Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Databricks Connect untuk Databricks Runtime 12.2 LTS dan versi-versi sebelumnya tidak digunakan lagi. Databricks Runtime 12.2 LTS dan semua versi LTS sebelumnya telah mencapai akhir dukungan. Gunakan Databricks Connect untuk Databricks Runtime 13.3 LTS ke atas sebagai gantinya. Untuk informasi tentang migrasi dari Databricks Connect untuk Databricks Runtime 12.2 LTS ke bawah ke Databricks Connect untuk Databricks Runtime 13.3 LTS ke atas, lihat Migrasi ke Databricks Connect untuk Python atau Migrasi ke Databricks Connect untuk Scala.
Databricks Connect memungkinkan Anda menyambungkan IDE populer seperti Visual Studio Code dan PyCharm, server notebook, dan aplikasi kustom lainnya ke dalam kluster Azure Databricks.
Artikel ini menjelaskan cara kerja Databricks Connect, memandu Anda melalui langkah-langkah untuk memulai dengan Databricks Connect, menjelaskan cara memecahkan masalah yang mungkin timbul saat menggunakan Databricks Connect, dan perbedaan antara berjalan menggunakan Databricks Connect versus berjalan di buku catatan Azure Databricks.
Gambaran Umum
Databricks Connect adalah pustaka klien untuk Databricks Runtime. Ini memungkinkan Anda untuk menulis pekerjaan menggunakan Spark API dan menjalankannya dari jarak jauh pada kluster Azure Databricks, bukan di sesi Spark lokal.
Misalnya, saat Anda menjalankan perintah spark.read.format(...).load(...).groupBy(...).agg(...).show() DataFrame menggunakan Databricks Connect, representasi logis perintah dikirim ke server Spark yang berjalan di Azure Databricks untuk eksekusi pada kluster jarak jauh.
Dengan Databricks Connect, Anda dapat:
- Jalankan pekerjaan Spark skala besar dari aplikasi Python, R, Scala, atau Java apa pun. Di mana saja Anda dapat
import pyspark,require(SparkR)atauimport org.apache.spark, Anda sekarang dapat menjalankan pekerjaan Spark langsung dari aplikasi Anda, tanpa perlu menginstal plugin IDE apa pun atau menggunakan skrip pengiriman Spark. - Langkah demi langkah dan debug kode di IDE Anda bahkan saat bekerja dengan kluster yang berlokasi jauh.
- Iterasi dengan cepat ketika mengembangkan perpustakaan. Anda tidak perlu memulai ulang kluster setelah mengubah dependensi pustaka Python atau Java di Databricks Connect, karena setiap sesi klien diisolasi satu sama lain dalam kluster.
- Matikan kluster idle tanpa kehilangan pekerjaan. Karena aplikasi klien dipisahkan dari kluster, aplikasi ini tidak terpengaruh oleh restart atau peningkatan kluster, yang biasanya menyebabkan Anda kehilangan semua variabel, RDD, dan objek DataFrame yang ditentukan dalam buku catatan.
Catatan
Untuk pengembangan Python dengan kueri SQL, Databricks merekomendasikan agar Anda menggunakan Konektor SQL Databricks untuk Python alih-alih Databricks Connect. Konektor databricks SQL untuk Python lebih mudah diatur daripada Databricks Connect. Selain itu, Databricks Connect mengurai dan merencanakan pekerjaan yang dijalankan di mesin lokal Anda, sementara melakukan pekerjaan tersebut pada sumber daya komputasi jarak jauh. Hal ini dapat membuat sangat sulit untuk debug kesalahan runtime. Konektor SQL Databricks untuk Python mengirimkan kueri SQL langsung ke sumber daya komputasi jarak jauh dan mengambil hasil.
Persyaratan
Bagian ini mencantumkan persyaratan untuk Databricks Connect.
Hanya versi Databricks Runtime berikut yang didukung:
- Databricks Runtime 12.2 LTS ML, Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML, Databricks Runtime 11.3 LTS
- Databricks Runtime versi 10.4 LTS ML, Databricks Runtime versi 10.4 LTS
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Runtime Databricks 7.3 LTS
Anda harus menginstal Python 3 di komputer pengembangan Anda, dan versi minor penginstalan Python klien Anda harus sama dengan versi Python minor kluster Azure Databricks Anda. Tabel berikut ini memperlihatkan versi Python yang diinstal dengan setiap Databricks Runtime.
Versi Runtime Databricks Versi Python 12.2 LTS ML, 12.2 LTS 3.9 11.3 LTS ML, 11.3 LTS 3.9 10.4 LTS ML, 10.4 LTS 3.8 9.1 LTS ML, 9.1 LTS 3.8 7.3 LTS 3.7 Databricks sangat menyarankan agar Anda mengaktifkan lingkungan virtual Python untuk setiap versi Python yang Anda gunakan dengan Databricks Connect. Lingkungan virtual Python membantu memastikan bahwa Anda menggunakan versi Python dan Databricks Connect yang benar bersama-sama. Ini dapat membantu mengurangi waktu yang dihabiskan untuk menyelesaikan masalah teknis terkait.
Misalnya, jika Anda menggunakan venv di komputer pengembangan dan kluster Anda menjalankan Python 3.9, Anda harus membuat
venvlingkungan dengan versi tersebut. Contoh perintah berikut menghasilkan skrip untuk mengaktifkanvenvlingkungan dengan Python 3.9, dan perintah ini kemudian menempatkan skrip tersebut dalam folder tersembunyi bernama.venvdalam direktori kerja saat ini:# Linux and macOS python3.9 -m venv ./.venv # Windows python3.9 -m venv .\.venvUntuk menggunakan skrip tersebut untuk mengaktifkan lingkungan ini
venv, lihat Cara kerja venvs.Sebagai contoh lain, jika Anda menggunakan Conda di komputer pengembangan dan kluster Anda menjalankan Python 3.9, Anda harus membuat lingkungan Conda dengan versi tersebut, misalnya:
conda create --name dbconnect python=3.9Untuk mengaktifkan lingkungan Conda dengan nama lingkungan ini, jalankan
conda activate dbconnect.Versi paket utama dan minor dari Databricks Connect harus selalu sesuai dengan versi Databricks Runtime Anda. Databricks merekomendasikan agar Anda selalu menggunakan paket terbaru Databricks Connect yang cocok dengan versi Databricks Runtime Anda. Misalnya, ketika Anda menggunakan kluster Databricks Runtime 12.2 LTS, Anda juga harus menggunakan paket tersebut
databricks-connect==12.2.*.Catatan
Lihat catatan rilis Databricks Connect untuk daftar rilis Databricks Connect yang tersedia dan pembaruan pemeliharaan.
Java Runtime Environment (JRE) 8. Klien telah diuji dengan OpenJDK 8 JRE. Klien tidak mendukung Java 11.
Catatan
Di Windows, jika Anda melihat kesalahan bahwa Databricks Connect tidak dapat menemukan winutils.exe, lihat Tidak dapat menemukan winutils.exe di Windows.
Menyiapkan klien
Selesaikan langkah-langkah berikut untuk menyiapkan klien lokal untuk Databricks Connect.
Catatan
Sebelum Anda mulai menyiapkan klien Databricks Connect lokal, Anda harus memenuhi persyaratan untuk Databricks Connect.
Langkah 1: Instal klien Databricks Connect
Dengan lingkungan virtual Anda diaktifkan, menghapus instalasi PySpark, jika sudah diinstal, dengan menjalankan perintah
uninstall. Ini diperlukan karena paketdatabricks-connectbertentangan dengan PySpark. Untuk detailnya, lihat Penginstalan PySpark yang Saling Bertentangan. Untuk memeriksa apakah PySpark sudah diinstal, jalankanshowperintah .# Is PySpark already installed? pip3 show pyspark # Uninstall PySpark pip3 uninstall pysparkDengan lingkungan virtual Anda masih diaktifkan, instal klien Databricks Connect dengan menjalankan
installperintah .--upgradeGunakan opsi untuk meningkatkan penginstalan klien yang ada ke versi yang ditentukan.pip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.Catatan
Databricks merekomendasikan agar Anda menambahkan notasi "tanda bintang titik" untuk menentukan
databricks-connect==X.Y.*alih-alihdatabricks-connect=X.Y, untuk memastikan bahwa paket terbaru diinstal.
Langkah 2: Mengonfigurasikan properti koneksi
Kumpulkan properti konfigurasi berikut.
URL per-ruang kerja Azure Databricks. Ini juga sama seperti
https://diikuti oleh nilai Nama Host Server untuk kluster Anda; lihat Dapatkan detail koneksi untuk sumber daya komputasi Azure Databricks.Token akses pribadi Azure Databricks atau token ID Microsoft Entra (sebelumnya Azure Active Directory).
- Untuk pengalihan kredensial Azure Data Lake Storage (ADLS), Anda harus menggunakan token ID Microsoft Entra. Passthrough kredensial Microsoft Entra ID hanya didukung pada kluster Standar yang menjalankan Databricks Runtime 7.3 LTS ke atas, dan tidak kompatibel dengan autentikasi principal layanan.
- Untuk informasi selengkapnya tentang autentikasi dengan token ID Microsoft Entra, lihat Autentikasi menggunakan token ID Microsoft Entra.
ID komputasi klasik Anda. Anda dapat memperoleh ID komputasi klasik dari URL. Di sini ID adalah
1108-201635-xxxxxxxx. Lihat juga URL dan ID sumber daya komputasi.
ID organisasi unik untuk ruang kerja Anda. Lihat Dapatkan pengidentifikasi untuk objek ruang kerja.
Port yang digunakan oleh Databricks Connect untuk terhubung ke kluster Anda. Port default adalah
15001. Jika kluster Anda dikonfigurasi untuk menggunakan port yang berbeda, seperti8787yang diberikan dalam instruksi sebelumnya untuk Azure Databricks, gunakan nomor port yang dikonfigurasi.
Konfigurasikan koneksi sebagai berikut.
Anda dapat menggunakan CLI, konfigurasi SQL, atau variabel lingkungan. Prioritas metode konfigurasi dari tertinggi ke terendah adalah: SQL kunci konfigurasi, CLI, dan variabel lingkungan.
antarmuka baris perintah (CLI)
Jalankan
databricks-connect.databricks-connect configureLisensi menampilkan:
Copyright (2018) Databricks, Inc. This library (the "Software") may not be used except in connection with the Licensee's use of the Databricks Platform Services pursuant to an Agreement ...Terima lisensi dan nilai konfigurasi pasokan. Untuk Databricks Host dan Databricks Token, masukkan URL ruang kerja dan token akses pribadi yang Anda catat di Langkah 1.
Do you accept the above agreement? [y/N] y Set new config values (leave input empty to accept default): Databricks Host [no current value, must start with https://]: <databricks-url> Databricks Token [no current value]: <databricks-token> Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id> Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id> Port [15001]: <port>Jika Anda mendapatkan pesan bahwa token ID Microsoft Entra terlalu panjang, Anda dapat membiarkan Databricks Token kosong dan memasukkan token secara manual di
~/.databricks-connect.
Konfigurasi SQL atau variabel lingkungan. Tabel berikut menunjukkan SQL kunci konfigurasi dan variabel lingkungan yang sesuai dengan properti konfigurasi yang Anda catat di Langkah 1. Untuk mengatur kunci konfigurasi SQL, gunakan
sql("set config=value"). Misalnya:sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh").Pengaturan kunci konfigurasi SQL Nama variabel lingkungan Databricks Host spark.databricks.alamat.layanan DATABRICKS_ADDRESS Databricks Token spark.databricks.service.token DATABRICKS_API_TOKEN ID Kluster spark.databricks.service.clusterId DATABRICKS_CLUSTER_ID ID Organisasi spark.databricks.service.orgId DATABRICKS_ORG_ID Pelabuhan spark.databricks.service.port DATABRICKS_PORT
Dengan lingkungan virtual Anda masih diaktifkan, uji konektivitas ke Azure Databricks sebagai berikut.
databricks-connect testJika kluster yang Anda atur tidak sedang berjalan, pengujian akan memulai kluster tersebut, yang akan tetap berjalan hingga waktu autoterminasi yang telah ditetapkan. Output akan terlihat mirip dengan contoh berikut:
* PySpark is installed at /.../.../pyspark * Checking java version java version "1.8..." Java(TM) SE Runtime Environment (build 1.8...) Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode) * Testing scala command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state ../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2... /_/ Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala> spark.range(100).reduce(_ + _) Spark context Web UI available at https://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi res0: Long = 4950 scala> :quit * Testing python command ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set. ../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUiJika tidak ada kesalahan terkait koneksi yang ditampilkan (
WARNpesan tidak apa-apa), maka Anda telah berhasil tersambung.
Menggunakan Databricks Connect
Bagian ini menjelaskan cara mengonfigurasi IDE atau server buku catatan pilihan Anda untuk menggunakan klien untuk Databricks Connect.
Di bagian ini:
- JupyterLab
- Jupyter Notebook Klasik
- PyCharm
- SparkR dan RStudio Desktop
- sparklyr dan RStudio Desktop
- IntelliJ (Scala atau Java)
- PyDev dengan Eclipse
- Eclipse
- SBT
- Spark shell
JupyterLab
Catatan
Sebelum Anda mulai menggunakan Databricks Connect, Anda harus memenuhi persyaratan dan menyiapkan klien untuk Databricks Connect.
Untuk menggunakan Databricks Connect dengan JupyterLab dan Python, ikuti instruksi berikut.
Untuk menginstal JupyterLab, dengan lingkungan virtual Python Anda diaktifkan, jalankan perintah berikut dari terminal atau Prompt Perintah Anda:
pip3 install jupyterlabUntuk memulai JupyterLab di browser web Anda, jalankan perintah berikut dari lingkungan virtual Python yang diaktifkan:
jupyter labJika JupyterLab tidak muncul di browser web Anda, salin URL yang dimulai dengan
localhostatau127.0.0.1dari lingkungan virtual Anda, dan masukkan di bilah alamat browser web Anda.Buat buku catatan baru: di JupyterLab, klik File > Baru > Buku Catatan di menu utama, pilih Python 3 (ipykernel) dan klik Pilih.
Di sel pertama buku catatan, masukkan kode contoh atau kode Anda sendiri. Jika Anda menggunakan kode Anda sendiri, Anda minimal harus menginstansiasi sebuah instans dari
, seperti yang ditunjukkan dalam contoh kode . Untuk menjalankan buku catatan, klik Jalankan > Semua Sel.
Untuk men-debug buku catatan, klik ikon bug (Aktifkan Debugger) di samping Python 3 (ipykernel) di toolbar buku catatan. Atur satu atau beberapa titik henti, lalu klik Jalankan > Semua Sel.
Untuk mematikan JupyterLab, klik
File Shut Down . Jika proses JupyterLab masih berjalan di terminal atau Prompt Perintah Anda, hentikan proses ini dengan menekan Ctrl + clalu masukkanyuntuk mengonfirmasi.
Untuk instruksi debug yang lebih spesifik, lihat Debugger.
Jupyter Notebook Klasik
Catatan
Sebelum Anda mulai menggunakan Databricks Connect, Anda harus memenuhi persyaratan dan menyiapkan klien untuk Databricks Connect.
Skrip konfigurasi untuk Databricks Connect secara otomatis menambahkan paket ke konfigurasi proyek Anda. Untuk memulai di kernel Python, jalankan:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
Untuk mengaktifkan singkatan %sql untuk menjalankan dan memvisualisasikan kueri SQL, gunakan cuplikan berikut:
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
Visual Studio Code
Catatan
Sebelum Anda mulai menggunakan Databricks Connect, Anda harus memenuhi persyaratan dan menyiapkan klien untuk Databricks Connect.
Untuk menggunakan Databricks Connect dengan Visual Studio Code, lakukan hal berikut:
Verifikasi bahwa ekstensi Python dipasang.
Buka Palet Perintah (Command+Shift+P di macOS dan Ctrl+Shift+P di Windows/Linux).
Pilih interpreter Python. Buka Code > Preferensi > Pengaturan, dan pilih python settings.
Jalankan
databricks-connect get-jar-dir.Tambahkan direktori yang dikembalikan dari perintah ke Pengaturan Pengguna JSON di bawah
python.venvPath. Ini harus ditambahkan ke Konfigurasi Python.Nonaktifkan linter. Klik ... di sisi kanan dan sunting pengaturan JSON. Pengaturan yang dimodifikasi adalah sebagai berikut:
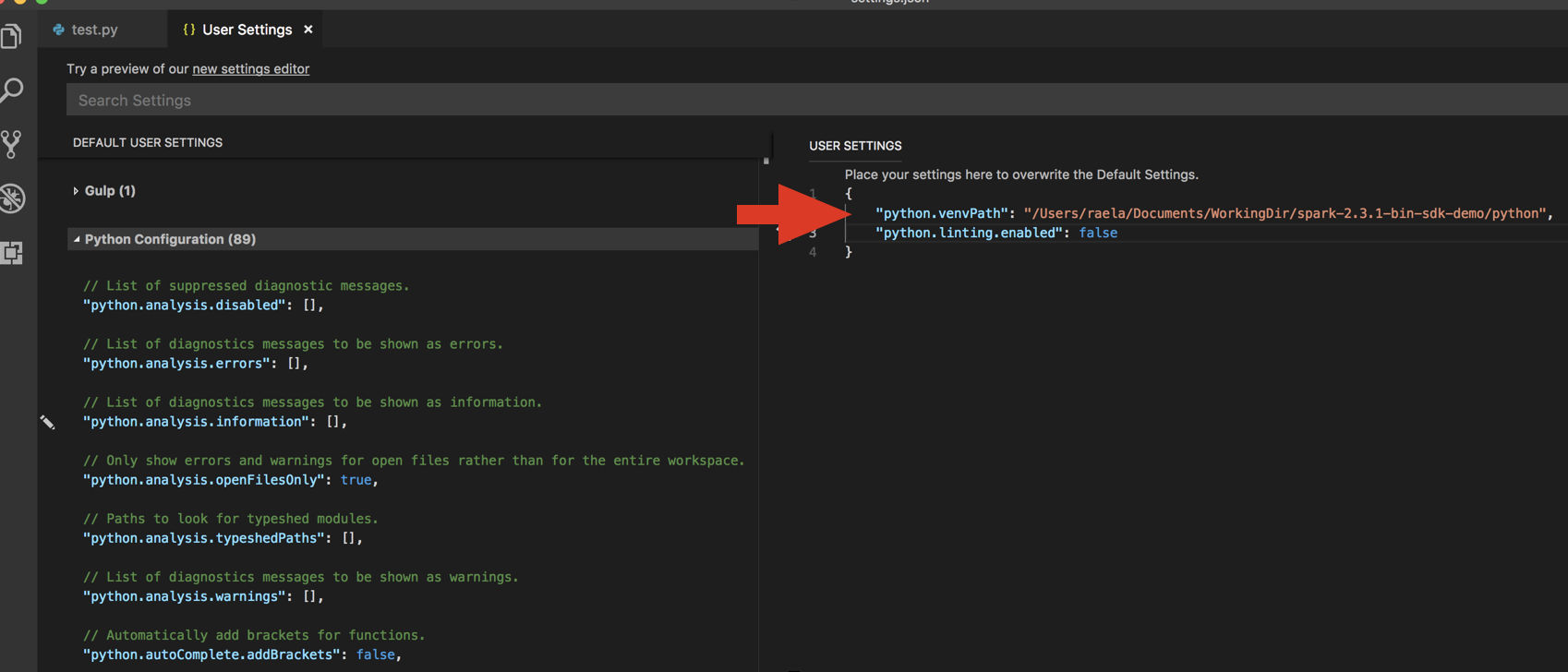
Jika berjalan dengan lingkungan virtual, yang merupakan cara yang disarankan untuk mengembangkan Python di VS Code, di Command Palette, ketik
select python interpreterdan arahkan ke lingkungan Anda yang cocok dengan versi Python kluster Anda.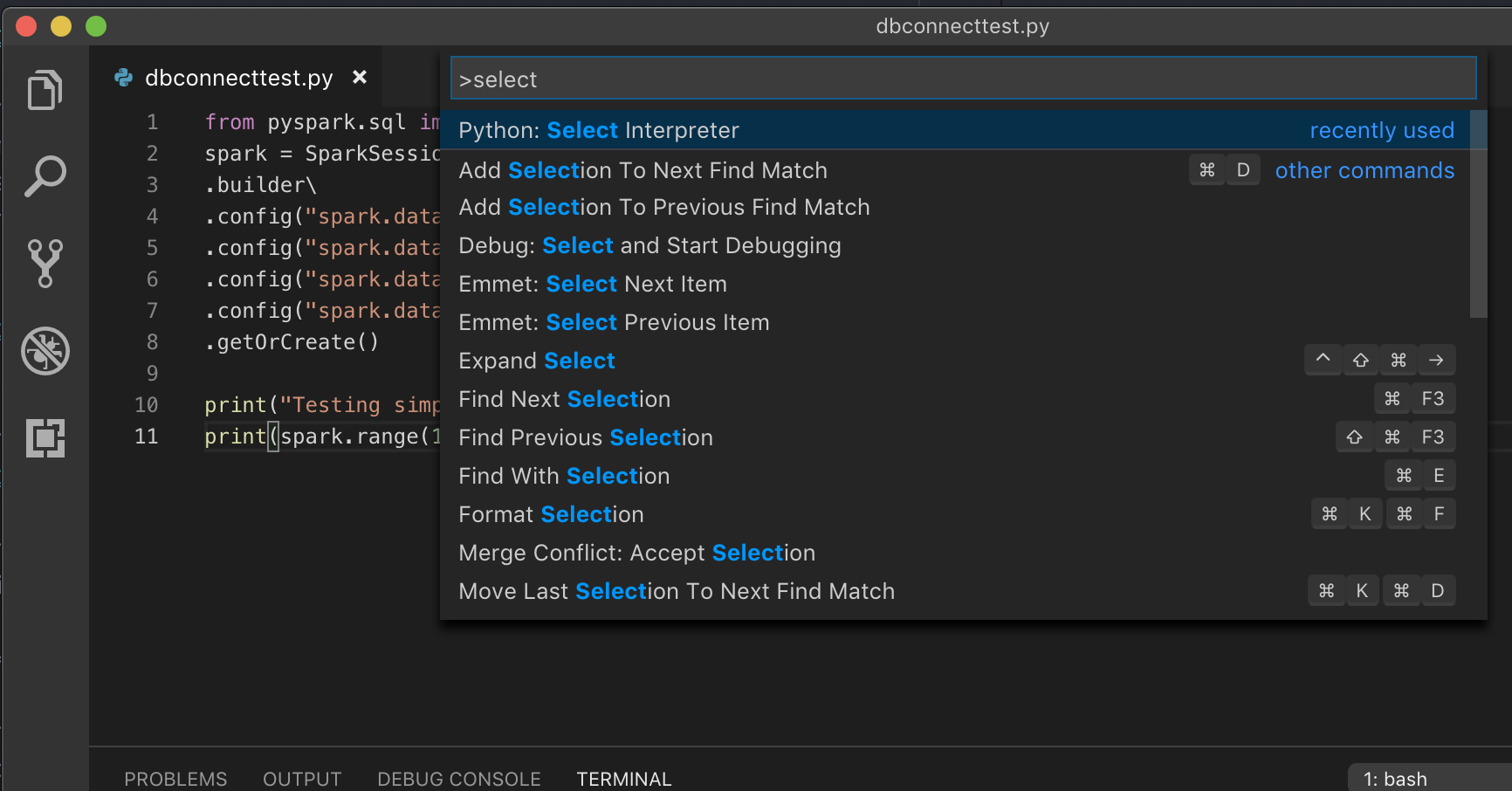
Misalnya, jika kluster Anda adalah Python 3.9, lingkungan pengembangan Anda harus Python 3.9.
PyCharm
Catatan
Sebelum Anda mulai menggunakan Databricks Connect, Anda harus memenuhi persyaratan dan menyiapkan klien untuk Databricks Connect.
Skrip konfigurasi untuk Databricks Connect secara otomatis menambahkan paket ke konfigurasi proyek Anda.
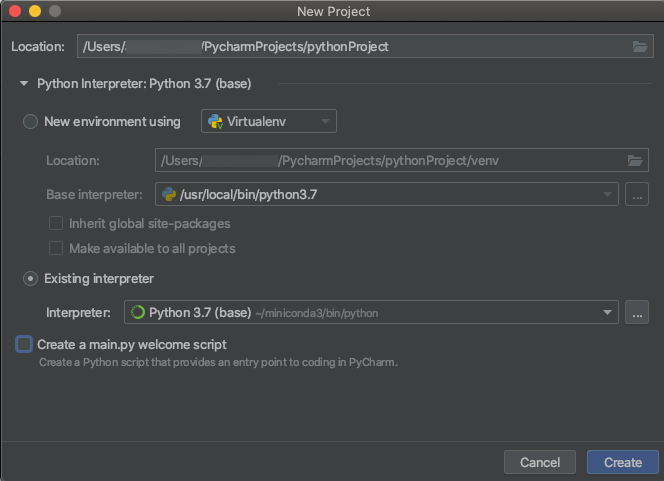
Kluster Python 3
Saat Anda membuat proyek PyCharm, pilih Penerjemah yang Ada. Dari menu tarik-turun, pilih lingkungan Conda yang Anda buat (lihat Persyaratan).
Buka Menjalankan > Konfigurasi Edit.
Tambahkan
PYSPARK_PYTHON=python3Sebagai variabel lingkungan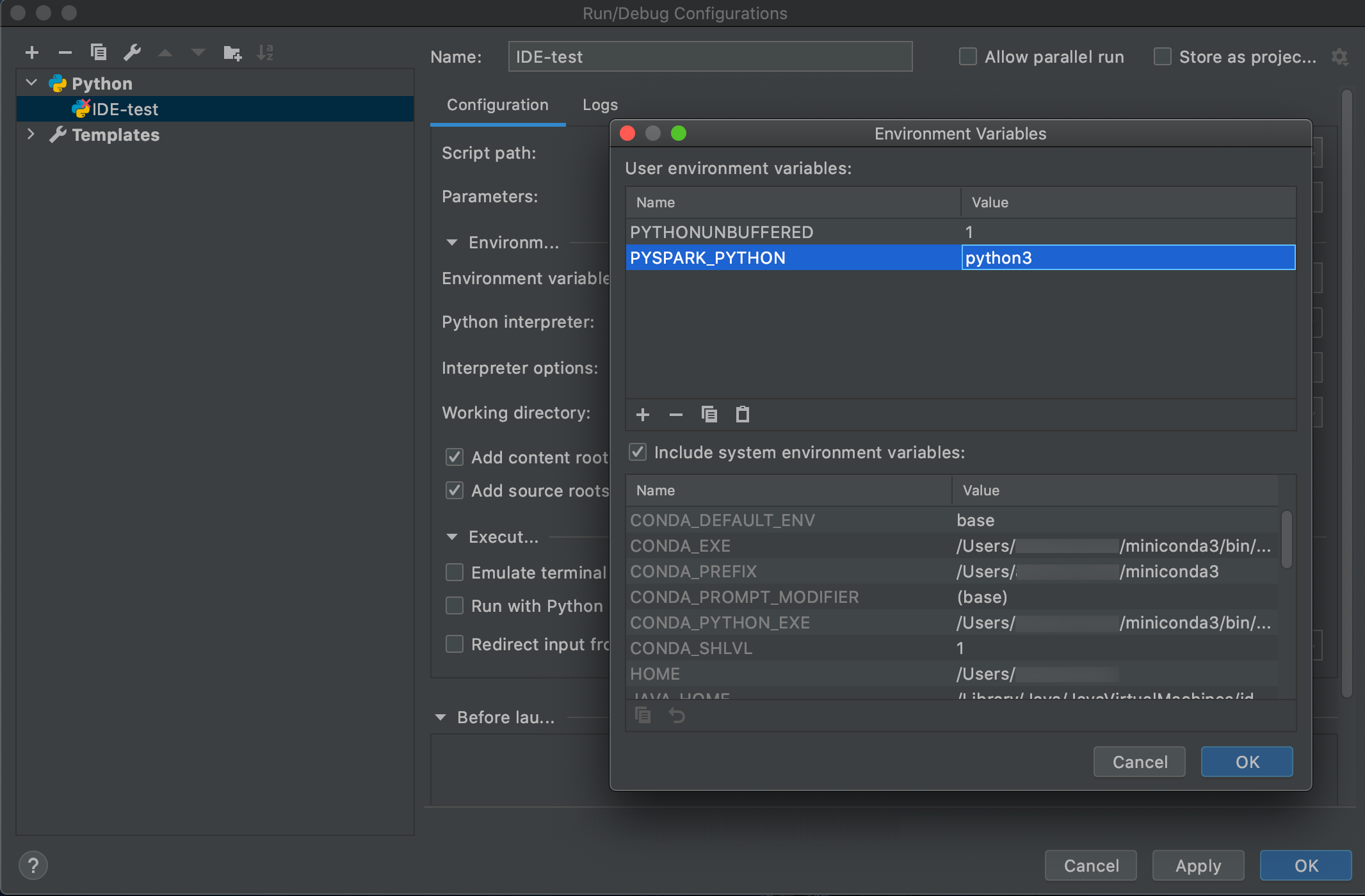
SparkR dan RStudio Desktop
Catatan
Sebelum Anda mulai menggunakan Databricks Connect, Anda harus memenuhi persyaratan dan menyiapkan klien untuk Databricks Connect.
Untuk menggunakan Databricks Connect dengan SparkR dan RStudio Desktop, lakukan hal berikut:
Unduh dan bongkar distribusi Spark sumber terbuka ke komputer pengembangan Anda. Pilih versi yang sama seperti di kluster Azure Databricks Anda (Hadoop 2.7).
Jalankan
databricks-connect get-jar-dir. Perintah ini mengembalikan jalur seperti/usr/local/lib/python3.5/dist-packages/pyspark/jars. Salin jalur file dari satu direktori di atas jalur file direktori JAR, misalnya,/usr/local/lib/python3.5/dist-packages/pyspark, yang merupakanSPARK_HOMEdirektori.Konfigurasikan jalur Spark lib dan Spark home dengan menambahkannya ke bagian atas skrip R Anda. Atur
<spark-lib-path>ke direktori tempat Anda membongkar paket Spark sumber terbuka di langkah 1. Atur<spark-home-path>ke direktori Koneksi Databricks dari langkah 2.# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7 library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths()))) # Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark Sys.setenv(SPARK_HOME = "<spark-home-path>")Memulai sesi Spark dan mulai menjalankan perintah SparkR.
sparkR.session() df <- as.DataFrame(faithful) head(df) df1 <- dapply(df, function(x) { x }, schema(df)) collect(df1)
sparklyr dan RStudio Desktop
Catatan
Sebelum Anda mulai menggunakan Databricks Connect, Anda harus memenuhi persyaratan dan menyiapkan klien untuk Databricks Connect.
Penting
Fitur ini ada di Pratinjau Publik.
Anda dapat menyalin kode dependen sparklyr yang telah Anda kembangkan secara lokal menggunakan Databricks Connect dan menjalankannya di buku catatan Azure Databricks atau Server RStudio yang dihosting di ruang kerja Azure Databricks Anda dengan perubahan kode minimal atau tanpa perubahan kode.
Di bagian ini:
- Persyaratan
- pasang, konfigurasikan, dan gunakan sparklyr
- Sumber
- keterbatasan Sparklyr dan RStudio Desktop
Persyaratan
- sparklyr 1.2 atau lebih tinggi.
- Databricks Runtime 7.3 LTS atau lebih tinggi dengan versi Databricks Connect yang cocok.
Pasang, konfigurasikan, dan gunakan sparklyr
Di RStudio Desktop, pasang sparklyr 1.2 atau lebih tinggi dari CRAN atau pasang versi master terbaru dari GitHub.
# Install from CRAN install.packages("sparklyr") # Or install the latest master version from GitHub install.packages("devtools") devtools::install_github("sparklyr/sparklyr")Aktifkan lingkungan Python dengan versi Databricks Connect yang benar yang diinstal dan jalankan perintah berikut di terminal untuk mendapatkan
<spark-home-path>:databricks-connect get-spark-homeMulai sesi Spark dan mulai jalankan perintah sparklyr.
library(sparklyr) sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) library(dplyr) src_tbls(sc) iris_tbl %>% countTutup koneksi.
spark_disconnect(sc)
Sumber
Untuk informasi selengkapnya, lihat dokumen README di GitHub.
Untuk contoh kode, lihat sparklyr.
keterbatasan Sparklyr dan RStudio Desktop
Fitur berikut tidak didukung:
- API sparklyr streaming
- api ML sparklyr
- broom API
- mode serialisasi csv_file
- spark submit
IntelliJ (Scala atau Java)
Catatan
Sebelum Anda mulai menggunakan Databricks Connect, Anda harus memenuhi persyaratan dan menyiapkan klien untuk Databricks Connect.
Untuk menggunakan Databricks Connect dengan IntelliJ (Scala atau Java), lakukan hal berikut:
Jalankan
databricks-connect get-jar-dir.Arahkan dependensi ke folder yang dihasilkan oleh perintah. Buka File > Struktur Proyek > Modul > Dependensi > tanda '+' > JAR atau Direktori.
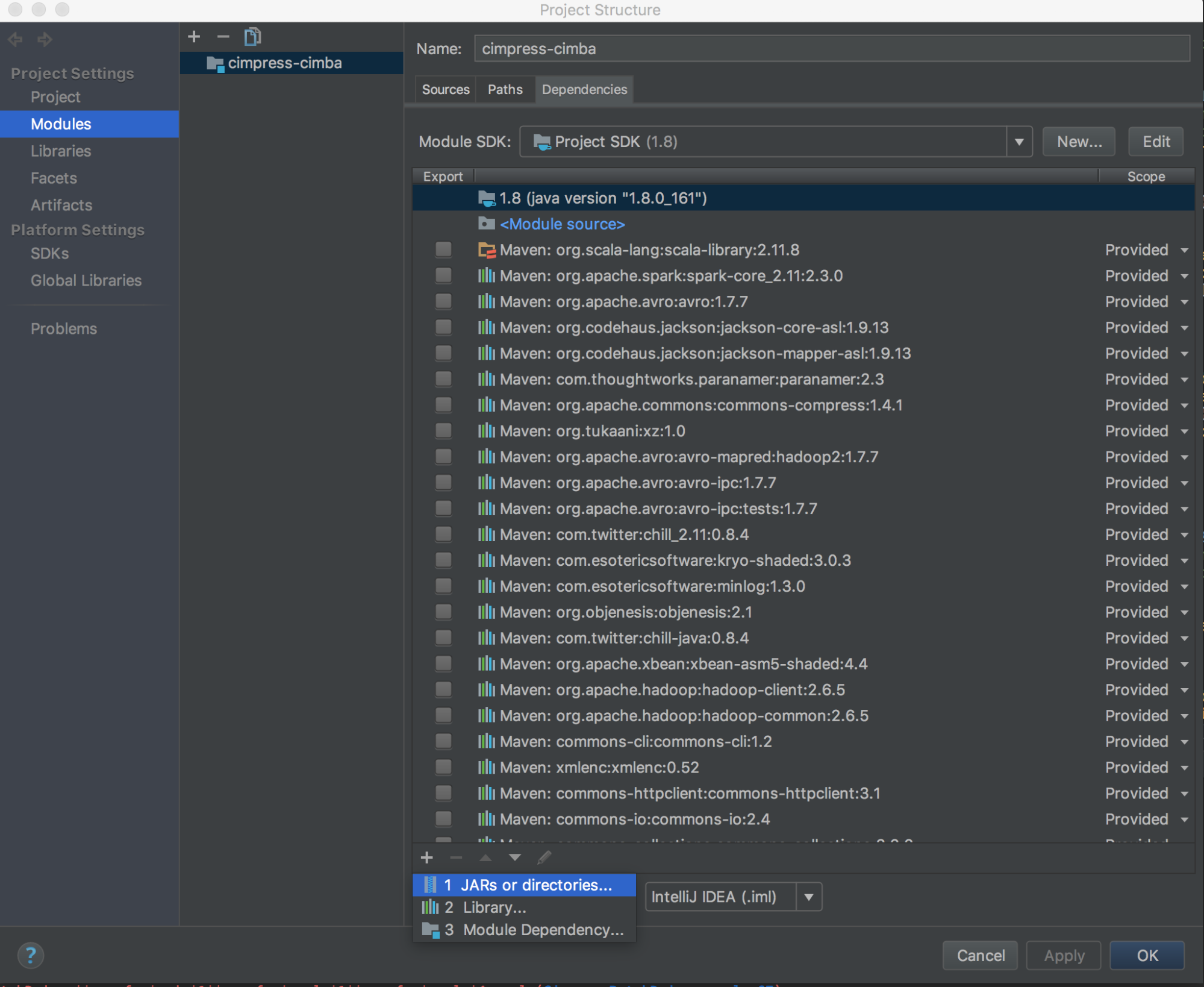
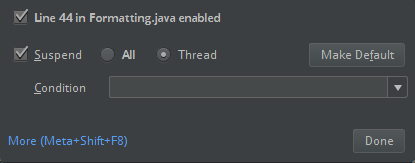
Untuk menghindari konflik, kami sangat menyarankan untuk menghapus penginstalan Spark lainnya dari classpath Anda. Jika ini tidak memungkinkan, pastikan bahwa JARs yang Anda tambahkan berada di depan classpath. Secara khusus, mereka harus lebih dari versi Spark lain yang sudah terpasang (jika tidak, Anda akan menggunakan salah satu versi Spark lainnya dan menjalankan secara lokal atau melempar pengecualian
ClassDefNotFoundError).Periksa pengaturan opsi breakout di IntelliJ. Defaultnya adalah Semua dan akan menyebabkan batas waktu jaringan jika Anda mengatur breakpoint untuk debugging. Atur ke Thread untuk menghindari menghentikan utas jaringan latar belakang.
PyDev dengan Eclipse
Catatan
Sebelum Anda mulai menggunakan Databricks Connect, Anda harus memenuhi persyaratan dan menyiapkan klien untuk Databricks Connect.
Untuk menggunakan Databricks Connect dan PyDev dengan Eclipse, ikuti instruksi berikut.
- Mulai Eclipse.
- Buat proyek: klik File > Proyek Baru > Proyek > PyDev > PyDev Project, lalu klik Berikutnya.
- Tentukan Nama proyek.
- Untuk Konten Proyek, tentukan path ke lingkungan virtual Python Anda.
- Klik Silakan konfigurasikan penerjemah sebelum melanjutkan.
- Klik Konfigurasi Manual.
- Klik Telusuri Baru > untuk python/pypy exe.
- Telusuri dan pilih jalur lengkap ke penerjemah Python yang dirujuk dari lingkungan virtual, lalu klik Buka.
- Dalam dialog Pilih penerjemah, klik OK.
- Dalam dialog Pilihan yang diperlukan, klik OK.
- Dalam dialog Preferensi, klik Terapkan dan Tutup.
- Dalam dialog PyDev Project, klik Selesai.
- Klik Buka Perspektif.
- Tambahkan ke proyek file kode Python (
.py) yang berisi kode contoh atau kode Anda sendiri. Jika Anda menggunakan kode Anda sendiri, Anda minimal harus menginstansiasi sebuah instans dari, seperti yang ditunjukkan dalam contoh kode . - Dengan file kode Python terbuka, atur titik henti apa pun di mana Anda ingin kode Anda dijeda saat berjalan.
- Klik Jalankan > Jalankan atau Jalankan > Debug.
Untuk instruksi eksekusi dan debug yang lebih spesifik, lihat Menjalankan Program.
Gerhana
Catatan
Sebelum Anda mulai menggunakan Databricks Connect, Anda harus memenuhi persyaratan dan menyiapkan klien untuk Databricks Connect.
Untuk menggunakan Databricks Connect dan Eclipse, lakukan hal berikut:
Jalankan
databricks-connect get-jar-dir.Arahkan konfigurasi JAR eksternal ke direktori yang dikembalikan dari perintah. Buka menu Proyek > Properti > Jalur Build Java > Pustaka > Tambahkan JAR Eksternal.
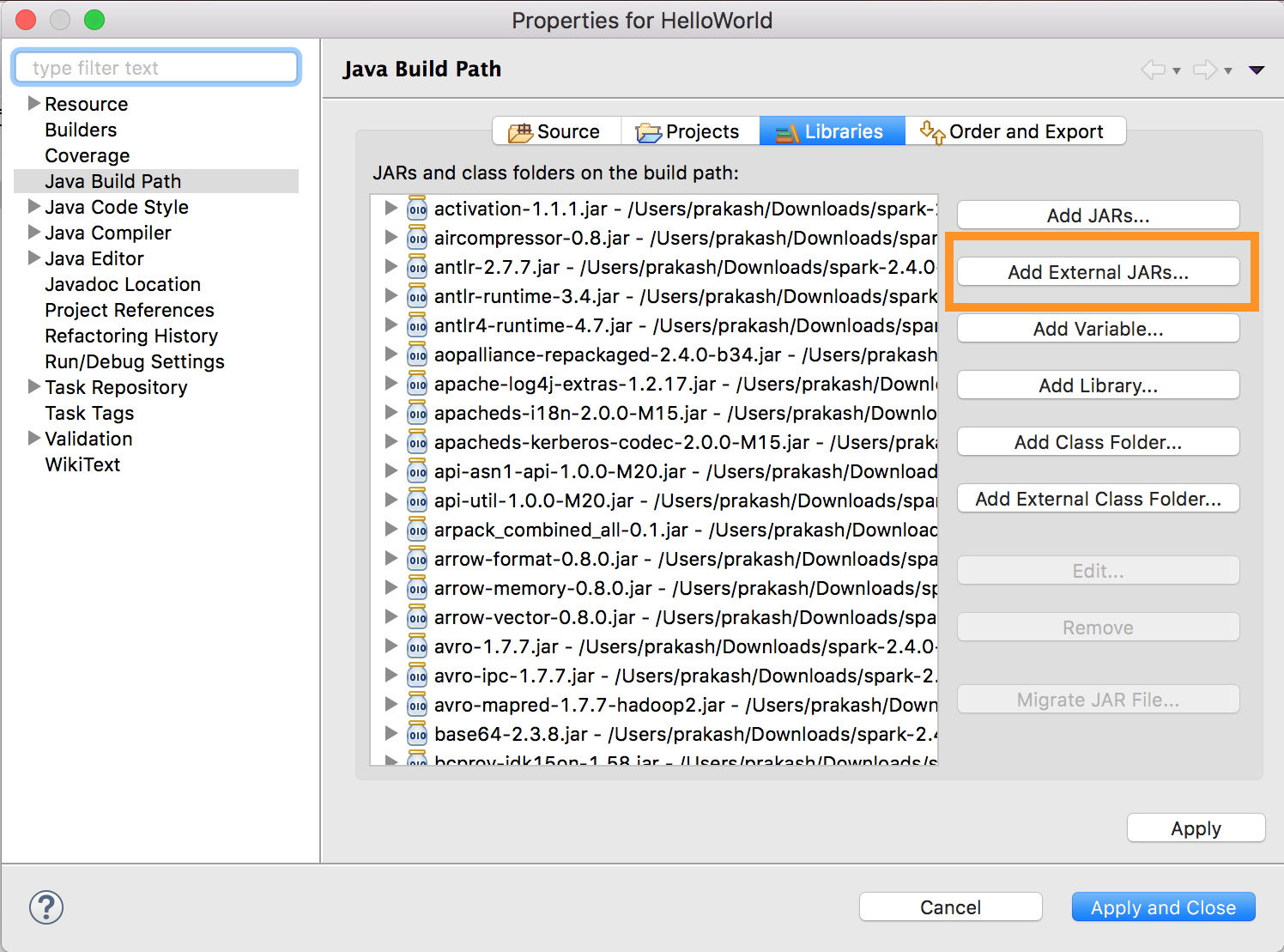
Untuk menghindari konflik, kami sangat menyarankan untuk menghapus penginstalan Spark lainnya dari classpath Anda. Jika ini tidak memungkinkan, pastikan bahwa JARs yang Anda tambahkan berada di depan classpath. Secara khusus, mereka harus lebih dari versi Spark lain yang sudah terpasang (jika tidak, Anda akan menggunakan salah satu versi Spark lainnya dan menjalankan secara lokal atau melempar pengecualian
ClassDefNotFoundError).
SBT
Catatan
Sebelum Anda mulai menggunakan Databricks Connect, Anda harus memenuhi persyaratan dan menyiapkan klien untuk Databricks Connect.
Untuk menggunakan Databricks Connect dengan SBT, Anda harus mengonfigurasi file Anda build.sbt untuk ditautkan terhadap JAR Databricks Connect alih-alih dependensi pustaka Spark biasa. Anda melakukan ini dengan direktif unmanagedBase dalam contoh file build berikut, yang mengasumsikan aplikasi Scala yang memiliki com.example.Test objek utama:
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Shell Spark
Catatan
Sebelum Anda mulai menggunakan Databricks Connect, Anda harus memenuhi persyaratan dan menyiapkan klien untuk Databricks Connect.
Untuk menggunakan Databricks Connect dengan shell Spark dan Python atau Scala, ikuti instruksi berikut.
Dengan mengaktifkan lingkungan virtual Anda, pastikan bahwa
databricks-connect testperintah berhasil berjalan di Menyiapkan klien.Setelah mengaktifkan lingkungan virtual Anda, mulai shell Spark. Untuk Python, jalankan
pysparkperintah . Untuk Scala, jalankanspark-shellperintah .# For Python: pyspark# For Scala: spark-shellShell Spark muncul, misalnya untuk Python:
Python 3... (v3...) [Clang 6... (clang-6...)] on darwin Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.... /_/ Using Python version 3... (v3...) Spark context Web UI available at http://...:... Spark context available as 'sc' (master = local[*], app id = local-...). SparkSession available as 'spark'. >>>Untuk Scala:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). ../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://... Spark context available as 'sc' (master = local[*], app id = local-...). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3... /_/ Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...) Type in expressions to have them evaluated. Type :help for more information. scala>Lihat Analisis Interaktif dengan Spark Shell untuk informasi tentang cara menggunakan shell Spark dengan Python atau Scala untuk menjalankan perintah pada kluster Anda.
Gunakan variabel bawaan
sparkuntuk mewakiliSparkSessionpada kluster yang sedang berjalan, misalnya untuk Python:>>> df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsUntuk Scala:
>>> val df = spark.read.table("samples.nyctaxi.trips") >>> df.show(5) +--------------------+---------------------+-------------+-----------+----------+-----------+ |tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip| +--------------------+---------------------+-------------+-----------+----------+-----------+ | 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171| | 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110| | 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023| | 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017| | 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282| +--------------------+---------------------+-------------+-----------+----------+-----------+ only showing top 5 rowsUntuk menghentikan shell Spark, tekan
Ctrl + datauCtrl + z, atau jalankan perintahquit()atauexit()untuk Python atau:qatau:quituntuk Scala.
Contoh kode
Contoh kode sederhana ini mengkueri tabel yang ditentukan lalu memperlihatkan 5 baris pertama tabel yang ditentukan. Untuk menggunakan tabel lain, sesuaikan panggilan ke spark.read.table.
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Contoh kode yang lebih panjang ini melakukan hal berikut:
- Membuat sebuah DataFrame dalam memori.
- Membuat tabel dengan nama
zzz_demo_temps_tabledalamdefaultskema. Jika tabel dengan nama ini sudah ada, tabel akan dihapus terlebih dahulu. Untuk menggunakan skema atau tabel yang berbeda, sesuaikan panggilan kespark.sql,temps.write.saveAsTable, atau keduanya. - Menyimpan konten DataFrame ke tabel.
-
SELECTMenjalankan kueri pada konten tabel. - Memperlihatkan hasil kueri.
- Menghapus tabel.
Phyton
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
Scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
Java
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
Bekerja dengan ketergantungan
Biasanya kelas utama atau file Python Anda akan memiliki JAR dan file dependensi lainnya. Anda dapat menambahkan JAR dan file dependensi tersebut dengan menelepon sparkContext.addJar("path-to-the-jar") atau sparkContext.addPyFile("path-to-the-file"). Anda juga dapat menambahkan file Egg dan file zip melalui antarmuka addPyFile(). Setiap kali Anda menjalankan kode di IDE Anda, JAR dan file dependensi dipasang pada kluster.
Phyton
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
Python + Java UDFs
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
Scala
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
Mengakses Utilitas Databricks
Bagian ini menjelaskan cara menggunakan Databricks Connect untuk mengakses Utilitas Databricks.
Anda dapat menggunakan dbutils.fs dan dbutils.secrets utilitas dari modul referensi Utilitas Databricks (dbutils).
Perintah yang didukung adalah dbutils.fs.cp, dbutils.fs.head, dbutils.fs.ls, dbutils.fs.mkdirs, dbutils.fs.mv, dbutils.fs.put, dbutils.fs.rm, dbutils.secrets.get, dbutils.secrets.getBytes, dbutils.secrets.list, dbutils.secrets.listScopes.
Lihat Utilitas sistem file (dbutils.fs) atau jalankan dbutils.fs.help() dan utilitas Rahasia (dbutils.secrets) atau jalankan dbutils.secrets.help().
Phyton
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
Saat menggunakan Databricks Runtime 7.3 LTS atau lebih tinggi, untuk mengakses modul DBUtils dengan cara yang berfungsi baik secara lokal maupun di kluster Azure Databricks, gunakan yang berikut get_dbutils():
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
Jika tidak, gunakan langkah berikut get_dbutils():
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
Scala
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
Menyalin file antara sistem file lokal dan jarak jauh
Anda dapat menggunakan dbutils.fs untuk menyalin file antara klien Anda dan sistem file jarak jauh. Skema file:/ mengacu pada sistem file lokal pada klien.
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
Ukuran file maksimum yang dapat ditransfer dengan cara itu adalah 250 MB.
Aktifkan dbutils.secrets.get
Karena pembatasan keamanan, kemampuan untuk menelepon dbutils.secrets.get dinonaktifkan secara default. Hubungi dukungan Azure Databricks untuk mengaktifkan fitur ini untuk ruang kerja Anda.
Atur konfigurasi Hadoop
Pada klien Anda dapat mengatur konfigurasi Hadoop menggunakan spark.conf.set API, yang berlaku untuk operasi SQL dan DataFrame. Konfigurasi Hadoop yang ditetapkan pada sparkContext harus diatur dalam konfigurasi kluster atau menggunakan notebook. Ini karena konfigurasi yang ditetapkan sparkContext tidak terkait dengan sesi pengguna tetapi berlaku untuk seluruh kluster.
Pemecahan Masalah
Jalankan databricks-connect test untuk memeriksa masalah konektivitas. Bagian ini menjelaskan beberapa masalah umum yang mungkin Anda temui dengan Databricks Connect dan cara mengatasinya.
Di bagian ini:
- Ketidakcocokan versi Python
- Server tidak diaktifkan
- Penginstalan PySpark yang berkonflik
-
Bertentangan
SPARK_HOME -
Entri yang bertentangan atau Hilang
PATHuntuk biner - Pengaturan serialisasi yang bertentangan pada kluster
-
Tidak dapat menemukan
winutils.exepada Windows - Sintaks nama file, nama direktori, atau label volume salah pada Windows
Ketidakcocokan versi Python
Periksa versi Python yang Anda gunakan secara lokal memiliki setidaknya rilis minor yang sama dengan versi pada kluster (misalnya, 3.9.16 versus 3.9.15 ok, 3.9 versus 3.8 tidak).
Jika Anda memiliki beberapa versi Python yang dipasang secara lokal, pastikan bahwa Databricks Connect menggunakan yang benar dengan mengatur PYSPARK_PYTHON variabel lingkungan (misalnya, PYSPARK_PYTHON=python3).
Server tidak diaktifkan
Pastikan kluster mengaktifkan server Spark dengan spark.databricks.service.server.enabled true. Anda akan melihat baris berikut di log driver jika itu:
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
Penginstalan PySpark yang bertentangan
databricks-connectPaket berkonflik dengan PySpark. Setelah keduanya dipasang akan menyebabkan kesalahan saat menginsialisasi konteks Spark di Python. Ini dapat muncul dalam beberapa cara, termasuk kesalahan "stream rusak" atau "kelas tidak ditemukan". Jika Anda memasang PySpark di lingkungan Python Anda, pastikan itu dihapus sebelum memasang databricks-connect. Setelah menghapus pemasangan PySpark, pastikan untuk memasang ulang paket Koneksi Databricks sepenuhnya:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
Bertentangan SPARK_HOME
Jika sebelumnya Anda telah menggunakan Spark di mesin Anda, IDE Anda mungkin dikonfigurasi untuk menggunakan salah satu versi Spark lainnya daripada Databricks Connect Spark. Ini dapat muncul dalam beberapa cara, termasuk kesalahan "stream rusak" atau "kelas tidak ditemukan". Anda dapat melihat versi Spark mana yang digunakan dengan memeriksa nilai SPARK_HOME variabel lingkungan:
Phyton
import os
print(os.environ['SPARK_HOME'])
Scala
println(sys.env.get("SPARK_HOME"))
Java
System.out.println(System.getenv("SPARK_HOME"));
Resolusi
Jika SPARK_HOME diatur ke versi Spark yang berbeda dari yang ada di klien, Anda harus melepas pengaturan variabel SPARK_HOME dan mencoba lagi.
Periksa pengaturan variabel lingkungan IDE Anda, .bashrc, .zshrc, atau file .bash_profile Anda, dan di tempat lain variabel lingkungan dapat diatur. Anda kemungkinan besar harus berhenti dan memulai ulang IDE Anda untuk membersihkan status lama, dan Anda bahkan mungkin perlu membuat proyek baru jika masalah berlanjut.
Anda seharusnya tidak perlu mengatur SPARK_HOME ke nilai baru; melepaskannya seharusnya sudah cukup.
Entri yang bentrok atau Hilang PATH untuk binari
Ada kemungkinan PATH Anda dikonfigurasi sehingga perintah seperti spark-shell akan menjalankan beberapa biner lain yang dipasang sebelumnya, bukan yang disediakan dengan Databricks Connect. Hal ini dapat menyebabkan databricks-connect test gagal. Anda harus memastikan bahwa biner Databricks Connect digunakan, atau menghapus biner yang telah diinstal sebelumnya.
Jika Anda tidak dapat menjalankan perintah seperti spark-shell, ada kemungkinan PATH Anda tidak disiapkan secara otomatis oleh pip3 install dan Anda harus menambahkan dir penginstalan bin ke PATH Anda secara manual. Dimungkinkan untuk menggunakan Databricks Connect dengan IDEs meskipun ini tidak disiapkan. Namun, perintah itu databricks-connect test tidak akan berhasil.
Pengaturan serialisasi yang berkonflik pada kluster
Jika Anda melihat kesalahan "stream corrupted" saat menjalankan databricks-connect test, ini mungkin karena konfigurasi serialisasi kluster yang tidak kompatibel. Misalnya, mengatur spark.io.compression.codec config dapat menyebabkan masalah ini. Untuk mengatasi masalah ini, pertimbangkan untuk menghapus konfigurasi ini dari pengaturan kluster, atau mengatur konfigurasi di klien Koneksi Databricks.
Tidak dapat menemukan winutils.exe pada Windows
Jika Anda menggunakan Databricks Connect di Windows dan lihat:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Ikuti petunjuk untuk mengonfigurasi jalur Hadoop di Windows.
Nama file, nama direktori, atau sintaks label volume salah pada Windows
Jika Anda menggunakan Windows dan Databricks Connect dan lihat:
The filename, directory name, or volume label syntax is incorrect.
Java atau Databricks Connect dipasang di direktori dengan spasi di path Anda. Anda dapat mengatasi hal ini dengan memasang ke jalur direktori tanpa spasi, atau mengonfigurasi jalur Anda menggunakan formulir nama pendek.
Autentikasi menggunakan token ID Microsoft Entra
Catatan
Informasi berikut berlaku untuk Databricks Connect versi 7.3.5 hingga 12.2.x saja.
Databricks Connect untuk Databricks Runtime 13.3 LTS ke atas saat ini tidak mendukung token ID Microsoft Entra.
Saat Anda menggunakan Databricks Connect versi 7.3.5 hingga 12.2.x, Anda dapat mengautentikasi dengan menggunakan token ID Microsoft Entra alih-alih token akses pribadi. Token ID Microsoft Entra memiliki masa pakai terbatas. Ketika token ID Microsoft Entra kedaluwarsa, Databricks Connect gagal dengan kesalahan Invalid Token .
Untuk Databricks Connect versi 7.3.5 hingga 12.2.x, Anda dapat memberikan token ID Microsoft Entra di aplikasi Databricks Connect yang sedang berjalan. Aplikasi Anda perlu mendapatkan token akses baru, dan mengaturnya ke spark.databricks.service.token kunci konfigurasi SQL.
Phyton
spark.conf.set("spark.databricks.service.token", new_aad_token)
Scala
spark.conf.set("spark.databricks.service.token", newAADToken)
Setelah Anda memperbarui token, aplikasi dapat terus menggunakan objek dan status yang sama SparkSession dan apa pun yang dibuat dalam konteks sesi. Untuk menghindari kesalahan intermiten, Databricks merekomendasikan agar Anda memberikan token baru sebelum token lama kedaluwarsa.
Anda dapat memperpanjang masa pakai token ID Microsoft Entra untuk bertahan selama eksekusi aplikasi Anda. Untuk melakukannya, lampirkan TokenLifetimePolicy dengan masa pakai yang tepat untuk aplikasi otorisasi ID Microsoft Entra yang Anda gunakan untuk memperoleh token akses.
Catatan
Microsoft Entra ID passthrough menggunakan dua token: token akses Microsoft Entra ID yang telah dijelaskan sebelumnya dan Anda konfigurasikan di Databricks Connect versi 7.3.5 hingga 12.2.x, dan token passthrough ADLS untuk sumber daya tertentu yang dihasilkan Databricks saat Databricks memproses permintaan. Anda tidak dapat memperpanjang masa pakai token passthrough ADLS dengan menggunakan kebijakan masa pakai token ID Microsoft Entra. Jika Anda mengirim perintah ke kluster yang memakan waktu lebih dari satu jam, perintah akan gagal jika perintah mengakses sumber daya ADLS setelah tanda satu jam.
Batasan
- Streaming Terstruktur
- Menjalankan kode arbitrer yang bukan bagian dari pekerjaan Spark di kluster jarak jauh.
- API asli Scala, Python, dan R untuk operasi tabel Delta (misalnya,
DeltaTable.forPath) tidak didukung. Namun, API SQL (spark.sql(...)) dengan operasi Delta Lake dan Spark API (misalnya,spark.read.load) pada tabel Delta keduanya didukung. - Salin ke dalam.
- Menggunakan fungsi SQL, UDF Python atau Scala yang merupakan bagian dari katalog server. Namun, Scala dan Python UDF yang diperkenalkan secara lokal berfungsi.
- Apache Zeppelin 0.7.x ke bawah.
- Menghubungkan ke kluster dengan kontrol akses tabel.
- Menghubungkan ke kluster dengan isolasi proses diaktifkan (yakni,
spark.databricks.pyspark.enableProcessIsolationdiatur ketrue). - Perintah Delta
CLONESQL. - Tampilan Sementara Global.
-
Koala dan
pyspark.pandas. - Perintah SQL
CREATE TABLE table AS SELECT ...tidak selalu berfungsi. Sebagai gantinya, gunakanspark.sql("SELECT ...").write.saveAsTable("table").
- Penyampaian langsung kredensial ID Microsoft Entra hanya didukung pada kluster standar yang menjalankan Databricks Runtime 7.3 LTS ke atas, dan tidak kompatibel dengan autentikasi principal layanan.
-
Referensi Utilitas Databricks (
dbutils) berikut: