Menyalin secara massal dari database ke Azure Data Explorer dengan menggunakan templat Azure Data Factory
Azure Data Explorer adalah layanan analitik data yang cepat, dikelola sepenuhnya. Ini menawarkan analisis real-time pada volume besar data yang mengalir dari banyak sumber, seperti aplikasi, situs web, dan perangkat IoT.
Untuk menyalin data dari database di Oracle Server, Netezza, Teradata, atau SQL Server ke Azure Data Explorer, Anda harus memuat sejumlah besar data dari beberapa tabel. Biasanya, data harus dipartisi di setiap tabel sehingga Anda dapat memuat baris dengan beberapa alur secara paralel dari satu tabel. Artikel ini menjelaskan templat untuk digunakan dalam skenario ini.
Templat Azure Data Factory adalah alur Data Factory yang telah ditentukan sebelumnya. Templat ini dapat membantu Anda memulai dengan cepat dengan Data Factory dan mengurangi waktu pengembangan pada proyek integrasi data.
Anda membuat templat Salin Massal dari Database ke Azure Data Explorer dengan menggunakan aktivitas Pencarian dan ForEach . Untuk penyalinan data yang lebih cepat, Anda dapat menggunakan templat untuk membuat banyak alur per database atau per tabel.
Penting
Pastikan untuk menggunakan alat yang sesuai untuk kuantitas data yang ingin Anda salin.
- Gunakan templat Salin Massal dari Database ke Azure Data Explorer untuk menyalin data dalam jumlah besar dari database seperti server SQL dan Google BigQuery ke Azure Data Explorer.
- Gunakan alat Data Salin Data Factory untuk menyalin beberapa tabel dengan jumlah data kecil atau sedang ke Azure Data Explorer.
Prasyarat
- Langganan Azure. Membuat akun Azure gratis.
- Kluster dan database Azure Data Explorer. Membuat kluster dan database.
- Pabrik data. Membuat pabrik data.
- Sumber data.
Membuat ControlTableDataset
ControlTableDataset menunjukkan data apa yang akan disalin dari sumber ke tujuan dalam alur. Jumlah baris menunjukkan jumlah total alur yang diperlukan untuk menyalin data. Anda harus menentukan ControlTableDataset sebagai bagian dari database sumber.
Contoh format tabel sumber SQL Server diperlihatkan dalam kode berikut:
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
Elemen kode dijelaskan dalam tabel berikut:
| Properti | Deskripsi | Contoh |
|---|---|---|
| PartitionId | Urutan penyalinan | 1 |
| SourceQuery | Kueri yang menunjukkan data mana yang akan disalin selama runtime alur | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''> |
| ADXTableName | Nama tabel tujuan | MyAdxTable |
Jika ControlTableDataset Anda dalam format yang berbeda, buat ControlTableDataset yang sebanding untuk format Anda.
Menggunakan templat Salin Massal dari Database ke Azure Data Explorer
Di panel Mari kita mulai , pilih Buat alur dari templat untuk membuka panel Galeri templat.
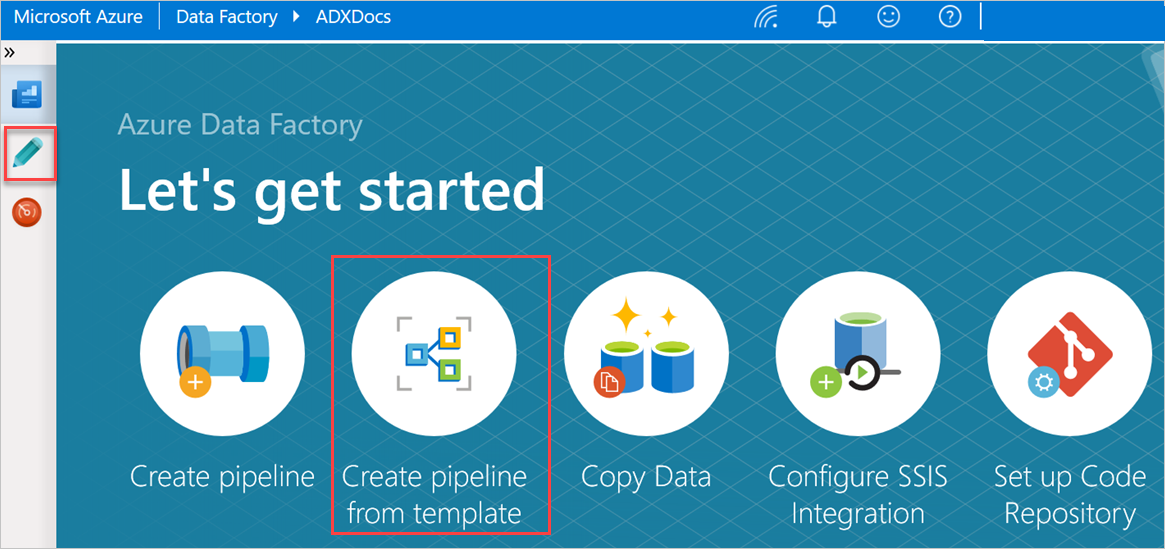
Pilih templat Salin Massal dari Database ke Azure Data Explorer.
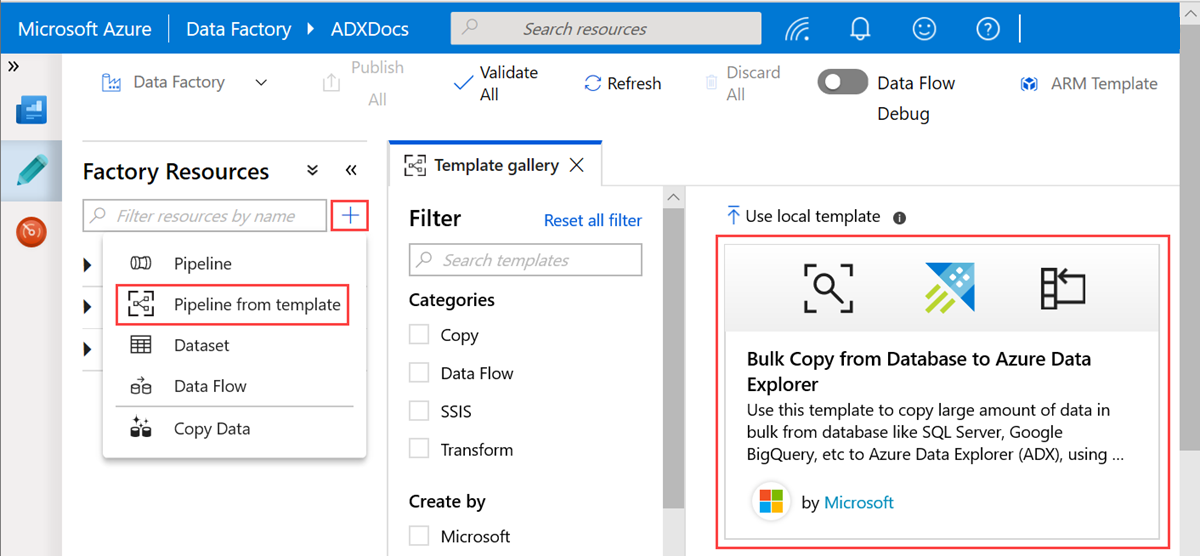
Di panel Salin Massal dari Database ke Azure Data Explorer , di bawah Input Pengguna, tentukan himpunan data Anda dengan melakukan hal berikut:
a. Di daftar drop-down ControlTableDataset, pilih layanan tertaut ke tabel kontrol yang menunjukkan data apa yang disalin dari sumber ke tujuan dan di mana data tersebut akan ditempatkan di tujuan.
b. Di daftar drop-down SourceDataset, pilih layanan tertaut ke database sumber.
c. Di daftar drop-down AzureDataExplorerTable, pilih tabel Azure Data Explorer. Jika himpunan data tidak ada, buat layanan tertaut Azure Data Explorer untuk menambahkan himpunan data.
d. Pilih Gunakan templat ini.
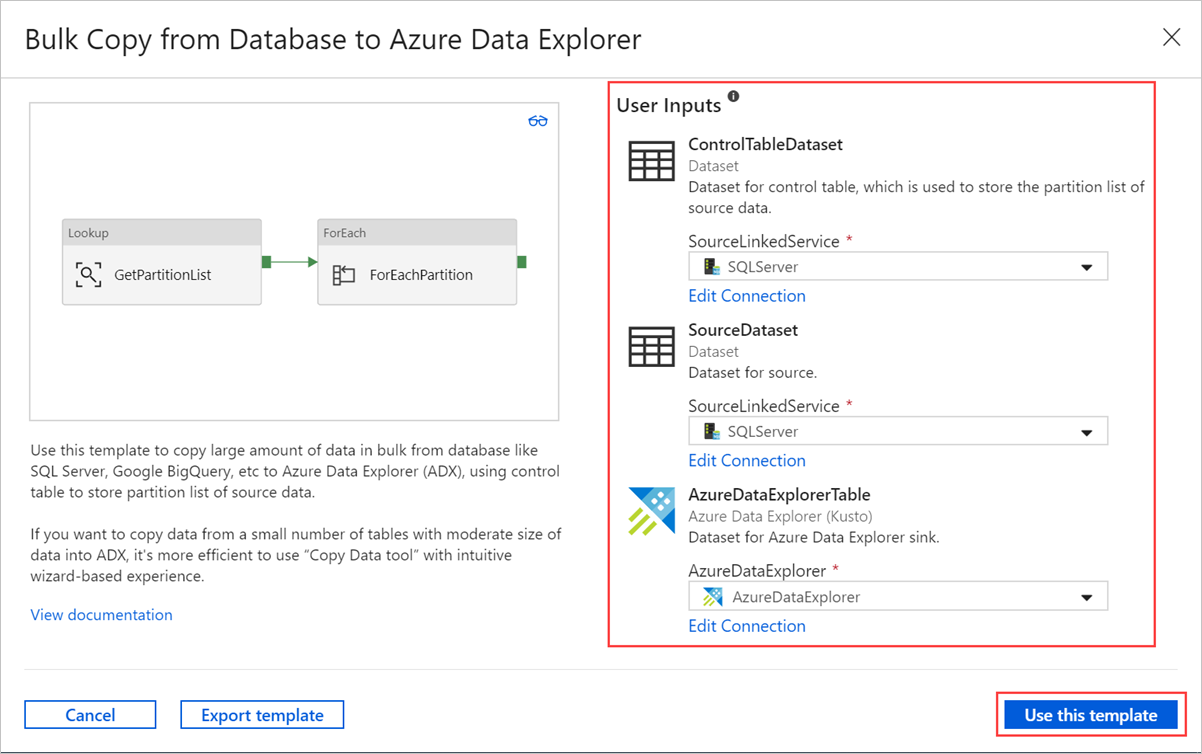
Pilih area di kanvas, di luar aktivitas, untuk mengakses alur templat. Pilih tab Parameter untuk memasukkan parameter untuk tabel, termasuk Nama (nama tabel kontrol) dan Nilai default (nama kolom).
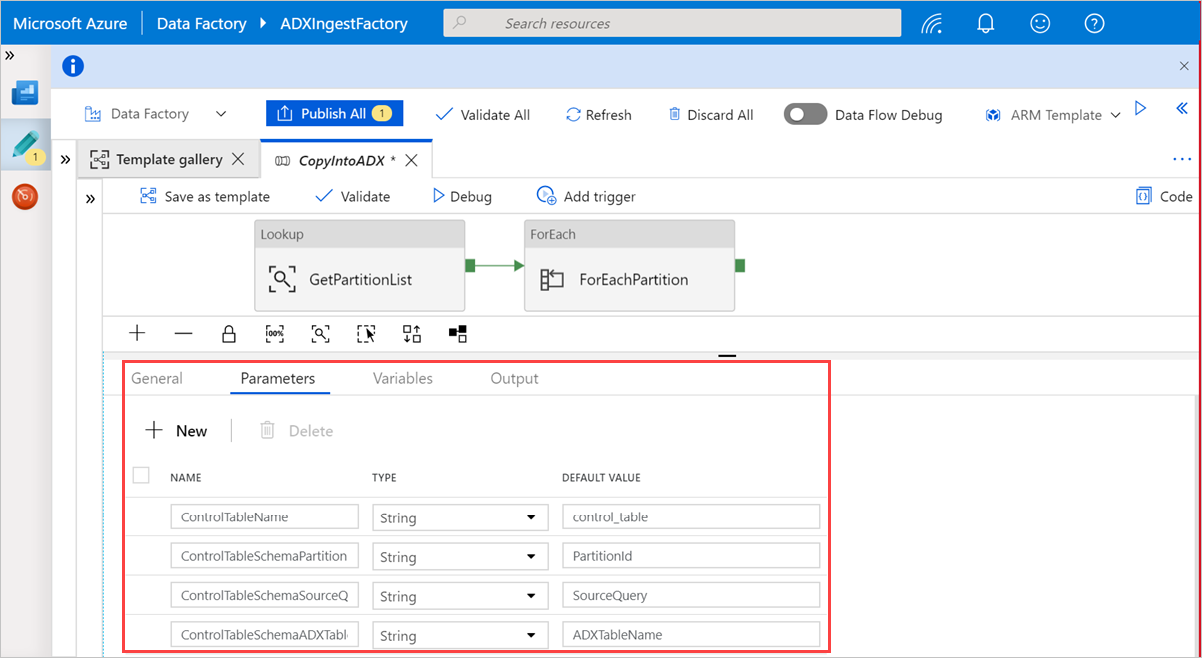
Di bawah Pencarian, pilih GetPartitionList untuk melihat pengaturan default. Kueri dibuat secara otomatis.
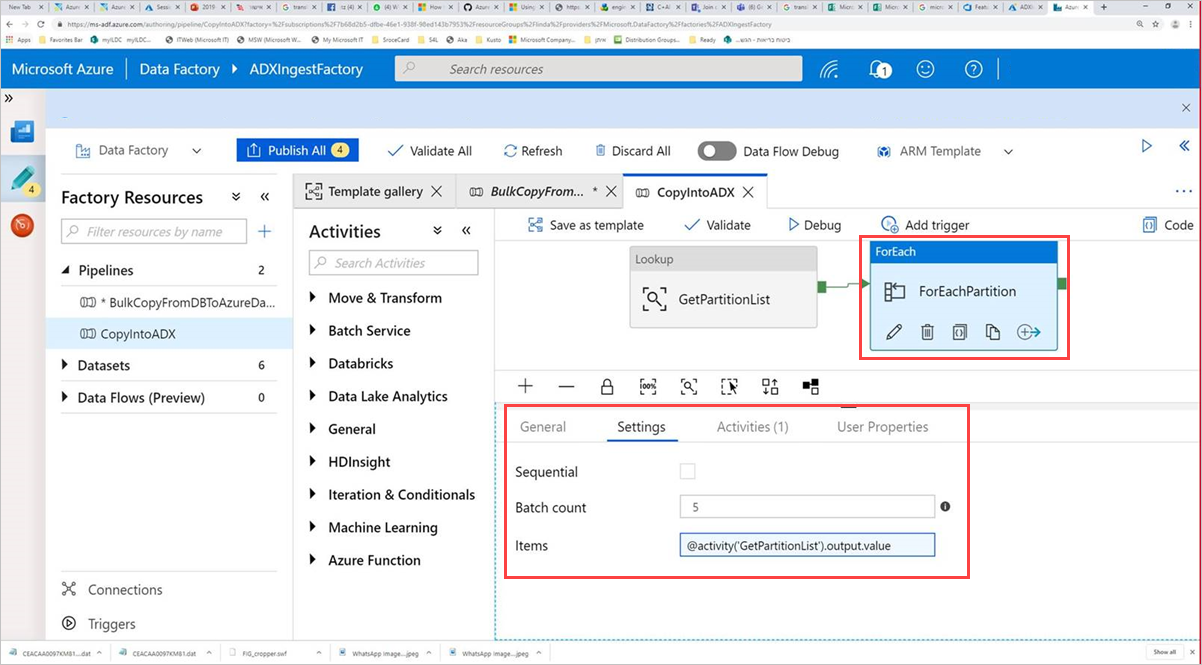
Pilih aktivitas Perintah, ForEachPartition, pilih tab Pengaturan , lalu lakukan hal berikut:
a. Dalam kotak Jumlah batch, masukkan angka dari 1 hingga 50. Pilihan ini menentukan jumlah alur yang berjalan secara paralel hingga jumlah baris ControlTableDataset tercapai.
b. Untuk memastikan bahwa batch alur berjalan secara paralel, jangan pilih kotak centang Berurutan.
Tip
Praktik terbaik adalah menjalankan banyak alur secara paralel sehingga data Anda dapat disalin dengan lebih cepat. Untuk meningkatkan efisiensi, partisi data dalam tabel sumber dan alokasikan satu partisi per alur, sesuai dengan tanggal dan tabel.
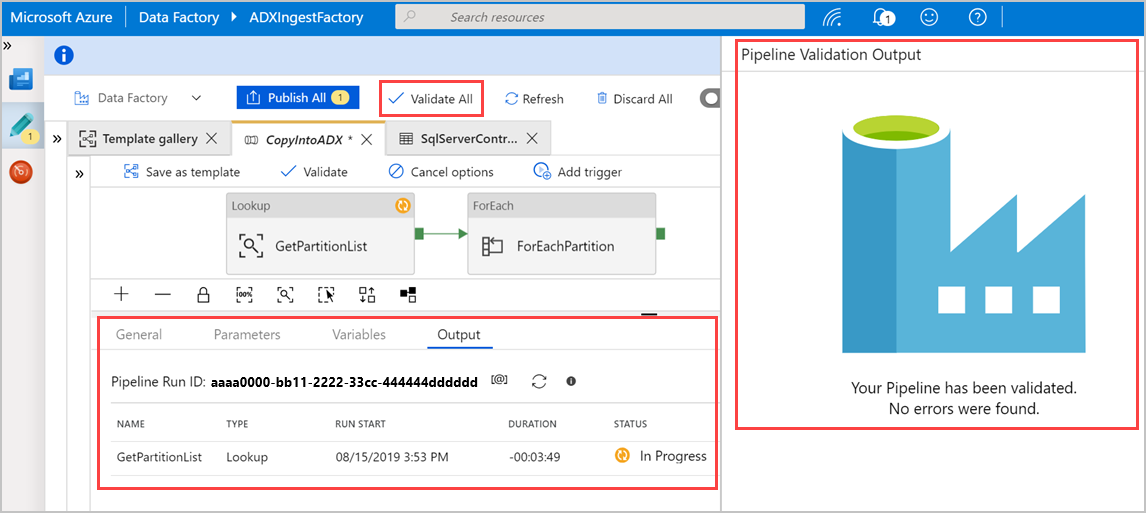
Pilih Validasi Semua untuk memvalidasi alur Azure Data Factory, lalu lihat hasilnya di panel Output Validasi Alur.
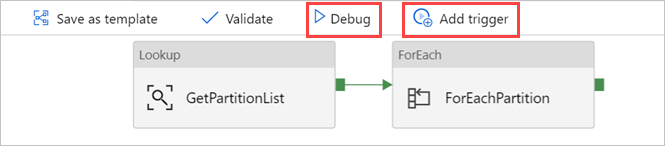
Jika perlu, pilih Debug, lalu pilih Tambahkan pemicu untuk menjalankan alur.
Anda sekarang dapat menggunakan templat untuk menyalin data dalam jumlah besar secara efisien dari database dan tabel Anda.
Konten terkait
- Pelajari tentang konektor Azure Data Explorer untuk Azure Data Factory.
- Edit layanan tertaut, himpunan data, dan alur di antarmuka pengguna Data Factory.
- Mengkueri data di antarmuka pengguna web Azure Data Explorer.