu mendapatkan tanggapan dari masing-masing layanan hilir. Kegagalan dalam salah satu layanan hilir berarti seluruh operasi gagal. Namun, masalah potensial adalah jumlah latensi yang diperkenalkan dengan memanggil layanan backend.
Jika ada layanan hilir yang mengalami kegagalan nontransient, seluruh transaksi harus ditandai sebagai gagal. Untuk menangani kasus ini, layanan Microsoft Azure Scheduler mengirimkan pesan asinkron kepada Supervisor, sehingga Supervisor dapat menjadwalkan transaksi kompensasi.
Layanan Pengiriman mengekspos API publik yang dapat digunakan klien untuk mendapatkan status pengiriman. Dalam artikel API gateway, kita membahas bagaimana gateway API dapat menyembunyikan layanan yang mendasarinya dari klien, sehingga klien tidak perlu tahu layanan mana yang mengekspos API mana.
Sementara drone sedang dalam penerbangan, layanan Drone mengirimkan peristiwa yang berisi lokasi dan status drone saat ini. Layanan Pengiriman mendengarkan peristiwa ini untuk melacak status pengiriman.
Ketika status pengiriman berubah, layanan Pengiriman mengirimkan peristiwa status pengiriman, seperti
DeliveryCreatedatauDeliveryCompleted. Layanan apa pun dapat berlangganan acara ini. Dalam desain saat ini, layanan Riwayat Pengiriman adalah satu-satunya pelanggan, tetapi mungkin ada pelanggan lain nanti. Misalnya, peristiwa mungkin masuk ke layanan analitik real-time. Dan karena Microsoft Azure Scheduler tidak perlu menunggu respons, menambahkan lebih banyak pelanggan tidak memengaruhi jalur alur kerja utama.
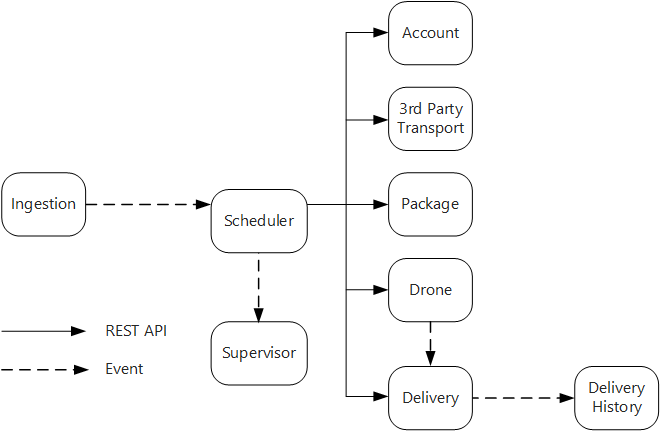
Perhatikan bahwa peristiwa status pengiriman berasal dari peristiwa lokasi drone. Misalnya, ketika drone mencapai lokasi pengiriman dan menurunkan paket, layanan Pengiriman menerjemahkan ini menjadi peristiwa DeliveryCompleted. Ini adalah contoh pemikiran dalam hal model domain. Seperti yang dijelaskan sebelumnya, Manajemen Drone termasuk dalam konteks terbatas yang terpisah. Peristiwa drone menyampaikan lokasi fisik drone. Peristiwa pengiriman, di sisi lain, mewakili perubahan status pengiriman, yang merupakan entitas bisnis yang berbeda.
Menggunakan layanan jala
Layanan jala adalah lapisan perangkat lunak yang menangani komunikasi layanan-ke-layanan. Layanan jala dirancang untuk mengatasi banyak masalah yang tercantum di bagian sebelumnya, dan untuk memindahkan tanggung jawab atas masalah ini dari layanan mikro itu sendiri dan ke lapisan bersama. Layanan jala bertindak sebagai proksi yang mencegat komunikasi jaringan antara layanan mikro dalam kluster. Saat ini, konsep layanan jala berlaku terutama untuk orkestrator kontainer, bukan arsitektur tanpa server.
Catatan
Layanan jala adalah contoh pola Ambassador - layanan pembantu yang mengirimkan permintaan jaringan atas nama aplikasi.
Saat ini, opsi utama untuk jala layanan di Kubernetes adalah Linkerd dan Istio. Kedua teknologi ini berkembang pesat. Namun, beberapa fitur yang memiliki kesamaan linkerd dan Istio meliputi:
Penyeimbangan muatan pada tingkat sesi, berdasarkan latensi yang diamati atau jumlah permintaan yang beredar. Hal ini dapat meningkatkan performa atas penyeimbangan muatan lapisan-4 yang disediakan oleh Kubernetes.
Perutean Layer-7 berdasarkan jalur URL, header host, versi API, atau aturan tingkat aplikasi lainnya.
Coba lagi permintaan yang gagal. Layanan jala memahami kode kesalahan HTTP, dan dapat secara otomatis mencoba kembali permintaan yang gagal. Anda dapat mengonfigurasi jumlah uji ulang maksimum tersebut, bersama dengan periode batas waktu untuk mengikat latensi maksimum.
Pemutusan Sirkuit. Jika instans gagal permintaan secara konsisten, jala layanan untuk sementara akan menandainya sebagai tidak tersedia. Setelah periode backoff, ia akan mencoba instans lagi. Anda dapat mengonfigurasikan pemutus sirkuit berdasarkan berbagai kriteria, seperti jumlah kegagalan berturut-turut,
Layanan jala menangkap metrik tentang panggilan antar layanan, seperti volume permintaan, latensi, tingkat kesalahan dan keberhasilan, dan ukuran respons. Layanan jala juga memungkinkan pelacakan terdistribusi dengan menambahkan informasi korelasi untuk setiap hop dalam permintaan.
Autentikasi TLS Bersama untuk panggilan layanan-ke-layanan.
Apakah Anda memerlukan layanan jala? Tergantung. Tanpa layanan jala, Anda perlu mempertimbangkan setiap tantangan yang disebutkan di awal artikel ini. Anda dapat memecahkan masalah seperti mencoba kembali, pemutus sirkuit, dan pelacakan terdistribusi tanpa jala layanan, tetapi jala layanan memindahkan masalah ini keluar dari layanan individual dan ke lapisan khusus. Di sisi lain, layanan jala menambah kompleksitas pengaturan dan konfigurasi kluster. Mungkin ada implikasi kinerja, karena permintaan sekarang dialihkan melalui proksi jala layanan, dan karena layanan tambahan sekarang berjalan pada setiap node di kluster. Anda harus melakukan pengujian performa dan beban menyeluruh sebelum menerapkan jala layanan dalam produksi.
Transaksi terdistribusi
Tantangan umum dalam layanan mikro adalah menangani transaksi dengan benar yang menjangkau beberapa layanan. Seringkali dalam skenario ini, keberhasilan transaksi adalah semua atau tidak sama sekali - jika salah satu layanan yang berpartisipasi gagal, seluruh transaksi harus gagal.
Ada dua kasus yang perlu dipertimbangkan:
Layanan mungkin mengalami kegagalan sementara seperti batas waktu jaringan. Kesalahan-kesalahan ini sering dapat diselesaikan hanya dengan mencoba kembali panggilan. Jika operasi masih gagal setelah sejumlah upaya, itu dianggap sebagai kegagalan nontransient.
Kegagalan nontransient adalah kegagalan yang tidak mungkin hilang dengan sendirinya. Kegagalan nontransient termasuk kondisi kesalahan normal, seperti input yang tidak valid. Mereka juga menyertakan pengecualian yang tidak ditangani dalam kode aplikasi atau proses crash. Jika jenis kesalahan ini terjadi, seluruh transaksi bisnis harus ditandai sebagai kegagalan. Mungkin perlu untuk membatalkan langkah-langkah lain dalam transaksi yang sama yang sudah berhasil.
Setelah kegagalan nontransient, transaksi saat ini mungkin dalam keadaan gagal sebagian, di mana satu atau beberapa langkah sudah berhasil diselesaikan. Misalnya, jika layanan Drone sudah menjadwalkan drone, drone harus dibatalkan. Dalam hal ini, aplikasi perlu membatalkan langkah-langkah yang berhasil, dengan menggunakan Transaksi Kompensasi. Dalam beberapa kasus, tindakan ini harus dilakukan oleh sistem eksternal atau bahkan oleh proses manual. Dalam desain Anda, ingatlah bahwa tindakan kompensasi juga dapat mengalami kegagalan.
Jika logika untuk kompensasi transaksi itu rumit, pertimbangkan untuk membuat layanan terpisah yang bertanggung jawab atas proses ini. Dalam aplikasi Pengiriman Drone, layanan Scheduler menempatkan operasi yang gagal ke antrean khusus. Layanan mikro terpisah, yang disebut Supervisor, membaca dari antrean ini dan memanggil API pembatalan pada layanan yang perlu dikompensasi. Ini adalah variasi dari pola Scheduler Agent Supervisor. Layanan Supervisor mungkin mengambil tindakan lain juga, seperti memberi tahu pengguna melalui teks atau email, atau mengirim peringatan ke dasbor operasi.
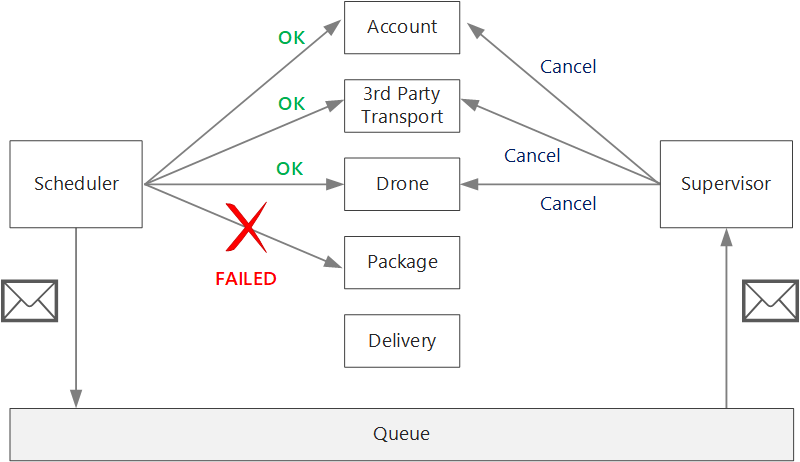
Layanan Microsoft Azure Scheduler itu sendiri mungkin gagal (misalnya, karena node crash). Dalam hal ini, instans baru dapat berputar dan mengambil alih. Namun, setiap transaksi yang sudah berlangsung harus dilanjutkan.
Salah satu pendekatannya adalah menyimpan pos pemeriksaan ke toko yang tahan lama setelah setiap langkah dalam alur kerja selesai. Jika instans layanan Microsoft Azure Scheduler crash di tengah transaksi, instans baru dapat menggunakan pos pemeriksaan untuk melanjutkan di mana instans sebelumnya tidak aktif. Namun, menulis pos pemeriksaan dapat membuat performa di overhead.
Pilihan lain adalah merancang semua operasi menjadi idempotent. Operasi dikatakan idempotent jika operasi tersebut dapat panggil beberapa kali tanpa menghasilkan efek samping tambahan setelah panggilan pertama. Pada dasarnya, layanan hilir harus mengabaikan panggilan duplikat, yang berarti layanan harus dapat mendeteksi panggilan duplikat. Tidak selalu mudah untuk menerapkan metode idempotent. Untuk informasi selengkapnya, lihat Operasi Idempotent.
Langkah berikutnya
Untuk layanan mikro yang berbicara langsung satu sama lain, penting untuk membuat API yang dirancang dengan baik.