Pencadangan otomatis untuk database Hyperscale
Berlaku untuk:![]() Azure SQL Database
Azure SQL Database
Artikel ini menjelaskan fitur pencadangan otomatis dengan database Hyperscale di Azure SQL Database.
Database Hyperscale menggunakan arsitektur unik dengan penyimpanan yang sangat dapat diskalakan dan tingkat performa komputasi. Cadangan Hyperscale berbasis rekam jepret dan hampir seketika. Pencadangan log disimpan dalam penyimpanan Azure jangka panjang untuk periode retensi cadangan.
Arsitektur Hyperscale tidak memerlukan pencadangan penuh, diferensial, atau log. Dengan demikian, frekuensi pencadangan, biaya penyimpanan, penjadwalan, redundansi penyimpanan, dan kemampuan pemulihan berbeda dari database lain di Azure SQL Database.
Performa pencadangan dan pemulihan
Pemisahan penyimpanan dan komputasi memungkinkan Hyperscale untuk mendorong operasi pencadangan dan pemulihan ke lapisan penyimpanan untuk menghilangkan konsumsi sumber daya pada replika komputasi. Pencadangan database tidak memengaruhi performa replika komputasi primer atau sekunder.
Operasi pencadangan dan pemulihan untuk database Hyperscale cepat terlepas dari ukuran data, karena menggunakan rekam jepret penyimpanan. Pencadangan hampir seketika.
Anda dapat memulihkan database ke titik waktu mana pun dalam periode retensi cadangannya dengan:
- Mengembalikan ke rekam jepret file yang berlaku.
- Menerapkan log transaksi untuk membuat database yang dipulihkan konsisten secara transaksional.
Dengan demikian, pemulihan bukan operasi ukuran data yang tetap sama. Pemulihan database Hyperscale dalam wilayah Azure yang sama selesai dalam hitungan menit, bukan jam atau hari, bahkan untuk database multi-terabyte.
Mengubah redundansi penyimpanan saat mengeluarkan pemulihan dapat mengakibatkan waktu pemulihan yang lebih lama karena pemulihan adalah ukuran data, dan karenanya waktu sebanding dengan ukuran database.
Membuat database baru dengan memulihkan cadangan yang ada atau menyalin database, juga memanfaatkan pemisahan komputasi dan penyimpanan di Hyperscale. Anda dapat membuat salinan untuk tujuan pengembangan atau pengujian, bahkan database multi-terabyte, dalam hitungan menit dalam wilayah yang sama saat Anda menggunakan jenis penyimpanan yang sama.
Retensi Pencadangan
Retensi cadangan jangka pendek default untuk database Hyperscale adalah 7 hari.
Retensi cadangan jangka pendek dalam rentang 1 hingga 35 hari dan kemampuan retensi cadangan jangka panjang (LTR) untuk database Hyperscale umumnya tersedia, per September 2023. Untuk informasi selengkapnya, lihat Retensi jangka panjang - Azure SQL Database dan Azure SQL Managed Instance.
Penjadwalan pencadangan
Tidak ada cadangan log transaksional yang lengkap, berbeda, dan tradisional untuk database Hyperscale. Sebagai gantinya, snapshot penyimpanan reguler dari file data diambil.
Log transaksi yang dihasilkan dipertahankan apa adanya untuk periode retensi yang dikonfigurasi. Pada waktu pemulihan, rekaman log transaksi yang relevan diterapkan ke rekam jepret penyimpanan yang dipulihkan. Hasilnya adalah database yang konsisten secara transaksional tanpa kehilangan data pada titik waktu yang ditentukan dalam periode retensi.
Memantau konsumsi penyimpanan cadangan
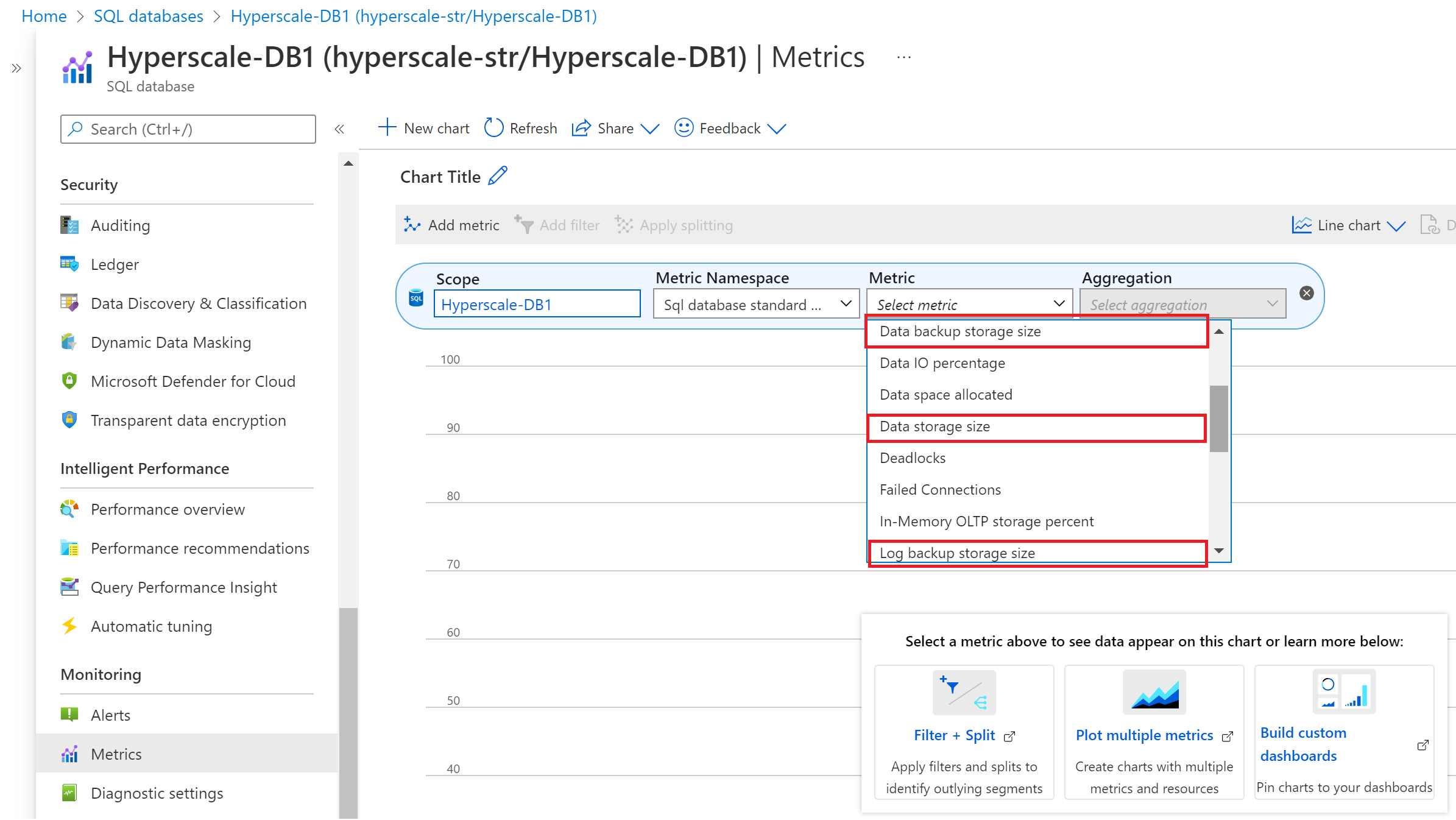
Di Hyperscale, metrik Azure Monitor melaporkan informasi konsumsi berikut:
- Ukuran penyimpanan cadangan data (ukuran cadangan rekam jepret)
- Ukuran penyimpanan data (ukuran database yang dialokasikan)
- Ukuran penyimpanan cadangan log (ukuran pencadangan log transaksi)
Untuk melihat metrik pencadangan dan penyimpanan data di portal Azure, ikuti langkah-langkah berikut:
- Buka database Hyperscale yang ingin Anda pantau metrik pencadangan dan penyimpanan datanya.
- Di bagian Pemantauan , pilih halaman Metrik .
- Dari daftar dropdown Metrik, pilih penyimpanan cadangan data, Ukuran penyimpanan data, dan Metrik penyimpanan cadangan log dengan aturan agregasi yang sesuai.
Mengurangi penggunaan penyimpanan cadangan
Konsumsi penyimpanan cadangan untuk database Hyperscale tergantung pada periode retensi, pilihan wilayah, redundansi penyimpanan cadangan, dan jenis beban kerja. Pertimbangkan beberapa teknik penyetelan berikut untuk mengurangi penggunaan penyimpanan cadangan Anda untuk database Hyperscale:
- Kurangi periode retensi cadangan hingga minimum untuk kebutuhan Anda.
- Hindari melakukan operasi tulis besar, seperti pemeliharaan indeks, lebih sering daripada yang Anda butuhkan. Untuk rekomendasi pemeliharaan indeks, lihat Mengoptimalkan pemeliharaan indeks untuk meningkatkan performa kueri dan mengurangi penggunaan sumber daya.
- Untuk operasi pemuatan data yang besar, pertimbangkan untuk menggunakan pemadatan data jika perlu.
- Gunakan database
tempdbsebagai ganti tabel permanen dalam logika aplikasi Anda untuk menyimpan hasil sementara dan/atau data sementara. - Gunakan penyimpanan cadangan redundan secara lokal atau zona-redundan saat kemampuan pemulihan geografis tidak perlu (misalnya, lingkungan dev/test).
Biaya penyimpanan cadangan
Biaya penyimpanan cadangan Hyperscale bergantung pada pilihan wilayah dan redundansi penyimpanan cadangan. Biaya penyimpanan cadangan Hyperscale juga tergantung pada jenis beban kerja.
Beban kerja yang melakukan banyak penulisan lebih cenderung sering mengubah halaman data, yang menghasilkan snapshot penyimpanan yang lebih besar. Beban kerja tersebut juga menghasilkan lebih banyak log transaksi, berkontribusi pada biaya pencadangan keseluruhan. Penyimpanan cadangan dikenakan biaya berdasarkan gigabyte yang digunakan per bulan. Untuk detail harga, lihat halaman harga Azure SQL Database.
Untuk Hyperscale, penyimpanan cadangan yang dapat ditagih dihitung sebagai berikut:
Total billable backup storage size = (data backup storage size + log backup storage size)
Ukuran penyimpanan data tidak disertakan dalam cadangan yang dapat ditagih karena sudah ditagih sebagai penyimpanan database yang dialokasikan.
Database Hyperscale yang dihapus menimbulkan biaya cadangan untuk mendukung pemulihan ke titik waktu sebelum penghapusan. Untuk database Hyperscale yang dihapus, penyimpanan cadangan yang dapat ditagih dihitung sebagai berikut:
Total billable backup storage size for deleted Hyperscale database = (data storage size + data backup size + log backup storage size) * (remaining backup retention period after deletion / configured backup retention period)
Ukuran penyimpanan data disertakan dalam rumus karena penyimpanan database yang dialokasikan tidak ditagih secara terpisah untuk database yang dihapus. Untuk database yang dihapus, data disimpan setelah penghapusan untuk mengaktifkan pemulihan selama periode retensi cadangan yang dikonfigurasi.
Penyimpanan cadangan yang dapat ditagih untuk database yang dihapus berkurang secara bertahap dari waktu ke waktu setelah dihapus. Ini menjadi nol ketika cadangan tidak lagi dipertahankan, dan kemudian pemulihan tidak lagi dimungkinkan. Jika ini adalah penghapusan permanen dan Anda tidak lagi memerlukan cadangan, Anda dapat mengoptimalkan biaya dengan mengurangi retensi sebelum menghapus database.
Memantau biaya pencadangan
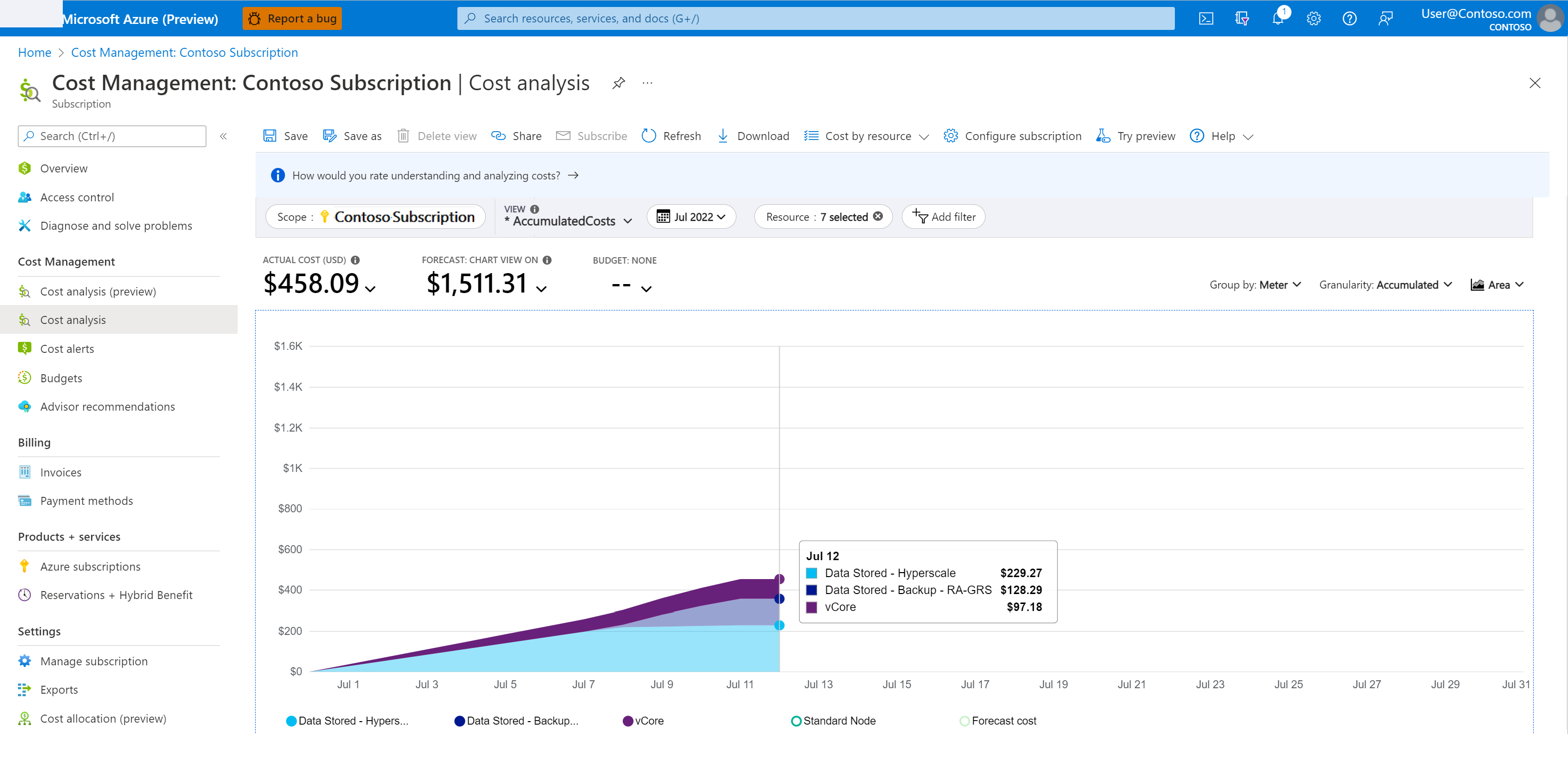
Untuk memahami biaya penyimpanan cadangan:
Di portal Azure, buka Cost Management + Billing.
Pilih Azure Cost Management>Analisis biaya.
Untuk Cakupan, pilih langganan yang diinginkan.
Filter untuk periode waktu dan layanan yang Anda minati dengan mengikuti langkah-langkah berikut:
- Tambahkan filter untuk Nama layanan.
- Pilih sql-database dari daftar dropdown.
- Tambahkan filter lain untuk Meter.
- Untuk memantau biaya pencadangan untuk pemulihan point-in-time, pilih Data Disimpan - Cadangan - RA dari daftar dropdown.
Cuplikan layar berikut menunjukkan contoh analisis biaya.
Redundansi penyimpanan data dan cadangan
Hyperscale mendukung redundansi penyimpanan yang dapat dikonfigurasi. Saat membuat database Hyperscale, Anda dapat memilih jenis penyimpanan pilihan Anda: penyimpanan geo-zona redundan akses baca (RA-GZRS), penyimpanan geo-redundan akses baca (RA-GRS), penyimpanan redundan zona (ZRS), atau penyimpanan redundan lokal (LRS).
- Penyimpanan geo-zona-redundan: Menyalin cadangan Anda secara sinkron di tiga zona ketersediaan Azure di wilayah utama. mirip dengan penyimpanan zona redundan (ZRS). Selain itu, ini menyalin data Anda secara asinkron ke satu lokasi fisik di wilayah sekunder yang dipasangkan . Saat ini hanya tersedia di wilayah tertentu.
Untuk informasi selengkapnya tentang bagaimana cadangan direplikasi untuk jenis penyimpanan lainnya, lihat redundansi penyimpanan cadangan.
Karena Hyperscale menggunakan rekam jepret penyimpanan untuk cadangan, data dan cadangan berbagi akun penyimpanan yang sama. Akibatnya, redundansi penyimpanan cadangan yang dipilih berlaku untuk data dan cadangan.
Catatan
Pertimbangkan redundansi penyimpanan cadangan dengan hati-hati saat Anda membuat database Hyperscale, karena Anda hanya dapat mengaturnya selama pembuatan database. Anda tidak dapat mengubah pengaturan ini setelah sumber daya diprovisikan.
Gunakan replikasi geografis aktif untuk memperbarui pengaturan redundansi penyimpanan cadangan untuk database Hyperscale yang ada dengan waktu henti minimum. Atau, Anda dapat menggunakan salinan database.
Peringatan
- Pemulihan geografis dinonaktifkan segera setelah database diperbarui untuk menggunakan penyimpanan redundan secara lokal atau zona-redundan.
- Penyimpanan zona-redundan saat ini hanya tersedia di wilayah tertentu.
- Penyimpanan geo-zona-redundan saat ini hanya tersedia di wilayah tertentu.
Memulihkan database Hyperscale ke wilayah lain
Anda mungkin perlu memulihkan database Hyperscale Anda ke wilayah yang berbeda dari wilayah saat ini. Alasan umum termasuk operasi atau latihan pemulihan bencana, atau relokasi. Metode utama adalah melakukan pemulihan geografis database. Anda menggunakan langkah yang sama dengan yang akan Anda gunakan untuk memulihkan database lain di Azure SQL Database ke wilayah lain:
- Buat server di wilayah target jika Anda belum memiliki server yang sesuai di sana. Server ini harus dimiliki oleh langganan yang sama dengan server asli (sumber).
- Ikuti instruksi dalam topik di halaman pemulihan geo tentang memulihkan database di Azure SQL Database dari pencadangan otomatis.
Catatan
Karena sumber dan target berada di wilayah terpisah, database tidak dapat berbagi penyimpanan rekam jepret dengan database sumber seperti yang dilakukan dalam pemulihan non-geo. Pemulihan non-geo selesai dengan cepat terlepas dari ukuran database.
Pemulihan geografis database Hyperscale adalah operasi ukuran data, bahkan jika target berada di wilayah yang dipasangkan dari penyimpanan yang direplikasi secara geografis. Oleh karena itu, pemulihan geografis akan memakan waktu yang jauh lebih lama dibandingkan dengan pemulihan titik waktu di wilayah yang sama.
Jika target berada di wilayah berpasangan, transfer data akan berada dalam suatu wilayah. Transfer tersebut akan jauh lebih cepat daripada transfer data lintas wilayah. Tetapi itu masih akan menjadi operasi ukuran data.
Jika mau, Anda bisa menyalin database ke wilayah lain. Gunakan metode ini jika pemulihan geografis tidak tersedia karena tidak didukung dengan jenis redundansi penyimpanan yang dipilih. Untuk detailnya, lihat Salinan database untuk Hyperscale.
Konten terkait
Pencadangan database adalah bagian penting dari setiap kelangsungan bisnis dan strategi pemulihan bencana karena membantu melindungi data Anda dari kerusakan atau penghapusan yang tidak disengaja.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk