Apa itu Databricks Koneksi?
Catatan
Artikel ini membahas Databricks Koneksi untuk Databricks Runtime 13.0 ke atas.
Untuk informasi tentang versi lama Databricks Koneksi, lihat Databricks Koneksi untuk Databricks Runtime 12.2 LTS dan di bawah ini.
- Untuk langsung melewati artikel ini dan mulai menggunakan Databricks Koneksi untuk Python, lihat Databricks Koneksi untuk Python.
- Untuk langsung melewati artikel ini dan mulai menggunakan Databricks Koneksi untuk R, lihat Databricks Koneksi untuk R.
- Untuk langsung melewati artikel ini dan mulai menggunakan Databricks Koneksi untuk Scala, lihat Databricks Koneksi untuk Scala.
Gambaran Umum
Databricks Koneksi memungkinkan Anda menghubungkan ID Populer seperti Visual Studio Code, PyCharm, RStudio Desktop, IntelliJ IDEA, server notebook, dan aplikasi kustom lainnya ke kluster Azure Databricks. Artikel ini menjelaskan cara kerja Databricks Koneksi.
Databricks Koneksi adalah pustaka klien untuk Databricks Runtime. Ini memungkinkan Anda menulis kode menggunakan API Spark dan menjalankannya dari jarak jauh pada kluster Azure Databricks alih-alih dalam sesi Spark lokal.
Misalnya, saat Anda menjalankan perintah spark.read.format(...).load(...).groupBy(...).agg(...).show() DataFrame menggunakan Databricks Koneksi, representasi logis perintah dikirim ke server Spark yang berjalan di Azure Databricks untuk eksekusi pada kluster jarak jauh.
Dengan Databricks Connect, Anda dapat:
Jalankan kode Spark skala besar dari aplikasi Python, R, atau Scala apa pun. Di mana saja Anda dapat
import pysparkuntuk Python,library(sparklyr)untuk R, atauimport org.apache.sparkuntuk Scala, Anda sekarang dapat menjalankan kode Spark langsung dari aplikasi Anda, tanpa perlu menginstal plugin IDE apa pun atau menggunakan skrip pengiriman Spark.Catatan
Databricks Koneksi untuk Databricks Runtime 13.0 ke atas mendukung menjalankan aplikasi Python. R dan Scala hanya didukung di Databricks Koneksi untuk Databricks Runtime 13.3 LTS ke atas.
Langkahi dan debug kode di IDE Anda bahkan saat bekerja dengan kluster jarak jauh.
Iterasi dengan cepat ketika mengembangkan perpustakaan. Anda tidak perlu menghidupkan ulang kluster setelah mengubah dependensi pustaka Python atau Scala di Databricks Koneksi, karena setiap sesi klien diisolasi satu sama lain dalam kluster.
Matikan kluster idle tanpa kehilangan pekerjaan. Karena aplikasi klien dipisahkan dari kluster, aplikasi ini tidak terpengaruh oleh restart atau peningkatan kluster, yang biasanya menyebabkan Anda kehilangan semua variabel, RDD, dan objek DataFrame yang ditentukan dalam buku catatan.
Untuk Databricks Runtime 13.3 LTS ke atas, Databricks Koneksi sekarang dibangun di atas Koneksi Spark sumber terbuka. Spark Koneksi memperkenalkan arsitektur server klien yang dipisahkan untuk Apache Spark yang memungkinkan konektivitas jarak jauh ke kluster Spark menggunakan API DataFrame dan rencana logis yang tidak terselesaikan sebagai protokol. Dengan arsitektur "V2" ini berdasarkan Spark Koneksi, Databricks Koneksi menjadi klien tipis yang sederhana dan mudah digunakan. Spark Koneksi dapat disematkan di mana saja untuk terhubung ke Azure Databricks: di IDEs, notebook, dan aplikasi, yang memungkinkan pengguna dan mitra individu sama-sama membangun pengalaman pengguna baru (interaktif) berdasarkan platform Databricks. Untuk informasi selengkapnya tentang Spark Koneksi, lihat Memperkenalkan Spark Koneksi.
Databricks Koneksi menentukan di mana kode Anda berjalan dan debug, seperti yang ditunjukkan pada gambar berikut.
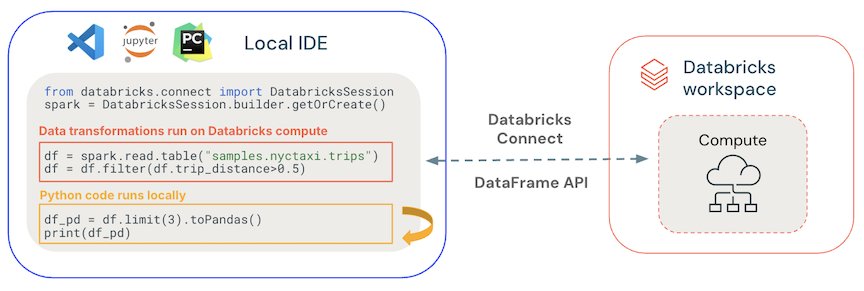
Untuk menjalankan kode: Semua kode berjalan secara lokal, sementara semua kode yang melibatkan operasi DataFrame berjalan pada kluster di ruang kerja Azure Databricks jarak jauh dan respons eksekusi dikirim kembali ke pemanggil lokal.
Untuk kode penelusuran kesalahan: Semua kode di-debug secara lokal, sementara semua kode Spark terus berjalan pada kluster di ruang kerja Azure Databricks jarak jauh. Kode mesin Spark inti tidak dapat di-debug langsung dari klien.
Langkah berikutnya
- Untuk mulai mengembangkan solusi Databricks Koneksi dengan Python, mulailah dengan tutorial Databricks Koneksi for Python.
- Untuk mulai mengembangkan solusi Databricks Koneksi dengan R, mulailah dengan tutorial Databricks Koneksi for R.
- Untuk mulai mengembangkan solusi Databricks Koneksi dengan Scala, mulailah dengan tutorial Databricks Koneksi for Scala.