Cara memodelkan dan mempartisi data di Azure Cosmos DB menggunakan contoh dunia nyata
BERLAKU UNTUK: ![]() NoSQL
NoSQL
Artikel ini dibuat pada beberapa konsep Azure Cosmos DB seperti pemodelan data, pemartisian, dan throughput yang diprovisi untuk mendemostrasikan cara mengatasi penggunaan desain dunia nyata.
Jika Anda biasanya menggunakan database relasional, Anda mungkin telah membangun kebiasaan dan intuisi tentang cara mendesain model data. Karena batasan spesifik, tetapi juga kekuatan unik Azure Cosmos DB, sebagian besar praktik terbaik ini tidak diterjemahkan dengan baik dan dapat menyeret Anda ke dalam solusi suboptimal. Tujuan artikel ini adalah untuk memandu Anda melalui proses lengkap pemodelan kasus penggunaan dunia nyata di Azure Cosmos DB, dari pemodelan item hingga kolokasi entitas dan partisi kontainer.
Unduh atau lihat kode sumber yang dihasilkan komunitas yang mengilustrasikan konsep dari artikel ini.
Penting
Kontributor komunitas menyumbang sampel kode ini dan tim Azure Cosmos DB tidak mendukung pemeliharaannya.
Skenario
Untuk latihan ini, kami akan mempertimbangkan domain platform blogging tempat pengguna dapat membuat postingan. Pengguna juga dapat menyukai dan menambahkan komentar ke postingan tersebut.
Tip
Kami telah menyoroti beberapa kata dalam garis miring; kata-kata ini mengidentifikasi jenis "hal-hal" yang harus dimanipulasi oleh model kami.
Menambahkan lebih banyak persyaratan ke spesifikasi kami:
- Halaman depan menampilkan umpan postingan yang baru dibuat,
- Kami dapat mengambil semua postingan untuk pengguna, semua komentar untuk postingan, dan semua tanda sukai untuk postingan,
- Postingan ditampilkan dengan nama pengguna penulisnya dan hitungan berapa banyak komentar dan suka yang mereka miliki,
- Komentar dan suka juga ditampilkan dengan nama pengguna dari pengguna yang telah membuatnya,
- Saat ditampilkan sebagai daftar, postingan hanya perlu menyajikan ringkasan kontennya yang terpotong.
Identifikasi pola akses utama
Untuk memulai, kami memberikan beberapa struktur pada spesifikasi awal kami dengan mengidentifikasi pola akses solusi kami. Saat merancang model data untuk Azure Cosmos DB, penting untuk memahami permintaan mana yang harus dilayani model kami untuk memastikan bahwa model melayani permintaan tersebut secara efisien.
Untuk membuat proses keseluruhan lebih mudah diikuti, kami mengategorikan permintaan yang berbeda sebagai perintah atau kueri, meminjam beberapa kosakata dari CQRS. Di CQRS, perintah adalah permintaan tulis (yaitu, niat untuk memperbarui sistem) dan kueri adalah permintaan baca-saja.
Berikut adalah daftar permintaan yang diekspos platform kami:
- [C1] Membuat/mengedit pengguna
- [Q1] Mengambil pengguna
- [C2] Membuat/mengedit postingan
- [Q2] Mengambil postingan
- [Q3] Mencantumkan postingan pengguna dalam bentuk singkat
- [C3] Membuat komentar
- [Q4] Mencantumkan komentar postingan
- [C4] Menyukai postingan
- [Q5] Mencantumkan suka postingan
- [Q6] Cantumkan postingan x terbaru yang dibuat dalam bentuk pendek (umpan)
Pada tahap ini, kami belum memikirkan detail apa yang dikandung oleh setiap entitas (pengguna, posting, dll.). Langkah ini biasanya di antara langkah pertama yang akan ditanggulangi saat merancang terhadap toko relasional. Kita mulai dengan langkah ini terlebih dahulu karena kita harus mencari tahu bagaimana entitas tersebut menerjemahkan dalam hal tabel, kolom, kunci asing, dll. Ini jauh lebih sedikit kekhawatiran dengan database dokumen yang tidak memberlakukan skema apa pun saat menulis.
Alasan utama mengapa penting untuk mengidentifikasi pola akses kami dari awal, adalah karena daftar permintaan ini akan menjadi rangkaian pengujian kami. Setiap kali kami melakukan iterasi atas model data, kami melalui setiap permintaan dan memeriksa performa dan skalabilitasnya. Kami menghitung unit permintaan yang digunakan di setiap model dan mengoptimalkannya. Semua model ini menggunakan kebijakan pengindeksan default dan Anda dapat menimpanya dengan mengindeks properti tertentu, yang selanjutnya dapat meningkatkan konsumsi dan latensi RU.
V1: Versi pertama
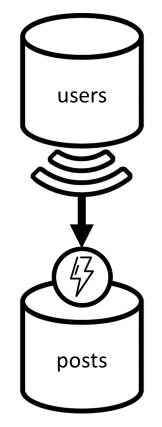
Kita mulai dengan dua kontainer: users dan posts.
Kontainer pengguna
Kontainer ini hanya menyimpan item pengguna:
{
"id": "<user-id>",
"username": "<username>"
}
Kami mempartisi kontainer ini dengan id, yang berarti bahwa setiap partisi logis dalam kontainer tersebut hanya berisi satu item.
Kontainer postingan
Kontainer ini menghosting entitas seperti posting, komentar, dan suka:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
Kami mempartisi kontainer ini dengan postId, yang berarti bahwa setiap partisi logis dalam kontainer tersebut berisi satu posting, semua komentar untuk posting tersebut dan semua suka untuk posting tersebut.
Kami telah memperkenalkan properti dalam item yang type disimpan dalam kontainer ini untuk membedakan antara tiga jenis entitas yang dihosting kontainer ini.
Juga, kami telah memilih untuk mereferensikan data terkait, bukan menyematkannya (periksa bagian ini untuk detail tentang konsep-konsep ini) karena:
- tidak ada batas atas berapa banyak postingan yang dapat dibuat pengguna,
- postingan dapat sangat panjang,
- tidak ada batas atas berapa banyak komentar dan suka yang bisa didapat oleh sebuah postingan,
- kami ingin dapat menambahkan komentar atau suka ke postingan tanpa harus memperbarui postingan tersebut.
Seberapa baik performa model kami?
Sekarang saatnya untuk menilai kinerja dan skalabilitas versi pertama kami. Untuk setiap permintaan yang diidentifikasi sebelumnya, kami mengukur latensinya dan berapa banyak unit permintaan yang dikonsumsinya. Pengukuran ini dilakukan terhadap kumpulan data dummy yang berisi 100.000 pengguna dengan 5 hingga 50 postingan per pengguna, dan hingga 25 komentar dan 100 suka per postingan.
[C1] Membuat/mengedit pengguna
Permintaan ini mudah diterapkan karena kami hanya membuat atau memperbarui item dalam users kontainer. Permintaan tersebar dengan baik di semua partisi berkat id kunci partisi.
| Latensi | Biaya RU | Performa |
|---|---|---|
7 Ms |
5.71 RU |
✅ |
[Q1] Mengambil pengguna
Mengambil pengguna dilakukan dengan membaca item yang sesuai dari users kontainer.
| Latensi | Biaya RU | Performa |
|---|---|---|
2 Ms |
1 RU |
✅ |
[C2] Membuat/mengedit postingan
Demikian pula dengan [C1], kami hanya perlu menulis ke posts kontainer.
| Latensi | Biaya RU | Performa |
|---|---|---|
9 Ms |
8.76 RU |
✅ |
[Q2] Mengambil postingan
Kita mulai dengan mengambil dokumen yang sesuai dari posts kontainer. Tetapi itu tidak cukup, sesuai spesifikasi kami, kami juga harus mengagregasi nama pengguna penulis postingan, jumlah komentar, dan jumlah suka untuk postingan tersebut. Agregasi yang tercantum memerlukan 3 kueri SQL lagi untuk dikeluarkan.
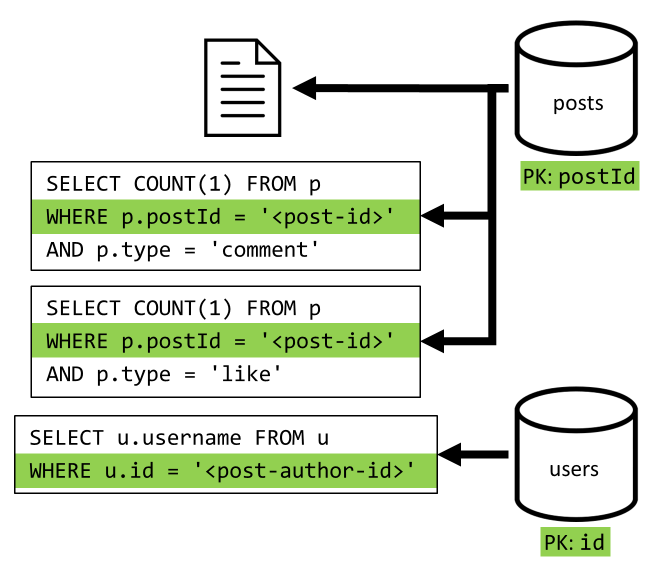
Masing-masing kueri lainnya memfilter pada kunci partisi dari kontainer masing-masing, yang merupakan apa yang ingin kita maksimalkan performa dan skalabilitasnya. Tapi kami akhirnya harus melakukan empat operasi untuk mengembalikan satu postingan, jadi kami akan meningkatkannya dalam iterasi berikutnya.
| Latensi | Biaya RU | Performa |
|---|---|---|
9 Ms |
19.54 RU |
⚠ |
[Q3] Mencantumkan postingan pengguna dalam bentuk pendek
Pertama, kita harus mengambil postingan yang diinginkan dengan kueri SQL yang mengambil postingan yang sesuai dengan pengguna tertentu. Tetapi kita juga harus mengeluarkan lebih banyak kueri untuk mengagregasi nama pengguna penulis dan jumlah komentar dan suka.
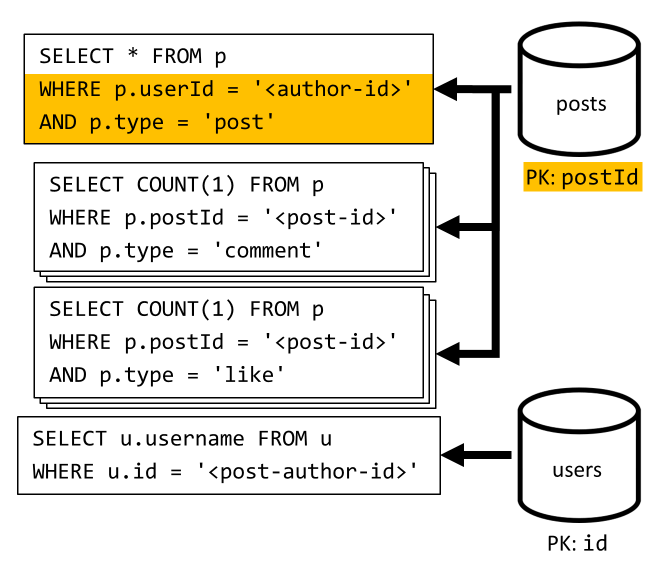
Implementasi ini menyajikan banyak kelemahan:
- kueri yang menggabungkan hitungan komentar dan suka harus dikeluarkan untuk setiap postingan yang ditampilkan oleh kueri pertama,
- kueri utama tidak memfilter kunci
postspartisi kontainer, yang mengarah ke fan-out dan pemindaian partisi di seluruh kontainer.
| Latensi | Biaya RU | Performa |
|---|---|---|
130 Ms |
619.41 RU |
⚠ |
[C3] Membuat komentar
Komentar dibuat dengan menulis item yang sesuai dalam posts kontainer.
| Latensi | Biaya RU | Performa |
|---|---|---|
7 Ms |
8.57 RU |
✅ |
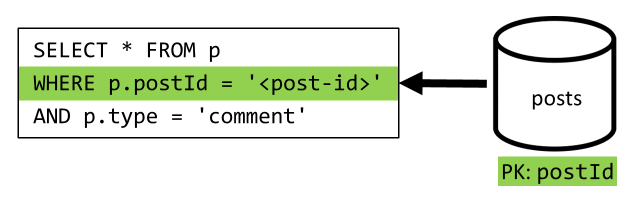
[Q4] Mencantumkan komentar postingan
Kita mulai dengan kueri yang mengambil semua komentar untuk postingan tersebut dan sekali lagi, kita juga perlu mengumpulkan nama pengguna secara terpisah untuk setiap komentar.
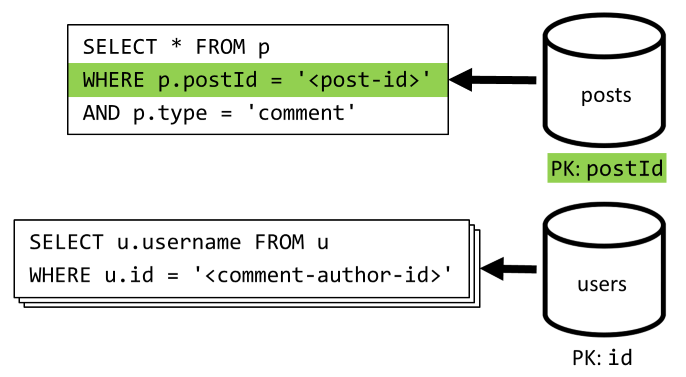
Meskipun kueri utama memang memfilter pada kunci partisi kontainer, menggabungkan nama pengguna secara terpisah menghukum performa keseluruhan. Kami memperbaikinya nanti.
| Latensi | Biaya RU | Performa |
|---|---|---|
23 Ms |
27.72 RU |
⚠ |
[C4] Menyukai postingan
Sama seperti [C3], kami membuat item yang sesuai dalam posts kontainer.
| Latensi | Biaya RU | Performa |
|---|---|---|
6 Ms |
7.05 RU |
✅ |
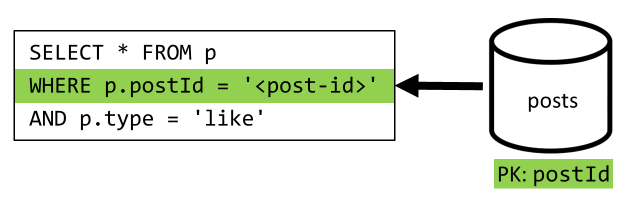
[Q5] Mencantumkan sukai postingan
Sama seperti [Q4], kami meminta sukai untuk postingan tersebut, kemudian mengumpulkan nama penggunanya.
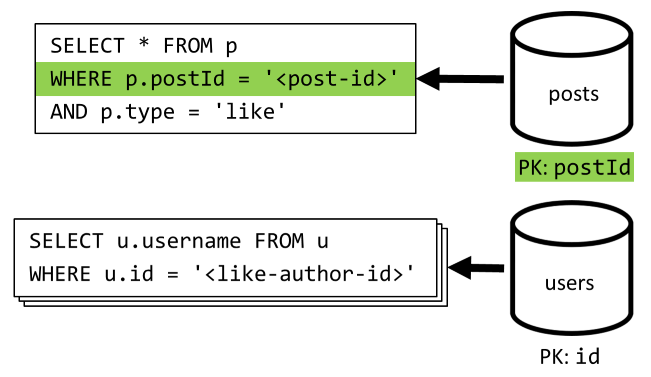
| Latensi | Biaya RU | Performa |
|---|---|---|
59 Ms |
58.92 RU |
⚠ |
[Q6] Cantumkan postingan x terbaru yang dibuat dalam bentuk pendek (umpan)
Kami mengambil postingan terbaru dengan mengkueri posts kontainer yang diurutkan berdasarkan tanggal pembuatan turun, lalu mengagregasi nama pengguna dan jumlah komentar dan suka untuk setiap postingan.
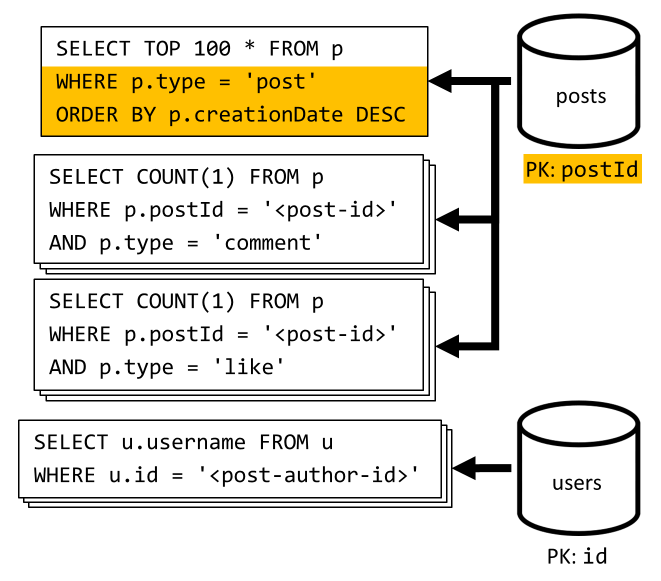
Sekali lagi, kueri awal kami tidak memfilter kunci posts partisi kontainer, yang memicu fan-out yang mahal. Yang ini bahkan lebih buruk karena kita menargetkan kumpulan hasil yang lebih besar dan mengurutkan hasil dengan ORDER BY klausul, yang membuatnya lebih mahal dalam hal unit permintaan.
| Latensi | Biaya RU | Performa |
|---|---|---|
306 Ms |
2063.54 RU |
⚠ |
Merefleksikan performa V1
Melihat masalah performa yang kita hadapi di bagian sebelumnya, kita dapat mengidentifikasi dua kelas utama masalah:
- beberapa permintaan mengharuskan beberapa kueri dikeluarkan untuk mengumpulkan semua data yang perlu kita tampilkan,
- beberapa kueri tidak memfilter pada kunci partisi kontainer yang mereka targetkan, yang memicu fan-out yang menghambat skalabilitas kami.
Kita selesaikan masing-masing masalah tersebut, dimulai dengan yang pertama.
V2: Memperkenalkan denormalisasi untuk mengoptimalkan kueri baca
Alasan mengapa kita harus mengeluarkan lebih banyak permintaan dalam beberapa kasus adalah karena hasil permintaan awal tidak berisi semua data yang perlu kita kembalikan. Mendenormalisasi data memecahkan masalah semacam ini di seluruh himpunan data kami saat bekerja dengan penyimpanan data non-relasional seperti Azure Cosmos DB.
Dalam contoh kami, kami memodifikasi item postingan untuk menambahkan nama pengguna penulis postingan, jumlah komentar, dan jumlah suka:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Kami juga memodifikasi komentar dan menyukai item untuk menambahkan nama pengguna dari pengguna yang telah membuatnya:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
Mendenormalisasi jumlah komentar dan suka
Apa yang ingin kami capai adalah bahwa setiap kali kami menambahkan komentar atau semacamnya, kami juga menambah commentCount atau likeCount dalam postingan yang sesuai. Sebagai postId partisi kontainer kami posts , item baru (komentar atau suka), dan posting yang sesuai berada di partisi logis yang sama. Akibatnya, kita dapat menggunakan prosedur yang disimpan untuk melakukan operasi itu.
Saat Anda membuat komentar ([C3]), alih-alih hanya menambahkan item baru dalam posts kontainer, kami memanggil prosedur tersimpan berikut pada kontainer tersebut:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
Prosedur yang disimpan ini mengambil ID postingan dan isi komentar baru sebagai parameter, kemudian:
- mengambil postingan
- menaikkan
commentCount - menggantikan postingan
- menambahkan komentar baru
Karena prosedur tersimpan dijalankan sebagai transaksi atomik, nilai commentCount dan jumlah komentar aktual selalu tetap sinkron.
Kami jelas menyebut prosedur yang disimpan serupa saat menambahkan suka baru untuk menaikkan likeCount.
Mendenormalisasi nama pengguna
Nama pengguna memerlukan pendekatan yang berbeda karena pengguna tidak hanya berada di partisi yang berbeda, tetapi juga berada dalam kontainer yang berbeda. Saat harus mendenormalisasi data di seluruh partisi dan kontainer, kita dapat menggunakan umpan perubahan kontainer sumber.
Dalam contoh kami, kami menggunakan umpan perubahan users kontainer untuk bereaksi setiap kali pengguna memperbarui nama penggunanya. Saat itu terjadi, kami menyebarkan perubahan dengan memanggil prosedur lain yang disimpan pada posts kontainer:
function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
Prosedur yang tersimpan ini mengambil ID pengguna dan nama pengguna baru pengguna sebagai parameter, lalu:
- mengambil semua item yang cocok dengan
userId(yang dapat menjadi postingan, komentar, atau suka) - untuk setiap item tersebut
- menggantikan
userUsername - menggantikan item
- menggantikan
Penting
Operasi ini mahal karena memerlukan prosedur tersimpan ini untuk dijalankan pada setiap partisi posts kontainer. Kami berasumsi bahwa sebagian besar pengguna memilih nama pengguna yang cocok selama pendaftaran dan tidak akan pernah mengubahnya, sehingga pembaruan ini akan jarang dijalankan.
Berapa perolehan performa V2?
Mari kita bicara tentang beberapa perolehan performa V2.
[Q2] Mengambil postingan
Setelah denormalisasi kami telah siap, kami hanya perlu mengambil satu item untuk menangani permintaan tersebut.
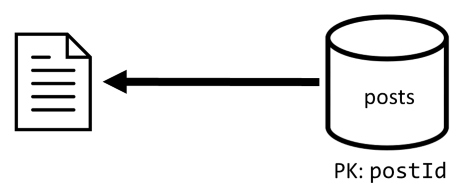
| Latensi | Biaya RU | Performa |
|---|---|---|
2 Ms |
1 RU |
✅ |
[Q4] Mencantumkan komentar postingan
Di sini lagi, kita dapat menyisihkan permintaan tambahan yang mengambil nama pengguna dan berakhir dengan satu kueri yang memfilter pada kunci partisi.
| Latensi | Biaya RU | Performa |
|---|---|---|
4 Ms |
7.72 RU |
✅ |
[Q5] Mencantumkan sukai postingan
Situasi yang sama persis saat mencantumkan suka.
| Latensi | Biaya RU | Performa |
|---|---|---|
4 Ms |
8.92 RU |
✅ |
V3: Memastikan semua permintaan dapat diskalakan
Masih ada dua permintaan yang belum sepenuhnya kami optimalkan saat melihat peningkatan performa kami secara keseluruhan. Permintaan ini adalah [Q3] dan [Q6]. Mereka adalah permintaan yang melibatkan kueri yang tidak memfilter kunci partisi kontainer yang mereka targetkan.
[Q3] Mencantumkan postingan pengguna dalam bentuk pendek
Permintaan ini sudah mendapat manfaat dari peningkatan yang diperkenalkan di V2, yang mengampuni lebih banyak kueri.

Tetapi kueri yang tersisa masih belum memfilter pada kunci partisi posts kontainer.
Cara untuk memikirkan situasi ini sederhana:
- Permintaan ini harus memfilter karena
userIdkami ingin mengambil semua postingan untuk pengguna tertentu. - Ini tidak berkinerja baik karena dijalankan terhadap
postskontainer, yang tidak memilikiuserIdpartisi. - Menyatakan yang jelas, kami akan menyelesaikan masalah performa kami dengan menjalankan permintaan ini terhadap kontainer yang dipartisi dengan
userId. - Ternyata kami sudah memiliki kontainer ini:
userskontainernya!
Jadi kami memperkenalkan denormalisasi tingkat kedua dengan menduplikasi seluruh postingan ke users kontainer. Dengan melakukan itu, kami secara efektif mendapatkan salinan posting kami, hanya dipartisi di sepanjang dimensi yang berbeda, membuatnya jauh lebih efisien untuk diambil oleh mereka userId.
Kontainer users sekarang berisi dua jenis item:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Dalam contoh ini:
- Kami telah memperkenalkan
typebidang dalam item pengguna untuk membedakan pengguna dari postingan, - Kami juga telah menambahkan
userIdbidang dalam item pengguna, yang berlebihan denganidbidang tetapi diperlukan karenauserskontainer sekarang dipartisi denganuserId(dan bukanidseperti sebelumnya)
Untuk mencapai denormalisasi itu, kami sekali lagi menggunakan umpan perubahan. Kali ini, kami bereaksi pada umpan perubahan posts kontainer untuk mengirimkan postingan baru atau diperbarui ke users kontainer. Dan karena mencantumkan postingan tidak perlu mengembalikan konten lengkapnya, kita dapat memotongnya dalam proses.
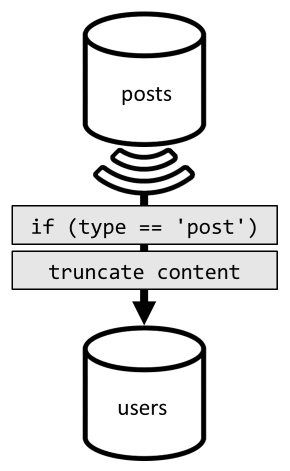
Kita sekarang dapat merutekan kueri kita ke users kontainer, memfilter pada kunci partisi kontainer.

| Latensi | Biaya RU | Performa |
|---|---|---|
4 Ms |
6.46 RU |
✅ |
[Q6] Cantumkan postingan x terbaru yang dibuat dalam bentuk pendek (umpan)
Kita harus menangani situasi serupa di sini: bahkan setelah menghindarkan lebih banyak kueri yang tidak perlu dibiarkan oleh denormalisasi yang diperkenalkan di V2, kueri yang tersisa tidak memfilter pada kunci partisi kontainer:
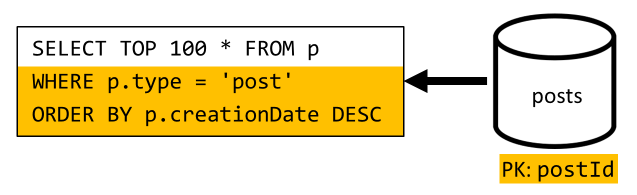
Mengikuti pendekatan yang sama, memaksimalkan performa dan skalabilitas permintaan ini mengharuskan hanya mengenai satu partisi. Hanya mencapai satu partisi yang dapat dibayangkan karena kita hanya perlu mengembalikan jumlah item yang terbatas. Untuk mengisi halaman beranda platform blogging kami, kita hanya perlu mendapatkan 100 posting terbaru, tanpa perlu paginate melalui seluruh himpunan data.
Jadi untuk mengoptimalkan permintaan terakhir ini, kami memperkenalkan kontainer ketiga untuk desain kami, sepenuhnya didedikasikan untuk melayani permintaan ini. Kami mendenormalisasi postingan kami ke kontainer feed baru tersebut:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
Bidang mempartisi type kontainer ini, yang selalu post ada di item kami. Melakukannya memastikan bahwa semua item dalam kontainer ini akan berada di partisi yang sama.
Untuk mencapai denormalisasi, kami hanya perlu mengaitkan pada pipa umpan perubahan yang sebelumnya telah kami perkenalkan untuk mengirim postingan ke kontainer baru tersebut. Satu hal penting yang perlu diingat adalah bahwa kita perlu memastikan bahwa kita hanya menyimpan 100 postingan terbaru; jika tidak, konten kontainer dapat tumbuh melebihi ukuran maksimum partisi. Batasan ini dapat diimplementasikan dengan memanggil pasca-pemicu setiap kali dokumen ditambahkan dalam kontainer:
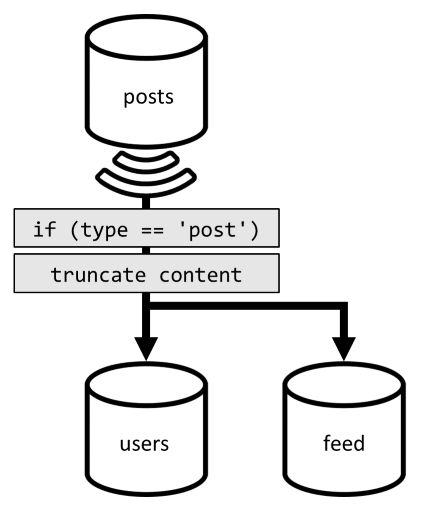
Berikut adalah inti pemicu postingan yang memangkas koleksi:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
Langkah terakhir adalah mengalihkan kueri kami ke kontainer baru feed kami:
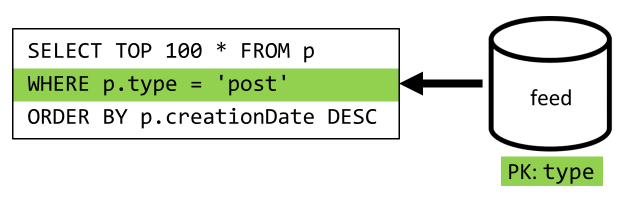
| Latensi | Biaya RU | Performa |
|---|---|---|
9 Ms |
16.97 RU |
✅ |
Kesimpulan
Mari kita lihat peningkatan performa dan skalabilitas keseluruhan yang telah kami perkenalkan atas berbagai versi desain kami.
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] | 7 ms / 5.71 RU |
7 ms / 5.71 RU |
7 ms / 5.71 RU |
| [Q1] | 2 ms / 1 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [C2] | 9 ms / 8.76 RU |
9 ms / 8.76 RU |
9 ms / 8.76 RU |
| [Q2] | 9 ms / 19.54 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [Q3] | 130 ms / 619.41 RU |
28 ms / 201.54 RU |
4 ms / 6.46 RU |
| [C3] | 7 ms / 8.57 RU |
7 ms / 15.27 RU |
7 ms / 15.27 RU |
| [Q4] | 23 ms / 27.72 RU |
4 ms / 7.72 RU |
4 ms / 7.72 RU |
| [C4] | 6 ms / 7.05 RU |
7 ms / 14.67 RU |
7 ms / 14.67 RU |
| [Q5] | 59 ms / 58.92 RU |
4 ms / 8.92 RU |
4 ms / 8.92 RU |
| [Q6] | 306 ms / 2063.54 RU |
83 ms / 532.33 RU |
9 ms / 16.97 RU |
Kami telah mengoptimalkan skenario baca-berat
Anda mungkin telah memperhatikan bahwa kami telah memkonsentasikan upaya kami untuk meningkatkan performa permintaan baca (kueri) dengan mengorbankan permintaan tulis (perintah). Dalam banyak kasus, operasi tulis sekarang memicu denormalisasi berikutnya melalui umpan perubahan, yang membuatnya lebih mahal secara komputasi dan lebih lama untuk diwujudkan.
Kami membenarkan fokus ini pada performa baca dengan fakta bahwa platform blogging (seperti kebanyakan aplikasi sosial) baca-berat. Beban kerja baca-berat menunjukkan bahwa jumlah permintaan baca yang harus dilayani biasanya merupakan pesanan besaran yang lebih tinggi dari jumlah permintaan tulis. Jadi masuk akal untuk membuat permintaan tulis lebih mahal untuk dieksekusi agar permintaan baca menjadi lebih murah dan bekerja lebih baik.
Jika kita melihat pengoptimalan paling ekstrem yang telah kita lakukan, [Q6] pergi dari 2000 + RU menjadi hanya 17 RU; kita telah mencapainya dengan mendenormalisasi posting dengan biaya sekitar 10 RU per item. Karena kami akan melayani lebih banyak permintaan umpan dibandingkan pembuatan atau pembaruan postingan, biaya denormalisasi ini dapat diabaikan mengingat penghematan keseluruhan.
Denormalisasi dapat diterapkan secara bertahap
Peningkatan skalabilitas yang telah kami jelajahi dalam artikel ini melibatkan denormalisasi dan duplikasi data di seluruh himpunan data. Perlu dicatat bahwa optimasi ini tidak harus diberlakukan pada hari ke-1. Kueri yang memfilter pada kunci partisi berperforma lebih baik dalam skala besar, tetapi kueri lintas partisi dapat diterima jika jarang disebut atau terhadap himpunan data terbatas. Jika Anda hanya membangun prototipe, atau meluncurkan produk dengan basis pengguna kecil dan terkontrol, Anda mungkin dapat mengampuni peningkatan tersebut untuk nanti. Yang penting kemudian adalah memantau performa model Anda sehingga Anda dapat memutuskan apakah dan kapan saatnya untuk membawanya.
Umpan perubahan yang kami gunakan untuk mendistribusikan pembaruan ke kontainer lain menyimpan semua pembaruan tersebut secara terus-menerus. Persistensi ini memungkinkan untuk meminta semua pembaruan sejak pembuatan kontainer dan tampilan denormalisasi bootstrap sebagai operasi catch-up satu kali bahkan jika sistem Anda sudah memiliki banyak data.
Langkah berikutnya
Setelah pengenalan pemodelan dan pemartisian data praktis ini, Anda mungkin ingin memeriksa artikel berikut untuk meninjau konsep yang telah kami bahas: