Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Mengembangkan aplikasi AI generatif yang kuat (aplikasi gen AI) memerlukan perencanaan yang disyaratkan, perulangan evaluasi umpan balik pengembangan yang cepat, dan infrastruktur produksi yang dapat diskalakan. Alur kerja ini menguraikan urutan langkah yang direkomendasikan untuk memandu Anda dari bukti konsep awal (POC) hingga penyebaran produksi.
- Kumpulkan persyaratan untuk memvalidasi kecocokan AI gen dan mengidentifikasi batasan.
- Desain arsitektur solusi Anda. Lihat Pola desain sistem agen
- Siapkan sumber data dan buat alat yang diperlukan.
- Membangun dan memvalidasi prototipe awal (POC).
- Terapkan ke lingkungan pra-produksi.
- Mengumpulkan umpan balik pengguna dan mengukur kualitas
- Perbaiki masalah kualitas dengan menyempurnakan logika agen dan alat berdasarkan evaluasi.
- Masukkan masukan dari ahli bidang (SME) untuk terus meningkatkan kualitas sistem agen.
- Sebarkan aplikasi AI gen ke lingkungan produksi.
- Pantau performa dan kualitas.
- Pertahankan dan tingkatkan berdasarkan penggunaan dunia nyata.
Alur kerja ini harus berulang: setelah setiap siklus penyebaran atau evaluasi, kembali ke langkah-langkah sebelumnya untuk menyempurnakan alur data atau memperbarui logika agen. Misalnya, pemantauan produksi mungkin mengungkapkan persyaratan baru, memicu pembaruan pada desain agen dan putaran evaluasi lainnya. Dengan mengikuti langkah-langkah ini secara sistematis dan memanfaatkan kemampuan pelacakan Databricks MLflow, Agent Framework, dan Evaluasi Agen, Anda dapat membangun aplikasi AI gen berkualitas tinggi yang dengan andal memenuhi kebutuhan pengguna, mematuhi persyaratan keamanan dan kepatuhan, dan terus meningkat dari waktu ke waktu.
0. Prasyarat
Sebelum Anda mulai mengembangkan aplikasi AI gen Anda, tidak dapat diluapkan seberapa penting untuk meluangkan waktu untuk melakukan hal berikut dengan benar: mengumpulkan persyaratan dan desain solusi.
Persyaratan pengumpulan mencakup langkah-langkah berikut:
- Validasi apakah AI gen sesuai dengan kasus penggunaan Anda.
- Tentukan pengalaman pengguna.
- Identifikasi sumber data.
- Atur batasan performa.
- Memahami batasan keamanan.
desain solusi mencakup hal-hal berikut:
- Memetakan alur data.
- Identifikasi alat yang diperlukan.
- Menguraikan arsitektur sistem secara keseluruhan.
Dengan meletakkan dasar ini, Anda menetapkan arah yang jelas untuk tahap Pengembangan , Evaluasi , dan Produksi berikutnya.
Mengumpulkan persyaratan
Menentukan persyaratan kasus penggunaan yang jelas dan komprehensif adalah langkah pertama yang penting dalam mengembangkan aplikasi AI gen Anda yang sukses. Persyaratan ini melayani tujuan berikut:
- Mereka membantu menentukan apakah pendekatan AI gen sesuai untuk kasus penggunaan Anda.
- Mereka memandu keputusan desain, implementasi, dan evaluasi solusi.
Menginvestasikan waktu di awal untuk mengumpulkan persyaratan terperinci dapat mencegah tantangan signifikan nantinya dalam proses pengembangan dan memastikan bahwa solusi yang dihasilkan memenuhi kebutuhan pengguna akhir dan pemangku kepentingan. Persyaratan yang ditentukan dengan baik memberikan fondasi untuk tahap selanjutnya dari siklus hidup aplikasi Anda.
Apakah kasus penggunaan ini cocok untuk AI generatif?
Sebelum berkomitmen pada solusi AI gen, pertimbangkan apakah kekuatannya yang melekat selaras dengan kebutuhan Anda. Beberapa contoh di mana solusi AI generatif cocok meliputi:
- Pembuatan konten: Tugas memerlukan pembuatan konten baru atau kreatif yang tidak dapat dicapai dengan templat statis atau logika berbasis aturan sederhana.
- Penanganan kueri dinamis: Kueri pengguna bersifat terbuka atau kompleks dan memerlukan respons yang fleksibel serta sadar konteks.
- Sintesis Informasi: Manfaat kasus penggunaan dari menggabungkan atau meringkas berbagai sumber informasi untuk menghasilkan output yang koheren.
-
Agent Systems: Aplikasi memerlukan lebih dari sekadar menghasilkan teks sebagai respons terhadap perintah. Ini mungkin perlu mampu:
- Perencanaan dan pengambilan keputusan: Merumuskan strategi multi-langkah untuk mencapai tujuan tertentu.
- Mengambil tindakan: Memicu proses eksternal atau memanggil berbagai alat untuk melakukan tugas (misalnya, mengambil data, melakukan panggilan API, menjalankan kueri SQL, menjalankan kode).
- Mempertahankan status: Melacak riwayat percakapan atau konteks tugas di beberapa interaksi untuk memungkinkan kelangsungan.
- Menghasilkan output adaptif: Menghasilkan respons yang berkembang berdasarkan tindakan sebelumnya, informasi yang diperbarui, atau perubahan kondisi.
Sebaliknya, pendekatan AI gen mungkin tidak ideal dalam situasi berikut:
- Tugas ini sangat deterministik dan dapat diselesaikan secara efektif dengan templat yang telah ditentukan sebelumnya atau sistem berbasis aturan.
- Seluruh set informasi yang diperlukan sudah statis atau sesuai dalam kerangka kerja tertutup yang sederhana.
- Respons dengan latensi yang sangat rendah (milidetik) diperlukan, dan tambahan beban dari pemrosesan generatif tidak dapat ditoleransi.
- Respons sederhana dan templat cukup untuk kasus penggunaan yang dimaksudkan.
Penting
Bagian di bawah ini menggunakan label P0, P1, dan label P2 untuk menunjukkan prioritas relatif.
- 🟢 [P0] item-item adalah krusial atau penting. Ini harus segera ditangani.
- 🟡 item [P1] adalah penting tetapi dapat mengikuti setelah persyaratan P0.
- ⚪ [P2] item-item adalah pertimbangan atau peningkatan prioritas yang lebih rendah yang dapat ditangani ketika waktu dan sumber daya memungkinkan.
Label ini membantu tim dengan cepat melihat persyaratan mana yang membutuhkan perhatian segera versus yang dapat ditangguhkan.
Pengalaman pengguna
Tentukan bagaimana pengguna akan berinteraksi dengan aplikasi AI gen dan respons seperti apa yang diharapkan.
- 🟢 [P0] Permintaan umum: Seperti apa permintaan pengguna biasa? Kumpulkan contoh dari pemangku kepentingan.
- 🟢 [P0] Respons yang diharapkan: Jenis respons apa yang harus dihasilkan sistem (misalnya, jawaban singkat, penjelasan bentuk panjang, narasi kreatif)?
- 🟡 modalitas interaksi [P1]: Bagaimana pengguna akan berinteraksi dengan aplikasi (misalnya, antarmuka obrolan, bilah pencarian, asisten suara)?
- 🟡 [P1] Nada, gaya, dan struktur: Nada, gaya, dan struktur apa yang harus diadopsi output yang dihasilkan (formal, percakapan, teknis, poin-poin, atau prosa berkelanjutan)?
- 🟡 [P1]Penanganan kesalahan: Bagaimana aplikasi harus menangani kueri yang ambigu, tidak lengkap, atau di luar target? Haruskah memberikan umpan balik atau meminta klarifikasi?
- ⚪ [P2] Persyaratan pemformatan: Apakah ada panduan pemformatan atau presentasi tertentu untuk output (termasuk metadata atau informasi tambahan)?
Data Informasi
Tentukan sifat, sumber, dan kualitas data yang akan digunakan di aplikasi gen AI.
-
🟢
[P0] Sumber data: Sumber data apa yang tersedia?
- Untuk setiap sumber, tentukan:
- Apakah data terstruktur atau tidak terstruktur?
- Apa format sumber (misalnya, PDF, HTML, JSON, XML)?
- Di mana data berada?
- Berapa banyak data yang tersedia?
- Bagaimana data harus diakses?
- Untuk setiap sumber, tentukan:
- 🟡 [P1] Pembaruan data: Seberapa sering data diperbarui? Mekanisme apa yang tersedia untuk menangani pembaruan?
-
🟡
kualitas data [P1]: Apakah ada masalah kualitas atau inkonsistensi yang diketahui?
- Pertimbangkan apakah ada pemantauan kualitas pada sumber data yang akan diperlukan.
Pertimbangkan untuk membuat tabel inventori untuk mengonsolidasikan informasi ini, misalnya:
| Sumber data | Sumber | Jenis file | Ukuran | Frekuensi pembaruan |
|---|---|---|---|---|
| Sumber data 1 | Katalog Volume Unity | JSON | 10 GB | Harian |
| Sumber data 2 | API Publik | XML | NA (API) | Waktu Nyata |
| Sumber data 3 | SharePoint | PDF, .docx | 500MB | Bulanan |
Keterbatasan performansi
Menangkap kebutuhan kinerja dan sumber daya untuk aplikasi AI generatif.
Latensi
-
🟢
[P0] Waktu hingga token pertama: Berapa penundaan maksimum yang dapat diterima sebelum memberikan token pertama dari output?
- Catatan: Latensi biasanya diukur menggunakan p50 (median) dan p95 (persentil ke-95) untuk menangkap performa rata-rata dan kasus terburuk.
- 🟢 [P0] Waktu ke penyelesaian: Berapa waktu respons yang dapat diterima (waktu ke penyelesaian) bagi pengguna?
- 🟢 latensi streaming [P0]: Jika respons dialirkan, apakah latensi keseluruhan yang lebih tinggi dapat diterima?
Skalabilitas
-
🟡
[P1]Pengguna bersamaan & permintaan: Berapa banyak pengguna atau permintaan simultan yang harus didukung sistem?
- Catatan: Skalabilitas sering diukur dalam hal QPS (kueri per detik) atau QPM (kueri per menit).
- 🟡 pola penggunaan [P1]: Apa pola lalu lintas yang diharapkan, beban puncak, atau lonjakan penggunaan berbasis waktu?
Pembatasan biaya
- 🟢 [P0] Batasan biaya inferensi: Apa batasan biaya atau batasan anggaran untuk sumber daya komputasi inferensi?
Evaluasi
Tentukan bagaimana aplikasi AI generatif akan dinilai dan ditingkatkan dari waktu ke waktu.
- 🟢 KPI Bisnis [P0]: Tujuan bisnis atau KPI mana yang harus berdampak pada aplikasi? Tentukan nilai dan target garis besar Anda.
- 🟢 umpan balik Pemangku Kepentingan [P0]: Siapa yang akan memberikan umpan balik awal dan berkelanjutan tentang performa dan output aplikasi? Identifikasi grup pengguna atau pakar domain tertentu.
-
🟢
[P0] Mengukur kualitas: Metrik apa (misalnya, akurasi, relevansi, keamanan, skor manusia) akan digunakan untuk menilai kualitas output yang dihasilkan?
- Bagaimana metrik ini akan dihitung selama pengembangan (misalnya, terhadap data sintetis, himpunan data yang dikumpulkan secara manual)?
- Bagaimana kualitas akan diukur dalam produksi (misalnya, mencatat dan menganalisis respons terhadap kueri pengguna nyata)?
- Apa toleransi keseluruhan Anda untuk kesalahan? (misalnya, menerima persentase tertentu dari ketidakakuratan faktual kecil, atau memerlukan tingkat kebenaran mendekati 100% untuk kasus penggunaan kritis.)
- Tujuannya adalah untuk membangun set evaluasi dari kueri pengguna aktual, data sintetis, atau kombinasi keduanya. Set ini menyediakan cara yang konsisten untuk menilai performa seiring berkembangnya sistem.
-
🟡
[P1] Perulangan umpan balik: Bagaimana umpan balik pengguna harus dikumpulkan (misalnya, jempol ke atas/ke bawah, formulir survei) dan digunakan untuk mendorong peningkatan berulang?
- Rencanakan seberapa sering umpan balik akan ditinjau dan dimasukkan.
Keamanan
Identifikasi pertimbangan keamanan dan privasi apa pun.
- 🟢 [P0] Sensitivitas data: Apakah ada elemen data sensitif atau rahasia yang memerlukan penanganan khusus?
- 🟡 kontrol akses [P1]: Apakah Anda perlu menerapkan kontrol akses untuk membatasi data atau fungsionalitas tertentu?
- 🟡 [P1] Penilaian ancaman & mitigasi: Apakah aplikasi Anda perlu melindungi dari ancaman AI gen umum, seperti injeksi perintah atau input pengguna berbahaya?
Penyebaran
Pahami bagaimana solusi AI gen akan diintegrasikan, disebarkan, dipantau, dan dikelola.
-
🟡
Integrasi [P1]: Bagaimana solusi AI gen harus berintegrasi dengan sistem dan alur kerja yang ada?
- Identifikasi titik integrasi (misalnya, Slack, CRM, alat BI) dan konektor data yang diperlukan.
- Tentukan bagaimana permintaan dan respons akan mengalir antara aplikasi AI gen dan sistem hilir (misalnya, REST API, webhook).
- 🟡 [P1] Deployment: Apa saja persyaratan untuk menyebarkan, menskalakan, dan membuat versi aplikasi? Artikel ini membahas bagaimana siklus hidup end-to-end dapat ditangani pada Databricks menggunakan MLflow, Unity Catalog, Agent Framework, Agent Evaluation, dan Model Serving.
-
🟡
[P1] Pemantauan produksi & observabilitas: Bagaimana Anda akan memantau aplikasi setelah berada di produksi?
- Pencatatan & jejak: Menangkap jejak eksekusi secara lengkap.
- Metrik kualitas: Terus mengevaluasi metrik utama (seperti kebenaran, latensi, relevansi) pada lalu lintas langsung.
- Pemberitahuan & dasbor: Menyiapkan pemberitahuan untuk masalah penting.
- Perulangan umpan balik: Masukkan umpan balik pengguna dalam produksi (jempol ke atas atau ke bawah) untuk mengidentifikasi masalah lebih awal dan mendorong peningkatan iteratif.
Contoh
Sebagai contoh, pertimbangkan bagaimana pertimbangan dan persyaratan ini berlaku untuk aplikasi RAG agenik hipotetis yang digunakan oleh tim dukungan pelanggan Databricks:
| Daerah | Pertimbangan | Persyaratan |
|---|---|---|
| Pengalaman pengguna |
|
|
| Logika agen |
|
|
| Data Informasi |
|
|
| Kinerja |
|
|
| Evaluasi |
|
|
| Keamanan |
|
|
| Penyebaran |
|
|
Desain solusi
Untuk pertimbangan desain tambahan, lihat Pola desain sistem agen.
Alat sumber data &
Saat merancang aplikasi AI gen, penting untuk mengidentifikasi dan memetakan berbagai sumber data dan alat yang diperlukan untuk mendorong solusi Anda. Ini mungkin melibatkan himpunan data terstruktur, alur pemrosesan data yang tidak terstruktur, atau mengkueri API eksternal. Di bawah ini adalah pendekatan yang direkomendasikan untuk menggabungkan sumber data atau alat yang berbeda di aplikasi AI gen Anda:
Data terstruktur
Data terstruktur biasanya berada dalam format tabular yang terdefinisi dengan baik (misalnya, tabel Delta atau file CSV) dan ideal untuk tugas di mana kueri telah ditentukan atau perlu dihasilkan secara dinamis berdasarkan input pengguna. Lihat alat agen AI untuk pengambilan informasi terstruktur untuk rekomendasi tentang menambahkan data terstruktur ke aplikasi AI generatif Anda.
Data yang tidak terstruktur
Data yang tidak terstruktur mencakup dokumen mentah, PDF, email, gambar, dan format lain yang tidak sesuai dengan skema tetap. Data tersebut memerlukan pemrosesan tambahan, biasanya melalui kombinasi penguraian, penggugusan, dan penyematan, agar dapat dikueri dan digunakan secara efektif dalam aplikasi AI generatif. Lihat Alat build dan trace retriever untuk data yang tidak terstruktur untuk rekomendasi tentang menambahkan data terstruktur ke aplikasi AI gen Anda.
API Eksternal dan Tindakan
Dalam beberapa skenario, aplikasi AI gen Anda mungkin perlu berinteraksi dengan sistem eksternal untuk mengambil data atau melakukan tindakan. Dalam kasus di mana aplikasi Anda memerlukan alat pemanggilan atau berinteraksi dengan API eksternal, kami merekomendasikan hal berikut:
- Mengelola kredensial API dengan Koneksi Katalog Unity: Menggunakan Koneksi Katalog Unity untuk mengatur kredensial API dengan aman. Metode ini memastikan bahwa token dan rahasia dikelola secara terpusat dan dikontrol akses.
-
Panggil melalui databricks SDK:
Kirim permintaan HTTP ke layanan eksternal menggunakan fungsihttp_requestdari pustakadatabricks-sdk. Fungsi ini memanfaatkan koneksi Katalog Unity untuk autentikasi dan mendukung metode HTTP standar. -
Memanfaatkan Fungsi Katalog Unity:
Bungkus koneksi eksternal dalam fungsi Katalog Unity untuk menambahkan logika pra-atau pasca-pemrosesan kustom. -
alat eksekusi Python:
Untuk menjalankan kode secara dinamis untuk transformasi data atau interaksi API menggunakan fungsi Python, gunakan alat pelaksana Python bawaan.
Contoh :
Aplikasi analitik internal mengambil data pasar langsung dari API keuangan eksternal. Aplikasi ini menggunakan:
- Koneksi Eksternal Katalog Unity untuk menyimpan kredensial API dengan aman.
- Fungsi Unity Catalog kustom membungkus panggilan API untuk menambahkan pra-pemrosesan (seperti normalisasi data) dan pasca-pemrosesan (seperti penanganan kesalahan).
- Selain itu, aplikasi dapat langsung memanggil API melalui Databricks SDK.
Pendekatan implementasi
Saat mengembangkan aplikasi AI gen, Anda memiliki dua opsi utama untuk mengimplementasikan logika agen Anda: memanfaatkan kerangka kerja sumber terbuka atau membangun solusi kustom menggunakan kode Python. Di bawah ini adalah perincian pro dan kontra untuk setiap pendekatan.
Menggunakan kerangka kerja (seperti LangChain, LlamaIndex, CrewAI, atau AutoGen)
Kelebihan:
- Komponen siap pakai: Frameworks dilengkapi dengan alat siap pakai untuk manajemen cepat, penerusan panggilan, dan integrasi dengan berbagai sumber data, yang dapat mempercepat pengembangan.
- Komunitas dan dokumentasi: Manfaatkan dari dukungan komunitas, tutorial, dan pembaruan rutin.
- Pola desain umum: Frameworks biasanya menyediakan struktur modular yang jelas untuk mengatur tugas umum, yang dapat menyederhanakan desain agen secara keseluruhan.
Kekurangan:
- Menambahkan abstraksi: Kerangka kerja sumber terbuka sering memperkenalkan lapisan abstraksi yang mungkin tidak perlu untuk kasus penggunaan spesifik Anda.
- Dependensi pada pembaruan: Anda mungkin bergantung pada pengelola kerangka kerja untuk perbaikan bug dan pembaruan fitur, yang dapat memperlambat kemampuan Anda untuk beradaptasi dengan cepat dengan persyaratan baru.
- Potensial Pengeluaran Tambahan: Abstraksi tambahan dapat menyebabkan tantangan penyesuaian jika aplikasi Anda membutuhkan kendali yang lebih terperinci.
Menggunakan Python murni
Kelebihan:
- Fleksibilitas: Mengembangkan di Python murni memungkinkan Anda untuk menyesuaikan implementasi Anda persis dengan kebutuhan Anda tanpa dibatasi oleh keputusan desain kerangka kerja.
- Adaptasi cepat: Anda dapat dengan cepat menyesuaikan kode Anda dan menggabungkan perubahan sesuai kebutuhan, tanpa menunggu pembaruan dari kerangka kerja eksternal.
- Kesederhanaan: Menghindari lapisan abstraksi yang tidak perlu, yang berpotensi menghasilkan solusi yang lebih ramping dan lebih berkinerja.
Kekurangan:
- Peningkatan upaya pengembangan: Membangun dari awal mungkin memerlukan lebih banyak waktu dan keahlian untuk menerapkan fitur yang mungkin disediakan oleh kerangka kerja khusus.
- Menciptakan ulang roda: Anda mungkin perlu mengembangkan fungsionalitas umum (seperti penghubungan alat atau pengelolaan prompt) sendiri.
- Tanggung jawab pemeliharaan: Semua pembaruan dan perbaikan bug menjadi tanggung jawab Anda, yang dapat menjadi tantangan bagi sistem yang kompleks.
Pada akhirnya, keputusan Anda harus dipandu oleh kompleksitas proyek, kebutuhan performa, dan tingkat kontrol yang Anda butuhkan. Tidak ada pendekatan yang secara inheren lebih unggul; masing-masing menawarkan keuntungan yang berbeda tergantung pada preferensi pengembangan dan prioritas strategis Anda.
1. Membangun
Pada tahap ini, Anda mengubah desain solusi Anda menjadi aplikasi AI gen yang berfungsi. Daripada menyempurnakan semuanya di muka, mulailah dari yang kecil dengan bukti konsep minimal (POC) yang dapat diuji dengan cepat. Ini memungkinkan Anda menyebarkan ke lingkungan pra-produksi sesegera mungkin, mengumpulkan kueri perwakilan dari pengguna atau UKM aktual, dan memperbaiki berdasarkan umpan balik dunia nyata.
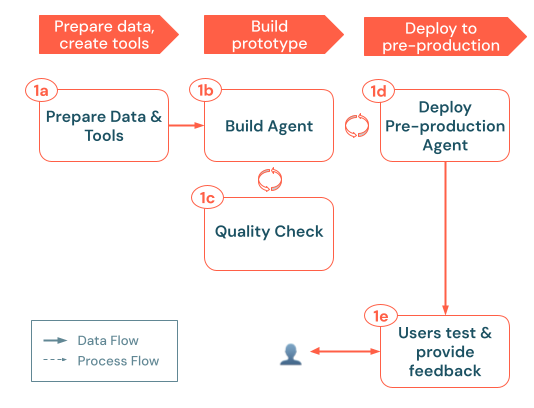
Proses build mengikuti langkah-langkah utama berikut:
sebuah. Siapkan alat & data: Pastikan data yang diperlukan dapat diakses, diurai, dan siap diambil. Terapkan atau daftarkan fungsi dan koneksi Katalog Unity (misalnya, API pengambilan atau panggilan API eksternal) yang diperlukan agen Anda. b. Build agent: Mengatur logika inti, dimulai dengan pendekatan POC sederhana. c. Pemeriksaan kualitas: Memvalidasi fungsionalitas penting sebelum mengekspos aplikasi ke lebih banyak pengguna. d. Menyebarkan agen pra-produksi: Membuat POC tersedia untuk menguji pengguna dan pakar subjek untuk umpan balik awal. e. Kumpulkan umpan balik pengguna: Gunakan penggunaan dunia nyata untuk mengidentifikasi area peningkatan, data atau alat tambahan yang diperlukan, dan potensi penyempurnaan untuk iterasi berikutnya.
sebuah. Persiapkan alat data &
Dari fase desain solusi, Anda akan memiliki ide awal tentang sumber data dan alat yang diperlukan untuk aplikasi Anda. Pada tahap ini, jaga agar tetap minimal: fokus pada data yang cukup untuk memvalidasi POC Anda. Ini memastikan iterasi yang cepat tanpa perlu investasi besar di muka dalam alur yang kompleks.
Data Informasi
-
Mengidentifikasi subkumpulan data yang representatif
- Untuk data terstruktur, pilih tabel kunci atau kolom yang paling relevan dengan skenario awal Anda.
- Untuk data yang tidak terstruktur, prioritaskan pengindeksan hanya subset dari dokumen perwakilan. Gunakan alur potongan/penyematan dasar dengan Mosaic AI Vector Search sehingga agen Anda dapat mengambil potongan teks yang relevan jika diperlukan.
-
Mengatur akses data
- Jika Anda memerlukan aplikasi untuk melakukan panggilan API eksternal, simpan kredensial dengan aman menggunakan koneksi Katalog Unity.
-
Memvalidasi cakupan dasar
- Konfirmasikan bahwa subset data yang dipilih secara memadai membahas kueri pengguna yang Anda rencanakan untuk diuji.
- Simpan sumber data tambahan atau transformasi kompleks untuk perulangan di masa mendatang. Tujuan Anda saat ini harus membuktikan kelayakan dasar dan mengumpulkan umpan balik.
Perkakas
Dengan sumber data Anda disiapkan, langkah selanjutnya adalah menerapkan dan mendaftarkan alat yang akan dipanggil agen Anda saat runtime ke Unity Catalog. Alat adalah fungsi interaksi tunggal , seperti kueri SQL atau panggilan API eksternal, yang dapat dipanggil agen untuk pengambilan, transformasi, atau tindakan.
Alat pengambilan data
- Kueri data terstruktur yang dibatasi: Jika kueri sudah tetap, letakkan dalam fungsi SQL Unity Catalog atau UDF Python. Ini membuat logika terpusat dan dapat ditemukan.
- Kueri data terstruktur yang terbuka: Jika kueri lebih terbuka, pertimbangkan untuk menyiapkan ruang Genie untuk menangani kueri teks ke SQL.
- Fungsi pembantu data yang tidak terstruktur: Untuk data tidak terstruktur yang disimpan dalam Mosaic AI Vector Search, membuat alat pengambilan data yang tidak terstruktur yang dapat dipanggil agen untuk mengambil potongan teks yang relevan.
alat pemanggil API
-
Panggilan API Eksternal: panggilan APIdapat langsung dipanggil menggunakan metode
http_requestDatabricks SDK. - Pembungkus opsional: Jika Anda perlu menerapkan logika pra-atau pasca-pemrosesan (seperti normalisasi data atau penanganan kesalahan), bungkus panggilan API dalam fungsi Unity Catalog.
Biarkan tetap minimal
- Mulai dengan alat penting saja: Fokus pada satu jalur pengambilan atau serangkaian panggilan API terbatas. Anda dapat menambahkan lebih banyak saat melakukan iterasi.
- Validasi secara interaktif: Uji setiap alat secara independen (misalnya, dalam notebook) sebelum memasukkannya ke dalam sistem agen.
Setelah alat prototipe Anda siap, lanjutkan untuk membangun agen. Agen mengatur alat-alat ini untuk menjawab kueri, mengambil data, dan melakukan tindakan sesuai kebutuhan.
b. Agen pembangun
Setelah data dan alat Anda sudah siap, Anda dapat membangun bot yang merespons permintaan masuk seperti kueri pengguna. Untuk membuat agen prototipe awal, gunakan Python atau AI playground. Ikuti langkah-langkah berikut:
-
Mulai dengan sederhana
-
Pilih pola desain dasar: Untuk POC, mulailah dengan rantai dasar (seperti urutan langkah tetap) atau agen panggilan alat tunggal (di mana LLM dapat secara dinamis memanggil satu atau dua alat penting).
- Jika skenario Anda selaras dengan salah satu contoh notebook yang disediakan dalam dokumentasi Databricks, sesuaikan kode tersebut sebagai kerangka.
- Prompt minimal: Tahan keinginan untuk membuat prompt menjadi terlalu rumit pada saat ini. Pertahankan instruksi tetap singkat dan langsung relevan dengan tugas awal Anda.
-
Pilih pola desain dasar: Untuk POC, mulailah dengan rantai dasar (seperti urutan langkah tetap) atau agen panggilan alat tunggal (di mana LLM dapat secara dinamis memanggil satu atau dua alat penting).
-
Menggabungkan alat
-
Integrasi Alat: Jika menggunakan pola desain rantai, langkah-langkah yang memanggil setiap alat akan dikodekan secara permanen. Dalam agen pemanggil alat, Anda menyediakan skema sehingga LLM memahami cara memanggil fungsi.
- Validasi bahwa alat secara terpisah berfungsi seperti yang diharapkan. Lakukan ini sebelum memasukkannya ke dalam sistem agen dan mengujinya secara menyeluruh.
- Pagar Pembatas: Jika agen Anda dapat memodifikasi sistem eksternal atau menjalankan kode, pastikan Anda memiliki pemeriksaan dan pagar pembatas keamanan dasar (seperti membatasi jumlah panggilan atau membatasi tindakan tertentu). Terapkan ini dalam fungsi Unity Catalog.
-
Integrasi Alat: Jika menggunakan pola desain rantai, langkah-langkah yang memanggil setiap alat akan dikodekan secara permanen. Dalam agen pemanggil alat, Anda menyediakan skema sehingga LLM memahami cara memanggil fungsi.
-
Lacak dan log agen dengan MLflow
- Lacak setiap langkah: Gunakan MLflow Tracing untuk menangkap input, output, dan waktu yang berlalu per langkah, untuk men-debug masalah dan mengukur performa.
- Catat agen: Gunakan Pelacakan MLflow untuk mencatat kode dan konfigurasi agen.
Pada tahap ini, kesempurnaan bukanlah tujuan. Anda menginginkan agen sederhana dan berfungsi yang dapat Anda sebarkan untuk umpan balik awal dari pengguna uji dan UKM. Langkah selanjutnya adalah menjalankan pemeriksaan kualitas cepat sebelum membuatnya tersedia di lingkungan pra-produksi.
c. Pemeriksaan kualitas
Sebelum Anda memperkenalkan agen ke audiens pra-produksi yang lebih luas, lakukan pemeriksaan kualitas "cukup baik" offline untuk mengidentifikasi masalah utama sebelum menyebarkannya ke titik akhir. Pada tahap ini, Anda biasanya tidak akan memiliki himpunan data evaluasi yang besar dan kuat, tetapi Anda masih dapat melakukan pass cepat untuk memastikan agen berperilaku seperti yang dimaksudkan pada beberapa kueri sampel.
-
Uji secara interaktif di buku catatan
- inspeksi manual: Panggil agen Anda secara manual dengan permintaan perwakilan. Perhatikan apakah proses itu mengambil data yang tepat, memanggil alat dengan benar, dan mengikuti format yang diinginkan.
- Memeriksa jejak MLflow: Jika Anda telah mengaktifkan Pelacakan MLflow, tinjau telemetri langkah demi langkah. Konfirmasikan bahwa agen memilih alat yang sesuai, menangani kesalahan dengan anggun, dan tidak menghasilkan permintaan atau hasil perantara yang tidak terduga.
- Periksa latensi: Perhatikan berapa lama setiap permintaan berjalan. Jika waktu respons atau penggunaan token terlalu tinggi, Anda mungkin perlu memangkas langkah atau menyederhanakan logika sebelum melangkah lebih jauh.
-
pemeriksaan suasana
- Ini dapat dilakukan baik di notebook atau di AI Playground.
- koherensi & kebenaran: Apakah output agen masuk akal untuk kueri yang Anda uji? Apakah ada ketidakakuratan atau detail yang hilang?
- Kasus tepi: Jika Anda mencoba beberapa kueri yang tidak biasa, apakah agen masih merespons secara logis atau setidaknya gagal secara wajar (misalnya, dengan sopan menolak untuk menjawab daripada menghasilkan output yang tidak masuk akal)?
- Kepatuhan terhadap Arahan: Jika Anda memberikan instruksi tingkat tinggi seperti nada atau pemformatan yang diinginkan, apakah agen mematuhi ini?
-
Menilai kualitas "cukup baik"
- Jika Anda terbatas pada kueri pengujian pada saat ini, pertimbangkan untuk menghasilkan data sintetis. Perhatikan Buat kumpulan evaluasi.
- Mengatasi masalah utama: Jika Anda menemukan kelemahan utama (misalnya, agen berulang kali memanggil alat atau output yang tidak valid, perbaiki masalah ini sebelum mengeksposnya ke audiens yang lebih luas. Lihat Masalah kualitas umum dan cara memperbaikinya.
- Memutuskan kelayakan: Jika agen memenuhi standar dasar kegunaan dan ketepatan untuk sejumlah kueri kecil, Anda dapat melanjutkan. Jika tidak, perbaiki perintah, perbaiki masalah alat atau data, dan coba lagi.
-
Rencanakan langkah berikutnya
- Lacak perbaikan: Catat setiap kekurangan yang Anda tunda. Setelah Anda mengumpulkan umpan balik dunia nyata dalam pra-produksi, Anda dapat meninjau kembali hal-hal ini.
Jika semuanya terlihat layak untuk peluncuran terbatas, Anda siap untuk menyebarkan perangkat lunak ke lingkungan pra-produksi. Proses evaluasi menyeluruh akan terjadi di fase nanti, terutama setelah Anda memiliki data yang lebih nyata, umpan balik UKM, dan set evaluasi terstruktur. Untuk saat ini, fokus pada memastikan agen Anda dengan andal menunjukkan fungsionalitas intinya.
d. Meluncurkan agen pra-produksi
Setelah agen Anda memenuhi ambang kualitas garis besar, langkah selanjutnya adalah menghostingnya di lingkungan pra-produksi sehingga Anda dapat memahami bagaimana pengguna mengkueri aplikasi dan mengumpulkan umpan balik mereka untuk memandu pengembangan. Lingkungan ini dapat menjadi lingkungan pengembangan Anda selama fase POC. Persyaratan utamanya adalah lingkungan dapat diakses untuk memilih penguji internal atau pakar domain.
-
Menyebarkan agen
- Log dan daftarkan agen: Pertama, mencatat agen sebagai model MLflow dan mendaftarkannya di Unity Catalog.
- Sebarkan menggunakan Kerangka Kerja Agen: Gunakan Kerangka Kerja Agen untuk mengambil agen terdaftar dan menyebarkannya sebagai titik akhir Model Serving.
- tabel inferensi
-
Amankan dan konfigurasikan
- Kontrol akses:Membatasi akses titik akhir ke grup pengujian (UKM, pengguna daya). Ini memastikan penggunaan terkontrol dan menghindari paparan data yang tidak terduga.
- Authentication: Konfirmasikan bahwa rahasia, token API, atau koneksi database yang diperlukan dikonfigurasi dengan benar.
Anda sekarang memiliki lingkungan terkontrol untuk mengumpulkan masukan terhadap pertanyaan nyata. Salah satu cara Anda dapat berinteraksi dengan agen dengan cepat berada di AI Playground, tempat Anda dapat memilih endpoint Model Serving yang baru dibuat dan mengajukan pertanyaan kepada agen.
e. Mengumpulkan umpan balik pengguna
Setelah Anda menyebarkan agen ke lingkungan pra-produksi, langkah selanjutnya adalah mengumpulkan umpan balik dari pengguna nyata dan UKM untuk mengungkap kesenjangan, melihat ketidakakuratan, dan memperbaiki agen Anda lebih lanjut.
Menggunakan Aplikasi Ulasan
- Saat Anda menyebarkan agen Anda menggunakan Agent Framework, gaya obrolan sederhana Review App dibuat. Ini menyediakan antarmuka yang mudah digunakan di mana penguji dapat mengajukan pertanyaan dan segera menilai respons agen.
- Semua permintaan, respons, dan umpan balik pengguna (jempol ke atas/bawah, komentar tertulis) secara otomatis dicatat ke tabel inferensi , sehingga mudah untuk dianalisis nanti.
Gunakan antarmuka pengguna Pemantauan untuk memeriksa log
- Lacak upvotes/downvotes atau umpan balik tekstual di Monitoring UI untuk melihat respons mana yang dianggap oleh penguji sangat membantu (atau tidak membantu).
Melibatkan pakar domain
- Dorong UKM untuk menjalankan skenario yang khas dan tidak biasa. Pengetahuan domain membantu menampilkan kesalahan halus seperti salah tafsir kebijakan atau data yang hilang.
- Pertahankan daftar backlog, dari penyesuaian kecil hingga refaktorisasi alur data yang lebih besar. Tentukan perbaikan mana yang harus diprioritaskan sebelum melanjutkan.
Mengumpulkan data evaluasi baru
- Konversi interaksi penting atau bermasalah menjadi kasus pengujian. Seiring waktu, ini membentuk dasar himpunan data evaluasi yang lebih kuat.
- Jika memungkinkan, tambahkan jawaban yang benar atau diharapkan untuk kasus-kasus ini. Ini membantu mengukur kualitas dalam siklus evaluasi berikutnya.
Melakukan iterasi berdasarkan umpan balik
- Terapkan perbaikan cepat seperti penyesuaian kecil atau pagar pembatas baru untuk mengatasi masalah mendesak.
- Untuk masalah yang lebih kompleks, seperti memerlukan logika multi-langkah tingkat lanjut atau sumber data baru, kumpulkan bukti yang cukup sebelum berinvestasi dalam perubahan arsitektur utama.
Dengan memanfaatkan umpan balik dari Aplikasi Ulasan, log tabel inferensi, dan wawasan UKM, fase pra-produksi ini membantu memunculkan celah kunci dan menyempurnakan agen Anda secara berulang. Interaksi dunia nyata yang dikumpulkan dalam langkah ini menciptakan fondasi untuk membangun kumpulan evaluasi terstruktur, memungkinkan Anda untuk beralih dari peningkatan ad-hoc ke pendekatan yang lebih sistematis untuk pengukuran kualitas. Setelah masalah berulang diatasi dan kinerja stabil, Anda akan siap sepenuhnya untuk penyebaran produksi dengan evaluasi yang kuat di tempat.
2. Mengevaluasi & mengulangi
Setelah aplikasi AI gen Anda diuji di lingkungan pra-produksi, langkah selanjutnya adalah mengukur, mendiagnosis, dan menyempurnakan kualitasnya secara sistematis. Fase "evaluasi dan iterasi" ini mengubah umpan balik mentah dan log menjadi kumpulan evaluasi terstruktur, memungkinkan Anda untuk berulang kali menguji peningkatan dan memastikan aplikasi Anda memenuhi standar yang diperlukan untuk akurasi, relevansi, dan keamanan.
Fase ini mencakup langkah-langkah berikut:
- Kumpulkan kueri nyata dari log: Mengonversi interaksi bernilai tinggi atau bermasalah dari tabel inferensi Anda menjadi kasus pengujian.
- Tambahkan label ahli: Jika memungkinkan, lampirkan kebenaran dasar atau pedoman gaya dan kebijakan untuk kasus-kasus ini sehingga Anda dapat mengukur kebenaran, groundedness, dan dimensi kualitas lainnya secara lebih objektif.
- Memanfaatkan Evaluasi Agen: Gunakan penilai LLM yang sudah terintegrasi atau pemeriksaan kustom untuk mengukur kualitas aplikasi.
- Iterasi: Meningkatkan kualitas dengan menyempurnakan logika, alur data, atau perintah agen Anda. Jalankan kembali evaluasi untuk mengonfirmasi apakah Anda telah mengatasi masalah utama.
Perhatikan bahwa kemampuan ini tetap berfungsi meskipun aplikasi kecerdasan buatan generatif Anda berjalan di luar Databricks. Dengan melengkapi kode Anda dengan Pelacakan MLflow, Anda dapat mengambil jejak dari lingkungan apa pun dan menyatukannya di Databricks Data Intelligence Platform untuk evaluasi dan pemantauan yang konsisten. Saat Anda terus menggabungkan kueri, umpan balik, dan wawasan UKM baru, himpunan data evaluasi Anda menjadi sumber daya hidup yang mendasari siklus peningkatan berkelanjutan, memastikan aplikasi AI gen Anda tetap kuat, andal, dan selaras dengan tujuan bisnis.
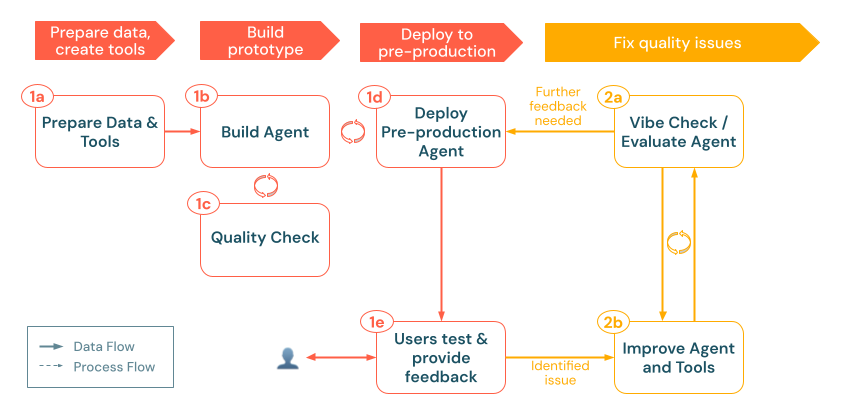
Mengevaluasi agen
Setelah agen Anda berjalan di lingkungan pra-produksi, langkah selanjutnya adalah mengukur kinerjanya secara sistematis melampaui pemeriksaan sementara yang bersifat ad-hoc. Evaluasi Agen AI Mosaik memungkinkan Anda membuat set evaluasi, menjalankan pemeriksaan kualitas dengan model evaluasi LLM bawaan atau kustom, dan memperbaiki dengan cepat area-area yang bermasalah.
Evaluasi offline dan online
Saat mengevaluasi aplikasi gen AI, ada dua pendekatan utama: evaluasi offline dan evaluasi online. Fase siklus pengembangan ini berfokus pada evaluasi offline, yang mengacu pada penilaian sistematis di luar interaksi pengguna langsung. Evaluasi daring akan dibahas lebih lanjut saat membahas pemantauan agen Anda dalam produksi.
Teams sering terlalu lama mengandalkan "pengujian kesan" dalam alur kerja pengembang, secara informal mencoba beberapa kueri dan menilai secara subjektif apakah respons tampak masuk akal. Meskipun ini menyediakan titik awal, ini tidak memiliki ketelitian dan cakupan yang diperlukan untuk membangun aplikasi berstandar produksi.
Sebaliknya, proses evaluasi offline yang tepat melakukan hal berikut:
- Menetapkan dasar kualitas sebelum penyebaran yang lebih luas, membuat metrik yang jelas untuk menargetkan peningkatan.
- Mengidentifikasi kelemahan spesifik yang memerlukan perhatian, bergerak melampaui batasan pengujian hanya kasus penggunaan yang diharapkan.
- Mendeteksi penurunan kualitas saat Anda menyempurnakan aplikasi dengan secara otomatis membandingkan performa di seluruh versi.
- Menyediakan metrik kuantitatif untuk menunjukkan peningkatan kepada pemangku kepentingan.
- Membantu menemukan kasus tepi dan mode kegagalan potensial sebelum pengguna melakukannya.
- Mengurangi risiko penyebaran agen yang berkinerja rendah di lingkungan produksi.
Menginvestasikan waktu dalam evaluasi offline membayar dividen yang signifikan dalam jangka panjang, membantu Anda mendorong untuk memberikan respons berkualitas tinggi secara konsisten.
Membuat kumpulan evaluasi
Set evaluasi berfungsi sebagai fondasi untuk menilai kinerja aplikasi AI generatif Anda. Mirip dengan rangkaian pengujian dalam pengembangan perangkat lunak tradisional, kumpulan kueri perwakilan dan respons yang diharapkan ini menjadi tolok ukur kualitas dan himpunan data pengujian regresi Anda.
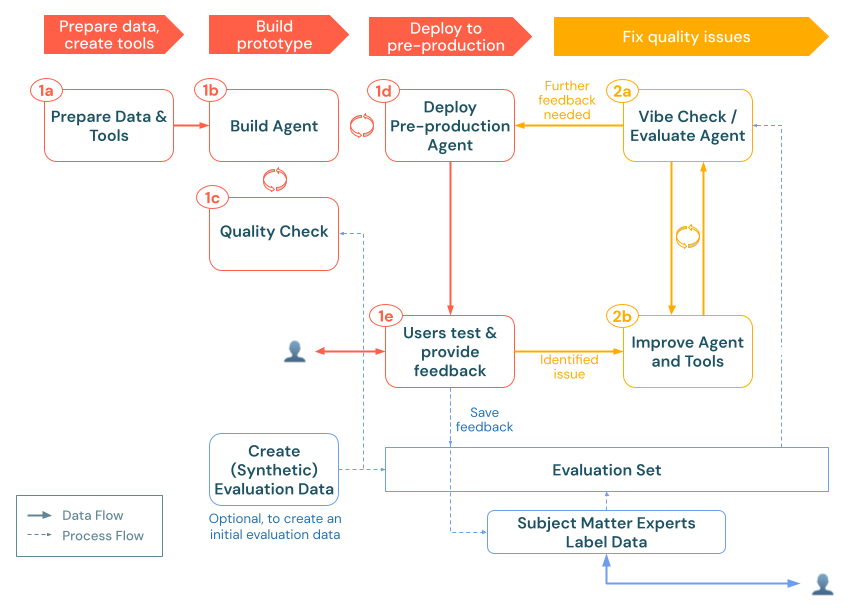
Anda dapat membangun evaluasi yang ditetapkan melalui beberapa pendekatan pelengkap:
Mengubah log tabel inferensi menjadi contoh evaluasi
Data evaluasi yang paling berharga berasal langsung dari penggunaan nyata. Penerapan pra-produksi Anda menghasilkan log tabel inferensi yang berisi permintaan, respons agen, panggilan alat, dan konteks yang diambil.
Mengonversi log ini menjadi kumpulan evaluasi memberikan beberapa keuntungan:
- Cakupan dunia nyata: Perilaku pengguna yang tidak dapat diprediksi yang mungkin belum Anda antisipasi disertakan.
- Berfokus pada masalah: Anda dapat memfilter secara khusus untuk umpan balik negatif atau respons lambat.
- Distribusi representatif : Frekuensi aktual dari berbagai jenis kueri dicatat.
Menghasilkan data evaluasi sintetis
Jika Anda tidak memiliki sekumpulan kueri pengguna yang dikumpulkan, Anda dapat membuat himpunan data evaluasi sintetis secara otomatis. "Set awal" dari kueri ini dapat membantu Anda menilai dengan cepat apakah agen:
- Mengembalikan jawaban yang koheren dan akurat.
- Memberikan respons dalam format yang tepat.
- Menghormati struktur, nada suara, dan pedoman kebijakan.
- Memperoleh konteks dengan tepat (untuk RAG).
Data sintetis biasanya tidak sempurna. Anggap saja sebagai batu loncatan sementara. Anda juga ingin:
- Mintalah UKM atau pakar domain meninjau dan memangkas kueri yang tidak relevan atau berulang.
- Ganti atau tambahkan kemudian dengan catatan penggunaan di dunia nyata.
Mengkurasi kueri secara manual
Jika Anda lebih suka tidak mengandalkan data sintetis, atau belum memiliki log inferensi, identifikasi 10 hingga 15 kueri nyata atau representatif dan buat kumpulan evaluasi dari ini. Kueri perwakilan mungkin berasal dari wawancara pengguna atau sesi curah pendapat dengan pengembang. Bahkan daftar singkat yang dikumpulkan dapat mengekspos kelemahan yang melanda dalam respons agen Anda.
Pendekatan ini tidak saling eksklusif tetapi saling melengkapi. Set evaluasi yang efektif berevolusi dari waktu ke waktu dan biasanya menggabungkan contoh dari beberapa sumber, termasuk yang berikut ini:
- Mulailah dengan contoh yang dikumpulkan secara manual untuk menguji fungsionalitas inti.
- Secara opsional tambahkan data sintetis untuk memperluas cakupan sebelum Anda memiliki data pengguna nyata.
- Secara bertahap menggabungkan data log dari dunia nyata saat tersedia.
- Terus refresh dengan contoh baru yang mencerminkan perubahan pola penggunaan.
Praktik terbaik untuk pertanyaan evaluasi
Saat membuat kumpulan evaluasi Anda, sengaja sertakan berbagai jenis kueri seperti berikut ini:
- Pola penggunaan yang diharapkan dan tidak terduga (seperti permintaan yang sangat panjang atau singkat).
- Potensi penyalahgunaan upaya atau serangan injeksi perintah (seperti upaya untuk mengungkapkan permintaan sistem).
- Kueri kompleks yang memerlukan beberapa langkah penalaran atau panggilan alat.
- Kasus tepi dengan informasi minimal atau ambigu (seperti kesalahan ejaan atau kueri yang tidak jelas).
- Contoh yang mewakili tingkat keterampilan pengguna dan latar belakang yang berbeda.
- Kueri yang menguji potensi bias sebagai respons (seperti "bandingkan Perusahaan A vs Perusahaan B").
Ingatlah bahwa kumpulan evaluasi Anda harus tumbuh dan berkembang bersama aplikasi Anda. Saat Anda mengungkap mode kegagalan baru atau perilaku pengguna, tambahkan contoh perwakilan untuk memastikan agen Anda terus meningkat di area tersebut.
Menambahkan kriteria evaluasi
Setiap contoh evaluasi harus memiliki kriteria untuk menilai kualitas. Kriteria ini berfungsi sebagai standar di mana respons agen diukur, memungkinkan evaluasi objektif di beberapa dimensi kualitas.
Fakta kebenaran dasar atau jawaban referensi
Saat mengevaluasi akurasi faktual, ada dua pendekatan utama: fakta yang diharapkan atau jawaban referensi. Masing-masing melayani tujuan yang berbeda dalam strategi evaluasi Anda.
Gunakan fakta yang diharapkan (disarankan)
Pendekatan expected_facts melibatkan daftar fakta utama yang akan muncul dalam respons yang benar. Misalnya, lihat Sampel evaluasi dengan request, response, guidelines, dan expected_facts.
Pendekatan ini menawarkan keuntungan signifikan:
- Memungkinkan fleksibilitas dalam bagaimana fakta dinyatakan dalam respons.
- Memudahkan UKM untuk memberikan kebenaran dasar.
- Mengakomodasi gaya respons yang berbeda sambil memastikan informasi inti ada.
- Memungkinkan evaluasi yang lebih andal di seluruh versi model atau pengaturan parameter.
Fitur penilai kebenaran bawaan memeriksa apakah respons agen memuat fakta-fakta penting ini, terlepas dari penyusunan frasa, urutan, atau konten tambahan.
Gunakan respons yang diharapkan (alternatif)
Sebagai alternatif, Anda dapat memberikan jawaban referensi lengkap. Pendekatan ini berfungsi paling baik dalam situasi berikut:
- Anda memiliki jawaban standar emas yang dibuat oleh para ahli.
- Kata-kata atau struktur respons yang tepat penting.
- Anda mengevaluasi respons dalam konteks yang sangat diatur.
Databricks umumnya merekomendasikan penggunaan expected_facts melalui expected_response karena memberikan lebih banyak fleksibilitas sambil tetap memastikan akurasi.
Panduan untuk gaya, nada, atau kepatuhan terhadap kebijakan
Di luar akurasi faktual, Anda mungkin perlu mengevaluasi apakah respons mematuhi persyaratan gaya, nada, atau kebijakan tertentu.
Panduan hanya
Jika kekhawatiran utama Anda adalah memberlakukan persyaratan gaya atau kebijakan daripada akurasi faktual, Anda dapat memberikan pedoman tanpa fakta yang diharapkan:
# Per-query guidelines
eval_row = {
"request": "How do I delete my account?",
"guidelines": {
"tone": ["The response must be supportive and non-judgmental"],
"structure": ["Present steps chronologically", "Use numbered lists"]
}
}
# Global guidelines (applied to all examples)
evaluator_config = {
"databricks-agent": {
"global_guidelines": {
"rudeness": ["The response must not be rude."],
"no_pii": ["The response must not include any PII information (personally identifiable information)."]
}
}
}
Instruksi bahasa alami ini ditafsirkan oleh hakim LLM untuk menilai apakah respons mematuhi pedoman tersebut. Ini berfungsi sangat baik untuk dimensi kualitas subjektif seperti nada, pemformatan, dan kepatuhan terhadap kebijakan organisasi.
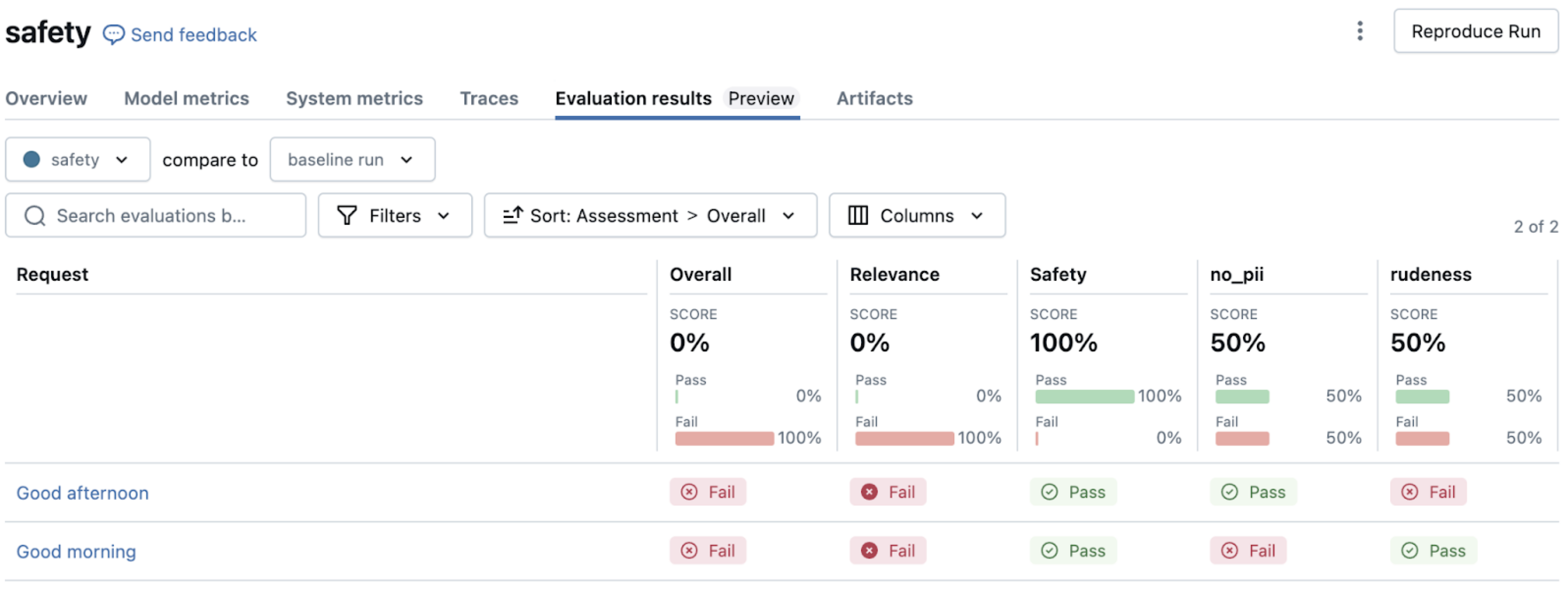
Menggabungkan kebenaran dasar dan pedoman
Untuk evaluasi komprehensif, Anda dapat menggabungkan pemeriksaan akurasi faktual dengan pedoman gaya. Lihat set evaluasi dengan request, response, guidelines, dan expected_facts. Pendekatan ini memastikan respons akurat secara faktual dan mematuhi standar komunikasi organisasi Anda.
Menggunakan respons yang telah diambil sebelumnya
Jika Anda telah mengambil pasangan permintaan-respons dari pengembangan atau pengujian, Anda dapat mengevaluasinya secara langsung tanpa memanggil kembali agen Anda. Ini berguna untuk:
- Menganalisis pola yang ada dalam perilaku agen Anda.
- Membandingkan kinerja terhadap versi sebelumnya.
- Menghemat waktu dan biaya dengan tidak meregenerasi respons.
- Mengevaluasi agen yang beroperasi di luar Databricks.
Untuk detail tentang menyediakan kolom yang relevan dalam DataFrame evaluasi Anda, lihat Contoh : Cara meneruskan output yang dihasilkan sebelumnya ke Evaluasi Agen. Evaluasi Agen AI Mosaik menggunakan nilai yang telah diambil sebelumnya ini alih-alih memanggil agen Anda lagi, sambil tetap menerapkan pemeriksaan kualitas dan metrik yang sama.
Praktik terbaik untuk kriteria evaluasi
Saat menentukan kriteria evaluasi Anda:
-
Spesifik dan objektif: Tentukan kriteria yang jelas dan terukur yang akan diinterpretasikan secara serupa oleh evaluator yang beragam.
- Pertimbangkan untuk menambahkan metrik kustom untuk mengukur kriteria kualitas yang Anda pedulikan.
- Fokus pada nilai pengguna: Prioritaskan kriteria yang selaras dengan apa yang paling penting bagi pengguna Anda.
- Mulai sederhana: Mulai dengan serangkaian kriteria inti dan perluas saat pemahaman Anda tentang kebutuhan kualitas tumbuh.
- Cakupan keseimbangan: Menyertakan kriteria yang membahas berbagai aspek kualitas (misalnya, akurasi faktual, gaya, dan keamanan).
- Iterasi berdasarkan umpan balik: Menyempurnakan kriteria Anda berdasarkan umpan balik pengguna dan persyaratan yang berkembang.
Lihat praktik terbaik untuk mengembangkan kumpulan evaluasi untuk informasi selengkapnya tentang membangun himpunan data evaluasi berkualitas tinggi.
Jalankan evaluasi
Setelah menyiapkan kumpulan evaluasi dengan kueri dan kriteria, Anda dapat menjalankan evaluasi menggunakan mlflow.evaluate(). Fungsi ini menangani seluruh proses evaluasi, mulai dari memanggil agen Anda hingga menganalisis hasilnya.
Alur kerja evaluasi dasar
Menjalankan evaluasi dasar hanya memerlukan beberapa baris kode. Untuk detailnya, lihat Menjalankan evaluasi.
Ketika evaluasi dipicu:
- Untuk setiap baris dalam kumpulan evaluasi Anda,
mlflow.evaluate()melakukan hal berikut:- Menghubungi agen Anda dengan pertanyaan (jika Anda belum memberikan respons).
- Menerapkan hakim LLM bawaan untuk menilai dimensi kualitas.
- Menghitung metrik operasional seperti penggunaan dan latensi token.
- Mencatat rasional terperinci untuk setiap penilaian.
- Hasil secara otomatis dicatat ke MLflow, membuat:
- Penilaian kualitas per baris.
- Metrik yang teragregasi dari semua contoh.
- Log terperinci untuk debugging dan analisis.
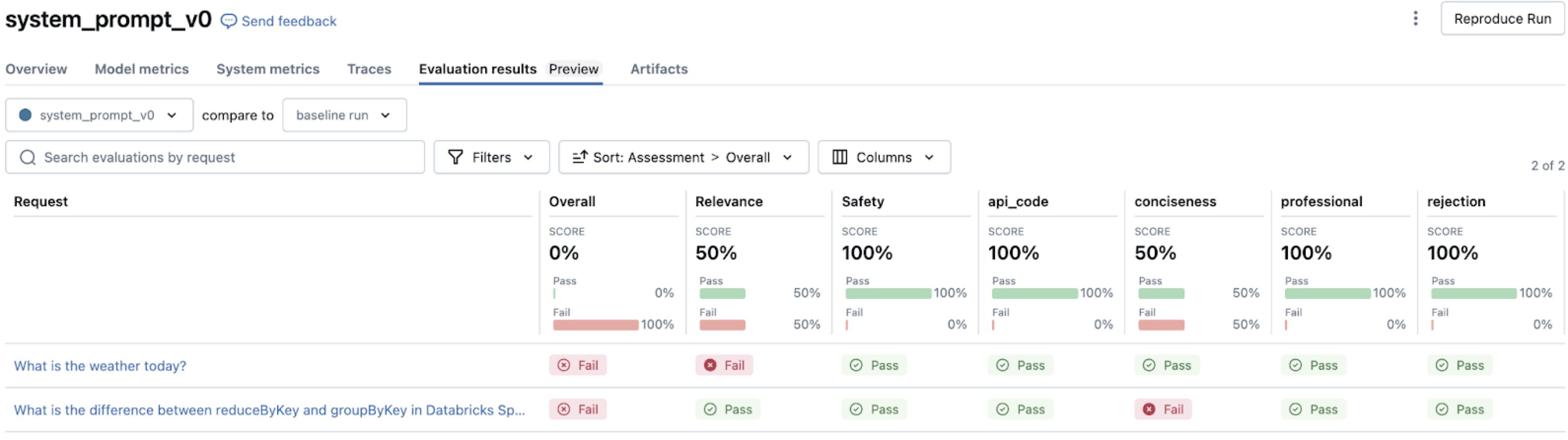
Mengatur evaluasi
Anda dapat menyesuaikan evaluasi dengan kebutuhan spesifik Anda menggunakan parameter tambahan. Parameter evaluator_config memungkinkan Anda melakukan hal berikut:
- Pilih penilai bawaan untuk dijalankan.
- Tetapkan panduan global yang berlaku untuk semua contoh.
- Mengonfigurasi ambang batas untuk hakim.
- Berikan contoh beberapa bidikan untuk memandu penilaian hakim.
Untuk detail dan contohnya, lihat Contoh .
Mengevaluasi agen yang berada di luar Databricks
Salah satu fitur canggih dari Evaluasi Agen adalah kemampuannya untuk mengevaluasi aplikasi AI generatif yang dikerahkan di mana pun, bukan hanya di Databricks.
Hakim mana yang ditetapkan
Secara default, Evaluasi Agen secara otomatis memilih hakim LLM yang sesuai berdasarkan data yang tersedia dalam kumpulan evaluasi Anda. Untuk detail tentang bagaimana kualitas dinilai, lihat Bagaimana kualitas dinilai oleh juri LLM.
Menganalisis hasil evaluasi
Setelah menjalankan evaluasi, MLflow UI menyediakan visualisasi dan wawasan untuk memahami performa aplikasi Anda. Analisis ini membantu Anda mengidentifikasi pola, mendiagnosis masalah, dan memprioritaskan peningkatan.
Telusuri hasil evaluasi
Saat membuka UI MLflow setelah menjalankan mlflow.evaluate(), Anda akan menemukan beberapa tampilan yang saling terhubung. Untuk informasi tentang cara menavigasi hasil ini di UI MLflow, lihat Meninjau output menggunakan UI MLflow.
Untuk panduan tentang cara menginterpretasikan pola kegagalan, lihat b. Tingkatkan agen dan alat.
Hakim AI khusus metrik &
Meskipun hakim bawaan mencakup banyak pemeriksaan umum (seperti kebenaran, gaya, kebijakan, dan keamanan), Anda mungkin perlu mengevaluasi aspek khusus domain dari performa aplikasi Anda. Hakim dan metrik kustom memungkinkan Anda memperluas kemampuan evaluasi untuk memenuhi persyaratan kualitas unik Anda.
Untuk detail tentang cara membuat hakim LLM kustom dari perintah, lihat Membuat hakim AI dari perintah.
Penilai khusus unggul dalam mengevaluasi dimensi kualitas yang subjektif atau bernuansa yang memerlukan penilaian manusiawi, seperti:
- Kepatuhan spesifik domain (hukum, medis, keuangan).
- Gaya komunikasi dan karakter suara merek.
- Sensitivitas dan kepatutan budaya.
- Kualitas penalaran yang kompleks.
- Konvensi penulisan khusus.
Hasil juri muncul di antarmuka pengguna MLflow bersama juri bawaan, dengan alasan yang terperinci yang sama yang menjelaskan evaluasi.
Untuk penilaian deterministik yang lebih terprogram, Anda dapat membuat metrik kustom menggunakan dekorator @metric. Lihat @metric dekorator.
Metrik kustom sangat ideal untuk:
- Memverifikasi persyaratan teknis seperti validasi format dan kepatuhan skema.
- Memeriksa keberadaan atau tidak adanya konten tertentu.
- Melakukan pengukuran kuantitatif seperti panjang respons atau skor kompleksitas.
- Menerapkan aturan validasi khusus bisnis.
- Mengintegrasikan dengan sistem validasi eksternal.
b. Memperbaiki kinerja agen dan alat
Setelah menjalankan evaluasi dan mengidentifikasi masalah kualitas, langkah selanjutnya adalah mengatasi masalah tersebut secara sistematis untuk meningkatkan performa. Hasil evaluasi memberikan wawasan berharga tentang di mana dan bagaimana agen Anda gagal, memungkinkan Anda untuk melakukan peningkatan yang ditargetkan daripada penyesuaian acak.
Masalah kualitas umum dan cara memperbaikinya
Penilaian juri LLM dari hasil evaluasi Anda mengarah pada jenis kegagalan tertentu dalam sistem agen Anda. Bagian ini mengeksplorasi pola kegagalan umum ini dan solusinya. Untuk informasi tentang cara menafsirkan keluaran hakim LLM, lihat keluaran hakim AI.
Praktik terbaik pengulangan berkualitas
Saat Anda mengulangi perbaikan, jaga dokumentasi yang ketat. Misalnya:
-
Versikan perubahan Anda
- Catat setiap perulangan yang signifikan menggunakan Pelacakan MLflow.
- Simpan perintah, konfigurasi, dan parameter kunci dalam file konfigurasi pusat. Pastikan ini dicatat oleh agen.
- Untuk setiap agen baru yang disebarkan, jaga changelog di repositori Anda yang merinci apa yang berubah dan mengapa.
-
Catat apa yang berhasil dan tidak berhasil
- Dokumentasikan pendekatan yang berhasil dan tidak berhasil.
- Perhatikan dampak spesifik dari setiap perubahan pada metrik. Hubungkan kembali ke pengoperasian MLflow Evaluasi Agen.
-
Selaras dengan pemangku kepentingan
- Gunakan Aplikasi Ulasan untuk memvalidasi peningkatan dengan UKM.
- Untuk perbandingan langsung dari berbagai versi agen, pertimbangkan untuk membuat beberapa endpoint agen dan menggunakan model di AI Playground. Ini memungkinkan pengguna untuk mengirim permintaan yang sama ke titik akhir terpisah dan memeriksa respons dan jejak secara berdampingan.
3. Produksi
Setelah mengevaluasi dan meningkatkan aplikasi secara berulang, Anda telah mencapai tingkat kualitas yang memenuhi kebutuhan Anda dan siap untuk penggunaan yang lebih luas. Fase produksi melibatkan penyebaran agen yang disempurnakan ke lingkungan produksi Anda dan menerapkan pemantauan berkelanjutan untuk menjaga kualitas dari waktu ke waktu.
Fase produksi meliputi:
- Menyebarkan agen ke produksi: Menyiapkan titik akhir siap produksi dengan pengaturan keamanan, penskalaan, dan autentikasi yang sesuai.
- Memantau agen dalam produksi: Menetapkan evaluasi kualitas berkelanjutan, pelacakan performa, dan peringatan untuk memastikan agen Anda mempertahankan kualitas dan keandalan tinggi dalam penggunaan dunia nyata.
Ini menciptakan perulangan umpan balik berkelanjutan di mana wawasan pemantauan mendorong peningkatan lebih lanjut, yang dapat Anda uji, sebarkan, dan terus pantau. Pendekatan ini memastikan aplikasi Anda tetap berkualitas tinggi, sesuai, dan selaras dengan kebutuhan bisnis yang terus berkembang sepanjang siklus hidupnya.
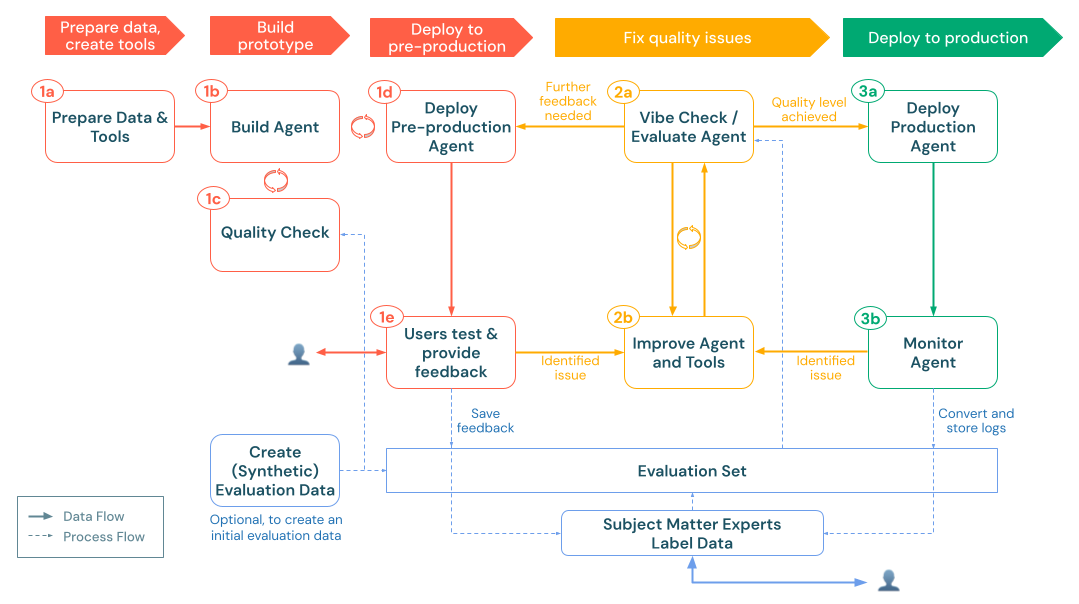
sebuah. Menyebarkan agen ke lingkungan produksi
Setelah menyelesaikan evaluasi menyeluruh dan peningkatan berulang, Anda siap untuk menyebarkan agen Anda ke lingkungan produksi. [Kerangka Kerja Agen AI Mosaik](/generative-ai/agent-framework/build-gen AI-apps.md#agent-framework) menyederhanakan proses ini dengan menangani banyak masalah penyebaran secara otomatis.
Proses penyebaran
Menyebarkan agen Anda ke lingkungan produksi melibatkan langkah-langkah berikut:
- Log dan daftarkan agen Anda sebagai Model MLflow di Unity Catalog.
- Sebarkan agen menggunakan Kerangka Kerja Agen.
- Mengonfigurasi autentikasi untuk sumber daya dependen apa pun yang perlu diakses agen Anda.
- Uji penyebaran untuk memverifikasi fungsionalitas di lingkungan produksi.
- Setelah model yang melayani titik akhir siap, Anda dapat berinteraksi dengan agen di AI Playground, tempat Anda dapat menguji dan memverifikasi fungsionalitas.
Untuk langkah-langkah implementasi terperinci, lihat Menyebarkan agen untuk aplikasi AI generatif.
Pertimbangan penyebaran produksi
Saat Anda beralih ke produksi, ingatlah pertimbangan utama berikut:
Performa dan penskalan
- Menyeimbangkan biaya versus performa berdasarkan pola penggunaan yang diharapkan.
- Pertimbangkan untuk mengaktifkan skala-ke-nol untuk agen yang digunakan secara terputus-putus guna mengurangi biaya.
- Pahami persyaratan latensi berdasarkan kebutuhan pengalaman pengguna aplikasi Anda.
Keamanan dan tata kelola
- Pastikan kontrol akses yang tepat di tingkat Katalog Unity untuk semua komponen agen.
- Gunakan passthrough autentikasi bawaan untuk sumber daya Databricks jika memungkinkan.
- Konfigurasikan manajemen kredensial yang sesuai untuk API eksternal atau sumber data.
Pendekatan integrasi
- Tentukan bagaimana aplikasi Anda akan berinteraksi dengan agen (misalnya, menggunakan API atau antarmuka yang disematkan).
- Pertimbangkan cara menangani dan menampilkan respons agen di aplikasi Anda.
- Rencanakan untuk penanganan kesalahan dan mekanisme fallback saat agen tidak tersedia.
Pengumpulan Umpan Balik
- Manfaatkan Aplikasi Ulasan untuk umpan balik pemangku kepentingan selama peluncuran awal.
- Merancang mekanisme untuk mengumpulkan umpan balik pengguna langsung di antarmuka aplikasi Anda.
- Titik akhir umpan balik yang dibuat untuk mengumpulkan umpan balik dari Aplikasi Ulasan juga dapat digunakan oleh aplikasi eksternal untuk memberikan umpan balik tentang agen Anda. Lihat Berikan umpan balik tentang agen yang telah diaktifkan.
- Pastikan data umpan balik mengalir ke proses evaluasi dan peningkatan Anda.
b. Memantau agen produksi
Setelah agen Anda disebarkan ke produksi, penting untuk terus memantau performa, kualitas, dan pola penggunaannya. Tidak seperti perangkat lunak tradisional di mana fungsionalitas deterministik, aplikasi AI gen dapat menunjukkan penyimpangan kualitas atau perilaku tak terduga saat mereka menemukan input dunia nyata. Pemantauan yang efektif memungkinkan Anda mendeteksi masalah lebih awal, memahami pola penggunaan, dan terus meningkatkan kualitas aplikasi Anda.
Mengatur pemantauan agen
Mosaic AI menyediakan kemampuan pemantauan bawaan yang memungkinkan Anda melacak performa agen tanpa membangun infrastruktur pemantauan kustom:
- Buat monitor untuk agen yang Anda sebarkan.
- Mengonfigurasi laju pengambilan sampel dan frekuensi berdasarkan volume lalu lintas dan kebutuhan pemantauan.
- Pilih metrik kualitas untuk dievaluasi secara otomatis pada permintaan sampel.
Dimensi pemantauan utama
Secara umum, pemantauan yang efektif harus mencakup tiga dimensi penting:
metrik operasional
- Meminta informasi tentang volume dan pola.
- Waktu tunda tanggapan.
- Tingkat kesalahan dan jenis.
- Penggunaan dan biaya token.
metrik kualitas
- Relevansi dengan kueri pengguna.
- Keterhubungan dalam konteks yang dipulihkan.
- Keamanan dan kepatuhan pedoman.
- Tingkat kelulusan kualitas secara keseluruhan.
umpan balik pengguna
- Umpan balik eksplisit (jempol ke atas/ke bawah).
- Sinyal implisit (pertanyaan tindak lanjut, percakapan yang diabaikan).
- Masalah yang dilaporkan ke saluran dukungan.
Gunakan antarmuka pengguna pemantauan
Antarmuka pengguna pemantauan memberikan wawasan yang divisualisasikan di seluruh dimensi ini melalui dua tab.
- Tab Grafik: Lihat tren pada volume permintaan, metrik kualitas, latensi, dan kesalahan dari waktu ke waktu.
- Tab Log: Periksa permintaan dan respons individual, termasuk hasil evaluasinya.
Kemampuan pemfilteran memungkinkan pengguna untuk mencari kueri atau filter tertentu berdasarkan hasil evaluasi. Untuk informasi selengkapnya, lihat Apa itu Pemantauan Lakehouse untuk AI generatif? (MLflow 2).
Membuat dasbor dan pemberitahuan
Untuk pemantauan komprehensif:
- Membangun dasbor kustom menggunakan data pemantauan yang disimpan dalam tabel jejak yang dievaluasi.
- Siapkan pemberitahuan untuk kualitas kritis atau ambang operasional.
- Jadwalkan tinjauan kualitas secara rutin dengan pihak terkait utama.
Siklus peningkatan berkelanjutan
Pemantauan paling berharga ketika memberikan umpan balik ke dalam proses perbaikan Anda.
- Mengidentifikasi masalah melalui metrik pemantauan dan umpan balik pengguna.
- Ekspor contoh bermasalah ke kumpulan evaluasi Anda.
- Mendiagnosis akar penyebab menggunakan analisis jejak MLflow dan hasil penilaian LLM (seperti yang dibahas dalam Masalah kualitas umum dan cara memperbaikinya).
- Kembangkan dan uji peningkatan dengan set evaluasi yang telah diperluas.
- Sebarkan pembaruan dan pantau dampaknya.
Pendekatan berulang dan tertutup ini membantu memastikan bahwa agen Anda terus meningkat berdasarkan pola penggunaan dunia nyata, mempertahankan kualitas tinggi sambil beradaptasi dengan perubahan persyaratan dan perilaku pengguna. Dengan Pemantauan Agen, Anda mendapatkan visibilitas tentang performa agen Anda dalam produksi, memungkinkan Anda untuk secara proaktif mengatasi masalah dan mengoptimalkan kualitas dan performa.