Menyerap data dari Apache Kafka ke Azure Data Explorer
Apache Kafka adalah platform streaming terdistribusi untuk membangun alur data streaming real-time yang memindahkan data antara sistem atau aplikasi dengan andal. Kafka Connect adalah alat untuk streaming data yang dapat diskalakan dan andal antara Apache Kafka dan sistem data lainnya. Kusto Kafka Sink berfungsi sebagai konektor dari Kafka dan tidak memerlukan penggunaan kode. Unduh jar konektor sink dari repositori Git atau Confluent Connector Hub.
Artikel ini menunjukkan cara menyerap data dengan Kafka, menggunakan penyiapan Docker mandiri untuk menyederhanakan kluster Kafka dan penyiapan kluster konektor Kafka.
Untuk informasi selengkapnya, lihat repositori Git konektor dan spesifikasi versi.
Prasyarat
- Langganan Azure. Membuat akun Azure gratis.
- Kluster dan database Azure Data Explorer dengan kebijakan cache dan retensi default ataudatabase KQL di Microsoft Fabric.
- Azure CLI.
- Docker dan Docker Compose.
Membuat perwakilan layanan Microsoft Entra
Perwakilan layanan Microsoft Entra dapat dibuat melalui portal Azure atau secara terprogram, seperti dalam contoh berikut.
Perwakilan layanan ini akan menjadi identitas yang digunakan oleh konektor untuk menulis data tabel Anda di Kusto. Anda nantinya akan memberikan izin bagi perwakilan layanan ini untuk mengakses sumber daya Kusto.
Masuk ke langganan Azure Anda melalui Azure CLI. Kemudian autentikasi di browser.
az loginPilih langganan untuk menghosting perwakilan. Langkah ini diperlukan saat Anda memiliki beberapa langganan.
az account set --subscription YOUR_SUBSCRIPTION_GUIDBuat perwakilan layanan. Dalam contoh ini, perwakilan layanan disebut
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Dari data JSON yang dikembalikan, salin
appId,password, dantenantuntuk digunakan di masa mendatang.{ "appId": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "displayName": "my-service-principal", "name": "my-service-principal", "password": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "tenant": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn" }
Anda telah membuat aplikasi Microsoft Entra dan perwakilan layanan.
Membuat tabel target
Dari lingkungan kueri Anda, buat tabel yang disebut
Stormsmenggunakan perintah berikut:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)Buat pemetaan
Storms_CSV_Mappingtabel terkait untuk data yang diserap menggunakan perintah berikut:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'Buat kebijakan batching penyerapan pada tabel untuk latensi penyerapan antrean yang dapat dikonfigurasi.
Tip
Kebijakan batching penyerapan adalah pengoptimal performa dan mencakup tiga parameter. Kondisi pertama yang dipenuhi memicu penyerapan ke dalam tabel Azure Data Explorer.
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'Gunakan perwakilan layanan dari Buat perwakilan layanan Microsoft Entra untuk memberikan izin untuk bekerja dengan database.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
Jalankan lab
Lab berikut dirancang untuk memberi Anda pengalaman mulai membuat data, menyiapkan konektor Kafka, dan mengalirkan data ini ke Azure Data Explorer dengan konektor. Anda kemudian dapat melihat data yang diserap.
Mengkloning repositori git
Kloning repositori git lab.
Buat direktori lokal di komputer Anda.
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holKloning repositori.
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
Isi repositori kloning
Jalankan perintah berikut untuk mencantumkan konten repositori kloning:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
Hasil pencarian ini adalah:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
Meninjau file dalam repositori kloning
Bagian berikut menjelaskan bagian penting dari file di pohon file di atas.
adx-sink-config.json
File ini berisi file properti sink Kusto tempat Anda akan memperbarui detail konfigurasi tertentu:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
Ganti nilai untuk atribut berikut sesuai penyiapan Data Explorer Azure Anda: aad.auth.authority, , aad.auth.appkeyaad.auth.appid, kusto.tables.topics.mapping (nama database), kusto.ingestion.url, dan kusto.query.url.
Konektor - Dockerfile
File ini memiliki perintah untuk menghasilkan gambar docker untuk instans konektor. Ini termasuk pengunduhan konektor dari direktori rilis repositori git.
Direktori storm-events-producer
Direktori ini memiliki program Go yang membaca file "StormEvents.csv" lokal dan menerbitkan data ke topik Kafka.
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
Memulai kontainer
Di terminal, mulai kontainer:
docker-compose upAplikasi produsen akan mulai mengirim peristiwa ke topik tersebut
storm-events. Anda akan melihat log yang mirip dengan log berikut:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....Untuk memeriksa log, jalankan perintah berikut di terminal terpisah:
docker-compose logs -f | grep kusto-connect
Memulai konektor
Gunakan panggilan Kafka Connect REST untuk memulai konektor.
Di terminal terpisah, luncurkan tugas sink dengan perintah berikut:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectorsUntuk memeriksa status, jalankan perintah berikut di terminal terpisah:
curl http://localhost:8083/connectors/storm/status
Konektor akan mulai mengantre proses penyerapan ke Azure Data Explorer.
Catatan
Jika Anda mengalami masalah konektor log, buat masalah.
Mengkueri dan meninjau data
Mengonfirmasi penyerapan data
Tunggu data tiba dalam
Stormstabel. Untuk mengonfirmasi transfer data, periksa jumlah baris:Storms | countKonfirmasikan bahwa tidak ada kegagalan dalam proses penyerapan:
.show ingestion failuresSetelah Anda melihat data, cobalah beberapa kueri.
Mengkueri data
Untuk melihat semua rekaman, jalankan kueri berikut ini:
StormsGunakan
wheredanprojectuntuk memfilter data tertentu:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdsummarizeGunakan operator:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart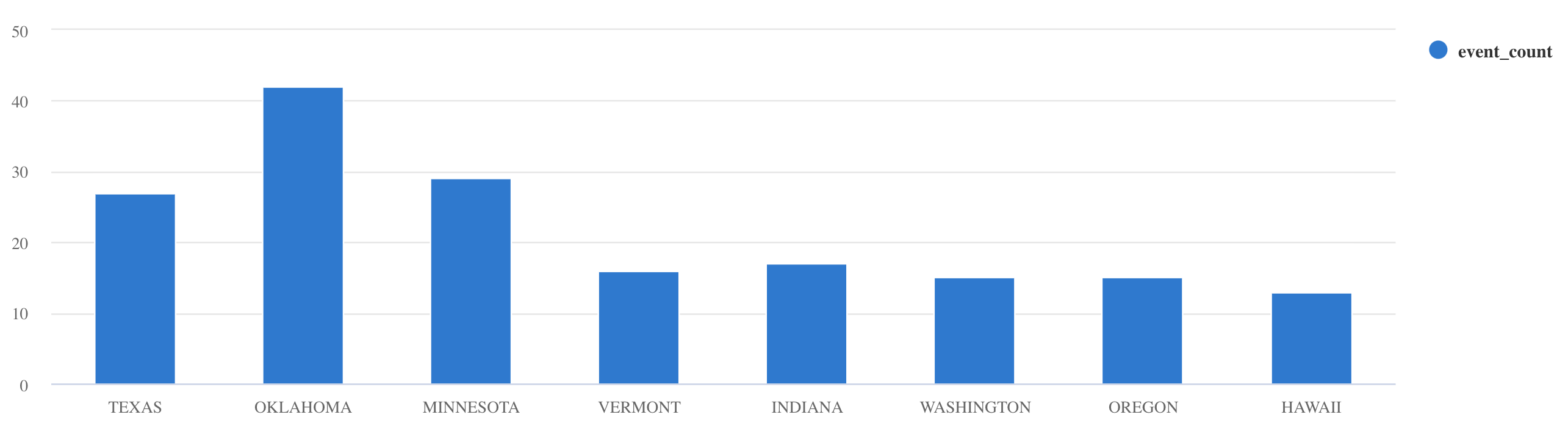
Untuk contoh dan panduan kueri lainnya, lihat Menulis kueri di dokumentasi KQL dan Bahasa Kueri Kusto.
Mengatur ulang
Untuk mereset, lakukan langkah-langkah berikut:
- Hentikan kontainer (
docker-compose down -v) - Hapus (
drop table Storms) - Membuat ulang
Stormstabel - Membuat ulang pemetaan tabel
- Hidupkan ulang kontainer (
docker-compose up)
Membersihkan sumber daya
Untuk menghapus sumber daya Azure Data Explorer, gunakan az cluster delete atau az Kusto database delete:
az kusto cluster delete -n <cluster name> -g <resource group name>
az kusto database delete -n <database name> --cluster-name <cluster name> -g <resource group name>
Menyetel konektor Kafka Sink
Sesuaikan konektor Kafka Sink untuk bekerja dengan kebijakan batching penyerapan:
- Sesuaikan batas ukuran Kafka Sink
flush.size.bytesmulai dari 1 MB, meningkat dengan kenaikan 10 MB atau 100 MB. - Saat menggunakan Kafka Sink, data diagregasi dua kali. Pada data sisi konektor diagregasi sesuai dengan pengaturan flush, dan di sisi layanan Azure Data Explorer sesuai dengan kebijakan batching. Jika waktu batching terlalu singkat dan tidak ada data yang dapat diserap oleh konektor dan layanan, waktu batching harus ditingkatkan. Atur ukuran batching pada 1 GB dan tingkatkan atau kurangi dengan kenaikan 100 MB sesuai kebutuhan. Misalnya, jika ukuran flush adalah 1 MB dan ukuran kebijakan batching adalah 100 MB, setelah batch 100-MB dikumpulkan oleh konektor Kafka Sink, batch 100 MB akan diserap oleh layanan Azure Data Explorer. Jika waktu kebijakan batching adalah 20 detik dan konektor Kafka Sink memerah 50 MB dalam periode 20 detik - maka layanan akan menyerap batch 50 MB.
- Anda dapat menskalakan dengan menambahkan instans dan partisi Kafka. Tingkatkan
tasks.maxke jumlah partisi. Buat partisi jika Anda memiliki cukup data untuk menghasilkan blob ukuranflush.size.bytespengaturan. Jika blob lebih kecil, batch diproses ketika mencapai batas waktu, sehingga partisi tidak akan menerima throughput yang cukup. Sejumlah besar partisi berarti lebih banyak pemrosesan overhead.
Konten terkait
- Pelajari selengkapnya tentang arsitektur Big data.
- Pelajari cara menyerap data sampel berformat JSON ke Azure Data Explorer.
- Untuk lab Kafka tambahan:
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk