Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menjelaskan cara membaca dan menulis ke tabel Google BigQuery di Azure Databricks.
Penting
Dokumentasi federasi kueri lama telah ditarik dan mungkin tidak akan diperbarui. Konfigurasi yang disebutkan dalam konten ini tidak secara resmi didukung atau diuji oleh Databricks. Jika Lakehouse Federation mendukung database sumber Anda, Databricks merekomendasikan penggunaannya sebagai gantinya.
Anda harus tersambung ke BigQuery menggunakan autentikasi berbasis kunci.
Hak akses
Proyek Anda harus memiliki izin Google tertentu untuk membaca dan menulis menggunakan BigQuery.
Nota
Artikel ini membahas tampilan termaterialisasi BigQuery. Untuk detailnya, lihat artikel Pengantar tampilan materialisasi oleh Google. Untuk mempelajari terminologi BigQuery lainnya dan model keamanan BigQuery, lihat dokumentasi Google BigQuery.
Membaca dan menulis data dengan BigQuery bergantung pada dua proyek Google Cloud:
- Project (
project): ID untuk proyek Google Cloud tempat Azure Databricks membaca atau menulis tabel BigQuery. - Proyek induk (
parentProject): ID untuk proyek induk, yang merupakan ID Proyek Google Cloud yang digunakan untuk melakukan tagihan atas pembacaan dan penulisan. Atur ini ke proyek Google Cloud yang terkait dengan akun layanan Google tempat Anda akan membuat kunci.
Anda harus secara eksplisit memberikan nilai project dan parentProject dalam kode yang mengakses BigQuery. Gunakan kode yang mirip dengan yang berikut ini:
spark.read.format("bigquery") \
.option("table", table) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Izin yang diperlukan untuk proyek Google Cloud bergantung pada apakah project dan parentProject sama. Bagian berikut mencantumkan izin yang diperlukan untuk setiap skenario.
Izin diperlukan jika project dan parentProject cocok
Jika ID untuk Anda project dan parentProject sama, gunakan tabel berikut untuk menentukan izin minimum:
| Tugas pada Azure Databricks | Izin Google diperlukan dalam proyek |
|---|---|
| Membaca tabel BigQuery tanpa tampilan materialisasi | Dalam proyek project:
|
| Membaca tabel BigQuery dengan tampilan materialisasi | Dalam proyek project:
Dalam proyek materialisasi:
|
| Membuat tabel BigQuery | Dalam proyek project:
|
Izin diperlukan jika project dan parentProject berbeda
Jika ID untuk Anda project dan parentProject berbeda, gunakan tabel berikut untuk menentukan izin minimum:
| Tugas pada Azure Databricks | Izin Google diperlukan |
|---|---|
| Membaca tabel BigQuery tanpa tampilan materialisasi | Dalam proyek parentProject:
Dalam proyek project:
|
| Membaca tabel BigQuery dengan tampilan materialisasi | Dalam proyek parentProject:
Dalam proyek project:
Dalam proyek materialisasi:
|
| Membuat tabel BigQuery | Dalam proyek parentProject:
Dalam proyek project:
|
Langkah 1: Menyiapkan Google Cloud
Mengaktifkan BIGQuery Storage API
BIGQuery Storage API diaktifkan secara default di proyek Google Cloud baru tempat BigQuery diaktifkan. Namun, jika Anda memiliki proyek yang sudah ada dan BIGQuery Storage API tidak diaktifkan, ikuti langkah-langkah di bagian ini untuk mengaktifkannya.
Anda dapat mengaktifkan BIGQuery Storage API menggunakan Google Cloud CLI atau Google Cloud Console.
Mengaktifkan BIGQuery Storage API menggunakan Google Cloud CLI
gcloud services enable bigquerystorage.googleapis.com
Mengaktifkan BIGQuery Storage API menggunakan Google Cloud Console
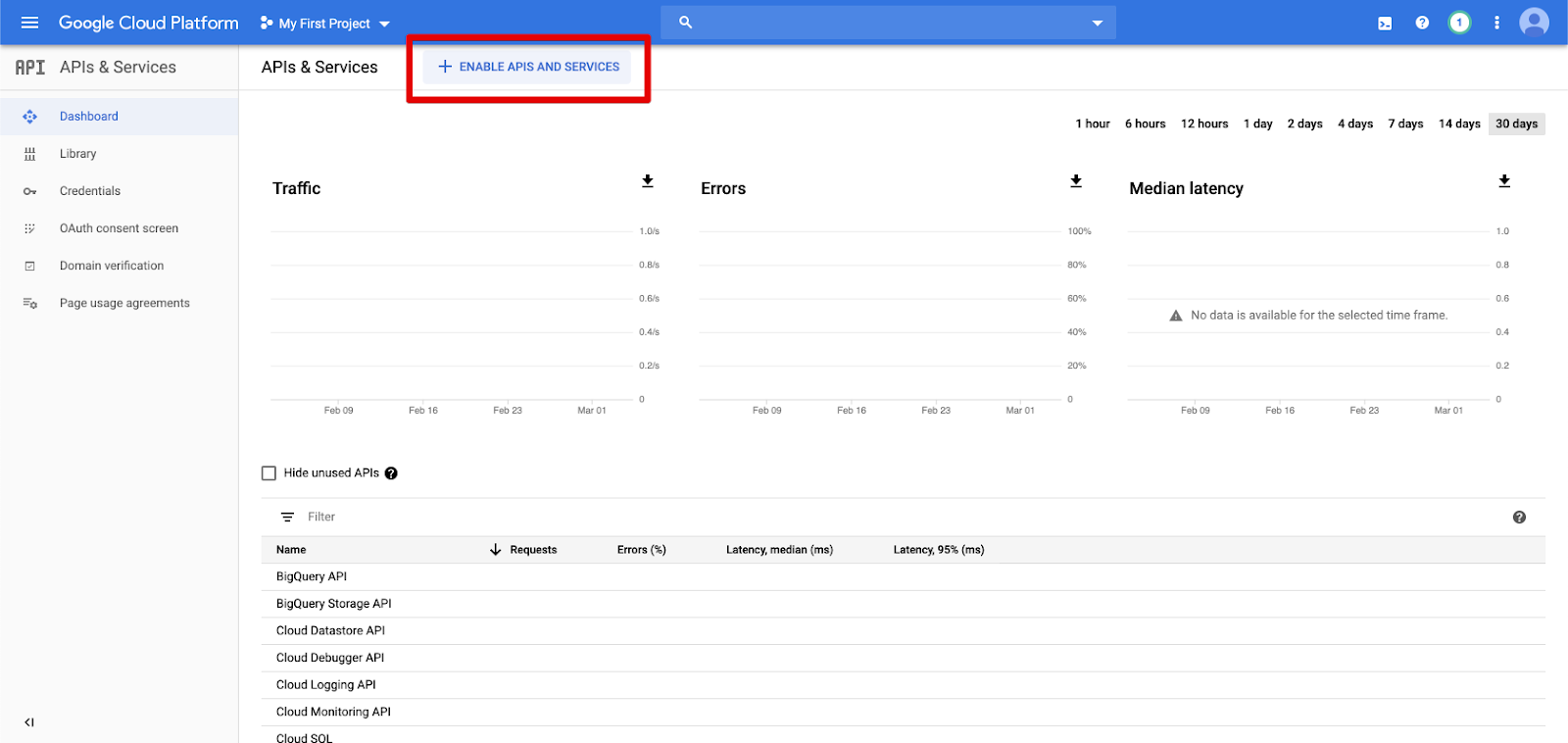
Klik API & Layanan di panel navigasi kiri.
Klik tombol AKTIFKAN APIS DAN LAYANAN .
Ketik
bigquery storage apidi bilah pencarian dan pilih hasil pertama.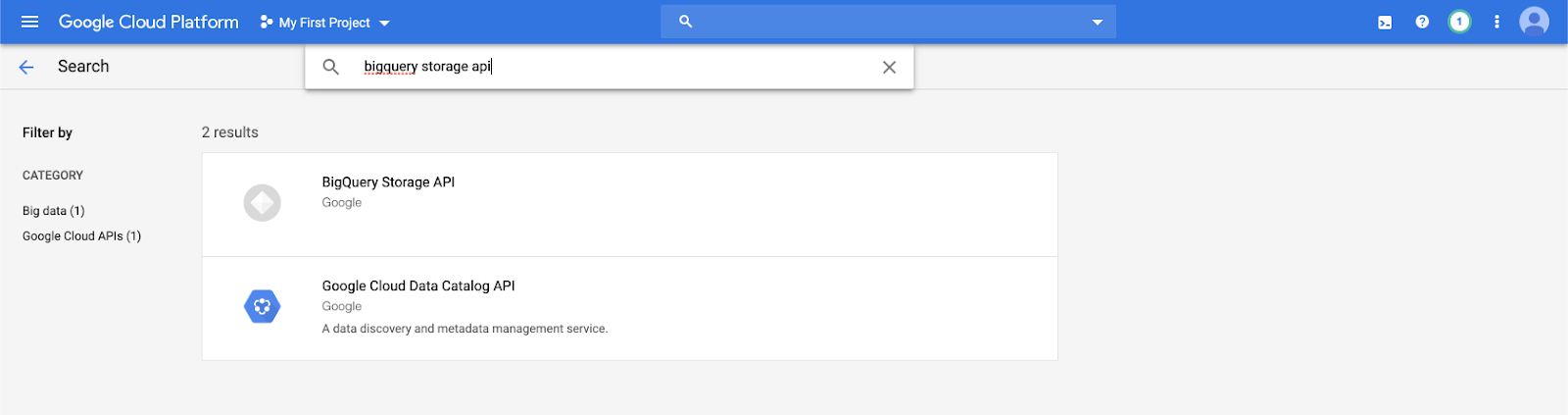
Pastikan BIGQuery Storage API diaktifkan.
Membuat akun layanan Google untuk Azure Databricks
Buat akun layanan untuk kluster Azure Databricks. Databricks merekomendasikan untuk memberikan hak istimewa paling sedikit kepada akun layanan ini untuk melakukan tugasnya. Lihat BigQuery Roles and Permissions.
Anda dapat membuat akun layanan menggunakan Google Cloud CLI atau Google Cloud Console.
Membuat akun layanan Google menggunakan Google Cloud CLI
gcloud iam service-accounts create <service-account-name>
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.user \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding <project-name> \
--role roles/bigquery.dataEditor \
--member="serviceAccount:<service-account-name>@<project-name>.iam.gserviceaccount.com"
Buat kunci untuk akun layanan Anda:
gcloud iam service-accounts keys create --iam-account \
"<service-account-name>@<project-name>.iam.gserviceaccount.com" \
<project-name>-xxxxxxxxxxx.json
Membuat akun layanan Google menggunakan Google Cloud Console
Untuk membuat akun:
Klik IAM dan Admin di panel navigasi kiri.
Klik Akun Layanan.
Klik + BUAT AKUN LAYANAN.
Masukkan nama dan deskripsi akun layanan.
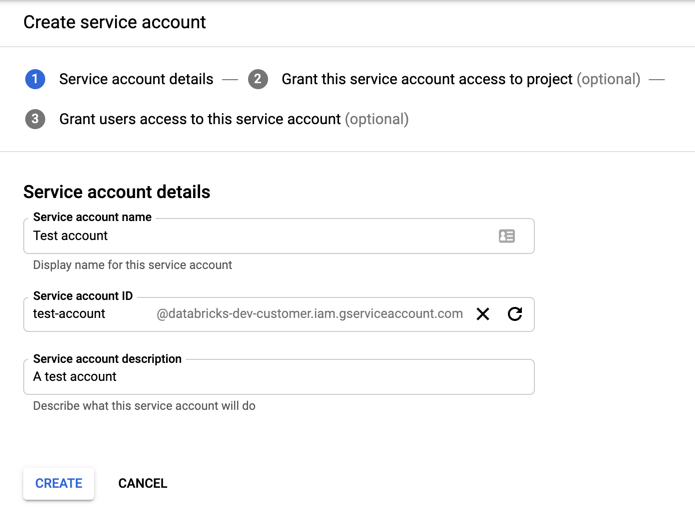
Klik Buat.
Tentukan peran untuk akun layanan Anda. Di menu drop-down Pilih peran, ketik
BigQuerydan tambahkan peran berikut: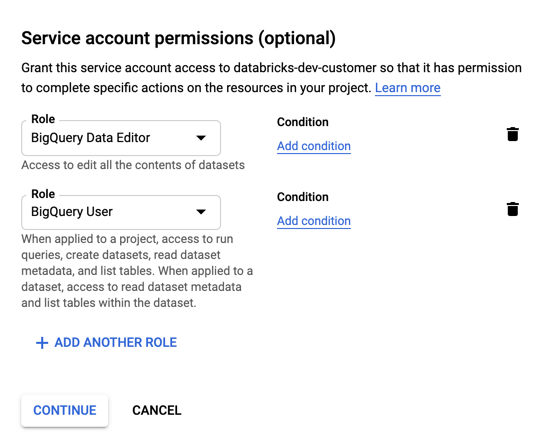
Klik LANJUTKAN.
Klik DONE.
Untuk membuat kunci untuk akun layanan Anda:
Di daftar akun layanan, klik akun anda yang baru dibuat.
Di bagian Kunci, pilih tombol TAMBAHKAN KUNCI > Buat kunci baru.
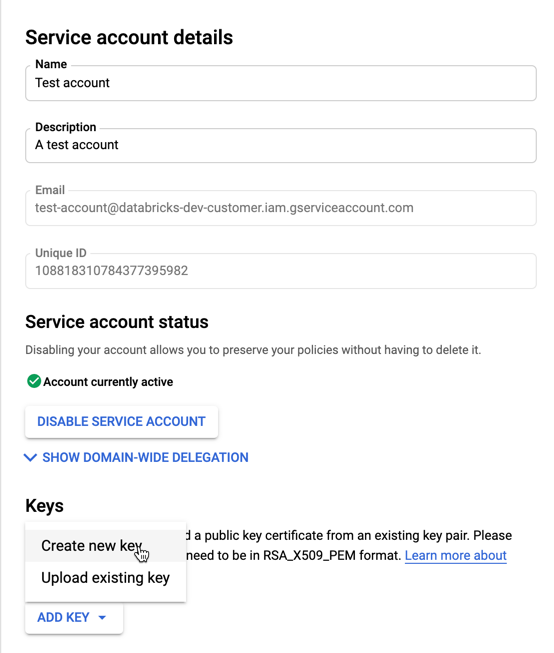
Terima jenis kunci JSON.
Klik Buat. File kunci JSON diunduh ke komputer Anda.
Penting
File kunci JSON yang Anda buat untuk akun layanan adalah kunci privat yang harus dibagikan hanya dengan pengguna yang berwenang, karena mengontrol akses ke himpunan data dan sumber daya di akun Google Cloud Anda.
Membuat wadah Google Cloud Storage (GCS) untuk penyimpanan sementara
Untuk menulis data ke BigQuery, sumber data memerlukan akses ke wadah GCS.
Klik Penyimpanan di panel navigasi kiri.
Klik BUAT BUCKET.
Konfigurasikan detail wadah.
Klik Buat.
Klik tab Izin dan Tambahkan anggota.
Berikan izin berikut ke akun layanan pada bucket.
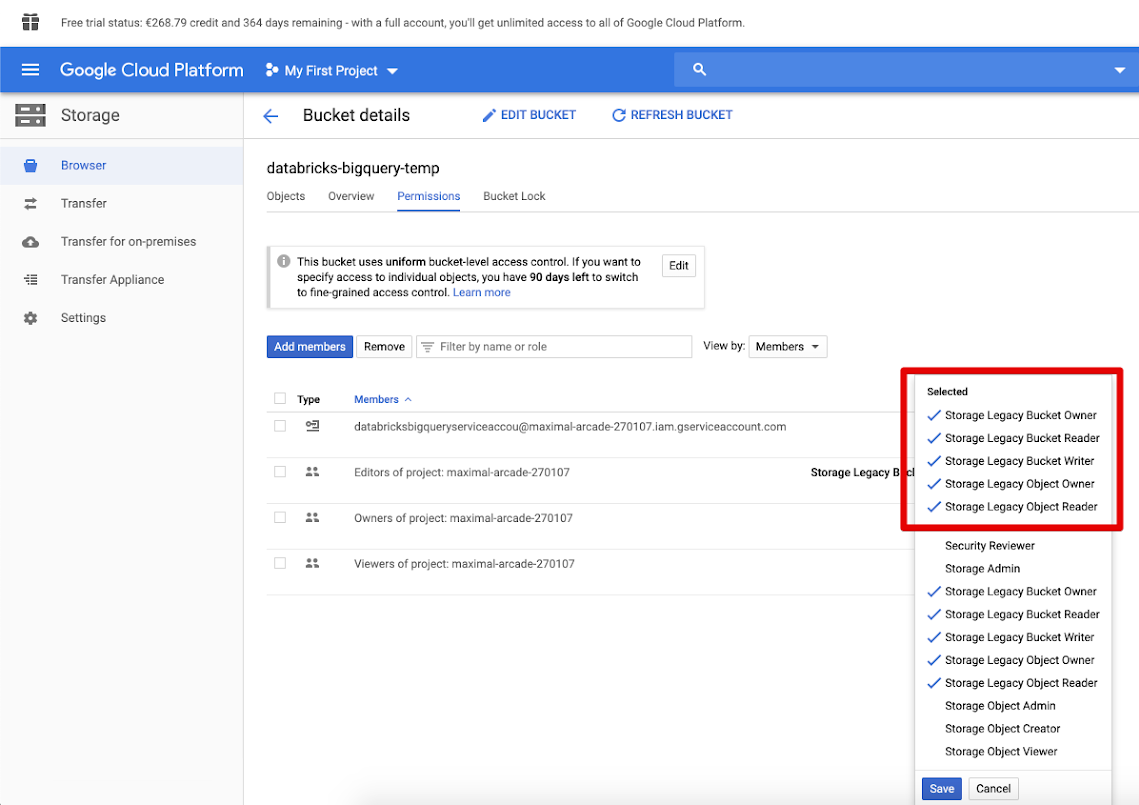
Klik SIMPAN.
Langkah 2: Menyiapkan Azure Databricks
Untuk mengonfigurasi kluster untuk mengakses tabel BigQuery, Anda harus menyediakan file kunci JSON Anda sebagai konfigurasi Spark. Gunakan alat lokal untuk menyandikan Base64 file kunci JSON Anda. Untuk tujuan keamanan, jangan gunakan alat berbasis web atau jarak jauh yang dapat mengakses kunci Anda.
Saat Anda mengonfigurasi kluster:
Di tab Konfigurasi Spark, tambahkan konfigurasi Spark berikut. Ganti <base64-keys> dengan string file kunci JSON yang dikodekan Base64 Anda. Ganti item lain dalam tanda kurung siku (seperti <client-email>) dengan nilai bidang tersebut dari file kunci JSON Anda.
credentials <base64-keys>
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key <private-key>
spark.hadoop.fs.gs.auth.service.account.private.key.id <private-key-id>
Membaca dan menulis ke tabel BigQuery
Untuk membaca tabel BigQuery, tentukan
df = spark.read.format("bigquery") \
.option("table",<table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.load()
Untuk menulis ke tabel BigQuery, tentukan
df.write.format("bigquery") \
.mode("<mode>") \
.option("temporaryGcsBucket", "<bucket-name>") \
.option("table", <table-name>) \
.option("project", <project-id>) \
.option("parentProject", <parent-project-id>) \
.save()
di mana <bucket-name> adalah nama wadah yang Anda buat di Buat wadah Google Cloud Storage (GCS) untuk penyimpanan sementara. Lihat Izin untuk mempelajari tentang persyaratan untuk nilai-nilai <project-id> dan <parent-id>.
Membuat tabel eksternal dari BigQuery
Penting
Fitur ini tidak didukung oleh Katalog Unity.
Anda dapat mendeklarasikan tabel yang tidak dikelola di Databricks yang akan membaca data langsung dari BigQuery:
CREATE TABLE chosen_dataset.test_table
USING bigquery
OPTIONS (
parentProject 'gcp-parent-project-id',
project 'gcp-project-id',
temporaryGcsBucket 'some-gcp-bucket',
materializationDataset 'some-bigquery-dataset',
table 'some-bigquery-dataset.table-to-copy'
)
Contoh notebook Python: Memuat tabel Google BigQuery ke dalam DataFrame
Notebook Python berikut memuat tabel Google BigQuery ke dalam Azure Databricks DataFrame.
Contoh notebook Google BigQuery Python
Contoh notebook Scala: Memuat tabel Google BigQuery ke dalam DataFrame
Notebook Scala berikut memuat tabel Google BigQuery ke dalam Azure Databricks DataFrame.