Migrasi data langsung dari Apache Cassandra ke Azure Cosmos DB for Apache Cassandra dengan menggunakan proksi dual-write dan Apache Spark
API untuk Cassandra di Azure Cosmos DB telah menjadi pilihan yang bagus untuk beban kerja perusahaan yang berjalan di Apache Cassandra karena berbagai alasan seperti:
Tidak ada overhead pengelolaan dan pemantauan: Ini menghilangkan overal pengelolaan dan pemantauan berbagai pengaturan di OS, JVM, dan file yaml dan interaksinya.
Penghematan biaya yang signifikan: Anda dapat menghemat biaya dengan Azure Cosmos DB, yang mencakup biaya VM, bandwidth, dan lisensi apa pun yang berlaku. Anda tidak perlu mengelola pusat data, server, penyimpanan SSD, jaringan, dan biaya listrik.
Kemampuan untuk menggunakan kode dan alat yang ada: Azure Cosmos DB menyediakan kompatibilitas tingkat protokol kawat dengan SDK dan alat Cassandra yang ada. Kompatibilitas ini memastikan Anda dapat menggunakan basis kode yang ada dengan Azure Cosmos DB untuk Apache Cassandra dengan perubahan sepele.
Azure Cosmos DB tidak mendukung protokol gosip Apache Cassandra asli untuk replikasi. Oleh karena itu, saat waktu henti nol merupakan persyaratan untuk migrasi, diperlukan pendekatan yang berbeda. Tutorial ini menjelaskan cara memigrasikan data secara langsung ke Azure Cosmos DB for Apache Cassandra dari kluster Apache Cassandra asli menggunakan proksi dual-write dan Apache Spark.
Gambar berikut mengilustrasikan pola tersebut. Proksi tulis ganda digunakan untuk menangkap perubahan langsung, sementara data historis disalin secara massal menggunakan Apache Spark. Proksi dapat menerima koneksi dari kode aplikasi Anda dengan sedikit atau tanpa perubahan konfigurasi. Ini akan merutekan semua permintaan ke database sumber Anda dan secara asinkron merutekan penulisan ke API untuk Cassandra saat salinan massal terjadi.

Prasyarat
Provisikan akun Azure Cosmos DB untuk Apache Cassandra.
Tinjau dasar-dasar menyambungkan ke Azure Cosmos DB untuk Apache Cassandra.
Tinjau fitur yang didukung di Azure Cosmos DB untuk Apache Cassandra untuk memastikan kompatibilitas.
Pastikan Anda memiliki konektivitas jaringan antara kluster sumber dan API target untuk titik akhir Cassandra.
Pastikan Anda telah memigrasikan skema keyspace/table dari database Cassandra sumber Anda ke API target untuk akun Cassandra.
Penting
Jika Anda memiliki persyaratan untuk mempertahankan Apache Cassandra
writetimeselama migrasi, tanda berikut harus ditetapkan saat membuat tabel:with cosmosdb_cell_level_timestamp=true and cosmosdb_cell_level_timestamp_tombstones=true and cosmosdb_cell_level_timetolive=trueContohnya:
CREATE KEYSPACE IF NOT EXISTS migrationkeyspace WITH REPLICATION= {'class': 'org.apache.> cassandra.locator.SimpleStrategy', 'replication_factor' : '1'};CREATE TABLE IF NOT EXISTS migrationkeyspace.users ( name text, userID int, address text, phone int, PRIMARY KEY ((name), userID)) with cosmosdb_cell_level_timestamp=true and > cosmosdb_cell_level_timestamp_tombstones=true and cosmosdb_cell_level_timetolive=true;
Provisi kluster Spark
Kami merekomendasikan Azure Databricks. Gunakan runtime yang mendukung Spark 3.0 atau yang lebih tinggi.
Penting
Anda perlu memastikan bahwa akun Azure Databricks Anda memiliki konektivitas jaringan dengan kluster Apache Cassandra sumber Anda. Hal ini mungkin memerlukan injeksi VNet. Lihat artikel di sini untuk informasi selengkapnya.

Tambahkan ketergantungan Spark
Anda perlu menambahkan pustaka Apache Spark Cassandra Connector ke klaster Anda untuk terhubung ke titik akhir asli dan Azure Cosmos DB Cassandra. Di klaster Anda, pilih Pustaka > Pasang Baru > Maven, lalu tambahkan com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 di koordinat Maven.
Penting
Jika Anda memiliki persyaratan untuk mempertahankan Apache Cassandra writetime untuk setiap baris selama migrasi, sebaiknya gunakan sampel ini. Jar dependensi dalam sampel ini juga berisi konektor Spark, jadi Anda harus menginstal ini, bukan rangkaian konektor di atas. Sampel ini juga berguna jika Anda ingin melakukan validasi perbandingan baris antara sumber dan target setelah pemuatan data historis selesai. Lihat bagian "menjalankan pemuatan data historis" dan "memvalidasi sumber dan target" di bawah untuk detail selengkapnya.
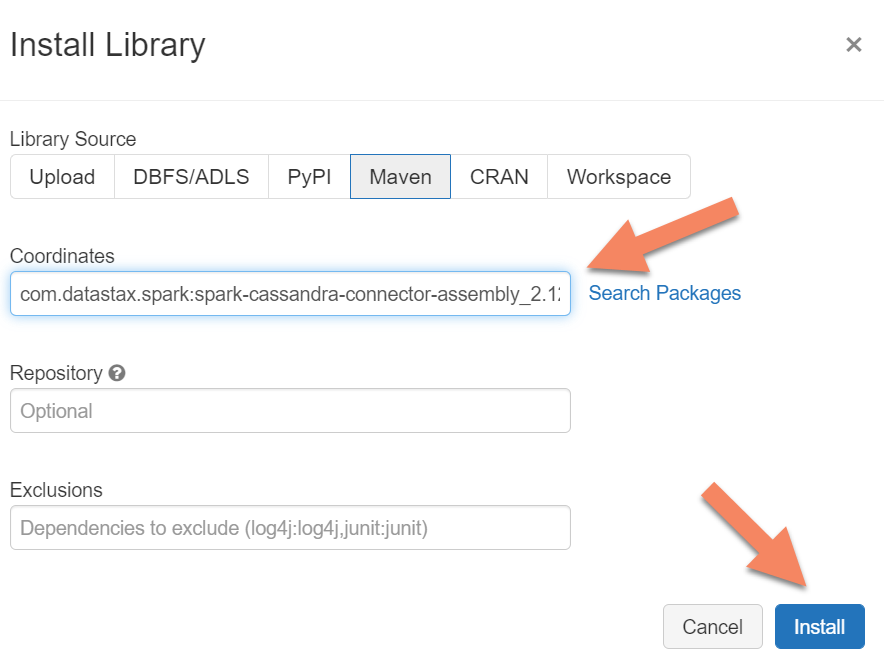
Pilih Pasang,lalu mulai ulang klaster ketika pemasangan selesai.
Catatan
Pastikan untuk memulai ulang kluster Azure Databricks setelah pustaka Konektor Cassandra terpasang.
Pasang proksi dual-write
Untuk tampilan optimal selama dual writes, kami merekomendasikan untuk menginstal proksi pada seluruh node dalam sumber kluster Cassandra Anda.
#assuming you do not have git already installed
sudo apt-get install git
#assuming you do not have maven already installed
sudo apt install maven
#clone repo for dual-write proxy
git clone https://github.com/Azure-Samples/cassandra-proxy.git
#change directory
cd cassandra-proxy
#compile the proxy
mvn package
Mulai proksi dual-write
Kami merekomendasikan untuk memasang proksi pada seluruh simpul dalam sumber kluster Cassandra. Pada kondisi minimum, jalankan perintah berikut untuk memulai proksi di setiap simpul. Ganti <target-server> dengan sebuah IP atau alamat server dari satu node dalam kluster target. Ganti <path to JKS file> dengan jalur ke file .jks lokal, dan ganti <keystore password> dengan kata sandi terkait.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password>
Mulai proksi dengan cara ini dengan asumsi bahwa poin-poin berikut adalah benar:
- Titik akhir sumber dan target memiliki nama pengguna dan kata sandi yang sama.
- Titik akhir sumber dan target mengimplementasikan Secure Sockets Layer (SSL).
Jika titik akhir sumber dan target Anda tidak dapat memenuhi kriteria tersebut, baca terus untuk opsi konfigurasi lebih lanjut.
Mengonfigurasi SSL
Untuk SSL, Anda dapat mengimplementasi sebuah keystore yang sudah ada (contohnya, yang digunakan oleh sumber kluster Anda), atau membuat sertifikat dengan tanda tangan sendiri menggunakan keytool:
keytool -genkey -keyalg RSA -alias selfsigned -keystore keystore.jks -storepass password -validity 360 -keysize 2048
Anda juga dapat menonaktifkan SSL untuk titik akhir sumber atau target jika tidak mengimplementasi SSL. Gunakan --disable-source-tls atau --disable-target-tls flags:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password> --disable-source-tls true --disable-target-tls true
Catatan
Pastikan aplikasi klien Anda menggunakan keystore dan kata sandi yang sama dengan yang digunakan untuk proksi dual-write ketika menyambungkan koneksi SSL ke database melalui proksi tersebut.
Konfigurasikan informasi masuk dan port
Secara default, sumber informasi masuk akan diteruskan melalui aplikasi klien Anda. Proksi akan menggunakan informasi masuk untuk membuat koneksi ke kluster sumber dan target. Seperti disebutkan sebelumnya, proses ini mengasumsikan bahwa informasi masuk sumber dan target adalah sama. Anda harus menentukan nama pengguna dan kata sandi yang berbeda untuk API target untuk titik akhir Cassandra secara terpisah saat memulai proksi:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
Port sumber dan target default, saat tidak ditentukan, akan menjadi 9042. Dalam hal ini, API untuk Cassandra berjalan pada port 10350, jadi Anda perlu menggunakan --source-port atau --target-port untuk menentukan nomor port:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
Sebarkan proksi dari jarak jauh
Mungkin ada keadaan dimana Anda tidak ingin memasang proksi pada node kluster, dan memilih untuk memasangnya pada komputer terpisah. Dalam skenario itu, Anda perlu menentukan alamat IP <source-server>:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar <source-server> <destination-server>
Peringatan
Menginstal dan menjalankan proksi dari jarak jauh di mesin terpisah (sebagai ganti menjalankannya di semua node di kluster Apache Cassandra sumber Anda) akan memengaruhi performa saat migrasi langsung terjadi. Meskipun akan bekerja secara fungsional, driver klien tidak akan dapat membuka koneksi ke semua node dalam kluster, dan akan bergantung pada node koordinator tunggal (tempat proksi diinstal) untuk membuat koneksi.
Izinkan perubahan kode aplikasi nol
Secara default, proksi tersebut mengikuti port 29042. Kode aplikasi harus diubah pada titik port ini. Tetapi, Anda juga bisa mengubah port yang diikuti oleh proksi. Anda dapat melakukan ini jika Anda ingin menghilangkan perubahan kode tingkat aplikasi dengan:
- Menjalankan sumber server Cassandra pada port yang berbeda.
- Menjalankan proksi pada port Cassandra standar 9042.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042
Catatan
Menginstal proksi pada kluster node tidak membutuhkan restart node. Namun, jika Anda memiliki banyak klien aplikasi dan memilih untuk menjalankan proksi pada port 9042 standar Cassandra untuk menghilangkan perubahan kode level aplikasi, Anda perlu mengubah port default Apache Cassandra. Anda kemudian perlu memulai ulang simpul di kluster Anda, dan mengonfigurasi port sumber untuk menjadi port baru yang Anda tentukan untuk sumber kluster Cassandra Anda.
Dalam contoh berikut, kami mengubah sumber kluster Cassandra untuk dijalankan pada port 3074, dan kami memulai kluster pada port 9042:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042 --source-port 3074
Protokol paksa
Proksi tersebut memiliki beberapa fungsi untuk memaksa protokol-protokol yang mungkin diperlukan jika titik akhir sumber lebih modern daripada target atau jika target tidak mendukung. Dalam hal ini, Anda dapat menentukan --protocol-version dan --cql-version untuk memaksa protokol mematuhi target:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --protocol-version 4 --cql-version 3.11
Setelah proksi dual-write berjalan, Anda perlu mengubah port pada aplikasi klien Anda dan memulai ulang. (Atau ubah port Cassandra dan mulai ulang kluster jika Anda telah memilih pendekatan tersebut.) Proksi kemudian akan mulai meneruskan menulis ke titik akhir target. Anda bisa mempelajari tentang pantauan dan metrik tersedia di alat proksi.
Jalankan muatan data riwayat
Untuk memuat data, buatlah catatan Scala di dalam akun Azure Databricks Anda. Ganti konfigurasi Cassandra sumber dan target Anda dengan informasi masuk terkait, dan ganti keyspace dan tabel sumber dan target. Tambahkan variabel lebih untuk tiap tabel sesuai kebutuhan ke contoh berikut, kemudian jalankan. Setelah aplikasi Anda mulai mengirimkan permintaan ke proksi dual-write, Anda siap untuk memindahkan data riwayat.
Penting
Sebelum memigrasikan data, tingkatkan throughput kontainer ke jumlah yang diperlukan agar aplikasi Anda bermigrasi dengan cepat. Menskalakan throughput sebelum memulai migrasi akan membantu Anda melakukan migrasi data dalam waktu yang lebih singkat. Untuk membantu melindungi terhadap pembatasan tarif selama beban data historis, Anda mungkin ingin mengaktifkan percobaan ulang sisi server (SSR) di API untuk Cassandra. Lihat artikel kami di sini untuk informasi selengkapnya, dan petunjuk tentang cara mengaktifkan SSR.
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//set timestamp to ensure it is before read job starts
val timestamp: Long = System.currentTimeMillis / 1000
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.option("writetime", timestamp)
.mode(SaveMode.Append)
.save
Catatan
Dalam sampel Scala sebelumnya, Anda akan melihat bahwa timestamp sedang diatur ke waktu saat ini sebelum membaca semua data dalam tabel sumber. Kemudian, writetime sedang diatur ke penandaan waktu dengan kondisi.backdated ini. Hal ini untuk meyakinkan bahwa rekaman-rekaman yang dituliskan dari muatan data riwayat ke titik akhir target tidak bisa menimpa pembaruan yang datang dengan penandaan waktu selanjutnya dari proksi dual-write saat riwayat data sedang dibaca.
Penting
Jika Anda butuh mempertahankan penandaan waktu tertentu karena suatu alasan, Anda disarankan untuk melakukan pendekatan pemindahan data riwayat yang mempertahankan penandaan waktu, seperti contoh berikut ini. Jar dependensi dalam sampel juga berisi konektor Spark, jadi Anda tidak perlu menginstal rangkaian konektor Spark yang disebutkan di prasyarat sebelumnya - menginstal keduanya di kluster Spark Anda akan menyebabkan konflik.
Validasi sumber dan target
Saat muatan data riwayat sudah lengkap, database Anda seharusnya sudah sinkron dan siap untuk dipindahkan langsung. Namun, sebaiknya Anda memvalidasi sumber dan target untuk memastikan mereka cocok sebelum akhirnya memotongnya.
Catatan
Jika Anda menggunakan sampel cassandra migrator yang disebutkan di atas untuk mempertahankan writetime, hal ini mencakup kemampuan untuk memvalidasi migrasi dengan membandingkan baris di sumber dan target berdasarkan toleransi tertentu.