Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
BERLAKU UNTUK:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Terkadang, Anda ingin melakukan migrasi data skala besar dari data lake atau gudang data perusahaan (EDW) ke Azure. Di lain waktu, Anda ingin mengambil data dalam jumlah besar, dari sumber yang berbeda ke Azure, untuk analitik data besar. Dalam setiap kasus, skalabilitas dan performa optimal perlu dicapai.
Azure Data Factory dan alur Azure Synapse Analytics menyediakan mekanisme untuk menelan data, dengan keuntungan berikut:
- Menangani data dalam jumlah besar
- Performa tinggi
- Hemat biaya
Keunggulan ini sangat cocok untuk insinyur data yang ingin membangun alur penyerapan data skalabel yang berperforma tinggi.
Setelah membaca artikel ini, Anda akan dapat menjawab pertanyaan-pertanyaan berikut:
- Tingkat performa dan skalabilitas apa yang dapat saya capai menggunakan aktivitas penyalinan untuk skenario migrasi data dan penyerapan data?
- Langkah apa yang harus saya ambil untuk menyempurnakan performa aktivitas penyalinan?
- Pengoptimalan performa apa yang dapat saya manfaatkan untuk menjalankan aktivitas penyalinan tunggal?
- Apa faktor eksternal lain yang perlu dipertimbangkan saat mengoptimalkan performa penyalinan?
Catatan
Jika Anda belum terbiasa dengan aktivitas penyalinan secara umum, lihat ringkasan aktivitas penyalinan sebelum membaca artikel ini.
Menyalin performa dan skalabilitas yang dapat dicapai menggunakan pipa Azure Data Factory dan Synapse
Azure Data Factory dan alur Synapse menawarkan arsitektur tanpa server yang memungkinkan paralelisme pada tingkat yang berbeda.
Arsitektur ini memungkinkan Anda untuk mengembangkan alur yang memaksimalkan throughput pemindahan data untuk lingkungan Anda. Alur ini sepenuhnya menggunakan sumber daya berikut:
- Bandwidth jaringan antara penyimpanan data sumber dan tujuan
- Operasi input/output penyimpanan data sumber atau tujuan per detik (IOPS) dan bandwidth
Pemanfaatan penuh ini berarti bahwa Anda dapat memperkirakan throughput keseluruhan dengan mengukur throughput minimum yang tersedia di sumber daya berikut:
- Penyimpanan data sumber
- Penyimpanan data tujuan
- Bandwidth jaringan di antara penyimpanan data sumber dan tujuan
Tabel berikut memperlihatkan perhitungan durasi pemindahan data. Durasi di setiap sel dihitung berdasarkan jaringan dan bandwidth penyimpanan data tertentu serta ukuran muatan data tertentu.
Catatan
Durasi yang diberikan di bawah ini dimaksudkan untuk mewakili performa yang dapat dicapai dalam solusi integrasi data ujung ke ujung dengan menggunakan satu atau beberapa teknik pengoptimalan performa yang dijelaskan dalam Menyalin fitur pengoptimalan performa, termasuk menggunakan ForEach untuk mempartisi dan memunculkan beberapa kegiatan menyalin bersamaan. Sebaiknya Anda mengikuti langkah-langkah dijelaskan dalam Langkah penyesuaian performa untuk mengoptimalkan performa penyalinan untuk himpunan data dan konfigurasi sistem tertentu. Anda harus menggunakan angka yang diperoleh dalam uji penyesuaian performa untuk perencanaan penyebaran produksi, perencanaan kapasitas, dan proyeksi penagihan.
| Ukuran data / bandwidth |
50 Mbps | 100 Mbps | 500 Mbps | 1 Gbps | 5 Gbps | 10 Gbps | 50 Gbps |
|---|---|---|---|---|---|---|---|
| 1 GB | 2,7 menit | 1,4 menit | 0,3 menit | 0,1 menit | 0,03 menit | 0,01 menit | 0,0 menit |
| 10 GB | 27,3 menit | 13,7 menit | 2,7 menit | 1,3 menit | 0,3 menit | 0,1 menit | 0,03 menit |
| 100 GB | 4,6 jam | 2,3 jam | 0,5 jam | 0,2 jam | 0,05 jam | 0,02 jam | 0,0 jam |
| 1 TB | 46,6 jam | 23,3 jam | 4,7 jam | 2,3 jam | 0,5 jam | 0,2 jam | 0,05 jam |
| 10 TB | 19,4 hari | 9,7 hari | 1,9 hari | 0,9 hari | 0,2 hari | 0,1 hari | 0,02 hari |
| 100 TB | 194,2 hari | 97,1 hari | 19,4 hari | 9,7 hari | 1,9 hari | 1 hari | 0,2 hari |
| 1 PB | 64,7 bln | 32,4 bln | 6,5 bln | 3,2 bln | 0,6 bln | 0,3 bln | 0,06 bln |
| 10 PB | 647,3 bln | 323,6 bln | 64,7 bln | 31,6 bln | 6,5 bln | 3,2 bln | 0,6 bln |
Salin dapat diskalakan pada level yang berbeda:
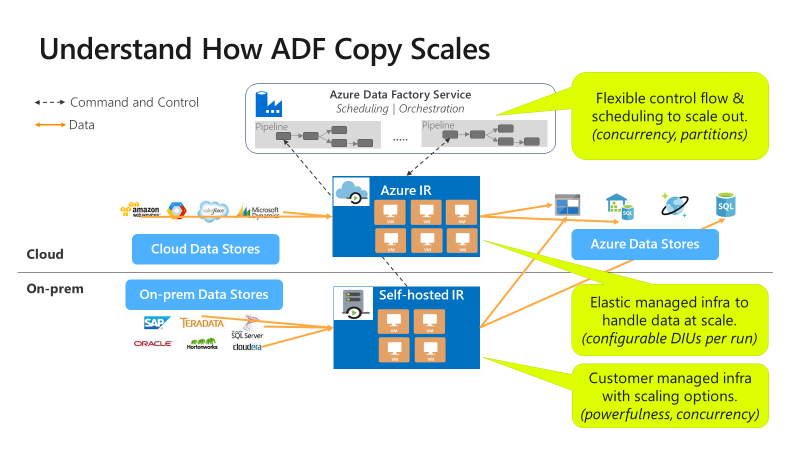
Alur kontrol dapat memulai beberapa aktivitas penyalinan secara paralel, misalnya menggunakan Untuk Setiap loop.
Satu aktivitas salin dapat memanfaatkan sumber daya komputasi yang dapat diskalakan.
- Saat menggunakan runtime integrasi (IR) Azure, Anda dapat menentukan hingga 256 unit integrasi data (DIU) untuk setiap aktivitas penyalinan, dengan cara tanpa server.
- Saat menggunakan IR yang dihost sendiri, Anda dapat mengambil salah satu pendekatan berikut:
- Perluas skala komputer secara manual.
- Peluasan skala ke beberapa komputer (hingga 4 simpul), dan satu aktivitas penyalinan akan mempartisi filenya yang diatur di semua simpul.
Satu aktivitas penyalinan dibaca dari dan ditulis ke penyimpanan data menggunakan beberapa rangkaian secara paralel.
Langkah-langkah penyetelan kinerja
Lakukan langkah-langkah berikut untuk menyempurnakan performa layanan Anda dengan aktivitas penyalinan:
Pilih himpunan data pengujian dan buat garis besar.
Selama pengembangan, uji alur dengan menggunakan aktivitas penyalinan terhadap sampel data representatif. Himpunan data yang dipilih harus mewakili pola data umum beserta atribut berikut:
- Struktur folder
- Pola file
- Skema data
Dan himpunan data Anda harus cukup besar untuk mengevaluasi performa penyalinan. Ukuran yang tepat membutuhkan setidaknya 10 menit agar aktivitas penyalinan selesai. Kumpulkan detail eksekusi dan karakteristik performa setelah pemantauan aktivitas penyalinan.
Cara memaksimalkan performa satu aktivitas penyalinan:
Sebaiknya Anda terlebih dahulu memaksimalkan performa menggunakan satu aktivitas penyalinan.
Jika aktivitas penyalinan dijalankan pada runtime integrasi Azure:
Mulai dengan nilai default untuk Unit Integrasi Data (DIU) dan pengaturan penyalinan paralel.
Jika aktivitas penyalinan dijalankan pada runtime integrasi yang dihost sendiri:
Kami menyarankan Agar Anda menggunakan mesin khusus untuk menghosting IR. Mesin harus terpisah dari server yang menghosting penyimpanan data. Mulai dengan nilai default untuk pengaturan salinan paralel dan menggunakan satu simpul untuk IR yang dihost sendiri.
Lakukan eksekusi uji performa. Perhatikan performa yang dicapai. Sertakan nilai aktual yang digunakan, seperti DIU dan penyalinan paralel. Lihat pemantauan aktivitas penyalinan tentang cara mengumpulkan hasil eksekusi dan pengaturan performa yang digunakan. Pelajari cara memecahkan masalah performa aktivitas penyalinan untuk mengidentifikasi dan mengatasi hambatan.
Ulangi untuk melakukan eksekusi uji performa tambahan dengan mengikuti panduan pemecahan masalah dan penyesuaian. Setelah eksekusi satu aktivitas penyalinan tidak dapat mencapai throughput yang lebih baik, pertimbangkan apakah akan memaksimalkan throughput agregat dengan menjalankan beberapa penyalinan secara bersamaan. Opsi ini dibahas dalam poin bernomor berikutnya.
Cara memaksimalkan throughput agregat dengan menjalankan beberapa penyalinan secara bersamaan:
Sekarang Anda telah memaksimalkan performa satu aktivitas penyalinan. Jika batas atas throughput lingkungan Anda belum tercapai, Anda dapat menjalankan beberapa aktivitas penyalinan secara paralel. Anda dapat berjalan secara paralel dengan menggunakan konstruksi aliran kontrol. Salah satu konstruksi tersebut adalah Untuk Setiap perulangan. Untuk informasi selengkapnya, lihat artikel berikut tentang templat solusi:
Memperluas konfigurasi ke seluruh himpunan data.
Jika puas dengan hasil dan performa eksekusi, Anda dapat memperluas penentuan dan alur untuk mencakup seluruh himpunan data.
Memecahkan masalah performa aktivitas penyalinan
Ikuti langkah penyetelan performa untuk merencanakan dan melakukan uji performa untuk skenario Anda. Dan pelajari cara memecahkan masalah performa setiap aktivitas penyalinan dari Memecahkan masalah performa aktivitas penyalinan.
Fitur optimalisasi performa penyalinan
Layanan ini menyediakan fitur pengoptimalan performa berikut:
- Unit Integrasi Data
- Skalabilitas runtime integrasi yang dihost sendiri
- Salinan paralel
- Salinan yang dipentaskan
Unit Integrasi Data
Unit Integrasi Data (DIU) adalah ukuran yang mewakili kekuatan satu unit di Azure Data Factory dan pipa Synapse. Daya adalah kombinasi dari CPU, memori, dan alokasi sumber daya jaringan. DIU hanya berlaku untuk runtime integrasi Azure. DIU tidak berlaku untuk runtime integrasi yang dihost sendiri. Pelajari selengkapnya di sini.
Skalabilitas runtime integrasi yang dihost sendiri
Sebaiknya Anda menghosting beban kerja bersamaan yang meningkat. Sebaiknya, sebaiknya Anda mencapai performa yang lebih tinggi di tingkat beban kerja saat ini. Anda dapat meningkatkan skala pemrosesan dengan pendekatan berikut:
- Anda dapat meningkatkan skala IR yang dihost sendiri, dengan meningkatkan jumlah pekerjaan bersamaan yang dapat dijalankan pada simpul.
Tingkatkan skala pekerjaan hanya jika prosesor dan memori simpul tidak digunakan sepenuhnya. - Anda dapat meluaskan skala IR yang dihost sendiri, dengan menambahkan lebih banyak simpul (komputer).
Untuk informasi selengkapnya, lihat:
- Optimalisasi performa aktivitas penyalinan: Skalabilitas runtime integrasi yang dihost sendiri
- Membuat dan mengonfigurasi runtime integrasi yang dihost sendiri: Pertimbangan skala
Salinan paralel
Anda dapat mengatur properti parallelCopies untuk menunjukkan paralelisme yang Anda inginkan untuk digunakan oleh aktivitas penyalinan. Anggap properti ini sebagai jumlah maksimum rangkaian dalam aktivitas penyalinan. Rangkaian beroperasi secara paralel. Rangkaian dibaca dari sumber Anda, atau ditulis ke penyimpanan data sink Anda. Pelajari selengkapnya.
Salinan yang dipentaskan
Operasi penyalinan data dapat mengirim data langsung ke penyimpanan data sink. Sebagai alternatif, Anda dapat memilih untuk menggunakan penyimpanan Blob sebagai penyimpanan penahapan sementara. Pelajari selengkapnya.
Konten terkait
Lihat artikel aktivitas salin lainnya: