Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Memigrasikan database kelas Exadata dengan performa tinggi ke cloud semakin menjadi penting bagi pelanggan Microsoft. Suite perangkat lunak rantai pasokan biasanya menetapkan standar tinggi karena tuntutan intens pada I/O penyimpanan dengan beban kerja baca dan tulis campuran yang didorong oleh satu node komputasi. Infrastruktur Azure dalam kombinasi dengan Azure NetApp Files mampu memenuhi kebutuhan beban kerja yang sangat menuntut ini. Artikel ini menyajikan contoh bagaimana permintaan ini terpenuhi untuk satu pelanggan dan bagaimana Azure dapat memenuhi tuntutan beban kerja Oracle penting Anda.
Oracle dengan performa skala perusahaan
Saat menjelajahi batas maksimum performa, penting untuk mengenali dan mengurangi batasan apa pun yang dapat menyebabkan hasil yang salah atau bias. Misalnya, jika niatnya adalah untuk membuktikan kemampuan performa sistem penyimpanan, klien idealnya harus dikonfigurasi sehingga CPU tidak menjadi faktor mitigasi sebelum batas performa penyimpanan tercapai. Untuk itu, pengujian dimulai dengan jenis instans E104ids_v5 karena VM ini dilengkapi tidak hanya dengan antarmuka jaringan 100 Gbps, tetapi dengan batas keluar yang sama besarnya (100 Gbps).
Pengujian terjadi dalam dua fase:
- Fase pertama berfokus pada pengujian menggunakan alat SLOB2 (Silly Little Oracle Benchmark) standar industri Kevin Closson - versi 2.5.4. Tujuannya adalah untuk mendorong I/O Oracle sebanyak mungkin dari satu komputer virtual (VM) ke beberapa volume Azure NetApp Files, lalu peluasan skala menggunakan lebih banyak database untuk menunjukkan penskalaan linier.
- Setelah menguji batas penskalaan, pengujian kami dialihkan ke model E96ds_v5 yang lebih murah namun hampir sama kemampuan untuk beberapa fase pengujian pelanggan menggunakan beban kerja aplikasi rantai pasokan yang nyata dan data dari dunia nyata.
Performa peningkatan skala SLOB2
Bagan berikut menangkap profil performa satu E104ids_v5 Azure VM yang menjalankan satu database Oracle 19c terhadap delapan volume Azure NetApp Files dengan delapan titik akhir penyimpanan. Volume tersebar di tiga grup disk ASM: data, log, dan arsip. Lima volume dialokasikan ke grup disk data, dua volume ke grup disk log, dan satu volume ke grup disk arsip. Semua hasil yang diambil di seluruh artikel ini dikumpulkan menggunakan wilayah Azure produksi dan layanan Azure produksi aktif.
Untuk menyebarkan Oracle di komputer virtual Azure menggunakan beberapa volume Azure NetApp Files di beberapa titik akhir penyimpanan, gunakan grup volume aplikasi untuk Oracle.
Arsitektur host tunggal
Diagram berikut menggambarkan arsitektur tempat pengujian selesai; perhatikan database Oracle yang tersebar di beberapa volume dan titik akhir Azure NetApp Files.

I/O pada penyimpanan satu host
Diagram berikut menunjukkan beban kerja yang dipilih secara acak 100% dengan rasio hit buffer database sekitar 8%. SLOB2 mampu mendorong sekitar 850.000 permintaan I/O per detik sambil mempertahankan latensi peristiwa baca berurutan file DB submillisecond. Dengan ukuran blok database sebesar 8K, yang menghasilkan throughput penyimpanan sekitar 6.800 MiB/dtk.

Kapasitas pemrosesan host tunggal
Diagram berikut menunjukkan bahwa, untuk beban kerja I/O berurutan yang intensif bandwidth seperti pemindaian tabel penuh atau aktivitas RMAN, Azure NetApp Files dapat memberikan seluruh kemampuan bandwidth dari VM E104ids_v5 itu sendiri.

Catatan
Karena instans komputasi berada pada maksimum teoritis bandwidthnya, penambahan konkurensi aplikasi hanya mengakibatkan peningkatan latensi di sisi klien. Ini menghasilkan beban kerja SLOB2 melebihi jangka waktu penyelesaian yang ditargetkan oleh karena itu jumlah utas dibatasi pada enam.
Performa pengembangan skala SLOB2
Bagan berikut menangkap profil performa tiga E104ids_v5 Azure VM masing-masing menjalankan satu database Oracle 19c dan masing-masing dengan sekumpulan volume Azure NetApp Files mereka sendiri dan tata letak grup disk ASM yang identik seperti yang dijelaskan di bagian Meningkatkan performa. Grafik menunjukkan bahwa dengan multi-volume/multi-endpoint Azure NetApp Files, performa dengan mudah diskalakan secara konsisten dan dapat diprediksi.
Arsitektur multi-host
Diagram berikut menggambarkan arsitektur tempat pengujian selesai; perhatikan tiga database Oracle yang tersebar di beberapa volume dan titik akhir Azure NetApp Files. Titik akhir dapat didedikasikan untuk satu host seperti yang ditunjukkan dengan Oracle VM 1 atau dibagikan di antara host seperti yang ditunjukkan dengan Oracle VM2 dan Oracle VM 3.

IO penyimpanan multi-host
Diagram berikut menunjukkan beban kerja yang dipilih secara acak 100% dengan rasio hit buffer database sekitar 8%. SLOB2 mampu mendorong sekitar 850.000 permintaan I/O per detik di ketiga host satu per satu. SLOB2 dapat mencapainya saat beroperasi secara paralel dengan total kolektif sekitar 2.500.000 permintaan I/O per detik dengan setiap host masih mempertahankan latensi untuk event baca berurutan pada file db di bawah satu milidetik. Dengan ukuran blok database 8K, ini berjumlah sekitar 20.000 MiB/s di antara dengan ketiga host.

Throughput multi-host
Diagram berikut menunjukkan bahwa untuk beban kerja berurutan, Azure NetApp Files masih dapat memberikan kemampuan bandwidth penuh dari E104ids_v5 VM itu sendiri bahkan saat skalanya diperluas. SLOB2 mampu menghasilkan I/O yang berjumlah lebih dari 30.000 MiB/dtk di tiga host saat berjalan paralel.

Kinerja dunia nyata
Setelah batas penskalakan diuji dengan SLOB2, pengujian dilakukan dengan rangkaian aplikasi rantai pasokan nyata terhadap Oracle pada lingkungan file Azure NetApp dengan hasil yang sangat baik. Data berikut dari laporan Oracle Automatic Workload Repository (AWR) adalah tampilan yang disorot tentang bagaimana satu pekerjaan penting tertentu dilakukan.
Database ini memiliki IO tambahan yang signifikan selain beban kerja aplikasi karena kilas balik diaktifkan dan memiliki ukuran blok database 16k. Berdasarkan bagian profil IO dari laporan AWR, terlihat bahwa ada tingginya rasio penulisan dibandingkan dengan pembacaan.
| - | Membaca dan menulis per detik | Baca per detik | Tulis per detik |
|---|---|---|---|
| Jumlah (MB) | 4,988.1 | 1,395.2 | 3,592.9 |
Meskipun peristiwa tunggu "db file sequential read" menunjukkan latensi yang lebih tinggi sebesar 2,2 ms dibandingkan dengan pengujian SLOB2, pelanggan ini mengalami pengurangan waktu eksekusi pekerjaan selama lima belas menit ketika berpindah dari database RAC di Exadata ke database instance tunggal di Azure.
Batasan sumber daya Azure
Semua sistem akhirnya mencapai batasan sumber daya, secara tradisional dikenal sebagai titik hambat. Beban kerja database, terutama yang sangat menuntut seperti paket aplikasi rantai pasokan, adalah entitas yang memerlukan banyak sumber daya. Menemukan batasan sumber daya ini dan mengerjakannya sangat penting untuk penyebaran yang berhasil. Bagian ini menjelaskan berbagai batasan yang mungkin Anda temui dalam lingkungan seperti itu dan bagaimana cara mengatasinya. Dalam setiap subbagian, harap pelajari praktik terbaik dan alasan di belakangnya.
Mesin virtual
Bagian ini merinci kriteria yang akan dipertimbangkan dalam memilih VM untuk performa terbaik dan alasan di balik pilihan yang dibuat untuk pengujian. Azure NetApp Files adalah layanan Network Attached Storage (NAS), oleh karena itu ukuran bandwidth jaringan yang sesuai sangat penting untuk performa optimal.
Chipset
Topik pertama yang menarik adalah pemilihan chipset. Pastikan bahwa SKU VM apa pun yang Anda pilih dibangun pada satu chipset karena alasan konsistensi. Varian Intel dari E_v5 VM berjalan pada konfigurasi Intel Xeon Platinum 8370C (Ice Lake) Generasi ketiga. Semua VM dalam keluarga ini dilengkapi dengan satu antarmuka jaringan 100 Gbps. Sebaliknya, seri E_v3, yang disebutkan melalui contoh, dibangun di atas empat chipset terpisah, dengan berbagai bandwidth jaringan fisik. Empat chipset yang digunakan dalam keluarga E_v3 (Broadwell, Skylake, Cascade Lake, Haswell) memiliki kecepatan prosesor yang berbeda, yang memengaruhi karakteristik performa mesin.
Baca dokumentasi Azure Compute dengan cermat memperhatikan opsi chipset. Juga lihat praktik terbaik SKU Azure VM untuk Azure NetApp Files. Memilih VM dengan satu chipset lebih disukai untuk konsistensi terbaik.
Bandwidth jaringan yang tersedia
Penting untuk memahami perbedaan antara bandwidth yang tersedia dari antarmuka jaringan VM dan bandwidth terukur yang diterapkan terhadap bandwidth tersebut. Saat dokumentasi Azure Compute membahas batas bandwidth jaringan, batas ini diterapkan hanya dalam penulisan keluar. Lalu lintas masuk tidak dikenai batasan dan karena itu hanya dibatasi oleh bandwidth fisik dari kartu antarmuka jaringan (NIC) itu sendiri. Bandwidth jaringan sebagian besar mesin virtual melebihi limit egress yang diterapkan pada mesin.
Karena volume Azure NetApp Files terkait dengan jaringan, batas keluar dapat dipahami khusus diterapkan pada penulisan, sedangkan batas masuk mencakup beban kerja baca dan yang serupa dengan membaca. Meskipun batas keluaran sebagian besar mesin lebih besar dari bandwidth jaringan NIC, hal yang sama tidak dapat dikatakan untuk E104_v5 yang digunakan dalam pengujian untuk artikel ini. E104_v5 memiliki NIC 100 Gbps dengan batas keluar yang ditetapkan pada 100 Gbps juga. Sebagai perbandingan, E96_v5 dengan NIC 100 Gbps-nya memiliki batas egress 35 Gbps dengan ingress tidak terbatas pada 100 Gbps. Ketika VM berkurang ukurannya, batas keluar berkurang tetapi ingress tetap tidak terkekang oleh batas yang diberlakukan secara logis.
Batas keluar berlaku untuk seluruh VM dan diterapkan terhadap semua beban kerja berbasis jaringan. Saat menggunakan Oracle Data Guard, semua penulisan dilakukan dua kali pada log arsip dan harus diperhitungkan dalam pertimbangan batas egress. Ini juga berlaku untuk log arsip dengan tujuan ganda dan RMAN, jika digunakan. Saat memilih VM, biasakan diri Anda dengan alat baris perintah seperti ethtool, yang mengekspos konfigurasi NIC karena Azure tidak mendokumentasikan konfigurasi antarmuka jaringan.
Konkurensi jaringan
Volume Azure VM dan Azure NetApp Files dilengkapi dengan jumlah bandwidth tertentu. Seperti yang ditunjukkan sebelumnya, selama VM memiliki headroom CPU yang memadai, beban kerja dapat secara teori menggunakan bandwidth yang tersedia untuknya --yang berada dalam batas kartu jaringan dan atau batas keluar yang diterapkan. Namun, dalam praktiknya, jumlah throughput yang dapat dicapai diprediksi berdasarkan konkurensi beban kerja di jaringan, yaitu jumlah alur jaringan dan titik akhir jaringan.
Baca bagian batas alur jaringan dari dokumen bandwidth jaringan VM untuk pemahaman yang lebih besar. Intinya: semakin banyak alur jaringan yang menghubungkan klien ke penyimpanan, semakin kaya potensi performa.
Oracle mendukung dua klien NFS terpisah, Kernel NFS dan Direct NFS (dNFS). Kernel NFS, hingga baru-baru ini, hanya mendukung satu aliran jaringan antara dua titik akhir (komputasi – penyimpanan). Direct NFS, yang lebih unggul dalam hal performa dari keduanya, mendukung jumlah aliran jaringan yang bervariasi - pengujian menunjukkan kemampuan menangani ratusan koneksi unik per titik akhir - yang dapat meningkat atau menurun sesuai dengan permintaan beban. Karena penskalaan aliran jaringan antara dua titik akhir, NFS Langsung jauh lebih disukai daripada Kernel NFS, sehingga menjadi konfigurasi yang direkomendasikan. Grup produk Azure NetApp Files tidak merekomendasikan penggunaan Kernel NFS dengan beban kerja Oracle. Untuk informasi selengkapnya, lihat Manfaat menggunakan Azure NetApp Files dengan Oracle Database.
Keserentakan eksekusi
Menggunakan NFS Langsung, satu chipset untuk konsistensi, dan memahami batasan bandwidth jaringan memiliki batas manfaatnya. Pada akhirnya, aplikasi mendorong performa. Bukti konsep menggunakan SLOB2 dan bukti konsep menggunakan rangkaian aplikasi rantai pasokan dunia nyata terhadap data pelanggan nyata dapat mendorong jumlah throughput yang signifikan hanya karena aplikasi berjalan pada tingkat konkurensi yang tinggi; yang pertama menggunakan sejumlah besar utas per skema, yang terakhir menggunakan beberapa koneksi dari beberapa server aplikasi. Singkatnya, konkurensi mendorong beban kerja, konkurensi rendah--throughput rendah, konkurensi tinggi--throughput tinggi selama infrastruktur tersedia untuk mendukung hal yang sama.
Jaringan yang dipercepat
Jaringan terakselerasi memungkinkan virtualisasi I/O root tunggal (SR-IOV) pada VM, sangat meningkatkan kinerja jaringannya. Jalur berperforma tinggi ini melewatkan host dari jalur data, yang mengurangi latensi, jitter, dan penggunaan CPU untuk beban kerja jaringan yang paling berat pada jenis VM yang didukung. Saat menyebarkan VM melalui utilitas manajemen konfigurasi seperti terraform atau baris perintah, ketahuilah bahwa jaringan yang dipercepat tidak diaktifkan secara default. Untuk performa optimal, aktifkan jaringan yang dipercepat. Perhatikan bahwa jaringan yang dipercepat diaktifkan atau dinonaktifkan pada setiap antarmuka jaringan secara individual. Fitur jaringan yang dipercepat adalah fitur yang dapat diaktifkan atau dinonaktifkan secara dinamis.
Catatan
Artikel ini berisi referensi ke istilah SLAVE, istilah yang tidak lagi digunakan Microsoft. Ketika istilah ini dihapus dari perangkat lunak, kami akan menghapusnya dari artikel ini.
Pendekatan otoritatif untuk memastikan jaringan yang dipercepat untuk NIC dapat dilakukan melalui terminal Linux. Jika jaringan yang dipercepat diaktifkan untuk NIC, NIC virtual kedua ada yang terkait dengan NIC pertama. NIC kedua ini dikonfigurasi oleh sistem dengan SLAVE penanda diaktifkan. Jika tidak ada NIC yang ada dengan flag SLAVE, jaringan yang dipercepat tidak diaktifkan untuk antarmuka tersebut.
Dalam skenario di mana beberapa NIC dikonfigurasi, Anda perlu menentukan antarmuka SLAVE mana yang terkait dengan NIC yang digunakan untuk memasang volume NFS. Menambahkan kartu antarmuka jaringan ke VM tidak berpengaruh pada performa.
Gunakan proses berikut untuk mengidentifikasi pemetaan antara antarmuka jaringan yang dikonfigurasi dan antarmuka virtual terkait. Proses ini memvalidasi bahwa jaringan yang dipercepat diaktifkan untuk NIC tertentu pada komputer Linux Anda dan menampilkan kecepatan masuk fisik yang berpotensi dicapai NIC.
- Jalankan
ip aperintah: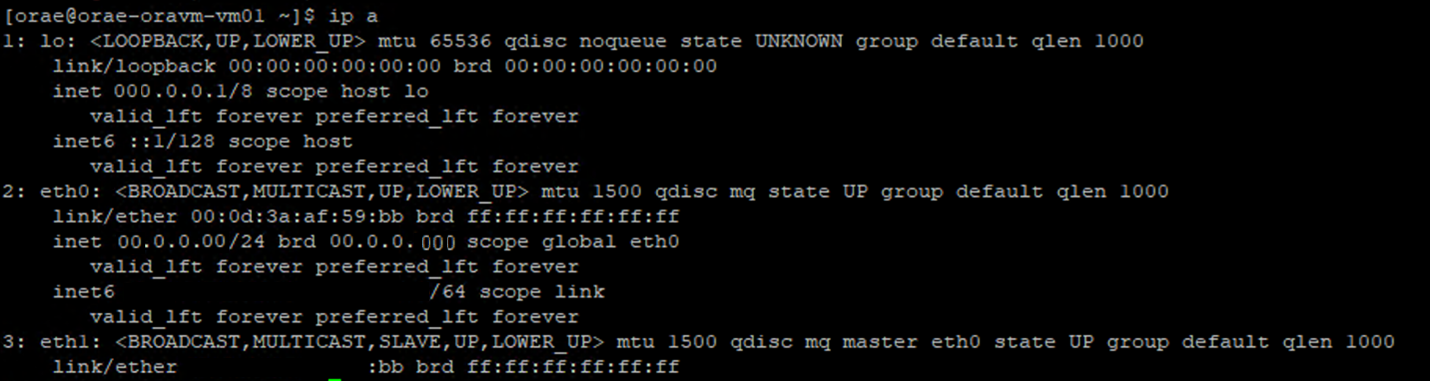
- Cantumkan
/sys/class/net/direktori ID NIC yang Anda verifikasi (eth0dalam contoh) dangrepuntuk kata 'lower':ls /sys/class/net/eth0 | grep lower lower_eth1 - Jalankan
ethtoolperintah terhadap perangkat ethernet yang diidentifikasi sebagai perangkat yang lebih rendah di langkah sebelumnya.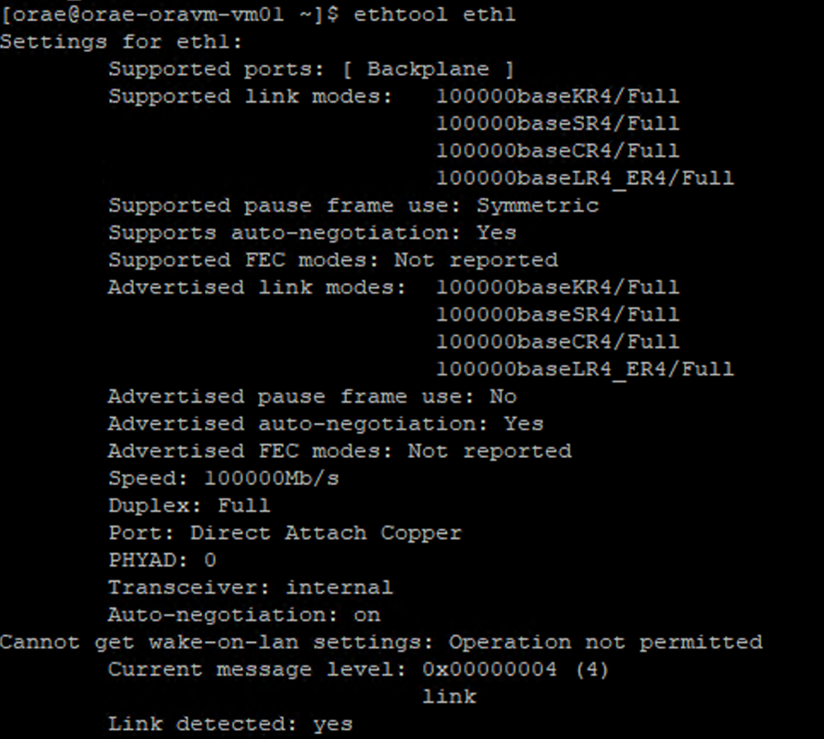
Azure VM: Batas bandwidth jaringan vs. disk
Tingkat keahlian diperlukan saat membaca dokumentasi batas performa Azure VM. Waspadalah terhadap:
- Throughput penyimpanan sementara dan angka IOPS mengacu pada kemampuan performa penyimpanan sementara di dalam kotak yang terhubung langsung ke VM.
- Throughput disk dan nomor I/O yang tidak di-cache mengacu secara khusus ke Azure Disk (Premium, Premium v2, dan Ultra) dan tidak mempengaruhi penyimpanan yang terhubung melalui jaringan seperti Azure NetApp Files.
- Melampirkan NIC tambahan ke VM tidak berdampak pada batas performa atau kemampuan performa VM (didokumentasikan dan diuji menjadi benar).
- Bandwidth jaringan maksimum mengacu pada batas keluar (yaitu, menulis saat Azure NetApp Files digunakan) diterapkan pada bandwidth jaringan VM. Tidak ada pembatasan untuk ingress (yaitu, pembacaan saat Azure NetApp Files terlibat) yang diterapkan. Mengingat CPU yang cukup, konkurensi jaringan yang cukup, dan titik akhir yang cukup kaya, VM dapat secara teoritis mendorong lalu lintas masuk ke batas NIC. Seperti disebutkan di bagian Bandwidth jaringan yang tersedia, gunakan alat seperti
ethtooluntuk melihat bandwidth NIC.
Bagan sampel ditampilkan untuk referensi:

Azure NetApp Files
Layanan penyimpanan pihak pertama Azure Azure NetApp Files menyediakan solusi penyimpanan terkelola penuh yang sangat tersedia yang mampu mendukung beban kerja Oracle yang menuntut yang diperkenalkan sebelumnya.
Karena batasan performa penyimpanan skala-up dalam database Oracle sudah dipahami dengan baik, artikel ini sengaja berfokus pada performa penyimpanan skala-out. Memperluas skala kinerja penyimpanan berarti memberikan akses kepada satu instans Oracle ke banyak volume Azure NetApp Files yang didistribusikan ke berbagai endpoint penyimpanan.
Dengan menskalakan beban kerja database di beberapa volume dengan cara seperti itu, performa database tidak tertaut dari batas atas volume dan titik akhir. Dengan penyimpanan tidak lagi memberlakukan batasan performa, arsitektur VM (CPU, NIC, dan batas keluaran VM) menjadi penghambat yang harus diatasi. Seperti yang disebutkan di bagian VM, pemilihan instans E104ids_v5 dan E96ds_v5 dilakukan dengan pertimbangan ini.
Apakah database ditempatkan pada satu volume kapasitas besar atau tersebar di beberapa volume yang lebih kecil, total biaya keuangannya sama. Keuntungan mendistribusikan I/O di beberapa volume dan berbagai titik akhir dibandingkan dengan satu volume dan titik akhir adalah menghindari batasan bandwidth—Anda dapat sepenuhnya menggunakan apa yang Anda bayar.
Penting
Untuk menyebarkan menggunakan Azure NetApp Files dalam multiple volume:multiple endpoint konfigurasi, hubungi Spesialis Azure NetApp Files atau Arsitek Solusi Cloud Anda untuk mendapatkan bantuan.
Basis data
Database Oracle versi 19c adalah versi rilis jangka panjang Oracle saat ini dan yang digunakan untuk menghasilkan semua hasil pengujian yang dibahas dalam makalah ini.
Untuk performa terbaik, semua volume database dipasang menggunakan NFS Langsung; disarankan untuk tidak menggunakan NFS Kernel karena kendala performa. Untuk perbandingan performa antara kedua klien, lihat Performa database Oracle pada volume tunggal Azure NetApp Files. Perhatikan, semua patch dNFS yang relevan (ID Dukungan Oracle 1495104) diterapkan, seperti halnya praktik terbaik yang diuraikan dalam Oracle Database di Microsoft Azure menggunakan laporan Azure NetApp Files .
Sementara Oracle dan Azure NetApp Files mendukung NFSv3 dan NFSv4.1, karena NFSv3 adalah protokol yang lebih matang yang umumnya dipandang memiliki stabilitas terbanyak dan merupakan opsi yang lebih andal untuk lingkungan yang sangat sensitif terhadap gangguan. Pengujian yang dijelaskan dalam artikel ini semuanya diselesaikan melalui NFSv3.
Penting
Beberapa patch yang direkomendasikan yang didokumentasikan Oracle di ID Dukungan 1495104 sangat penting untuk mempertahankan integritas data saat menggunakan dNFS. Penerapan patch tersebut sangat disarankan untuk lingkungan produksi.
Manajemen Penyimpanan Otomatis (ASM) didukung untuk volume NFS. Meskipun biasanya dikaitkan dengan penyimpanan berbasis blok di mana ASM menggantikan manajemen volume logis (LVM) dan sistem file keduanya, ASM memainkan peran berharga dalam skenario NFS multi-volume dan patut dipertimbangkan dengan kuat. Salah satu keunggulan ASM adalah penambahan online dinamis dan penyeimbangan ulang di seluruh volume dan titik akhir NFS yang baru ditambahkan, yang menyederhanakan manajemen dan memungkinkan perluasan performa serta kapasitas sesuai kebutuhan. Meskipun ASM sendiri tidak meningkatkan kinerja database, penggunaannya menghindari terjadinya file-file yang sering diakses dan kebutuhan untuk mempertahankan distribusi file secara manual—keuntungan yang mudah dilihat.
ASM melalui konfigurasi dNFS digunakan untuk menghasilkan semua hasil pengujian yang dibahas dalam artikel ini. Diagram berikut mengilustrasikan tata letak file ASM dalam volume Azure NetApp Files dan alokasi file ke grup disk ASM.

Ada beberapa batasan dalam penggunaan ASM pada volume NFS Azure NetApp Files yang dipasang, terutama dalam hal snapshot penyimpanan, yang dapat diatasi dengan pertimbangan arsitektur tertentu. Hubungi spesialis Azure NetApp Files atau arsitek solusi cloud Anda untuk tinjauan mendalam tentang pertimbangan ini.
Alat dan pengaturan uji sintetis
Bagian ini menjelaskan arsitektur pengujian, penyetelan, dan detail konfigurasi secara spesifik. Sementara bagian sebelumnya adalah alasan terfokus mengapa keputusan konfigurasi dibuat, bagian ini berfokus secara khusus pada "apa" keputusan konfigurasi.
Penyebaran otomatis
- VM database disebarkan menggunakan skrip bash yang tersedia di GitHub.
- Tata letak dan alokasi beberapa volume dan titik akhir Azure NetApp Files diselesaikan secara manual. Anda perlu bekerja dengan Spesialis Azure NetApp Files atau Arsitek Solusi Cloud untuk bantuan.
- Instalasi jaringan, konfigurasi ASM, pembuatan dan konfigurasi database, serta lingkungan SLOB2 pada setiap komputer dikonfigurasi menggunakan Ansible untuk konsistensi.
- Eksekusi pengujian Paralel SLOB2 di beberapa host juga diselesaikan menggunakan Ansible untuk konsistensi dan eksekusi simultan.
Konfigurasi komputer virtual
| Konfigurasi | Nilai |
|---|---|
| Wilayah Azure | Eropa Barat |
| VM SKU | E104ids_v5 |
| Jumlah NIC | 1 CATATAN: Menambahkan vNIC tidak berpengaruh pada jumlah sistem |
| Bandwidth maksimum jaringan egress (Mbps) | 100.000 |
| Penyimpanan sementara (SSD) GiB | 3,800 |
Konfigurasi sistem
Semua pengaturan konfigurasi sistem yang diperlukan Oracle untuk versi 19c diimplementasikan sesuai dengan dokumentasi Oracle.
Parameter berikut ditambahkan ke /etc/sysctl.conf file sistem Linux:
sunrpc.max_tcp_slot_table_entries: 128sunrpc.tcp_slot_table_entries = 128
Azure NetApp Files
Semua volume Azure NetApp Files dipasang dengan opsi pemasangan NFS berikut.
nfs rw,hard,rsize=262144,wsize=262144,sec=sys,vers=3,tcp
Parameter database
| Parameter | Nilai |
|---|---|
db_cache_size |
2g |
large_pool_size |
2g |
pga_aggregate_target |
3G |
pga_aggregate_limit |
3G |
sga_target |
25g |
shared_io_pool_size |
500m |
shared_pool_size |
5g |
db_files |
500 |
filesystemio_options |
SETALL |
job_queue_processes |
0 |
db_flash_cache_size |
0 |
_cursor_obsolete_threshold |
130 |
_db_block_prefetch_limit |
0 |
_db_block_prefetch_quota |
0 |
_db_file_noncontig_mblock_read_count |
0 |
Konfigurasi SLOB2
Semua pembuatan beban kerja untuk pengujian selesai menggunakan alat SLOB2 versi 2.5.4.
Empat belas skema SLOB2 dimuat ke dalam ruang tabel Oracle standar dan dijalankan, yang dikombinasikan dengan pengaturan file konfigurasi slob yang tercantum, letakkan himpunan data SLOB2 pada 7 TiB. Pengaturan berikut mencerminkan eksekusi baca acak untuk SLOB2. Parameter SCAN_PCT=0 konfigurasi diubah menjadi SCAN_PCT=100 selama pengujian berurutan.
UPDATE_PCT=0SCAN_PCT=0RUN_TIME=600SCALE=450GSCAN_TABLE_SZ=50GWORK_UNIT=32REDO_STRESS=LITETHREADS_PER_SCHEMA=1DATABASE_STATISTICS_TYPE=awr
Untuk pengujian baca acak, dilakukan sembilan kali eksekusi SLOB2. Jumlah utas ditingkatkan sebesar enam pada setiap iterasi pengujian, berawal dari satu.
Untuk pengujian berurutan, tujuh eksekusi SLOB2 dilakukan. Jumlah utas ditambahkan dua pada setiap perulangan pengujian, dimulai dari satu. Jumlah utas dibatasi hingga enam karena mencapai batas maksimum bandwidth jaringan.
Metrik AWR
Semua metrik performa dilaporkan melalui Repositori Beban Kerja Otomatis Oracle (AWR). Berikut ini adalah metrik yang disajikan dalam hasil:
- Throughput: penjumlahan dari throughput baca rata-rata dan throughput tulis rata-rata dari bagian AWR Load Profile
- Rata-rata membaca permintaan IO dari bagian AWR Load Profile
- db file berurutan membaca waktu tunggu rata-rata peristiwa dari bagian AWR Foreground Wait Events
Migrasi dari sistem yang dibuat khusus dan direkayasa ke cloud
Oracle Exadata adalah sistem rekayasa --kombinasi perangkat keras dan perangkat lunak yang dianggap sebagai solusi paling dioptimalkan untuk menjalankan beban kerja Oracle. Meskipun cloud memiliki keuntungan signifikan dalam skema keseluruhan dunia teknis, sistem khusus ini dapat terlihat sangat menarik bagi mereka yang telah membaca dan melihat pengoptimalan yang telah dibangun Oracle di sekitar beban kerja khusus mereka.
Ketika datang untuk menjalankan Oracle di Exadata, ada beberapa alasan umum Exadata dipilih:
- 1-2 jenis beban kerja IO tinggi yang secara alami cocok untuk fitur Exadata, dan karena beban kerja ini memerlukan fitur rekayasa Exadata yang esensial, database lainnya yang berjalan bersama mereka dikonsolidasikan ke Exadata.
- Beban kerja OLTP yang rumit atau sulit yang memerlukan RAC untuk ditingkatkan skalanya dan sulit dirancang dengan perangkat keras berpemilik tanpa pengetahuan mendalam tentang optimasi Oracle, atau mungkin merupakan utang teknis yang tidak dapat dioptimalkan.
- Penggunaan Exadata yang ada kurang optimal dengan berbagai beban kerja: ini bisa terjadi karena migrasi sebelumnya, penghentian operasional Exadata sebelumnya, atau karena keinginan untuk bekerja/menguji Exadata secara internal.
Sangat penting bagi setiap migrasi dari sistem Exadata untuk dipahami dari perspektif beban kerja dan seberapa sederhana atau kompleks migrasinya. Kebutuhan sekunder adalah untuk memahami alasan pembelian Exadata dari perspektif status. Keterampilan Exadata dan RAC memiliki permintaan yang lebih tinggi dan mungkin telah mendorong rekomendasi untuk membelinya oleh pemangku kepentingan teknis.
Penting
Tidak peduli skenarionya, kesimpulan utama harus, untuk beban kerja database apa pun yang berasal dari Exadata, semakin banyak fitur eksklusif Exadata yang digunakan, semakin kompleks migrasi dan perencanaannya. Lingkungan yang tidak banyak menggunakan fitur kepemilikan Exadata memiliki peluang untuk proses migrasi dan perencanaan yang lebih sederhana.
Ada beberapa alat yang dapat digunakan untuk menilai peluang beban kerja ini:
- Repositori Beban Kerja Otomatis (AWR):
- Semua database Exadata dilisensikan untuk menggunakan laporan AWR dan fitur performa dan diagnostik yang terhubung.
- Selalu aktif dan mengumpulkan data yang dapat digunakan untuk melihat informasi beban kerja historis dan menilai penggunaan. Nilai puncak dapat menilai penggunaan tinggi pada sistem,
- Laporan AWR jendela yang lebih besar dapat menilai beban kerja secara keseluruhan, memberikan wawasan berharga tentang penggunaan fitur dan cara memigrasikan beban kerja ke non-Exadata secara efektif. Laporan AWR puncak sebaliknya adalah yang terbaik untuk pengoptimalan dan pemecahan masalah performa.
- Laporan Global (RAC-Aware) AWR untuk Exadata juga mencakup bagian spesifik Exadata, yang mendalami penggunaan fitur Exadata tertentu dan menyediakan informasi wawasan yang berharga tentang cache flash, pencatatan flash, IO dan penggunaan fitur lainnya oleh database dan simpul sel.
Memisahkan dari Exadata
Saat mengidentifikasi beban kerja Oracle Exadata untuk bermigrasi ke cloud, pertimbangkan pertanyaan dan poin data berikut:
- Apakah beban kerja menggunakan beberapa fitur Exadata, di luar manfaat perangkat keras?
- Pemindaian cerdas
- Indeks penyimpanan
- Flash cache
- Pengelogan flash
- Kompresi kolom-berbasis hibrida
- Apakah beban kerja menggunakan offloading Exadata secara efisien? Dalam peristiwa penting di puncak waktu, berapa rasio (lebih dari 10% waktu basis data) dari beban kerja yang menggunakan:
- Pemindaian sel tabel cerdas (optimal)
- Sel multiblock baca fisik (kurang optimal)
- Sel satu blok baca fisik (paling tidak optimal)
- Kompresi Kolumnar Hibrid (HCC/EHCC): Berapa rasio terkompresi vs. yang tidak dikompresi:
- Apakah database menghabiskan lebih dari 10% waktu database untuk mengompresi dan mendekompresi data?
- Periksa perolehan performa untuk predikat menggunakan kompresi dalam kueri: apakah nilai yang diperoleh sepadan versus jumlah yang disimpan dengan kompresi?
- IO fisik sel: Tinjau penghematan yang diberikan oleh:
- jumlah yang diarahkan ke node basis data untuk menyeimbangkan CPU.
- mengidentifikasi jumlah byte yang dikembalikan oleh pemindaian pintar. Nilai-nilai ini dapat dikurangkan dalam IO untuk persentase pembacaan fisik blok tunggal sel setelah migrasi dari Exadata.
- Perhatikan jumlah bacaan logis dari cache. Tentukan apakah cache flash akan diperlukan dalam solusi IaaS cloud untuk beban kerja.
- Bandingkan byte total baca dan tulis fisik dengan jumlah yang dilakukan total dalam cache. Apakah memori dapat ditingkatkan untuk menghilangkan kebutuhan pembacaan fisik (umum bagi beberapa pengguna untuk mengecilkan SGA guna memaksa offloading untuk Exadata)?
- Dalam Statistik Sistem, identifikasi objek apa yang terpengaruh oleh statistik apa. Jika menyetel SQL, pengindeksan lebih lanjut, partisi, atau penyetelan fisik lainnya dapat mengoptimalkan beban kerja secara dramatis.
- Periksa Parameter Inisialisasi untuk parameter yang mengandung garis bawah (_) atau parameter yang sudah usang, yang perlu dipertimbangkan akibat dampaknya pada tingkat database yang mungkin mempengaruhi performa.
Konfigurasi server Exadata
Di Oracle versi 12.2 ke atas, penambahan spesifik Exadata akan disertakan dalam laporan global AWR. Laporan ini memiliki bagian yang memberikan nilai luar biasa untuk migrasi dari Exadata.
Versi Exadata dan detail sistem
Detail peringatan simpul sel
Disk Exadata tidak online
Data outlier untuk statistik OS Exadata apa pun
Kuning/Merah Muda: Mengkhawatirkan. Exadata tidak berjalan optimal.
Merah: Performa exadata terpengaruh secara signifikan.
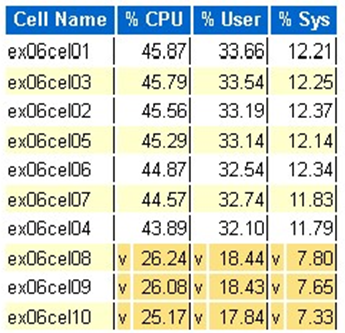
Statistik CPU OS Exadata: sel atas
- Statistik ini dikumpulkan oleh OS pada sel dan tidak dibatasi untuk database atau instans ini
-
vdan latar belakang kuning tua menunjukkan nilai penyimpangan di bawah rentang rendah. - Sebuah
^dan latar belakang kuning muda menunjukkan nilai pencilan di atas rentang tinggi. - Sel atas menurut persentase CPU ditampilkan dan berada dalam urutan menurun dari persentase CPU
- Rata-rata: 39,34% CPU, 28,57% pengguna, 10,77% sys
Pembacaan blok fisik sel tunggal
Penggunaan cache flash
Temp IO
Efisiensi cache berkolom
Database teratas menurut throughput IO
Meskipun penilaian ukuran dapat dilakukan, ada beberapa pertanyaan tentang rata-rata dan puncak simulasi yang terintegrasi dalam nilai-nilai ini untuk beban kerja besar. Bagian ini, yang ditemukan di akhir laporan AWR, sangat berharga karena menunjukkan flash rata-rata dan penggunaan disk dari 10 database teratas di Exadata. Meskipun banyak yang mungkin berasumsi bahwa mereka ingin menentukan ukuran database untuk kinerja puncak di cloud, ini tidak masuk akal untuk sebagian besar implementasi (lebih dari 95% berada dalam range rata-rata; dengan puncak yang disimulasikan dihitung, range rata-rata lebih besar dari 98%). Penting untuk membayar apa yang diperlukan, bahkan untuk beban kerja dengan permintaan tertinggi pada Oracle dan memeriksa Database Teratas berdasarkan Throughput IO dapat menjadi pencerahan untuk memahami kebutuhan sumber daya untuk database.
Menyesuaikan ukuran Oracle menggunakan AWR di Exadata
Saat melakukan perencanaan kapasitas untuk sistem lokal, wajar jika memiliki overhead signifikan yang terpasang dalam perangkat keras. Perangkat keras yang disediakan berlebihan perlu melayani beban kerja Oracle selama beberapa tahun kedepan, terlepas dari penambahan beban kerja karena pertumbuhan data, perubahan kode, atau peningkatan.
Salah satu manfaat cloud adalah menskalakan sumber daya dalam host VM dan penyimpanan dapat dilakukan saat permintaan meningkat. Ini membantu menghemat biaya cloud dan biaya lisensi yang melekat pada penggunaan prosesor (berkaitan dengan Oracle).
Ukuran yang tepat melibatkan penghapusan perangkat keras dari migrasi lift dan shift tradisional dan menggunakan informasi beban kerja yang disediakan oleh Repositori Beban Kerja Otomatis (AWR) Oracle untuk mengangkat dan mengalihkan beban kerja ke komputasi dan penyimpanan yang dirancang khusus untuk mendukungnya di cloud pilihan pelanggan. Proses penyesuaian ukuran yang tepat memastikan bahwa arsitektur di masa depan menghapus utang teknis pada infrastruktur, redundansi arsitektur yang akan terjadi jika sistem lokal diduplikasi ke cloud, dan memanfaatkan layanan cloud sebisa mungkin.
Pakar bidang Microsoft Oracle memperkirakan bahwa lebih dari 80% database Oracle ditentukan secara berlebihan dan mengalami biaya atau penghematan yang setara ketika beralih ke cloud, jika mereka meluangkan waktu untuk menyesuaikan beban kerja database Oracle sebelum bermigrasi ke cloud. Penilaian ini mengharuskan spesialis database di tim untuk mengubah pola pikir mereka tentang bagaimana mereka mungkin telah melakukan perencanaan kapasitas di masa lalu. Namun, hal ini sepadan dengan investasi pemangku kepentingan dalam cloud dan strategi cloud perusahaan.
Langkah berikutnya
- Jalankan Beban Kerja Oracle Anda yang Paling Menuntut di Azure tanpa Mengorbankan Performa atau Skalabilitas
- Arsitektur solusi menggunakan Azure NetApp Files - Oracle
- Merancang dan mengimplementasikan database Oracle di Azure
- Alat Estimasi untuk Penyusunan Ukuran Beban Kerja Oracle ke Azure IaaS VM
- Arsitektur referensi untuk Oracle Database Enterprise Edition di Azure
- Memahami grup volume aplikasi Azure NetApp Files untuk SAP Hana