Penyajian Model MLflow di Azure Databricks
Penting
Fitur ini ada di Pratinjau Publik.
Penting
- Dokumentasi ini telah dihentikan dan mungkin tidak diperbarui. Produk, layanan, atau teknologi yang disebutkan dalam konten ini tidak lagi didukung.
- Panduan dalam artikel ini adalah untuk Penyajian Model MLflow Warisan. Databricks merekomendasikan Anda memigrasikan model Anda melayani alur kerja ke Model Melayani untuk penyebaran dan skalabilitas titik akhir model yang disempurnakan. Untuk informasi selengkapnya, lihat Menjalankan model menggunakan Mosaic AI Model Serving.
Warisan MLflow Model Melayani memungkinkan Anda untuk menghosting model pembelajaran mesin dari Model Registry sebagai titik akhir REST yang diperbarui secara otomatis berdasarkan ketersediaan versi model dan tahapannya. Ini menggunakan kluster simpul tunggal yang berjalan di bawah akun Anda sendiri dalam apa yang sekarang disebut bidang komputasi klasik. Bidang komputasi ini mencakup jaringan virtual dan sumber daya komputasi terkait seperti kluster untuk notebook dan pekerjaan, gudang SQL pro dan klasik, dan model Warisan yang melayani titik akhir.
Saat Anda mengaktifkan model yang berfungsi untuk model terdaftar tertentu, Azure Databricks secara otomatis membuat kluster unik untuk model dan menyebarkan semua versi model yang tidak diarsipkan pada kluster tersebut. Azure Databricks memulai ulang kluster jika terjadi kesalahan dan mengakhiri kluster saat Anda menonaktifkan model yang berfungsi untuk model. Penayangan model secara otomatis disinkronkan dengan Model Registry dan menyebarkan versi model terdaftar baru. Versi model yang disebarkan dapat dikuk kalii dengan permintaan REST API standar. Azure Databricks mengautentikasi permintaan ke model menggunakan autentikasi standarnya.
Meskipun layanan ini sedang dalam pratinjau, Databricks merekomendasikan penggunaannya untuk throughput rendah dan aplikasi non-kritis. Target throughput adalah 200 qps dan ketersediaan target adalah 99,5%, meskipun tidak ada jaminan yang dibuat untuk keduanya. Selain itu, ada batas ukuran payload 16 MB per permintaan.
Setiap versi model disebarkan menggunakan penyebaran model MLflow dan berjalan di lingkungan Conda yang ditentukan oleh dependensinya.
Catatan
- Cluster dipertahankan selama penayangan diaktifkan, bahkan jika tidak ada versi model aktif. Untuk mengakhiri kluster penyajian, nonaktifkan model yang berfungsi untuk model terdaftar.
- Kluster dianggap sebagai kluster serba guna, tergantung pada harga beban kerja serba guna.
- Skrip init global tidak dijalankan pada model yang melayani kluster.
Penting
Anaconda Inc. memperbarui ketentuan layanan untuk alur anaconda.org. Berdasarkan persyaratan layanan baru, Anda mungkin memerlukan lisensi komersial jika Anda mengandalkan pengemasan dan distribusi Anaconda. Lihat FAQ Anaconda Commercial Edition untuk informasi lebih lanjut. Penggunaan Anda atas setiap saluran Anaconda diatur oleh persyaratan layanan mereka.
Model MLflow yang dicatat sebelum v1.18 (Databricks Runtime 8.3 ML atau lebih lama) secara default dicatat dengan saluran conda defaults (https://repo.anaconda.com/pkgs/) sebagai dependensi. Karena perubahan lisensi ini, Databricks telah menghentikan penggunaan saluran defaults untuk model yang dicatat menggunakan MLflow v1.18 dan di atasnya. Saluran default yang dicatat sekarang adalah conda-forge, yang menunjuk pada komunitas yang dikelola https://conda-forge.org/.
Jika Anda mencatat model sebelum MLflow v1.18 tanpa mengecualikan saluran defaults dari lingkungan conda untuk model tersebut, model tersebut mungkin memiliki dependensi pada saluran defaults yang mungkin tidak Anda maksudkan.
Untuk mengonfirmasi secara manual apakah model memiliki dependensi ini, Anda dapat memeriksa nilai channel dalam file conda.yaml yang dikemas dengan model yang dicatat. Misalnya, conda.yaml model dengan defaults dependensi saluran mungkin terlihat seperti ini:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Karena Databricks tidak dapat menentukan apakah penggunaan Anda atas repositori Anaconda untuk berinteraksi dengan model Anda diizinkan berdasarkan hubungan Anda dengan Anaconda, Databricks tidak memaksa pelanggannya untuk membuat perubahan apa pun. Jika penggunaan repositori Anaconda.com Anda melalui penggunaan Databricks diizinkan berdasarkan ketentuan Anaconda, Anda tidak perlu mengambil tindakan apa pun.
Jika Anda ingin mengubah saluran yang digunakan di lingkungan model, Anda dapat mendaftarkan ulang model ke registri model dengan baru conda.yaml. Anda dapat melakukannya dengan menentukan saluran di parameter conda_env dari log_model().
Untuk informasi selengkapnya tentang log_model() API, lihat dokumentasi MLflow untuk ragam model yang sedang Anda kerjakan, misalnya, log_model untuk scikit-learn.
Untuk informasi selengkapnya tentang conda.yaml file, lihat dokumentasi MLflow.
Persyaratan
- Penyajian Model MLflow Warisan tersedia untuk model Python MLflow. Anda harus mendeklarasikan semua dependensi model di lingkungan conda. Lihat Dependensi model log.
- Untuk mengaktifkan Penyajian Model, Anda harus memiliki izin pembuatan kluster.
Servis model dari Model Registry
Penayangan model tersedia di Azure Databricks dari Model Registry.
Mengaktifkan dan menonaktifkan penyajian model
Anda mengaktifkan model untuk melayani dari halaman model terdaftarnya.
Klik tab Melayani. Jika model belum diaktifkan untuk ditayangkan, tombol Aktifkan Penyajian akan muncul.
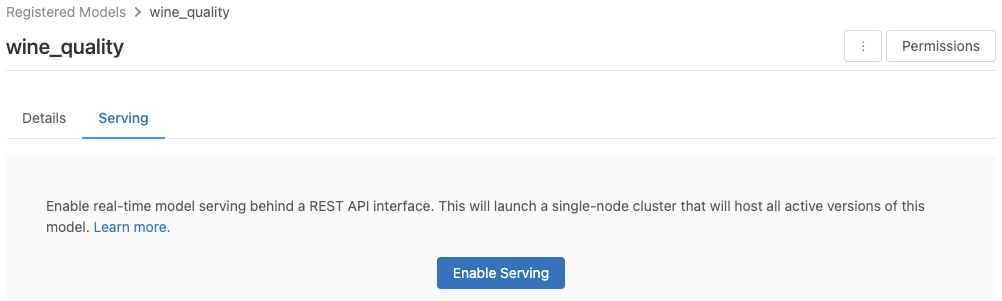
Klik Aktifkan Penyajian. Tab Melayani muncul dengan Status yang ditampilkan sebagai Tertunda. Setelah beberapa menit, Status berubah menjadi Siap.
Untuk menonaktifkan model untuk ditayangkan, klik Berhenti.
Memvalidasi penyajian model
Dari tab Melayani, Anda dapat mengirim permintaan ke model yang ditayangkan dan melihat respons.
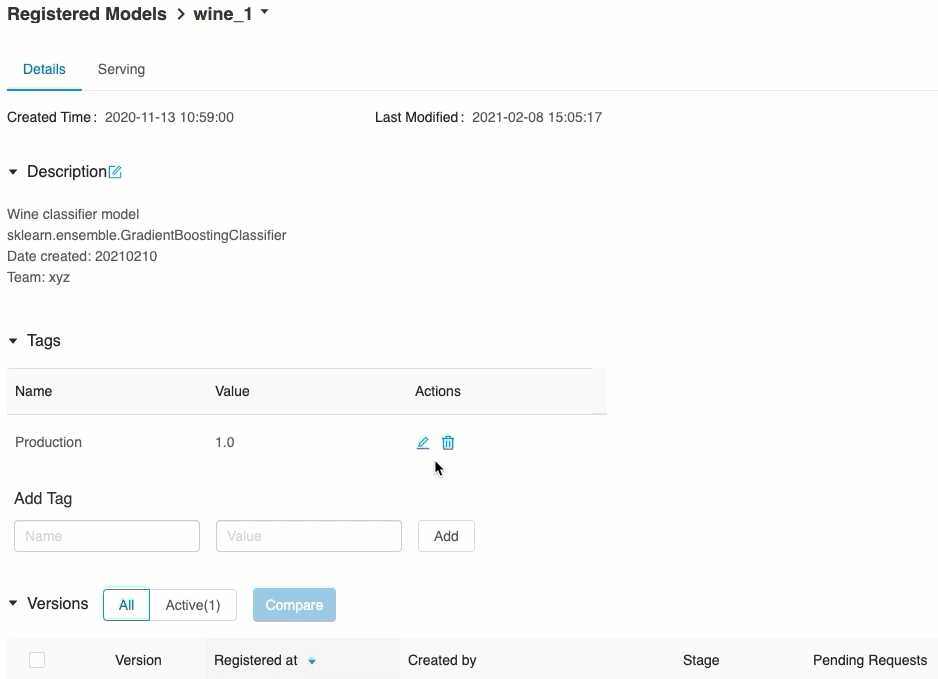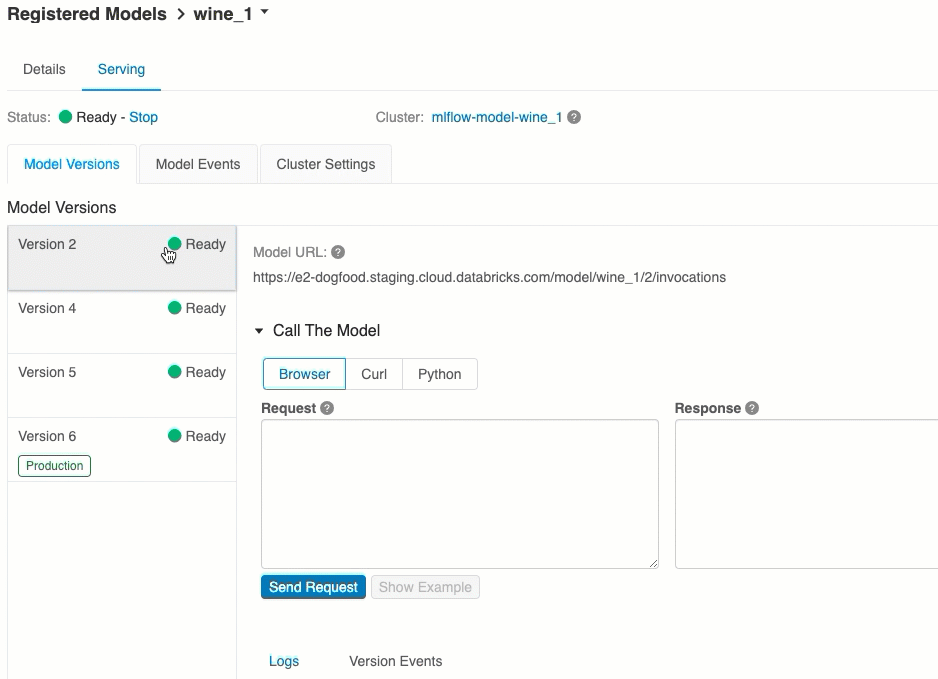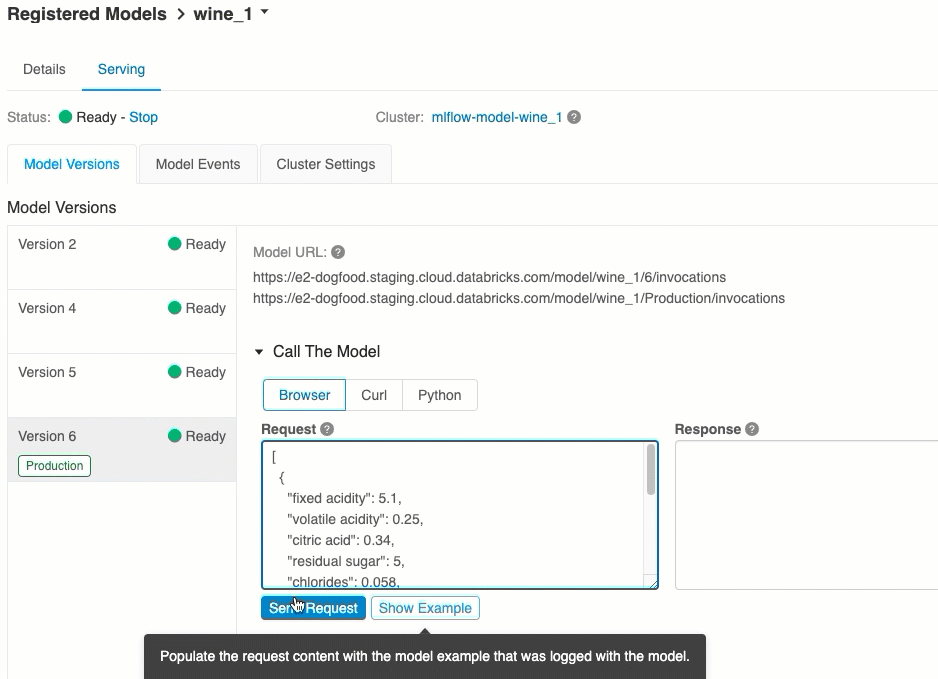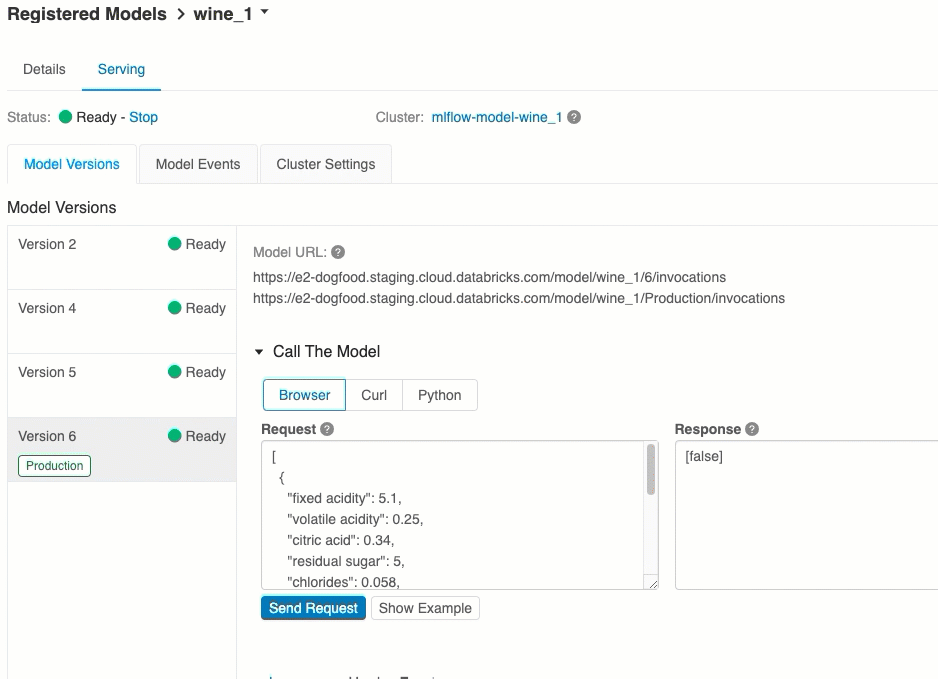
Versi model URI
Setiap versi model yang disebarkan diberi satu atau beberapa URI unik. Minimal, setiap versi model diberi URI yang dibangun sebagai berikut:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
Misalnya, untuk memanggil versi 1 dari model yang terdaftar sebagai iris-classifier, gunakan URI ini:
https://<databricks-instance>/model/iris-classifier/1/invocations
Anda juga dapat memanggil versi model berdasarkan tahapnya. Misalnya, jika versi 1 dalam tahap Produksi, itu juga dapat dinilai menggunakan URI ini:
https://<databricks-instance>/model/iris-classifier/Production/invocations
Daftar URI model yang tersedia muncul di bagian atas tab Versi Model di halaman sajian.
Mengelola versi yang ditayangkan
Semua versi model aktif (non-arsip) disebarkan, dan Anda dapat memintanya menggunakan URI. Azure Databricks secara otomatis menyebarkan versi model baru saat didaftarkan, dan secara otomatis menghapus versi lama saat diarsipkan.
Catatan
Semua versi yang disebarkan dari model terdaftar berbagi kluster yang sama.
Mengelola hak akses model
Hak akses model diwarisi dari Registri Model. Mengaktifkan atau menonaktifkan fitur penyajian memerlukan izin 'kelola' pada model terdaftar. Siapa pun yang memiliki hak baca dapat mencetak salah satu versi yang disebarkan.
Skor versi model yang disebarkan
Untuk mencetak model yang disebarkan, Anda dapat menggunakan UI atau mengirim permintaan REST API ke model URI.
Skor melalui UI
Ini adalah cara termudah dan tercepat untuk menguji model. Anda dapat menyisipkan data input model dalam format JSON dan mengklik Kirim Permintaan. Jika model telah dicatat dengan contoh input (seperti yang ditunjukkan pada grafik di atas), klik Contoh Beban untuk memuat contoh input.
Skor melalui permintaan REST API
Anda dapat mengirim permintaan penilaian melalui REST API menggunakan autentikasi Databricks standar. Contoh di bawah ini menunjukkan autentikasi menggunakan token akses pribadi dengan MLflow 1.x.
Catatan
Sebagai praktik terbaik keamanan, saat Anda mengautentikasi dengan alat, sistem, skrip, dan aplikasi otomatis, Databricks merekomendasikan agar Anda menggunakan token akses pribadi milik perwakilan layanan, bukan pengguna ruang kerja. Untuk membuat token untuk perwakilan layanan, lihat Mengelola token untuk perwakilan layanan.
Diberikan MODEL_VERSION_URI seperti https://<databricks-instance>/model/iris-classifier/Production/invocations (di mana <databricks-instance> adalah nama instans Databricks Anda) dan token Databricks REST API tersebut DATABRICKS_API_TOKEN, contoh berikut menunjukkan cara melakukan kueri model yang dilayani:
Contoh berikut mencerminkan format penilaian untuk model yang dibuat dengan MLflow 1.x. Jika Anda lebih suka menggunakan MLflow 2.0, Anda perlu memperbarui format permintaan payload Anda.
Bash
Cuplikan untuk mengkueri model yang menerima input dataframe.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
Cuplikan untuk mengkueri model yang menerima input tensor. Input tensor harus diformat seperti yang dijelaskan dalam dokumen API TensorFlow Serving.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
PowerBI
Anda dapat mencetak himpunan data di Power BI Desktop menggunakan langkah-langkah berikut:
Buka himpunan data yang ingin Anda skor.
Pergi untuk mengubah data.
Klik kanan di panel kiri dan pilih Buat Kueri Baru.
Buka Lihat > Editor Lanjutan.
Ganti badan kueri dengan cuplikan kode di bawah ini, setelah mengisi yang sesuai
DATABRICKS_API_TOKENdanMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionBeri nama kueri dengan nama model yang Anda inginkan.
Buka editor kueri tingkat lanjut untuk himpunan data Anda dan terapkan fungsi model.
Memantau model yang dilayani
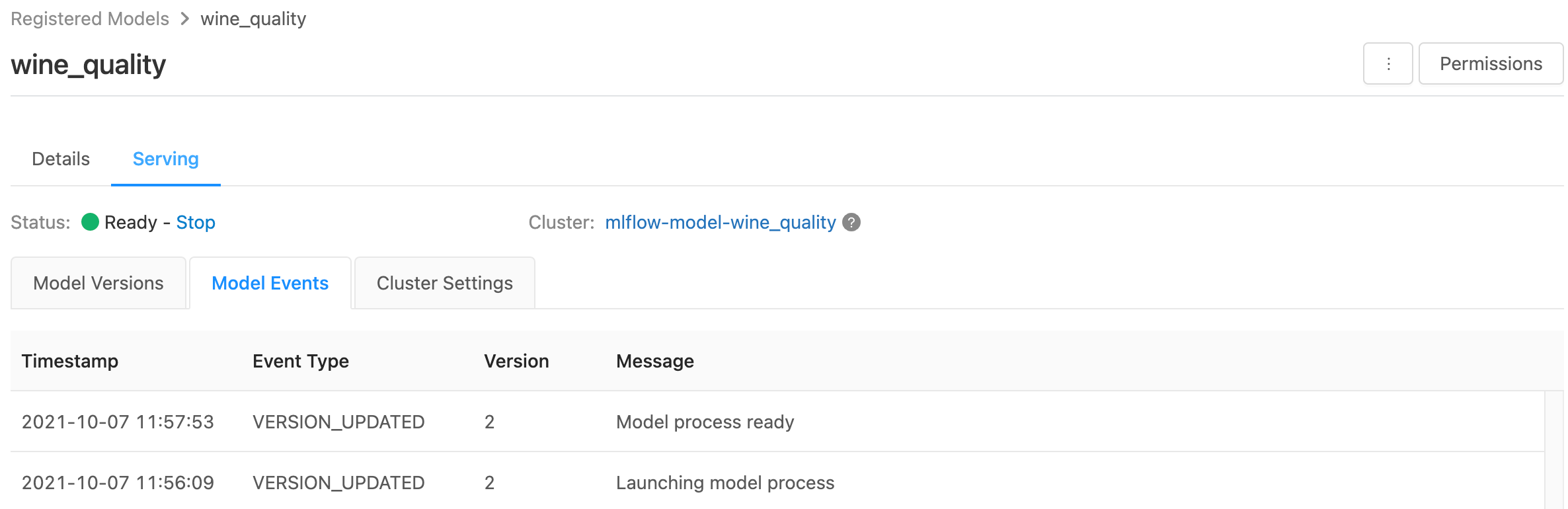
Halaman penyajian menampilkan indikator status untuk kluster penayangan serta versi model individual.
- Untuk memeriksa keadaan kluster penyajian, gunakan tab Peristiwa Model, yang menampilkan daftar semua peristiwa penyajian untuk model ini.
- Untuk memeriksa status versi model tunggal, klik tab Versi Model dan gulir untuk melihat tab Log atau Peristiwa Versi.
Mengkustomisasi kluster penyajian
Untuk menyesuaikan kluster penyajian, gunakan tab Pengaturan Kluster pada tab Penyajian .
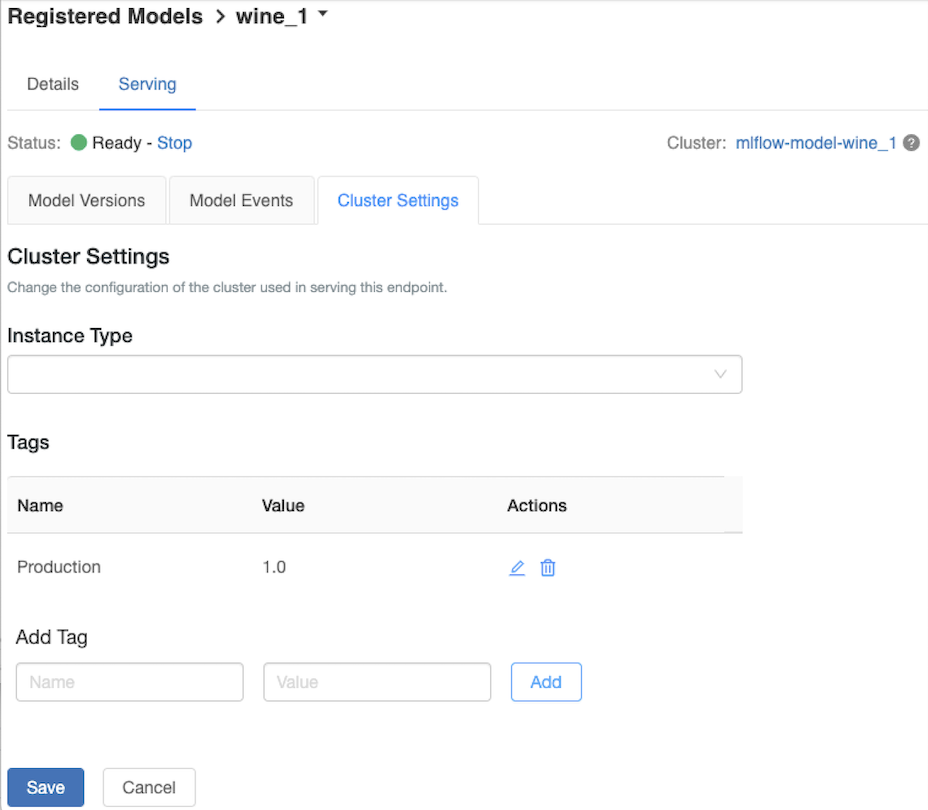
- Untuk memodifikasi ukuran memori dan jumlah inti kluster penyajian, gunakan menu drop-down Jenis Instans untuk memilih konfigurasi kluster yang diinginkan. Saat Anda mengklik Simpan, kluster yang ada dihentikan dan kluster baru dibuat dengan pengaturan yang ditentukan.
- Untuk menambahkan tag, ketik nama dan nilai di bidang Tambahkan Tag dan klik Tambahkan.
- Untuk mengedit atau menghapus tag yang sudah ada, klik salah satu ikon di kolom Tindakan
dari tabel Tag .
Integrasi penyimpanan fitur
Penyajian model lama dapat secara otomatis menelusuri nilai fitur dari toko online yang diterbitkan.
.. aws:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
Kesalahan yang diketahui
ResolvePackageNotFound: pyspark=3.1.0
Kesalahan ini dapat terjadi jika model bergantung dan pyspark dicatat menggunakan Databricks Runtime 8.x.
Jika Anda melihat kesalahan ini, tentukan versi pyspark secara eksplisit saat mencatat model, menggunakan conda_env parameter.
Unrecognized content type parameters: format
Kesalahan ini dapat terjadi sebagai akibat dari format protokol penilaian MLflow 2.0 baru. Jika Anda melihat kesalahan ini, Anda kemungkinan menggunakan format permintaan penilaian yang kedaluarsa. Untuk mengatasi kesalahan, Anda dapat:
Perbarui format permintaan penilaian Anda ke protokol terbaru.
Catatan
Contoh berikut mencerminkan format penilaian yang diperkenalkan dalam MLflow 2.0. Jika Anda lebih suka menggunakan MLflow 1.x, Anda dapat memodifikasi
log_model()panggilan API untuk menyertakan dependensi versi MLflow yang diinginkan dalamextra_pip_requirementsparameter . Melakukannya memastikan format penilaian yang sesuai digunakan.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
Mengkueri model yang menerima input dataframe pandas.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'Mengkueri model yang menerima input tensor. Input tensor harus diformat seperti yang dijelaskan dalam dokumen API TensorFlow Serving.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)PowerBI
Anda dapat mencetak himpunan data di Power BI Desktop menggunakan langkah-langkah berikut:
Buka himpunan data yang ingin Anda skor.
Pergi untuk mengubah data.
Klik kanan di panel kiri dan pilih Buat Kueri Baru.
Buka Lihat > Editor Lanjutan.
Ganti badan kueri dengan cuplikan kode di bawah ini, setelah mengisi yang sesuai
DATABRICKS_API_TOKENdanMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionBeri nama kueri dengan nama model yang Anda inginkan.
Buka editor kueri tingkat lanjut untuk himpunan data Anda dan terapkan fungsi model.
Jika permintaan penilaian Anda menggunakan klien MLflow, seperti
mlflow.pyfunc.spark_udf(), tingkatkan klien MLflow Anda ke versi 2.0 atau yang lebih tinggi untuk menggunakan format terbaru. Pelajari selengkapnya tentang protokol penilaian Model MLflow yang diperbarui di MLflow 2.0.
Untuk informasi selengkapnya tentang format data input yang diterima oleh server (misalnya, format berorientasi terpisah panda), lihat dokumentasi MLflow.