Azure Pembelajaran Mesin sebagai produk data untuk analitik skala cloud
Azure Machine Learning adalah platform terintegrasi untuk mengelola siklus hidup pembelajaran mesin dari awal hingga akhir, termasuk bantuan dengan pembuatan, operasi, dan konsumsi model dan alur kerja pembelajaran mesin. Beberapa manfaat dari layanan ini meliputi:
Kemampuan mendukung pembuat konten untuk meningkatkan produktivitas mereka dengan membantu mereka mengelola eksperimen, mengakses data, melacak pekerjaan, menyetel hiperparameter, dan mengotomatiskan alur kerja.
Kapasitas model untuk dijelaskan, direproduksi, diaudit, dan diintegrasikan dengan Azure DevOps, ditambah model kontrol keamanan yang kaya, dapat mendukung operator untuk memenuhi persyaratan pemerintahan dan kepatuhan.
Kemampuan inferensi terkelola dan integrasi yang kuat dengan komputasi Azure dan layanan data dapat membantu menyederhanakan cara layanan dikonsumsi.
Azure Machine Learning mencakup semua aspek siklus hidup ilmu data. Ini mencakup penyimpanan data dan pendaftaran himpunan data untuk memodelkan penyebaran. Ini dapat digunakan untuk segala jenis pembelajaran mesin, mulai dari pembelajaran mesin klasik hingga pembelajaran mendalam. Ini termasuk pembelajaran yang diawasi dan tidak diawasi. Apakah Anda lebih suka menulis Python, kode R, atau menggunakan opsi tanpa kode atau kode rendah seperti perancang, Anda dapat membangun, melatih, dan melacak pembelajaran mesin yang akurat dan model pembelajaran mendalam di ruang kerja Azure Machine Learning.
Azure Machine Learning, platform Azure, dan layanan Azure AI dapat bekerja sama untuk mengelola siklus hidup pembelajaran mesin. Seorang praktisi pembelajaran mesin dapat menggunakan Azure Synapse Analytics, Azure SQL Database, atau Microsoft Power BI untuk mulai menganalisis data dan transisi ke Azure Machine Learning untuk membuat prototipe, mengelola eksperimen, dan operasionalisasi. Di zona pendaratan Azure, Azure Machine Learning dapat dianggap sebagai produk data.
Azure Pembelajaran Mesin dalam analitik skala cloud
Fondasi zona pendaratan Cloud Adoption Framework (CAF), zona pendaratan data analitik skala cloud, dan konfigurasi Azure Pembelajaran Mesin menyiapkan profesional pembelajaran mesin dengan lingkungan yang telah dikonfigurasi sebelumnya yang dapat berulang kali menyebarkan beban kerja pembelajaran mesin baru atau memigrasikan beban kerja yang ada. Kemampuan ini dapat membantu para profesional pembelajaran mesin untuk mendapatkan lebih banyak kelincahan dan nilai untuk waktu mereka.
Prinsip-prinsip desain berikut dapat memandu implementasi zona pendaratan Azure AML:
Akses data yang dipercepat: Komponen penyimpanan zona pendaratan prakonfigurasi sebagai penyimpanan data di ruang kerja Azure Machine Learning.
Kolaborasi yang diaktifkan: Mengatur ruang kerja berdasarkan proyek dan memusatkan manajemen akses untuk sumber daya zona pendaratan untuk mendukung rekayasa data, ilmu data, dan profesional pembelajaran mesin untuk bekerja sama.
Implementasi yang aman: Sebagai default untuk setiap penyebaran, ikuti praktik terbaik dan gunakan isolasi jaringan, identitas, dan manajemen akses untuk mengamankan aset data.
Layanan mandiri: Profesional pembelajaran mesin dapat memperoleh lebih banyak kelincahan dan organisasi dengan mengeksplorasi opsi untuk menyebarkan sumber daya proyek baru.
Pemisahan kekhawatiran antara manajemen data dan konsumsi data: Passthrough identitas adalah jenis autentikasi default untuk Azure Machine Learning dan penyimpanan.
Aplikasi data yang lebih cepat (selaras dengan sumber): Zona pendaratan Azure Data Factory, Azure Synapse Analytics, dan Databricks dapat dikonfigurasi sebelumnya untuk ditautkan ke Azure Pembelajaran Mesin.
Observability: Konfigurasi pengelogan dan referensi pusat dapat membantu memantau lingkungan.
Gambaran umum implementasi
Catatan
Bagian ini merekomendasikan konfigurasi khusus untuk analitik skala cloud. Ini melengkapi dokumentasi Azure Pembelajaran Mesin dan praktik terbaik Cloud Adoption Framework.
Organisasi dan penyiapan ruang kerja
Anda dapat menyebarkan jumlah ruang kerja pembelajaran mesin yang dibutuhkan beban kerja dan untuk setiap zona pendaratan yang Anda sebarkan. Rekomendasi berikut dapat membantu penyiapan Anda:
Sebarkan setidaknya satu ruang kerja pembelajaran mesin per proyek.
Bergantung pada siklus hidup proyek pembelajaran mesin Anda, sebarkan satu ruang kerja pengembangan (dev) ke kasus penggunaan prototipe dan jelajahi data sejak dini. Untuk pekerjaan yang membutuhkan eksperimen, pengujian, dan penyebaran berkelanjutan, sebarkan ruang kerja penahapan dan produksi.
Ketika beberapa lingkungan diperlukan untuk ruang kerja dev, penahapan, dan produksi di zona pendaratan data, sebaiknya hindari duplikasi data dengan meminta setiap lingkungan yang mendarat di zona pendaratan data produksi yang sama.
Lihat Mengatur dan menyiapkan lingkungan Azure Machine Learning untuk mempelajari selengkapnya tentang cara mengatur dan menyiapkan sumber daya Azure Machine Learning.
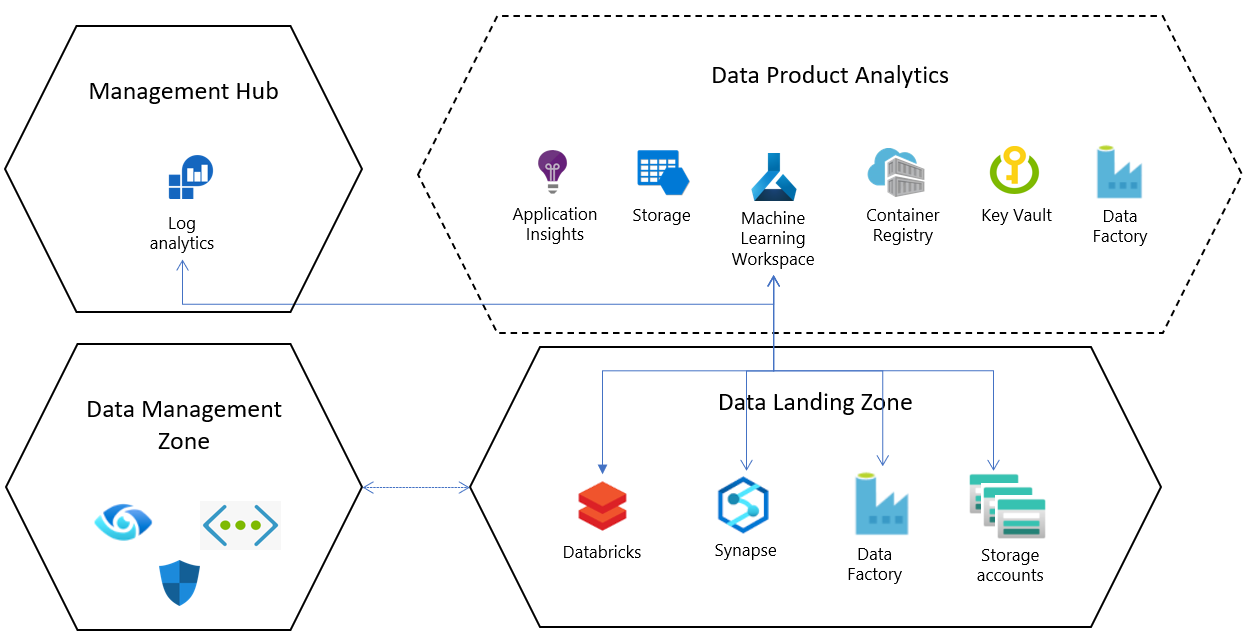
Untuk setiap konfigurasi sumber daya default di zona pendaratan data, Azure Machine Learning service disebarkan dalam grup sumber daya khusus dengan konfigurasi berikut dan sumber daya dependen:
- Azure Key Vault
- Application Insights
- Azure Container Registry
- Gunakan Azure Pembelajaran Mesin untuk menyambungkan ke akun Azure Storage dan autentikasi berbasis identitas Microsoft Entra untuk membantu pengguna tersambung ke akun tersebut.
- Pembuatan log diagnostik disiapkan untuk setiap ruang kerja dan dikonfigurasikan ke sumber daya Analitik Log pusat dalam skala perusahaan; ini dapat membantu status sumber daya dan kesehatan kerja Azure Machine Learning untuk dianalisis secara terpusat di dalam dan di seluruh zona pendaratan.
- Lihat Apa itu ruang kerja Azure Machine Learning? untuk mempelajari selengkapnya tentang sumber daya dan ketergantungan Azure Machine Learning.
Integrasi dengan layanan inti zona pendaratan data
Zona pendaratan data dilengkapi dengan set layanan default yang digunakan di lapisan layanan inti. Layanan inti ini dapat dikonfigurasi saat Azure Machine Learning disebarkan di zona pendaratan data.
Sambungkan ruang kerja Azure Synapse Analytics atau Databricks sebagai layanan tertaut untuk mengintegrasikan data dan memproses data besar.
Secara default, layanan data lake disediakan di zona pendaratan data, dan penyebaran produk Azure Machine Learning dilengkapi dengan koneksi (penyimpanan data) yang telah dikonfigurasi sebelumnya ke akun penyimpanan ini.
Konektivitas jaringan
Jaringan untuk menerapkan Pembelajaran Mesin Azure di zona pendaratan Azure diatur dengan praktik terbaik keamanan untuk Azure Machine Learning dan praktik terbaik jaringan CAF. Praktik terbaik ini mencakup konfigurasi berikut:
- Azure Machine Learning dan sumber daya yang dependen dikonfigurasikan untuk menggunakan titik akhir Private Link.
- Sumber daya komputasi terkelola hanya disebarkan dengan alamat IP pribadi.
- Konektivitas jaringan ke repositori gambar basis publik Azure Machine Learning dan layanan mitra seperti Azure Artifacts dapat dikonfigurasikan pada tingkat jaringan.
Pengelolaan identitas dan akses
Pertimbangkan rekomendasi berikut untuk mengelola identitas dan akses pengguna dengan Azure Machine Learning Azure:
Penyimpanan data di Azure Machine Learning dapat dikonfigurasikan untuk menggunakan autentikasi berbasis mandat atau identitas. Saat Anda menggunakan kontrol akses dan konfigurasi data lake di Azure Data Lake Storage Gen2, konfigurasikan penyimpanan data untuk menggunakan autentikasi berbasis identitas; ini memungkinkan Azure Machine Learning mengoptimalkan izin akses pengguna untuk penyimpanan.
Gunakan grup Microsoft Entra untuk mengelola izin pengguna untuk penyimpanan dan sumber daya pembelajaran mesin.
Azure Machine Learning dapat menggunakan identitas terkelola yang ditetapkan pengguna untuk kontrol akses dan membatasi jangkauan akses ke Azure Container Registry, Key Vault, Azure Storage, dan Application Insights.
Buat identitas terkelola yang ditetapkan pengguna ke kluster komputasi terkelola yang dibuat di Azure Machine Learning.
Penyediaan infrastruktur melalui layanan mandiri
Layanan mandiri dapat diaktifkan dan diatur dengan kebijakan untuk Azure Machine Learning. Tabel berikut mencantumkan set kebijakan default saat Anda menyebarkan Azure Machine Learning. Untuk informasi selengkapnya, lihat Definisi kebijakan bawaan Azure Policy untuk Azure Machine Learning.
| Kebijakan | Jenis | Referensi |
|---|---|---|
| Ruang kerja Azure Machine Learning harus menggunakan Azure Private Link. | Bawaan | Lihat di portal Microsoft Azure |
| Ruang kerja Azure Machine Learning harus menggunakan identitas terkelola yang ditetapkan pengguna. | Bawaan | Lihat di portal Microsoft Azure |
| [Pratinjau]: Konfigurasikan registri yang diizinkan untuk komputasi Azure Machine Learning yang ditentukan. | Bawaan | Lihat di portal Microsoft Azure |
| Konfigurasikan ruang kerja Azure Machine Learning dengan titik akhir privat. | Bawaan | Lihat di portal Microsoft Azure |
| Konfigurasikan komputasi Azure Machine Learning agar menonaktifkan metode autentikasi lokal. | Bawaan | Lihat di portal Microsoft Azure |
| Append-machinelearningcompute-setupscriptscreationscript | Kustom (zona pendaratan CAF) | Lihat di GitHub |
| Deny-machinelearning-hbiworkspace | Kustom (zona pendaratan CAF) | Lihat di GitHub |
| Deny-machinelearning-publicaccesswhenbehindvnet | Kustom (zona pendaratan CAF) | Lihat di GitHub |
| Deny-machinelearning-AKS | Kustom (zona pendaratan CAF) | Lihat di GitHub |
| Deny-machinelearningcompute-subnetid | Kustom (zona pendaratan CAF) | Lihat di GitHub |
| Deny-machinelearningcompute-vmsize | Kustom (zona pendaratan CAF) | Lihat di GitHub |
| Deny-machinelearningcomputecluster-remoteloginportpublicaccess | Kustom (zona pendaratan CAF) | Lihat di GitHub |
| Deny-machinelearningcomputecluster-scale | Kustom (zona pendaratan CAF) | Lihat di GitHub |
Rekomendasi untuk mengelola lingkungan Anda
Zona pendaratan data analitik skala cloud menguraikan implementasi referensi untuk penyebaran berulang, yang dapat membantu Anda menyiapkan lingkungan yang dapat dikelola dan diatur. Pertimbangkan rekomendasi berikut ini untuk menggunakan Azure Machine Learning untuk mengelola lingkungan Anda:
Gunakan grup Microsoft Entra untuk mengelola akses ke sumber daya pembelajaran mesin.
Publikasikan dasbor pemantauan pusat untuk memantau kesehatan alur, pemanfaatan komputasi, dan manajemen kuota untuk pembelajaran mesin.
Jika Anda secara tradisional menggunakan kebijakan Azure bawaan dan perlu memenuhi persyaratan kepatuhan tambahan, kompilasi kebijakan Azure kustom untuk meningkatkan pemerintahan dan layanan mandiri.
Untuk melacak biaya penelitian dan pengembangan, sebarkan satu ruang kerja pembelajaran mesin di zona pendaratan sebagai sumber daya bersama selama tahap awal menjelajahi kasus penggunaan Anda.
Penting
Gunakan kluster Azure Machine Learning untuk pelatihan model kelas produksi, dan Azure Kubernetes Service (AKS) untuk penyebaran tingkat produksi.
Tip
Gunakan Azure Machine Learning untuk proyek ilmu data. Ini mencakup alur kerja end-to-end dengan sublayanan dan fitur, dan memungkinkan proses untuk sepenuhnya otomatis.
Langkah berikutnya
Gunakan templat dan panduan Analisis Produk Data untuk menyebarkan Azure Machine Learning, dan referensi dokumentasi dan tutorial Azure Machine Learning untuk memulai membangun solusi Anda.
Lanjutkan ke empat artikel Cloud Adoption Framework berikut ini untuk mempelajari lebih lanjut tentang praktik terbaik penyebaran dan manajemen Azure Machine Learning untuk perusahaan:
Mengatur dan menyiapkan lingkungan Azure Machine Learning: Saat merencanakan penyebaran Azure Machine Learning, bagaimana struktur tim, lingkungan, atau geografi sumber daya memengaruhi cara ruang kerja disiapkan?
Praktik terbaik Azure Machine Learning untuk keamanan perusahaan: Pelajari cara mengamankan lingkungan dan sumber daya Anda dengan Azure Machine Learning.
Mengelola anggaran, biaya, dan kuota untuk Azure Machine Learning pada skala organisasi: Organisasi menghadapi banyak tantangan manajemen dan pengoptimalan saat mengelola beban kerja, tim, dan biaya komputasi pengguna yang timbul dari Azure Machine Learning.
Panduan DevOps pembelajaran mesin: Pembelajaran mesin DevOps adalah perubahan organisasi yang bergantung pada kombinasi orang, proses, dan teknologi untuk memberikan solusi pembelajaran mesin dengan cara yang kuat, terukur, andal, dan otomatis. Panduan ini merangkum praktik dan informasi terbaik bagi perusahaan untuk menggunakan Azure Machine Learning untuk mengadopsi pembelajaran mesin DevOps.