Mengidentifikasi bahasa lisan secara otomatis dengan model identifikasi bahasa
Penting
Tenggat waktu untuk memigrasikan konten Azure Video Indexer karena penghentian Azure Media Services telah berlalu. Lihat panduan penghentian untuk informasi selengkapnya.
Azure AI Video Indexer mendukung identifikasi bahasa otomatis (LID), yang merupakan proses mengidentifikasi bahasa lisan secara otomatis dari konten audio. File media ditranskripsikan dalam bahasa yang diidentifikasi dominan.
Lihat daftar bahasa yang didukung oleh Bahasa Pengindeks Video Azure AI dalam bahasa yang didukung.
Pastikan untuk meninjau bagian Panduan dan batasan .
Memilih identifikasi bahasa otomatis pada pengindeksan
Saat mengindeks atau mengindeks ulang video menggunakan API, pilih opsi auto detect di parameter sourceLanguage.
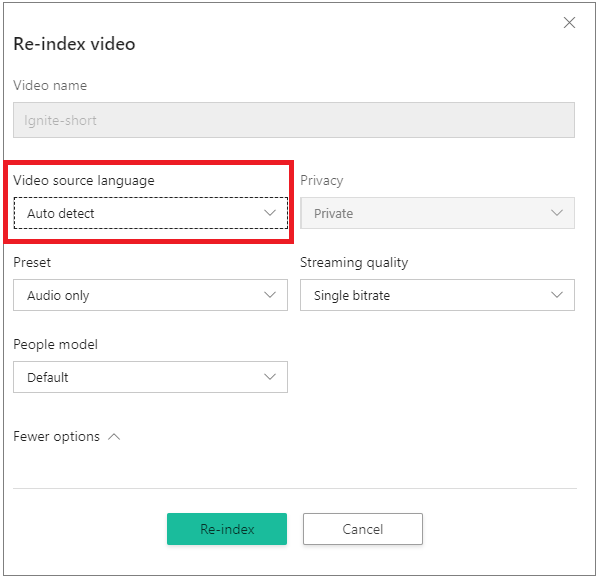
Saat menggunakan portal, buka Video akun Anda di beranda Azure AI Video Indexer dan arahkan mouse ke atas nama video yang ingin Anda indeks ulang. Di sudut kanan bawah, pilih tombol Indeks ulang. Dalam dialog Indeks ulang video, pilih Deteksi otomatis dari kotak menu turun bawah Bahasa sumber video.
Output model
Pengindeks Video Azure AI mentranskripsikan video sesuai dengan bahasa yang paling mungkin jika keyakinan untuk bahasa tersebut adalah > 0.6. Jika bahasa tidak dapat diidentifikasi dengan percaya diri, ia mengasumsikan bahasa lisan adalah bahasa Inggris.
Bahasa dominan model tersedia dalam wawasan JSON sebagai atribut sourceLanguage (di bawah akar/video/wawasan). Skor keyakinan yang sesuai juga tersedia di bawah atribut sourceLanguageConfidence.
"insights": {
"version": "1.0.0.0",
"duration": "0:05:30.902",
"sourceLanguage": "fr-FR",
"language": "fr-FR",
"transcript": [...],
. . .
"sourceLanguageConfidence": 0.8563
}
Pedoman dan batasan
Identifikasi bahasa otomatis (LID) mendukung bahasa-bahasa berikut:
Lihat daftar bahasa yang didukung oleh Bahasa Pengindeks Video Azure AI dalam bahasa yang didukung.
- Jika audio berisi bahasa selain daftar yang didukung, hasilnya tidak terduga.
- Jika Azure AI Video Indexer tidak dapat mengidentifikasi bahasa dengan keyakinan yang cukup tinggi (lebih besar dari 0,6), bahasa fallbacknya adalah bahasa Inggris.
- Saat ini, tidak ada dukungan untuk file dengan audio bahasa campuran. Jika audio berisi bahasa campuran, hasilnya tidak terduga.
- Audio berkualitas rendah dapat memengaruhi hasil model.
- Model membutuhkan setidaknya satu menit ucapan dalam audio.
- Model ini dirancang untuk mengenali ucapan percakapan spontan (bukan perintah suara, nyanyian, dan sebagainya).
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk