Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Catatan
Organisasi artikel ini mengasumsikan Anda menggunakan antarmuka pengguna komputasi formulir sederhana. Untuk gambaran umum pembaruan formulir sederhana, lihat Menggunakan formulir sederhana untuk mengelola komputasi.
Artikel ini menjelaskan pengaturan konfigurasi yang tersedia saat membuat sumber daya komputasi semua tujuan atau pekerjaan baru. Sebagian besar pengguna membuat sumber daya komputasi menggunakan kebijakan yang ditetapkan, yang membatasi pengaturan yang dapat dikonfigurasi. Jika Anda tidak melihat pengaturan tertentu di UI Anda, itu karena kebijakan yang Anda pilih tidak memungkinkan Anda mengonfigurasi pengaturan tersebut.
Untuk rekomendasi tentang mengonfigurasi komputasi untuk beban kerja Anda, lihat Rekomendasi konfigurasi komputasi.
Konfigurasi dan alat manajemen yang dijelaskan dalam artikel ini berlaku untuk komputasi semua tujuan dan pekerjaan. Untuk pertimbangan selengkapnya tentang mengonfigurasi komputasi pekerjaan, lihat Mengonfigurasi komputasi untuk pekerjaan.
Membuat sumber daya komputasi serba guna baru
Untuk membuat sumber daya komputasi tujuan baru:
- Di bilah sisi ruang kerja, klik Komputasi.
- Klik tombol Buat compute.
- Konfigurasikan sumber daya komputasi.
- Klik Buat.
Sumber daya komputasi baru Anda akan secara otomatis mulai berputar dan siap digunakan segera.
kebijakan komputasi
Kebijakan adalah sekumpulan aturan yang digunakan untuk membatasi opsi konfigurasi yang tersedia untuk pengguna saat mereka membuat sumber daya komputasi. Jika pengguna tidak memiliki hak pembuatan kluster Yang tidak dibatasi , mereka hanya dapat membuat sumber daya komputasi menggunakan kebijakan yang diberikan.
Untuk membuat sumber daya komputasi sesuai dengan kebijakan, pilih kebijakan dari menu drop-down Kebijakan .
Secara default, semua pengguna memiliki akses ke kebijakan Komputasi Pribadi, memungkinkan mereka membuat sumber daya komputasi komputer tunggal. Jika Anda memerlukan akses ke Komputasi Pribadi atau kebijakan tambahan apa pun, hubungi admin ruang kerja Anda.
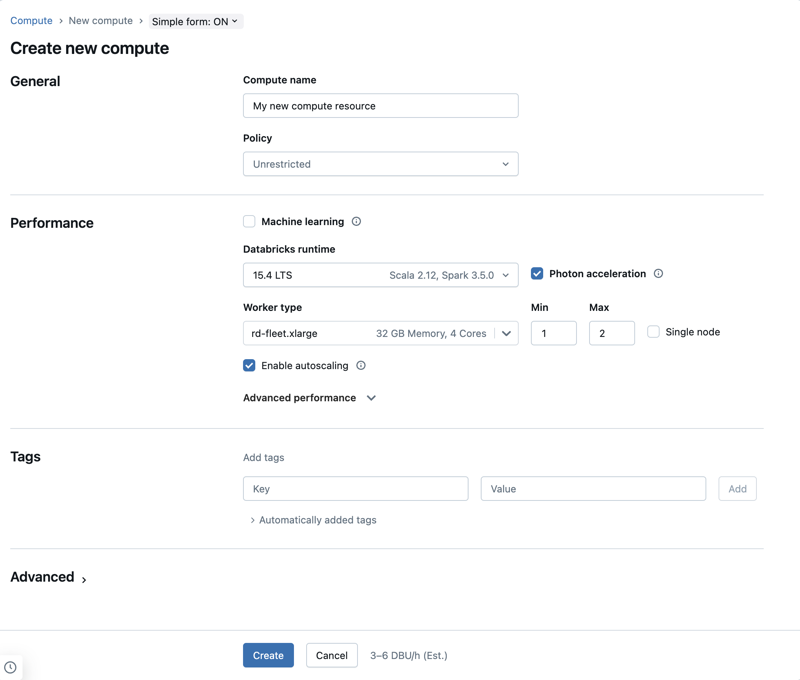
Pengaturan performa
Pengaturan berikut muncul di bawah bagian Performa dari UI komputasi formulir sederhana.
- Versi Databricks Runtime
- Gunakan akselerasi Photon
- jenis node pekerja
- komputasi simpul tunggal
- Mengaktifkan penskalaan otomatis
- pengaturan performa tingkat lanjut
Versi-versi Databricks Runtime
Databricks Runtime adalah kumpulan komponen inti yang berjalan pada komputasi Anda. Pilih runtime menggunakan menu drop-down Versi Runtime Databricks. Untuk detail tentang versi Databricks Runtime tertentu, lihat Versi dan kompatibilitas catatan rilis Databricks Runtime. Semua versi menyertakan Apache Spark. Databricks merekomendasikan hal berikut:
- Untuk komputasi serba guna, gunakan versi terbaru untuk memastikan Anda memiliki pengoptimalan terbaru dan kompatibilitas terbaru antara kode Anda dan paket yang telah dimuat sebelumnya.
- Untuk pekerjaan komputasi yang menjalankan beban kerja operasional, pertimbangkan untuk menggunakan versi Databricks Runtime Dukungan Jangka Panjang (LTS). Menggunakan versi LTS akan memastikan Anda tidak mengalami masalah kompatibilitas dan dapat menguji beban kerja Anda secara menyeluruh sebelum meningkatkan.
- Untuk kasus penggunaan ilmu data dan pembelajaran mesin, pertimbangkan versi ML Runtime Databricks.
Gunakan akselerasi Photon
Photon diaktifkan secara default pada komputasi yang menjalankan Databricks Runtime 9.1 LTS ke atas.
Untuk mengaktifkan atau menonaktifkan akselerasi Photon, pilih kotak centang Gunakan Akselerasi Foton. Untuk mempelajari selengkapnya tentang Photon, lihat Apa itu Photon?.
Tipe node pekerja
Sumber daya komputasi terdiri dari satu simpul driver dan nol atau lebih simpul pekerja. Anda dapat memilih jenis instans penyedia cloud terpisah untuk node driver dan pekerja, meskipun secara default node driver menggunakan jenis instans yang sama dengan node pekerja. Pengaturan node driver berada di bawah bagian performa lanjutan.
Berbagai keluarga dari jenis instans sesuai dengan penggunaan tertentu, seperti beban kerja yang memori-intensif atau komputasi-intensif. Anda juga dapat memilih kumpulan untuk digunakan sebagai simpul pekerja atau simpul pengemudi.
Penting
Jangan gunakan kumpulan dengan instance spot sebagai tipe driver Anda. Pilih jenis driver sesuai permintaan untuk mencegah driver Anda diklaim kembali. Lihat Hubungkan ke kumpulan.
Dalam komputasi multi-simpul, simpul pekerja menjalankan eksekutor Spark dan layanan lain yang diperlukan untuk memastikan sumber daya komputasi berfungsi dengan baik. Saat Anda mendistribusikan beban kerja dengan Spark, semua pemrosesan terdistribusi terjadi pada node pekerja. Azure Databricks menjalankan satu eksekutor pada setiap node pekerja. Oleh karena itu, istilah pelaksana dan pekerja digunakan secara bergantian dalam konteks arsitektur Databricks.
Kiat
Untuk menjalankan pekerjaan Spark, Anda setidaknya membutuhkan satu node worker. Jika sumber daya komputasi memiliki nol pekerja, Anda dapat menjalankan perintah non-Spark pada simpul driver, tetapi perintah Spark akan gagal.
Jenis node fleksibel
Jika ruang kerja Anda mengaktifkan jenis node yang fleksibel, Anda dapat menggunakan jenis node fleksibel untuk sumber daya komputasi Anda. Jenis node fleksibel memungkinkan sumber daya komputasi Anda untuk kembali ke jenis instans alternatif yang kompatibel saat jenis instans yang Anda tentukan tidak tersedia. Perilaku ini meningkatkan keandalan peluncuran komputasi dengan mengurangi kegagalan kapasitas selama peluncuran komputasi. Lihat Meningkatkan keandalan peluncuran komputasi menggunakan jenis node fleksibel.
Alamat IP simpul pekerja
Azure Databricks meluncurkan simpul pekerja dengan masing-masing dua alamat IP privat. Alamat IP privat utama node digunakan untuk lalu lintas internal Azure Databricks. Alamat IP privat sekunder digunakan oleh kontainer Spark untuk komunikasi intra-kluster. Model ini memungkinkan Azure Databricks untuk menyediakan isolasi antara beberapa sumber daya komputasi di ruang kerja yang sama.
Jenis tipe instans GPU
Untuk tugas yang menantang secara komputasi yang menuntut performa tinggi, seperti yang terkait dengan pembelajaran mendalam, Azure Databricks mendukung sumber daya komputasi yang dipercepat dengan unit pemrosesan grafis (GPU). Untuk informasi selengkapnya, lihat komputasi yang didukung GPU.
VM komputasi rahasia Azure
Tipe VM komputasi rahasia Azure mencegah akses tidak sah ke data ketika sedang digunakan, termasuk dari operator cloud. Jenis VM ini bermanfaat bagi industri dan wilayah yang sangat diatur, serta bisnis dengan data sensitif di cloud. Untuk informasi selengkapnya mengenai komputasi rahasia Azure, lihat tautan tersebut.
Untuk menjalankan beban kerja Anda menggunakan VM komputasi rahasia Azure, pilih dari seri VM DC atau EC di menu dropdown untuk simpul pekerja dan simpul pengemudi. Lihat opsi VM Rahasia Azure.
Komputasi simpul tunggal
Kotak centang simpul tunggal memungkinkan Anda membuat sumber daya komputasi simpul tunggal.
Komputasi simpul tunggal ditujukan untuk pekerjaan yang menggunakan sejumlah kecil data atau beban kerja yang tidak terdistribusi seperti pustaka pembelajaran mesin simpul tunggal. Komputasi multi-simpul harus digunakan untuk pekerjaan yang lebih besar dengan beban kerja terdistribusi.
Properti simpul tunggal
Sumber daya komputasi simpul tunggal memiliki properti berikut:
- Menjalankan Spark secara lokal.
- Driver bertindak sebagai master dan pekerja, tanpa node pekerja.
- Membuat satu utas eksekutor per inti logis dalam sumber daya pemrosesan, dikurangi 1 inti untuk pengemudi.
- Menyimpan semua output log
stderr,stdout, danlog4jdi log driver. - Tidak dapat dikonversi ke sumber daya komputasi multi-simpul.
Memilih simpul tunggal atau multi
Pertimbangkan kasus penggunaan Anda saat memutuskan antara node tunggal atau simpul multipel:
Pemrosesan data skala besar akan menghabiskan sumber daya pada satu sumber daya komputasi simpul. Untuk beban kerja ini, Databricks merekomendasikan penggunaan komputasi multi-simpul.
Sumber daya komputasi multi-simpul tidak dapat diskalakan ke 0 pekerja. Gunakan komputasi simpul tunggal sebagai gantinya.
Penjadwalan GPU tidak diaktifkan pada komputasi simpul tunggal.
Pada komputasi simpul tunggal, Spark tidak dapat membaca file Parquet dengan kolom UDT. Pesan kesalahan berikut menghasilkan:
The Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.Untuk mengatasi masalah ini, nonaktifkan pembaca Parquet bawaan:
spark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
Aktifkan autoscaling
Saat Mengaktifkan penskalaan otomatis dicentang, Anda dapat memberikan jumlah minimum dan maksimum pekerja untuk sumber daya komputasi. Databricks kemudian memilih jumlah pekerja yang sesuai yang diperlukan untuk menjalankan pekerjaan Anda.
Untuk menetapkan jumlah minimum dan maksimum pekerja yang sumber daya komputasi Anda akan sesuaikan secara otomatis, gunakan kolom Min dan Max di samping dropdown jenis pekerja .
Jika Anda tidak mengaktifkan penskalaan otomatis, Anda harus memasukkan jumlah pekerja tetap di bidang Pekerja di samping dropdown Jenis pekerja .
Catatan
Saat sumber daya komputasi berjalan, halaman detail komputasi menampilkan jumlah pekerja yang dialokasikan. Anda dapat membandingkan jumlah pekerja yang dialokasikan dengan konfigurasi pekerja dan melakukan penyesuaian sesuai kebutuhan.
Manfaat penskalaan otomatis
Dengan penskalaan otomatis, Azure Databricks merealokasi pekerja secara dinamis untuk memperhitungkan karakteristik pekerjaan Anda. Bagian tertentu dari alur Anda mungkin lebih menuntut secara komputasi daripada yang lain, dan Databricks secara otomatis menambahkan pekerja tambahan selama fase pekerjaan Anda ini (dan menghapusnya saat tidak lagi diperlukan).
Penskalaan otomatis memudahkan untuk mencapai pemanfaatan tinggi karena Anda tidak perlu menyediakan komputasi yang sesuai dengan beban kerja. Ini berlaku terutama untuk beban kerja yang persyaratannya berubah dari waktu ke waktu (seperti menjelajahi himpunan data selama sehari), tetapi juga dapat berlaku untuk beban kerja satu kali lebih pendek yang persyaratan provisinya tidak diketahui. Autoscaling dengan demikian menawarkan dua keuntungan:
- Beban kerja dapat berjalan lebih cepat dibandingkan dengan sumber daya komputasi berukuran tetap yang kurang memadai.
- Penskalaan otomatis dapat mengurangi biaya keseluruhan dibandingkan dengan sumber daya komputasi yang ukurannya tetap.
Bergantung pada ukuran konstanta sumber daya komputasi dan beban kerja, penskalaan otomatis memberi Anda satu atau kedua manfaat ini secara bersamaan. Ukuran komputasi dapat di bawah jumlah minimum pekerja yang dipilih saat penyedia cloud mengakhiri instans. Dalam hal ini, Azure Databricks terus mencoba memprovisikan ulang instans untuk mempertahankan jumlah minimum pekerja.
Catatan
Penskalaan otomatis tidak tersedia untuk tugas spark-submit.
Catatan
Penskalaan otomatis komputasi memiliki batasan dalam menurunkan ukuran kluster untuk beban kerja streaming yang terstruktur. Databricks merekomendasikan penggunaan Alur Deklaratif Lakeflow Spark dengan penskalaan otomatis yang disempurnakan untuk beban kerja streaming. Lihat Mengoptimalkan pemanfaatan kluster Alur Deklaratif Lakeflow Spark dengan Autoscaling.
Bagaimana penskalaan otomatis berperilaku
Ruang kerja pada paket Premium menggunakan penskalaan otomatis yang dioptimalkan. Ruang kerja pada paket harga standar menggunakan penskalaan otomatis standar.
Autoscaling yang dioptimalkan memiliki karakteristik berikut:
- Skalakan dari min ke maks dalam 2 langkah.
- Dapat mengurangi skala, meskipun sumber daya komputasi tidak menganggur, dengan melihat status file shuffle.
- Mengurangi skala berdasarkan persentase dari node saat ini.
- Dalam komputasi pekerjaan, skala akan mengecil jika sumber daya komputasi kurang digunakan selama 40 detik terakhir.
- Pada komputasi serba guna, menurunkan skala jika sumber daya komputasi kurang digunakan selama 150 detik terakhir.
-
spark.databricks.aggressiveWindowDownSProperti konfigurasi Spark menentukan dalam hitungan detik seberapa sering komputasi membuat keputusan penurunan skala. Meningkatkan nilai menyebabkan sistem menurunkan tingkat operasi lebih lambat. Nilai maksimumnya adalah 600.
Penskalaan otomatis standar digunakan di ruang kerja rencana standar. Autoscaling standar memiliki karakteristik berikut:
- Dimulai dengan menambahkan 8 simpul. Kemudian meningkatkan skala secara eksponensial, mengambil sejumlah langkah yang diperlukan untuk mencapai maksimum.
- Mengurangi sumber daya ketika 90% node tidak sibuk selama 10 menit dan sistem komputasi telah menganggur setidaknya selama 30 detik.
- Menurunkan skala secara eksponensial, dimulai dengan 1 node.
Peringatan
Jangan aktifkan Apache Spark Dynamic Allocation (spark.dynamicAllocation.enabled) pada sumber daya komputasi yang menggunakan penskalaan otomatis Databricks. Autoscaling Databricks mengelola node pekerja dan siklus hidup executor di tingkat platform. Mengaktifkan Alokasi Dinamis Spark secara paralel dapat menyebabkan keputusan penskalaan yang bertentangan, yang mengarah ke pergantian eksekutor, NODES_LOST kesalahan, dan tugas yang tidak pernah dijalankan.
Penskalakan otomatis dengan kumpulan
Jika Anda melampirkan sumber daya komputasi ke kumpulan, pertimbangkan hal berikut:
- Pastikan ukuran compute yang diminta kurang dari atau sama dengan jumlah minimum instans menganggur di kumpulan. Jika lebih besar, waktu mulai komputasi akan setara dengan komputasi yang tidak menggunakan kumpulan.
- Pastikan ukuran komputasi maksimum kurang dari atau sama dengan kapasitas maksimum kumpulan. Jika lebih besar, pembuatan komputasi akan gagal.
Contoh penskalaan otomatis
Jika Anda mengonfigurasi ulang sumber daya komputasi statis untuk skala otomatis, Azure Databricks segera mengubah ukuran sumber daya komputasi dalam batas minimum dan maksimum lalu memulai penskalaan otomatis. Sebagai contoh, tabel berikut menunjukkan apa yang terjadi pada sumber daya komputasi dengan ukuran awal tertentu jika Anda mengonfigurasi ulang sumber daya komputasi untuk skala otomatis antara 5 dan 10 simpul.
| Ukuran awal | 'Ukuran setelah konfigurasi ulang |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Pengaturan performa tingkat lanjut
Pengaturan berikut muncul di bawah bagian performa lanjutan di antarmuka pengguna komputasi formulir sederhana.
instans turunan
Untuk menghemat biaya, Anda dapat memilih menggunakan instans Spot, juga dikenal sebagai instans Spot Azure, dengan memeriksa kotak centang instans Spot.

Instans pertama akan selalu sesuai permintaan (node driver selalu sesuai permintaan) dan instans berikutnya akan menjadi instans spot.
Jika instans dikeluarkan karena tidak tersedia, Azure Databricks akan mencoba memperoleh instans spot baru untuk menggantikan instans yang dikeluarkan. Jika instans spot tidak dapat diperoleh, instans sesuai permintaan digunakan untuk menggantikan instans yang dihentikan. Failback sesuai permintaan ini hanya didukung untuk instans spot yang telah terakuisisi sepenuhnya dan sedang berjalan. Instans spot yang gagal selama proses penyiapan tidak diganti secara otomatis.
Selain itu, ketika node baru ditambahkan ke sumber daya komputasi yang ada, Azure Databricks berusaha mendapatkan instans spot untuk node tersebut.
Penghentian otomatis
Anda dapat mengatur penghentian otomatis untuk komputasi di bawah bagian Performa tingkat lanjut. Selama pembuatan komputasi, tentukan periode tidak aktif dalam hitungan menit setelah itu Anda ingin sumber daya komputasi dihentikan.
Jika perbedaan antara waktu saat ini dan perintah terakhir yang dijalankan pada sumber daya komputasi lebih dari periode tidak aktif yang ditentukan, Azure Databricks secara otomatis mengakhiri sumber daya komputasi tersebut. Untuk informasi selengkapnya tentang penghentian komputasi, lihat Mengakhiri komputasi.
Jenis driver
Anda dapat memilih jenis driver di bawah bagian performa tingkat lanjut. Simpul driver mempertahankan informasi status semua buku catatan yang dilampirkan ke sumber daya komputasi. Node pengemudi juga mempertahankan SparkContext, menafsirkan semua perintah yang Anda jalankan dari buku catatan atau pustaka pada sumber daya komputasi, dan menjalankan master Apache Spark yang berkoordinasi dengan pelaksana Spark.
Nilai default dari tipe node driver sama dengan tipe node pekerja. Anda dapat memilih jenis node driver yang lebih besar dengan lebih banyak memori jika Anda berencana untuk collect() sejumlah besar data dari pekerja-pekerja Spark dan menganalisisnya di notebook.
Kiat
Karena node driver mempertahankan semua informasi status notebook yang terpasang, pastikan untuk melepaskan notebook yang tidak digunakan dari node driver.
Tagar
Tag memungkinkan Anda untuk dengan mudah memantau biaya sumber daya komputasi yang digunakan oleh berbagai grup di organisasi Anda. Tentukan tag sebagai pasangan kunci-nilai saat Anda membuat komputasi, dan Azure Databricks menerapkan tag ini ke sumber daya cloud seperti VM dan volume disk, serta log penggunaan Databricks.
Untuk komputasi yang diluncurkan dari kumpulan, tag kustom hanya diterapkan ke laporan penggunaan DBU dan tidak disebarluaskan ke sumber daya cloud.
Untuk informasi terperinci tentang cara kumpulan dan jenis tag komputasi bekerja sama, lihat Menggunakan tag untuk mengaitkan dan melacak penggunaan
Untuk menambahkan tag ke sumber daya komputasi Anda:
- Di bagian Tag , tambahkan pasangan kunci-nilai untuk setiap tag kustom.
- Klik Tambahkan.
Pengaturan tingkat lanjut
Pengaturan berikut muncul di bawah bagian Tingkat Lanjut dari antarmuka pengguna komputasi formulir sederhana:
- Cara Akses
- Mengaktifkan penyimpanan lokal yang melakukan penskalaan otomatis
- Enkripsi disk lokal
- Konfigurasi Spark
- Pengiriman log komputer
- akses SSH ke komputasi
- variabel Lingkungan
Mode akses
Mode akses adalah fitur keamanan yang menentukan siapa yang dapat menggunakan sumber daya komputasi dan data yang dapat mereka akses menggunakan sumber daya komputasi. Setiap sumber daya komputasi dalam Azure Databricks memiliki mode akses. Pengaturan mode akses ditemukan di bawah bagian Tingkat Lanjut dari antarmuka pengguna komputasi formulir sederhana.
Pemilihan mode akses Otomatis secara default, yang berarti mode akses dipilih secara otomatis untuk Anda berdasarkan Databricks Runtime yang Anda pilih. Otomatis diatur ke Standar kecuali runtime pembelajaran mesin otomatis atau Runtime Databricks yang lebih rendah dari 14.3 dipilih, maka Dedicated digunakan.
Databricks merekomendasikan agar Anda menggunakan mode akses standar kecuali fungsionalitas yang diperlukan tidak didukung.
| Mode Akses | Description | Bahasa yang Didukung |
|---|---|---|
| Standar | Dapat digunakan oleh beberapa pengguna dengan isolasi data di antara pengguna. | Python, SQL, Scala |
| Dedicated | Dapat ditetapkan ke dan digunakan oleh satu pengguna atau grup. | Python, SQL, Scala, R |
Untuk informasi terperinci tentang dukungan fungsionalitas untuk setiap mode akses ini, lihat Persyaratan dan batasan komputasi standar serta Persyaratan dan batasan komputasi khusus.
Catatan
Di Databricks Runtime 13.3 LTS ke atas, skrip dan pustaka init didukung oleh semua mode akses. Persyaratan dan tingkat dukungan bervariasi. Lihat Di mana skrip init dapat diinstal? dan pustaka dengan jangkauan komputasi.
Aktifkan penyimpanan lokal yang berskala otomatis
Seringkali sulit untuk memperkirakan berapa banyak ruang disk yang akan diambil pekerjaan tertentu. Untuk menyelamatkan Anda agar tidak perlu memperkirakan berapa banyak gigabyte disk terkelola untuk dilampirkan ke komputasi Anda pada waktu pembuatan, Azure Databricks secara otomatis memungkinkan penskalaan otomatis penyimpanan lokal pada semua komputasi Azure Databricks.
Dengan penskalaan otomatis penyimpanan lokal, Azure Databricks memantau jumlah ruang disk kosong yang tersedia pada pekerja Spark komputasi Anda. Jika pekerja mulai kehabisan disk, Azure Databricks otomatis melampirkan disk terkelola baru ke pekerja sebelum ruang disk habis. Disk terpasang hingga batas 5 TB dari total ruang disk per komputer virtual (termasuk penyimpanan lokal awal komputer virtual).
Disk terkelola yang terpasang pada komputer virtual dilepaskan hanya ketika komputer virtual dikembalikan ke Azure. Artinya, disk terkelola tidak pernah terlepas dari komputer virtual selama disk tersebut merupakan bagian dari komputasi yang sedang berjalan. Untuk menurunkan skala penggunaan disk terkelola, Azure Databricks merekomendasikan penggunaan fitur ini dalam komputasi yang dikonfigurasi dengan komputasi autoscaling atau automatik penghentian.
Enkripsi disk lokal
Penting
Fitur ini ada di Pratinjau Publik.
Beberapa jenis instans yang Anda gunakan untuk menjalankan komputasi mungkin memiliki disk yang terpasang secara lokal. Azure Databricks dapat menyimpan data acak atau data sementara pada disk yang terpasang secara lokal ini. Untuk memastikan semua data dalam keadaan diam dienkripsi untuk semua jenis penyimpanan, termasuk data pengacakan yang disimpan sementara pada disk lokal pada sumber daya komputasi, Anda dapat mengaktifkan enkripsi disk lokal.
Penting
Beban kerja Anda mungkin berjalan lebih lambat karena dampak performa membaca dan menulis data terenkripsi ke dan dari volume lokal.
Ketika enkripsi disk lokal diaktifkan, Azure Databricks menghasilkan kunci enkripsi secara lokal yang unik untuk setiap simpul komputasi dan digunakan untuk mengenkripsi semua data yang disimpan pada disk lokal. Cakupan kunci bersifat lokal untuk setiap simpul komputasi dan dihancurkan bersama dengan simpul komputasi itu sendiri. Selama masa pakainya, kunci berada dalam memori untuk enkripsi dan dekripsi dan disimpan dienkripsi pada disk.
Untuk mengaktifkan enkripsi disk lokal, Anda harus menggunakan API Kluster. Selama pembuatan atau pengeditan komputasi, setel enable_local_disk_encryption ke true.
Konfigurasi Spark
Untuk menyempurnakan pekerjaan Spark, Anda dapat menyediakan properti konfigurasi Spark kustom.
Pada halaman konfigurasi komputasi, klik tombol Tingkat Lanjut.
Klik tab Spark.
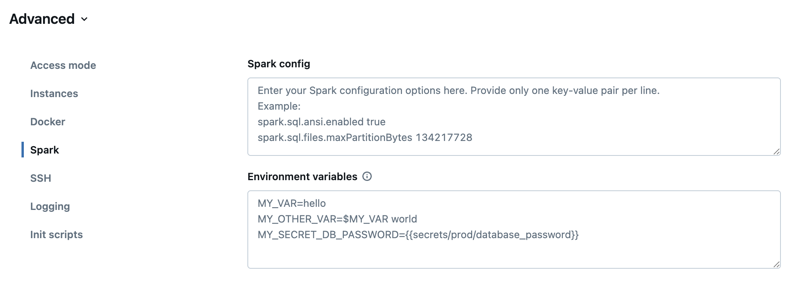
Di Konfigurasi Spark, masukkan properti konfigurasi sebagai satu pasangan nilai kunci per baris.
Saat Anda mengonfigurasi komputasi menggunakan Clusters API, atur properti Spark di spark_conf bidang di API buat kluster atau API perbarui kluster.
Untuk menerapkan konfigurasi Spark pada komputasi, admin ruang kerja dapat menggunakan kebijakan komputasi.
Ambil suatu properti konfigurasi Spark dari penyimpanan rahasia
Databricks merekomendasikan untuk menyimpan informasi sensitif, seperti kata sandi, secara rahasia, bukan teks biasa. Untuk mereferensikan rahasia dalam konfigurasi Spark, gunakan sintaks berikut:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Misalnya, untuk mengatur properti konfigurasi Spark yang disebut password ke nilai rahasia yang disimpan di secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
Untuk informasi selengkapnya, lihat Mengelola rahasia.
Pengiriman log sistem komputasi
Saat Anda membuat komputasi serbaguna atau komputasi pekerjaan, Anda dapat menentukan lokasi untuk log kluster, termasuk log dari driver Spark, node pekerja, dan kejadian. Log dikirim setiap lima menit dan diarsipkan per jam di tujuan yang Anda pilih. Databricks terus mengirimkan log hingga sumber daya komputasi dihentikan.
Anda dapat menyimpan log di salah satu lokasi berikut:
- Volume (disarankan): Menyimpan log di jalur volume Unity Catalog. Ini adalah opsi yang direkomendasikan dan paling aman saat menggunakan sumber daya komputasi yang mendukung Katalog Unity.
- DBFS (warisan): Menyimpan log di jalur Databricks File System (DBFS). Opsi ini hanya tersedia jika direktori root dan mount point DBFS tidak dinonaktifkan untuk lingkungan kerja. Lihat Nonaktifkan akses ke root DBFS dan mount di ruang kerja Azure Databricks yang ada.
Untuk mengonfigurasi lokasi pengiriman log:
- Pada halaman komputasi, klik tombol Tingkat Lanjut.
- Klik tab Pengelogan.
- Pilih jenis tujuan.
- Masukkan jalur Log .
Untuk menyimpan log, Databricks membuat subfolder di jalur log pilihan Anda yang dinamai sesuai dengan cluster_idkomputernya.
Misalnya, jika jalur log yang ditentukan /Volumes/catalog/schema/volume, log untuk 06308418893214 dikirimkan ke /Volumes/catalog/schema/volume/06308418893214.
Catatan
Mengirimkan log ke volume hanya didukung pada komputasi yang mendukung Katalog Unity dengan mode akses Standar atau Mode akses khusus yang ditetapkan untuk pengguna. Ini tidak didukung dengan Mode akses khusus yang ditetapkan ke grup. Jika Anda memilih volume sebagai jalur, verifikasi bahwa pemilik komputasi atau pengguna yang ditetapkan ke dalamnya memiliki izin READ VOLUME dan WRITE VOLUME pada volume tersebut. Lihat Hak Istimewa untuk volume Katalog Unity.
Akses SSH ke sumber daya komputasi
Untuk alasan keamanan, dalam Azure Databricks port SSH ditutup secara default. Jika Anda ingin mengaktifkan akses SSH ke kluster Spark Anda, lihat SSH ke simpul pengendali.
Catatan
SSH hanya dapat diaktifkan jika ruang kerja Anda disebarkan di jaringan virtual Azure anda sendiri.
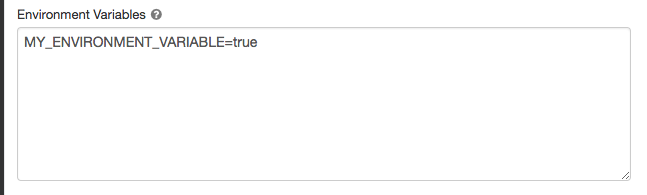
Variabel lingkungan
Konfigurasikan variabel lingkungan kustom yang dapat Anda akses dari skrip init yang berjalan pada sumber daya komputasi. Databricks juga menyediakan variabel lingkungan yang telah ditentukan sebelumnya yang dapat Anda gunakan dalam skrip init. Anda tidak dapat mengganti variabel lingkungan yang telah ditentukan sebelumnya ini.
Pada halaman konfigurasi komputasi, klik Tingkat Lanjut.
Klik tab Spark.
Atur variabel lingkungan di bidang variabel lingkungan.
Anda juga dapat mengatur variabel lingkungan menggunakan bidang spark_env_vars di Create cluster API atau Update cluster API.