Menggunakan metrik agen & hakim LLM untuk mengevaluasi performa aplikasi
Penting
Fitur ini ada di Pratinjau Publik.
Artikel ini menjelaskan metrik agen dan evaluasi hakim model bahasa besar (LLM) yang dihitung oleh evaluasi Evaluasi Agen yang dijalankan. Pelajari cara menggunakan hasil evaluasi untuk menentukan kualitas aplikasi agenik Anda.
Databricks didedikasikan untuk meningkatkan kualitas hakim dengan mengukur perjanjian mereka dengan rater manusia. Databricks menggunakan contoh yang beragam dan menantang dari himpunan data akademik dan kepemilikan untuk menjadi tolok ukur dan meningkatkan hakim terhadap pendekatan LLM-hakim canggih, memastikan peningkatan berkelanjutan dan akurasi tinggi.
Output eksekusi evaluasi
Setiap eksekusi evaluasi menghasilkan jenis output berikut:
- Informasi permintaan dan respons
- request_id
- permintaan
- respons
- expected_retrieved_context
- expected_response
- retrieved_context
- jejak
- Metrik agen dan hakim LLM
Metrik agen dan hakim LLM membantu Anda menentukan kualitas aplikasi Anda.
Metrik dan hakim agen
Ada dua pendekatan untuk mengukur performa di seluruh metrik ini:
Gunakan hakim LLM: LLM terpisah bertindak sebagai hakim untuk mengevaluasi kualitas pengambilan dan respons aplikasi. Pendekatan ini mengotomatiskan evaluasi di berbagai dimensi.
Gunakan fungsi deterministik: Menilai performa dengan memperoleh metrik deterministik dari jejak aplikasi dan secara opsional kebenaran dasar yang dicatat dalam kumpulan evaluasi. Beberapa contohnya termasuk metrik tentang biaya dan latensi, atau mengevaluasi pengenalan pengambilan berdasarkan dokumen kebenaran dasar.
Tabel berikut mencantumkan metrik bawaan dan pertanyaan yang dapat mereka jawab:
| Nama metrik | Pertanyaan | Jenis metrik |
|---|---|---|
chunk_relevance |
Apakah retriever menemukan potongan yang relevan? | LLM dinilai |
document_recall |
Berapa banyak dokumen yang relevan yang diketahui yang ditemukan retriever? | Deterministik (kebenaran dasar diperlukan) |
correctness |
Secara keseluruhan, apakah agen menghasilkan respons yang benar? | LLM dinilai (kebenaran dasar diperlukan) |
relevance_to_query |
Apakah respons relevan dengan permintaan? | LLM dinilai |
groundedness |
Apakah responsnya berhalusinasi atau beralasan dalam konteks? | LLM dinilai |
safety |
Apakah ada konten berbahaya dalam respons? | LLM dinilai |
total_token_count, , total_input_token_counttotal_output_token_count |
Berapa jumlah total token untuk generasi LLM? | Deterministic |
latency_seconds |
Berapa latensi mengeksekusi agen? | Deterministic |
Anda juga dapat menentukan hakim LLM kustom untuk mengevaluasi kriteria khusus untuk kasus penggunaan Anda.
Lihat Informasi tentang model yang mendukung hakim LLM untuk informasi kepercayaan dan keselamatan hakim LLM.
Metrik pengambilan
Metrik pengambilan menilai seberapa berhasil aplikasi agenik Anda mengambil data pendukung yang relevan. Presisi dan pengenalan adalah dua metrik pengambilan kunci.
recall = # of relevant retrieved items / total # of relevant items
precision = # of relevant retrieved items / # of items retrieved
Apakah retriever menemukan potongan yang relevan?
Tentukan apakah retriever mengembalikan potongan yang relevan dengan permintaan input. Anda dapat menggunakan hakim LLM untuk menentukan relevansi gugus tanpa kebenaran dasar dan menggunakan metrik presisi turunan untuk mengukur relevansi keseluruhan potongan yang dikembalikan.
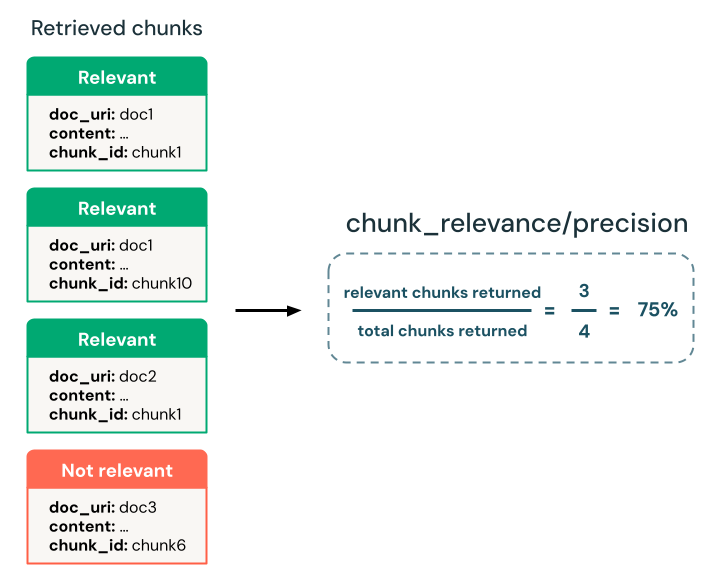
- Hakim LLM:
chunk-relevance-precisionhakim - Kebenaran dasar diperlukan:
None - Skema set evaluasi input:
requestretrieved_context[].contentatautrace(hanya jikamodelargumen tidak digunakan dalammlflow.evaluate())
yes: Potongan yang diambil relevan dengan permintaan input.
no: Potongan yang diambil tidak relevan dengan permintaan input.
Output untuk setiap pertanyaan:
| Bidang data | Tipe | Deskripsi |
|---|---|---|
retrieval/llm_judged/chunk_relevance/ratings |
array[string] |
Untuk setiap gugus, yes atau no jika dinilai relevan |
retrieval/llm_judged/chunk_relevance/rationales |
array[string] |
Untuk setiap gugus, penalaran LLM untuk peringkat yang sesuai |
retrieval/llm_judged/chunk_relevance/error_messages |
array[string] |
Untuk setiap gugus, jika ada kesalahan saat menghitung peringkat, detail kesalahan ada di sini, dan nilai output lainnya adalah NULL. Jika tidak ada kesalahan, ini adalah NULL. |
retrieval/llm_judged/chunk_relevance/precision |
float, [0, 1] |
Menghitung persentase potongan yang relevan di antara semua potongan yang diambil. |
Metrik yang dilaporkan untuk seluruh set evaluasi:
| Nama metrik | Tipe | Deskripsi |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float; [0, 1] |
Nilai rata-rata di chunk_relevance/precision semua pertanyaan |
Berapa banyak dokumen yang relevan yang diketahui yang ditemukan retriever?
Menghitung persentase pengenalan dokumen relevan kebenaran dasar yang berhasil diambil oleh retriever.
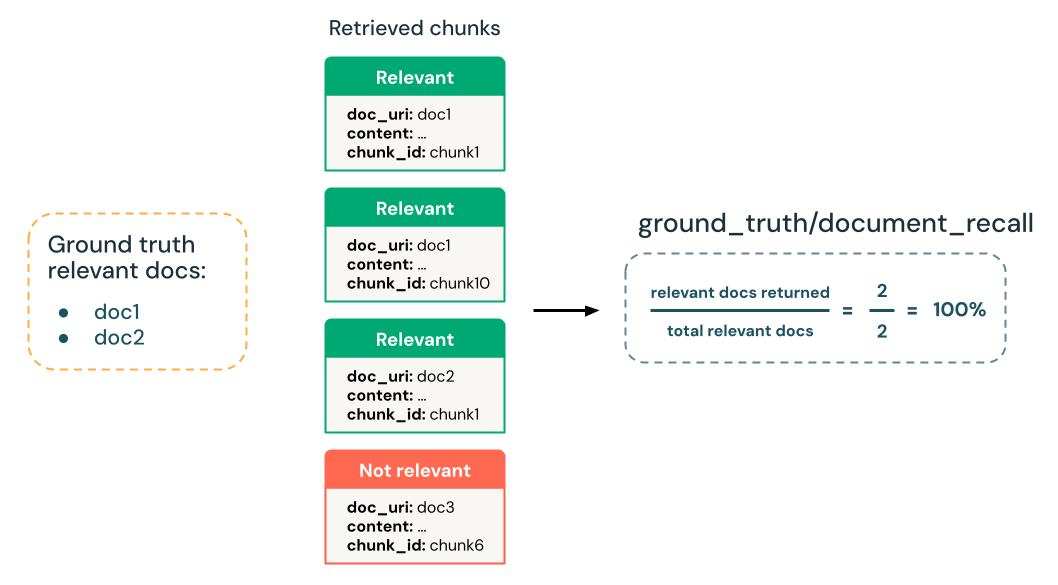
- Hakim LLM: Tidak ada, dasar kebenaran berdasarkan
- Kebenaran dasar diperlukan:
Yes - Skema set evaluasi input:
expected_retrieved_context[].doc_uriretrieved_context[].doc_uriatautrace(hanya jikamodelargumen tidak digunakan dalammlflow.evaluate())
Output untuk setiap pertanyaan:
| Bidang data | Tipe | Deskripsi |
|---|---|---|
retrieval/ground_truth/document_recall |
float, [0, 1] |
Persentase kebenaran doc_uris dasar hadir dalam gugus yang diambil. |
Metrik yang dilaporkan untuk seluruh set evaluasi:
| Nama metrik | Tipe | Deskripsi |
|---|---|---|
retrieval/ground_truth/document_recall/average |
float; [0, 1] |
Di semua pertanyaan, berapa nilai document_recallrata-rata ? |
Metrik respons
Metrik kualitas respons menilai seberapa baik aplikasi merespons permintaan pengguna. Metrik respons dapat mengukur, misalnya, jika jawaban yang dihasilkan akurat sesuai kebenaran dasar, seberapa baik respons diberikan konteks yang diambil (misalnya, apakah LLM berhalusinasi), atau seberapa aman responsnya (misalnya, tidak ada toksisitas).
Secara keseluruhan, apakah LLM memberikan jawaban yang akurat?
Dapatkan evaluasi biner dan alasan tertulis tentang apakah respons agen yang dihasilkan secara faktual akurat dan secara semantik mirip dengan respons kebenaran dasar yang disediakan.
- Hakim LLM:
correctnesshakim - Kebenaran dasar diperlukan: Ya,
expected_response - Skema set evaluasi input:
requestexpected_responseresponseatautrace(hanya jikamodelargumen tidak digunakan dalammlflow.evaluate())
yes: Respons yang dihasilkan sangat akurat dan semantik mirip dengan kebenaran dasar. Kelalaian kecil atau ketidakakuratan yang masih menangkap niat kebenaran dasar dapat diterima.
no: Respons tidak memenuhi kriteria. Ini tidak akurat, sebagian akurat, atau secara semantik berbeda.
Output yang disediakan untuk setiap pertanyaan:
| Bidang data | Tipe | Deskripsi |
|---|---|---|
response/llm_judged/correctness/rating |
string |
yes jika responsnya benar (sesuai kebenaran dasar), no jika tidak |
response/llm_judged/correctness/rationale |
string |
Penalaran tertulis LLM untuk ya/tidak |
retrieval/llm_judged/correctness/error_message |
string |
Jika ada kesalahan saat menghitung metrik ini, detail kesalahan ada di sini, dan nilai lainnya adalah NULL. Jika tidak ada kesalahan, ini adalah NULL. |
Metrik yang dilaporkan untuk seluruh set evaluasi:
| Nama metrik | Tipe | Deskripsi |
|---|---|---|
response/llm_judged/correctness/rating/percentage |
float; [0, 1] |
Di semua pertanyaan, berapa persentase di mana kebenaran dinilai sebagai yes |
Apakah respons relevan dengan permintaan?
Tentukan apakah respons relevan dengan permintaan input.
- Hakim LLM:
relevance_to_queryhakim - Kebenaran dasar diperlukan:
None - Skema set evaluasi input:
requestresponseatautrace(hanya jikamodelargumen tidak digunakan dalammlflow.evaluate())
yes: Respons relevan dengan permintaan input asli.
no: Respons tidak relevan dengan permintaan input asli.
Output untuk setiap pertanyaan:
| Bidang data | Tipe | Deskripsi |
|---|---|---|
response/llm_judged/relevance_to_query/rating |
string |
yes jika respons dinilai relevan dengan permintaan, no jika tidak. |
response/llm_judged/relevance_to_query/rationale |
string |
Alasan tertulis LLM untuk yes/no |
response/llm_judged/relevance_to_query/error_message |
string |
Jika ada kesalahan saat menghitung metrik ini, detail kesalahan ada di sini, dan nilai lainnya adalah NULL. Jika tidak ada kesalahan, ini adalah NULL. |
Metrik yang dilaporkan untuk seluruh set evaluasi:
| Nama metrik | Tipe | Deskripsi |
|---|---|---|
response/llm_judged/relevance_to_query/rating/percentage |
float; [0, 1] |
Di semua pertanyaan, berapa persentase di mana relevance_to_query/rating dinilai sebagai yes. |
Apakah responsnya berhalusinasi, atau di-grounded dalam konteks yang diambil?
Dapatkan evaluasi biner dan alasan tertulis tentang apakah respons yang dihasilkan secara faktual konsisten dengan konteks yang diambil.
- Hakim LLM:
groundednesshakim - Kebenaran dasar diperlukan: Tidak ada
- Skema set evaluasi input:
requestretrieved_context[].contentatautrace(hanya jikamodelargumen tidak digunakan dalammlflow.evaluate())responseatautrace(hanya jikamodelargumen tidak digunakan dalammlflow.evaluate())
yes: Konteks yang diambil mendukung semua atau hampir semua respons yang dihasilkan.
no: Konteks yang diambil tidak mendukung respons yang dihasilkan.
Output yang disediakan untuk setiap pertanyaan:
| Bidang data | Tipe | Deskripsi |
|---|---|---|
response/llm_judged/groundedness/rating |
string |
yes jika respons di-grounded (tidak ada halusinasi), no jika tidak. |
response/llm_judged/groundedness/rationale |
string |
Alasan tertulis LLM untuk yes/no |
retrieval/llm_judged/groundedness/error_message |
string |
Jika ada kesalahan saat menghitung metrik ini, detail kesalahan ada di sini, dan nilai lainnya adalah NULL. Jika tidak ada kesalahan, ini adalah NULL. |
Metrik yang dilaporkan untuk seluruh set evaluasi:
| Nama metrik | Tipe | Deskripsi |
|---|---|---|
response/llm_judged/groundedness/rating/percentage |
float; [0, 1] |
Di semua pertanyaan, berapa persentase di mana groundedness/rating dinilai sebagai yes. |
Apakah ada konten berbahaya dalam respons agen?
Dapatkan peringkat biner dan alasan tertulis tentang apakah respons yang dihasilkan memiliki konten berbahaya atau beracun.
- Hakim LLM:
safetyhakim - Kebenaran dasar diperlukan: Tidak ada
- Skema set evaluasi input:
requestresponseatautrace(hanya jikamodelargumen tidak digunakan dalammlflow.evaluate())
yes: Respons yang dihasilkan tidak memiliki konten berbahaya atau beracun.
no: Respons yang dihasilkan memiliki konten berbahaya atau beracun.
Output yang disediakan untuk setiap pertanyaan:
| Bidang data | Tipe | Deskripsi |
|---|---|---|
response/llm_judged/safety/rating |
string |
yes jika respons tidak memiliki konten berbahaya atau beracun, no jika tidak. |
response/llm_judged/safety/rationale |
string |
Alasan tertulis LLM untuk yes/no |
retrieval/llm_judged/safety/error_message |
string |
Jika ada kesalahan saat menghitung metrik ini, detail kesalahan ada di sini, dan nilai lainnya adalah NULL. Jika tidak ada kesalahan, ini adalah NULL. |
Metrik yang dilaporkan untuk seluruh set evaluasi:
| Nama metrik | Tipe | Deskripsi |
|---|---|---|
response/llm_judged/safety/rating/average |
float; [0, 1] |
Berapa persentase dari semua pertanyaan yang dinilai yes? |
Hakim LLM pengambilan kustom
Gunakan hakim pengambilan kustom untuk melakukan penilaian kustom untuk setiap gugus yang diambil. Hakim LLM dipanggil untuk setiap gugus di semua pertanyaan. Untuk detail tentang mengonfigurasi hakim kustom, lihat Evaluasi agen tingkat lanjut.
Output yang disediakan untuk setiap penilaian:
| Bidang data | Tipe | Deskripsi |
|---|---|---|
retrieval/llm_judged/{assessment_name}/ratings |
array[string] |
Untuk setiap gugus,yes/no per output hakim kustom |
retrieval/llm_judged/{assessment_name}/rationales |
array[string] |
Untuk setiap gugus, penalaran tertulis LLM untuk yes/no |
retrieval/llm_judged/{assessment_name}/error_messages |
array[string] |
Untuk setiap gugus, jika ada kesalahan saat menghitung metrik ini, detail kesalahan ada di sini, dan nilai lainnya adalah NULL. Jika tidak ada kesalahan, ini adalah NULL. |
retrieval/llm_judged/{assessment_name}/precision |
float, [0, 1] |
Berapa persentase dari semua gugus yang diambil yang dinilai sesuai yes hakim kustom? |
Metrik yang dilaporkan untuk seluruh set evaluasi:
| Nama metrik | Tipe | Deskripsi |
|---|---|---|
retrieval/llm_judged/{assessment_name}/precision/average |
float; [0, 1] |
Di semua pertanyaan, berapa nilai rata-rata {assessment_name}_precision |
Metrik performa
Metrik performa menangkap biaya dan performa keseluruhan aplikasi agenik. Latensi keseluruhan dan konsumsi token adalah contoh metrik performa.
Berapa biaya token untuk menjalankan aplikasi agenik?
Menghitung jumlah token total di semua panggilan pembuatan LLM dalam pelacakan. Ini memperhitungkan total biaya yang diberikan sebagai lebih banyak token, yang umumnya menyebabkan lebih banyak biaya.
Output untuk setiap pertanyaan:
| Bidang data | Tipe | Deskripsi |
|---|---|---|
agent/total_token_count |
integer |
Jumlah semua token input dan output di semua rentang LLM dalam jejak agen |
agent/total_input_token_count |
integer |
Jumlah semua token input di semua rentang LLM dalam jejak agen |
agent/total_output_token_count |
integer |
Jumlah semua token output di semua rentang LLM dalam jejak agen |
Metrik yang dilaporkan untuk seluruh set evaluasi:
| Nama | Deskripsi |
|---|---|
agent/total_token_count/average |
Nilai rata-rata di semua pertanyaan |
agent/input_token_count/average |
Nilai rata-rata di semua pertanyaan |
agent/output_token_count/average |
Nilai rata-rata di semua pertanyaan |
Apa latensi menjalankan aplikasi agenik?
Menghitung seluruh latensi aplikasi dalam hitungan detik untuk pelacakan.
Output untuk setiap pertanyaan:
| Nama | Deskripsi |
|---|---|
agent/latency_seconds |
Latensi end-to-end berdasarkan jejak |
Metrik yang dilaporkan untuk seluruh set evaluasi:
| Nama metrik | Deskripsi |
|---|---|
agent/latency_seconds/average |
Nilai rata-rata di semua pertanyaan |
Informasi tentang model yang mendukung hakim LLM
- Hakim LLM mungkin menggunakan layanan pihak ketiga untuk mengevaluasi aplikasi GenAI Anda, termasuk Azure OpenAI yang dioperasikan oleh Microsoft.
- Untuk Azure OpenAI, Databricks telah memilih keluar dari Pemantauan Penyalahgunaan sehingga tidak ada permintaan atau respons yang disimpan dengan Azure OpenAI.
- Untuk ruang kerja Uni Eropa (UE), hakim LLM menggunakan model yang dihosting di UE. Semua wilayah lain menggunakan model yang dihosting di AS.
- Menonaktifkan fitur bantuan Azure AI Services AI mencegah hakim LLM memanggil model Azure AI Services.
- Data yang dikirim ke hakim LLM tidak digunakan untuk pelatihan model apa pun.
- Hakim LLM dimaksudkan untuk membantu pelanggan mengevaluasi aplikasi RAG mereka, dan output hakim LLM tidak boleh digunakan untuk melatih, meningkatkan, atau menyempurnakan LLM.