Memantau Aliran Data
BERLAKU UNTUK:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Cobalah Data Factory di Microsoft Fabric, solusi analitik all-in-one untuk perusahaan. Microsoft Fabric mencakup semuanya mulai dari pergerakan data hingga ilmu data, analitik real time, kecerdasan bisnis, dan pelaporan. Pelajari cara memulai uji coba baru secara gratis!
Setelah Anda selesai membangun dan melakukan penelusuran kesalahan aliran data Anda, Anda ingin menjadwalkan aliran data untuk dijalankan sesuai jadwal dalam konteks alur. Anda dapat menjadwalkan alur menggunakan Pemicu. Untuk menguji dan men-debug aliran data Anda dari alur, Anda dapat menggunakan tombol Debug pada pita toolbar atau opsi Picu Sekarang dari Penyusun Alur untuk menjalankan eksekusi sekali jalankan untuk menguji aliran data Anda dalam konteks alur.
Saat Anda menjalankan alur, Anda dapat memantau alur dan semua aktivitas yang terkandung dalam alur termasuk aktivitas Aliran Data. Pilih ikon monitor di panel UI sebelah kiri. Anda dapat melihat layar yang mirip dengan layar berikut. Ikon yang disorot memungkinkan Anda menelusuri aktivitas di alur, termasuk aktivitas Aliran Data.
Anda melihat statistik pada tingkat ini, termasuk durasi dan status. ID Eksekusi di tingkat aktivitas berbeda dengan ID Eksekusi di tingkat alur. ID Eksekusi pada level sebelumnya adalah untuk alur. Memilih kacamata memberi Anda detail mendalam tentang eksekusi aliran data Anda.

Saat Anda berada dalam tampilan pemantauan node grafis, Anda dapat melihat versi lihat-saja yang disederhanakan dari grafik aliran data Anda. Untuk melihat tampilan detail dengan simpul grafik yang lebih besar yang menyertakan label tahap transformasi, gunakan penggeser zoom di sebelah kanan kanvas. Anda juga dapat menggunakan tombol pencarian di sebelah kanan untuk menemukan bagian logika aliran data Anda dalam grafik.
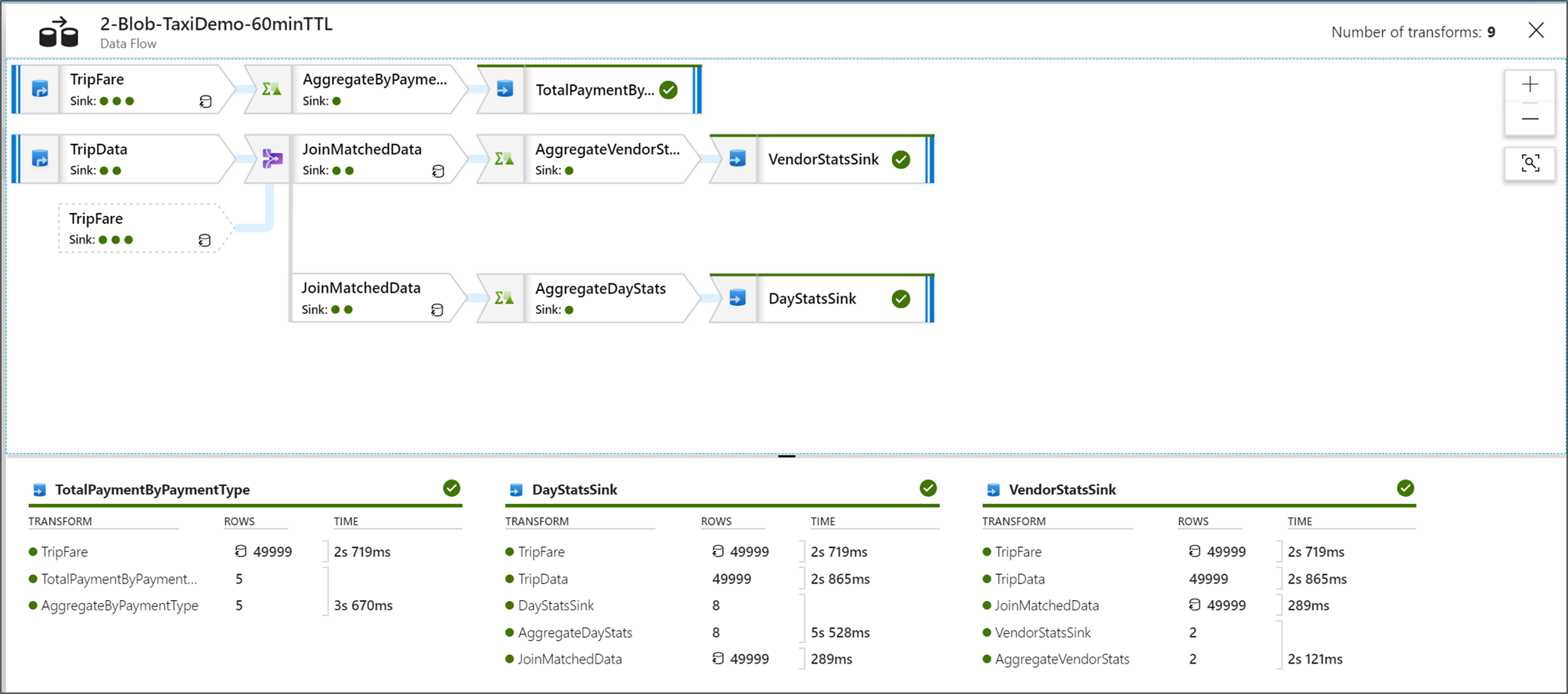
Melihat Paket Eksekusi Aliran Data
Saat Aliran Data Anda dijalankan di Spark, layanan menentukan jalur kode optimal berdasarkan keseluruhan aliran data Anda. Selain itu, jalur eksekusi mungkin terjadi pada simpul peluasan skala dan partisi data yang berbeda. Oleh karena itu, grafik pemantauan mewakili desain alur Anda, dengan mempertimbangkan jalur eksekusi transformasi Anda. Saat memilih setiap simpul, Anda dapat melihat "tahapan" yang mewakili kode yang dijalankan bersama-sama pada kluster. Waktu dan jumlah yang Anda lihat mewakili grup atau tahapan tersebut dibandingkan dengan langkah-langkah individual dalam desain Anda.
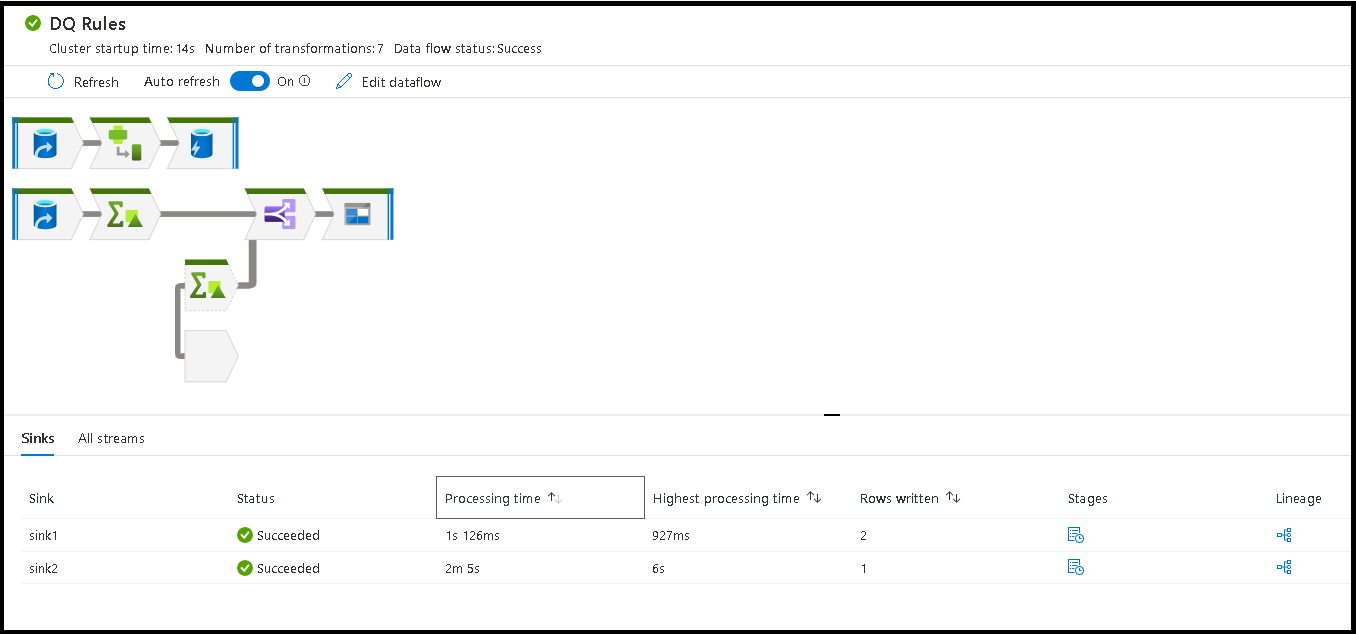
Saat Anda memilih ruang terbuka di jendela pemantauan, statistik di panel bawah menampilkan waktu dan jumlah baris untuk setiap Sink dan transformasi yang mengarah ke data sink untuk silsilah transformasi.
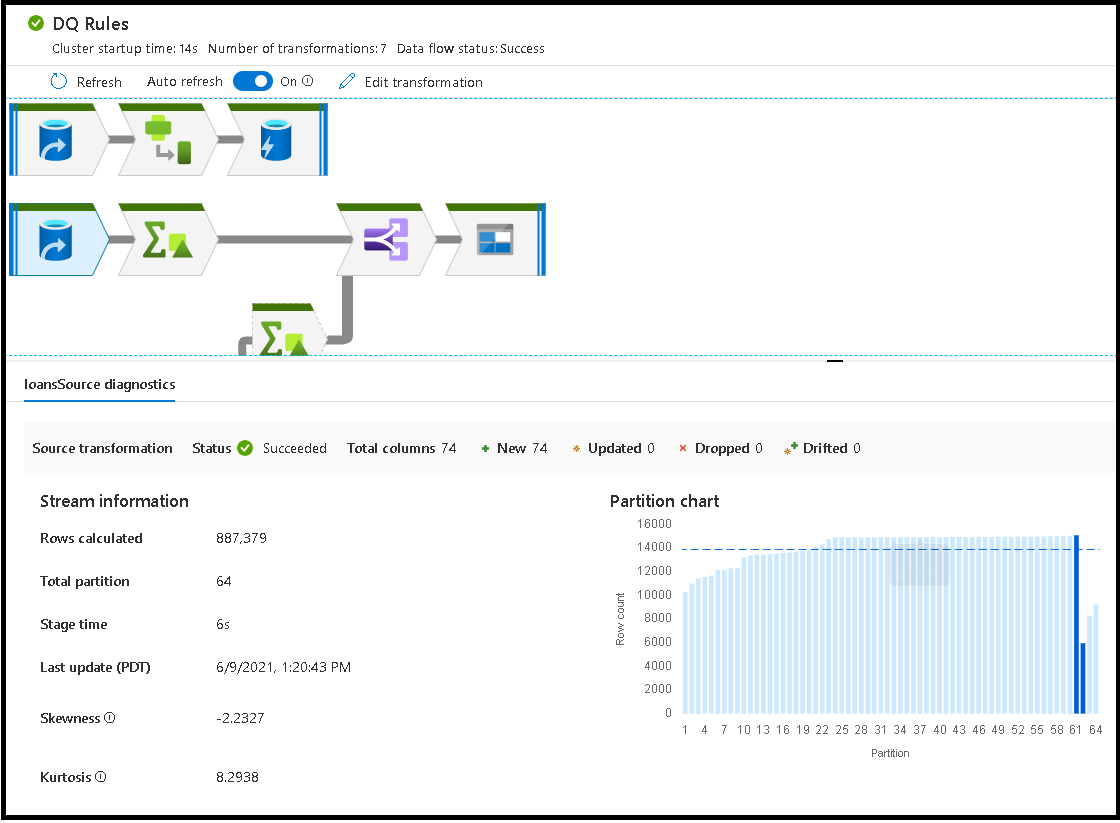
Saat Anda memilih transformasi individual, Anda menerima umpan balik tambahan pada panel kanan yang menunjukkan statistik partisi, jumlah kolom, kemiringan (seberapa merata data yang didistribusikan di seluruh partisi), dan kurtosis (seberapa lonjakan data).
Mengurutkan menurut waktu pemrosesan membantu Anda mengidentifikasi tahapan mana dalam aliran data Anda yang membutuhkan waktu paling lama.
Untuk menemukan transformasi mana di dalam setiap tahap yang paling banyak memakan waktu, urutkan berdasarkan waktu pemrosesan tertinggi.
*Baris yang ditulis juga dapat diurutkan sebagai cara untuk mengidentifikasi aliran mana di dalam aliran data Anda yang paling banyak menulis data.
Saat memilih Sink di tampilan node, Anda dapat melihat silsilah kolom. Ada tiga metode berbeda dari akumulasi kolom di seluruh aliran data Anda untuk mendarat di Sink. Yaitu:
- Dihitung: Anda menggunakan kolom untuk pemrosesan kondisional atau dalam ekspresi di aliran data Anda, tetapi jangan mendaratkannya di Sink
- Turunan: Kolom adalah kolom baru yang Anda buat dalam alur Anda, yaitu, kolom tersebut tidak ada di Sumber
- Dipetakan: Kolom berasal dari sumber dan Anda memetakannya ke bidang sink
- Status aliran data: Status eksekusi Anda saat ini
- Waktu mulai kluster: Jumlah waktu untuk memperoleh lingkungan komputasi JIT Spark untuk eksekusi aliran data Anda
- Jumlah transformasi: Berapa banyak langkah transformasi yang dijalankan dalam alur Anda

Waktu Pemrosesan Sink Total vs. Waktu Pemrosesan Transformasi
Setiap tahap transformasi mencakup total waktu untuk tahap tersebut untuk diselesaikan dengan setiap waktu eksekusi partisi yang dijumlahkan bersamaan. Saat Anda memilih Sink, Anda akan melihat "Waktu Pemrosesan Sink". Waktu ini mencakup total waktu transformasi ditambah waktu I/O yang diperlukan untuk menulis data Anda ke penyimpanan tujuan Anda. Perbedaan antara Waktu Pemrosesan Sink dan total transformasi adalah waktu I/O untuk menulis data.
Anda juga dapat melihat pengaturan waktu terperinci untuk setiap langkah transformasi partisi jika Anda membuka output JSON dari aktivitas aliran data Anda dalam tampilan pemantauan alur. JSON berisi waktu milidetik untuk setiap partisi, sedangkan tampilan pemantauan UX adalah waktu agregat partisi yang ditambahkan bersama-sama:
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
Waktu pemrosesan sink
Saat Anda memilih ikon transformasi sink di peta Anda, panel slide-in di sebelah kanan memperlihatkan titik data tambahan yang disebut "waktu pemrosesan pos" di bagian bawah. Ini adalah jumlah waktu yang dihabiskan untuk menjalankan pekerjaan Anda di kluster Spark setelah data Anda dimuat, diubah, dan ditulis. Kali ini dapat mencakup menutup kumpulan koneksi, mematikan driver, menghapus file, file coalescing, dll. Saat Anda melakukan tindakan dalam alur Anda seperti "pindahkan file" dan "output ke file tunggal", Anda mungkin melihat peningkatan nilai waktu pemrosesan pasca.
- Durasi tahap tulis: Waktu untuk menulis data ke lokasi penahapan untuk Synapse SQL
- Durasi SQL operasi tabel: Waktu yang dihabiskan untuk memindahkan data dari tabel sementara ke tabel target
- Durasi Pra SQL & Pasca SQL: Waktu yang dihabiskan untuk menjalankan perintah SQL pra/pasca
- Durasi pra perintah & pasca perintah: Waktu yang dihabiskan untuk menjalankan operasi pra/pasca untuk sumber/sink berbasis file. Misalnya memindahkan atau menghapus file setelah diproses.
- Durasi penggabungan: Waktu yang dihabiskan untuk menggabungkan file, penggabungan file digunakan untuk sink berbasis file saat menulis ke file tunggal atau ketika "Nama file sebagai data kolom" digunakan. Jika waktu yang signifikan dihabiskan dalam metrik ini, Anda harus menghindari penggunaan opsi ini.
- Waktu tahapan: Jumlah total waktu yang dihabiskan di dalam Spark untuk menyelesaikan operasi sebagai satu tahapan.
- Tabel penahapan sementara: Nama tabel sementara yang digunakan oleh aliran data ke data tahap dalam database.
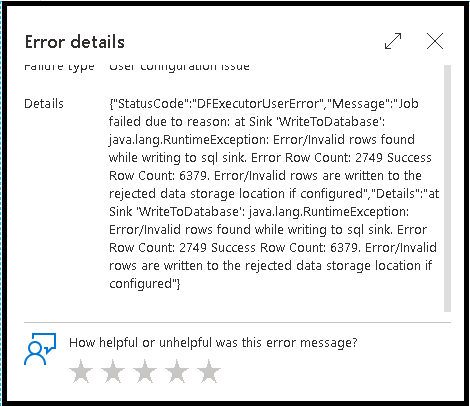
Baris kesalahan
Mengaktifkan penanganan baris kesalahan di sink aliran data Anda akan tercermin dalam output pemantauan. Saat Anda mengatur sink ke "laporkan keberhasilan pada kesalahan", output pemantauan menunjukkan jumlah baris yang berhasil dan gagal saat Anda memilih simpul pemantauan sink.
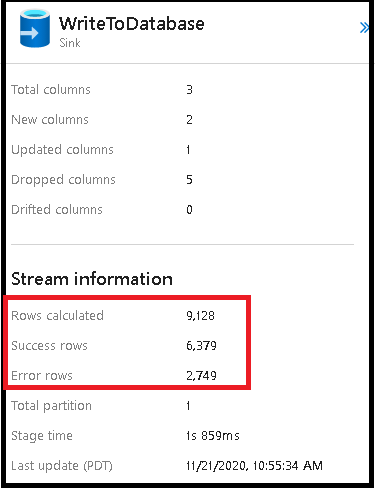
Saat Anda memilih "laporkan kegagalan pada kesalahan", output yang sama hanya ditampilkan dalam teks output pemantauan aktivitas. Ini karena aktivitas aliran data mengembalikan kegagalan untuk eksekusi dan tampilan pemantauan terperinci tidak tersedia.
Ikon Monitor
Ikon ini berarti bahwa data transformasi sudah di-cache pada kluster, sehingga waktu dan jalur eksekusi telah memperhitungkannya:
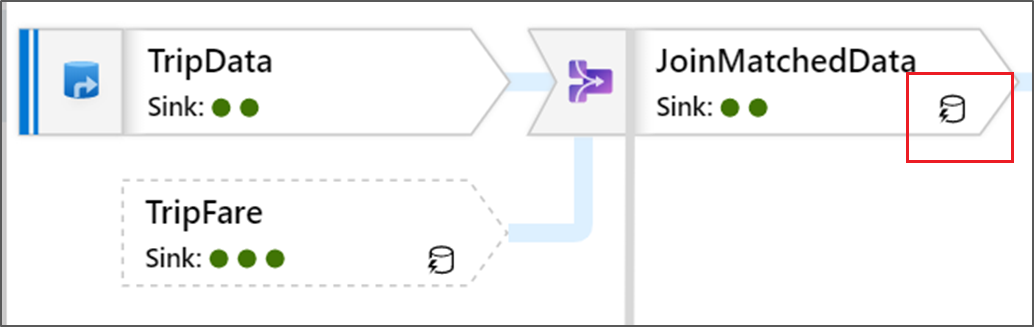
Anda juga melihat ikon lingkaran hijau dalam transformasi. Mereka mewakili hitungan jumlah sink di mana data mengalir.