Artikel ini menjelaskan bagaimana tim pengembangan menggunakan metrik untuk menemukan penyempitan dan meningkatkan performa sistem terdistribusi. Artikel ini didasarkan pada pengujian beban aktual yang kami lakukan untuk aplikasi sampel. Aplikasi ini berasal dari Dasar Azure Kubernetes Service (AKS) untuk layanan mikro.
Artikel ini adalah bagian dari rangkaian. Baca bagian pertama di sini.
Skenario: Aplikasi klien memulai transaksi bisnis yang melibatkan beberapa langkah.
Skenario ini melibatkan aplikasi pengiriman drone yang berjalan pada AKS. Pelanggan menggunakan aplikasi web untuk menjadwalkan pengiriman dengan drone. Setiap transaksi memerlukan beberapa langkah yang dilakukan oleh layanan mikro terpisah di back end:
- Layanan Pengiriman mengelola pengiriman.
- Layanan Penjadwal Drome menjadwalkan pengambilan drone.
- Layanan Paket mengelola paket.
Ada dua layanan lain: Layanan Penyerapan yang menerima permintaan klien dan menempatkannya pada antrean untuk diproses, dan layanan Alur Kerja yang mengoordinasikan langkah-langkah dalam alur kerja.
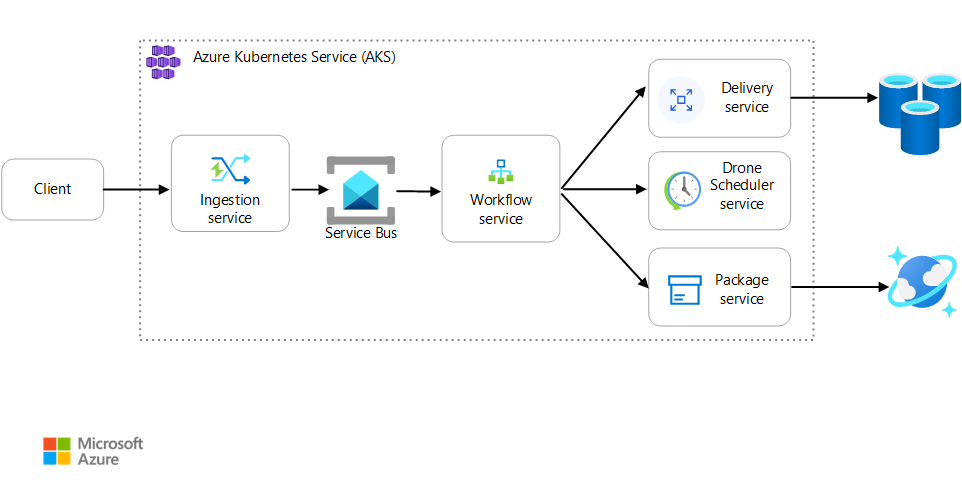
Untuk informasi selengkapnya tentang skenario ini, lihat Merancang arsitektur layanan mikro.
Tes 1: Garis Besar
Untuk pengujian beban pertama, tim membuat kluster AKS enam node dan menyebarkan tiga replika dari setiap layanan mikro. Pengujian beban adalah pengujian beban langkah, dimulai dari dua pengguna simulasi dan ditingkatkan hingga 40 pengguna simulasi.
| Pengaturan | Nilai |
|---|---|
| Simpul kluster | 6 |
| Pod | 3 per layanan |
Grafik berikut menunjukkan hasil pengujian beban, seperti yang ditunjukkan pada Visual Studio. Garis ungu mengatur beban pengguna, dan garis oranye mengatur total permintaan.
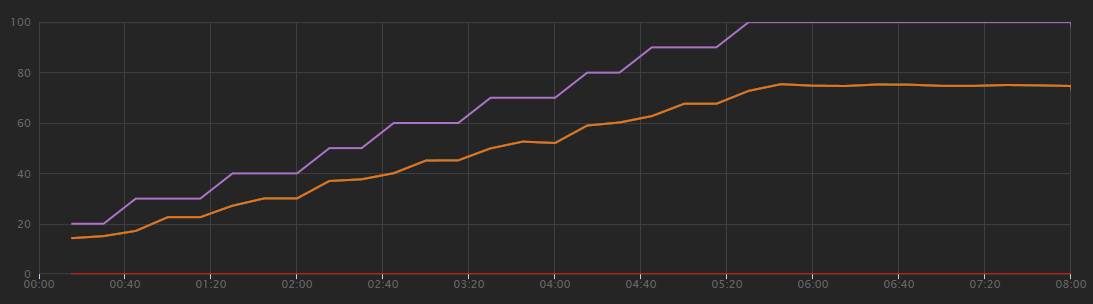
Hal pertama yang harus disadari tentang skenario ini adalah bahwa permintaan klien per detik bukanlah metrik performa yang berguna. Hal itu karena proses aplikasi meminta secara asinkron, sehingga klien langsung mendapat respons. Kode respons selalu HTTP 202 (Accepted), yang berarti permintaan diterima, tetapi pemrosesan tidak selesai.
Apa yang benar-benar ingin kita ketahui adalah apakah backend mengikuti tingkat permintaan. Antrean Bus Layanan dapat menyerap lonjakan, tetapi jika backend tidak dapat menangani beban yang berkelanjutan, pemrosesan akan makin tertinggal.
Berikut adalah grafik yang lebih informatif. Ini mengatur jumlah pesan masuk dan keluar pada antrean Bus Layanan. Pesan masuk ditampilkan dalam warna biru muda, dan pesan keluar ditampilkan dalam warna biru tua:
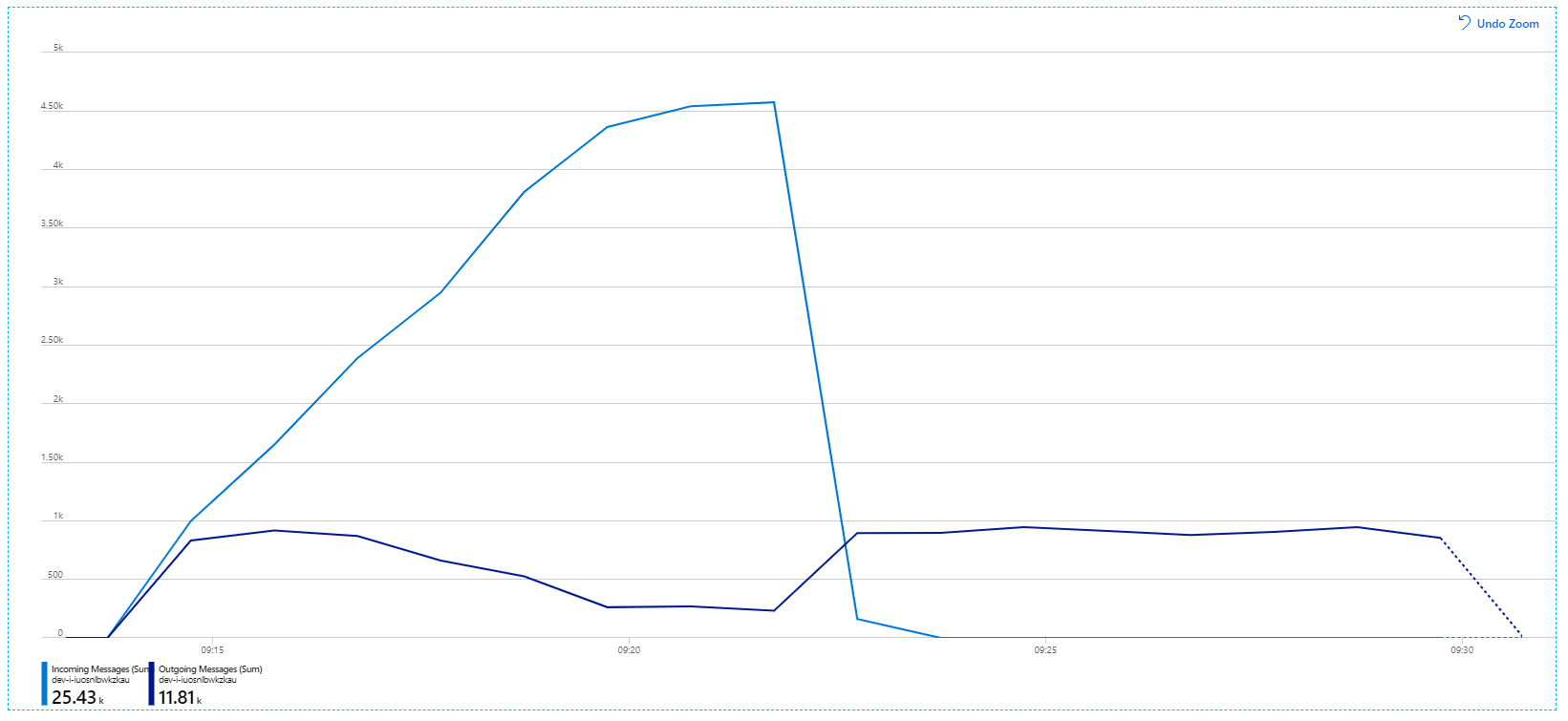
Bagan ini menunjukkan bahwa tingkat pesan masuk meningkat, mencapai puncak, lalu turun kembali ke nol pada akhir pengujian beban. Namun, jumlah pesan keluar mencapai puncak di awal pengujian, lalu benar-benar turun. Artinya layanan Alur Kerja, yang menangani permintaan, tidak mengikuti. Bahkan setelah pengujian beban berakhir (sekitar pukul 9.22 pada grafik), pesan masih diproses karena layanan Alur Kerja terus mengeluarkan antrean.
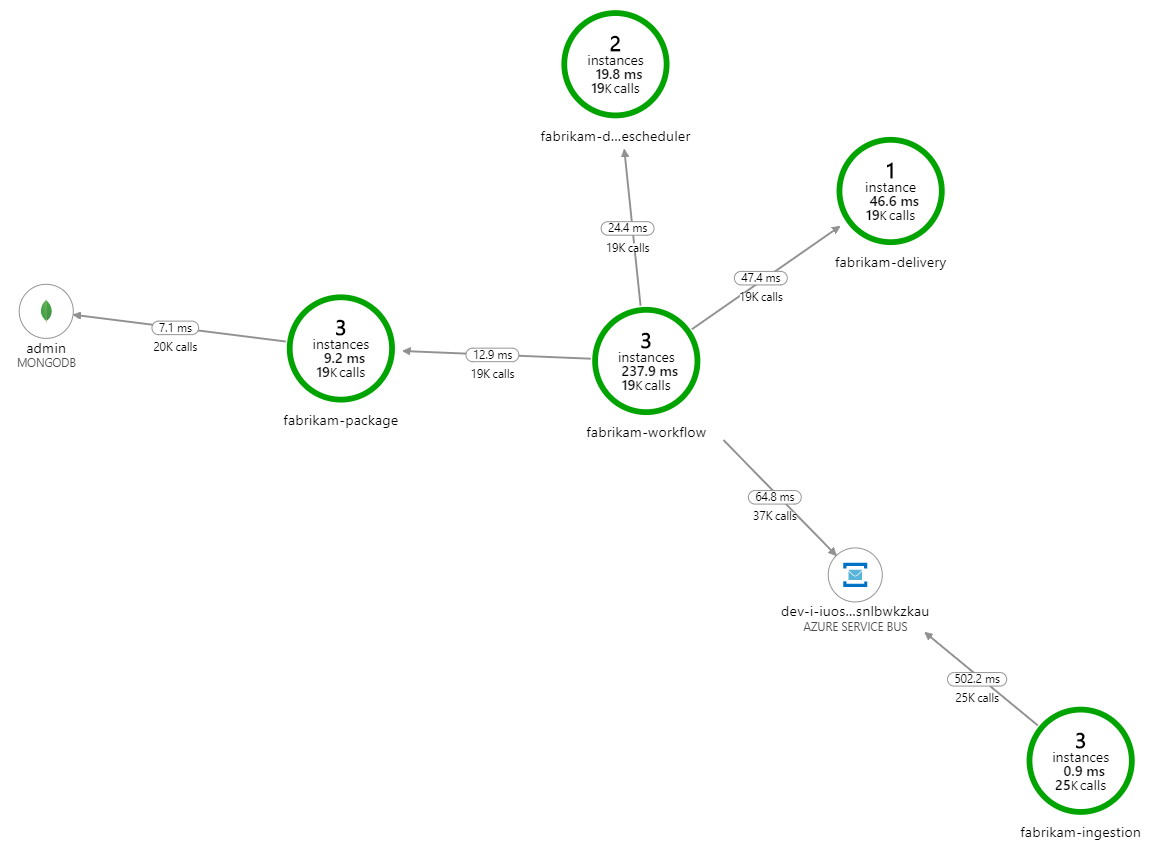
Apa yang memperlambat pemrosesan? Hal pertama yang harus dicari adalah kesalahan atau pengecualian yang mungkin menunjukkan masalah sistematis. Peta Aplikasi di Azure Monitor menunjukkan grafik panggilan di antara komponen, dan merupakan cara cepat untuk menemukan masalah, lalu mengeklik untuk mendapatkan detail selengkapnya.
Benar saja, Peta Aplikasi menunjukkan bahwa layanan Alur Kerja mendapatkan kesalahan dari layanan Pengiriman:
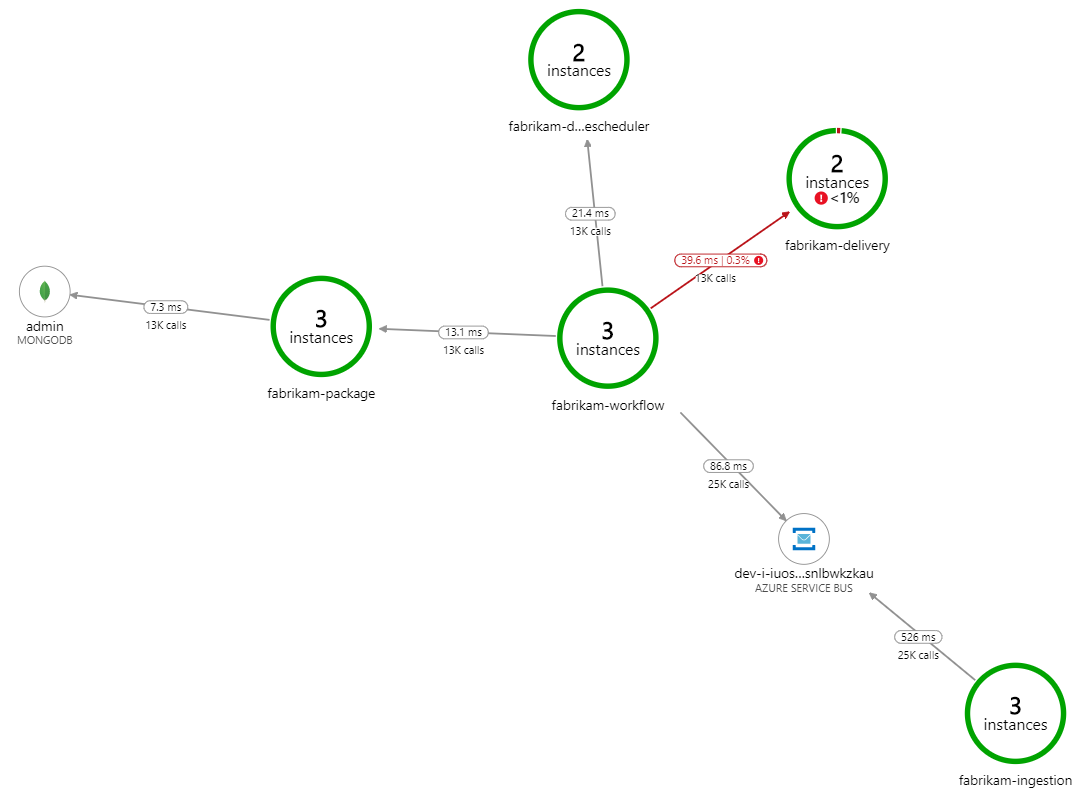
Untuk melihat detail selengkapnya, Anda dapat memilih node dalam grafik dan mengeklik tampilan transaksi end-to-end. Dalam hal ini, ini menunjukkan bahwa layanan Pengiriman mengembalikan kesalahan HTTP 500. Pesan kesalahan menunjukkan bahwa pengecualian dibuat karena batasan memori di Azure Cache for Redis.
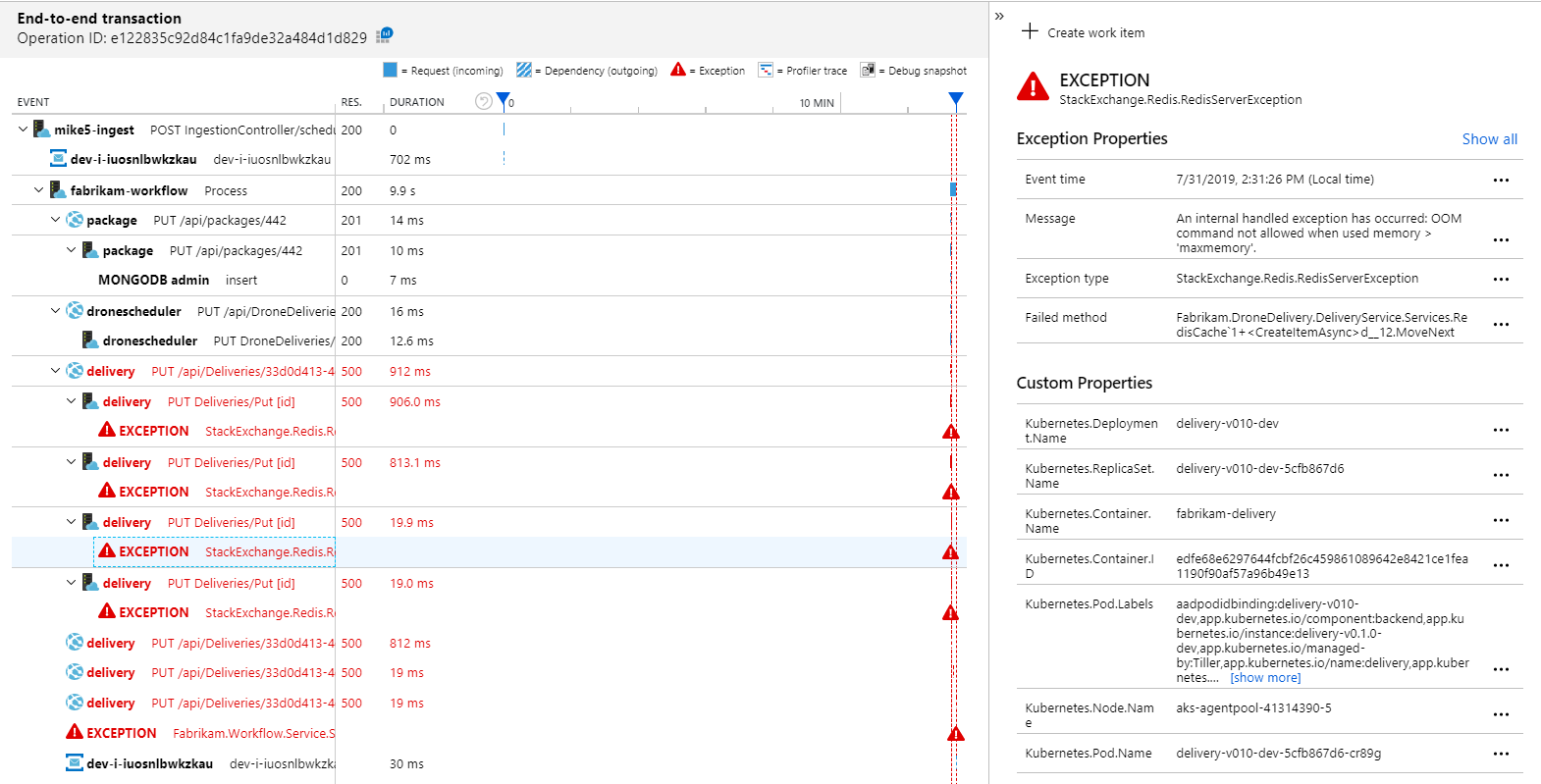
Anda mungkin memperhatikan bahwa panggilan ke Redis ini tidak muncul di Peta Aplikasi. Itu karena pustaka .NET untuk Application Insights tidak memiliki dukungan bawaan untuk melacak Redis sebagai dependensi. (Untuk daftar apa yang didukung di luar kotak, lihat Pengumpulan otomatis dependensi.) Sebagai fallback, Anda dapat menggunakan TRACKDependency API untuk melacak dependensi apa pun. Pengujian beban sering mengungkapkan celah semacam ini dalam telemetri, yang dapat diperbaiki.
Uji 2: Peningkatan ukuran cache
Untuk pengujian beban kedua, tim pengembangan meningkatkan ukuran cache di Azure Cache for Redis. (Lihat Cara Menskalakan Azure Cache for Redis.) Perubahan ini menyelesaikan pengecualian di luar memori, dan sekarang Peta Aplikasi menunjukkan kesalahan nol:
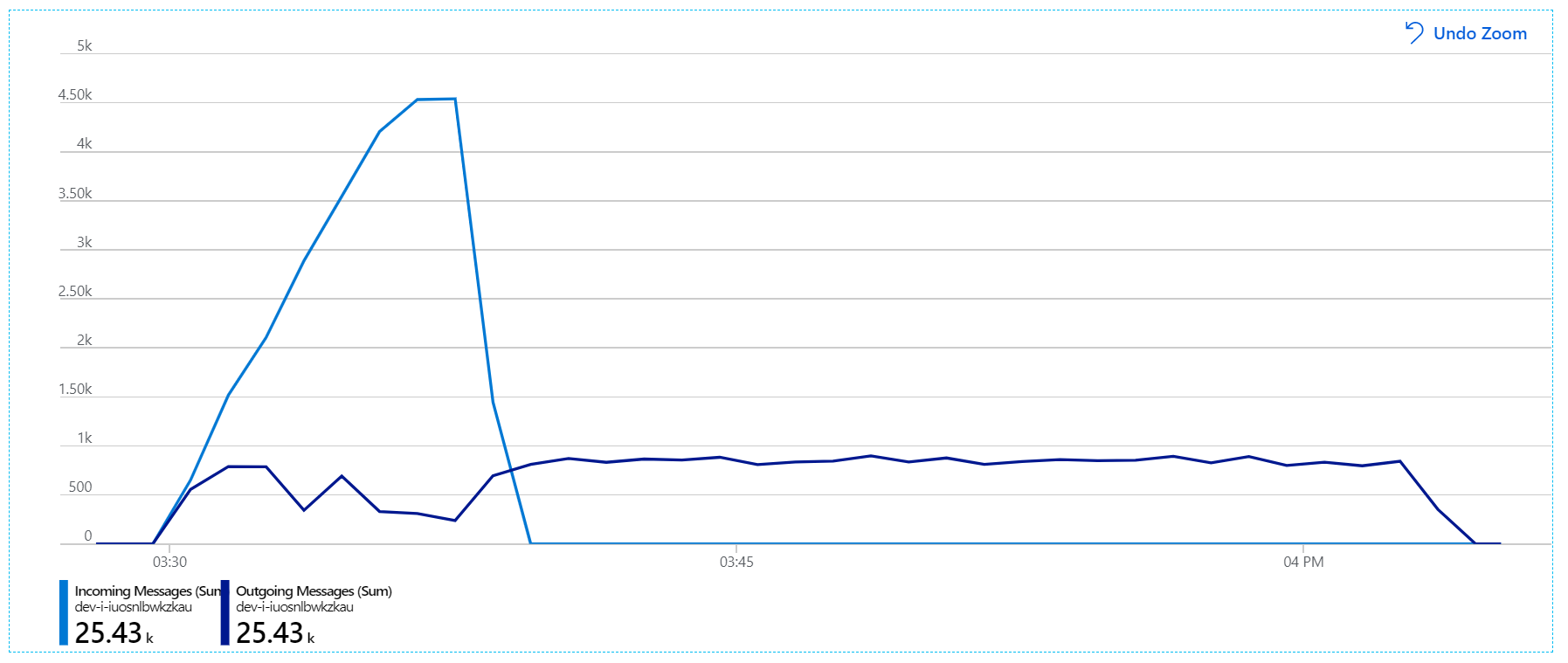
Namun, masih ada banyak kelambatan dalam memproses pesan. Pada puncak pengujian beban, tingkat pesan masuk lebih dari 5× tingkat keluar:
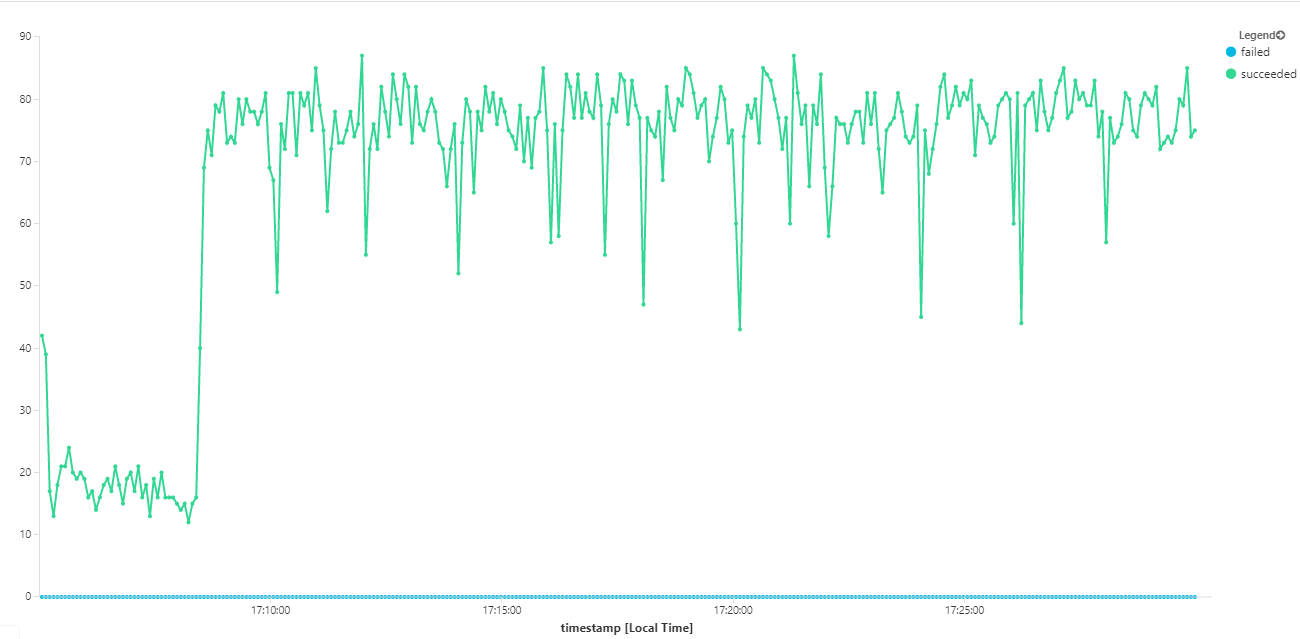
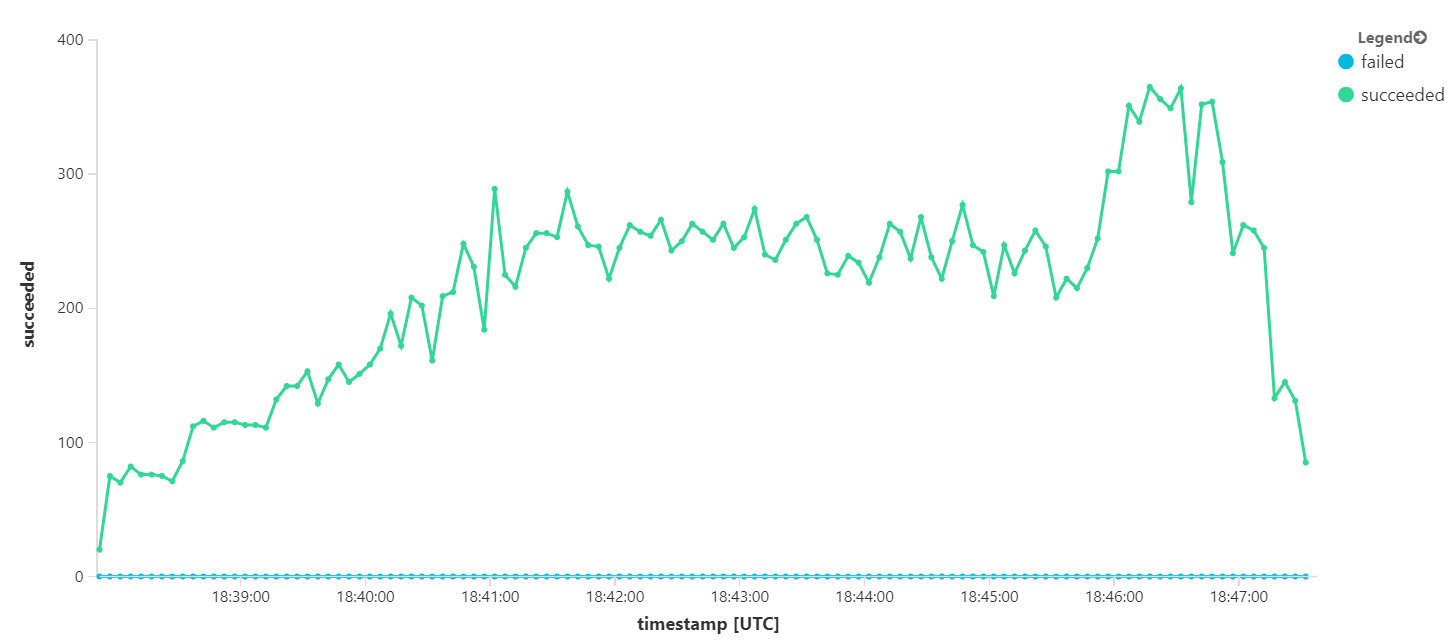
Grafik berikut mengukur throughput dalam hal penyelesaian pesan — yaitu, tingkat ketika layanan Alur Kerja menandai pesan Bus Layanan sebagai selesai. Setiap titik pada grafik mewakili 5 detik data, menunjukkan throughput maksimum ~ 16/detik.
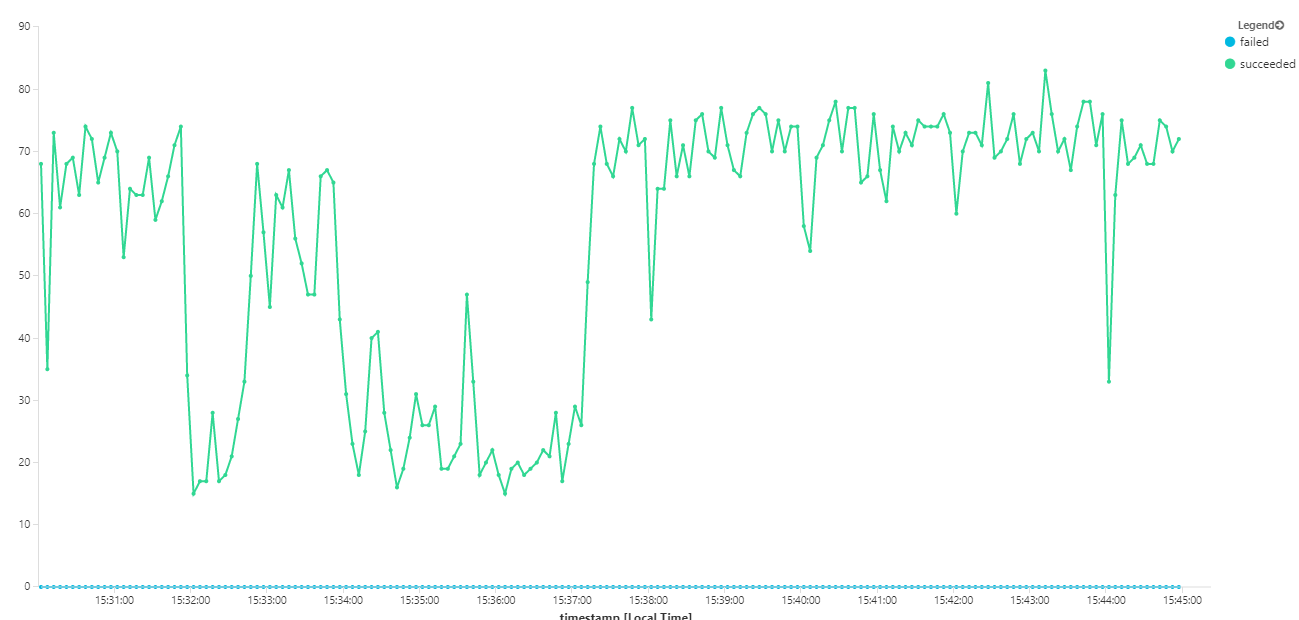
Grafik ini dihasilkan dengan menjalankan kueri di ruang kerja Analitik Log, menggunakan bahasa kueri Kusto:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
Uji 3: Meluaskan skala layanan backend
Tampaknya back end mengalami penyempitan. Langkah selanjutnya yang mudah adalah meluaskan skala layanan bisnis (Paket, Pengiriman, dan Penjadwal Drone), dan melihat apakah throughput meningkat. Untuk pengujian beban berikutnya, tim meningkatkan skala layanan ini dari tiga replika menjadi enam replika.
| Pengaturan | Nilai |
|---|---|
| Simpul kluster | 6 |
| Layanan penyerapan | 3 replika |
| Layanan alur kerja | 3 replika |
| Layanan Paket, Pengiriman, Penjadwal Drone | Masing-masing 6 replika |
Sayangnya pengujian beban ini hanya menunjukkan peningkatan sederhana. Pesan keluar masih tidak sama dengan pesan masuk:
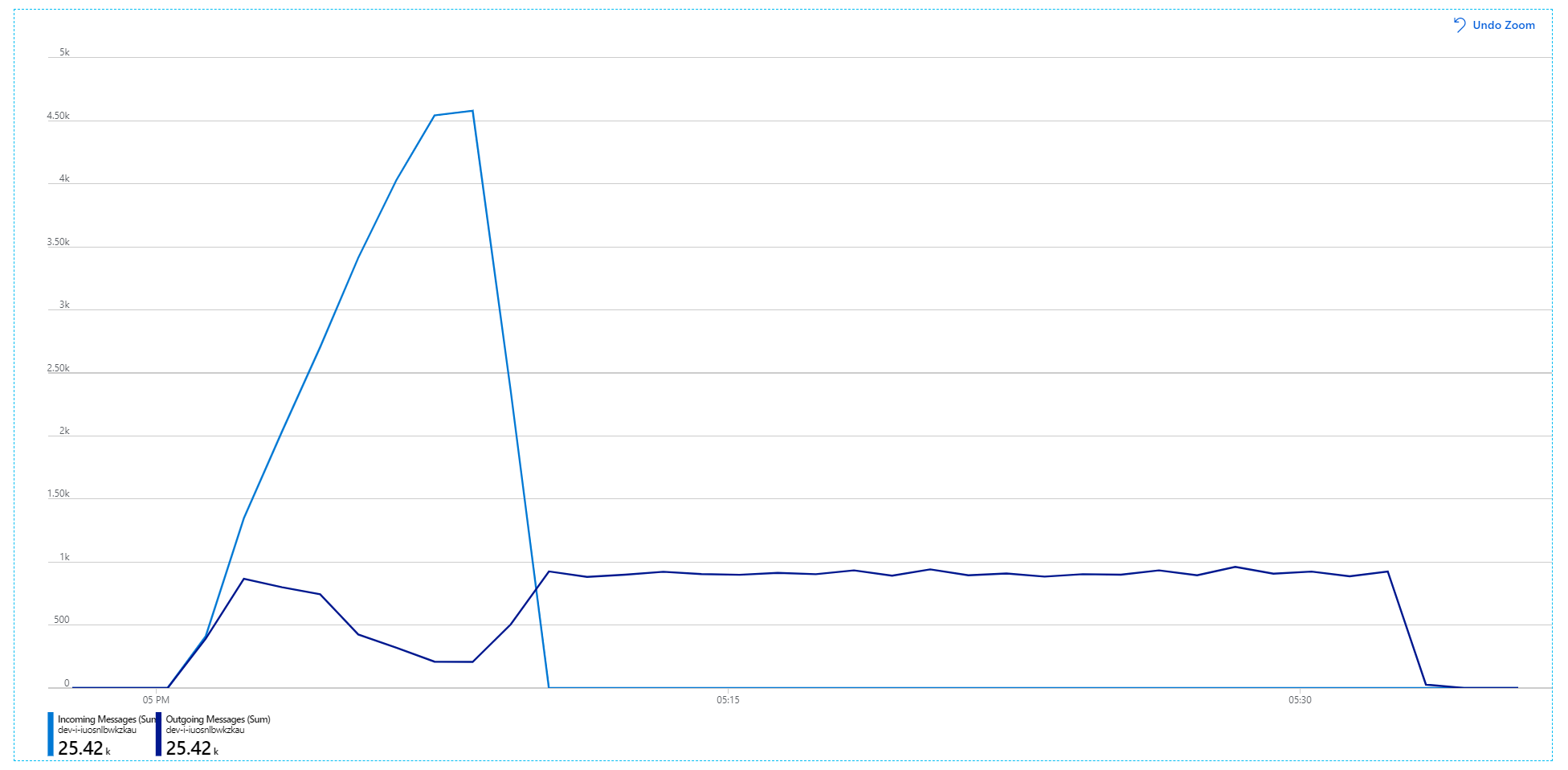
Throughput lebih konsisten, tetapi maksimum yang dicapai hampir sama dengan pengujian sebelumnya:
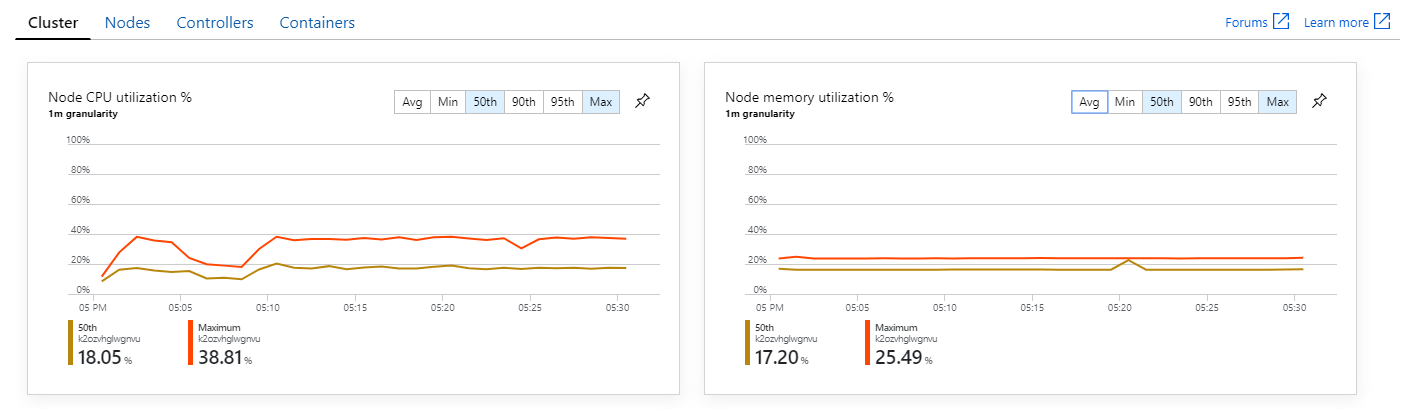
Selain itu, melihat wawasan kontainer Azure Monitor, tampaknya masalahnya tidak disebabkan oleh kelelahan sumber daya dalam kluster. Pertama, metrik tingkat node menunjukkan bahwa pemanfaatan CPU tetap di bawah 40% bahkan pada persentil ke-95, dan pemanfaatan memori sekitar 20%.
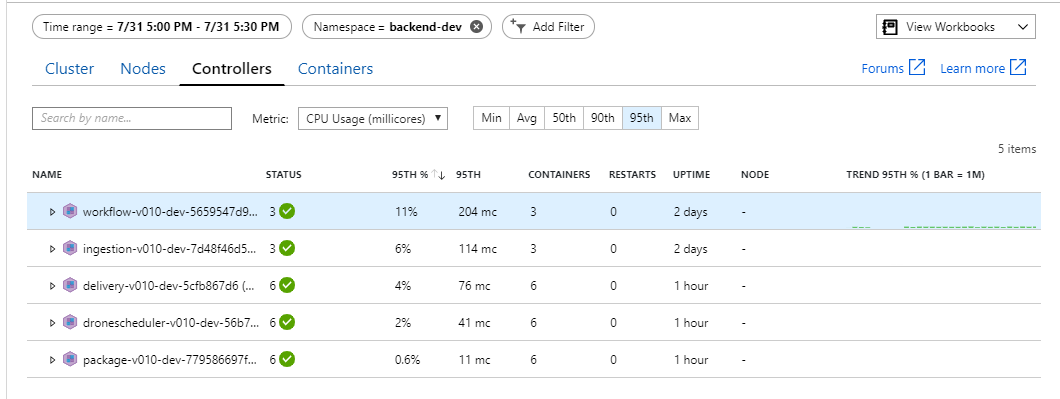
Di lingkungan Kubernetes, setiap pod dapat dibatasi sumber dayanya meskipun node tidak. Namun, tampilan tingkat pod menunjukkan bahwa semua pod sehat.
Dari pengujian ini, tampaknya hanya menambahkan lebih banyak pod ke back end tidak akan membantu. Langkah selanjutnya adalah melihat lebih dekat pada layanan Alur Kerja untuk memahami apa yang terjadi ketika pesan diproses. Application Insights menunjukkan bahwa durasi rata-rata operasi Process layanan Alur Kerja adalah 246 ms.
Kita juga dapat menjalankan kueri untuk mendapatkan metrik pada masing-masing operasi dalam setiap transaksi:
| target | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| delivery | 37 | 57 |
| paket | 12 | 17 |
| dronescheduler | 21 | 41 |
Baris pertama dalam tabel ini mewakili antrean Bus Layanan. Baris lainnya adalah panggilan ke layanan backend. Untuk referensi, berikut adalah kueri Analitik Log untuk tabel ini:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
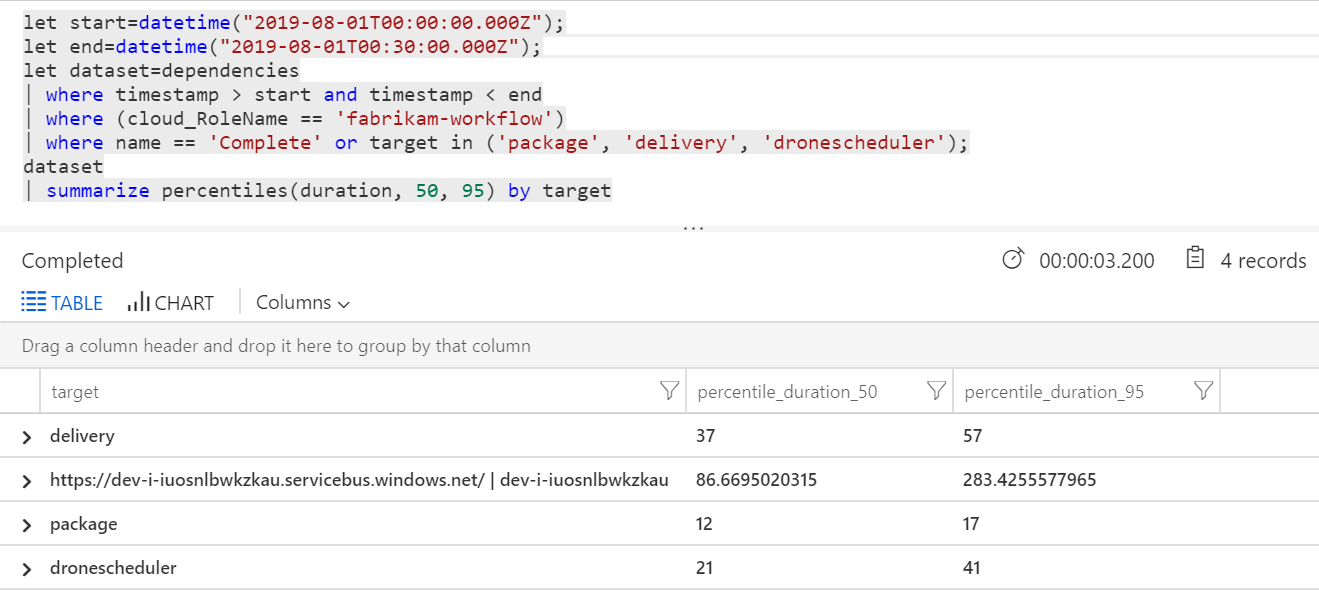
Latensi ini terlihat masuk akal. Namun, inilah wawasan utamanya: Jika total waktu operasi ~250 ms, itu menempatkan batas atas yang ketat pada seberapa cepat pesan dapat diproses secara seri. Oleh karena itu, kunci untuk meningkatkan throughput adalah paralelisme yang lebih besar.
Itu harus dimungkinkan dalam skenario ini, karena dua alasan:
- Ini adalah panggilan jaringan, sehingga sebagian besar waktu dihabiskan untuk menunggu penyelesaian I/O
- Pesan bersifat independen, dan tidak perlu diproses secara berurutan.
Tes 4: Meningkatkan paralelisme
Untuk pengujian ini, tim berfokus pada peningkatan paralelisme. Untuk melakukannya, mereka menyesuaikan dua pengaturan pada klien Bus Layanan yang digunakan oleh layanan Alur Kerja:
| Pengaturan | Deskripsi | Default | Nilai baru |
|---|---|---|---|
MaxConcurrentCalls |
Jumlah maksimum pesan yang akan diproses secara bersamaan. | 1 | 20 |
PrefetchCount |
Berapa banyak pesan yang akan diambil klien sebelumnya ke cache lokalnya. | 0 | 3000 |
Untuk informasi selengkapnya tentang pengaturan ini, lihat Praktik Terbaik untuk peningkatan performa menggunakan Olahpesan Bus Layanan. Menjalankan pengujian dengan pengaturan ini menghasilkan grafik berikut:
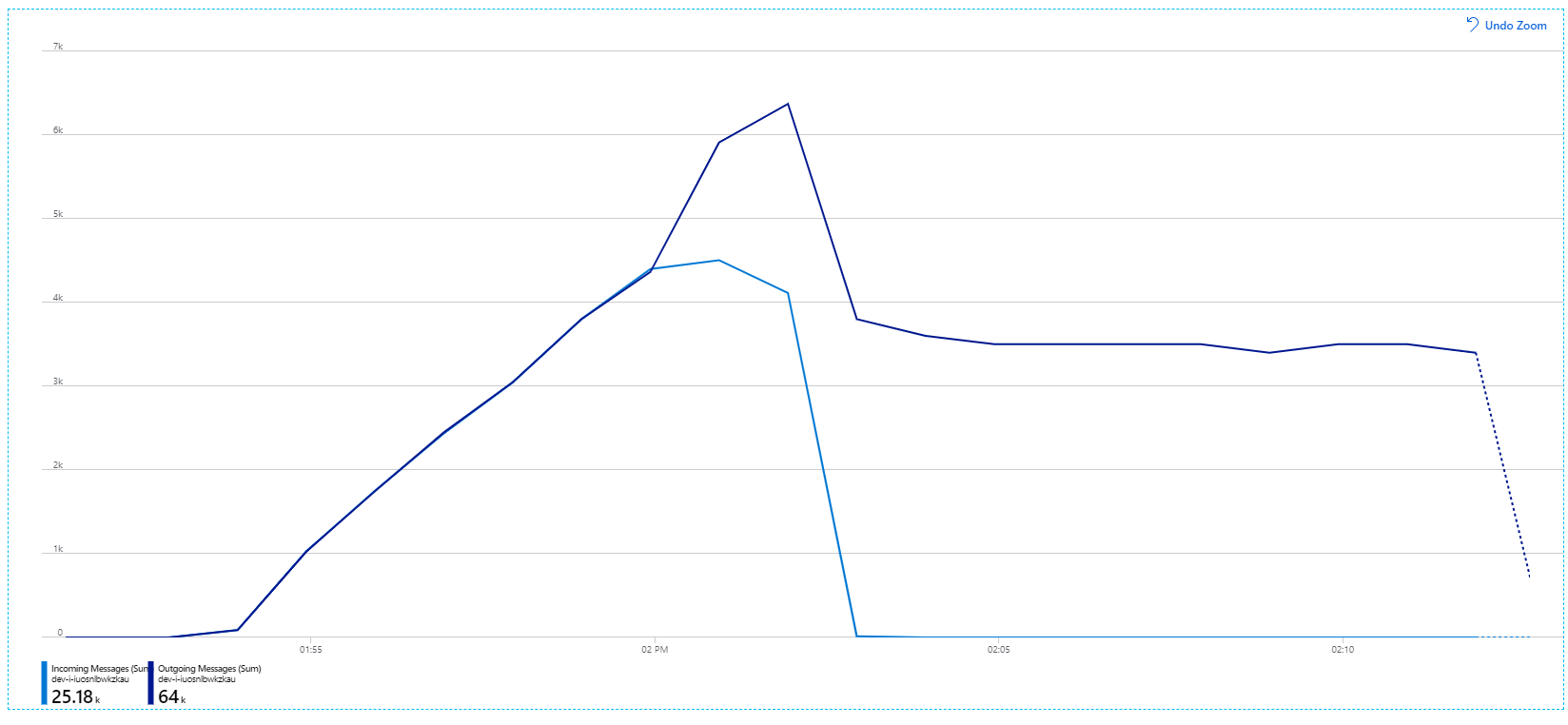
Ingat bahwa pesan masuk ditampilkan dalam warna biru muda, dan pesan keluar ditampilkan dalam warna biru tua.
Sekilas grafik ini terlihat sangat aneh. Untuk sementara, tingkat pesan keluar melacak tingkat masuk dengan tepat. Namun, selanjutnya sekitar tanda 2.03, tingkat pesan masuk turun, sementara jumlah pesan keluar terus meningkat, sebenarnya melebihi jumlah total pesan masuk. Itu tampaknya mustahil.
Petunjuk untuk misteri ini dapat ditemukan dalam tampilan Dependensi di Application Insights. Bagan ini merangkum semua panggilan yang dilakukan layanan Alur Kerja untuk Bus Layanan:
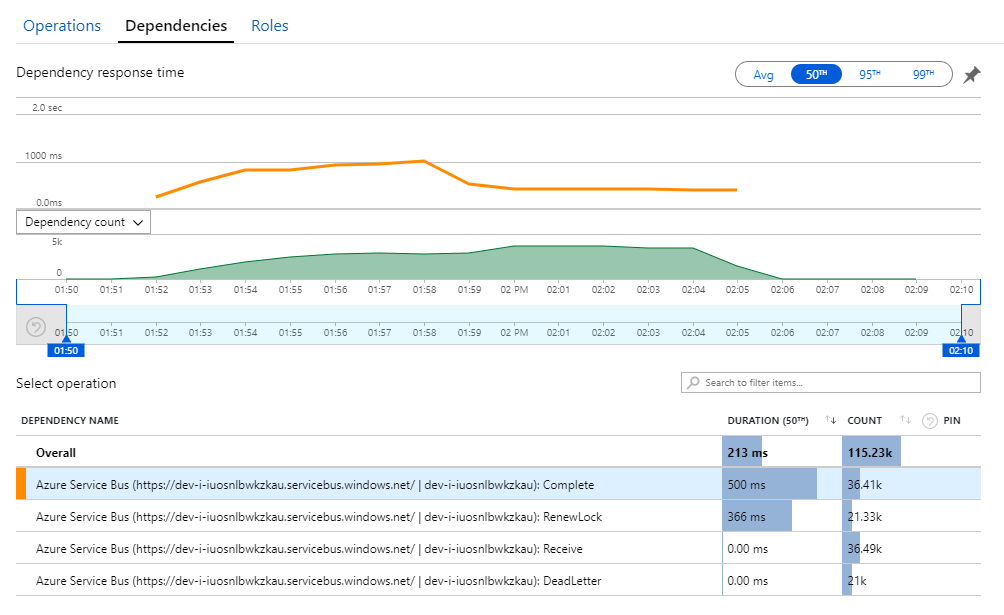
Perhatikan entri tersebut untuk DeadLetter. Panggilan tersebut menunjukkan pesan masuk ke anteran surat gagal Bus Layanan.
Untuk memahami apa yang terjadi, Anda perlu memahami semantik Peek-Lock dalam Bus Layanan. Ketika klien menggunakan Peek-Lock, Bus Layanan secara atomik mengambil dan mengunci pesan. Meskipun kunci disimpan, pesan dijamin tidak akan dikirim ke penerima lain. Jika kunci kedaluwarsa, pesan akan tersedia untuk penerima lain. Setelah jumlah maksimum upaya pengiriman (yang dapat dikonfigurasi), Bus Layanan akan menempatkan pesan ke antrean surat gagal , tempat pesan dapat diperiksa nanti.
Ingat bahwa layanan Alur Kerja sedang menyiapkan sejumlah besar pesan — 3000 pesan sekaligus). Itu berarti total waktu untuk memproses setiap pesan lebih lama, yang menyebabkan waktu habis pesan, kembali ke antrean, dan akhirnya masuk ke antrean surat gagal.
Anda juga dapat melihat perilaku ini dalam pengecualian, yang merekam banyak pengecualian MessageLostLockException:
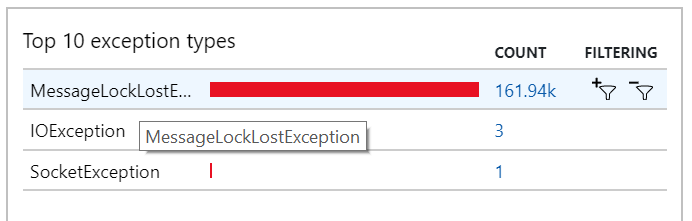
Uji 5: Meningkatkan durasi penguncian
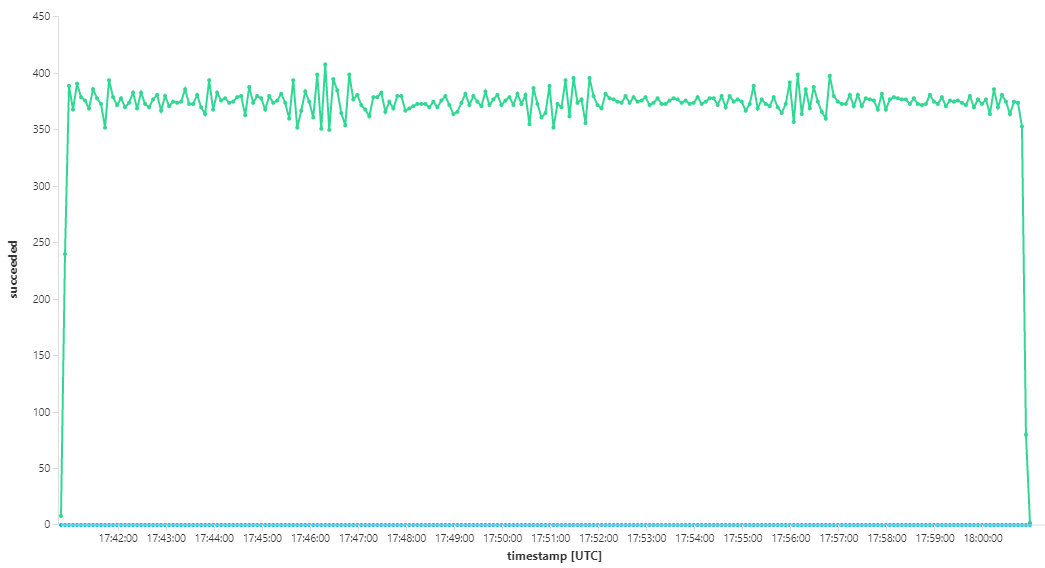
Untuk penguncian beban ini, durasi penguncian pesan diatur ke 5 menit, untuk mencegah batas waktu penguncian. Grafik pesan masuk dan keluar sekarang menunjukkan bahwa sistem mengikuti tingkat pesan masuk:
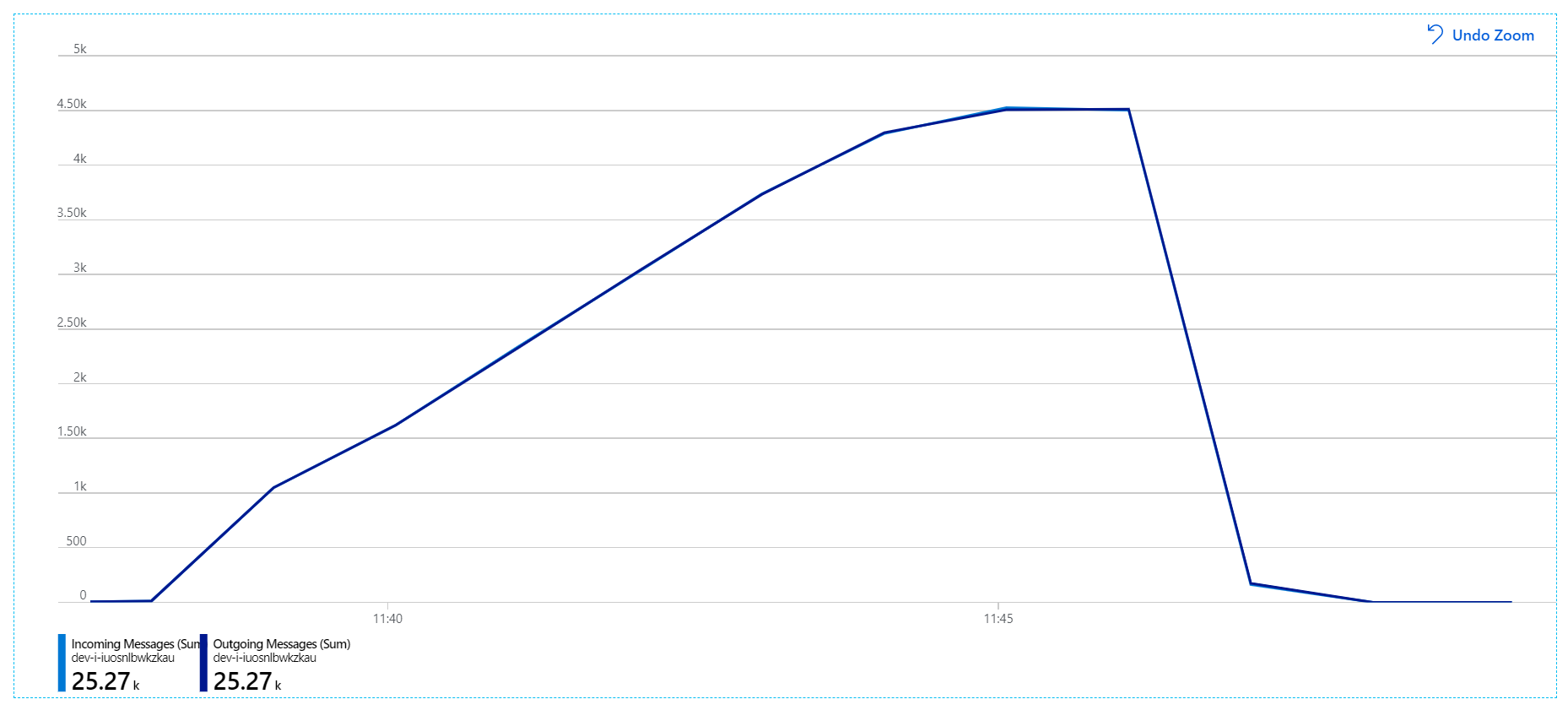
Selama total durasi pengujian beban 8 menit, aplikasi menyelesaikan operasi 25 K, dengan throughput puncak 72 operasi/detik, mewakili peningkatan throughput maksimum sebesar 400%.
Namun, menjalankan pengujian yang sama dengan durasi yang lebih lama menunjukkan bahwa aplikasi tidak dapat mempertahankan tingkat ini:
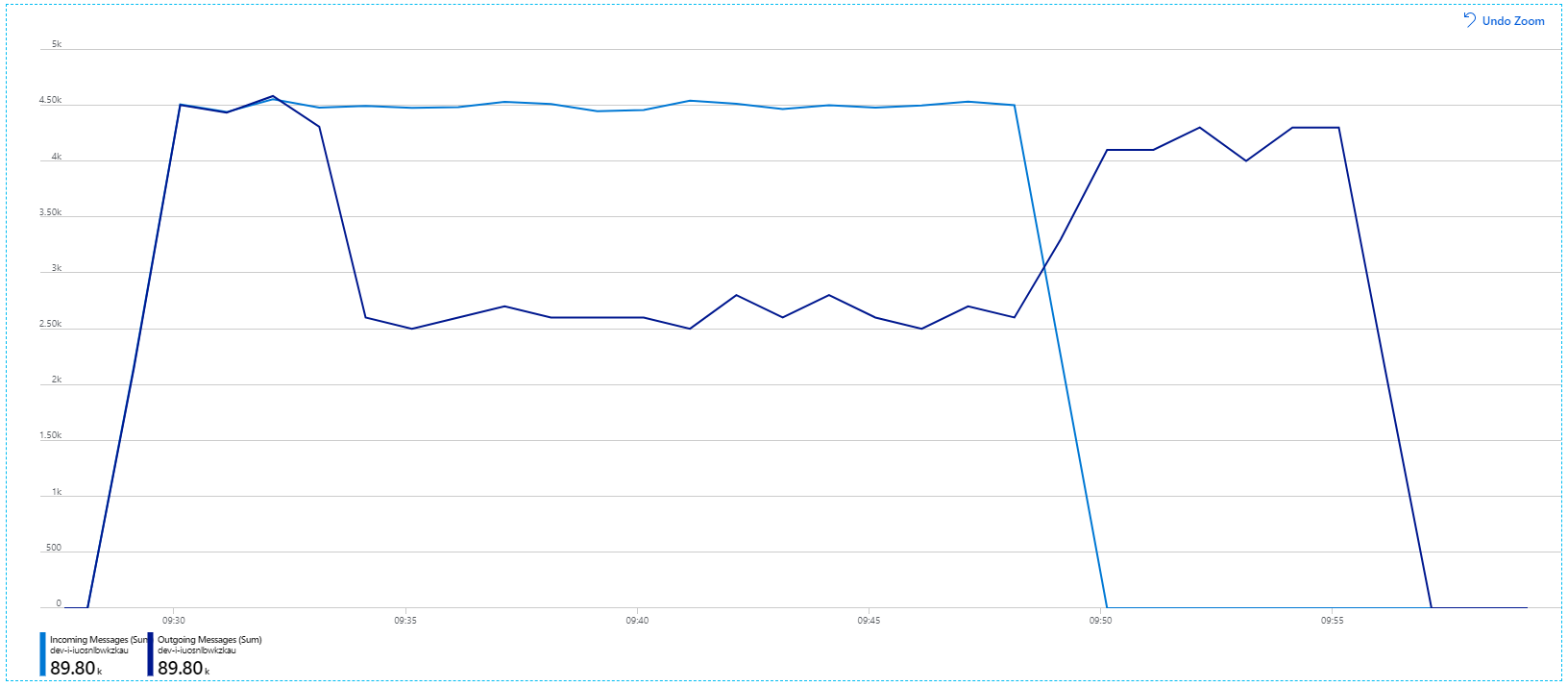
Metrik kontainer menunjukkan bahwa pemanfaatan CPU maksimum mendekati 100%. Pada titik ini, aplikasi tampaknya terikat CPU. Penskalaan kluster sekarang dapat meningkatkan performa, tidak seperti upaya sebelumnya untuk meningkatan skala.
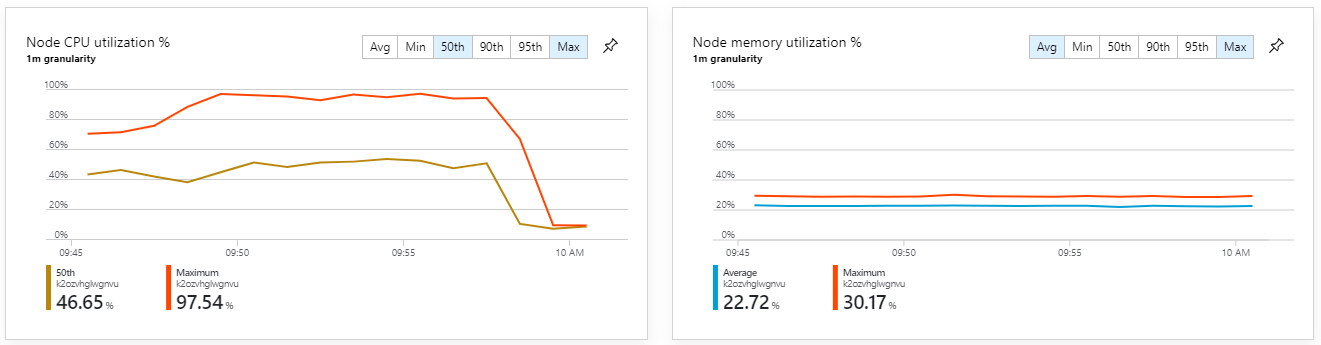
Uji 6: Meluaskan skala layanan backend (lagi)
Untuk pengujian beban akhir dalam seri, tim meningkatkan skala kluster dan pod Kubernetes sebagai berikut:
| Pengaturan | Nilai |
|---|---|
| Simpul kluster | 12 |
| Layanan penyerapan | 3 replika |
| Layanan alur kerja | 6 replika |
| Layanan Paket, Pengiriman, Penjadwal Drone | Masing-masing 9 replika |
Pengujian ini menghasilkan throughput berkelanjutan yang lebih tinggi, tanpa kelambatan yang signifikan dalam memproses pesan. Selain itu, pemanfaatan CPU node tetap di bawah 80%.
Ringkasan
Untuk skenario ini, penyempitan berikut diidentifikasi:
- Pengecualian di luar memori di Azure Cache for Redis.
- Kurangnya paralelisme dalam pemrosesan pesan.
- Durasi penguncian pesan yang tidak mencukupi, yang menyebabkan batas waktu penguncian dan pesan ditempatkan dalam antrean surat gagal.
- Kelelahan CPU.
Untuk mendiagnosis masalah ini, tim pengembangan mengandalkan metrik berikut:
- Tingkat pesan Bus Layanan masuk dan keluar.
- Peta Aplikasi di Application Insights.
- Kesalahan dan pengecualian.
- Kueri Log Analytics kustom.
- Pemanfaatan CPU dan memori dalam wawasan kontainer Azure Monitor.
Langkah berikutnya
Untuk informasi selengkapnya tentang rancangan skenario ini, lihat Merancang arsitektur layanan mikro.