Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pelajari cara membuat alur baru menggunakan Lakeflow Spark Declarative Pipelines (SDP) untuk orkestrasi data dan Auto Loader. Tutorial ini memperluas alur sampel dengan membersihkan data dan membuat kueri untuk menemukan 100 pengguna teratas.
Dalam tutorial ini, Anda mempelajari cara menggunakan Editor Alur Lakeflow untuk:
- Buat alur baru dengan struktur folder default dan mulai dengan sekumpulan file sampel.
- Tentukan batasan kualitas data menggunakan harapan.
- Gunakan fitur editor untuk memperluas alur dengan transformasi baru untuk melakukan analisis pada data Anda.
Persyaratan
Sebelum memulai tutorial ini, Anda harus:
- Masuk ke ruang kerja Azure Databricks.
- Mengaktifkan Unity Catalog untuk ruang kerja Anda.
- Aktifkan editor alur Lakeflow untuk ruang kerja Anda, dan Anda harus menyetujui. Lihat Mengaktifkan Editor Alur Lakeflow dan pemantauan yang diperbarui.
- Memiliki izin untuk membuat sumber daya komputasi atau akses ke sumber daya komputasi.
- Memiliki izin untuk membuat skema baru dalam katalog. Izin yang diperlukan adalah
ALL PRIVILEGESatauUSE CATALOGdanCREATE SCHEMA.
Langkah 1: Membuat alur
Dalam langkah ini, Anda membuat alur menggunakan struktur folder default dan sampel kode. Sampel kode mereferensikan users tabel di wanderbricks sumber data sampel.
Di ruang kerja Azure Databricks Anda, klik
 Baru, lalu
Baru, lalu  Alur ETL. Ini membuka editor alur, pada halaman buat alur.
Alur ETL. Ini membuka editor alur, pada halaman buat alur.Klik header untuk memberi nama pipeline Anda.
Tepat di bawah nama, pilih katalog dan skema default untuk tabel output Anda. Ini digunakan ketika Anda tidak menentukan katalog dan skema dalam definisi alur Anda.
Di bawah Langkah berikutnya untuk alur Anda, klik
 Mulailah dengan kode sampel di ikon SQL atau Mulailah dengan kode sampel di Python, berdasarkan preferensi bahasa Anda. Ini mengubah bahasa default untuk kode sampel Anda, tetapi Anda dapat menambahkan kode dalam bahasa lain nanti. Ini membuat struktur folder default dengan kode sampel untuk memulai.
Mulailah dengan kode sampel di ikon SQL atau Mulailah dengan kode sampel di Python, berdasarkan preferensi bahasa Anda. Ini mengubah bahasa default untuk kode sampel Anda, tetapi Anda dapat menambahkan kode dalam bahasa lain nanti. Ini membuat struktur folder default dengan kode sampel untuk memulai.Anda dapat melihat kode sampel di browser aset alur di sisi kiri ruang kerja. Di bawah
transformationsini adalah dua file yang menghasilkan masing-masing satu himpunan data alur. Di bawahexplorationsadalah buku catatan yang memiliki kode untuk membantu Anda menampilkan output alur Anda. Mengklik file memungkinkan Anda melihat dan mengedit kode di editor.Himpunan data output belum dibuat, dan grafik Alur di sisi kanan layar kosong.
Untuk menjalankan kode alur (kode dalam
transformationsfolder), klik Jalankan alur di bagian kanan atas layar.Setelah proses selesai, bagian bawah ruang kerja menunjukkan kepada Anda dua tabel baru yang dibuat,
sample_users_<pipeline-name>dansample_aggregation_<pipeline-name>. Anda juga dapat melihat bahwa grafik Pipeline di sisi kanan ruang kerja sekarang menunjukkan dua tabel, termasuk bahwasample_usersadalah sumber untuksample_aggregation.
Langkah 2: Menerapkan pemeriksaan kualitas data
Dalam langkah ini, Anda menambahkan pemeriksaan kualitas data ke sample_users tabel. Anda menggunakan ekspektasi alur untuk membatasi data. Dalam hal ini, Anda menghapus catatan pengguna apa pun yang tidak memiliki alamat email yang valid, dan menghasilkan tabel yang dibersihkan sebagai users_cleaned.
Di browser aset alur, klik
, dan pilih Transformasi.Dalam dialog Buat file transformasi baru , buat pilihan berikut:
- Pilih Python atau SQL untuk Bahasa. Ini tidak harus cocok dengan pilihan Anda sebelumnya.
- Beri nama file. Dalam hal ini, pilih
users_cleaned. - Untuk Jalur tujuan, biarkan default.
- Untuk Jenis himpunan data, biarkan sebagai Tidak Ada yang dipilih atau pilih Tampilan materialisasi. Jika Anda memilih Tampilan materialisasi, itu menghasilkan kode sampel untuk Anda.
Dalam file kode baru Anda, edit kode agar sesuai dengan yang berikut (gunakan SQL atau Python, berdasarkan pilihan Anda di layar sebelumnya). Ganti
<pipeline-name>dengan nama lengkap untuk tabel Andasample_users.SQL
-- Drop all rows that do not have an email address CREATE MATERIALIZED VIEW users_cleaned ( CONSTRAINT non_null_email EXPECT (email IS NOT NULL) ON VIOLATION DROP ROW ) AS SELECT * FROM sample_users_<pipeline-name>;Phyton
from pyspark import pipelines as dp # Drop all rows that do not have an email address @dp.materialized_view @dp.expect_or_drop("no null emails", "email IS NOT NULL") def users_cleaned(): return ( spark.read.table("sample_users_<pipeline_name>") )Klik Jalankan alur untuk memperbarui alur. Sekarang harus memiliki tiga tabel.
Langkah 3: Menganalisis pengguna teratas
Selanjutnya dapatkan 100 pengguna teratas dengan jumlah pemesanan yang telah dibuat. Gabungkan wanderbricks.bookings tabel ke tampilan materialisasi users_cleaned .
Di browser aset alur, klik
, dan pilih Transformasi.Dalam dialog Buat file transformasi baru , buat pilihan berikut:
- Pilih Python atau SQL untuk Bahasa. Ini tidak harus cocok dengan pilihan Anda sebelumnya.
- Beri nama file. Dalam hal ini, pilih
users_and_bookings. - Untuk Jalur tujuan, biarkan default.
- Untuk Jenis himpunan data, biarkan sebagai Tidak Ada yang dipilih.
Dalam file kode baru Anda, edit kode agar sesuai dengan yang berikut (gunakan SQL atau Python, berdasarkan pilihan Anda di layar sebelumnya).
SQL
-- Get the top 100 users by number of bookings CREATE OR REFRESH MATERIALIZED VIEW users_and_bookings AS SELECT u.name AS name, COUNT(b.booking_id) AS booking_count FROM users_cleaned u JOIN samples.wanderbricks.bookings b ON u.user_id = b.user_id GROUP BY u.name ORDER BY booking_count DESC LIMIT 100;Phyton
from pyspark import pipelines as dp from pyspark.sql.functions import col, count, desc # Get the top 100 users by number of bookings @dp.materialized_view def users_and_bookings(): return ( spark.read.table("users_cleaned") .join(spark.read.table("samples.wanderbricks.bookings"), "user_id") .groupBy(col("name")) .agg(count("booking_id").alias("booking_count")) .orderBy(desc("booking_count")) .limit(100) )Klik Jalankan alur untuk memperbarui himpunan data. Saat proses selesai, Anda dapat melihat di Grafik Alur bahwa ada empat tabel, termasuk tabel baru
users_and_bookings.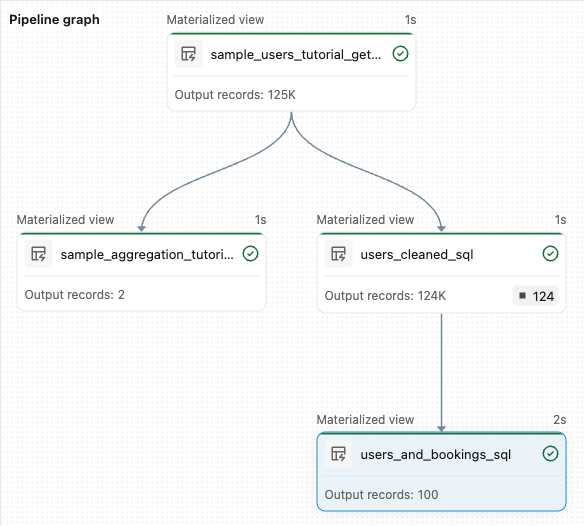
Langkah selanjutnya
Sekarang setelah Anda mempelajari cara menggunakan beberapa fitur editor alur Lakeflow dan membuat alur, berikut adalah beberapa fitur lain untuk mempelajari selengkapnya tentang:
Alat untuk bekerja dengan dan men-debug transformasi saat membuat alur:
- Eksekusi selektif
- Pratinjau data
- DAG interaktif (grafik himpunan data di alur Anda)
Integrasi Bundel Otomatisasi Deklaratif bawaan untuk kolaborasi yang efisien, kontrol versi, dan integrasi CI/CD langsung dari editor: