Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini memberikan gambaran umum tentang Mosaic AI Vector Search, termasuk apa itu dan cara kerjanya.
Apa itu Mosaic AI Vector Search?
Mosaic AI Vector Search adalah solusi pencarian vektor yang dibangun ke dalam Databricks Data Intelligence Platform dan terintegrasi dengan alat tata kelola dan produktivitasnya. Pencarian vektor adalah jenis pencarian yang dioptimalkan untuk memperoleh embedding vektor. Penyematan adalah representasi matematika dari konten semantik data, biasanya data teks atau gambar. Penyematan dihasilkan oleh model bahasa besar dan merupakan komponen utama dari banyak aplikasi AI generatif yang bergantung pada menemukan dokumen atau gambar yang mirip satu sama lain. Contohnya adalah sistem RAG, sistem pemberi rekomendasi, dan pengenalan gambar dan video.
Dengan Mosaic AI Vector Search, Anda membuat indeks pencarian vektor dari tabel Delta. Indeks mengandung data yang tertanam dengan metadata. Anda kemudian dapat mengkueri indeks menggunakan REST API untuk mengidentifikasi vektor yang paling mirip dan mengembalikan dokumen terkait. Anda dapat menyusun indeks untuk disinkronkan secara otomatis saat tabel Delta yang mendasar diperbarui.
Mosaic AI Vector Search mendukung hal berikut:
- Pencarian kesamaan kata kunci hibrid.
- Pemfilteran.
- Daftar kontrol akses (ACL) untuk mengelola titik akhir pencarian vektor.
- Sinkronkan hanya kolom yang dipilih.
- Simpan dan sinkronkan penyematan yang dihasilkan.
Bagaimana cara kerja Pencarian Vektor Mosaik AI?
Mosaic AI Vector Search menggunakan algoritma Hierarchical Navigable Small World (HNSW) untuk perkiraan pencarian tetangga terdekatnya dan metrik jarak L2 untuk mengukur kesamaan vektor embedding. Jika Anda ingin menggunakan kesamaan kosinus, Anda perlu menormalkan penyematan titik data Anda sebelum memberinya umpan ke pencarian vektor. Ketika titik data dinormalisasi, peringkat yang dihasilkan oleh jarak L2 sama dengan peringkat yang dihasilkan oleh kesamaan kosinus.
Mosaic AI Vector Search juga mendukung pencarian kesamaan kata kunci hibrid, yang menggabungkan pencarian penyematan berbasis vektor dengan teknik pencarian berbasis kata kunci tradisional. Pendekatan ini cocok dengan kata-kata yang tepat dalam kueri sekaligus menggunakan pencarian kesamaan berbasis vektor untuk menangkap hubungan semantik dan konteks kueri.
Dengan mengintegrasikan kedua teknik ini, pencarian kesamaan kata kunci hibrid mengambil dokumen yang tidak hanya berisi kata kunci yang tepat tetapi juga yang secara konseptual mirip, memberikan hasil pencarian yang lebih komprehensif dan relevan. Metode ini sangat berguna dalam aplikasi RAG di mana data sumber memiliki kata kunci unik seperti SKU atau pengidentifikasi yang tidak cocok untuk pencarian kesamaan murni.
Untuk detail tentang API, lihat Python SDK reference dan Melakukan kueri pada endpoint pencarian vektor.
Perhitungan pencarian kesamaan
Perhitungan pencarian kesamaan menggunakan rumus berikut:
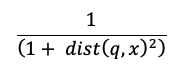
di mana dist adalah jarak Euclidean antara q kueri dan entri indeks x:
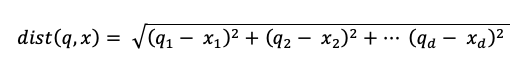
Algoritma pencarian kata kunci
Skor relevansi dihitung menggunakan Okapi BM25. Semua kolom teks atau string dicari, termasuk penyematan teks sumber dan kolom metadata dalam format teks atau string. Fungsi tokenisasi membagi teks pada perbatasan kata, menghapus tanda baca, dan mengubah semua teks menjadi huruf kecil.
Bagaimana pencarian kesamaan dan pencarian kata kunci digabungkan
Hasil pencarian kesamaan dan pencarian kata kunci dikombinasikan menggunakan fungsi Reciprocal Rank Fusion (RRF).
RRF menilai ulang setiap dokumen dari setiap metode menggunakan skor:
Persamaan RRF
Dalam persamaan di atas, peringkat dimulai pada 0, menjumlahkan skor untuk setiap dokumen dan mengembalikan dokumen penilaian tertinggi.
rrf_param mengontrol tingkat kepentingan relatif dokumen berperingkat tinggi dan rendah. Berdasarkan literatur, rrf_param ditetapkan menjadi 60.
Skor dinormalisasi sehingga skor tertinggi adalah 1 dan skor terendah adalah 0 menggunakan persamaan berikut:
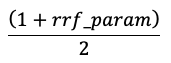
Opsi untuk menyediakan representasi vektor
Untuk membuat indeks pencarian vektor di Databricks, Anda harus terlebih dahulu memutuskan cara menyediakan penyematan vektor. Databricks mendukung tiga opsi:
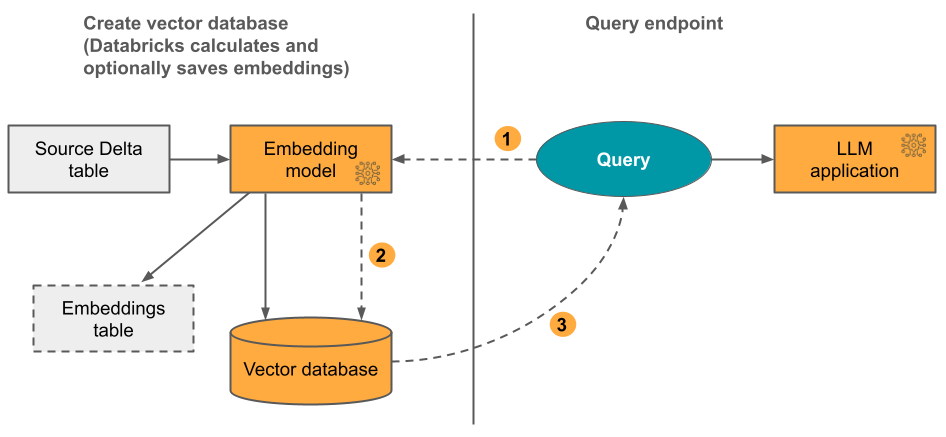
Opsi 1: Indeks Sinkronisasi Delta dengan penyematan yang dihitung oleh Databricks Anda menyediakan tabel Delta sumber yang berisi data dalam format teks. Databricks menghitung penyematan, menggunakan model yang Anda tentukan, dan secara opsional menyimpan penyematan ke tabel di Katalog Unity. Saat tabel Delta diperbarui, indeks tetap disinkronkan dengan tabel Delta.
Diagram berikut menggambarkan proses tersebut:
- Menghitung penggabungan kueri. Kueri dapat menyertakan filter metadata.
- Lakukan pencarian kesamaan untuk mengidentifikasi dokumen yang paling relevan.
- Mengembalikan dokumen yang paling relevan dan menambahkannya ke kueri.
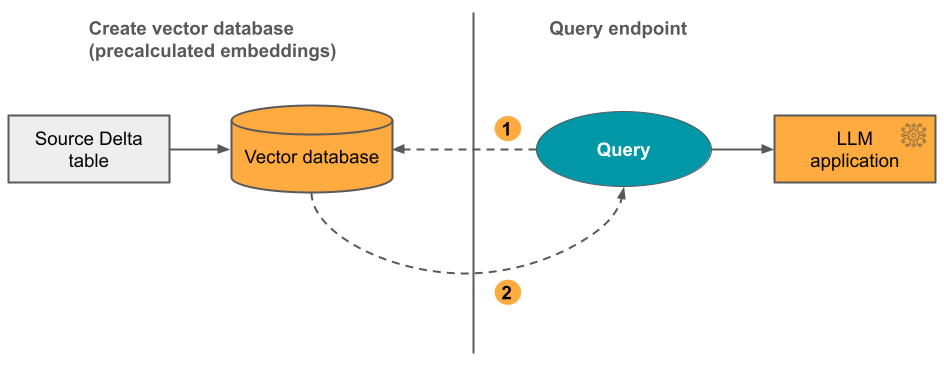
Opsi 2: Indeks Sinkronisasi Delta dengan penyematan yang dikelola sendiri Anda menyediakan tabel Delta sumber yang berisi penyematan yang telah dihitung sebelumnya. Saat tabel Delta diperbarui, indeks tetap disinkronkan dengan tabel Delta.
Diagram berikut menggambarkan proses tersebut:
- Kueri terdiri dari penyematan dan dapat menyertakan filter metadata.
- Lakukan pencarian kesamaan untuk mengidentifikasi dokumen yang paling relevan. Mengembalikan dokumen yang paling relevan dan menambahkannya ke kueri.
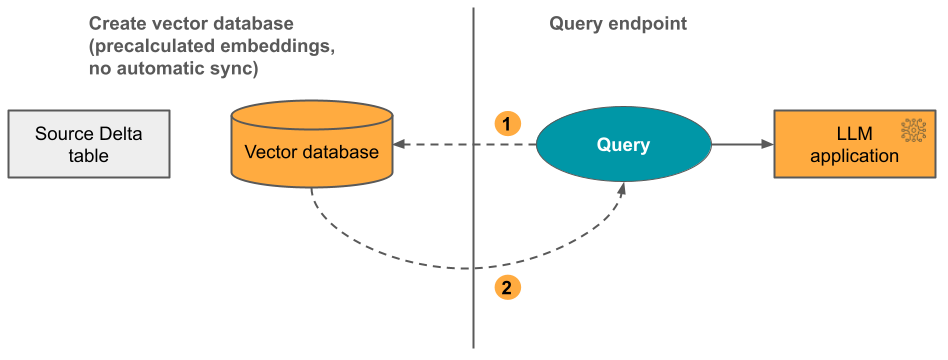
Opsi 3: Indeks Akses Vektor Langsung Anda harus memperbarui indeks secara manual menggunakan REST API saat tabel penyematan berubah.
Diagram berikut menggambarkan proses tersebut:
Opsi titik akhir
Mosaic AI Vector Search menyediakan opsi berikut sehingga Anda dapat memilih konfigurasi titik akhir yang memenuhi kebutuhan aplikasi Anda.
Nota
Titik akhir penyimpanan yang dioptimalkan berada di Pratinjau Umum dan tersedia di wilayah berikut: eastus, eastus2, westus, westus2, westeurope.
- Titik akhir standar memiliki kapasitas 320 juta vektor pada dimensi 768.
- Titik akhir yang dioptimalkan penyimpanan memiliki kapasitas yang lebih besar (lebih dari satu miliar vektor pada dimensi 768) dan menyediakan pengindeksan 10-20x lebih cepat. Kueri pada titik akhir yang dioptimalkan untuk penyimpanan memiliki latensi yang sedikit lebih tinggi sekitar 250ms. Harga untuk opsi ini dioptimalkan untuk jumlah vektor yang lebih besar. Untuk detail harga, lihat halaman harga pencarian vektor. Untuk informasi tentang mengelola biaya pencarian vektor, lihat Mosaic AI Vector Search: Panduan manajemen biaya.
Anda menentukan jenis titik akhir saat membuat titik akhir.
Lihat juga Batasan titik akhir yang dioptimalkan untuk penyimpanan.
Cara mengatur Mosaic AI Vector Search
Untuk menggunakan Mosaic AI Vector Search, Anda harus membuat hal berikut:
Titik akhir pencarian vektor. Titik akhir ini melayani indeks pencarian vektor. Anda dapat mengkueri dan memperbarui titik akhir menggunakan REST API atau SDK. Lihat Membuat endpoint pencarian vektor untuk petunjuknya.
Titik akhir meningkatkan kapasitas secara otomatis untuk mendukung ukuran indeks atau jumlah permintaan bersamaan. Titik akhir yang dioptimalkan untuk penyimpanan secara otomatis mengurangi skala saat indeks dihapus. Titik akhir standar tidak menurunkan skala secara otomatis.
Indeks pencarian vektor. Indeks pencarian vektor dibuat dari tabel Delta dan dioptimalkan untuk memberikan perkiraan real time pencarian tetangga terdekat. Tujuan pencarian adalah untuk mengidentifikasi dokumen yang mirip dengan kueri. Indeks pencarian vektor muncul di dan diatur oleh Katalog Unity. Lihat Membuat indeks pencarian vektor untuk instruksi.
Selain itu, jika Anda memilih agar Databricks menghitung embedding, Anda dapat menggunakan titik akhir API Model Dasar yang telah dikonfigurasi sebelumnya atau membuat titik akhir penyajian model untuk menyajikan model embedding pilihan Anda. Lihat API Model Dasar Bayar per Token atau Membuat titik akhir penyajian model dasar untuk panduan.
Untuk mengkueri titik akhir penyajian model, Anda menggunakan REST API atau Python SDK. Kueri Anda dapat menentukan filter berdasarkan kolom apa pun dalam tabel Delta. Untuk detailnya, lihat Menggunakan filter pada kueri, referensi API, atau referensi Python SDK.
Persyaratan
- Ruang kerja yang menggunakan Katalog Unity.
- Komputasi tanpa server diaktifkan. Untuk petunjuknya, lihat Menyambungkan ke komputasi tanpa server.
- Untuk titik akhir standar, tabel sumber harus mengaktifkan Ubah Umpan Data. Lihat Penggunaan umpan data perubahan Delta Lake di Azure Databricks.
- Untuk membuat indeks pencarian vektor, Anda harus memiliki hak istimewa CREATE TABLE pada skema katalog tempat indeks akan dibuat.
Izin untuk membuat dan mengelola titik akhir pencarian vektor dikonfigurasi menggunakan daftar kontrol akses. Lihat Daftar Kontrol Akses titik akhir pencarian vektor.
Perlindungan dan autentikasi data
Databricks menerapkan kontrol keamanan berikut untuk melindungi data Anda:
- Setiap permintaan pelanggan ke Mosaic AI Vector Search secara logis diisolasi, diautentikasi, dan diotorisasi.
- Mosaic AI Vector Search mengenkripsi semua data yang disimpan (AES-256) dan saat ditransmisikan (TLS 1.2+).
Mosaic AI Vector Search mendukung dua mode autentikasi, perwakilan layanan, dan token akses pribadi (PATs). Untuk aplikasi produksi, Databricks merekomendasikan agar Anda menggunakan prinsipal layanan, yang dapat memiliki performa per kueri hingga 100 msec lebih cepat dibandingkan dengan token akses pribadi.
Token prinsipal layanan. Admin dapat menghasilkan token perwakilan layanan dan meneruskannya ke SDK atau API. Lihat prinsipal layanan. Untuk kasus penggunaan produksi, Databricks merekomendasikan penggunaan token layanan utama.
# Pass in a service principal vsc = VectorSearchClient(workspace_url="...", service_principal_client_id="...", service_principal_client_secret="..." )Token akses pribadi. Anda dapat menggunakan token akses pribadi untuk mengautentikasi dengan Mosaic AI Vector Search. Lihat token autentikasi akses pribadi. Jika Anda menggunakan SDK di lingkungan notebook, SDK secara otomatis menghasilkan token PAT untuk autentikasi.
# Pass in the PAT token client = VectorSearchClient(workspace_url="...", personal_access_token="...")
Customer Managed Keys (CMK) didukung pada endpoint yang dibuat pada atau setelah 8 Mei 2024.
Memantau penggunaan dan biaya
Tabel sistem penggunaan yang dapat ditagih memungkinkan Anda memantau penggunaan dan biaya yang terkait dengan indeks pencarian vektor dan titik akhir. Berikut adalah kueri contoh:
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL THEN 'ingest'
WHEN usage_type = "STORAGE_SPACE" THEN 'storage'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
CASE WHEN workload_type = 'serving' THEN SUM(usage_quantity)
WHEN workload_type = 'ingest' THEN SUM(usage_quantity)
ELSE null
END as dbus,
CASE WHEN workload_type = 'storage' THEN SUM(usage_quantity)
ELSE null
END as dsus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
Anda juga dapat melihat penggunaan berdasarkan kebijakan anggaran. Lihat Pencarian Vektor Mosaik AI: Kebijakan anggaran.
Untuk detail tentang isi tabel penggunaan tagihan, lihat Referensi tabel sistem penggunaan tagihan yang dapat dikenakan biaya. Kueri tambahan ada dalam contoh buku catatan berikut.
Sistem pencarian vektor: tabel, kueri, dan buku catatan
Batas ukuran sumber daya dan data
Tabel berikut ini meringkas batas sumber daya dan ukuran data untuk titik akhir dan indeks pencarian vektor:
| Sumber daya | Granularitas | Batasan |
|---|---|---|
| Titik akhir pencarian vektor | Per ruang kerja | 100 |
| Penyematan | Per titik akhir | ~ 320.000.000 pada dimensi penyematan 768 ~ 160.000.000 pada dimensi penyematan 1536 ~ 80.000.000 pada dimensi penyematan 3072 (menskalakan kira-kira linier) |
| Dimensi pensisipan | Per indeks | 4096 |
| Indeks | Per titik akhir | 50 |
| Kolom | Per indeks | 50 |
| Kolom | Jenis yang didukung: Byte, pendek, bilangan bulat, panjang, mengambang, ganda, boolean, string, tanda waktu, tanggal | |
| Bidang metadata | Per indeks | 50 |
| Nama indeks | Per indeks | 128 karakter |
Batas berikut berlaku untuk pembuatan dan pembaruan indeks pencarian vektor:
| Sumber daya | Granularitas | Batasan |
|---|---|---|
| Ukuran baris untuk Indeks Sinkronisasi Delta | Per indeks | 100KB |
| Menyematkan ukuran kolom sumber untuk indeks Sinkronisasi Delta | Per Indeks | 32764 byte |
| Batas ukuran permintaan upsert dalam jumlah besar untuk indeks Direct Vector | Per Indeks | 10MB |
| Batas ukuran permintaan penghapusan massal untuk indeks Vektor Langsung | Per Indeks | 10MB |
Batas berikut berlaku untuk API kueri.
| Sumber daya | Granularitas | Batasan |
|---|---|---|
| Panjang teks kueri | Per kueri | 32764 byte |
| Jumlah maksimum hasil yang dikembalikan (perkiraan pencarian tetangga terdekat) | Per kueri | 10.000 |
| Jumlah maksimum hasil yang dikembalikan (pencarian kesamaan kata kunci hibrid) | Per kueri | 200 |
Keterbatasan
- Nama kolom
_idsudah dipesan. Jika tabel sumber Anda memiliki kolom bernama_id, ubah namanya sebelum membuat indeks pencarian vektor. - Tingkat izin baris dan kolom tidak didukung. Namun, Anda dapat menerapkan ACL tingkat aplikasi Anda sendiri menggunakan API filter.
Batasan titik akhir yang dioptimalkan untuk penyimpanan
Batasan di bagian ini hanya berlaku untuk titik akhir yang dioptimalkan penyimpanan. Titik akhir penyimpanan yang dioptimalkan berada di Pratinjau Umum.
- Mode sinkronisasi berkelanjutan tidak didukung.
- Fitur sinkronisasi kolom tidak didukung.
- Dimensi penyematan harus dapat dibagi dengan 16.
- Pembaruan inkremental tidak didukung. Setiap sinkronisasi sepenuhnya membangun kembali indeks pencarian vektor.
- Anda dapat mengantisipasi pengurangan waktu keseluruhan yang signifikan yang diperlukan untuk sinkronisasi dibandingkan dengan titik akhir standar. Himpunan data dengan 1 miliar penyematan harus menyelesaikan sinkronisasi dalam waktu kurang dari 8 jam. Himpunan data yang lebih kecil akan membutuhkan lebih sedikit waktu untuk disinkronkan.
- Ruang kerja yang mematuhi HIPAA, PCI, dan FedRAMP tidak didukung.
- Kunci yang dikelola pelanggan (CMK) tidak didukung.
- Titik akhir yang dioptimalkan untuk penyimpanan mendukung hingga 1 miliar penyematan vektor dengan 768 dimensi. Jika Anda memiliki kasus penggunaan skala yang lebih besar, hubungi tim akun Anda.