Zona pendaratan data
Zona pendaratan data terhubung ke zona pendaratan manajemen data Anda dengan peering jaringan virtual (VNet). Setiap zona pendaratan data dianggap sebagai zona pendaratan yang terkait dengan arsitektur zona pendaratan Azure.
Penting
Sebelum menyediakan zona pendaratan data, pastikan model operasi DevOps dan CI/CD Anda diberlakukan dan zona pendaratan manajemen data disebarkan.
Setiap zona pendaratan data memiliki beberapa lapisan yang memungkinkan kelincahan untuk integrasi data layanan dan produk data yang dikandungnya. Anda dapat menyebarkan zona pendaratan data baru dengan serangkaian layanan standar yang memungkinkan zona pendaratan data mulai menyerap dan menganalisis data.
Langganan Azure Anda yang terkait dengan zona pendaratan data Anda memiliki struktur berikut:
| Lapisan | Wajib | Kelompok Sumber Daya |
|---|---|---|
| Layanan Inti | Ya | |
| Aplikasi data | Opsional |
|
| Visualisasi | Opsional |
Catatan
Aplikasi data menghasilkan satu atau beberapa produk data.
Arsitektur zona pendaratan data
Arsitektur zona pendaratan data mengilustrasikan lapisan, grup sumber daya, dan layanan yang dimuat setiap grup sumber daya. Arsitektur ini juga memberikan gambaran umum semua grup dan peran yang terkait dengan zona pendaratan data Anda, ditambah sejauh mana akses mereka ke sarana kontrol dan data Anda.

Tip
Sebelum Anda menyebarkan zona pendaratan data, pastikan Anda mempertimbangkan jumlah zona pendaratan data awal yang ingin Anda sebarkan.
Gunakan arsitektur ini sebagai titik awal. Unduh file Visio dan ubah agar sesuai dengan persyaratan bisnis dan teknis spesifik Anda saat merencanakan implementasi zona pendaratan data Anda.
Lapisan layanan inti
Lapisan layanan inti mencakup semua layanan yang diperlukan untuk mengaktifkan zona pendaratan data Anda dalam konteks analitik skala cloud. Tabel berikut mencantumkan grup sumber daya yang menyediakan rangkaian standar layanan yang tersedia di setiap zona pendaratan data yang Anda sebarkan.
| Grup Sumber Daya | Wajib | Deskripsi |
|---|---|---|
network-rg |
Ya | Jaringan |
databricks-monitoring-rg |
Opsional | Pemantauan untuk ruang kerja Azure Databricks |
hive-rg |
Opsional | Metastore Apache Hive untuk Azure Databricks |
storage-rg |
Ya | Layanan data lake |
external-data-rg |
Ya | Mengunggah penyimpanan penyerapan |
runtimes-rg |
Ya | Runtime integrasi bersama |
mgmt-rg |
Ya | Agen CI/CD |
metadata-ingestion-rg |
Opsional | Penyerapan agnostik data |
databricks-monitoring-rg |
Opsional | Ruang kerja analitik log untuk ruang kerja databricks di zona pendaratan |
shared-synapse-rg |
Opsional | Azure Synapse Bersama |
shared-databricks-rg |
Opsional | Ruang kerja Azure Databricks bersama |
Jaringan
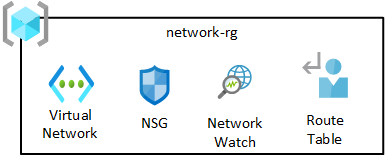
Grup sumber daya jaringan berisi komponen inti, termasuk Azure Network Watcher, kelompok keamanan jaringan (NSG), dan jaringan virtual. Semua layanan ini disebarkan ke grup sumber daya tunggal.
Jaringan virtual zona pendaratan data Anda secara otomatis di-peering dengan VNet zona pendaratan manajemen data dan VNet langganan konektivitas Anda.
Pemantauan ruang kerja Azure Databricks
Grup sumber daya ini bersifat opsional dan hanya disebarkan dengan Azure Databricks.
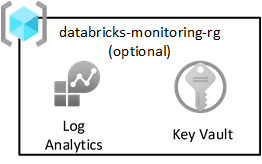
Pola zona pendaratan Azure merekomendasikan agar Anda mengirim semua log ke ruang kerja Analitik Log pusat. Namun, setiap zona pendaratan data juga mencakup grup sumber daya pemantauan untuk menangkap log Spark dari Databricks. Setiap grup sumber daya berisi ruang kerja Analitik Log bersama dan Azure Key Vault untuk menyimpan kunci Analitik Log.
Penting
Hanya gunakan ruang kerja Analitik Log di grup sumber daya pemantauan Databricks Anda untuk mengambil log Azure Databricks Spark.
Untuk informasi selengkapnya, lihat Memantau Azure Databricks.
Metastore Apache Hive untuk Azure Databricks
Grup sumber daya ini bersifat opsional dan hanya boleh disebarkan dengan Azure Databricks.
Metastore Apache Hive untuk Azure Databricks menyediakan database Azure Database for MySQL dan brankas kunci. Semua ruang kerja Azure Databricks di zona pendaratan data Anda menggunakan metastore ini sebagai metastore Apache Hive eksternal mereka.
Untuk informasi selengkapnya, lihat Metastore Apache Hive Eksternal.
Layanan data lake
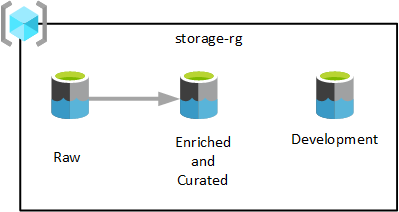
Seperti yang ditunjukkan pada diagram sebelumnya, tiga akun Azure Data Lake Storage Gen2 disediakan dalam satu grup sumber daya layanan data lake. Data yang diubah pada tahap yang berbeda disimpan di salah satu data lake zona pendaratan data Anda. Data tersedia untuk dikonsumsi oleh tim analitik, ilmu data, dan visualisasi Anda.
Lapisan data lake menggunakan terminologi yang berbeda tergantung pada teknologi dan vendor. Tabel ini menyediakan panduan tentang cara menerapkan istilah untuk analitik skala cloud:
| Analitik skala cloud | Delta Lake | Istilah lain | Deskripsi |
|---|---|---|---|
| Mentah | Perunggu | Pendaratan dan Kesuaian | Tabel Penyerapan |
| Diperkaya | Perak | Zona Standardisasi | Tabel Yang Disempurnakan. Entitas lengkap yang disimpan, recordset siap konsumsi dari sistem rekaman. |
| Dikumpulkan | Emas | Zona Produk | Tabel fitur atau agregat. Zona utama untuk aplikasi, tim, dan pengguna untuk menggunakan produk data. |
| Pengembangan | -- | Zona Pengembangan | Lokasi untuk teknisi dan ilmuwan data, yang terdiri dari kotak pasir analitik dan zona pengembangan produk. |
Catatan
Dalam diagram sebelumnya, setiap zona pendaratan data memiliki tiga data lake. Namun, tergantung pada kebutuhan Anda, Anda mungkin ingin mengonsolidasikan lapisan mentah, diperkaya, dan dikumpulkan ke dalam satu akun penyimpanan, dan mempertahankan akun penyimpanan lain yang disebut 'pengembangan' bagi konsumen data untuk membawa produk data berguna lainnya.
Untuk informasi selengkapnya, lihat:
- Gambaran umum Azure Data Lake Storage untuk analitik skala cloud
- Standardisasi Data
- Memprovisikan akun Azure Data Lake Storage Gen2 untuk setiap zona pendaratan data
- Pertimbangan utama untuk Azure Data Lake Storage
- Kontrol akses dan konfigurasi data lake di Azure Data Lake Storage
Mengunggah penyimpanan penyerapan
Penerbit data pihak ketiga perlu mendaratkan data di platform Anda sehingga tim aplikasi data Anda dapat menariknya ke data lake mereka. Seperti yang terlihat dalam diagram berikut, grup sumber daya penyimpanan penyerapan unggahan Memungkinkan Anda menyediakan penyimpanan blob untuk pihak ketiga.
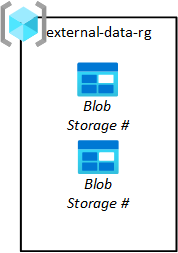
Tim aplikasi data Anda meminta blob penyimpanan ini. Permintaan mereka kemudian disetujui oleh tim operasi zona pendaratan data Anda. Data harus dihapus dari blob penyimpanan sumbernya setelah ditarik dari blob penyimpanan menjadi mentah.
Penting
Karena blob Azure Storage disediakan sesuai kebutuhan, Anda awalnya harus menyebarkan grup sumber daya layanan penyimpanan kosong di setiap zona pendaratan data.
Runtime integrasi bersama
Sebarkan komputer virtual dengan runtime integrasi yang dihost sendiri ke zona pendaratan data Anda. Host di grup sumber daya integrasi bersama. Penyebaran ini memungkinkan Anda melakukan onboarding produk data dengan cepat ke zona pendaratan data Anda.
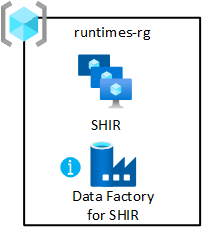
Untuk mengaktifkan grup sumber daya:
- Buat setidaknya satu Azure Data Factory di grup sumber daya integrasi bersama zona pendaratan data Anda. Gunakan hanya untuk menautkan runtime integrasi yang dihost sendiri bersama, bukan untuk alur data.
- Membuat dan mengonfigurasi runtime integrasi yang dihost sendiri di komputer virtual.
- Kaitkan runtime integrasi yang dihost sendiri dengan pabrik data Azure di zona pendaratan data Anda.
- Siapkan Azure Automation untuk memperbarui runtime integrasi yang dihost sendiri secara berkala.
Catatan
Penyebaran di atas menyediakan satu penyebaran komputer virtual dengan runtime integrasi yang dihost sendiri. Anda dapat mengaitkan runtime integrasi yang dihost sendiri dengan beberapa mesin lokal atau komputer virtual di Azure. Komputer ini disebut simpul. Anda dapat memiliki hingga empat simpul yang terkait dengan runtime integrasi yang dihost sendiri. Manfaat memiliki beberapa simpul pada komputer lokal yang memiliki gateway yang diinstal untuk gateway logis adalah:
- Ketersediaan runtime integrasi yang dihost sendiri lebih tinggi sehingga tidak lagi menjadi satu-satunya titik kegagalan dalam solusi big data atau integrasi data cloud Anda. Ketersediaan ini membantu memastikan kontinuitas saat Anda menggunakan hingga empat simpul.
- Peningkatan kinerja dan throughput selama pergerakan data antara penyimpanan data lokal dan cloud. Dapatkan informasi lebih lanjut tentang perbandingan performa.
Anda dapat mengaitkan beberapa simpul dengan menginstal perangkat lunak runtime integrasi yang dihost sendiri dari Pusat Unduhan. Kemudian, daftarkan dengan menggunakan salah satu kunci autentikasi yang diperoleh dari cmdlet New-AzDataFactoryV2IntegrationRuntimeKey, seperti yang dijelaskan dalam tutorial.
Informasi futher dirinci dalam Ketersediaan dan skalabilitas Tinggi Azure Datafactory.
Penting
Sebarkan runtime integrasi bersama sedekat mungkin dengan sumber data. Penyebaran mereka tidak membatasi penyebaran runtime integrasi Anda di zona pendaratan data atau ke cloud pihak ketiga. Sebagai gantinya, ini menyediakan fallback untuk sumber data asli cloud di wilayah.
Agen CI/CD
Agen CI/CD membantu Anda menyebarkan aplikasi data dan perubahan pada zona pendaratan data.
Untuk informasi selengkapnya, lihat Agen Azure Pipeline.
Penyerapan agnostik data
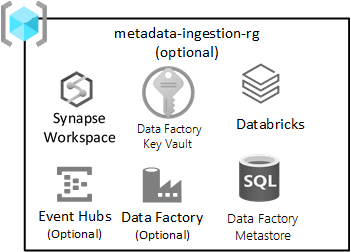
Grup sumber daya ini bersifat opsional, dan tidak melarang Anda menyebarkan zona pendaratan Anda.
Grup sumber daya ini berlaku jika Anda memiliki (atau mengembangkan) mesin penyerapan agnostik data untuk menyerap data secara otomatis berdasarkan mendaftarkan metadata (termasuk string koneksi, jalur untuk menyalin data dari dan ke, dan jadwal penyerapan. Grup sumber daya penyerapan dan pemrosesan memiliki layanan utama untuk kerangka kerja semacam ini.
Sebarkan instans Azure SQL Database untuk menyimpan metadata yang digunakan oleh Azure Data Factory. Provisikan Azure Key Vault untuk menyimpan rahasia yang berkaitan dengan layanan penyerapan otomatis. Rahasia ini dapat mencakup:
- Informasi masuk Azure Data Factory metastore
- Kredensial perwakilan layanan untuk proses penyerapan otomatis Anda
Untuk informasi selengkapnya, lihat Cara kerangka kerja penyerapan otomatis mendukung analitik skala cloud di Azure.
Layanan yang disertakan dalam grup sumber daya ini meliputi:
| Layanan | Wajib | Panduan |
|---|---|---|
| Azure Data Factory | Ya | Pabrik data Azure adalah mesin orkestrasi Anda untuk penyerapan agnostik data. |
| Azure SQL DB | Ya | Azure SQL DB adalah metastore untuk Azure Data Factory. |
| Azure Event Hubs atau IoT Hub | Opsional | Azure Event Hubs atau IoT Hub dapat menyediakan streaming real time ke Azure Event Hubs, ditambah pemrosesan batch dan streaming melalui ruang kerja rekayasa Databricks. |
| Azure Databricks | Opsional | Anda dapat menyebarkan Azure Databricks atau Azure Synapse Spark untuk digunakan dengan mesin penyerapan agnostik data Anda. |
| Azure Synapse | Opsional | Anda dapat menyebarkan Azure Databricks atau Azure Synapse Spark untuk digunakan dengan mesin penyerapan agnostik data. |
Databricks Bersama
Grup sumber daya ini bersifat opsional dan hanya disebarkan dengan Azure Databricks. Semua orang di zona pendaratan data Anda dapat menggunakan ruang kerja Databricks.
Azure Databricks adalah konsumen utama layanan Azure Data Lake Storage. Operasi file atom dioptimalkan untuk mesin analitik Spark. Pengoptimalan ini mempercepat penyelesaian pekerjaan Spark yang masalah layanan Azure Databricks.
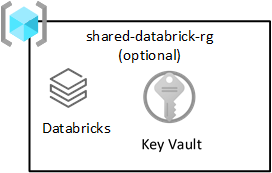
Penting
Ruang kerja Azure Databricks yang disebut ruang kerja Azure Databricks (analitik) disediakan untuk semua ilmuwan data dan DataOps, seperti yang ditunjukkan dalam grup sumber daya produk bersama.
Anda dapat mengonfigurasi ruang kerja ini untuk menyambungkan ke Azure Data Lake Anda menggunakan kontrol akses microsoft Entra atau akses tabel. Bergantung pada kasus penggunaan, Anda dapat mengonfigurasi akses bersyarah sebagai langkah keamanan lainnya.
Ikuti praktik terbaik analitik skala cloud untuk mengintegrasikan Azure Databricks:
Pola zona pendaratan Azure merekomendasikan agar Anda mengirim semua log ke ruang kerja Analitik Log pusat. Namun, setiap zona pendaratan data juga berisi grup sumber daya pemantauan untuk menangkap log Spark dari Databricks.
Azure Synapse Analytics bersama
Grup sumber daya ini bersifat opsional.
Selama penyiapan awal zona pendaratan data, satu ruang kerja Azure Synapse Analytics disebarkan untuk digunakan oleh semua analis data dan ilmuwan di grup sumber daya produk bersama Anda.
Anda dapat menyiapkan lebih banyak ruang kerja synapse untuk produk data jika diperlukan manajemen biaya dan pengisian ulang. Tim aplikasi data Anda mungkin menggunakan ruang kerja Azure Synapse Analytics khusus untuk membuat kumpulan Azure SQL Database khusus sebagai penyimpanan data baca yang digunakan oleh lapisan visualisasi Anda.
Penting
Cegah penggunaan ruang kerja Azure Synapse bersama Anda untuk pembuatan produk data dengan mengunci ruang kerja untuk hanya mengizinkan kueri sesuai permintaan SQL. Itu ada hanya untuk tujuan eksploitasi.
Aplikasi data
Setiap zona pendaratan data dapat memiliki beberapa produk data. Anda dapat membuat produk data ini dengan menyerap data dari sumber. Anda juga dapat membuat produk data dari produk data lain dalam zona pendaratan data yang sama atau dari zona pendaratan data lainnya. Pembuatan produk data produk data tunduk pada persetujuan pengurus data.
Grup sumber daya produk data
Produk grup sumber daya produk data Anda mencakup semua layanan yang diperlukan untuk membuat produk data tersebut. Misalnya, Azure Database diperlukan untuk MySQL, yang digunakan oleh alat visualisasi. Data harus diserap dan diubah sebelum masuk ke database MySQL tersebut. Dalam hal ini, Anda dapat menyebarkan Azure Database for MySQL dan Azure Data Factory ke dalam grup sumber daya produk data.
Tip
Jika Anda memilih untuk tidak menerapkan mesin agnostik data untuk menyerap sekali dari sumber operasional, atau jika koneksi kompleks tidak difasilitasi di mesin agnostik data Anda, buat aplikasi data yang selaras dengan sumber. Untuk informasi selengkapnya, lihat Aplikasi data (selaras dengan sumber)
Untuk informasi selengkapnya tentang cara onboarding produk data, lihat Produk data analitik skala cloud di Azure.
Visualisasi
Grup sumber daya visualisasi kosong dibuat untuk setiap zona pendaratan data. Isi grup sumber daya ini dengan layanan yang Anda butuhkan untuk menerapkan solusi visualisasi Anda. Menggunakan VNet yang ada memungkinkan solusi Anda terhubung ke produk data.
Grup sumber daya ini dapat menghosting komputer virtual untuk layanan visualisasi pihak ketiga.
Tip
Karena biaya lisensi, mungkin lebih ekonomis untuk menyebarkan produk visualisasi pihak ketiga ke zona pendaratan manajemen data Anda, dan agar produk tersebut terhubung di seluruh zona pendaratan data untuk menarik data kembali.