Mengonfigurasi pengaturan alur untuk Tabel Langsung Delta
Artikel ini memiliki detail tentang mengonfigurasi pengaturan alur untuk Tabel Langsung Delta. Delta Live Tables memiliki antarmuka pengguna untuk mengonfigurasi dan mengedit pengaturan alur. UI juga memiliki opsi untuk menampilkan dan mengedit pengaturan di JSON.
Catatan
Anda dapat mengonfigurasi sebagian besar pengaturan dengan UI atau spesifikasi JSON. Beberapa opsi tingkat lanjut hanya tersedia menggunakan konfigurasi JSON.
Databricks merekomendasikan untuk membiasakan diri dengan pengaturan Tabel Langsung Delta menggunakan UI. Jika perlu, Anda dapat langsung mengedit konfigurasi JSON di ruang kerja. File konfigurasi JSON juga berguna saat menyebarkan alur ke lingkungan baru atau menggunakan CLI atau REST API.
Untuk referensi lengkap ke pengaturan konfigurasi JSON Delta Live Tables, lihat Konfigurasi alur Delta Live Tables.
Catatan
- Karena sumber daya komputasi dikelola sepenuhnya untuk alur DLT tanpa server (Pratinjau Umum), pengaturan komputasi seperti Penskalaan Otomatis yang Ditingkatkan, kebijakan kluster, jenis instans, dan tag kluster tidak tersedia di UI Tabel Langsung Delta saat Anda memilih Tanpa Server untuk alur.
- Anda tidak dapat menambahkan pengaturan komputasi secara manual dalam
clustersobjek dalam konfigurasi JSON untuk alur, dan mencoba melakukannya menghasilkan kesalahan.
Untuk mempelajari tentang mengaktifkan alur DLT tanpa server, hubungi tim akun Azure Databricks Anda.
Pilih edisi produk
Pilih edisi produk Delta Live Tables dengan fitur terbaik untuk persyaratan alur Anda. Edisi produk berikut tersedia:
Coreuntuk menjalankan beban kerja penyerapan streaming.CorePilih edisi jika alur Anda tidak memerlukan fitur tingkat lanjut seperti mengubah ekspektasi pengambilan data (CDC) atau Tabel Langsung Delta.Prountuk menjalankan penyerapan streaming dan beban kerja CDC. Edisi produkPromendukung semua fiturCore, ditambah dukungan untuk beban kerja yang memerlukan pembaruan tabel berdasarkan perubahan pada data sumber.Advanceduntuk menjalankan beban kerja penyerapan streaming, beban kerja CDC, dan beban kerja yang membutuhkan ekspektasi. Edisi produkAdvancedmendukung fitur edisiCoredanPro, dan juga mendukung penegakan batasan kualitas data dengan harapan Delta Live Tables.
Anda dapat memilih edisi produk saat Anda membuat atau mengedit alur. Anda dapat memilih edisi yang berbeda untuk setiap alur. Lihat halaman produk Delta Live Tables.
Catatan: Jika alur Anda menyertakan fitur yang tidak didukung oleh edisi produk yang dipilih, seperti ekspektasi, Anda akan menerima pesan kesalahan yang menjelaskan alasan kesalahan tersebut. Anda kemudian dapat mengedit alur untuk memilih edisi yang sesuai.
Pilih mode alur
Anda dapat memperbarui alur Anda terus menerus atau dengan pemicu manual berdasarkan mode alur. Lihat Eksekusi alur berkelanjutan vs. yang dipicu.
Pilih kebijakan kluster
Pengguna harus memiliki izin untuk menyebarkan komputasi untuk mengonfigurasi dan memperbarui alur Tabel Langsung Delta. Admin ruang kerja dapat mengonfigurasi kebijakan kluster untuk memberi pengguna akses ke sumber daya komputasi untuk Tabel Langsung Delta. Lihat Menentukan batas pada komputasi alur Delta Live Tables.
Catatan
Kebijakan kluster bersifat opsional. Tanyakan kepada administrator ruang kerja Anda jika Anda tidak memiliki hak komputasi yang diperlukan untuk Tabel Langsung Delta.
Untuk memastikan bahwa nilai default kebijakan kluster diterapkan dengan benar, atur
apply_policy_default_valuesnilai ketruedalam konfigurasi kluster dalam konfigurasi alur Anda:{ "clusters": [ { "label": "default", "policy_id": "<policy-id>", "apply_policy_default_values": true } ] }
Mengonfigurasi pustaka kode sumber
Anda dapat menggunakan pemilih file di UI Delta Live Tables untuk mengonfigurasi kode sumber yang menentukan alur Anda. Kode sumber alur didefinisikan dalam buku catatan Databricks atau skrip SQL atau Python yang disimpan dalam file ruang kerja. Saat membuat atau mengedit alur, Anda bisa menambahkan satu atau beberapa buku catatan atau file ruang kerja atau kombinasi buku catatan dan file ruang kerja.
Karena Tabel Langsung Delta secara otomatis menganalisis dependensi himpunan data untuk membuat grafik pemrosesan untuk alur Anda, Anda dapat menambahkan pustaka kode sumber dalam urutan apa pun.
Anda juga dapat mengubah file JSON untuk menyertakan kode sumber Tabel Langsung Delta yang ditentukan dalam skrip SQL dan Python yang disimpan dalam file ruang kerja. Contoh berikut mencakup buku catatan dan file ruang kerja:
{
"name": "Example pipeline 3",
"storage": "dbfs:/pipeline-examples/storage-location/example3",
"libraries": [
{ "notebook": { "path": "/example-notebook_1" } },
{ "notebook": { "path": "/example-notebook_2" } },
{ "file": { "path": "/Workspace/Users/<user-name>@databricks.com/Apply_Changes_Into/apply_changes_into.sql" } },
{ "file": { "path": "/Workspace/Users/<user-name>@databricks.com/Apply_Changes_Into/apply_changes_into.py" } }
]
}
Tentukan lokasi penyimpanan
Anda dapat menentukan lokasi penyimpanan untuk alur yang diterbitkan ke metastore Apache Hive. Motivasi utama untuk menentukan lokasi adalah mengontrol lokasi penyimpanan objek untuk data yang ditulis oleh alur Anda.
Karena semua tabel, data, titik pemeriksaan, dan metadata untuk alur Tabel Langsung Delta dikelola sepenuhnya oleh Tabel Langsung Delta, sebagian besar interaksi dengan himpunan data Tabel Langsung Delta terjadi melalui tabel yang terdaftar ke metastore Apache Hive atau Katalog Unity.
Tentukan skema target untuk tabel output alur
Meskipun opsional, Anda harus menentukan target untuk menerbitkan tabel yang dibuat oleh alur Anda kapan saja Anda bergerak melampaui pengembangan dan pengujian untuk alur baru. Menerbitkan alur ke target membuat himpunan data tersedia untuk kueri di tempat lain di lingkungan Azure Databricks Anda. Lihat Menerbitkan data dari Tabel Langsung Delta ke metastore Apache Hive atau Menggunakan Katalog Unity dengan alur Tabel Langsung Delta Anda.
Mengonfigurasi pengaturan komputasi Anda
Catatan
Karena sumber daya komputasi dikelola sepenuhnya untuk alur DLT tanpa server (Pratinjau Umum), pengaturan komputasi tidak tersedia saat Anda memilih Tanpa Server untuk alur.
Setiap alur Tabel Langsung Delta memiliki dua kluster terkait:
- Kluster
updatesmemproses pembaruan alur. - Kluster
maintenancemenjalankan tugas pemeliharaan harian.
Konfigurasi yang digunakan oleh kluster ini ditentukan oleh clusters atribut yang ditentukan dalam pengaturan alur Anda.
Anda dapat menambahkan pengaturan komputasi yang hanya berlaku untuk jenis kluster tertentu dengan menggunakan label kluster. Ada tiga label yang dapat Anda gunakan saat mengonfigurasi kluster alur:
Catatan
Pengaturan label kluster dapat dihilangkan jika Anda hanya menentukan satu konfigurasi kluster. Label default diterapkan ke konfigurasi kluster jika tidak ada pengaturan untuk label yang disediakan. Pengaturan label kluster diperlukan hanya jika Anda perlu menyesuaikan pengaturan untuk jenis kluster yang berbeda.
- Label
defaultmenentukan pengaturan komputasi untuk diterapkan keupdateskluster danmaintenance. Menerapkan pengaturan yang sama ke kedua kluster meningkatkan keandalan pemeliharaan yang dijalankan dengan memastikan bahwa konfigurasi yang diperlukan seperti kredensial akses data untuk lokasi penyimpanan diterapkan ke kluster pemeliharaan. - Label
maintenancemenentukan pengaturan komputasi yang hanyamaintenanceberlaku untuk kluster. Anda juga dapat menggunakanmaintenancelabel untuk mengambil alih pengaturan yang dikonfigurasidefaultoleh label. - Label
updatesmenentukan pengaturan yang hanyaupdatesberlaku untuk kluster.updatesGunakan label untuk mengonfigurasi pengaturan yang seharusnya tidak diterapkan kemaintenancekluster.
Pengaturan yang default ditentukan menggunakan label dan updates digabungkan untuk membuat konfigurasi akhir untuk updates kluster. Jika pengaturan yang sama didefinisikan menggunakan default label dan updates , pengaturan yang ditentukan dengan updates label akan mengambil alih pengaturan yang ditentukan dengan default label.
Contoh berikut mendefinisikan parameter konfigurasi Spark yang ditambahkan hanya ke konfigurasi untuk updates kluster:
{
"clusters": [
{
"label": "default",
"autoscale": {
"min_workers": 1,
"max_workers": 5,
"mode": "ENHANCED"
}
},
{
"label": "updates",
"spark_conf": {
"key": "value"
}
}
]
}
Tabel Langsung Delta memiliki opsi serupa untuk pengaturan kluster seperti komputasi lain di Azure Databricks. Seperti pengaturan alur lainnya, Anda dapat memodifikasi konfigurasi JSON untuk kluster untuk menentukan opsi yang tidak ada di UI. Lihat Komputasi.
Catatan
- Karena runtime Tabel Langsung Delta mengelola siklus hidup kluster alur dan menjalankan versi kustom Databricks Runtime, Anda tidak dapat mengatur beberapa pengaturan kluster secara manual dalam konfigurasi alur, seperti versi Spark atau nama kluster. Lihat Atribut kluster yang tidak dapat diatur pengguna.
- Anda dapat mengonfigurasi alur Delta Live Tables untuk memanfaatkan Photon. Lihat Apa itu Photon?.
Pilih jenis instans untuk menjalankan alur
Secara default, Tabel Langsung Delta memilih jenis instans untuk simpul driver dan pekerja yang menjalankan alur Anda, tetapi Anda juga dapat mengonfigurasi jenis instans secara manual. Misalnya, Anda mungkin ingin memilih jenis instans untuk meningkatkan performa alur atau mengatasi masalah memori saat menjalankan alur Anda. Anda dapat mengonfigurasi jenis instans saat membuat atau mengedit alur dengan REST API, atau di UI Tabel Langsung Delta.
Untuk mengonfigurasi jenis instans saat Anda membuat atau mengedit alur di UI Tabel Langsung Delta:
- Klik tombol Pengaturan.
- Di bagian Tingkat Lanjut dari pengaturan alur, di menu drop-down Jenis pekerja dan Jenis driver, pilih jenis instans untuk alur.
Untuk mengonfigurasi jenis instans dalam pengaturan JSON alur, klik tombol JSON dan masukkan konfigurasi jenis instans dalam konfigurasi kluster:
Catatan
Untuk menghindari penetapan sumber daya yang tidak perlu ke maintenance kluster, contoh ini menggunakan label untuk mengatur jenis instans updates hanya updates untuk kluster. Untuk menetapkan jenis instans ke kluster updates dan maintenance , gunakan default label atau hilangkan pengaturan untuk label. Label default diterapkan ke konfigurasi kluster alur jika tidak ada pengaturan untuk label yang disediakan. Lihat Mengonfigurasi pengaturan komputasi Anda.
{
"clusters": [
{
"label": "updates",
"node_type_id": "Standard_D12_v2",
"driver_node_type_id": "Standard_D3_v2",
"..." : "..."
}
]
}
Menggunakan penskalaan otomatis untuk meningkatkan efisiensi dan mengurangi penggunaan sumber daya
Gunakan Penskalaan Otomatis yang Ditingkatkan untuk mengoptimalkan pemanfaatan kluster alur Anda. Autoscaling yang Ditingkatkan menambahkan sumber daya tambahan hanya jika sistem menentukan sumber daya tersebut akan meningkatkan kecepatan pemrosesan alur. Sumber daya dibebaskan ketika tidak lagi diperlukan, dan kluster dimatikan segera setelah semua pembaruan alur selesai.
Untuk mempelajari selengkapnya tentang Peningkatan Penskalaan Otomatis, termasuk detail konfigurasi, lihat Mengoptimalkan pemanfaatan kluster alur Tabel Langsung Delta dengan Penskalaan Otomatis yang Ditingkatkan.
Penundaan pematian komputasi
Karena kluster Delta Live Tables secara otomatis mati ketika tidak digunakan, mereferensikan kebijakan kluster yang mengatur autotermination_minutes dalam konfigurasi kluster Anda akan menghasilkan kesalahan. Untuk mengontrol perilaku matikan kluster, Anda dapat menggunakan mode pengembangan atau produksi atau menggunakan pipelines.clusterShutdown.delay pengaturan dalam konfigurasi alur. Contoh berikut mengatur pipelines.clusterShutdown.delay nilai menjadi 60 detik:
{
"configuration": {
"pipelines.clusterShutdown.delay": "60s"
}
}
Saat mode production diaktifkan, nilai default untuk pipelines.clusterShutdown.delay adalah 0 seconds. Saat mode development diaktifkan, nilai defaultnya adalah 2 hours.
Membuat kluster simpul tunggal
Jika Anda mengatur num_workers ke 0 dalam pengaturan kluster, kluster dibuat sebagai kluster Simpul Tunggal. Mengonfigurasi kluster penskalaan otomatis dan mengatur min_workers ke 0 serta max_workers ke 0 juga membuat kluster Simpul Tunggal.
Jika Anda mengonfigurasi kluster autoscaling dan hanya mengatur min_workers ke 0, maka kluster tidak dibuat sebagai kluster Simpul Tunggal. Kluster ini memiliki paling sedikit satu pekerja aktif setiap saat sampai dihentikan.
Contoh konfigurasi kluster untuk membuat kluster Simpul Tunggal di Delta Live Tables:
{
"clusters": [
{
"num_workers": 0
}
]
}
Mengonfigurasi tag kluster
Anda dapat menggunakan tag kluster untuk memantau penggunaan untuk kluster alur Anda. Tambahkan tag kluster di UI Tabel Delta Live saat Anda membuat atau mengedit alur, atau dengan mengedit pengaturan JSON untuk kluster alur Anda.
Konfigurasi penyimpanan cloud
Untuk mengakses penyimpanan Azure, Anda harus mengonfigurasi parameter yang diperlukan, termasuk token akses, menggunakan spark.conf pengaturan dalam konfigurasi kluster Anda. Untuk contoh mengonfigurasi akses ke akun penyimpanan Azure Data Lake Storage Gen2 (ADLS Gen2), lihat Mengakses kredensial penyimpanan dengan aman dengan rahasia dalam alur.
Membuat parameter deklarasi himpunan data di Python atau SQL
Kode Python dan SQL yang menentukan apakah himpunan data Anda dapat diparameterkan oleh pengaturan alur. Parameterisasi memungkinkan kasus penggunaan berikut:
- Pemisahan jalur panjang dan variabel lainnya dari kode Anda.
- Mengurangi jumlah data yang diproses dalam lingkungan pengembangan atau penahapan untuk mempercepat pengujian.
- Penggunaan ulang logika transformasi yang sama yang diproses dari beberapa sumber data.
Contoh berikut menggunakan nilai konfigurasi startDate untuk membatasi alur pengembangan ke subset data input:
CREATE OR REFRESH LIVE TABLE customer_events
AS SELECT * FROM sourceTable WHERE date > '${mypipeline.startDate}';
@dlt.table
def customer_events():
start_date = spark.conf.get("mypipeline.startDate")
return read("sourceTable").where(col("date") > start_date)
{
"name": "Data Ingest - DEV",
"configuration": {
"mypipeline.startDate": "2021-01-02"
}
}
{
"name": "Data Ingest - PROD",
"configuration": {
"mypipeline.startDate": "2010-01-02"
}
}
Interval pemicu alur
Anda dapat menggunakan pipelines.trigger.interval untuk mengontrol interval pemicu untuk alur yang memperbarui tabel atau seluruh alur. Karena alur yang dipicu memproses setiap tabel hanya sekali, pipelines.trigger.interval hanya digunakan dengan alur berkelanjutan.
Databricks merekomendasikan pengaturan pipelines.trigger.interval pada tabel individual karena default yang berbeda untuk streaming versus kueri batch. Atur nilai pada alur hanya saat pemrosesan Anda memerlukan pembaruan kontrol untuk seluruh grafik alur.
Anda mengatur pipelines.trigger.interval pada tabel menggunakan spark_conf di Python, atau SET di SQL:
@dlt.table(
spark_conf={"pipelines.trigger.interval" : "10 seconds"}
)
def <function-name>():
return (<query>)
SET pipelines.trigger.interval=10 seconds;
CREATE OR REFRESH LIVE TABLE TABLE_NAME
AS SELECT ...
Untuk mengatur pipelines.trigger.interval pada alur, tambahkan ke configuration objek di pengaturan alur:
{
"configuration": {
"pipelines.trigger.interval": "10 seconds"
}
}
Perbolehkan pengguna non-admin untuk melihat log driver dari alur yang diaktifkan Katalog Unity
Secara default, hanya pemilik alur dan admin ruang kerja yang memiliki izin untuk melihat log driver dari kluster yang menjalankan alur yang mendukung Katalog Unity. Anda dapat mengaktifkan akses ke log driver untuk setiap pengguna dengan izin CAN MANAGE, CAN VIEW, atau CAN RUN dengan menambahkan parameter konfigurasi Spark berikut ke configuration objek dalam pengaturan alur:
{
"configuration": {
"spark.databricks.acl.needAdminPermissionToViewLogs": "false"
}
}
Menambahkan pemberitahuan email untuk peristiwa alur
Anda dapat mengonfigurasi satu atau beberapa alamat email untuk menerima pemberitahuan saat hal berikut ini terjadi:
- Pembaruan alur berhasil diselesaikan.
- Pembaruan alur gagal, baik dengan kesalahan yang dapat diulang atau tidak dapat diulang. Pilih opsi ini untuk menerima pemberitahuan untuk semua kegagalan alur.
- Pembaruan alur gagal dengan kesalahan yang tidak dapat diulang (fatal). Pilih opsi ini untuk menerima pemberitahuan hanya ketika kesalahan yang tidak dapat diulang terjadi.
- Satu aliran data gagal.
Untuk mengonfigurasi pemberitahuan email saat Anda membuat atau mengedit alur:
- Klik Tambahkan pemberitahuan.
- Masukkan satu atau beberapa alamat email untuk menerima pemberitahuan.
- Klik kotak centang untuk setiap jenis pemberitahuan yang akan dikirim ke alamat email yang dikonfigurasi.
- Klik Tambahkan pemberitahuan.
Mengontrol manajemen batu nisan untuk kueri SCD tipe 1
Pengaturan berikut dapat digunakan untuk mengontrol perilaku manajemen batu nisan untuk DELETE peristiwa selama pemrosesan SCD tipe 1:
pipelines.applyChanges.tombstoneGCThresholdInSeconds: Atur nilai ini agar sesuai dengan interval tertinggi yang diharapkan, dalam hitungan detik, antara data di luar urutan. Defaultnya adalah 172800 detik (2 hari).pipelines.applyChanges.tombstoneGCFrequencyInSeconds: Pengaturan ini mengontrol seberapa sering, dalam hitungan detik, batu nisan diperiksa untuk pembersihan. Defaultnya adalah 1800 detik (30 menit).
Lihat TERAPKAN PERUBAHAN API: Menyederhanakan perubahan pengambilan data di Tabel Langsung Delta.
Mengonfigurasi izin alur
Anda harus memiliki CAN MANAGE izin atau IS OWNER pada alur untuk mengelola izin di dalamnya.
Di bar samping, klik Tabel Langsung Delta.
Pilih nama alur.
Klik menu
 kebab , dan pilih Izin.
kebab , dan pilih Izin.Di Pengaturan Izin, pilih menu drop-down Pilih Pengguna, Grup, atau Perwakilan Layanan... lalu pilih pengguna, grup, atau perwakilan layanan.
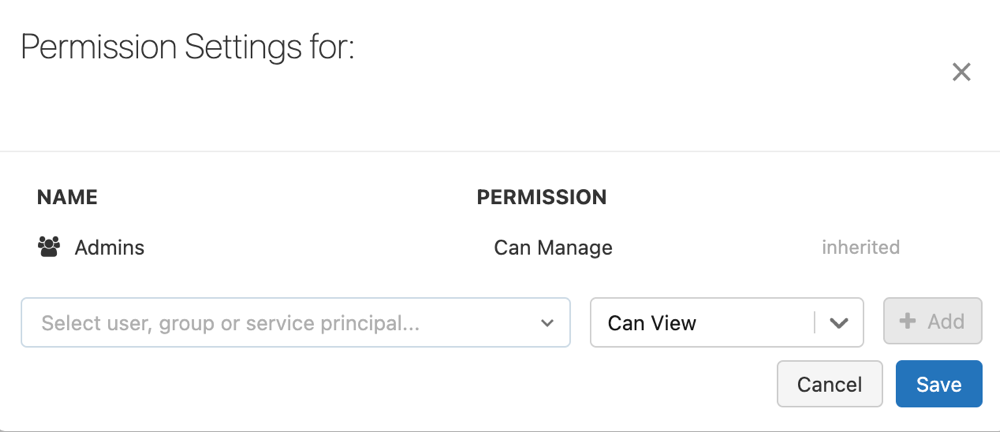
Pilih izin dari menu drop-down izin.
Klik Tambahkan.
Klik Simpan.
Mengaktifkan penyimpanan status RocksDB untuk Tabel Langsung Delta
Anda dapat mengaktifkan manajemen status berbasis RocksDB dengan mengatur konfigurasi berikut sebelum menyebarkan alur:
{
"configuration": {
"spark.sql.streaming.stateStore.providerClass": "com.databricks.sql.streaming.state.RocksDBStateStoreProvider"
}
}
Untuk mempelajari selengkapnya tentang penyimpanan status RocksDB, termasuk rekomendasi konfigurasi untuk RocksDB, lihat Mengonfigurasi penyimpanan status RocksDB di Azure Databricks.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk