Apa itu data lakehouse?
Data lakehouse adalah sistem manajemen data yang menggabungkan manfaat data lake dan gudang data. Artikel ini menjelaskan pola arsitektur lakehouse dan apa yang dapat Anda lakukan dengannya di Azure Databricks.
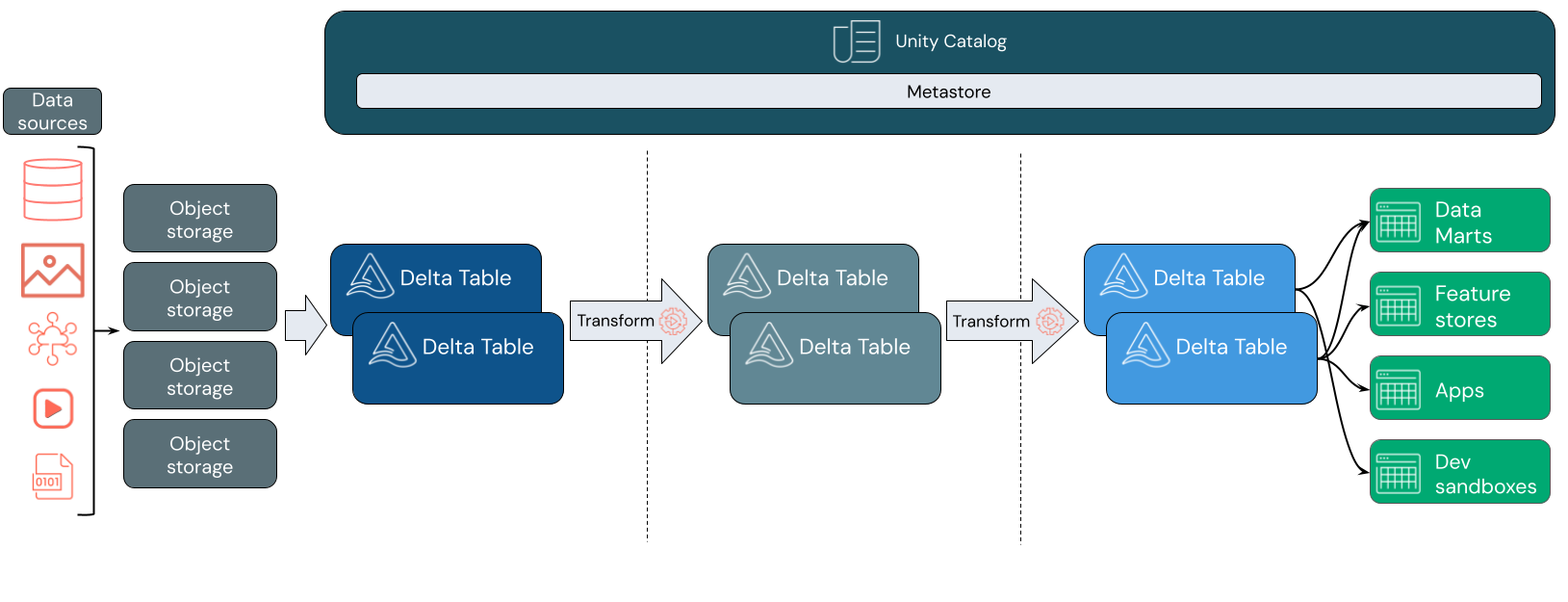
Untuk apa data lakehouse digunakan?
Data lakehouse menyediakan kemampuan penyimpanan dan pemrosesan yang dapat diskalakan untuk organisasi modern yang ingin menghindari sistem terisolasi untuk memproses beban kerja yang berbeda, seperti pembelajaran mesin (ML) dan kecerdasan bisnis (BI). Data lakehouse dapat membantu membangun satu sumber kebenaran, menghilangkan biaya redundan, dan memastikan kesegaran data.
Data lakehouse sering menggunakan pola desain data yang secara bertahap meningkatkan, memperkaya, dan menyempurnakan data saat bergerak melalui lapisan penahapan dan transformasi. Setiap lapisan lakehouse dapat mencakup satu atau beberapa lapisan. Pola ini sering disebut sebagai arsitektur medali. Untuk informasi selengkapnya, lihat Apa itu arsitektur medallion lakehouse?
Bagaimana cara kerja databricks lakehouse?
Databricks dibangun di Apache Spark. Apache Spark memungkinkan mesin yang dapat diskalakan secara besar-besaran yang berjalan pada sumber daya komputasi yang dipisahkan dari penyimpanan. Untuk informasi selengkapnya, lihat Apache Spark di Azure Databricks
Databricks lakehouse menggunakan dua teknologi utama tambahan:
- Delta Lake: lapisan penyimpanan yang dioptimalkan yang mendukung transaksi ACID dan penegakan skema.
- Katalog Unity: solusi tata kelola terpadu dan halus untuk data dan AI.
Penyerapan data
Pada lapisan penyerapan, data batch atau streaming tiba dari berbagai sumber dan dalam berbagai format. Lapisan logis pertama ini menyediakan tempat bagi data tersebut untuk mendarat dalam format mentahnya. Saat mengonversi file tersebut ke tabel Delta, Anda dapat menggunakan kemampuan penegakan skema Delta Lake untuk memeriksa data yang hilang atau tidak terduga. Anda dapat menggunakan Unity Catalog untuk mendaftarkan tabel sesuai dengan model tata kelola data Anda dan batas isolasi data yang diperlukan. Unity Catalog memungkinkan Anda melacak silsilah data Anda saat diubah dan disempurnakan, serta menerapkan model tata kelola terpadu untuk menjaga data sensitif tetap privat dan aman.
Pemrosesan, kurasi, dan integrasi data
Setelah diverifikasi, Anda dapat mulai mengumpulkan dan menyempurnakan data Anda. Ilmuwan data dan praktisi pembelajaran mesin sering bekerja dengan data pada tahap ini untuk mulai menggabungkan atau membuat fitur baru dan menyelesaikan pembersihan data. Setelah data Anda dibersihkan secara menyeluruh, data tersebut dapat diintegrasikan dan diatur ulang ke dalam tabel yang dirancang untuk memenuhi kebutuhan bisnis khusus Anda.
Pendekatan skema-on-write, dikombinasikan dengan kemampuan evolusi skema Delta, berarti Anda dapat membuat perubahan pada lapisan ini tanpa harus menulis ulang logika hilir yang melayani data kepada pengguna akhir Anda.
Penyajian data
Lapisan akhir menyajikan data yang bersih dan diperkaya untuk pengguna akhir. Tabel akhir harus dirancang untuk menyajikan data untuk semua kasus penggunaan Anda. Model tata kelola terpadu berarti Anda dapat melacak silsilah data kembali ke satu sumber kebenaran Anda. Tata letak data, yang dioptimalkan untuk tugas yang berbeda, memungkinkan pengguna akhir mengakses data untuk aplikasi pembelajaran mesin, rekayasa data, dan kecerdasan dan pelaporan bisnis.
Untuk mempelajari selengkapnya tentang Delta Lake, lihat Apa itu Delta Lake? Untuk mempelajari selengkapnya tentang Katalog Unity, lihat Apa itu Katalog Unity?
Kemampuan lakehouse Databricks
Lakehouse yang dibangun di Atas Databricks menggantikan ketergantungan saat ini pada data lake dan gudang data untuk perusahaan data modern. Beberapa tugas utama yang dapat Anda lakukan meliputi:
- Pemrosesan data real time: Memproses data streaming secara real time untuk analisis dan tindakan segera.
- Integrasi data: Menyatukan data Anda dalam satu sistem untuk memungkinkan kolaborasi dan membangun satu sumber kebenaran untuk organisasi Anda.
- Evolusi skema: Memodifikasi skema data dari waktu ke waktu untuk beradaptasi dengan perubahan kebutuhan bisnis tanpa mengganggu alur data yang ada.
- Transformasi data: Menggunakan Apache Spark dan Delta Lake menghadirkan kecepatan, skalabilitas, dan keandalan pada data Anda.
- Analisis dan pelaporan data: Jalankan kueri analitik kompleks dengan mesin yang dioptimalkan untuk beban kerja pergudangan data.
- Pembelajaran mesin dan AI: Terapkan teknik analitik tingkat lanjut ke semua data Anda. Gunakan ML untuk memperkaya data Anda dan mendukung beban kerja lainnya.
- Penerapan versi dan silsilah data: Pertahankan riwayat versi untuk himpunan data dan lacak silsilah data untuk memastikan keterbukaan dan keterlacakan data.
- Tata kelola data: Gunakan sistem terpadu tunggal untuk mengontrol akses ke data Anda dan melakukan audit.
- Berbagi data: Memfasilitasi kolaborasi dengan mengizinkan berbagi himpunan data, laporan, dan wawasan yang dikumpulkan di seluruh tim.
- Analitik operasional: Memantau metrik kualitas data, metrik kualitas model, dan penyimpangan dengan menerapkan pembelajaran mesin ke data pemantauan lakehouse.
Lakehouse vs Data Lake vs Gudang Data
Gudang data telah mendukung keputusan inteligensi bisnis (BI) selama sekitar 30 tahun, setelah berevolusi sebagai serangkaian pedoman desain untuk sistem yang mengontrol aliran data. Gudang data perusahaan mengoptimalkan kueri untuk laporan BI, tetapi dapat memakan waktu beberapa menit atau bahkan berjam-jam untuk menghasilkan hasil. Dirancang untuk data yang tidak mungkin berubah dengan frekuensi tinggi, gudang data berusaha mencegah konflik antara kueri yang berjalan bersamaan. Banyak gudang data mengandalkan format kepemilikan, yang sering membatasi dukungan untuk pembelajaran mesin. Pergudangan data di Azure Databricks memanfaatkan kemampuan databricks lakehouse dan Databricks SQL. Untuk informasi selengkapnya, lihat Apa itu pergudangan data di Azure Databricks?.
Didukung oleh kemajuan teknologi dalam penyimpanan data dan didorong oleh peningkatan eksponensial dalam jenis dan volume data, data lake telah mulai digunakan secara luas selama dekade terakhir. Data lake menyimpan dan memproses data dengan murah dan efisien. Data lake sering didefinisikan berlawanan dengan gudang data: Gudang data memberikan data yang bersih dan terstruktur untuk analitik BI, sementara data lake secara permanen dan murah menyimpan data apa pun dalam format apa pun. Banyak organisasi menggunakan data lake untuk ilmu data dan pembelajaran mesin, tetapi tidak untuk pelaporan BI karena sifatnya yang tidak valid.
Data lakehouse menggabungkan manfaat data lake dan gudang data dan menyediakan:
- Buka, akses langsung ke data yang disimpan dalam format data standar.
- Protokol pengindeksan yang dioptimalkan untuk pembelajaran mesin dan ilmu data.
- Latensi kueri rendah dan keandalan tinggi untuk BI dan analitik tingkat lanjut.
Dengan menggabungkan lapisan metadata yang dioptimalkan dengan data tervalidasi yang disimpan dalam format standar dalam penyimpanan objek cloud, data lakehouse memungkinkan ilmuwan data dan insinyur ML untuk membangun model dari laporan BI berbasis data yang sama.
Langkah selanjutnya
Untuk mempelajari selengkapnya tentang prinsip dan praktik terbaik untuk menerapkan dan mengoperasikan lakehouse menggunakan Databricks, lihat Pengantar data lakehouse yang dirancang dengan baik