Cara menjalankan evaluasi dan melihat hasilnya
Penting
Fitur ini ada di Pratinjau Publik.
Artikel ini menjelaskan cara menjalankan evaluasi dan melihat hasilnya menggunakan Evaluasi Agen AI Mosaik.
Untuk menjalankan evaluasi, Anda harus menentukan kumpulan evaluasi. Set evaluasi adalah sekumpulan permintaan umum yang akan dibuat pengguna ke aplikasi agenik Anda. Kumpulan evaluasi juga dapat menyertakan output yang diharapkan untuk setiap permintaan input. Tujuan dari set evaluasi adalah untuk membantu Anda mengukur dan memprediksi performa aplikasi agenik Anda dengan mengujinya pada pertanyaan yang representatif.
Untuk informasi selengkapnya tentang set evaluasi, termasuk skema yang diperlukan, lihat Kumpulan evaluasi.
Untuk memulai evaluasi, Anda menggunakan mlflow.evaluate() metode dari API MLflow. mlflow.evaluate() menghitung metrik kualitas, latensi, dan biaya untuk setiap input dalam set evaluasi dan juga menghitung metrik agregat di semua input. Metrik ini juga disebut sebagai hasil evaluasi. Kode berikut menunjukkan contoh panggilan mlflow.evaluate():
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
import pandas as pd
eval_df = pd.DataFrame(...)
# Puts the evaluation results in the current Run, alongside the logged model parameters
with mlflow.start_run():
logged_model_info = mlflow.langchain.log_model(...)
mlflow.evaluate(data=eval_df, model=logged_model_info.model_uri,
model_type="databricks-agent")
Dalam contoh ini, mlflow.evaluate() mencatat hasil evaluasinya dalam eksekusi MLflow yang mencakup, bersama dengan informasi yang dicatat oleh perintah lain (misalnya, parameter model). Jika Anda memanggil mlflow.evaluate() di luar eksekusi MLflow, MLflow memulai eksekusi baru dan evaluasi log menghasilkan eksekusi tersebut. Untuk informasi selengkapnya tentang mlflow.evaluate(), termasuk detail tentang hasil evaluasi yang dicatat dalam proses, lihat dokumentasi MLflow.
Persyaratan
Fitur bantuan Azure AI Services AI harus diaktifkan untuk ruang kerja Anda.
Cara memberikan input ke eksekusi evaluasi
Ada dua cara untuk memberikan input ke eksekusi evaluasi:
- Teruskan aplikasi sebagai argumen input.
mlflow.evaluate()panggilan ke dalam aplikasi untuk setiap input dalam set evaluasi dan menghitung metrik pada output yang dihasilkan. Opsi ini disarankan jika aplikasi Anda dicatat menggunakan MLflow dengan MLflow Tracing diaktifkan, atau jika aplikasi Anda diimplementasikan sebagai fungsi Python di notebook. - Berikan output yang dihasilkan sebelumnya untuk dibandingkan dengan kumpulan evaluasi. Opsi ini direkomendasikan jika aplikasi Anda dikembangkan di luar Databricks, jika Anda ingin mengevaluasi output dari aplikasi yang sudah disebarkan ke produksi, atau jika Anda ingin membandingkan hasil evaluasi antara konfigurasi evaluasi.
Sampel kode berikut menunjukkan contoh minimal untuk setiap metode. Untuk detail tentang skema set evaluasi, lihat Skema kumpulan evaluasi.
mlflow.evaluate()Agar panggilan menghasilkan output, tentukan kumpulan evaluasi dan aplikasi dalam panggilan fungsi seperti yang ditunjukkan dalam kode berikut. Untuk contoh yang lebih rinci, lihat Contoh: Evaluasi Agen menjalankan aplikasi.evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas Dataframe containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )Untuk memberikan output yang dihasilkan sebelumnya, tentukan hanya kumpulan evaluasi seperti yang ditunjukkan dalam kode berikut, tetapi pastikan bahwa itu termasuk output yang dihasilkan. Untuk contoh yang lebih rinci, lihat Contoh: Output yang dihasilkan sebelumnya disediakan.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas Dataframe with the evaluation set and application outputs model_type="databricks-agent", )
Output evaluasi
Evaluasi menghasilkan dua jenis output:
- Data tentang setiap permintaan dalam kumpulan evaluasi, termasuk yang berikut ini:
- Input yang dikirim ke aplikasi agenik.
- Output
responseaplikasi . - Semua data perantara yang dihasilkan oleh aplikasi, seperti ,
trace, dan sebagainyaretrieved_context. - Peringkat dan rasional dari setiap hakim LLM yang ditentukan Databricks dan ditentukan pelanggan. Peringkat mencirikan aspek kualitas yang berbeda dari output aplikasi, termasuk kebenaran, groundedness, presisi pengambilan, dan sebagainya.
- Metrik lain berdasarkan jejak aplikasi, termasuk latensi dan jumlah token untuk langkah-langkah yang berbeda.
- Nilai metrik agregat di seluruh kumpulan evaluasi, seperti jumlah token rata-rata dan total, latensi rata-rata, dan sebagainya.
Kedua jenis output ini dikembalikan dari mlflow.evaluate() dan juga dicatat dalam eksekusi MLflow. Anda dapat memeriksa output di notebook atau dari halaman eksekusi MLflow yang sesuai.
Meninjau output di buku catatan
Kode berikut ini memperlihatkan beberapa contoh cara meninjau hasil evaluasi yang dijalankan dari buku catatan Anda.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated metric values across the entire evaluation set
###
metrics_as_dict = evaluation_results.metrics
metrics_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {metrics_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
Kerangka per_question_results_df data mencakup semua kolom dalam skema input dan semua metrik komputasi khusus untuk setiap permintaan. Untuk detail selengkapnya tentang setiap metrik yang dilaporkan, lihat Menggunakan metrik agen & hakim LLM untuk mengevaluasi performa aplikasi.
Meninjau output menggunakan UI MLflow
Hasil evaluasi juga tersedia di UI MLflow. Untuk mengakses UI MLflow, klik ikon ![]() Eksperimen di bilah sisi kanan buku catatan lalu pada eksekusi yang sesuai, atau klik tautan yang muncul di hasil sel untuk sel buku catatan tempat Anda menjalankan
Eksperimen di bilah sisi kanan buku catatan lalu pada eksekusi yang sesuai, atau klik tautan yang muncul di hasil sel untuk sel buku catatan tempat Anda menjalankan mlflow.evaluate().
Meninjau metrik untuk satu eksekusi
Bagian ini menjelaskan metrik yang tersedia untuk setiap eksekusi evaluasi. Untuk membandingkan metrik di seluruh eksekusi, lihat Membandingkan metrik di seluruh eksekusi.
Metrik per permintaan
Metrik per permintaan tersedia dalam databricks-agents versi 0.3.0 ke atas.
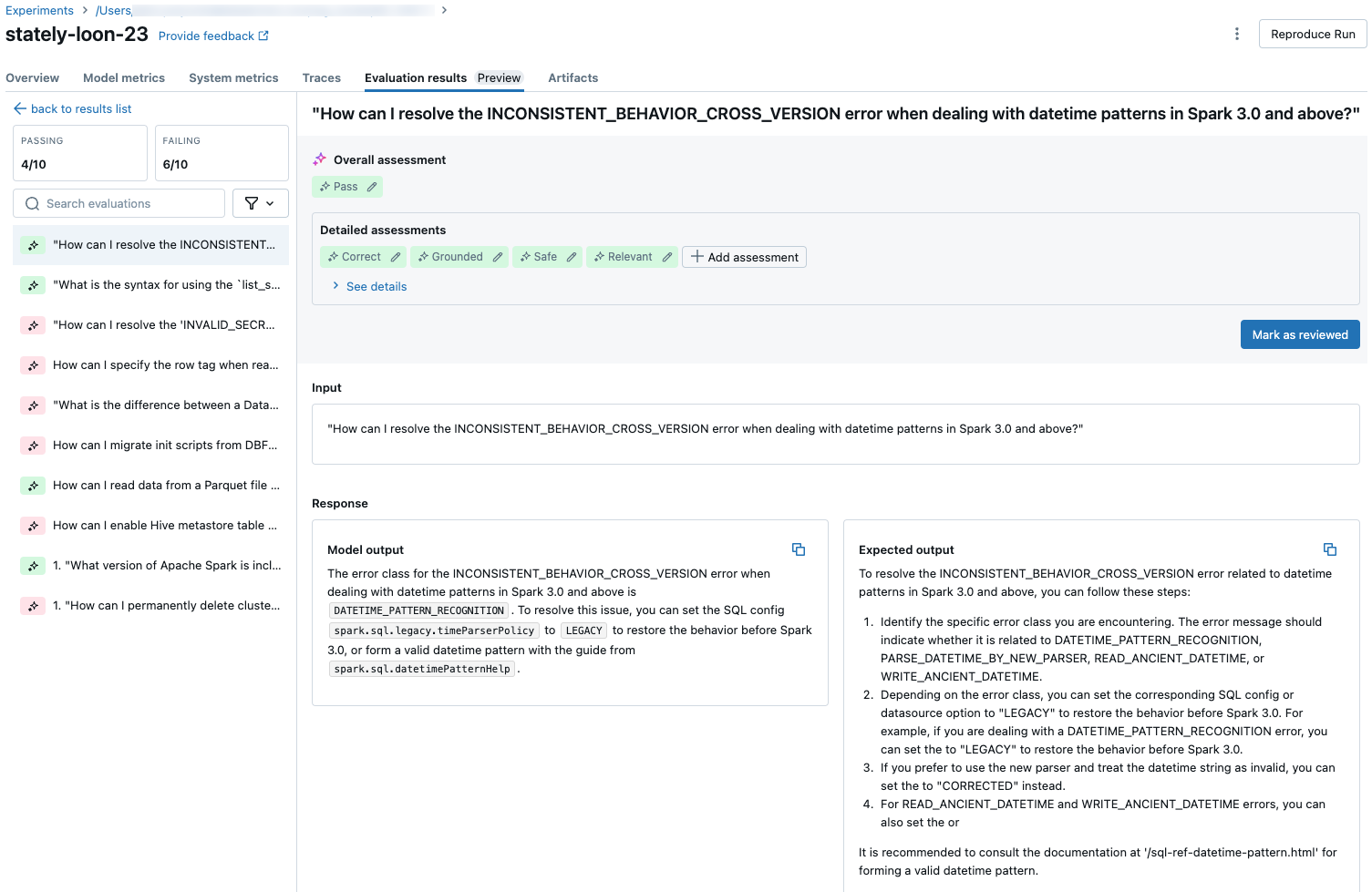
Untuk melihat metrik terperinci untuk setiap permintaan dalam kumpulan evaluasi, klik tab Hasil evaluasi pada halaman Eksekusi MLflow. Halaman ini memperlihatkan tabel ringkasan dari setiap eksekusi evaluasi. Untuk detail selengkapnya, klik ID Evaluasi eksekusi.
Halaman detail untuk eksekusi evaluasi memperlihatkan hal berikut:
- Output model: Respons yang dihasilkan dari aplikasi agenik dan jejaknya jika disertakan.
- Output yang diharapkan: Respons yang diharapkan untuk setiap permintaan.
- Penilaian terperinci: Penilaian juri LLM pada data ini. Klik Lihat detail untuk menampilkan pembenaran yang disediakan oleh juri.
Metrik agregat di seluruh set evaluasi penuh
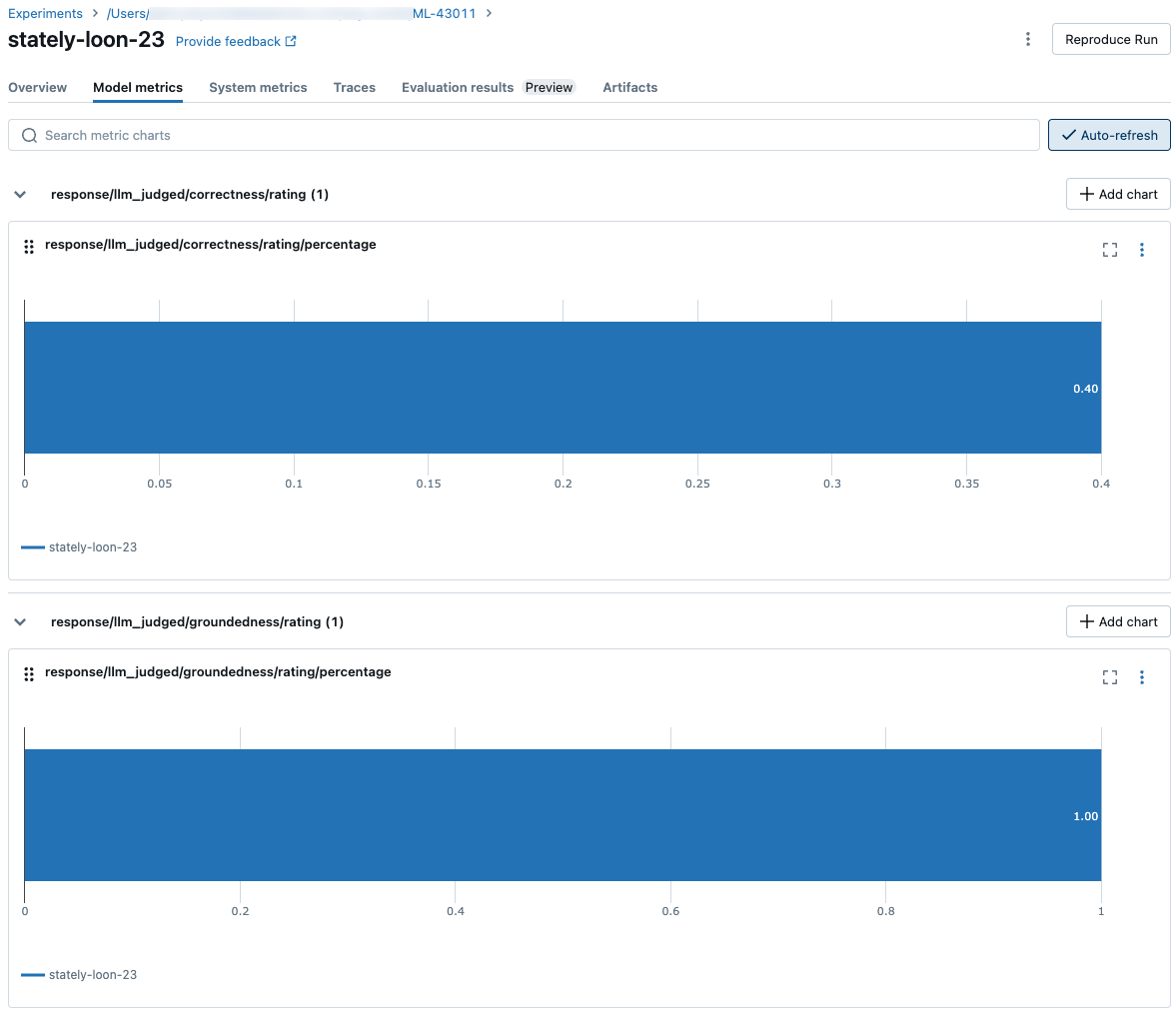
Untuk melihat nilai metrik agregat di seluruh kumpulan evaluasi lengkap, klik tab Gambaran Umum (untuk nilai numerik) atau tab Metrik model (untuk bagan).

Membandingkan metrik di seluruh eksekusi
Penting untuk membandingkan hasil evaluasi di seluruh eksekusi untuk melihat bagaimana aplikasi agenik Anda merespons perubahan. Membandingkan hasil dapat membantu Anda memahami apakah perubahan Anda berdampak positif pada kualitas atau membantu Anda memecahkan masalah perubahan perilaku.
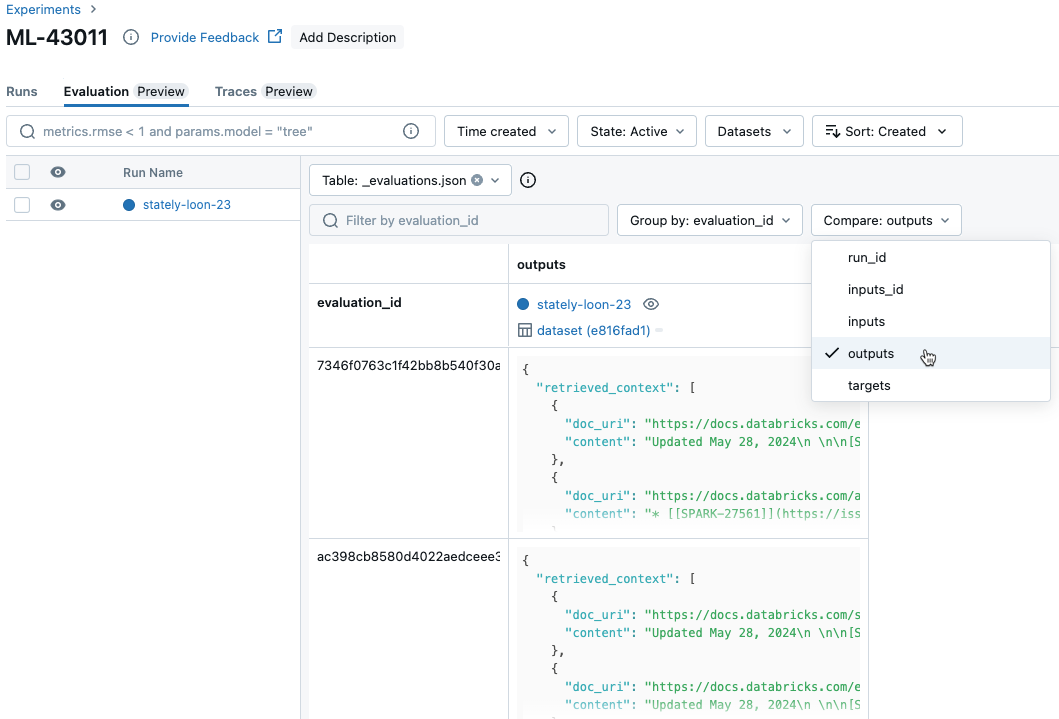
Membandingkan metrik per permintaan di seluruh eksekusi
Untuk membandingkan data untuk setiap permintaan individual di seluruh eksekusi, klik tab Evaluasi di halaman Eksperimen. Tabel memperlihatkan setiap pertanyaan dalam kumpulan evaluasi. Gunakan menu drop-down untuk memilih kolom yang akan ditampilkan.
Membandingkan metrik agregat di seluruh eksekusi
Anda dapat mengakses metrik agregat yang sama dari halaman Eksperimen, yang juga memungkinkan Anda membandingkan metrik ini di berbagai eksekusi. Untuk mengakses halaman Eksperimen, klik ikon ![]() Eksperimen di bilah sisi kanan buku catatan, atau klik tautan yang muncul di hasil sel untuk sel buku catatan tempat Anda menjalankan
Eksperimen di bilah sisi kanan buku catatan, atau klik tautan yang muncul di hasil sel untuk sel buku catatan tempat Anda menjalankan mlflow.evaluate().
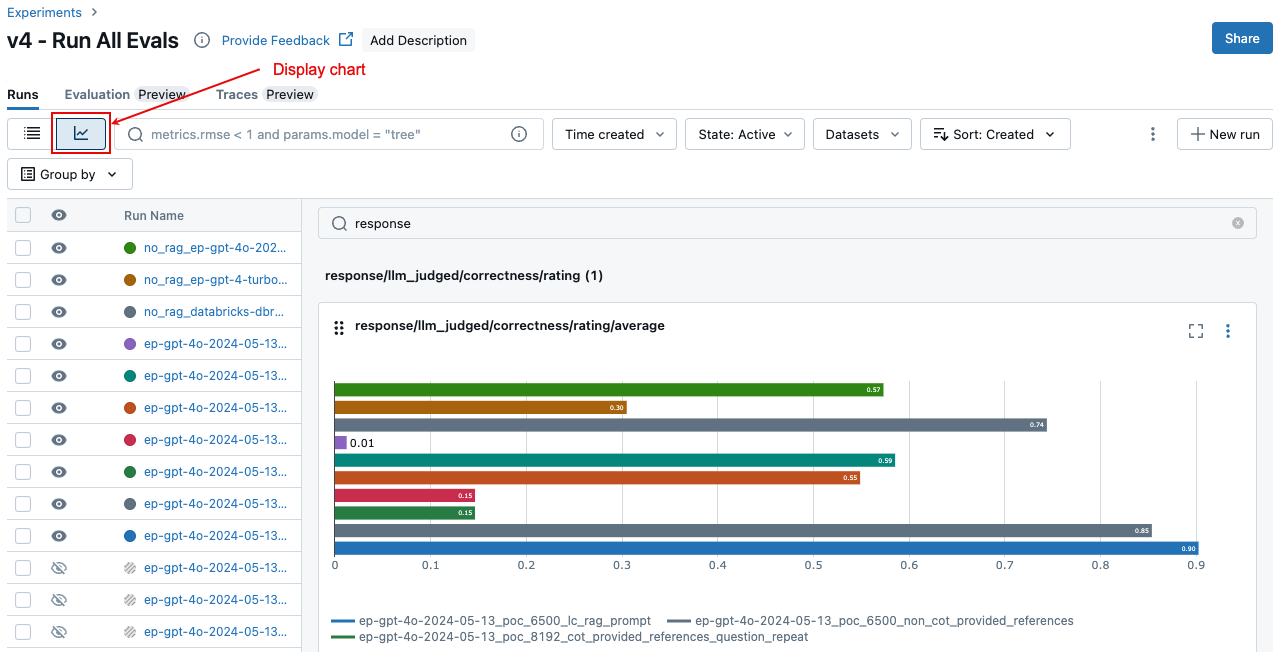
Pada halaman Eksperimen, klik ![]() . Ini memungkinkan Anda memvisualisasikan metrik agregat untuk eksekusi yang dipilih dan membandingkan dengan eksekusi sebelumnya.
. Ini memungkinkan Anda memvisualisasikan metrik agregat untuk eksekusi yang dipilih dan membandingkan dengan eksekusi sebelumnya.
mlflow.evaluate() Contoh panggilan
Bagian ini mencakup sampel mlflow.evaluate() kode panggilan, mengilustrasikan opsi untuk meneruskan aplikasi dan evaluasi yang diatur ke panggilan.
Contoh: Aplikasi eksekusi Evaluasi Agen
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# mlflow.evaluate() call
###
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model=model, # Reference to the application
model_type="databricks-agent",
)
###
# There are 4 options for passing an application in the `model` argument.
####
#### Option 1. Reference to a Unity Catalog registered model
model = "models:/catalog.schema.model_name/1" # 1 is the version number
#### Option 2. Reference to a MLflow logged model in the current MLflow Experiment
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
# `6b69501828264f9s9a64eff825371711` is the run_id, `chain` is the artifact_path that was
# passed when calling mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
#### Option 3. A PyFunc model that is loaded in the notebook
model = mlflow.pyfunc.load_model(...)
#### Option 4. A local function in the notebook
def model_fn(model_input):
# code that implements the application
response = 'the answer!'
return response
model = model_fn
###
# `data` is a pandas DataFrame with your evaluation set.
# These are simple examples. See the input schema for details.
####
# You do not have to start from a dictionary - you can use any existing pandas or
# Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
#### Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
#### Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
Contoh: Output yang dihasilkan sebelumnya disediakan
Untuk skema set evaluasi yang diperlukan, lihat Set evaluasi.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# mlflow.evaluate() call
###
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas Dataframe with the evaluation set and application outputs
model_type="databricks-agent",
)
###
# `data` is a pandas DataFrame with your evaluation set and outputs generated by the application.
# These are simple examples. See the input schema for details.
####
# You do not have to start from a dictionary - you can use any existing pandas or
# Spark DataFrame with this schema.
# Bare minimum data
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
}]
#### Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
#### Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
Pembatasan
Untuk percakapan multi-giliran, output evaluasi hanya mencatat entri terakhir dalam percakapan.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk