Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Berlaku untuk: ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Halaman ini menyediakan informasi tentang masalah kinerja Azure SQL Database dan Azure SQL Managed Instance yang terdeteksi melalui log sumber daya Intelligent Insights. Metrik dan log sumber daya dapat di-streaming ke log Azure Monitor, Azure Event Hubs, Azure Storage, atau solusi pihak ketiga untuk kemampuan peringatan dan pelaporan DevOps kustom.
Catatan
Untuk panduan pemecahan masalah performa cepat menggunakan Intelligent Insights, lihat diagram alur Pemecahan masalah yang direkomendasikan dalam dokumen ini.
Intelligent insights adalah fitur pratinjau, dan tidak tersedia di wilayah berikut: Eropa Barat, Eropa Utara, US Barat 1 dan US Timur 1.
Pola performa database yang dapat dideteksi
Intelligent Insights otomatis mendeteksi masalah performa berdasarkan waktu tunggu eksekusi kueri, kesalahan, atau waktu habis. Output Intelligent Insights mendeteksi pola performa ke log sumber daya. Pola performa yang dapat dideteksi diringkas dalam tabel di bawah ini.
| Pola performa yang dapat dideteksi | Azure SQL Database | Instans Terkelola Azure SQL |
|---|---|---|
| Mencapai batas sumber daya | Konsumsi sumber daya yang tersedia, utas pekerja database, atau sesi login database yang tersedia pada langganan yang dipantau telah mencapai batas sumber dayanya. Hal ini memengaruhi performa. | Konsumsi sumber daya CPU mencapai batas sumber dayanya. Ini memengaruhi performa database. |
| Peningkatan beban kerja | Peningkatan beban kerja atau akumulasi beban kerja berkelanjutan pada database terdeteksi. Hal ini memengaruhi performa. | Peningkatan beban kerja telah terdeteksi. Ini memengaruhi performa database. |
| Tekanan memori | Pekerja yang meminta peruntukan memori harus menunggu alokasi memori untuk jumlah waktu yang signifikan secara statistik, atau terjadi peningkatan akumulasi pekerja yang meminta peruntukan memori. Hal ini memengaruhi performa. | Pekerja yang telah meminta peruntukan memori sedang menunggu alokasi memori untuk jumlah waktu yang signifikan secara statistik. Ini memengaruhi performa database. |
| Penguncian | Penguncian database yang berlebihan terdeteksi memengaruhi performa. | Penguncian database yang berlebihan terdeteksi memengaruhi performa database. |
| Peningkatan MAXDOP | Tingkat maksimum opsi paralelisme (MAXDOP) berubah menjadi memengaruhi efisiensi eksekusi kueri. Hal ini memengaruhi performa. | Tingkat maksimum opsi paralelisme (MAXDOP) berubah menjadi memengaruhi efisiensi eksekusi kueri. Hal ini memengaruhi performa. |
| Ketidaksesuaian pagelatch | Beberapa utas secara bersamaan mencoba mengakses halaman buffer data dalam memori yang sama sehingga mengakibatkan peningkatan waktu tunggu dan menyebabkan ketidaksesuaian pagelatch. Hal ini memengaruhi performa. | Beberapa utas secara bersamaan mencoba mengakses halaman buffer data dalam memori yang sama sehingga mengakibatkan peningkatan waktu tunggu dan menyebabkan ketidaksesuaian pagelatch. Ini memengaruhi performa database. |
| Indeks Hilang | Indeks hilang terdeteksi memengaruhi performa. | Indeks hilang terdeteksi memengaruhi performa database. |
| Kueri Baru | Kueri baru terdeteksi memengaruhi performa keseluruhan. | Kueri baru terdeteksi memengaruhi performa database keseluruhan. |
| Statistik Tunggu Meningkat | Peningkatan waktu tunggu database terdeteksi memengaruhi performa. | Peningkatan waktu tunggu database terdeteksi memengaruhi performa database. |
| Ketidaksesuaian TempDB | Beberapa utas mencoba mengakses sumber daya yang sama tempdb yang menyebabkan hambatan. Hal ini memengaruhi performa. |
Beberapa utas mencoba mengakses sumber daya yang sama tempdb yang menyebabkan hambatan. Ini memengaruhi performa database. |
| Kekurangan DTU kumpulan elastis | Kurangnya eDTU yang tersedia di kumpulan elastis memengaruhi performa. | Tidak tersedia untuk Azure SQL Managed Instance karena menggunakan model vCore. |
| Regresi Rencana | Rencana baru, atau perubahan beban kerja dari rencana yang ada terdeteksi. Hal ini memengaruhi performa. | Rencana baru, atau perubahan beban kerja dari rencana yang ada terdeteksi. Ini memengaruhi performa database. |
| Perubahan nilai konfigurasi yang dicakup database | Perubahan konfigurasi pada database terdeteksi memengaruhi performa database. | Perubahan konfigurasi pada database terdeteksi memengaruhi performa database. |
| Klien lambat | Klien aplikasi lambat tidak dapat mengonsumsi output dari database dengan cukup cepat. Hal ini memengaruhi performa. | Klien aplikasi lambat tidak dapat mengonsumsi output dari database dengan cukup cepat. Ini memengaruhi performa database. |
| Penurunan tingkat harga | Aksi penurunan tingkat harga mengurangi sumber daya yang tersedia. Hal ini memengaruhi performa. | Aksi penurunan tingkat harga mengurangi sumber daya yang tersedia. Ini memengaruhi performa database. |
Tip
Agar terus mengoptimalkan performa database, aktifkan penyetelan otomatis. Fitur kecerdasan bawaan ini terus memantau database Anda, menyetel indeks secara otomatis, dan menerapkan koreksi rencana eksekusi kueri.
Bagian berikut menjelaskan pola kinerja yang dapat dideteksi secara lebih rinci.
Mencapai batas sumber daya
Apa yang terjadi
Pola performa yang dapat dideteksi ini menggabungkan masalah performa yang terkait dengan mencapai batas sumber daya yang tersedia, batas pekerja, dan batas sesi. Setelah masalah kinerja ini terdeteksi, bidang deskripsi log diagnostik menunjukkan apakah masalah kinerja terkait dengan batas sumber daya, pekerja, atau sesi.
Sumber daya pada Azure SQL Database biasanya disebut sumber daya DTU atau vCore, dan sumber daya pada Azure SQL Managed Instance disebut sebagai sumber daya vCore. Pola pencapaian batas sumber daya dikenali ketika penurunan kinerja kueri yang terdeteksi disebabkan oleh tercapainya salah satu batas sumber daya yang diukur.
Sumber daya batas sesi menunjukkan jumlah masuk bersamaan yang tersedia ke database. Pola performa ini dikenali ketika aplikasi yang terhubung ke database telah mencapai jumlah masuk bersamaan yang tersedia ke database. Jika aplikasi mencoba menggunakan lebih banyak sesi daripada yang tersedia di database, performa kueri akan terpengaruh.
Mencapai batas pekerja adalah kasus khusus pencapaian batas sumber daya karena pekerja yang tersedia tidak dihitung dalam penggunaan DTU atau vCore. Mencapai batas pekerja pada database dapat menyebabkan munculnya waktu tunggu khusus sumber daya, yang mengakibatkan penurunan kinerja kueri.
Memecahkan masalah batas sumber daya
Log diagnostik menghasilkan hash kueri dari kueri yang memengaruhi performa dan persentase konsumsi sumber daya. Anda bisa menggunakan informasi ini sebagai titik awal untuk mengoptimalkan beban kerja database Anda. Secara khusus, Anda dapat mengoptimalkan kueri yang memengaruhi penurunan kinerja dengan menambahkan indeks. Atau Anda dapat mengoptimalkan aplikasi dengan distribusi beban kerja yang lebih merata. Jika Anda tidak dapat mengurangi beban kerja atau mengoptimalkannya, pertimbangkan untuk menaikkan tingkat harga langganan database untuk meningkatkan jumlah sumber daya yang tersedia.
Jika batas sesi yang tersedia telah tercapai, Anda dapat mengoptimalkan aplikasi Anda dengan mengurangi jumlah masuk yang dibuat ke database. Jika Anda tidak dapat mengurangi jumlah masuk dari aplikasi Anda ke database, pertimbangkan untuk menaikkan tingkat harga langganan database Anda. Anda juga bisa memisahkan dan memindahkan database ke banyak database untuk distribusi beban kerja yang lebih seimbang.
Untuk saran selengkapnya tentang menyelesaikan batas sesi, lihat Cara mengatasi batas masuk maksimum. Lihat Manajemen sumber daya di Azure SQL Database untuk informasi tentang batasan di tingkat server dan langganan.
Peningkatan beban kerja
Apa yang terjadi
Pola performa ini mengidentifikasi masalah yang disebabkan oleh peningkatan beban kerja atau, dalam bentuk yang lebih parah, tumpukan beban kerja.
Deteksi ini dilakukan melalui kombinasi beberapa metrik. Metrik dasar yang diukur mendeteksi peningkatan beban kerja dibandingkan dengan garis besar beban kerja sebelumnya. Bentuk deteksi lainnya didasarkan pada pengukuran peningkatan besar pada utas pekerja aktif yang cukup besar untuk memengaruhi performa kueri.
Dalam bentuk yang lebih parah, beban kerja mungkin terus menumpuk karena ketidakmampuan database untuk menangani beban kerja. Hasilnya adalah ukuran beban kerja yang terus bertambah, yaitu kondisi tumpukan beban kerja. Karena kondisi ini, waktu beban kerja menunggu eksekusi terus meningkat. Kondisi ini mewakili salah satu masalah performa database yang paling parah. Masalah ini terdeteksi melalui pemantauan peningkatan jumlah utas pekerja yang dibatalkan.
Memecahkan masalah pertumbuhan beban kerja
Log diagnostik menghasilkan jumlah kueri yang eksekusinya telah meningkat dan hash kueri dengan kontribusi terbesar terhadap peningkatan beban kerja. Anda bisa menggunakan informasi ini sebagai titik awal untuk mengoptimalkan beban kerja. Kueri yang diidentifikasi sebagai kontributor terbesar terhadap peningkatan beban kerja sangat berguna sebagai titik awal Anda.
Anda dapat mempertimbangkan untuk mendistribusikan beban kerja secara lebih merata ke database. Pertimbangkan untuk mengoptimalkan kueri yang memengaruhi performa dengan menambahkan indeks. Anda juga dapat mendistribusikan beban kerja di antara beberapa database. Jika solusi ini tidak memungkinkan, pertimbangkan untuk menaikkan tingkat harga langganan database Anda untuk meningkatkan jumlah sumber daya yang tersedia.
Tekanan memori
Apa yang terjadi
Pola kinerja ini menunjukkan degradasi dalam performa database saat ini yang disebabkan oleh tekanan memori, atau dalam bentuk yang lebih parah, kondisi tumpukan memori, dibandingkan dengan garis dasar performa tujuh hari terakhir.
Tekanan memori menunjukkan kondisi performa di mana ada sejumlah besar utas pekerja yang meminta peruntukan memori. Volume tinggi menyebabkan kondisi pemanfaatan memori tinggi di mana database tidak dapat mengalokasikan memori secara efisien kepada semua pekerja yang memintanya. Salah satu alasan paling umum untuk masalah ini adalah terkait dengan jumlah memori yang tersedia untuk database di satu sisi. Di sisi lain, peningkatan beban kerja menyebabkan kenaikan utas pekerja dan tekanan memori.
Bentuk tekanan memori yang lebih parah adalah kondisi tumpukan memori. Kondisi ini menunjukkan bahwa jumlah utas pekerja yang meminta peruntukan memori lebih tinggi daripada memori yang dilepaskan kueri. Jumlah utas pekerja yang meminta peruntukan memori juga mungkin terus meningkat (menumpuk) karena mesin database tidak dapat mengalokasikan memori dengan cukup efisien untuk memenuhi permintaan. Kondisi memori yang menumpuk ini mewakili salah satu masalah performa database yang paling parah.
Memecahkan masalah tekanan memori
Log diagnostik menghasilkan detail penyimpanan objek memori dengan petugas (yaitu, utas pekerja) yang ditandai sebagai alasan tertinggi untuk penggunaan memori tinggi dan stempel waktu yang relevan. Anda dapat menggunakan informasi ini sebagai dasar pemecahan masalah.
Anda dapat mengoptimalkan atau menghapus kueri yang terkait dengan petugas dengan penggunaan memori tertinggi. Anda juga bisa memastikan bahwa Anda tidak meminta data yang tidak Anda rencanakan untuk digunakan. Praktik yang baik adalah selalu menggunakan klausul WHERE dalam kueri Anda. Selain itu, kami sarankan Anda membuat indeks non-kluster untuk mencari data alih-alih memindainya.
Anda juga dapat mengurangi beban kerja dengan mengoptimalkan atau mendistribusikannya ke beberapa database. Atau Anda dapat mendistribusikan beban kerja di antara beberapa database. Jika solusi ini tidak memungkinkan, pertimbangkan untuk menaikkan tingkat harga langganan database Anda untuk meningkatkan jumlah sumber daya yang tersedia ke database.
Untuk saran pemecahan masalah tambahan, lihat Meditasi peruntukan memori: Pengguna memori SQL Server misterius dengan banyak nama. Untuk informasi lebih lanjut tentang kesalahan kehabisan memori dalam Azure SQL Database, lihat Memecahkan masalah kesalahan kehabisan memori dengan Azure SQL Database.
Penguncian
Apa yang terjadi
Pola performa ini menunjukkan degradasi dalam performa database saat ini di mana penguncian database yang berlebihan terdeteksi dibandingkan dengan garis dasar kinerja tujuh hari terakhir.
Dalam RDBMS modern, penguncian sangat penting untuk menerapkan sistem multiutas di mana kinerja dimaksimalkan dengan menjalankan beberapa pekerja simultan dan transaksi database paralel jika memungkinkan. Penguncian dalam konteks ini mengacu pada mekanisme akses bawaan di mana hanya satu transaksi yang dapat secara eksklusif mengakses baris, halaman, tabel, dan file yang diperlukan dan tidak bersaing dengan transaksi lain untuk sumber daya. Ketika transaksi yang mengunci sumber daya untuk digunakan dilakukan dengan mereka, penguncian pada sumber daya tersebut dirilis, sehingga transaksi lain dapat mengakses sumber daya yang diperlukan. Untuk informasi selengkapnya tentang penguncian, lihat Mengunci di mesin database.
Jika transaksi yang dijalankan oleh mesin SQL menunggu jangka waktu yang lama untuk mengakses sumber daya yang dikunci untuk digunakan, waktu tunggu ini menyebabkan performa eksekusi beban kerja lambat.
Memecahkan masalah penguncian dan pemblokiran
Log diagnostik menghasilkan detail penguncian yang dapat Anda gunakan sebagai dasar pemecahan masalah. Anda dapat menganalisis laporan kueri pemblokiran, yaitu, kueri yang mengenali penurunan kinerja penguncian, dan menghapusnya. Dalam beberapa kasus, Anda mungkin berhasil mengoptimalkan kueri pemblokiran.
Cara paling sederhana dan paling aman untuk mengurangi masalah ini adalah dengan menjaga transaksi tetap pendek dan mengurangi jejak kunci kueri yang paling mahal. Anda dapat memecah sejumlah besar operasi menjadi operasi yang lebih kecil. Praktik yang baik adalah mengurangi jejak penguncian kueri dengan membuat kueri seefisien mungkin. Mengurangi pemindaian besar karena meningkatkan risiko kebuntuan dan berdampak buruk pada performa database secara keseluruhan. Untuk kueri teridentifikasi yang menyebabkan penguncian, Anda bisa membuat indeks baru atau menambahkan kolom ke indeks yang sudah ada agar tabel tidak dipindai.
Untuk saran lebih lanjut, lihat:
- Memahami dan mengatasi masalah pemblokiran Azure SQL Database
- Cara mengatasi masalah pemblokiran yang disebabkan oleh eskalasi penguncian di SQL Server
Peningkatan MAXDOP
Apa yang terjadi
Pola performa yang dapat dideteksi ini menunjukkan kondisi di mana rencana eksekusi kueri yang dipilih diparalelkan lebih dari yang seharusnya. Pengoptimal kueri dapat meningkatkan performa beban kerja dengan menjalankan kueri secara paralel untuk mempercepat banyak hal jika memungkinkan. Dalam beberapa kasus, pekerja paralel yang memproses kueri menghabiskan lebih banyak waktu menunggu satu sama lain untuk menyinkronkan dan menggabungkan hasil dibandingkan dengan mengeksekusi kueri yang sama dengan lebih sedikit pekerja paralel, atau bahkan dalam beberapa kasus dibandingkan dengan utas pekerja tunggal.
Sistem ahli menganalisis performa database saat ini dibandingkan dengan periode garis besar. Ini menentukan apakah kueri yang sudah berjalan beroperasi lebih lambat dari sebelumnya, mengingat rencana eksekusi kueri lebih paralel daripada yang seharusnya.
Opsi konfigurasi server MAXDOP digunakan untuk mengontrol berapa banyak inti CPU yang dapat digunakan untuk menjalankan kueri yang sama secara paralel.
Memecahkan masalah paralelisme
Log diagnostik menghasilkan hash kueri terkait dengan kueri di mana durasi eksekusi meningkat karena mereka diparalelkan lebih dari yang seharusnya. Log juga menghasilkan waktu tunggu CXP. Waktu ini mewakili satu utas penyelenggara/koordinator (utas 0) yang sedang menunggu semua utas lain selesai sebelum menggabungkan hasil dan bergerak maju. Selain itu, log diagnostik mengeluarkan waktu tunggu yang ditunggu oleh kueri berperforma buruk dalam eksekusi secara keseluruhan. Anda dapat menggunakan informasi ini sebagai dasar pemecahan masalah.
Pertama, optimalkan atau sederhanakan kueri yang kompleks. Praktik yang baik adalah memecah tugas batch panjang menjadi lebih kecil. Selain itu, pastikan Anda membuat indeks untuk mendukung kueri. Anda juga dapat secara manual memberlakukan tingkat paralelisme maksimum (MAXDOP) untuk kueri yang performanya ditandai buruk. Untuk mengonfigurasi operasi ini menggunakan T-SQL, lihat Mengonfigurasi opsi konfigurasi server MAXDOP.
Mengatur opsi konfigurasi server MAXDOP ke nol (0) sebagai nilai default menunjukkan bahwa database dapat menggunakan semua inti CPU yang tersedia untuk memparalelkan utas dalam menjalankan satu kueri. Mengatur MAXDOP ke satu (1) menunjukkan bahwa hanya satu inti yang dapat digunakan untuk satu eksekusi kueri. Dalam istilah sederhana, ini artinya paralelisme dimatikan. Bergantung pada basis kasus per kasus, inti yang tersedia ke database, dan informasi log diagnostik, Anda dapat menyetel opsi MAXDOP ke jumlah inti yang digunakan untuk eksekusi kueri paralel yang mungkin mengatasi masalah dalam kasus Anda.
Ketidaksesuaian pagelatch
Apa yang terjadi
Pola performa ini menunjukkan penurunan kinerja beban kerja database saat ini karena ketidaksesuaian pagelatch dibandingkan dengan garis besar beban kerja tujuh hari terakhir.
Latch adalah mekanisme sinkronisasi ringan yang digunakan untuk mengaktifkan multithreading. Latch menjamin konsistensi struktur dalam memori yang mencakup indeks, halaman data, dan struktur internal lainnya.
Ada banyak jenis latch yang tersedia. Untuk tujuan kesederhanaan, buffer latch digunakan untuk melindungi halaman dalam memori di kumpulan buffer. Latch IO digunakan untuk melindungi halaman yang belum dimuat ke dalam kumpulan buffer. Setiap kali data ditulis atau dibaca dari halaman di kumpulan buffer, utas pekerja perlu memperoleh buffer latch untuk halaman terlebih dahulu. Setiap kali utas pekerja mencoba mengakses halaman yang belum tersedia di kumpulan buffer dalam memori, permintaan IO dibuat untuk memuat informasi yang diperlukan dari penyimpanan. Rentetan peristiwa ini menunjukkan bentuk penurunan kinerja yang lebih parah.
Ketidaksesuaian kait halaman terjadi ketika beberapa utas secara bersamaan berusaha memperoleh latch pada struktur dalam memori yang sama, yang memperkenalkan peningkatan waktu tunggu untuk meminta eksekusi. Dalam kasus ketidaksesuaian pagelatch IO, waktu tunggu untuk mengakses data dari penyimpanan bahkan lebih besar. Ini dapat memengaruhi performa beban kerja secara signifikan. Ketidaksesuaian pagelatch adalah skenario paling umum dari utas yang menunggu satu sama lain dan bersaing untuk sumber daya pada beberapa sistem CPU.
Memecahkan masalah ketidakcocokan pagelatch
Log diagnostik menghasilkan detail ketidaksesuaian pagelatch. Anda dapat menggunakan informasi ini sebagai dasar pemecahan masalah.
Karena pagelatch adalah mekanisme kontrol internal, secara otomatis ia menentukan kapan sebaiknya digunakan. Keputusan aplikasi, termasuk desain skema, dapat memengaruhi perilaku pagelatch karena perilaku deterministik latch.
Salah satu metode untuk menangani ketidaksesuaian latch adalah mengganti kunci indeks sekuens dengan kunci nonsekuens untuk mendistribusikan sisipan secara merata di seluruh rentang indeks. Biasanya, kolom utama dalam indeks mendistribusikan beban kerja secara proporsional. Metode lain yang perlu dipertimbangkan adalah partisi tabel. Membuat skema partisi hash dengan kolom terkomputasi pada tabel berpartisi adalah pendekatan umum untuk mengurangi ketidaksesuaian latch yang berlebihan. Dalam kasus pertikaian IO pagelatch, memperkenalkan indeks membantu mengurangi masalah performa ini.
Untuk informasi selengkapnya, lihat Mendiagnosis dan mengatasi ketidaksesuaian latch di SQL Server (unduhan PDF).
Indeks hilang
Apa yang terjadi
Pola performa ini menunjukkan penurunan kinerja beban kerja database saat ini karena dibandingkan dengan garis besar tujuh hari terakhir karena indeks yang hilang.
Indeks digunakan untuk mempercepat performa kueri. Ini menyediakan akses cepat ke data tabel dengan mengurangi jumlah halaman himpunan data yang perlu dikunjungi atau dipindai.
Kueri spesifik yang menyebabkan penurunan kinerja diidentifikasi melalui deteksi ini yang membuat indeks akan bermanfaat bagi performa.
Memecahkan masalah kueri mahal dengan indeks
Log diagnostik menghasilkan hash kueri yang diidentifikasi memengaruhi performa beban kerja. Anda dapat menyusun indeks untuk kueri ini. Anda juga dapat mengoptimalkan atau menghapus kueri ini jika tidak diperlukan. Praktik kinerja yang baik adalah jangan melakukan kueri data yang tidak Anda gunakan.
Tip
Tahukah Anda bahwa kecerdasan bawaan dapat secara otomatis mengelola indeks berperforma terbaik untuk database Anda?
Untuk pengoptimalan kinerja berkelanjutan, kami sarankan Anda mengaktifkan penyetelan otomatis. Fitur kecerdasan bawaan unik ini terus memantau database dan secara otomatis menyetel dan membuat indeks untuk database.
Kueri baru
Apa yang terjadi
Pola performa ini menunjukkan bahwa kueri baru terdeteksi berperforma buruk dan memengaruhi kinerja beban kerja dibandingkan dengan garis dasar performa tujuh hari.
Menulis kueri berperforma baik kadang-kadang bisa menjadi tugas yang menantang. Untuk informasi selengkapnya tentang menulis kueri, lihat Menulis kueri SQL. Untuk mengoptimalkan kinerja kueri yang sudah ada, lihat Penyetelan kueri.
Memecahkan masalah performa kueri
Log diagnostik menghasilkan informasi hingga dua kueri baru yang paling memakan CPU, termasuk hash kueri mereka. Karena kueri yang terdeteksi memengaruhi performa beban kerja, optimalkan kueri Anda. Praktik yang baik adalah hanya mengambil data yang perlu Anda gunakan. Sebaiknya gunakan kueri dengan WHERE klausa. Sebaiknya Anda juga menyederhanakan kueri yang kompleks dan memecahnya menjadi kueri yang lebih kecil. Praktik bagus lainnya adalah memecah kueri batch besar menjadi kueri batch yang lebih kecil. Memperkenalkan indeks untuk kueri baru biasanya merupakan praktik yang baik untuk mengurangi masalah performa ini.
Di Azure SQL Database, pertimbangkan untuk menggunakan Wawasan Performa Kueri untuk Azure SQL Database.
Statistik tunggu meningkat
Apa yang terjadi
Pola performa yang dapat dideteksi ini menunjukkan penurunan kinerja beban kerja di mana kueri berperforma buruk diidentifikasi dibandingkan dengan garis dasar beban kerja tujuh hari terakhir.
Dalam hal ini, sistem tidak dapat mengklasifikasikan kueri berperforma buruk di bawah kategori performa standar lain yang dapat dideteksi, tetapi mendeteksi statistik tunggu yang bertanggung jawab atas regresi. Oleh karena itu, sistem menganggap mereka sebagai kueri dengan statistik tunggu yang meningkat, di mana statistik yang bertanggung jawab untuk regresi juga terungkap.
Memecahkan masalah statistik tunggu
Log diagnostik menghasilkan informasi tentang peningkatan detail waktu tunggu dan hash kueri dari kueri yang terdampak.
Karena sistem tidak berhasil mengidentifikasi akar penyebab untuk kueri berperforma buruk, informasi diagnostik adalah titik awal yang baik untuk pemecahan masalah secara manual. Anda dapat mengoptimalkan performa kueri ini. Praktik yang baik adalah hanya mengambil data yang perlu Anda gunakan dan menyederhanakan dan memecah kueri kompleks menjadi lebih kecil.
Untuk informasi selengkapnya tentang mengoptimalkan kinerja kueri, lihat Penyetelan kueri.
Ketidaksesuaian tempdb
Apa yang terjadi
Pola performa yang dapat dideteksi ini menunjukkan kondisi performa database di mana hambatan utas yang mencoba mengakses tempdb sumber daya ada. (Kondisi ini tidak terkait dengan IO.) Skenario umum untuk masalah performa ini adalah ratusan kueri bersamaan yang semuanya membuat, menggunakan, lalu menghilangkan tabel kecil tempdb . Sistem mendeteksi bahwa jumlah kueri bersamaan menggunakan tabel yang sama meningkat dengan signifikansi statistik yang tempdb memadai untuk memengaruhi performa database dibandingkan dengan garis besar performa tujuh hari terakhir.
Memecahkan masalah ketidakcocokan tempdb
Log diagnostik menghasilkan tempdb detail pertikaian. Anda dapat menggunakan informasi ini sebagai titik awal untuk pemecahan masalah. Ada dua hal yang dapat Anda kejar untuk meringankan ketidaksesuaian semacam ini dan meningkatkan throughput dari keseluruhan beban kerja: berhenti menggunakan tabel sementara. Atau, menggunakan tabel yang dioptimalkan untuk memori.
Untuk informasi selengkapnya, lihat Pengenalan tabel yang dioptimalkan untuk memori.
Kekurangan DTU kumpulan elastis
Apa yang terjadi
Pola performa ini menunjukkan penurunan performa beban kerja database saat ini dibandingkan dengan garis besar beban kerja tujuh hari terakhir. Hal ini disebabkan oleh kekurangan DTU yang tersedia di kumpulan elastis langganan Anda.
Sumber daya kumpulan elastis Azure digunakan sebagai kumpulan sumber daya tersedia yang dibagikan ke beberapa database untuk tujuan penskalaan. Ketika sumber daya eDTU di kumpulan elastis tidak cukup besar tersedia untuk mendukung semua database di kumpulan, masalah performa kekurangan DTU kolam elastis terdeteksi oleh sistem.
Memecahkan masalah kekurangan DTU kumpulan elastis
Log diagnostik menghasilkan informasi pada kumpulan elastis, mencantumkan database dengan konsumsi DTU teratas, dan menyediakan persentase DTU kumpulan yang digunakan oleh database yang paling banyak memakan waktu.
Karena kondisi performa ini terkait dengan banyaknya database menggunakan kumpulan eDTUs yang sama di kumpulan elastis, langkah-langkah pemecahan masalah berfokus pada database yang memakan DTU teratas. Anda dapat mengurangi beban kerja pada database yang memakan waktu teratas, yang mencakup pengoptimalan kueri yang memakan waktu teratas pada database tersebut. Anda juga bisa memastikan bahwa Anda tidak meminta data yang tidak direncanakan untuk digunakan. Pendekatan lain adalah mengoptimalkan aplikasi dengan menggunakan database yang memakan DTU teratas dan mendistribusikan kembali beban kerja di antara beberapa database.
Jika pengurangan dan pengoptimalan beban kerja saat ini pada database yang memakan DTU teratas Anda tidak dimungkinkan, pertimbangkan untuk menaikkan tingkat harga kumpulan elastis Anda. Peningkatan tersebut mengakibatkan peningkatan DTUs yang tersedia di kumpulan elastis.
Regresi rencana
Apa yang terjadi
Pola performa yang dapat dideteksi ini menunjukkan kondisi di mana database menggunakan rencana eksekusi kueri yang kurang optimal (suboptimal). Rencana suboptimal biasanya meningkatkan eksekusi kueri, yang memperlama waktu tunggu untuk kueri saat ini dan kueri lainnya.
Mesin database menentukan rencana eksekusi kueri dengan biaya paling rendah untuk eksekusi kueri. Ketika jenis kueri dan beban kerja berubah, terkadang rencana yang ada tidak lagi efisien, atau mungkin mesin database tidak membuat penilaian yang baik. Sebagai soal koreksi, rencana eksekusi kueri dapat dipaksakan secara manual.
Pola performa yang dapat dideteksi ini menggabungkan tiga kasus regresi rencana yang berbeda: regresi rencana baru, regresi rencana lama, dan rencana yang ada mengubah beban kerja. Jenis regresi rencana tertentu yang terjadi disediakan di detail properti di dalam log diagnostik.
Kondisi regresi rencana baru mengacu pada keadaan di mana mesin database mulai menjalankan rencana eksekusi kueri baru yang tidak seefisien rencana lama. Kondisi regresi rencana lama mengacu pada keadaan ketika mesin database beralih dari menggunakan paket baru yang lebih efisien ke paket lama, yang tidak seefisien rencana baru. Regresi beban kerja perubahan rencana yang ada mengacu pada keadaan di mana rencana lama dan rencana baru terus bergantian, dengan keseimbangan lebih mengarah ke rencana berperforma buruk.
Untuk informasi selengkapnya tentang regresi paket, lihat Apa itu regresi rencana di SQL Server?
Memecahkan masalah regresi paket
Log diagnostik menghasilkan hash kueri, ID rencana yang baik, ID paket yang buruk, dan ID kueri. Anda dapat menggunakan informasi ini sebagai dasar pemecahan masalah.
Anda dapat menganalisis rencana mana yang berperforma lebih baik untuk kueri spesifik yang dapat diidentifikasi dengan hash kueri yang disediakan. Setelah Anda menentukan rencana mana yang berfungsi lebih baik untuk kueri, Anda dapat memaksanya secara manual.
Untuk informasi selengkapnya, lihat Mempelajari bagaimana SQL Server mencegah regresi rencana.
Tip
Tahukah Anda bahwa fitur kecerdasan bawaan dapat secara otomatis mengelola rencana eksekusi kueri berperforma terbaik untuk database Anda?
Untuk pengoptimalan kinerja berkelanjutan, kami sarankan Anda mengaktifkan penyetelan otomatis. Fitur kecerdasan bawaan ini terus memantau database dan secara otomatis menyetel dan membuat rencana eksekusi kueri dengan performa terbaik untuk database Anda.
Perubahan nilai konfigurasi yang dicakup database
Apa yang terjadi
Pola performa yang dapat dideteksi ini menunjukkan kondisi di mana perubahan konfigurasi yang dicakup database menyebabkan regresi kinerja yang terdeteksi dibandingkan dengan perilaku beban kerja database tujuh hari terakhir. Pola ini menunjukkan bahwa perubahan terbaru yang dilakukan pada konfigurasi yang dicakup database tampaknya tidak bermanfaat bagi performa database Anda.
Perubahan konfigurasi yang dicakup database dapat diatur untuk setiap database individu. Konfigurasi ini digunakan berdasarkan kasus per kasus untuk mengoptimalkan performa database individu Anda. Opsi berikut dapat dikonfigurasi untuk setiap database individu: MAXDOP, LEGACY_CARDINALITY_ESTIMATION, PARAMETER_SNIFFING, QUERY_OPTIMIZER_HOTFIXES, dan CLEAR PROCEDURE_CACHE.
Memecahkan masalah perubahan konfigurasi yang terlingkup database
Log diagnostik menghasilkan perubahan konfigurasi yang dicakup database yang dibuat baru-baru ini yang menyebabkan penurunan kinerja dibandingkan dengan perilaku beban kerja tujuh hari sebelumnya. Anda dapat mengembalikan perubahan konfigurasi ke nilai sebelumnya. Anda juga dapat menyetel nilai demi nilai hingga tingkat performa yang diinginkan tercapai. Anda dapat menyalin nilai konfigurasi yang dicakup database dari database serupa dengan performa memuaskan. Jika Anda tidak dapat memecahkan masalah performa, kembalilah ke nilai default dan cobalah sempurnakan mulai dari garis besar ini.
Untuk informasi selengkapnya tentang mengoptimalkan konfigurasi yang dicakup database dan sintaks T-SQL tentang mengubah konfigurasi, lihat Mengubah konfigurasi yang dicakup database (Transact-SQL).
Klien lambat
Apa yang terjadi
Pola performa yang dapat dideteksi ini menunjukkan kondisi di mana klien yang menggunakan database tidak dapat mengonsumsi output database secepat database mengirimkan hasilnya. Karena database tidak menyimpan hasil kueri yang dieksekusi di buffer, database melambat dan menunggu klien untuk mengonsumsi output kueri yang dikirimkan sebelum melanjutkan. Kondisi ini juga mungkin terkait dengan jaringan yang tidak cukup cepat untuk mengirimkan output database ke klien yang mengonsumsi.
Kondisi ini dihasilkan hanya jika regresi performa terdeteksi dibandingkan dengan perilaku beban kerja database tujuh hari terakhir. Masalah performa ini hanya terdeteksi jika penurunan kinerja yang signifikan secara statistik terjadi dibandingkan dengan perilaku performa sebelumnya.
Memecahkan masalah aplikasi sisi klien
Pola performa yang dapat dideteksi ini menunjukkan kondisi sisi klien. Pemecahan masalah diperlukan di aplikasi sisi klien atau jaringan pihak klien. Log diagnostik menghasilkan hash kueri dan waktu tunggu yang tampaknya paling menunggu bagi klien untuk mengonsumsinya dalam dua jam terakhir. Anda dapat menggunakan informasi ini sebagai dasar pemecahan masalah.
Anda dapat mengoptimalkan performa aplikasi untuk konsumsi kueri ini. Anda juga dapat mempertimbangkan kemungkinan masalah latensi jaringan. Karena masalah penurunan kinerja didasarkan pada perubahan dalam garis besar performa dalam tujuh hari terakhir, carilah tahu apakah perubahan kondisi aplikasi atau jaringan baru-baru ini menyebabkan peristiwa regresi performa ini.
Penurunan tingkat harga
Apa yang terjadi
Pola performa yang dapat dideteksi ini menunjukkan kondisi di mana tingkat harga langganan database Anda diturunkan. Karena pengurangan sumber daya yang tersedia untuk database, sistem mendeteksi penurunan performa database saat ini dibandingkan dengan garis besar tujuh hari terakhir.
Selain itu, mungkin ada kondisi di mana tingkat harga langganan database Anda diturunkan dan kemudian ditingkatkan ke tingkat yang lebih tinggi dalam waktu singkat. Deteksi penurunan kinerja sementara ini dihasilkan di bagian detail log diagnostik sebagai penurunan dan peningkatan tingkat harga.
Memecahkan masalah penurunan tingkat harga
Jika Anda mengurangi tingkat harga, dan Anda puas dengan performanya, tidak ada yang perlu Anda lakukan. Jika Anda mengurangi tingkat harga dan tidak puas dengan performa database, kurangi beban kerja database atau pertimbangkan untuk menaikkan tingkat harga.
Alur pemecahan masalah yang direkomendasikan
Ikuti bagan alur untuk pendekatan yang direkomendasikan dalam memecahkan masalah performa menggunakan Intelligent Insights.
Akses Intelligent Insights melalui portal Microsoft Azure dengan pergi ke Azure SQL Analytics. Cobalah temukan pemberitahuan performa masuk, lalu pilihlah. Identifikasi apa yang terjadi di halaman deteksi. Amati analisis akar penyebab masalah yang disediakan, teks kueri, tren waktu kueri, dan evolusi insiden. Mencoba menyelesaikan masalah dengan menggunakan rekomendasi Intelligent Insights untuk mengurangi masalah performa.
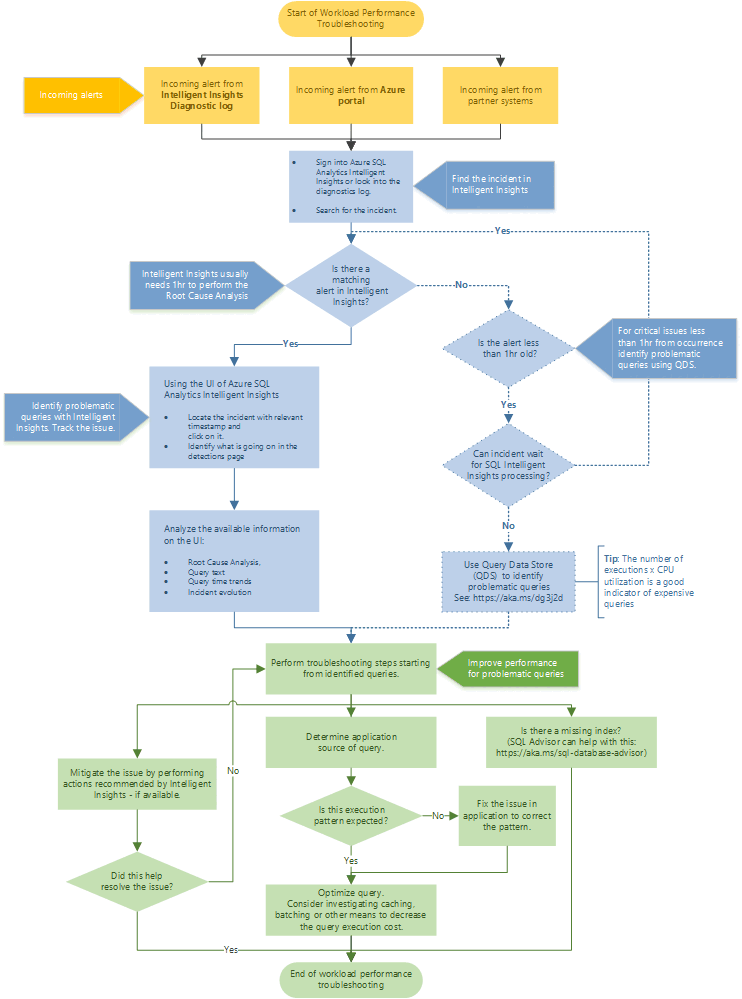
Tip
Pilih bagan alur untuk mengunduh versi PDF.
Intelligent Insights biasanya membutuhkan satu jam waktu untuk melakukan analisis akar penyebab masalah performa. Jika tidak dapat menemukan masalah di Intelligent Insights dan menurut Anda ini sangat penting, gunakan Penyimpanan Kueri untuk mengidentifikasi akar masalah performa secara manual. (Biasanya, masalah ini kurang dari satu jam.) Untuk informasi selengkapnya, lihat Memantau performa menggunakan Penyimpanan Kueri.