Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menjelaskan cara membangun alur data yang tidak terstruktur untuk aplikasi AI gen. Alur yang tidak terstruktur sangat berguna untuk aplikasi Retrieval-Augmented Generation (RAG).
Pelajari cara mengonversi konten yang tidak terstruktur seperti file teks dan PDF menjadi indeks vektor yang dapat dikueri agen AI atau pengambil ulang lainnya. Anda juga mempelajari cara bereksperimen dan menyetel alur Anda untuk mengoptimalkan potongan, pengindeksan, dan penguraian data, memungkinkan Anda memecahkan masalah dan bereksperimen dengan alur untuk mencapai hasil yang lebih baik.
Notebook saluran data yang tidak terstruktur
Buku catatan berikut ini memperlihatkan kepada Anda cara menerapkan informasi dalam artikel ini untuk membuat alur data yang tidak terstruktur.
Alur data tidak terstruktur Databricks
Komponen utama alur data
Fondasi aplikasi RAG apa pun dengan data yang tidak terstruktur adalah alur data. Alur ini bertanggung jawab untuk mengumpulkan dan menyiapkan data yang tidak terstruktur dalam format yang dapat digunakan aplikasi RAG secara efektif.

Meskipun alur data ini dapat menjadi kompleks tergantung pada kasus penggunaan, berikut ini adalah komponen utama yang perlu Anda pikirkan saat pertama kali membangun aplikasi RAG Anda:
- komposisi dan penyerapan Corpus: Pilih sumber data dan konten yang tepat berdasarkan kasus penggunaan tertentu.
-
Pemrosesan data: Mengubah data mentah menjadi format yang bersih dan konsisten yang cocok untuk penyisipan dan pengambilan.
- Penguraian: Ekstrak informasi yang relevan dari data mentah menggunakan teknik penguraian yang sesuai.
-
Pengayaan : Memperkaya data dengan metadata tambahan dan menghapus kebisingan.
- Ekstraksi Metadata: Ekstrak metadata yang berguna untuk melaksanakan pengambilan data yang lebih cepat dan efisien.
- Deduplikasi: Analisis dokumen untuk mengidentifikasi dan menghilangkan duplikat atau dokumen yang hampir mirip.
- Pemfilteran: Hilangkan dokumen yang tidak relevan atau tidak diinginkan dari kumpulan.
- Chunking: Memecah data yang telah diurai menjadi bagian kecil yang mudah dikelola untuk pengambilan yang efisien.
- Embedding: Konversikan data teks yang dipotong menjadi representasi vektor numerik yang menangkap makna semantiknya.
- Pengindeksan dan penyimpanan: Buat indeks vektor yang efisien untuk performa pencarian yang dioptimalkan.
Komposisi Corpus dan Penyerapan
Aplikasi RAG Anda tidak dapat mengambil informasi yang diperlukan untuk menjawab kueri pengguna tanpa korpus data yang tepat. Data yang benar sepenuhnya tergantung pada persyaratan dan tujuan spesifik aplikasi Anda, sehingga sangat penting untuk mendedikasikan waktu untuk memahami nuansa data yang tersedia. Untuk informasi selengkapnya, lihat alur kerja pengembang aplikasi AI Generatif.
Misalnya, saat membangun bot dukungan pelanggan, Anda mungkin mempertimbangkan untuk menyertakan yang berikut ini:
- Dokumen pangkalan pengetahuan
- Tanya Jawab Umum (FAQ)
- Manual dan spesifikasi produk
- Panduan Pemecahan Masalah
Libatkan pakar domain dan pemangku kepentingan dari awal proyek apa pun untuk membantu mengidentifikasi dan mengumpulkan konten yang relevan yang dapat meningkatkan kualitas dan cakupan korpus data Anda. Mereka dapat memberikan wawasan tentang jenis kueri yang mungkin dikirimkan pengguna dan membantu memprioritaskan informasi yang paling penting untuk disertakan.
Databricks merekomendasikan Anda menyerap data dengan cara yang dapat diskalakan dan bertahap. Azure Databricks menawarkan berbagai metode untuk penyerapan data, termasuk konektor yang dikelola sepenuhnya untuk aplikasi SaaS dan integrasi API. Sebagai praktik terbaik, data sumber mentah harus diserap dan disimpan dalam tabel target. Pendekatan ini memastikan pelestarian, keterlacakan, dan audit data. Lihat Konektor standar di Lakeflow Connect.
Prapemrosesan Data
Setelah data diserap, penting untuk membersihkan dan memformat data mentah ke dalam format yang konsisten yang cocok untuk penyematan dan pengambilan.
Penguraian
Setelah mengidentifikasi sumber data yang sesuai untuk aplikasi retriever Anda, langkah selanjutnya adalah mengekstrak informasi yang diperlukan dari data mentah. Proses ini, yang dikenal sebagai penguraian, melibatkan transformasi data yang tidak terstruktur menjadi format yang dapat digunakan aplikasi RAG secara efektif.
Teknik dan alat penguraian spesifik yang Anda gunakan bergantung pada jenis data yang sedang Anda kerjakan. Contohnya:
- Dokumen teks (PDF, dokumen Word): Pustaka di luar rak seperti tidak terstruktur dan PyPDF2 dapat menangani berbagai format file dan menyediakan opsi untuk menyesuaikan proses penguraian.
- dokumen HTML: pustaka pemrosesan HTML seperti BeautifulSoup dan lxml dapat digunakan untuk mengekstrak konten yang relevan dari halaman web. Pustaka ini dapat membantu menavigasi struktur HTML, memilih elemen tertentu, dan mengekstrak teks atau atribut yang diinginkan.
- Gambar dan dokumen yang dipindai: teknik Optical Character Recognition (OCR) biasanya diperlukan untuk mengekstrak teks dari gambar. Pustaka OCR populer termasuk pustaka sumber terbuka seperti versi Tesseract atau SaaS seperti Amazon Textract, Azure AI Vision OCR, dan Google Cloud Vision API.
Praktik terbaik untuk mengurai data
Penguraian memastikan data bersih, terstruktur, dan siap untuk pembuatan penyematan dan Pencarian Vektor. Saat mengurai data Anda, pertimbangkan praktik terbaik berikut:
- Pembersihan data: Memproses teks yang diekstrak sebelumnya untuk menghapus informasi yang tidak relevan atau berisik, seperti header, footer, atau karakter khusus. Kurangi jumlah informasi yang tidak perlu atau salah bentuk yang perlu diproses oleh rantai RAG Anda.
- Menangani kesalahan dan pengecualian: Terapkan penanganan kesalahan dan mekanisme pengelogan untuk mengidentifikasi dan menyelesaikan masalah apa pun yang dihadapi selama proses penguraian. Ini membantu Anda mengidentifikasi dan memperbaiki masalah dengan cepat. Melakukannya sering menunjukkan masalah di hulu terkait kualitas data sumber.
- Menyesuaikan logika penguraian: Tergantung pada struktur dan format data Anda, Anda mungkin perlu menyesuaikan logika penguraian untuk mengekstrak informasi yang paling relevan. Meskipun mungkin memerlukan upaya tambahan di muka, investasikan waktu untuk melakukan ini jika perlu, karena sering mencegah banyak masalah kualitas hilir.
- Mengevaluasi kualitas penguraian: Menilai kualitas data yang diurai secara teratur dengan meninjau sampel output secara manual. Ini dapat membantu Anda mengidentifikasi masalah atau area apa pun untuk perbaikan dalam proses penguraian.
Pengayaan
Perkaya data dengan metadata tambahan dan hapus kebisingan. Meskipun pengayaan bersifat opsional, pengayaan dapat secara drastis meningkatkan performa keseluruhan aplikasi Anda.
ekstraksi metadata
Menghasilkan dan mengekstrak metadata yang menangkap informasi penting tentang konten, konteks, dan struktur dokumen dapat secara signifikan meningkatkan kualitas dan performa pengambilan aplikasi RAG. Metadata menyediakan sinyal tambahan yang meningkatkan relevansi, mengaktifkan pemfilteran tingkat lanjut, dan mendukung persyaratan pencarian khusus domain.
Meskipun pustaka seperti LangChain dan LlamaIndex menyediakan pengurai bawaan yang mampu mengekstrak metadata standar terkait secara otomatis, sering kali membantu untuk melengkapi ini dengan metadata kustom yang disesuaikan dengan kasus penggunaan spesifik Anda. Pendekatan ini memastikan bahwa informasi khusus domain penting ditangkap, meningkatkan pengambilan dan pengembangan penggunaan selanjutnya. Anda juga dapat menggunakan model bahasa besar (LLM) untuk mengotomatiskan peningkatan metadata.
Jenis metadata meliputi:
- Metadata tingkat dokumen: Nama file, URL, informasi penulis, tanda waktu pembuatan dan modifikasi, koordinat GPS, dan penerapan versi dokumen.
- Metadata berbasis konten: Kata kunci yang diekstrak, ringkasan, topik, entitas yang disebutkan, dan tag khusus domain (nama dan kategori produk seperti PII atau HIPAA).
- Metadata struktural: judul seksi, daftar isi, nomor halaman, dan batas konten semantik (bab atau subbagian).
- Metadata kontekstual: Sistem sumber, tanggal penyerapan, tingkat sensitivitas data, bahasa asli, atau instruksi transnasional.
Menyimpan metadata bersama dokumen terpotong atau embedding yang sesuai sangat penting untuk performa optimal. Ini juga akan membantu mempersempit informasi yang diambil dan meningkatkan akurasi dan skalabilitas aplikasi Anda. Selain itu, mengintegrasikan metadata ke dalam alur pencarian hibrid, yang berarti menggabungkan pencarian kesamaan vektor dengan pemfilteran berbasis kata kunci, dapat meningkatkan relevansi, terutama dalam himpunan data besar atau skenario kriteria pencarian tertentu.
Deduplikasi
Bergantung pada sumber, Anda dapat berakhir dengan dokumen duplikat atau mendekati duplikat. Misalnya, jika Anda mengambil dari satu atau beberapa penyimpanan bersama, beberapa salinan dokumen yang sama bisa ditemukan di beberapa lokasi. Beberapa salinan tersebut mungkin memiliki modifikasi yang halus. Demikian pula, pangkalan pengetahuan Anda mungkin memiliki salinan dokumentasi produk Anda atau salinan draf posting blog. Jika duplikat ini tetap berada di korpus Anda, Anda dapat berakhir dengan bagian yang sangat berlebihan dalam indeks akhir Anda yang dapat menurunkan performa aplikasi Anda.
Anda dapat menghilangkan beberapa duplikat menggunakan metadata saja. Misalnya, jika item memiliki judul dan tanggal pembuatan yang sama tetapi beberapa entri dari sumber atau lokasi yang berbeda, Anda dapat memfilternya berdasarkan metadata.
Namun, ini mungkin tidak cukup. Untuk membantu mengidentifikasi dan menghilangkan duplikat berdasarkan konten dokumen, Anda dapat menggunakan teknik yang dikenal sebagai hashing peka lokalitas. Secara khusus, teknik yang disebut MinHash berfungsi dengan baik di sini, dan implementasi Spark sudah tersedia di Spark ML. Ini bekerja dengan membuat hash untuk dokumen berdasarkan kata-kata yang dikandungnya dan kemudian dapat secara efisien mengidentifikasi duplikat atau mendekati duplikat dengan menggunakan hash tersebut. Pada tingkat yang sangat tinggi, ini adalah proses empat langkah:
- Buat vektor fitur untuk setiap dokumen. Jika diperlukan, pertimbangkan untuk menerapkan teknik seperti menghentikan penghapusan kata, stemming, dan lemmatisasi untuk meningkatkan hasilnya, lalu tokenisasi menjadi n-gram.
- Sesuaikan model MinHash dan hash vektor menggunakan MinHash untuk jarak Jaccard.
- Jalankan gabungan kesamaan menggunakan hash tersebut untuk menghasilkan set hasil untuk setiap duplikat atau dokumen yang hampir duplikat.
- Filter duplikat yang tidak ingin Anda simpan.
Langkah deduplikasi garis dasar dapat memilih dokumen untuk disimpan secara acak (seperti dokumen pertama dalam hasil setiap duplikat atau pilihan acak di antara duplikat). Peningkatan potensial adalah memilih versi "terbaik" dari duplikat menggunakan logika lain (seperti yang terakhir diperbarui, status publikasi, atau sumber yang paling otoritatif). Selain itu, perhatikan bahwa Anda mungkin perlu bereksperimen dengan langkah pembuatan fitur dan jumlah tabel hash yang digunakan dalam model MinHash untuk meningkatkan hasil pencocokan.
Untuk informasi selengkapnya, lihat Dokumentasi Spark untuk hashing yang sensitif terhadap lokalitas.
Penyaringan
Beberapa dokumen yang Anda serap ke dalam korpus Anda mungkin tidak berguna untuk agen Anda, baik karena tidak relevan dengan tujuannya, terlalu tua atau tidak dapat diandalkan, atau karena mengandung konten bermasalah seperti bahasa berbahaya. Namun, dokumen lain mungkin berisi informasi sensitif yang tidak ingin Anda ekspos melalui agen Anda.
Oleh karena itu, pertimbangkan untuk menyertakan langkah dalam alur Anda untuk memfilter dokumen-dokumen ini dengan menggunakan metadata apa pun, seperti menerapkan pengklasifikasi toksisitas ke dokumen untuk menghasilkan prediksi yang dapat Anda gunakan sebagai filter. Contoh lain adalah menerapkan algoritma deteksi informasi identitas pribadi (PII) ke dokumen untuk memfilter dokumen.
Akhirnya, sumber dokumen apa pun yang Anda umpankan ke agen Anda adalah vektor serangan potensial bagi pelaku jahat untuk meluncurkan serangan keracunan data. Anda juga dapat mempertimbangkan untuk menambahkan mekanisme deteksi dan pemfilteran untuk membantu mengidentifikasi dan menghilangkannya.
Penggugusan

Setelah mengurai data mentah ke dalam format yang lebih terstruktur, menghapus duplikat, dan memfilter informasi yang tidak diinginkan, langkah selanjutnya adalah memecahnya menjadi unit yang lebih kecil dan dapat dikelola yang disebut gugus. Mensegmentasi dokumen besar menjadi potongan yang lebih kecil dan terkonsentrasi secara semantik memastikan bahwa data yang diambil sesuai dalam konteks LLM sambil meminimalkan dimasukkannya informasi yang mengganggu atau tidak relevan. Pilihan yang dibuat pada pembagian data akan secara langsung memengaruhi data yang diambil yang disiapkan oleh LLM, menjadikannya salah satu lapisan pengoptimalan pertama dalam aplikasi RAG.
Saat memotong data Anda, pertimbangkan faktor-faktor berikut:
- Strategi pengelompokan: Metode yang Anda gunakan untuk membagi teks asli menjadi bagian-bagian. Ini dapat melibatkan teknik dasar seperti pemisahan menurut kalimat, paragraf, jumlah karakter/token tertentu, dan strategi pemisahan khusus dokumen yang lebih canggih.
- Ukuran gugus: Potongan yang lebih kecil mungkin berfokus pada detail tertentu tetapi kehilangan beberapa informasi kontekstual di sekitarnya. Potongan yang lebih besar dapat menangkap lebih banyak konteks tetapi dapat mencakup informasi yang tidak relevan atau mahal secara komputasi.
- Tumpang tindih antar gugus: Untuk memastikan bahwa informasi penting tidak hilang saat membagi data menjadi potongan, pertimbangkan untuk menyertakan beberapa tumpang tindih antara gugus yang berdekatan. Tumpang tindih dapat memastikan kelangsungan dan pelestarian konteks di seluruh gugus dan meningkatkan hasil pengambilan.
- Koherensi Semantik: Jika memungkinkan, bertujuan untuk membuat gugus koheren semantik yang berisi informasi terkait tetapi dapat berdiri secara independen sebagai unit teks yang bermakna. Ini dapat dicapai dengan mempertimbangkan struktur data asli, seperti paragraf, bagian, atau batas topik.
- Metadata:Metadata yang relevan, seperti nama dokumen sumber, judul bagian, atau nama produk, dapat meningkatkan pengambilan. Informasi tambahan ini dapat membantu mencocokkan kueri pengambilan dengan segmen.
Strategi pemotongan data
Menemukan metode pengelompokan yang tepat adalah proses iteratif dan bergantung pada konteks. Tidak ada pendekatan yang cocok untuk semua. Ukuran dan metode potongan optimal tergantung pada kasus penggunaan tertentu dan sifat data yang sedang diproses. Secara luas, strategi pemotongan dapat dilihat sebagai berikut:
- Potongan ukuran tetap: Pisahkan teks menjadi potongan dengan ukuran yang telah ditentukan sebelumnya, seperti jumlah karakter atau token tetap (misalnya, LangChain CharacterTextSplitter). Meskipun pembagian berdasarkan jumlah karakter/token secara arbitrer mudah dan cepat untuk diatur, biasanya tidak akan menghasilkan gugus yang koheren secara semantik yang konsisten. Pendekatan ini jarang berfungsi untuk aplikasi tingkat produksi.
- Potongan berbasis paragraf: Gunakan batas paragraf alami dalam teks untuk menentukan gugus. Metode ini dapat membantu mempertahankan koherensi semantik gugus, karena paragraf sering berisi informasi terkait (misalnya, LangChain RecursiveCharacterTextSplitter).
- Pemotongan khusus format: Format seperti Markdown atau HTML memiliki struktur bawaan yang dapat menentukan batas potongan (misalnya, header Markdown). Alat seperti LangChain's MarkdownHeaderTextSplitter atau pemisah berbasis header/section HTML dapat digunakan untuk tujuan ini.
- Potongan Semantik: Teknik seperti pemodelan topik dapat diterapkan untuk mengidentifikasi bagian koheren semantik dalam teks. Pendekatan ini menganalisis konten atau struktur setiap dokumen untuk menentukan batas potongan yang paling tepat berdasarkan pergeseran topik. Meskipun lebih terlibat daripada pendekatan dasar, potongan semantik dapat membantu membuat gugus yang lebih selaras dengan divisi semantik alami dalam teks (lihat LangChain SemanticChunker, misalnya).
Contoh: Pembagian berukuran tetap
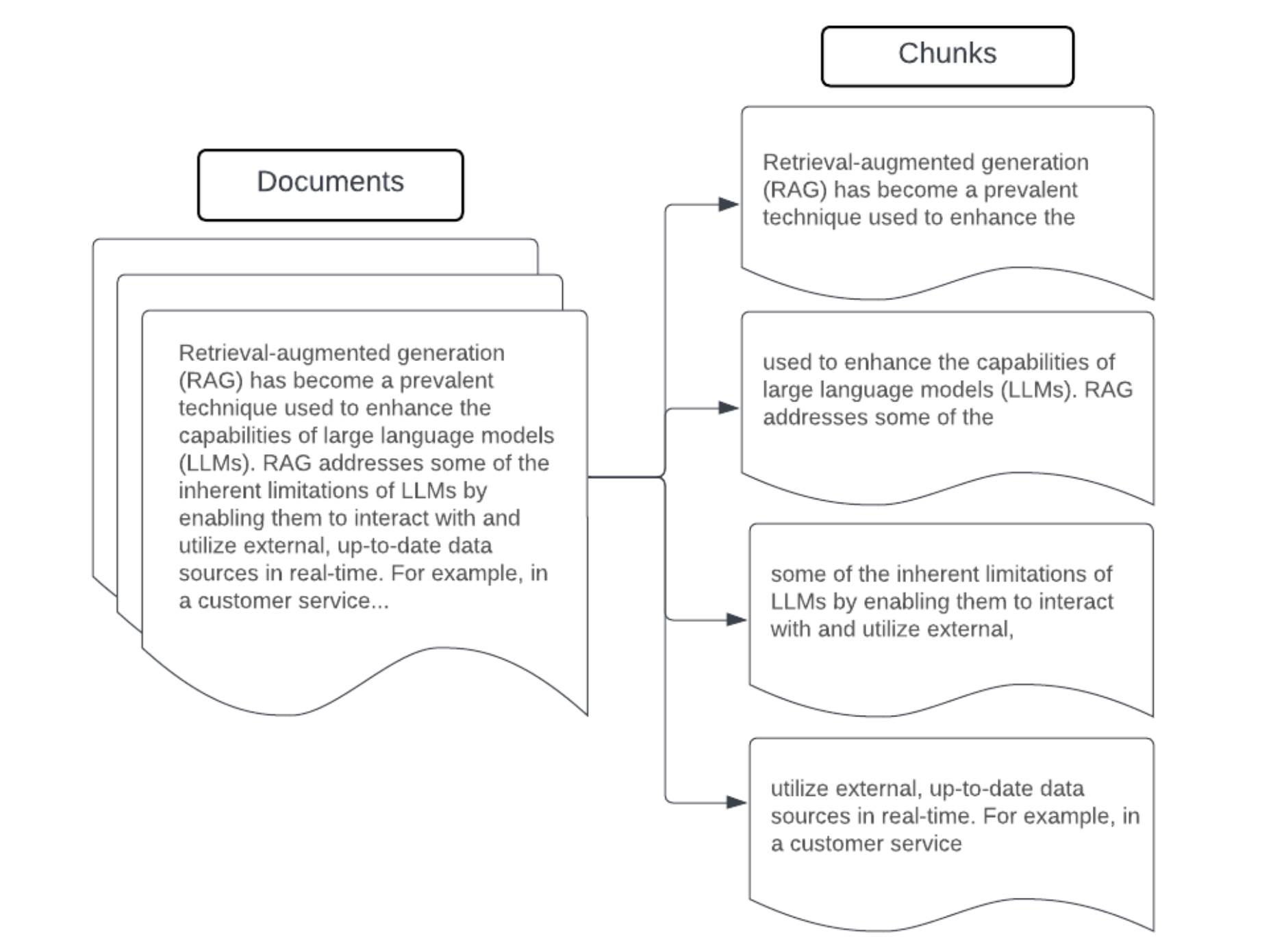
Contoh pembagian ukuran tetap menggunakan LangChain RecursiveCharacterTextSplitter dengan chunk_size=100 dan chunk_overlap=20. ChunkViz menyediakan cara interaktif untuk memvisualisasikan bagaimana berbagai ukuran gugus dan nilai tumpang tindih gugus dengan pemisah karakter Langchain memengaruhi potongan yang dihasilkan.
Penyematan

Setelah memotong data Anda, langkah selanjutnya adalah mengonversi gugus teks menjadi representasi vektor menggunakan model penyematan. Model penyematan mengonversi setiap potongan teks menjadi representasi vektor yang menangkap makna semantiknya. Dengan mewakili gugus sebagai vektor padat, penyematan memungkinkan pengambilan potongan yang paling relevan dengan cepat dan akurat berdasarkan kesamaan semantiknya dengan kueri pengambilan. Kueri pengambilan akan diubah pada saat waktu kueri menggunakan model penyematan yang sama yang digunakan untuk menyematkan potongan dalam alur data.
Saat memilih model penyematan, pertimbangkan faktor-faktor berikut:
- Pilihan model: Setiap model penyematan memiliki nuansa, dan tolok ukur yang tersedia mungkin tidak menangkap karakteristik spesifik data Anda. Sangat penting untuk memilih model yang telah dilatih pada data serupa. Mungkin juga bermanfaat untuk mengeksplorasi model embedding yang tersedia yang dirancang untuk tugas tertentu. Lakukan eksperimen dengan model embedding siap pakai yang berbeda, bahkan model yang barangkali memiliki peringkat lebih rendah di papan peringkat standar seperti MTEB. Beberapa contoh yang perlu dipertimbangkan:
- Token maksimum: Ketahui batas token maksimum untuk model embedding yang Anda pilih. Jika Anda meneruskan potongan yang melebihi batas ini, potongan tersebut akan dipangkas, berpotensi kehilangan informasi penting. Misalnya, bge-large-en-v1.5 memiliki batas token maksimum 512.
- Ukuran model: Model penyematan yang lebih besar umumnya berkinerja lebih baik tetapi memerlukan lebih banyak sumber daya komputasi. Berdasarkan kasus penggunaan spesifik dan sumber daya yang tersedia, Anda harus menyeimbangkan performa dan efisiensi.
- Penyempurnaan: Jika aplikasi RAG Anda berkaitan dengan bahasa khusus domain (seperti akronim atau terminologi perusahaan internal), pertimbangkan untuk menyempurnakan model penyematan pada data khusus domain. Ini dapat membantu model menangkap nuansa dan terminologi domain tertentu dengan lebih baik dan sering dapat menyebabkan peningkatan performa pengambilan.
Pengindeksan dan penyimpanan
Langkah selanjutnya dalam alur adalah membuat indeks pada penyematan dan metadata yang dihasilkan pada langkah-langkah sebelumnya. Tahap ini melibatkan pengorganisasian penyematan vektor dimensi tinggi ke dalam struktur data efisien yang memungkinkan pencarian kesamaan yang cepat dan akurat.
Mosaic AI Vector Search menggunakan teknik pengindeksan terbaru saat Anda menyebarkan titik akhir pencarian vektor dan indeks untuk memastikan pencarian yang cepat dan efisien untuk kueri pencarian vektor Anda. Anda tidak perlu khawatir tentang pengujian dan memilih teknik pengindeksan terbaik.
Setelah indeks Anda dibangun dan disebarkan, indeks siap untuk disimpan dalam sistem yang mendukung kueri latensi rendah yang dapat diskalakan. Untuk alur RAG produksi dengan himpunan data besar, gunakan database vektor atau layanan pencarian yang dapat diskalakan untuk memastikan latensi rendah dan throughput tinggi. Simpan metadata tambahan bersama embedding untuk memungkinkan pemfilteran yang efisien selama pengambilan.