Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Ekstensi Databricks untuk Visual Studio Code menyediakan fitur tambahan dalam Visual Studio Code yang memungkinkan Anda menentukan, menyebarkan, dan menjalankan Bundel Aset Databricks dengan mudah untuk menerapkan praktik terbaik CI/CD ke Pekerjaan Lakeflow, Alur Deklaratif Lakeflow Spark, dan Tumpukan MLOps Anda. Lihat Apa itu Bundel Aset Databricks?.
Untuk menginstal ekstensi Databricks untuk Visual Studio Code, lihat Menginstal ekstensi Databricks untuk Visual Studio Code.
Dukungan Bundel Aset Databricks dalam proyek
Ekstensi Databricks untuk Visual Studio Code menambahkan fitur berikut untuk proyek Bundel Aset Databricks Anda:
- Autentikasi dan konfigurasi mudah Bundel Aset Databricks Anda melalui UI Visual Studio Code, termasuk pemilihan profil AuthType. Lihat Mengatur otorisasi untuk ekstensi Databricks di Visual Studio Code.
- Pemilih Target di panel ekstensi Databricks untuk beralih dengan cepat antara lingkungan target bundle. Lihat Ubah ruang kerja target penyebaran.
- Opsi Ambil alih kluster Pekerjaan dalam bundel di panel ekstensi untuk mengaktifkan penimpaan kluster yang mudah.
- Tampilan Bundles Resource Explorer , yang memungkinkan Anda menelusuri sumber daya bundel menggunakan UI Visual Studio Code, menyebarkan sumber daya Bundel Aset Databricks lokal Anda ke ruang kerja Azure Databricks jarak jauh Anda dengan satu klik, dan langsung membuka sumber daya yang disebarkan di ruang kerja Anda dari Visual Studio Code. Lihat Bundle Resource Explorer.
- Tampilan Variabel Bundel, yang memungkinkan Anda menelusuri dan mengedit variabel bundel menggunakan UI Visual Studio Code. Lihat Tampilan Variabel Bundel.
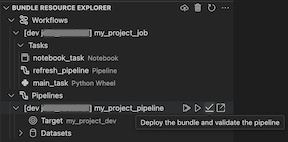
Bundel Resource Explorer
Tampilan Bundel Resource Explorer di ekstensi Databricks untuk Visual Studio Code menggunakan definisi sumber daya dalam konfigurasi bundel proyek untuk menampilkan sumber daya, termasuk himpunan data alur dan skemanya. Ini juga memungkinkan Anda untuk menyebarkan dan menjalankan sumber daya, memvalidasi dan melakukan pembaruan parsial pipeline, melihat peristiwa dan diagnostik eksekusi pipeline, serta menavigasi ke sumber daya di ruang kerja Azure Databricks jarak jauh Anda. Untuk informasi tentang sumber daya konfigurasi bundel, lihat sumber daya.
Misalnya, diberikan definisi pekerjaan sederhana:
resources:
jobs:
my-notebook-job:
name: 'My Notebook Job'
tasks:
- task_key: notebook-task
existing_cluster_id: 1234-567890-abcde123
notebook_task:
notebook_path: notebooks/my-notebook.py
Tampilan Bundel Resource Explorer dalam ekstensi menampilkan sumber daya tugas notebook:
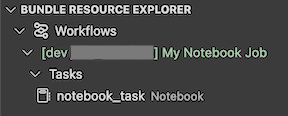
Menyebarkan dan menjalankan tugas
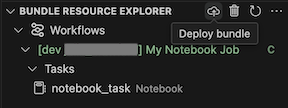
Untuk menyebarkan bundel, klik ikon cloud (Sebarkan bundel).
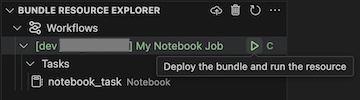
Untuk menjalankan pekerjaan, di tampilan Bundle Resource Explorer, pilih nama pekerjaan dengan nama My Notebook Job dalam contoh ini. Selanjutnya klik ikon putar (Sebarkan bundel dan jalankan sumber daya).
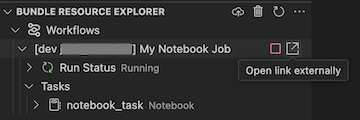
Untuk melihat pekerjaan yang sedang berjalan, dalam tampilan Bundel Resource Explorer , perluas nama pekerjaan, klik Jalankan Status, lalu klik ikon tautan (Buka tautan eksternal).
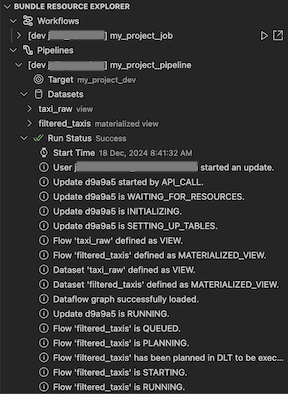
Memvalidasi dan mendiagnosis masalah alur
Untuk sebuah alur kerja, Anda dapat memicu validasi dan pembaruan parsial dengan memilih alur kerja tersebut, lalu pilih ikon centang (Sebarkan bundel dan validasi alur kerja). Peristiwa dalam proses ditampilkan, dan kegagalan apa pun yang terjadi dapat didiagnosis dalam panel MASALAH Visual Studio Code.
Tampilan Variabel Kumpulan
Tampilan Variabel Bundel di ekstensi Databricks untuk Visual Studio Code menampilkan variabel kustom dan pengaturan terkait yang ditentukan dalam konfigurasi bundel Anda. Anda juga dapat menentukan variabel secara langsung menggunakan Tampilan Variabel Bundel. Nilai-nilai ini menggantikan yang diatur dalam file konfigurasi bundel. Untuk informasi tentang variabel kustom, lihat Variabel kustom.
Misalnya, Bundle Variables View dalam ekstensi akan menampilkan hal berikut:

Untuk variabel my_custom_var yang ditentukan dalam konfigurasi bundel ini:
variables:
my_custom_var:
description: 'Max workers'
default: '4'
resources:
jobs:
my_job:
name: my_job
tasks:
- task_key: notebook_task
job_cluster_key: job_cluster
notebook_task:
notebook_path: ../src/notebook.ipynb
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
spark_version: 13.3.x-scala2.12
node_type_id: i3.xlarge
autoscale:
min_workers: 1
max_workers: ${var.my_custom_var}