Ikhtisar kelangsungan bisnis dan pemulihan bencana
Kelangsungan bisnis dan pemulihan bencana di Azure Data Explorer memungkinkan bisnis Anda untuk terus beroperasi dalam menghadapi gangguan. Artikel ini membahas ketersediaan (intra-wilayah) dan pemulihan bencana. Ini merinci kemampuan asli dan pertimbangan arsitektur untuk penyebaran Azure Data Explorer yang tangguh. Ini merinci pemulihan dari kesalahan manusia, ketersediaan tinggi, diikuti oleh beberapa konfigurasi pemulihan bencana. Konfigurasi ini tergantung pada persyaratan ketahanan seperti Tujuan Titik Pemulihan (RPO) dan Tujuan Waktu Pemulihan (RTO), upaya yang diperlukan, dan biaya.
Mengurangi peristiwa yang mengganggu
- Kesalahan manusia
- Ketersediaan Tinggi Azure Data Explorer
- Pemadaman zona ketersediaan Azure
- Pemadaman pusat data Azure
- Pemadaman wilayah Azure
Kesalahan manusia
Kesalahan manusia tidak dapat dihindari. Pengguna dapat secara tidak sengaja menghilangkan kluster, database, atau tabel.
Penghapusan tidak sengaja terhadap kluster atau basis data
Penghapusan kluster atau database yang tidak disengaja adalah tindakan yang tidak dapat dipulihkan. Sebagai pemilik sumber daya Azure Data Explorer, Anda dapat mencegah kehilangan data dengan mengaktifkan kemampuan kunci hapus, yang tersedia di tingkat sumber daya Azure.
Penghapusan tidak sengaja terhadap tabel
Pengguna dengan izin admin tabel atau yang lebih tinggi diizinkan untuk melakukan drop tabel. Jika salah satu pengguna tersebut secara tidak sengaja menjatuhkan tabel, Anda dapat memulihkannya menggunakan .undo drop table perintah . Agar perintah ini berhasil, Anda harus terlebih dahulu mengaktifkan properti pemulihan dalam kebijakan penyimpanan.
Penghapusan tidak sengaja terhadap tabel eksternal
Tabel eksternal adalah entitas skema kueri Kusto yang mereferensikan data yang disimpan di luar database. Penghapusan tabel eksternal hanya menghapus metadata tabel. Anda dapat memulihkannya dengan menjalankan kembali perintah pembuatan tabel. Gunakan kemampuan hapus lunak untuk melindungi dari penghapusan atau penimpaan tidak sengaja terhadap file/blob selama jangka waktu yang dikonfigurasikan pengguna.
Ketersediaan Tinggi Azure Data Explorer
Ketersediaan tinggi mengacu pada toleransi kesalahan Azure Data Explorer, komponennya, dan dependensi yang mendasar dalam wilayah Azure. Toleransi kesalahan ini menghindari titik kegagalan tunggal (SPOF) dalam implementasi. Di Azure Data Explorer, ketersediaan tinggi mencakup lapisan persistensi, lapisan komputasi, dan konfigurasi pengikut pemimpin.
Lapisan persistensi
Azure Data Explorer memanfaatkan Azure Storage sebagai lapisan persistensinya yang tahan lama. Azure Storage secara otomatis memberikan toleransi kegagalan, dengan pengaturan default yang menawarkan Penyimpanan Redundan Secara Lokal (LRS) dalam pusat data. Tiga replika dipertahankan. Jika replika hilang saat digunakan, replika lain disebarkan tanpa gangguan. Ketahanan lebih lanjut dimungkinkan dengan Zone Redundant Storage (ZRS) yang menempatkan replika secara cerdas di seluruh zona ketersediaan regional Azure untuk toleransi kesalahan maksimum dengan biaya tambahan. Penyimpanan yang diaktifkan ZRS secara otomatis dikonfigurasi saat kluster Azure Data Explorer disebarkan ke Zona Ketersediaan.
Lapisan komputasi
Azure Data Explorer adalah platform komputasi terdistribusi dan dapat memiliki dua hingga banyak simpul tergantung pada jenis peran skala dan simpul. Pada waktu provisi, pilih zona ketersediaan untuk mendistribusikan penyebaran simpul, di seluruh zona untuk ketahanan intra-wilayah maksimum. Kegagalan zona ketersediaan tidak akan mengakibatkan pemadaman lengkap tetapi sebaliknya, penurunan performa hingga pemulihan zona.
Konfigurasi kluster pemandu-pengikut
Azure Data Explorer menyediakan kemampuan pengikut opsional agar kluster pemimpin diikuti oleh kluster pengikut lain untuk akses baca-saja ke data dan metadata pemimpin. Perubahan pada pemimpin, seperti create, append, dan drop secara otomatis disinkronkan ke pengikut. Meskipun pemimpin dapat menjangkau wilayah Azure, kluster pengikut harus dihosting di wilayah yang sama dengan pemimpin. Jika kluster pemimpin tidak berfungsi atau database atau tabel tidak sengaja dihilangkan, kluster pengikut akan kehilangan akses hingga akses dipulihkan di pemimpin.
Pemadaman zona ketersediaan Azure
Zona ketersediaan Azure adalah lokasi fisik unik dalam wilayah Azure yang sama. Mereka dapat melindungi komputasi dan data kluster Azure Data Explorer dari kegagalan wilayah parsial. Kegagalan zona adalah skenario ketersediaan karena merupakan intra-wilayah.
Sematkan kluster Azure Data Explorer ke zona yang sama dengan sumber daya Azure terhubung lainnya. Untuk informasi selengkapnya tentang mengaktifkan zona ketersediaan, lihat membuat kluster.
Catatan
Penyebaran ke zona ketersediaan dimungkinkan saat membuat kluster atau dapat dimigrasikan nanti.
Pemadaman pusat data Azure
Zona ketersediaan Azure dilengkapi dengan biaya dan beberapa pelanggan memilih untuk menyebarkan tanpa redundansi zona. Dengan penyebaran Azure Data Explorer seperti itu, pemadaman pusat data Azure akan mengakibatkan pemadaman kluster. Oleh karena itu, menangani pemadaman pusat data Azure identik dengan pemadaman wilayah Azure.
Pemadaman wilayah Azure
Azure Data Explorer tidak memberikan perlindungan otomatis terhadap pemadaman seluruh wilayah Azure. Untuk meminimalkan dampak bisnis jika ada pemadaman seperti itu, beberapa kluster Azure Data Explorer di seluruh wilayah berpasangan Azure. Berdasarkan tujuan waktu pemulihan (RTO), tujuan titik pemulihan (RPO), serta pertimbangan upaya dan biaya, ada beberapa konfigurasi pemulihan bencana. Pengoptimalan biaya dan performa dimungkinkan dengan rekomendasi Azure Advisor dan konfigurasi skala otomatis.
Konfigurasi pemulihan bencana
Bagian ini merinci beberapa konfigurasi pemulihan bencana tergantung pada persyaratan ketahanan (RPO dan RTO), upaya yang diperlukan, dan biaya.
Tujuan waktu pemulihan (RTO) mengacu pada waktu untuk pulih dari gangguan. Misalnya, RTO 2 jam berarti aplikasi harus aktif dan berjalan dalam waktu dua jam setelah gangguan. Tujuan titik pemulihan (RPO) mengacu pada interval waktu yang mungkin berlalu selama gangguan sebelum kuantitas data hilang selama periode tersebut lebih besar dari ambang batas yang diizinkan. Misalnya, jika RPO adalah 24 jam, dan aplikasi memiliki data mulai dari 15 tahun yang lalu, mereka masih berada dalam parameter RPO yang disepakati.
Proses penyerapan, pemrosesan, dan kurasi membutuhkan desain yang rajin di muka saat merencanakan pemulihan bencana. Penyerapan mengacu pada data yang diintegrasikan ke dalam Azure Data Explorer dari berbagai sumber; pemrosesan mengacu pada transformasi dan aktivitas serupa; kurasi mengacu pada tampilan materialisasi, ekspor ke data lake, dan sebagainya.
Berikut ini adalah konfigurasi pemulihan bencana populer, dan masing-masing dijelaskan secara rinci di bawah ini.
- Konfigurasi Active-Active-Active (always-on)
- Konfigurasi Aktif-Aktif
- Konfigurasi siaga Active-Hot
- Konfigurasi kluster pemulihan data sesuai permintaan
Konfigurasi aktif-aktif-aktif
Konfigurasi ini juga disebut "always-on". Untuk penyebaran aplikasi penting tanpa toleransi untuk pemadaman, Anda harus menggunakan beberapa kluster Azure Data Explorer di seluruh wilayah berpasangan Azure. Siapkan penyerapan, pemrosesan, dan kurasi secara paralel dengan semua kluster. SKU kluster harus sama di seluruh wilayah. Azure akan memastikan bahwa pembaruan diluncurkan dan terhuyung di seluruh wilayah berpasangan Azure. Pemadaman wilayah Azure tidak akan menyebabkan pemadaman aplikasi. Anda mungkin mengalami beberapa latensi atau penurunan performa.
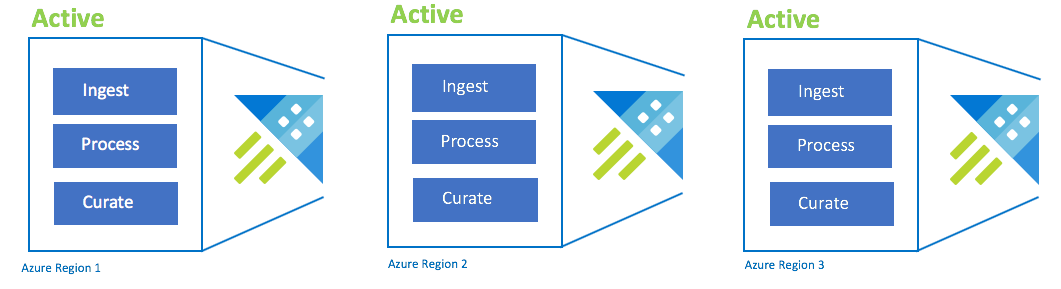
| Konfigurasi | RPO | RTO | Usaha | Biaya |
|---|---|---|---|---|
| Active-Active-Active-n | 0 jam | 0 jam | Lower | Tertinggi |
Konfigurasi Aktif-Aktif
Konfigurasi ini identik dengan konfigurasi aktif-aktif-aktif, tetapi hanya melibatkan dua wilayah berpasangan Azure. Konfigurasikan penyerapan, pemrosesan, dan kurasi ganda. Pengguna dirutekan ke wilayah terdekat. SKU kluster harus sama di seluruh wilayah.
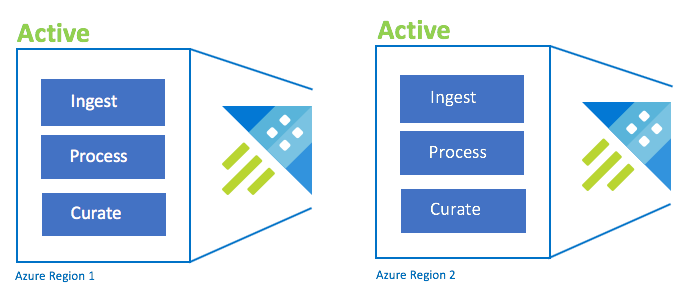
| Konfigurasi | RPO | RTO | Usaha | Biaya |
|---|---|---|---|---|
| Aktif-Aktif | 0 jam | 0 jam | Lower | Sangat Penting |
Konfigurasi siaga Active-Hot
Konfigurasi Active-Hot mirip dengan konfigurasi Active-Active dalam dual ingest, processing, dan curation. Meskipun kluster siaga online untuk penyerapan, proses, dan kurasi, kluster siaga tidak tersedia untuk kueri. Kluster siaga tidak perlu berada di SKU yang sama dengan kluster utama. Ini bisa dari SKU dan skala yang lebih kecil, yang dapat mengakibatkannya kurang berkinerja. Dalam skenario bencana, pengguna dialihkan ke kluster siaga, yang secara opsional dapat ditingkatkan skalanya untuk meningkatkan performa.
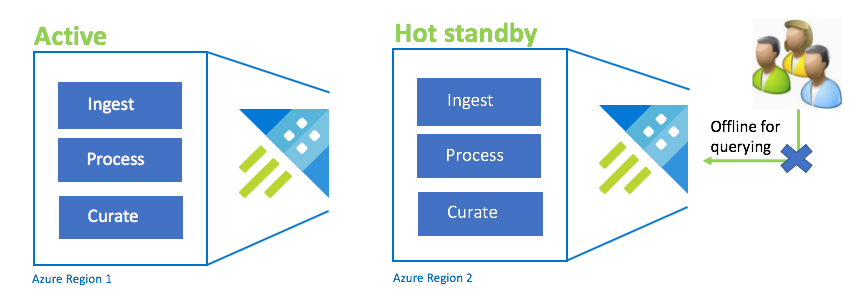
| Konfigurasi | RPO | RTO | Usaha | Biaya |
|---|---|---|---|---|
| Siaga Aktif-Panas | 0 jam | Kurang Penting | Medium | Medium |
Konfigurasi pemulihan data sesuai permintaan
Solusi ini menawarkan ketahanan paling sedikit (RPO dan RTO tertinggi), adalah biaya terendah dan tertinggi dalam upaya. Dalam konfigurasi ini, tidak ada kluster pemulihan data. Konfigurasikan ekspor berkelanjutan data yang dikumpulkan (kecuali data mentah dan menengah juga diperlukan) ke akun penyimpanan yang dikonfigurasi GRS (Geo Redundant Storage). Kluster pemulihan data dipisahkan jika ada skenario pemulihan bencana. Pada saat itu, DLL, konfigurasi, kebijakan, dan proses diterapkan. Data diserap dari penyimpanan dengan properti penyerapan kustoCreationTime untuk menaiki waktu penyerapan yang default ke waktu sistem.
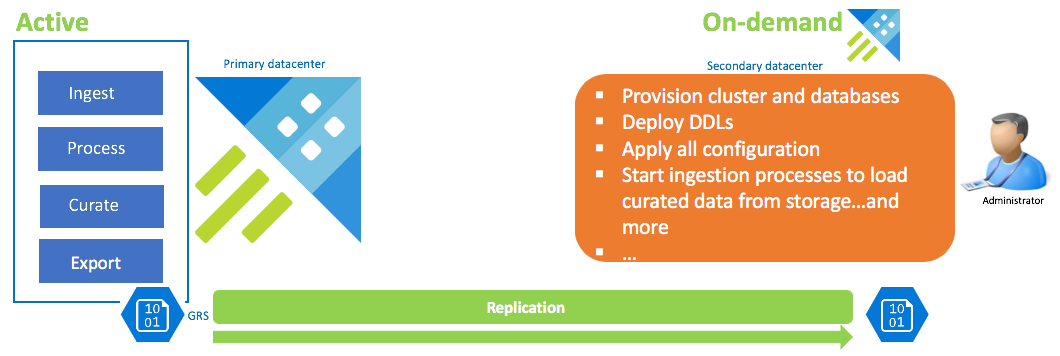
| Konfigurasi | RPO | RTO | Usaha | Biaya |
|---|---|---|---|---|
| Kluster pemulihan data sesuai permintaan | Tertinggi | Tertinggi | Tertinggi | Terendah |
Ringkasan opsi konfigurasi pemulihan bencana
| Konfigurasi | Ketahanan | RPO | RTO | Usaha | Biaya |
|---|---|---|---|---|---|
| Active-Active-Active-n | Tertinggi | 0 jam | 0 jam | Lower | Tertinggi |
| Aktif-Aktif | Sangat Penting | 0 jam | 0 jam | Lower | Sangat Penting |
| Siaga Aktif-Panas | Medium | 0 jam | Kurang Penting | Medium | Medium |
| Kluster pemulihan data sesuai permintaan | Terendah | Tertinggi | Tertinggi | Tertinggi | Terendah |
Praktik terbaik
Terlepas dari konfigurasi pemulihan bencana mana yang dipilih, ikuti praktik terbaik berikut:
- Semua objek, kebijakan, dan konfigurasi database harus dipertahankan dalam kontrol sumber sehingga dapat dirilis ke kluster dari alat otomatisasi rilis Anda. Untuk informasi selengkapnya, lihat Dukungan Azure DevOps untuk Azure Data Explorer.
- Merancang, mengembangkan, dan menerapkan rutinitas validasi untuk memastikan semua kluster sinkron dari perspektif data. Azure Data Explorer mendukung gabungan lintas kluster. Hitungan sederhana atau baris di seluruh tabel dapat membantu memvalidasi.
- Prosedur rilis harus melibatkan pemeriksaan dan keseimbangan tata kelola yang memastikan pencerminan kluster.
- Jadilah sepenuhnya kognizan dari apa yang diperlukan untuk membangun kluster dari awal.
- Buat daftar periksa unit penyebaran. Daftar Anda akan unik untuk kebutuhan Anda, tetapi harus mencakup: skrip penyebaran, koneksi penyerapan, alat BI, dan konfigurasi penting lainnya.