Menerapkan DataOps ke Azure Data Factory
BERLAKU UNTUK: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Azure Data Factory adalah layanan Integrasi Data dan ETL Microsoft di cloud. Makalah ini menyediakan panduan untuk DataOps di pabrik data. Ini tidak dimaksudkan untuk menjadi tutorial lengkap tentang CI/CD, Git, atau DevOps. Sebaliknya, Anda akan menemukan panduan tim pabrik data untuk mencapai DataOps dalam layanan dengan referensi ke tautan implementasi terperinci untuk praktik terbaik penyebaran pabrik data, manajemen pabrik, dan tata kelola. Ada bagian sumber daya di akhir makalah ini dengan tautan ke tutorial.
Apa itu DataOps?
DataOps adalah proses yang dilakukan organisasi data untuk manajemen data kolaboratif yang dimaksudkan untuk memberikan nilai yang lebih cepat kepada pembuat keputusan.
Gartner memberikan definisi yang jelas dari DataOps ini:
DataOps adalah praktik manajemen data kolaboratif yang berfokus pada peningkatan komunikasi, integrasi, dan otomatisasi aliran data antara manajer data dan konsumen data di seluruh organisasi. Tujuan DataOps adalah untuk memberikan nilai lebih cepat dengan membuat manajemen pengiriman dan perubahan data, model data, dan artefak terkait yang dapat diprediksi. DataOps menggunakan teknologi untuk mengotomatiskan desain, penyebaran, dan manajemen pengiriman data dengan tingkat tata kelola yang sesuai dan menggunakan metadata untuk meningkatkan kegunaan dan nilai data di lingkungan dinamis.
Bagaimana Anda mencapai DataOps di Azure Data Factory?
Azure Data Factory menyediakan paradigma alur data berbasis visual untuk membangun integrasi data skala cloud dan proyek ETL dengan mudah. Pabrik data bergantung pada integrasi asli dengan alat kontrol versi yang matang seperti GitHub dan Azure DevOps, serta ekosistem Azure yang lebih luas, untuk menyediakan banyak fitur bawaan untuk memfasilitasi DataOps yang mencakup kolaborasi, tata kelola, dan hubungan artefak yang kaya.
Secara khusus, setelah Anda membawa repositori GitHub atau Azure DevOps Anda sendiri ke dalam pabrik data, layanan ini menyediakan opsi UI bawaan intuitif untuk perintah umum, seperti penerapan, menyimpan artefak, dan kontrol versi. Layanan ini juga menyediakan opsi untuk menyediakan PRAKTIK terbaik cek masuk CI/CD dan kode, untuk melindungi kewarasan dan kesehatan lingkungan produksi Anda.
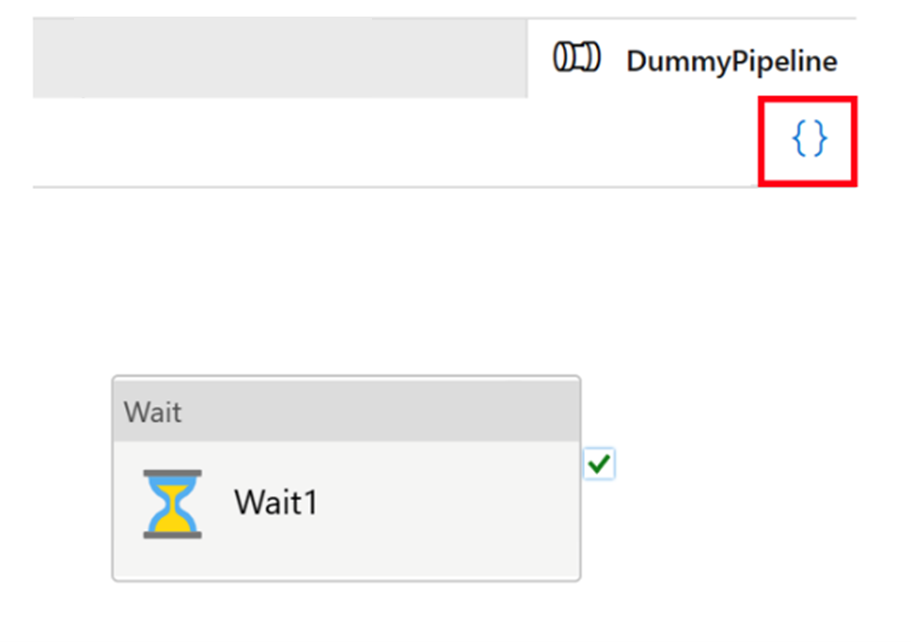
"Kode" di Azure Data Factory
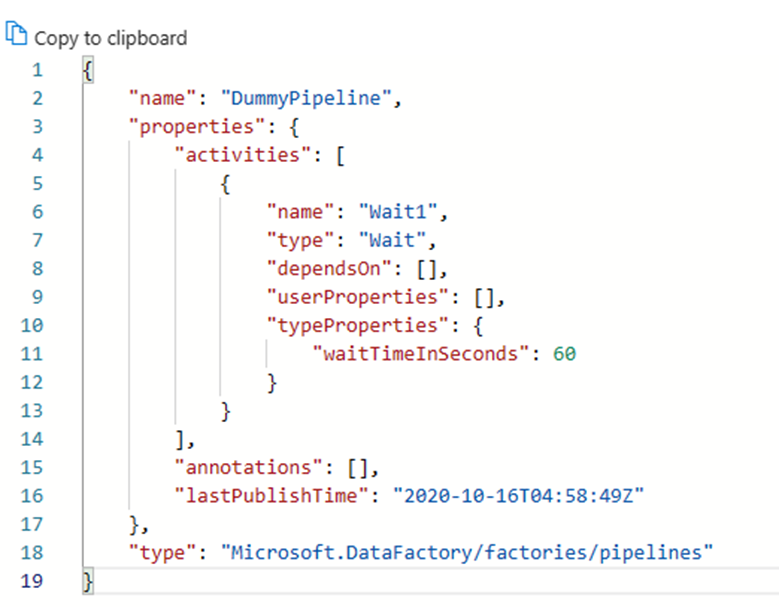
Semua artefak di Azure Data Factory, baik alur, layanan tertaut, pemicu, dll. memiliki representasi "kode" yang sesuai di JSON di balik integrasi UI visual. Artefak ini bertindak sesuai dengan standar templat Azure Resource Manager. Anda dapat menemukan kode dengan mengklik ikon tanda kurung siku di kanan atas kanvas. Contoh "kode" JSON akan terlihat seperti ini:
Mode langsung dan kontrol versi Git
Setiap pabrik memiliki satu sumber kebenaran tunggal: alur, layanan tertaut, dan definisi pemicu yang disimpan dalam layanan. Sumber kebenaran ini adalah apa yang dijalankan alur dan apa yang menentukan perilaku pemicu. Jika Anda berada dalam mode langsung, setiap kali Anda menerbitkan, Anda langsung memodifikasi satu sumber kebenaran. Gambar berikut menunjukkan seperti apa tombol Terbitkan Semua dalam mode langsung.

Mode langsung dapat nyaman untuk orang tunggal yang bekerja di proyek sampingan, karena memungkinkan pengembang untuk melihat efek langsung dari perubahan kode mereka. Namun, tidak disarankan bagi tim pengembang yang mengerjakan proyek kerja tingkat produksi. Bahayanya termasuk jari gemuk, penghapusan sumber daya penting yang tidak disengaja, penerbitan kode yang belum diucapkan, dll., hanya untuk beberapa nama. Saat mengerjakan proyek dan platform misi penting, pertimbangkan untuk membawa repositori Git dan menggunakan mode Git di pabrik data untuk menyederhanakan proses pengembangan. Kontrol versi dan kemampuan check-in terjaga dari mode Git membantu Anda mencegah sebagian besar, jika tidak semua, dari kecelakaan yang terkait dengan menyentuh mode langsung secara langsung.
Catatan
Dalam mode Git, tombol Terbitkan atau Terbitkan Semua akan digantikan oleh Simpan atau Simpan Semua, dan perubahan Anda diterapkan pada cabang Anda sendiri (tidak secara langsung mengubah basis kode langsung).
Menyiapkan integrasi GitHub dan Azure DevOps
Di Azure Data Factory, sangat disarankan untuk menyimpan repositori Anda di GitHub atau Azure DevOps. Layanan ini sepenuhnya mendukung metode dan pilihan repositori mana yang akan digunakan tergantung pada standar organisasi individual Anda. Ada dua metode untuk menyiapkan repositori baru atau untuk menyambungkan ke repositori yang ada: menggunakan portal Azure atau membuat dari antarmuka pengguna Azure Data Factory Studio
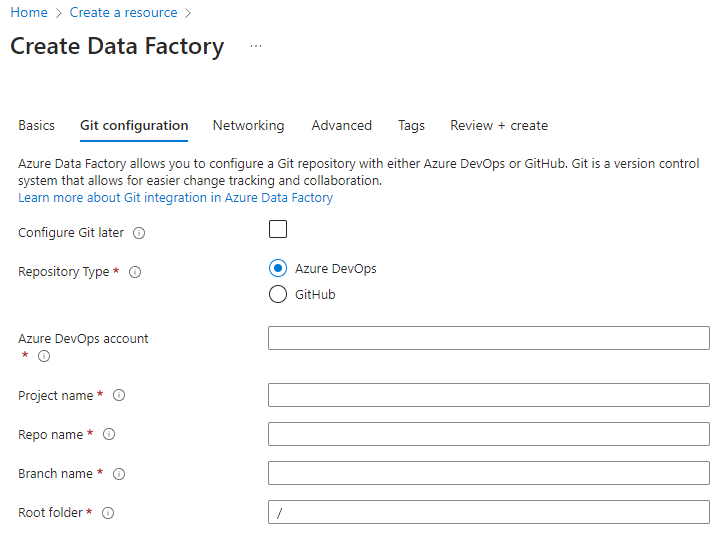
pembuatan pabrik portal Azure
Saat Anda membuat pabrik data baru dari portal Azure, repositori Git default adalah Azure DevOps. Anda juga dapat memilih GitHub sebagai repositori dan mengonfigurasi pengaturan repositori Anda.
Dari portal Azure, pilih jenis repositori dan masukkan nama repositori dan cabang untuk membuat pabrik baru yang terintegrasi secara asli dengan Git.
Memberlakukan penggunaan Git dengan Azure Policy di organisasi Anda
Penggunaan Git dalam proyek Azure Data Factory Anda adalah praktik terbaik yang sangat direkomendasikan. Bahkan jika Anda tidak menerapkan proses CI/CD lengkap, integrasi Git dengan ADF memungkinkan penyimpanan artefak sumber daya Anda di lingkungan kotak pasir Anda sendiri (cabang Git) tempat Anda dapat menguji perubahan Anda secara independen dari cabang pabrik lainnya. Anda dapat menggunakan Azure Policy untuk memberlakukan penggunaan Git di pabrik organisasi Anda.
Azure Data Factory Studio
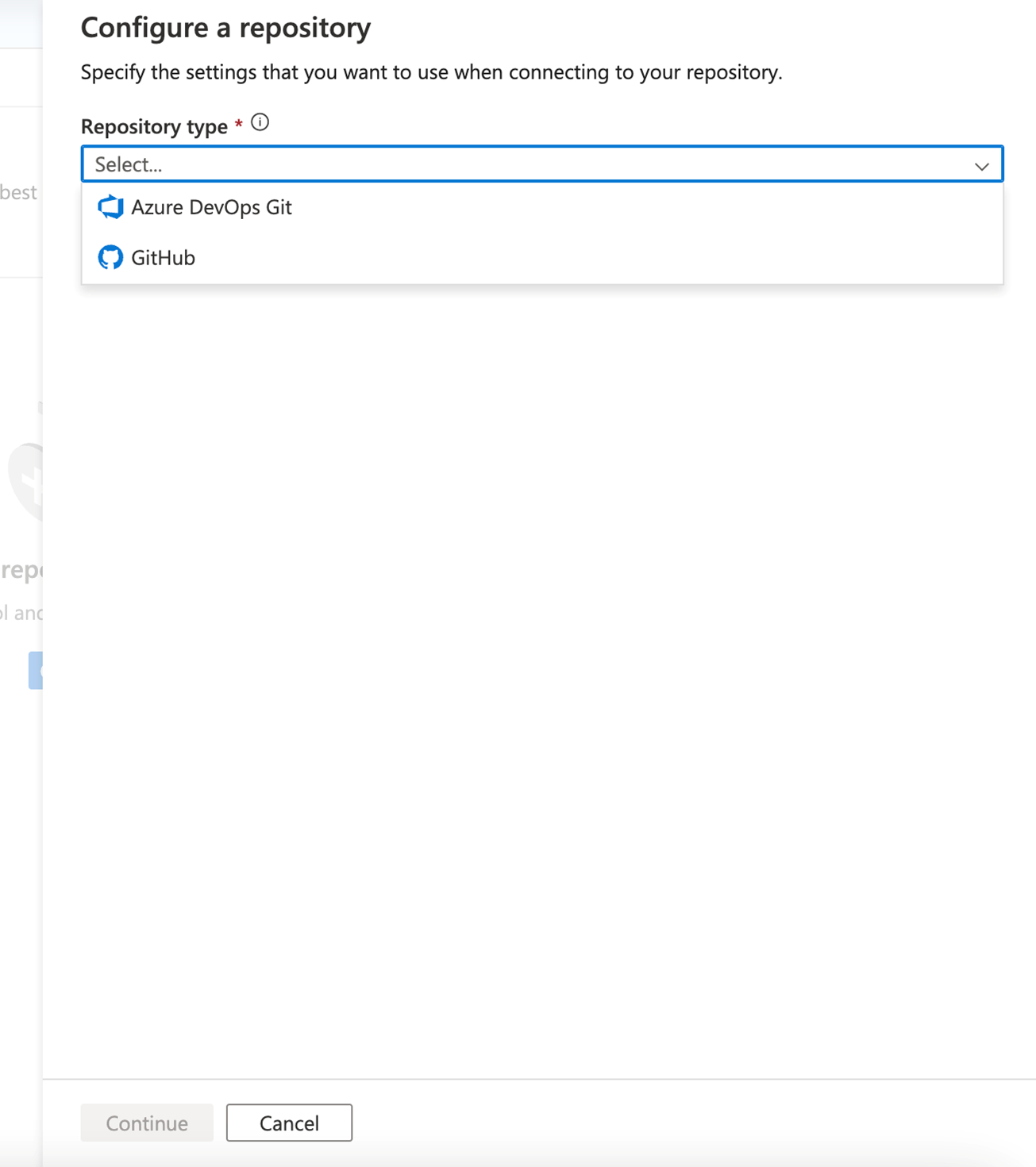
Setelah membuat pabrik data, Anda juga dapat menyambungkan ke repositori melalui Azure Data Factory Studio. Di tab Kelola , Anda akan melihat opsi untuk mengonfigurasi pengaturan repositori dan repositori Anda.

Melalui proses terpandu, Anda diarahkan melalui serangkaian langkah untuk membantu Anda dengan mudah mengonfigurasi dan terhubung ke repositori pilihan Anda. Setelah sepenuhnya disiapkan, Anda dapat mulai bekerja secara kolaboratif dan menyimpan sumber daya Anda ke repositori Anda.
Integrasi Berkelanjutan dan Penyediaan Berkelanjutan (CI/CD)
CI/CD adalah paradigma pengembangan kode di mana perubahan diperiksa dan diuji saat mereka bergerak melalui berbagai tahap - pengembangan, pengujian, penahapan, dll. Setelah ditinjau dan diuji melalui setiap tahap mereka akhirnya diterbitkan ke basis kode langsung di lingkungan produksi.
Integrasi berkelanjutan (CI) adalah praktik pengujian dan validasi secara otomatis setiap kali pengembang membuat perubahan pada basis kode Anda. Pengiriman berkelanjutan (CD) berarti bahwa setelah pengujian Integrasi Berkelanjutan berhasil, perubahan dibawa ke tahap berikutnya terus menerus.
Seperti yang dibahas secara singkat sebelumnya, "kode" di Azure Data Factory mengambil bentuk templat Azure Resource Manager JSON. Oleh karena itu, perubahan melalui proses integrasi dan pengiriman berkelanjutan (CI/CD) terdiri dari penambahan, penghapusan, dan pengeditan pada blob JSON.
Eksekusi alur di Azure Data Factory
Sebelum berbicara tentang CI/CD di Azure Data Factory, pertama-tama kita perlu berbicara tentang bagaimana layanan menjalankan alur. Sebelum pabrik data menjalankan alur, pabrik data melakukan hal-hal berikut:
- Menarik definisi terbaru yang diterbitkan dari alur, dan aset terkaitnya, seperti himpunan data, layanan tertaut, dll.
- Mengkompilasinya ke tindakan; jika pabrik data menjalankannya baru-baru ini, ia mengambil tindakan dari kompilasi cache.
- Menjalankan alur.
Menjalankan alur memerlukan langkah-langkah berikut:
- Layanan mengambil rekam jepret titik waktu dari definisi alur.
- Sepanjang durasi alur, definisi tidak berubah.
- Bahkan jika alur Anda berjalan untuk waktu yang lama, alur tersebut tidak terpengaruh oleh perubahan berikutnya yang dilakukan setelah dimulai. Jika Anda menerbitkan perubahan pada layanan tertaut, alur, dll., selama proses, ini tidak memengaruhi eksekusi yang sedang berlangsung.
- Saat Anda menerbitkan perubahan, eksekusi berikutnya dimulai setelah publikasi menggunakan definisi yang diperbarui.
Penerbitan di Azure Data Factory
Terlepas dari apakah Anda menyebarkan alur dengan Alur Rilis Azure untuk mengotomatiskan penerbitan, atau dengan penyebaran manual templat Resource Manager, di backend, penerbitan adalah serangkaian operasi buat/perbarui pada himpunan data, layanan tertaut, alur, dan pemicu, untuk setiap artefak. Efeknya sama dengan melakukan panggilan Rest API yang mendasar secara langsung.
Beberapa hal berasal dari tindakan di sini:
- Semua panggilan API ini sinkron, yang berarti bahwa panggilan hanya kembali ketika penerbitan berhasil/gagal. Tidak akan ada status penyebaran parsial untuk artefak.
- Panggilan API berurutan dalam jumlah besar. Kami mencoba untuk menyejajarkan panggilan, sambil mempertahankan dependensi referensial artefak. Urutan penyebaran adalah layanan tertaut -> himpunan data/runtime integrasi -> alur -> pemicu. Urutan ini memastikan bahwa artefak dependen dapat mereferensikan dependensinya dengan benar. Misalnya, alur bergantung pada himpunan data sehingga pabrik data menyebarkannya setelah himpunan data.
- Penyebaran layanan tertaut, himpunan data, dll. independen dari alur. Ada situasi di mana pabrik data memperbarui layanan tertaut sebelum pembaruan alur. Kita akan berbicara tentang situasi ini di bagian Kapan Harus Menghentikan Pemicu.
- Penyebaran tidak akan menghapus artefak dari pabrik. Anda perlu secara eksplisit memanggil API penghapusan untuk setiap jenis artefak (alur, himpunan data, layanan tertaut, dll.) untuk membersihkan pabrik. Lihat contoh skrip pasca penyebaran dari Azure Data Factory misalnya.
- Bahkan jika Anda belum menyentuh alur, himpunan data, atau layanan tertaut, layanan tersebut masih memanggil panggilan API pembaruan cepat ke pabrik.
Pemicu penerbitan
- Pemicu memiliki status: dimulai atau dihentikan.
- Anda tidak dapat membuat perubahan pada pemicu dalam mode mulai . Anda perlu menghentikan pemicu sebelum menerbitkan perubahan apa pun.
- Anda dapat memanggil API Buat atau Perbarui Pemicu pada pemicu dalam mode mulai .
- Jika payload berubah, API gagal.
- Jika payload tetap tidak berubah, API berhasil.
- Perilaku ini berdampak besar pada kapan harus menghentikan pemicu.
Kapan harus menghentikan pemicu
Ketika datang ke penyebaran ke pabrik data produksi, dengan pemicu langsung memulai eksekusi alur sepanjang waktu, pertanyaannya menjadi "Haruskah kita menghentikannya?".
Jawaban singkatnya adalah bahwa hanya dalam beberapa skenario berikut yang harus Anda pertimbangkan untuk menghentikan pemicu:
- Anda perlu menghentikan pemicu jika Memperbarui definisi pemicu, termasuk bidang seperti tanggal akhir, frekuensi, dan asosiasi alur.
- Disarankan untuk menghentikan pemicu jika Anda memperbarui himpunan data atau layanan tertaut yang direferensikan dalam alur langsung. Misalnya, jika Anda memutar kredensial untuk SQL Server.
- Anda dapat memilih untuk menghentikan pemicu jika alur terkait melemparkan kesalahan dan gagal dan membebani server Anda.
Berikut adalah beberapa poin yang perlu dipertimbangkan mengenai menghentikan pemicu:
- Seperti yang dijelaskan di bagian Alur Berjalan di Azure Data Factory, ketika pemicu memulai eksekusi alur, dibutuhkan rekam jepret alur, himpunan data, runtime integrasi, dan definisi layanan tertaut. Jika alur berjalan sebelum perubahan terisi ke backend, pemicu memulai eksekusi dengan versi lama. Dalam kebanyakan kasus, ini harus baik-baik saja.
- Seperti yang dijelaskan di bagian Pemicu Penerbitan. Saat pemicu dalam status dimulai , pemicu tidak dapat diperbarui. Oleh karena itu, jika Anda perlu mengubah detail tentang definisi pemicu, hentikan pemicu sebelum menerbitkan perubahan.
- Seperti yang dijelaskan di bagian Penerbitan di Azure Data Factory, modifikasi pada himpunan data atau layanan tertaut diterbitkan sebelum alur berubah. Untuk memastikan eksekusi alur menggunakan kredensial yang benar dan berkomunikasi dengan server yang tepat, kami sarankan Anda menghentikan pemicu terkait juga.
Menyiapkan perubahan "kode"
Kami menyarankan agar Anda mengikuti praktik terbaik ini untuk permintaan pull.
- Setiap pengembang harus bekerja pada cabang individu mereka sendiri, dan pada akhir hari, membuat permintaan pull ke cabang utama repositori. Lihat tutorial tentang permintaan pull di GitHub dan DevOps.
- Ketika penjaga gerbang menyetujui permintaan pull dan menggabungkan perubahan ke cabang utama, proses CI/CD dapat dimulai. Ada dua metode yang disarankan untuk mempromosikan perubahan di seluruh lingkungan: otomatis dan manual.
- Setelah siap memulai alur CI/CD, Anda dapat melakukannya secara umum menggunakan Azure Pipeline Release atau membuat penyebaran alur individual tertentu menggunakan utilitas sumber terbuka ini dari Azure Player.
Penyebaran perubahan otomatis
Untuk membantu penyebaran otomatis, sebaiknya gunakan paket npm utilitas Azure Data Factory. Menggunakan paket npm membantu memvalidasi semua sumber daya dalam alur dan menghasilkan templat ARM untuk pengguna.
Untuk mulai menggunakan paket npm utilitas Azure Data Factory, lihat Penerbitan otomatis untuk integrasi dan pengiriman berkelanjutan.
Penyebaran perubahan manual
Setelah menggabungkan cabang kembali ke cabang kolaborasi utama di repositori Git, Anda dapat menerbitkan perubahan secara manual ke layanan Azure Data Factory langsung. Layanan ini menyediakan kontrol UI atas penerbitan dari pabrik non-pengembangan dengan opsi Nonaktifkan penerbitan (dari ADF Studio).
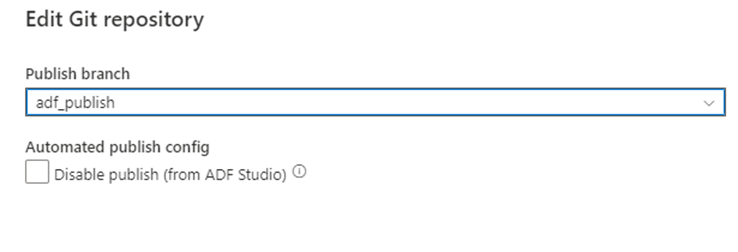
Penyebaran selektif
Penyebaran selektif bergantung pada fitur GitHub dan Azure DevOps, yang dikenal sebagai pemilihan ceri. Fitur ini memungkinkan Anda untuk menyebarkan hanya perubahan tertentu tetapi tidak yang lain. Misalnya, satu pengembang telah membuat perubahan pada beberapa alur, tetapi untuk penyebaran hari ini, kami mungkin hanya ingin menyebarkan perubahan pada satu alur.
Ikuti tutorial dari Azure DevOps dan GitHub untuk memilih penerapan yang relevan dengan alur yang Anda butuhkan. Pastikan bahwa semua perubahan, termasuk perubahan relevan yang dilakukan pada pemicu, layanan tertaut, dan dependensi yang terkait dengan alur, telah dipilih.
Setelah ceri memilih perubahan dan digabungkan ke alur kolaborasi utama, Anda dapat memulai proses CI/CD untuk perubahan yang diusulkan. Informasi tambahan tentang cara perbaikan panas, pemilihan ceri, atau menggunakan kerangka kerja eksternal untuk penyebaran selektif seperti yang dijelaskan di bagian Pengujian otomatis di artikel ini.
Pengujian Unit
Pengujian unit adalah bagian penting dari proses pengembangan alur baru atau mengedit artefak pabrik data yang ada, yang berfokus pada komponen pengujian kode. Data Factory memungkinkan pengujian unit individual di tingkat artefak alur dan aliran data dengan menggunakan fitur debug alur.

Saat mengembangkan aliran data, Anda akan dapat memperoleh wawasan tentang setiap transformasi individu dan perubahan kode dengan menggunakan fitur pratinjau data untuk mencapai pengujian unit sebelum menyebarkan perubahan Anda pada produksi.

Layanan ini memberikan umpan balik langsung dan interaktif tentang aktivitas alur Anda di UI saat penelusuran kesalahan dan pengujian unit di Azure Data Factory.
Pengujian otomatis
Ada beberapa alat yang tersedia untuk pengujian otomatis yang dapat Anda gunakan dengan Azure Data Factory. Karena layanan menyimpan objek dalam layanan sebagai entitas JSON, akan lebih mudah untuk menggunakan kerangka kerja pengujian unit .NET sumber terbuka NUnit dengan Visual Studio. Lihat postingan ini Menyiapkan pengujian otomatis untuk Azure Data Factory yang memberikan penjelasan mendalam tentang cara menyiapkan lingkungan pengujian unit otomatis untuk pabrik Anda. (Terima kasih khusus kepada Richard Swinbank untuk izin menggunakan blog ini.)
Pelanggan juga dapat menjalankan alur TEST dengan PowerShell atau AZ CLI sebagai bagian dari proses CI/CD untuk langkah-langkah pra dan pasca penyebaran.
Kekuatan utama pabrik data terletak pada parameterisasi himpunan datanya. Fitur ini memberdayakan pelanggan untuk menjalankan alur yang sama dengan himpunan data yang berbeda untuk memastikan pengembangan baru mereka memenuhi semua persyaratan sumber dan tujuan.
Kerangka kerja CI/CD lainnya untuk Azure Data Factory
Seperti yang dijelaskan sebelumnya, integrasi Git bawaan tersedia secara asli melalui antarmuka pengguna Azure Data Factory termasuk penggabungan, percabangan, perbandingan, dan publikasi. Namun, ada kerangka kerja CI/CD berguna lainnya yang populer di komunitas Azure, yang menyediakan mekanisme alternatif untuk memberikan kemampuan serupa. Metodologi Git Azure Data Factory didasarkan pada templat ARM, sedangkan kerangka kerja seperti ADFTools oleh Kamil Nowinski mengambil pendekatan yang berbeda dengan mengandalkan artefak JSON individual dari pabrik Anda sebagai gantinya. Teknisi data yang paham di Azure DevOps dan lebih suka bekerja di lingkungan tersebut (dibandingkan dengan pendekatan UI berbasis ARM yang ditawarkan layanan di luar kotak) mungkin menemukan bahwa kerangka kerja ini berfungsi dengan baik untuk mereka dan untuk skenario umum seperti penyebaran parsial. Kerangka kerja ini juga dapat menyederhanakan penanganan pemicu saat menyebarkan ke lingkungan yang telah menjalankan status pemicu.
Tata kelola data di Azure Data Factory
Aspek penting dari DataOps yang efektif adalah tata kelola data. Untuk alat ETL integrasi data, menyediakan silsilah data dan hubungan artefak dapat memberikan informasi penting bagi teknisi data untuk memahami dampak perubahan hilir. Pabrik data menyediakan tampilan artefak terkait bawaan yang merupakan implementasi pabrik Anda.
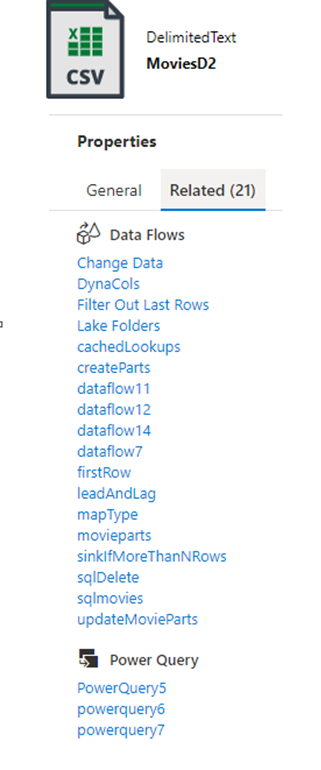
Integrasi asli dengan Microsoft Purview lebih lanjut menyediakan silsilah data, analisis dampak, dan katalog data.
Microsoft Purview menyediakan solusi tata kelola data terpadu untuk membantu mengelola dan mengatur data lokal, multicloud, dan perangkat lunak sebagai layanan (SaaS). Ini memungkinkan Anda untuk dengan mudah membuat peta holistik dan terbaru dari lanskap data Anda dengan penemuan data otomatis, klasifikasi data sensitif, dan silsilah data end-to-end. Fitur-fitur ini memungkinkan konsumen data untuk mengakses manajemen data yang berharga dan dapat dipercaya.
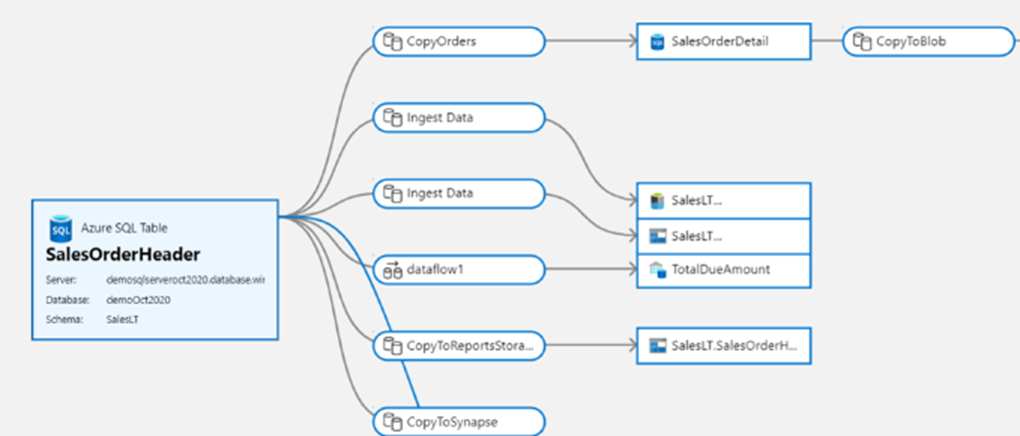
Dengan integrasi asli ke Dalam Purview Data Catalog Anda, pabrik data memungkinkan pencarian dan penemuan aset data yang mudah digunakan dalam alur integrasi data Anda di seluruh luas data estate organisasi Anda.

Anda dapat menggunakan bilah pencarian utama dari Azure Data Factory Studio untuk menemukan aset data di katalog Purview Anda.
