Tutorial: Mendeteksi dan menganalisis anomali menggunakan kemampuan pembelajaran mesin KQL di Azure Monitor
Bahasa Kueri Kusto (KQL) mencakup operator pembelajaran mesin, fungsi, dan plugin untuk analisis rangkaian waktu, deteksi anomali, prakiraan, dan analisis akar penyebab. Gunakan kemampuan KQL ini untuk melakukan analisis data tingkat lanjut di Azure Monitor tanpa overhead mengekspor data ke alat pembelajaran mesin eksternal.
Dalam tutorial ini, Anda akan mempelajari cara:
- Membuat rangkaian waktu
- Mengidentifikasi anomali dalam rangkaian waktu
- Mengubah pengaturan deteksi anomali untuk menyempurnakan hasil
- Menganalisis akar penyebab anomali
Catatan
Tutorial ini menyediakan tautan ke lingkungan demo Analitik Log tempat Anda dapat menjalankan contoh kueri KQL. Data di lingkungan demo bersifat dinamis, sehingga hasil kueri tidak sama dengan hasil kueri yang diperlihatkan dalam artikel ini. Namun, Anda dapat menerapkan kueri dan prinsipal KQL yang sama di lingkungan Anda sendiri dan semua alat Azure Monitor yang menggunakan KQL.
Prasyarat
- Akun Azure dengan langganan aktif. Buat akun secara gratis.
- Ruang kerja dengan data log.
Izin yang diperlukan
Anda harus memiliki Microsoft.OperationalInsights/workspaces/query/*/read izin ke ruang kerja Analitik Log yang Anda kueri, seperti yang disediakan oleh peran bawaan Pembaca Analitik Log, misalnya.
Membuat rangkaian waktu
Gunakan operator KQL make-series untuk membuat rangkaian waktu.
Mari kita buat rangkaian waktu berdasarkan log dalam tabel Penggunaan, yang menyimpan informasi tentang berapa banyak data setiap tabel di ruang kerja yang diserap setiap jam, termasuk data yang dapat ditagih dan tidak dapat ditagih.
Kueri ini menggunakan make-series untuk membuat bagan jumlah total data yang dapat ditagih yang diserap oleh setiap tabel di ruang kerja setiap hari, selama 21 hari terakhir:
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
Dalam bagan yang dihasilkan, Anda dapat dengan jelas melihat beberapa anomali - misalnya, dalam AzureDiagnostics jenis data dan SecurityEvent :
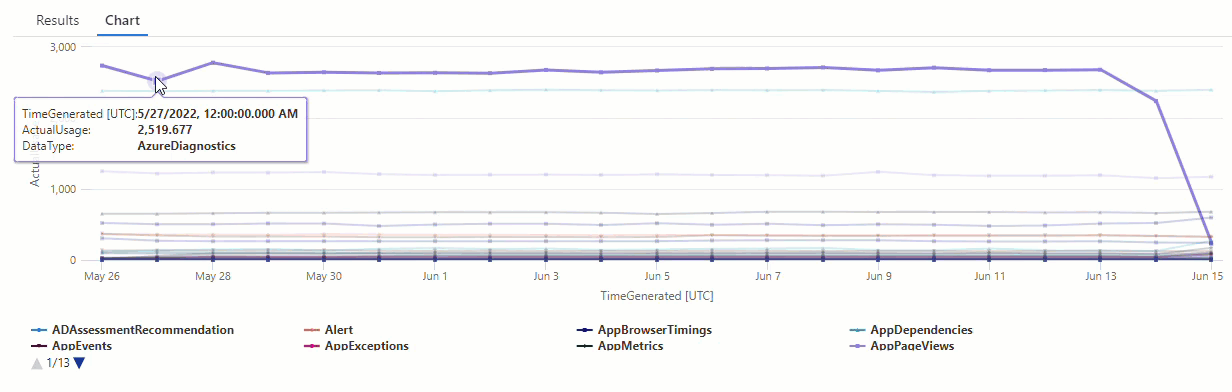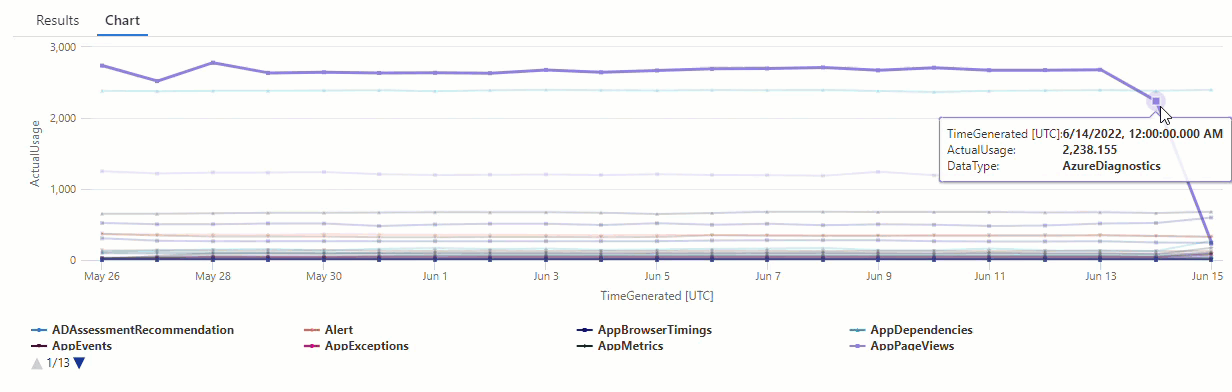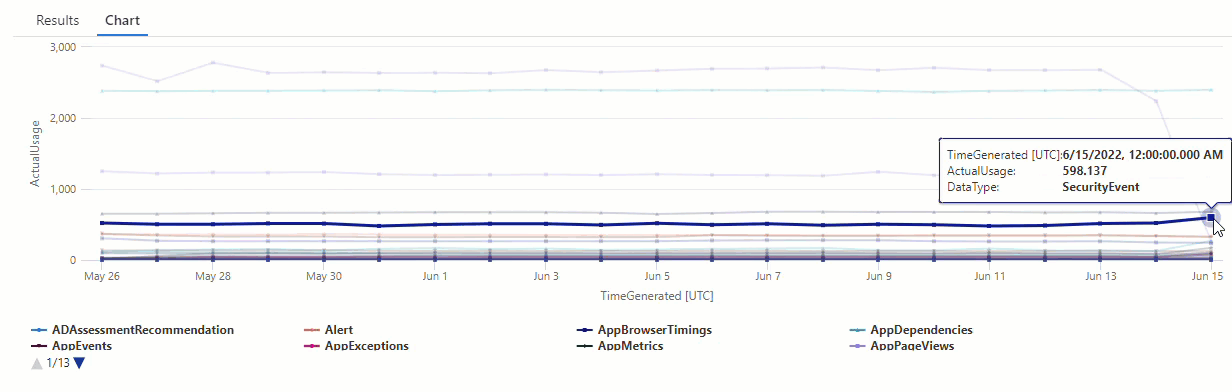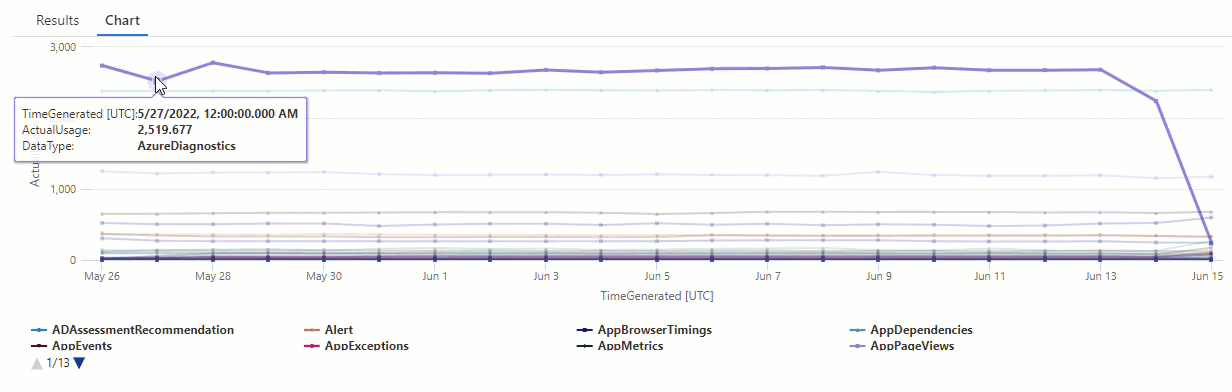
Selanjutnya, kita akan menggunakan fungsi KQL untuk mencantumkan semua anomali dalam rangkaian waktu.
Catatan
Untuk informasi selengkapnya tentang make-series sintaksis dan penggunaan, lihat operator seri buatan.
Menemukan anomali dalam rangkaian waktu
Fungsi ini series_decompose_anomalies() mengambil serangkaian nilai sebagai input dan mengekstrak anomali.
Mari kita berikan kumpulan hasil kueri rangkaian waktu sebagai input ke series_decompose_anomalies() fungsi:
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Kueri ini mengembalikan semua anomali penggunaan untuk semua tabel dalam tiga minggu terakhir:

Melihat hasil kueri, Anda bisa melihat bahwa fungsi:
- Menghitung penggunaan harian yang diharapkan untuk setiap tabel.
- Membandingkan penggunaan harian aktual dengan penggunaan yang diharapkan.
- Menetapkan skor anomali ke setiap titik data, menunjukkan sejauh mana penyimpangan penggunaan aktual dari penggunaan yang diharapkan.
- Mengidentifikasi anomali positif (
1) dan negatif (-1) di setiap tabel.
Catatan
Untuk informasi selengkapnya tentang series_decompose_anomalies() sintaksis dan penggunaan, lihat series_decompose_anomalies().
Mengubah pengaturan deteksi anomali untuk menyempurnakan hasil
Adalah praktik yang baik untuk meninjau hasil kueri awal dan membuat perubahan pada kueri, jika perlu. Outlier dalam data input dapat memengaruhi pembelajaran fungsi, dan Anda mungkin perlu menyesuaikan pengaturan deteksi anomali fungsi untuk mendapatkan hasil yang lebih akurat.
Filter hasil series_decompose_anomalies() kueri untuk anomali dalam AzureDiagnostics jenis data:

Hasilnya menunjukkan dua anomali pada 14 Juni dan 15 Juni. Bandingkan hasil ini dengan bagan dari kueri pertama make-series kami, di mana Anda dapat melihat anomali lain pada 27 dan 28 Mei:

Perbedaan hasil terjadi karena series_decompose_anomalies() fungsi menilai anomali relatif terhadap nilai penggunaan yang diharapkan, yang dihitung fungsi berdasarkan rentang penuh nilai dalam seri input.
Untuk mendapatkan hasil yang lebih halus dari fungsi, kecualikan penggunaan pada 15 Juni - yang merupakan outlier dibandingkan dengan nilai lain dalam seri - dari proses pembelajaran fungsi.
Sintaks series_decompose_anomalies() fungsi adalah:
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
Test_points menentukan jumlah titik di akhir seri yang akan dikecualikan dari proses pembelajaran (regresi).
Untuk mengecualikan titik data terakhir, atur Test_points ke 1:
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Filter hasil untuk AzureDiagnostics jenis data:

Semua anomali dalam bagan dari kueri pertama make-series kami sekarang muncul dalam tataan hasil.
Menganalisis akar penyebab anomali
Membandingkan nilai yang diharapkan dengan nilai anomali membantu Anda memahami penyebab perbedaan antara dua set.
Plugin KQL diffpatterns() membandingkan dua himpunan data dari struktur yang sama dan menemukan pola yang mencirikan perbedaan antara dua himpunan data.
Kueri ini membandingkan AzureDiagnostics penggunaan pada 15 Juni, outlier ekstrem dalam contoh kami, dengan penggunaan tabel pada hari lain:
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
Kueri mengidentifikasi setiap entri dalam tabel seperti yang terjadi pada AnomalyDate (15 Juni) atau OtherDates. Plugin diffpatterns() kemudian membagi himpunan data ini - yang disebut A (OtherDates dalam contoh kami) dan B (AnomalyDate dalam contoh kami) - dan mengembalikan beberapa pola yang berkontribusi pada perbedaan dalam dua set:

Melihat hasil kueri, Anda bisa melihat perbedaan berikut:
- Ada 24.892.147 instans penyerapan dari sumber daya CH1-GEARAMAAKS pada semua hari lain dalam rentang waktu kueri, dan tidak ada penyerapan data dari sumber daya ini pada 15 Juni. Data dari sumber daya CH1-GEARAMAAKS menyurati 73,36% dari total penyerapan pada hari lain dalam rentang waktu kueri dan 0% dari total penyerapan pada 15 Juni.
- Ada 2.168.448 instans penyerapan dari sumber daya NSG-TESTSQLMI519 pada semua hari lain dalam rentang waktu kueri, dan 110.544 instans penyerapan dari sumber daya ini pada 15 Juni. Data dari sumber daya NSG-TESTSQLMI519 menyuplai 6,39% dari total penyerapan pada hari lain dalam rentang waktu kueri dan 25,61% penyerapan pada 15 Juni.
Perhatikan bahwa, rata-rata, ada 108.422 instans penyerapan dari sumber daya NSG-TESTSQLMI519 selama 20 hari yang membentuk periode hari lainnya (membagi 2.168.448 dengan 20). Oleh karena itu, penyerapan dari sumber daya NSG-TESTSQLMI519 pada 15 Juni tidak secara signifikan berbeda dari penyerapan dari sumber daya ini pada hari lain. Namun, karena tidak ada penyerapan dari CH1-GEARAMAAKS pada 15 Juni, penyerapan dari NSG-TESTSQLMI519 membentuk persentase yang jauh lebih besar dari total penyerapan pada tanggal anomali dibandingkan dengan hari lain.
Kolom PercentDiffAB memperlihatkan perbedaan titik persentase absolut antara A dan B (|PercentA - PercentB|), yang merupakan ukuran utama perbedaan antara dua set. Secara default, diffpatterns() plugin mengembalikan selisih lebih dari 5% antara dua himpunan data, tetapi Anda dapat mengubah ambang batas ini. Misalnya, untuk mengembalikan hanya perbedaan 20% atau lebih antara dua himpunan data, Anda dapat mengatur | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) dalam kueri di atas. Kueri sekarang hanya mengembalikan satu hasil:

Catatan
Untuk informasi selengkapnya tentang diffpatterns() sintaksis dan penggunaan, lihat plugin pola diff.
Langkah berikutnya
Pelajari lebih lanjut tentang: