Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Nota
Artikel ini membahas Jenkins, yang dikembangkan oleh pihak ketiga. Untuk menghubungi penyedia, lihat Bantuan Jenkins.
Artikel ini menjelaskan cara menggunakan server otomatisasi Jenkins dengan Azure Databricks untuk menerapkan alur kerja pengembangan CI/CD.
Untuk gambaran umum CI/CD dengan Azure Databricks, lihat CI/CD di Azure Databricks. Untuk praktik terbaik, lihat Praktik terbaik dan alur kerja CI/CD yang direkomendasikan di Databricks.
Penyiapan mesin pengembangan lokal
Contoh artikel ini menggunakan Jenkins untuk menginstruksikan Databricks CLI dan Declarative Automation Bundles untuk melakukan hal berikut:
- Buat file roda Python di komputer pengembangan lokal Anda.
- Sebarkan file roda Python bawaan bersama dengan file Python tambahan dan notebook Python dari komputer pengembangan lokal Anda ke ruang kerja Azure Databricks.
- Uji dan jalankan file roda Python dan notebook yang diunggah di ruang kerja tersebut.
Untuk menyiapkan komputer pengembangan lokal Anda untuk menginstruksikan ruang kerja Azure Databricks Anda untuk melakukan tahap build dan unggah untuk contoh ini, lakukan hal berikut pada komputer pengembangan lokal Anda:
Langkah 1: Instal alat yang diperlukan
Dalam langkah ini, Anda menginstal Databricks CLI, Jenkins, jq, dan alat untuk pembangunan wheel Python pada mesin pengembangan lokal Anda. Alat-alat ini diperlukan untuk menjalankan contoh ini.
Instal Databricks CLI versi 0.205 atau lebih tinggi, jika Anda belum melakukannya. Jenkins menggunakan Databricks CLI untuk meneruskan tes contoh ini dan menjalankan instruksi ke ruang kerja Anda. Lihat Menginstal atau memperbarui Databricks CLI.
Instal dan mulai Jenkins, jika Anda belum melakukannya. Lihat Menginstal Jenkins untuk Linux, macOS, atau Windows.
Pasang jq. Contoh ini menggunakan
jquntuk mengurai beberapa output perintah berformat JSON.Gunakan
pipuntuk menginstal alat build wheel Python menggunakan perintah berikut (beberapa sistem mungkin mengharuskan Anda untuk menggunakan alih-alihpip3):pip install --upgrade wheel
Langkah 2: Membuat Alur Jenkins
Dalam langkah ini, Anda menggunakan Jenkins untuk membuat Jenkins Pipeline untuk contoh artikel ini. Jenkins menyediakan beberapa jenis proyek yang berbeda untuk membuat alur CI/CD. Jenkins Pipelines menyediakan antarmuka untuk menentukan tahapan dalam Jenkins Pipeline dengan menggunakan kode Groovy untuk memanggil dan mengonfigurasi plugin Jenkins.
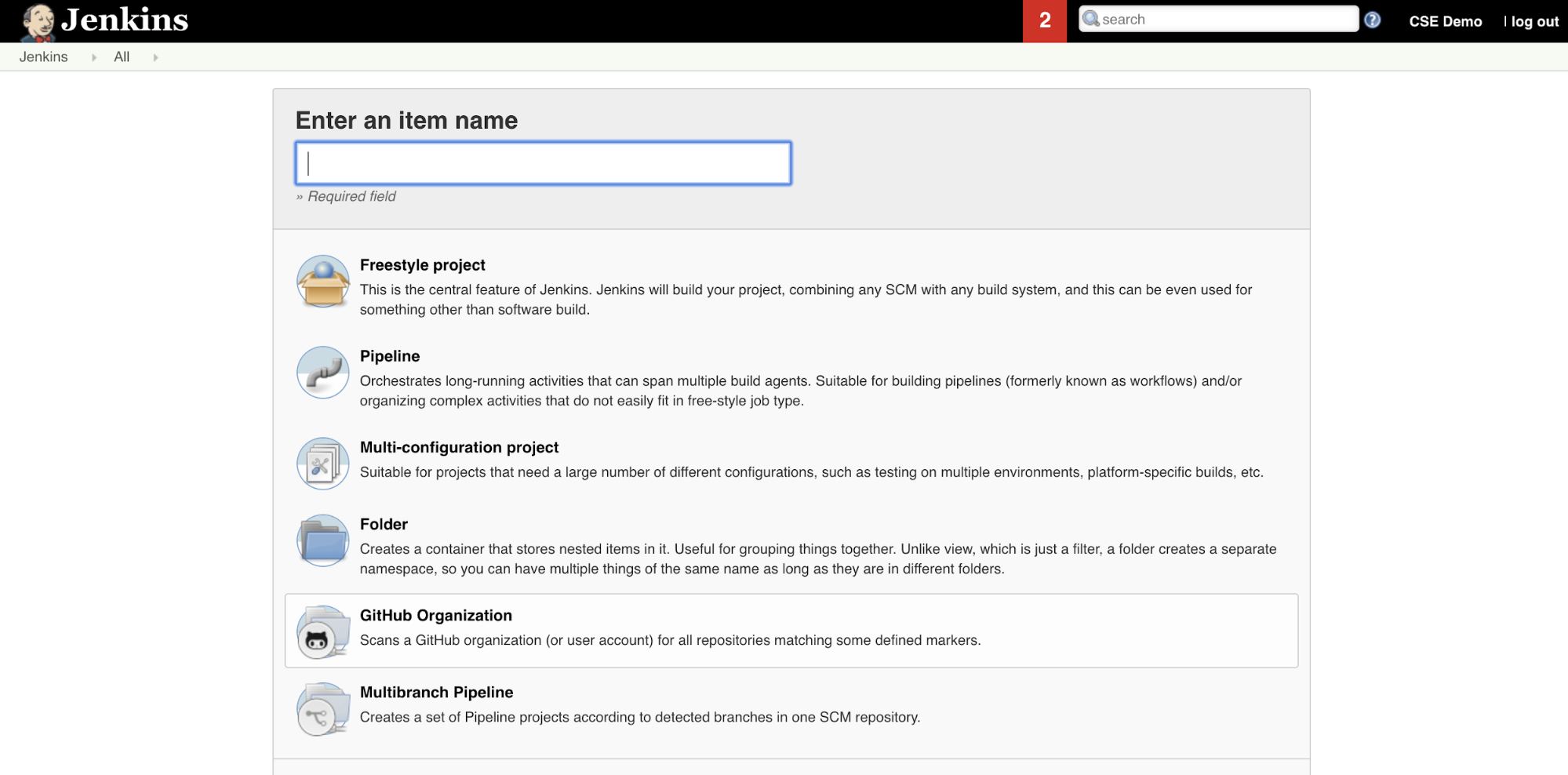
Untuk membuat Alur Jenkins di Jenkins:
- Setelah Anda memulai Jenkins, dari Dasbor Jenkins Anda, klik Item Baru.
- Untuk Masukkan nama item, ketik nama untuk Alur Jenkins, misalnya
jenkins-demo. - Klik ikon Jenis proyek alur .
- Klik OK. Halaman Konfigurasi Pipeline Jenkins akan muncul.
- Di area Alur, di daftar drop-down Definition, pilih Skrip alur dari SCM.
- Di daftar drop-down SCM , pilih Git.
- Untuk URL Repositori, ketik URL ke repositori yang dihosting oleh penyedia Git bagian ketiga Anda.
- Untuk Penentu Cabang, ketik
*/<branch-name>, di mana<branch-name>adalah nama cabang di repositori yang ingin Anda gunakan, misalnya*/main. - Untuk jalur Skrip, ketik
Jenkinsfile, jika belum diatur. Anda membuatJenkinsfilelebih lanjut di artikel ini. - Hapus centang pada kotak berjudul Checkout Ringan, jika sudah dicentang.
- Kliklah Simpan.
Langkah 3: Menambahkan variabel lingkungan global ke Jenkins
Dalam langkah ini, Anda menambahkan tiga variabel lingkungan global ke Jenkins. Jenkins meneruskan variabel lingkungan ini ke Databricks CLI. Databricks CLI memerlukan nilai untuk variabel lingkungan ini untuk mengautentikasi ke ruang kerja Azure Databricks Anda. Contoh ini menggunakan autentikasi mesin-ke-mesin (M2M) OAuth untuk perwakilan layanan (meskipun jenis autentikasi lainnya juga tersedia). Untuk menyiapkan autentikasi M2M OAuth untuk ruang kerja Azure Databricks Anda, lihat Mengotorisasi akses perwakilan layanan ke Azure Databricks dengan OAuth.
Tiga variabel lingkungan global untuk contoh ini adalah:
-
DATABRICKS_HOST, atur ke URL ruang kerja Azure Databricks Anda, dimulai denganhttps://. Lihat Nama instans ruang kerja, URL, dan ID. -
DATABRICKS_CLIENT_ID, diatur ke ID klien perwakilan layanan, yang juga dikenal sebagai ID aplikasinya. -
DATABRICKS_CLIENT_SECRET, atur ke rahasia Azure Databricks OAuth utama layanan.
Untuk mengatur variabel lingkungan global di Jenkins, dari Dasbor Jenkins Anda:
- Di bar samping, klik Kelola Jenkins.
- Di bagian Konfigurasi Sistem , klik Sistem.
- Di bagian Properti global , centang kotak berjudul Variabel lingkungan.
- Klik Tambahkan lalu masukkan Nama dan Nilai variabel lingkungan. Ulangi ini untuk setiap variabel lingkungan tambahan.
- Setelah selesai menambahkan variabel lingkungan, klik Simpan untuk kembali ke Dasbor Jenkins Anda.
Mendesain Jenkins Pipeline
Jenkins menyediakan beberapa jenis proyek yang berbeda untuk membuat alur CI/CD. Contoh ini mengimplementasikan Alur Jenkins. Jenkins Pipelines menyediakan antarmuka untuk menentukan tahapan dalam Jenkins Pipeline dengan menggunakan kode Groovy untuk memanggil dan mengonfigurasi plugin Jenkins.
Anda menulis definisi Alur Jenkins dalam file teks yang disebut Jenkinsfile, yang pada gilirannya diperiksa ke repositori kontrol sumber proyek. Untuk informasi selengkapnya, lihat Jenkins Pipeline. Berikut adalah Alur Jenkins untuk contoh artikel ini. Dalam contoh Jenkinsfile, ganti tempat penampung berikut:
- Ganti
<user-name>dan<repo-name>dengan nama pengguna dan nama repositori untuk Anda yang dihosting oleh penyedia Git bagian ketiga Anda. Artikel ini menggunakan URL GitHub sebagai contoh. - Ganti
<release-branch-name>dengan nama cabang rilis di repositori Anda. Misalnya, ini bisa menjadimain. - Ganti
<databricks-cli-installation-path>dengan jalur pada komputer pengembangan lokal Anda tempat CLI Databricks diinstal. Misalnya, di macOS, ini bisa berupa/usr/local/bin. - Ganti
<jq-installation-path>dengan jalur pada komputer pengembangan lokal Anda tempatjqdiinstal. Misalnya, di macOS, ini bisa berupa/usr/local/bin. - Ganti
<job-prefix-name>dengan beberapa string untuk membantu mengidentifikasi pekerjaan yang dibuat secara unik di ruang kerja Anda untuk contoh ini. Misalnya, ini bisa menjadijenkins-demo. - Perhatikan bahwa
BUNDLETARGETdiatur kedev, yang merupakan nama target Bundel Automasi Deklaratif yang ditentukan nanti dalam artikel ini. Dalam implementasi dunia nyata, ubah ini menjadi nama target bundel Anda sendiri. Detail selengkapnya tentang target bundel disediakan nanti di artikel ini.
Berikut adalah Jenkinsfile, yang harus ditambahkan ke akar repositori Anda:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
Sisa artikel ini menjelaskan setiap tahap dalam Alur Jenkins ini dan cara menyiapkan artefak dan perintah agar Jenkins berjalan pada tahap tersebut.
Menarik artefak terbaru dari repositori pihak ketiga
Tahap pertama dalam Alur Jenkins ini, tahapnya Checkout , didefinisikan sebagai berikut:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
Tahap ini memastikan bahwa direktori kerja yang digunakan Jenkins pada mesin pengembangan lokal Anda memiliki artefak terbaru dari repositori Git pihak ketiga Anda. Biasanya, Jenkins mengatur direktori kerja ini ke <your-user-home-directory>/.jenkins/workspace/<pipeline-name>. Ini memungkinkan Anda untuk menyimpan salinan artefak Anda sendiri dalam pengembangan secara terpisah dari artefak yang digunakan oleh Jenkins dari repositori Git pihak ketiga Anda, semuanya pada komputer pengembangan lokal yang sama.
Memvalidasi Paket Aset Databricks
Tahap kedua dalam Jalur Jenkins ini, tahap Validate Bundle, didefinisikan sebagai berikut:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
Tahap ini memastikan bahwa paket, yang menentukan alur kerja untuk menguji dan menjalankan artefak Anda, secara sintaksis benar. Bundel Otomatisasi Deklaratif memungkinkan untuk mengekspresikan data lengkap, analitik, dan proyek ML sebagai kumpulan file sumber. Lihat Apa itu Bundel Otomatisasi Deklaratif?.
Untuk menentukan bundel untuk artikel ini, buat file bernama databricks.yml di akar repositori kloning pada komputer lokal Anda. Dalam file contoh databricks.yml ini, ganti placeholder berikut:
- Ganti
<bundle-name>dengan nama program unik untuk paketnya. Misalnya, ini bisa menjadijenkins-demo. - Ganti
<job-prefix-name>dengan beberapa string untuk membantu mengidentifikasi pekerjaan yang dibuat secara unik di ruang kerja Anda untuk contoh ini. Misalnya, ini bisa menjadijenkins-demo. NilaiJOBPREFIXharus cocok dengan yang ada di Jenkinsfile Anda. - Ganti
<spark-version-id>dengan ID versi Databricks Runtime untuk kluster pekerjaan Anda, misalnya13.3.x-scala2.12. - Ganti
<cluster-node-type-id>dengan ID jenis node untuk kluster pekerjaan Anda, misalnyaStandard_DS3_v2. - Perhatikan bahwa
devdalamtargetspemetaan sama denganBUNDLETARGETdi Jenkinsfile Anda. Target bundel menentukan host dan perilaku penyebaran terkait.
Berikut adalah databricks.yml file, yang harus ditambahkan ke akar repositori Anda agar contoh ini beroperasi dengan benar:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: '/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl'
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
Untuk informasi selengkapnya tentang file databricks.yml, lihat Konfigurasi Bundel Otomatisasi Deklaratif.
Menyebarkan bundel ke ruang kerja Anda
Tahap ketiga Jenkins Pipeline, berjudul Deploy Bundle, didefinisikan sebagai berikut:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
Tahap ini melakukan dua hal:
-
artifactKarena pemetaan dalamdatabricks.ymlfile diatur kewhl, ini menginstruksikan Databricks CLI untuk membangun file roda Python menggunakansetup.pyfile di lokasi yang ditentukan. - Setelah file roda Python dibangun di komputer pengembangan lokal Anda, Databricks CLI menyebarkan file roda Python bawaan bersama dengan file dan notebook Python yang ditentukan ke ruang kerja Azure Databricks Anda. Secara default, Bundel Automasi Deklaratif menyebarkan file roda Python dan file lainnya ke
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>.
Untuk mengaktifkan file roda Python yang akan dibuat seperti yang ditentukan dalam databricks.yml file, buat folder dan file berikut di akar repositori kloning Anda di komputer lokal Anda.
Untuk menentukan logika dan pengujian unit untuk file roda Python yang akan dijalankan notebook, buat dua file bernama addcol.py dan test_addcol.py, dan tambahkan ke struktur folder bernama python/dabdemo/dabdemo dalam folder repositori Libraries Anda:
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
File addcol.py berisi fungsi pustaka yang dibangun nanti ke dalam file roda Python lalu diinstal pada kluster Azure Databricks. Fungsi ini menambahkan kolom baru yang diisi dengan nilai literal ke dalam DataFrame Apache Spark.
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
File test_addcol.py berisi pengujian untuk meneruskan objek DataFrame tiruan ke with_status fungsi, yang ditentukan dalam addcol.py. Hasilnya kemudian dibandingkan dengan objek DataFrame yang berisi nilai yang diharapkan. Jika nilai cocok, yang dalam hal ini mereka lakukan, pengujian lolos:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Untuk mengaktifkan Databricks CLI untuk mengemas kode pustaka ini dengan benar ke dalam file roda Python, buat dua file bernama __init__.py dan __main__.py di folder yang sama dengan dua file sebelumnya. Selain itu, buat file bernama setup.py di python/dabdemo folder :
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
File __init__.py berisi nomor versi dan penulis pustaka. Ganti <my-author-name> dengan nama Anda:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
File __main__.py berisi titik masuk pustaka:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
File setup.py berisi pengaturan tambahan untuk membangun pustaka ke dalam file roda Python. Ganti <my-url>, <my-author-name>@<my-organization>, dan <my-package-description> dengan nilai yang bermakna:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Menguji logika komponen roda Python
Tahap Run Unit Tests ini, yang merupakan tahap keempat dalam Jenkins Pipeline, menggunakan pytest untuk menguji logika pustaka guna memastikan ini berfungsi sebagaimana dirancang. Tahap ini didefinisikan sebagai berikut:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
Tahap ini menggunakan Databricks CLI untuk menjalankan pekerjaan notebook. Pekerjaan ini menjalankan buku catatan Python dengan nama berkas run-unit-test.py. Buku catatan ini berjalan pytest terhadap logika pustaka.
Untuk menjalankan pengujian unit untuk contoh ini, tambahkan file buku catatan Python bernama run_unit_tests.py dengan konten berikut ke akar repositori kloning Anda di komputer lokal Anda:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Menggunakan roda Python bawaan
Tahap kelima dari Alur Jenkins ini, berjudul Run Notebook, menjalankan notebook Python yang memanggil logika dalam file roda Python bawaan, sebagai berikut:
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
Tahap ini menjalankan Databricks CLI, yang pada gilirannya menginstruksikan ruang kerja Anda untuk menjalankan pekerjaan notebook. Notebook ini membuat objek DataFrame, meneruskannya ke fungsi pustaka with_status , mencetak hasilnya, dan melaporkan hasil eksekusi pekerjaan. Buat buku catatan dengan menambahkan file buku catatan Python bernama dabdaddemo_notebook.py dengan konten berikut di akar repositori kloning Anda di komputer pengembangan lokal Anda:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Mengevaluasi hasil eksekusi pekerjaan buku catatan
Tahapan Evaluate Notebook Runs , tahap keenam dari Jenkins Pipeline ini, mengevaluasi hasil eksekusi pekerjaan notebook sebelumnya. Tahap ini didefinisikan sebagai berikut:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
Tahap ini menjalankan Databricks CLI, yang pada gilirannya menginstruksikan ruang kerja Anda untuk menjalankan pekerjaan file Python. File Python ini menentukan kriteria kegagalan dan keberhasilan untuk pekerjaan notebook yang dijalankan dan melaporkan kegagalan atau hasil keberhasilan ini. Buat file bernama evaluate_notebook_runs.py dengan konten berikut di akar repositori kloning Anda di komputer pengembangan lokal Anda:
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Impor dan laporkan hasil pengujian
Tahap ketujuh dalam Alur Jenkins ini, berjudul Import Test Results, menggunakan Databricks CLI untuk mengirim hasil pengujian dari ruang kerja Anda ke mesin pengembangan lokal Anda. Tahap kedelapan dan terakhir, berjudul Publish Test Results, menerbitkan hasil pengujian ke Jenkins dengan menggunakan junit plugin Jenkins. Ini memungkinkan Anda memvisualisasikan laporan dan dasbor yang terkait dengan status hasil pengujian. Tahapan ini didefinisikan sebagai berikut:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
Dorong semua perubahan kode ke repositori pihak ketiga Anda
Anda sekarang harus mengunggah konten dari repositori yang telah Anda kloning pada mesin pengembangan lokal Anda ke repositori pihak ketiga milik Anda. Sebelum mengunggah, Anda harus terlebih dahulu menambahkan entri berikut ke dalam file .gitignore di repositori kloning Anda, karena Anda sebaiknya tidak mengunggah file kerja internal bundel, laporan validasi, file pengembangan Python, dan cache Python ke repositori pihak ketiga Anda. Anda biasanya ingin menghasilkan ulang laporan validasi baru dan paket Python wheel terbaru di ruang kerja Azure Databricks Anda, alih-alih menggunakan laporan validasi dan paket Python wheel yang berpotensi kedaluwarsa.
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
Jalankan Alur Jenkins Anda
Anda sekarang siap untuk menjalankan Alur Jenkins Anda secara manual. Untuk melakukan ini, dari Dashboard Jenkins Anda:
- Klik nama Alur Jenkins Anda.
- Pada bilah samping, klik Bangun Sekarang.
- Untuk melihat hasilnya, klik Pipeline terakhir (misalnya,
#1) lalu klik Output Konsol.
Pada titik ini, alur CI/CD telah menyelesaikan siklus integrasi dan penyebaran. Dengan mengotomatiskan proses ini, Anda dapat memastikan bahwa kode Anda telah diuji dan disebarkan oleh proses yang efisien, konsisten, dan dapat diulang. Untuk menginstruksikan penyedia Git pihak ketiga Anda untuk menjalankan Jenkins setiap kali peristiwa tertentu terjadi, seperti permintaan pull repositori, lihat dokumentasi penyedia Git pihak ketiga Anda.